On the Integration of Self-Attention and Convolution

本文原始文档:https://www.yuque.com/lart/papers/nlu51g
整体概览可见链接里的公众号文章,本文主要针对模型设计的细节进行解释。
从摘要读文章
Convolution and self-attention are two powerful techniques for representation learning, and they are usually considered as two peer approaches that are distinct from each other. In this paper, we show that there exists a strong underlying relation between them, in the sense that the bulk of computations of these two paradigms are in fact done with the same operation.
指出卷积核自注意力实际上可以使用相同的操作完成。
Specifically, we first show that a traditional convolution with kernel size kxk can be decomposed into k^2 individual 1x1 convolutions, followed by shift and summation operations.
这里使用偏移和求和操作来实现对kxk的卷积进行拆解,空间偏移可以看:Pytorch中Spatial-Shift-Operation的5种实现策略
Then, we interpret the projections of queries, keys, and values in self-attention module as multiple 1x1 convolutions, followed by the computation of attention weights and aggregation of the values. Therefore, the first stage of both two modules comprises the similar operation.
self-attention和卷积的第一阶段有着类似的操作。
More importantly, the first stage contributes a dominant computation complexity (square of the channel size) comparing to the second stage.
这里强调了第一阶段的1x1卷积贡献了通道平方的计算复杂度。 实际上,对于大多数任务而言,自注意力的问题主要还是集中在attention矩阵的计算过程,其与序列长度的平方成正比。往往这个时候通道带来的计算量反而不是很大。不知道本文如何解释这一点? 在阅读文章后才知道,论文的关于计算复杂度的分析是针对与窗口的形式下的attention计算来考虑的。那这就解释的通了。不过这里的描述却有着误导的嫌疑。
This observation naturally leads to an elegant integration of these two seemingly distinct paradigms, i.e., a mixed model that enjoys the benefit of both self-Attention and Convolution (ACmix), while having minimum computational overhead compared to the pure convolution or self-attention counterpart.
由此引出了一种更优雅的集成两种运算的方式。看起来是要在前面这个1x1卷积上入手。
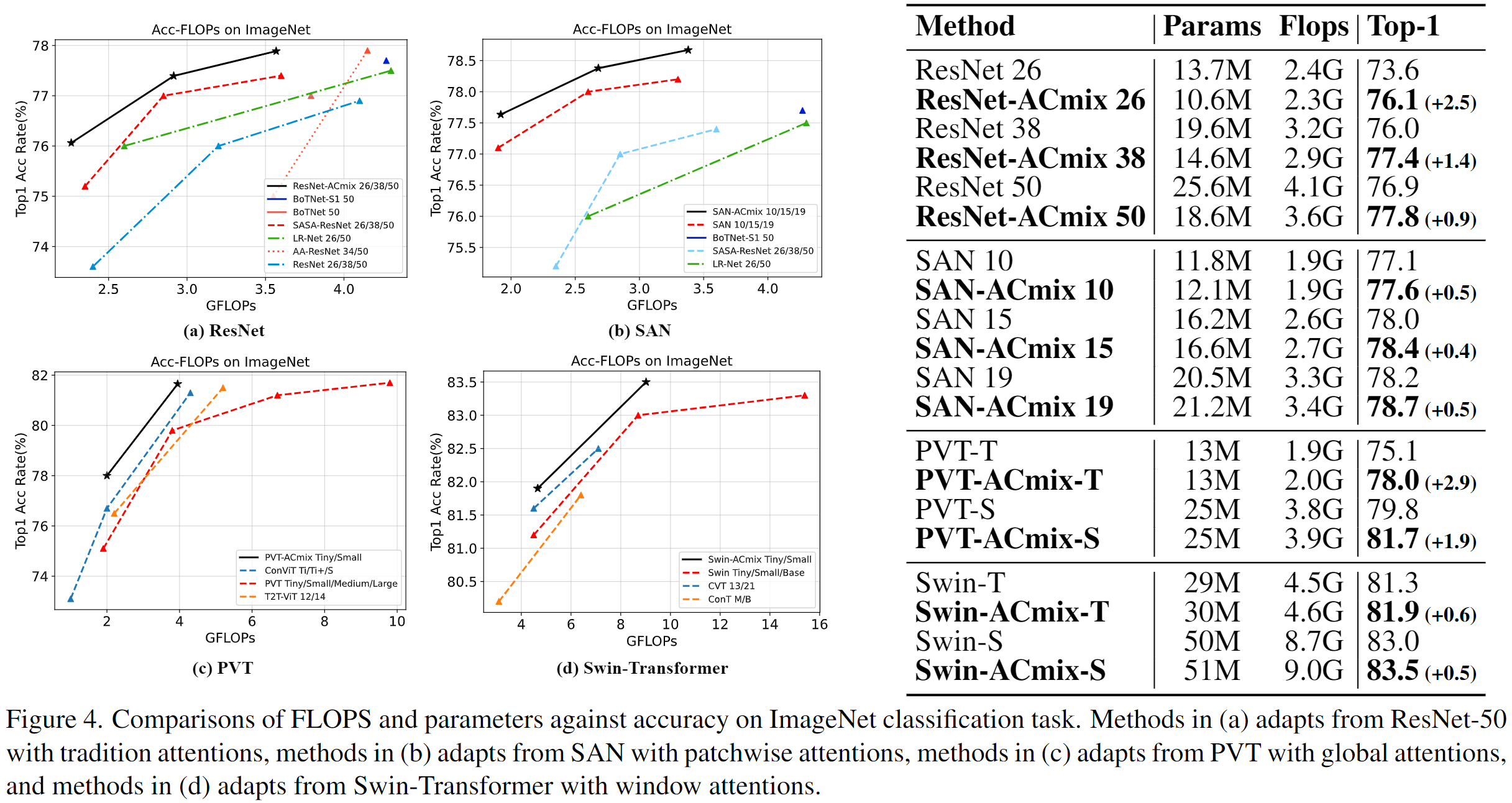
Extensive experiments show that our model achieves consistently improved results over competitive baselines on image recognition and downstream tasks. Code and pre-trained models will be released at this https URL and this https URL.
主要内容
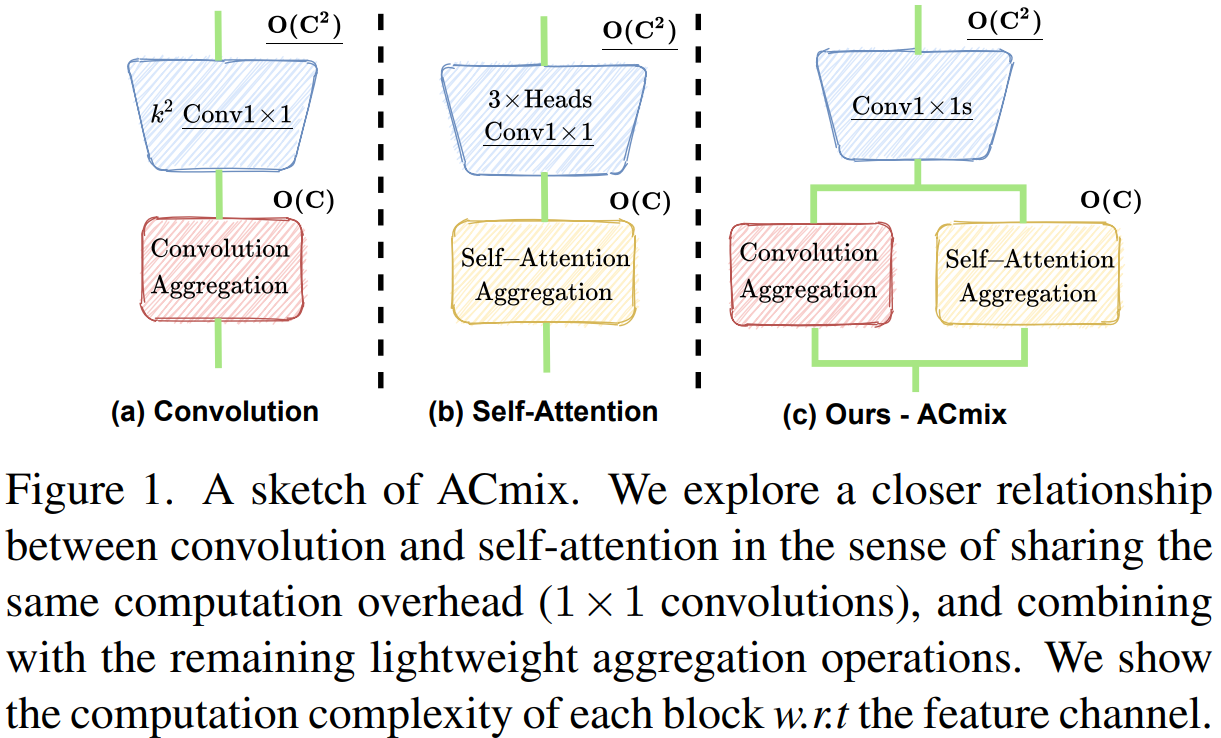
从结构概览可以看出来,本文的目的是将卷积和自注意力中隐式包含的1x1卷积实现共享,从而减少这部分的计算量。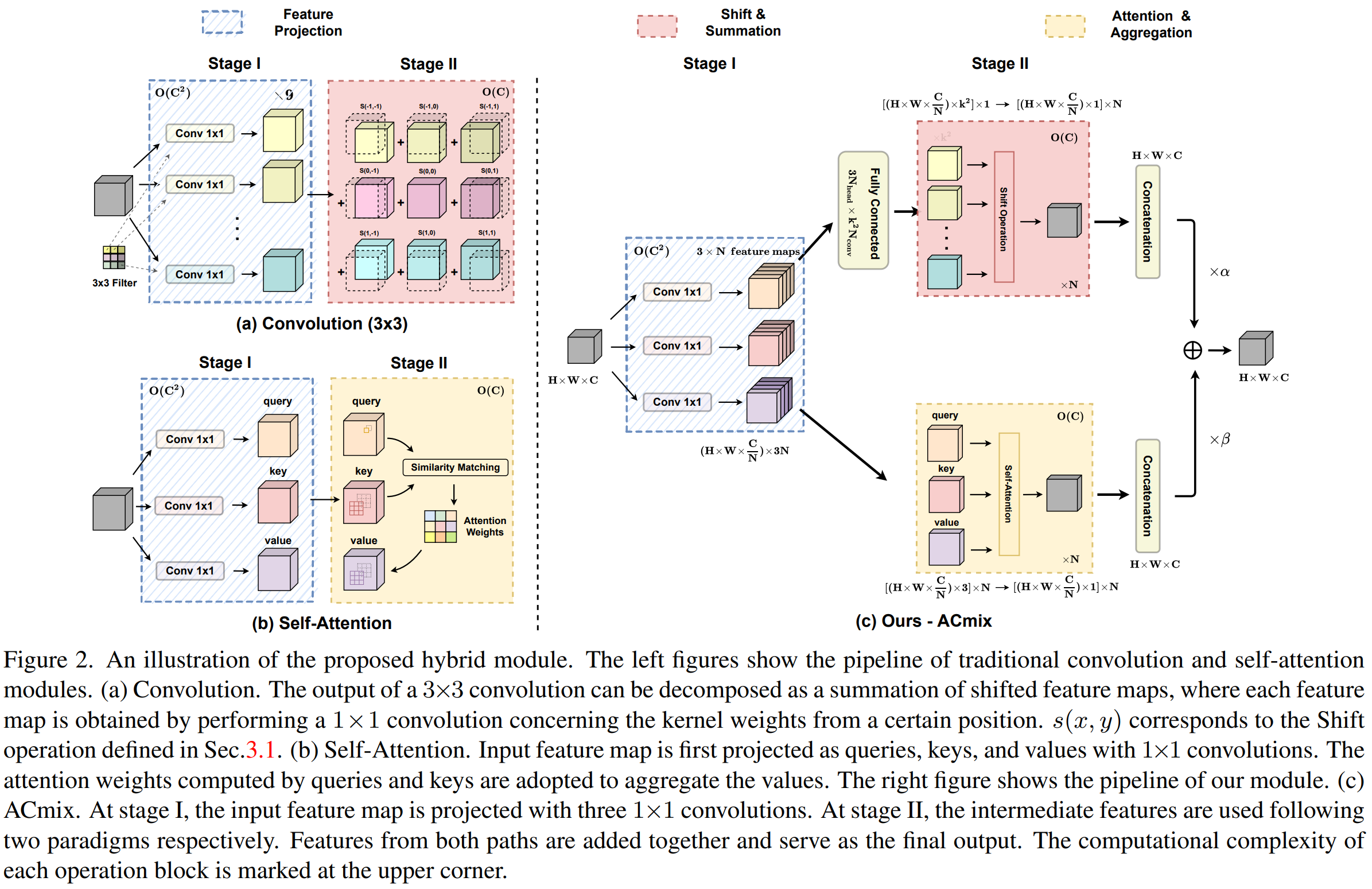
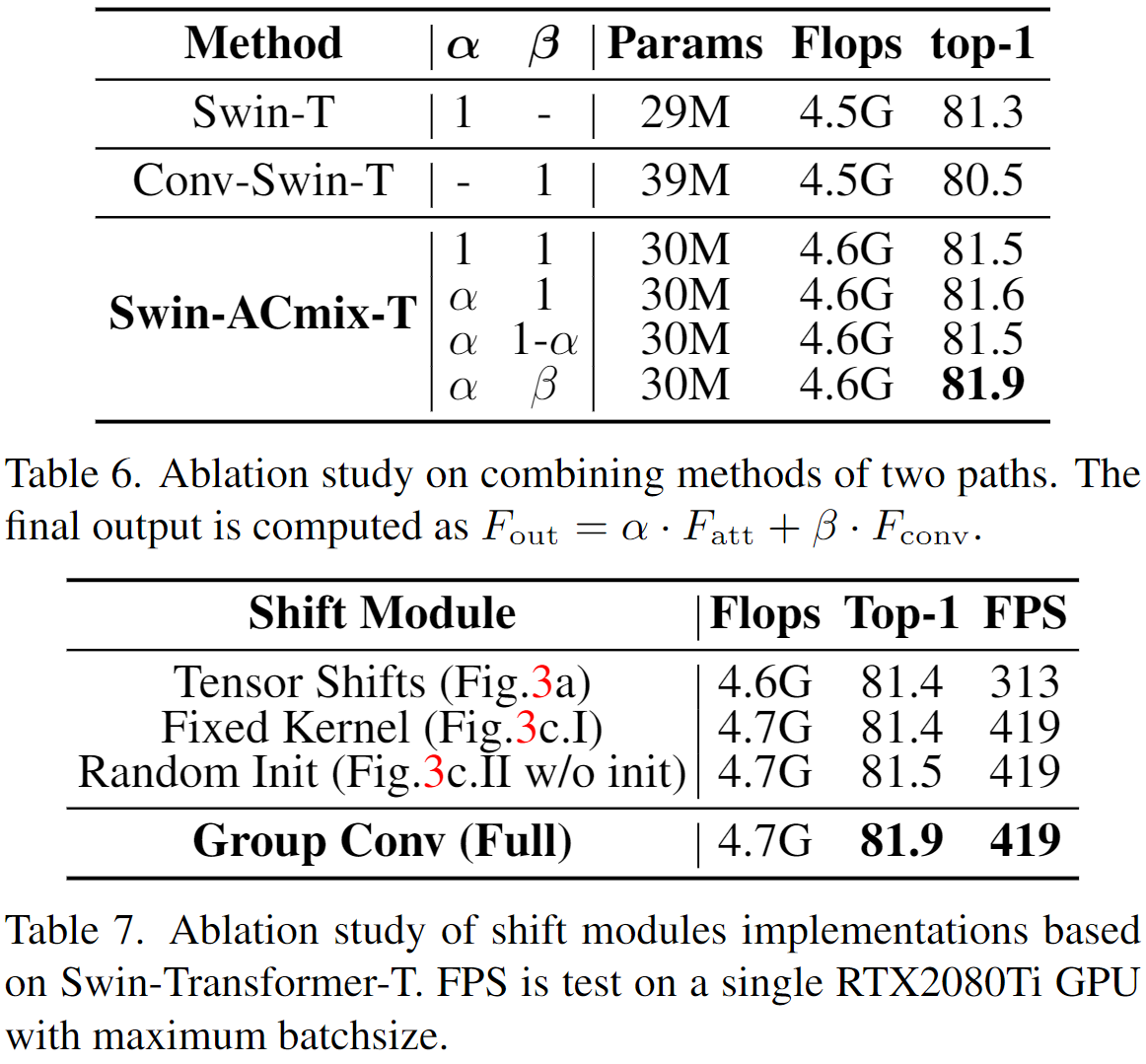
具体如何实现呢,虽然论文图中给出了大致的表示。图中虽然标注了符号,但是却并不够清晰。
为了更加清晰地理解这个过程,我们可以分析下作者提供的计算量的统计。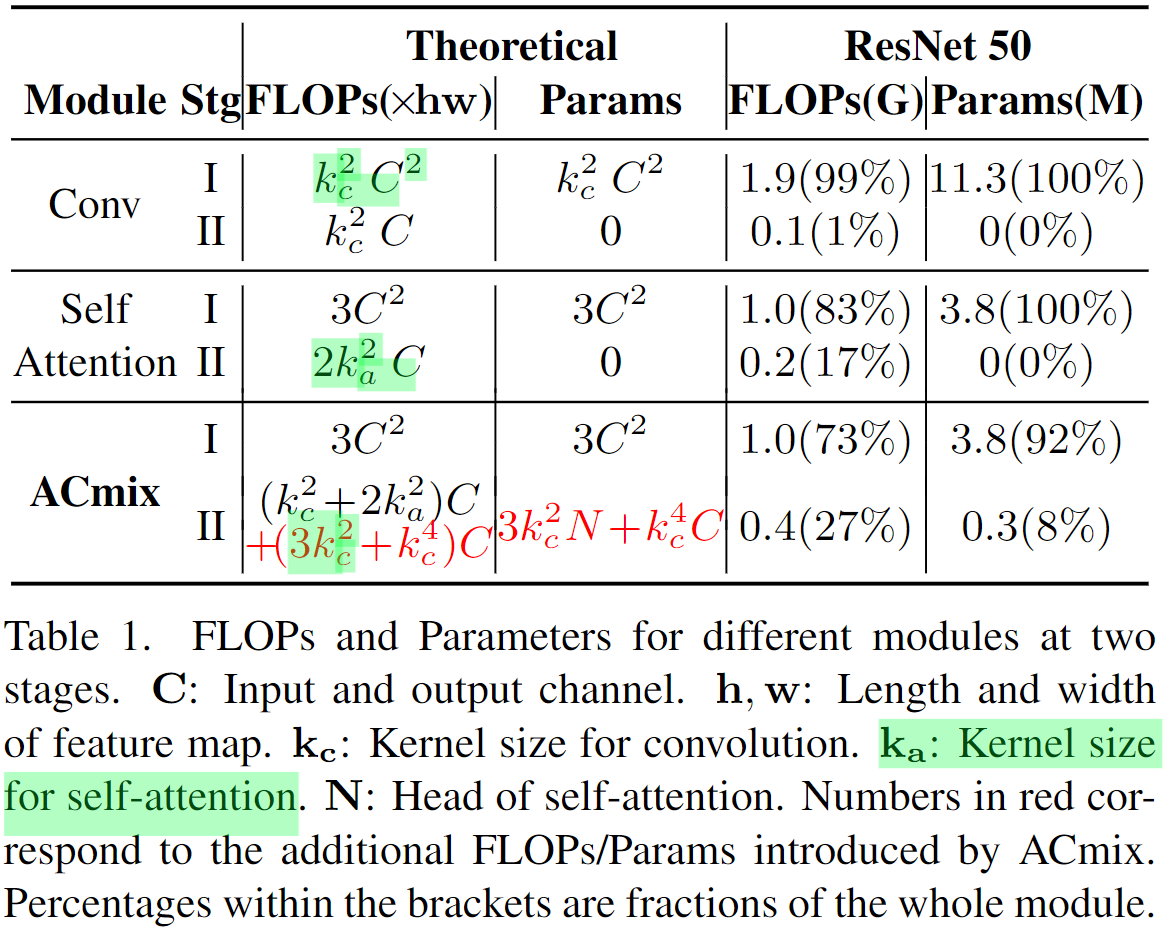
这里对比了卷积、自注意力机制,以及本文整合二者得到的ACmix结构的两阶段计算形式下的计算量和参数量。
卷积操作
对于卷积而言,其可以拆分为变换和偏移聚合两个阶段: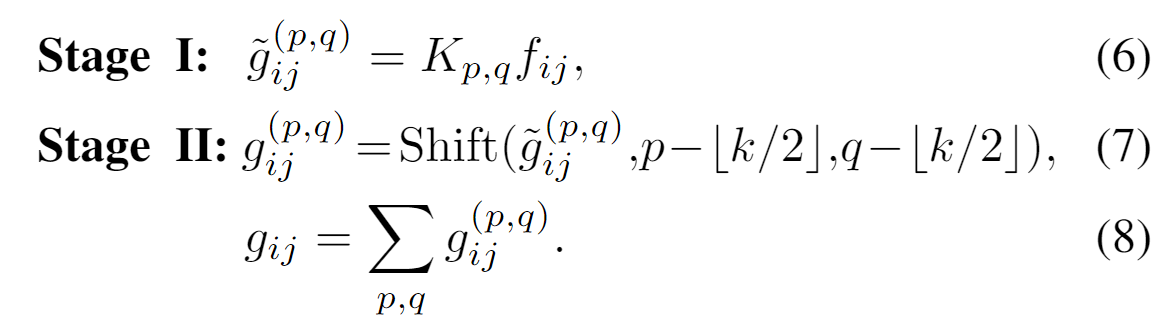
这里又涉及到了空间偏移操作(Pytorch中Spatial-Shift-Operation的5种实现策略)。其搭配独立的点卷积(要是共享的话那就不是完全等价了)和加和操作可以实现对于标准卷积的等效替换。从表格中可以看到,这里的参数量包含了 组
组 个参数,即标准的
个参数,即标准的 卷积。所以是等价变换。
卷积。所以是等价变换。
在第二阶段,卷积只有加和操作,其计算量(这里只考虑了加法计算,不同于第一阶段的FLOPs,只考虑了乘法或者是加法计算,而非整体量) 。此时没有中间参数,所以参数量为0。
。此时没有中间参数,所以参数量为0。
自注意力操作
对于自注意力操作而言,遵循卷积的拆分思路,这里可以拆分为变换和自适应动态加权聚合两个阶段: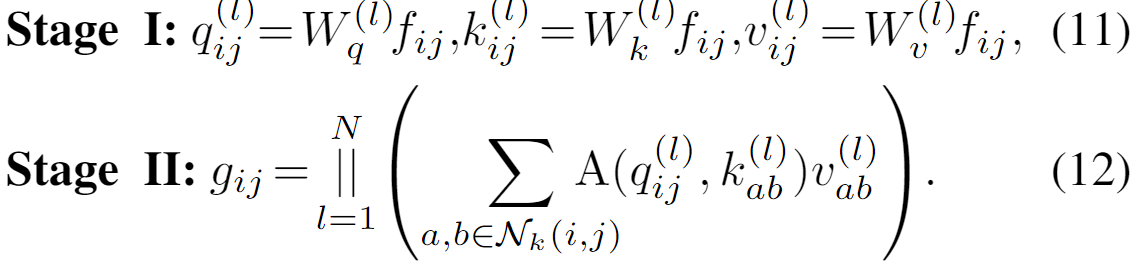
第一个阶段就是对qkv计算过程。就是3个单纯的1x1卷积。
第二个阶段包含了attention矩阵的计算以及拼接不同分组(头)的操作。此阶段的计算只考虑窗口 范围内的元素。所以计算量中序列长度也是固定的为
范围内的元素。所以计算量中序列长度也是固定的为 。所以在q和k的计算中,计算量为
。所以在q和k的计算中,计算量为 ,而在qk和v的计算中,计算量为
,而在qk和v的计算中,计算量为 。所以整体为2倍。而且此时没有额外的需要学习的参数。所以参数量为0。
。所以整体为2倍。而且此时没有额外的需要学习的参数。所以参数量为0。
ACmix操作
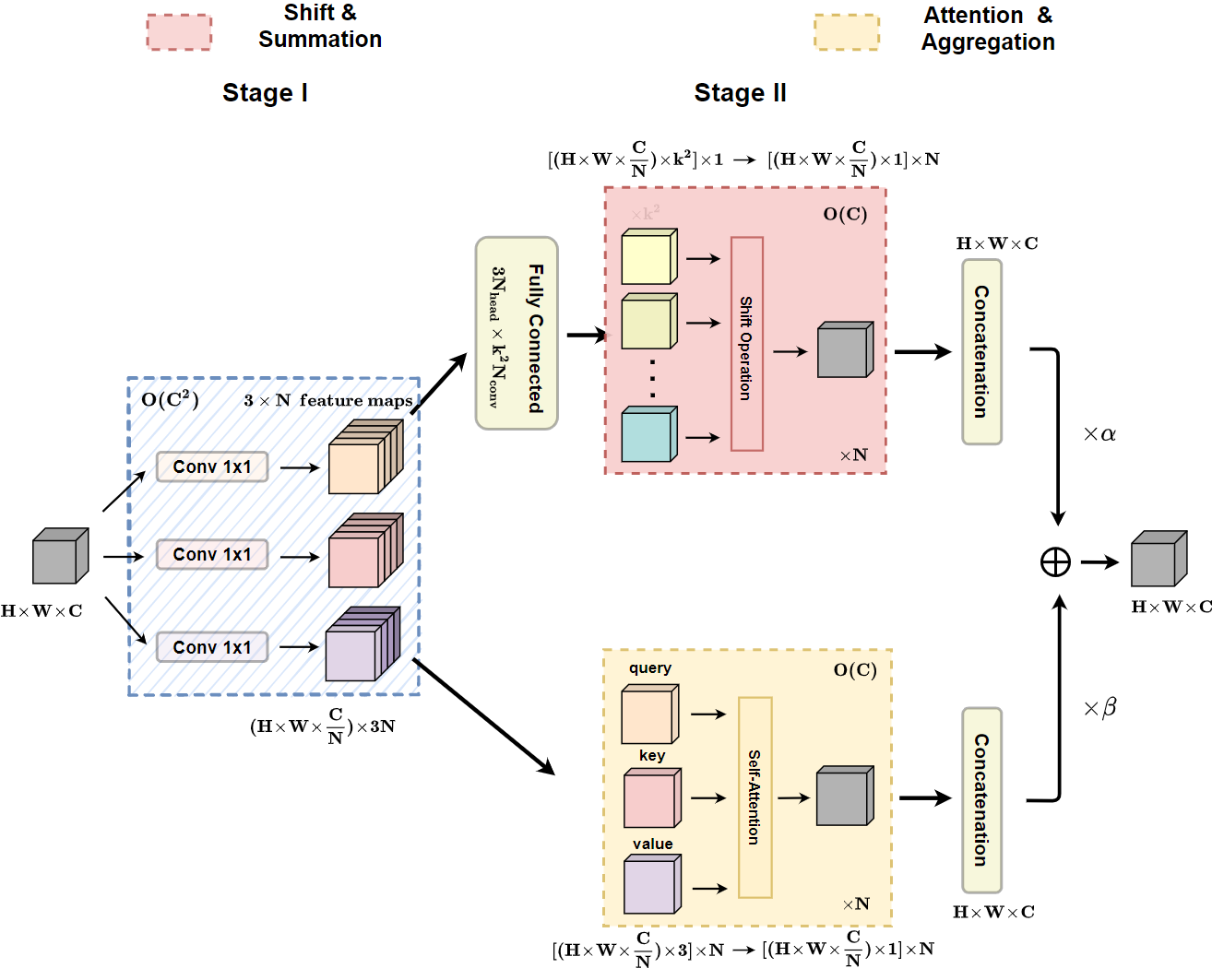
ACmix操作整合了卷积和自注意力操作。对他们使用了共享的特征变换结构。
第一阶段中,共享的特征变换结构,将通道C扩展3倍,并将其折叠为N组。这里的N会被用于表示self-attention中的“头”的概念。这里的计算量和参数量也就是3各独立的1x1卷积操作对应的量。
第二阶段中,需要考虑两部分结构: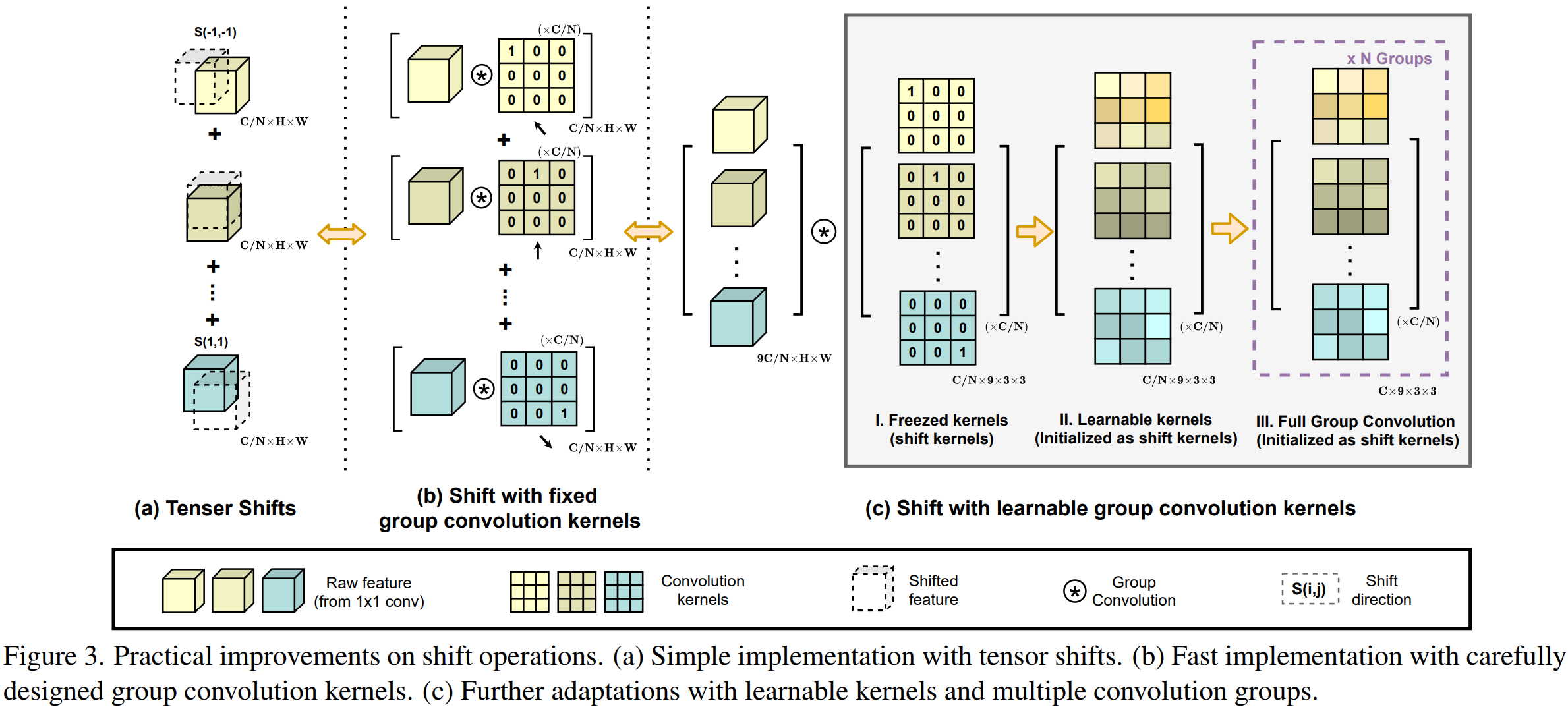
- 卷积部分:
- 先通过全连接层将通道数进行扩张,从而变换对应于不同偏移方向的多个点的特征。由于目的是为了等效
 大小的卷积核。所以这里需要扩张为
大小的卷积核。所以这里需要扩张为 。从图中来看,并不能明确这里具体使用的何种操作。但是按照前表中对应这一部分的计算量(
。从图中来看,并不能明确这里具体使用的何种操作。但是按照前表中对应这一部分的计算量( )来看,这里的操作应该就是使用
)来看,这里的操作应该就是使用 %22%20aria-hidden%3D%22true%22%3E%0A%20%3Cuse%20xlink%3Ahref%3D%22%23E1-MJMATHI-4E%22%20x%3D%220%22%20y%3D%220%22%3E%3C%2Fuse%3E%0A%3C%2Fg%3E%0A%3C%2Fsvg%3E#card=math&code=N&id=WGXY4)组的分组卷积(N间不共享,C/N内共享),将
%22%20aria-hidden%3D%22true%22%3E%0A%20%3Cuse%20xlink%3Ahref%3D%22%23E1-MJMATHI-4E%22%20x%3D%220%22%20y%3D%220%22%3E%3C%2Fuse%3E%0A%3C%2Fg%3E%0A%3C%2Fsvg%3E#card=math&code=N&id=WGXY4)组的分组卷积(N间不共享,C/N内共享),将 扩展到
扩展到 。
。 - 之后的空间偏移和聚合操作从而获得卷积分支的结果。
- 按照表格中仍然保留了原始空间聚合操作的计算量(
 ),这反映了
),这反映了 个偏移特征组(
个偏移特征组( )是被并行处理,并且最后会被直接加到一起。
)是被并行处理,并且最后会被直接加到一起。 - 但是考虑到直接空间偏移的处理会破坏数据的局部性,并且很难实现向量化处理。这可能会极大地损害模块在推理时的实际效率。所以作者准备使用卷积类似的等效变换。如上图所示,作者设计了三种形式。最终应用了第三种可学习的分组卷积结构来实现替换。这里同时引入了一个
 大小的卷积操作。按照图中的形式这里使用的是分组卷积,但是却并没有说明具体是什么操作。表中给出的对应计算量为
大小的卷积操作。按照图中的形式这里使用的是分组卷积,但是却并没有说明具体是什么操作。表中给出的对应计算量为 。
。 - 考虑到输入为
 %22%20aria-hidden%3D%22true%22%3E%0A%20%3Cuse%20xlink%3Ahref%3D%22%23E1-MJMATHI-4E%22%20x%3D%220%22%20y%3D%220%22%3E%3C%2Fuse%3E%0A%20%3Cuse%20xlink%3Ahref%3D%22%23E1-MJMAIN-D7%22%20x%3D%221110%22%20y%3D%220%22%3E%3C%2Fuse%3E%0A%3Cg%20transform%3D%22translate(2111%2C0)%22%3E%0A%20%3Cuse%20xlink%3Ahref%3D%22%23E1-MJMATHI-6B%22%20x%3D%220%22%20y%3D%220%22%3E%3C%2Fuse%3E%0A%20%3Cuse%20transform%3D%22scale(0.707)%22%20xlink%3Ahref%3D%22%23E1-MJMAIN-32%22%20x%3D%22737%22%20y%3D%22488%22%3E%3C%2Fuse%3E%0A%20%3Cuse%20transform%3D%22scale(0.707)%22%20xlink%3Ahref%3D%22%23E1-MJMATHI-63%22%20x%3D%22737%22%20y%3D%22-211%22%3E%3C%2Fuse%3E%0A%20%3Cuse%20xlink%3Ahref%3D%22%23E1-MJMAIN-D7%22%20x%3D%221197%22%20y%3D%220%22%3E%3C%2Fuse%3E%0A%3Cg%20transform%3D%22translate(2198%2C0)%22%3E%0A%20%3Cuse%20xlink%3Ahref%3D%22%23E1-MJMATHI-43%22%20x%3D%220%22%20y%3D%220%22%3E%3C%2Fuse%3E%0A%20%3Cuse%20xlink%3Ahref%3D%22%23E1-MJMAIN-2F%22%20x%3D%22760%22%20y%3D%220%22%3E%3C%2Fuse%3E%0A%20%3Cuse%20xlink%3Ahref%3D%22%23E1-MJMATHI-4E%22%20x%3D%221261%22%20y%3D%220%22%3E%3C%2Fuse%3E%0A%20%3Cuse%20xlink%3Ahref%3D%22%23E1-MJMAIN-D7%22%20x%3D%222371%22%20y%3D%220%22%3E%3C%2Fuse%3E%0A%20%3Cuse%20xlink%3Ahref%3D%22%23E1-MJMATHI-48%22%20x%3D%223372%22%20y%3D%220%22%3E%3C%2Fuse%3E%0A%20%3Cuse%20xlink%3Ahref%3D%22%23E1-MJMAIN-D7%22%20x%3D%224483%22%20y%3D%220%22%3E%3C%2Fuse%3E%0A%20%3Cuse%20xlink%3Ahref%3D%22%23E1-MJMATHI-57%22%20x%3D%225483%22%20y%3D%220%22%3E%3C%2Fuse%3E%0A%3Cg%20transform%3D%22translate(-56%2C-765)%22%3E%0A%20%3Cuse%20xlink%3Ahref%3D%22%23E1-MJSZ4-E152%22%20x%3D%2223%22%20y%3D%220%22%3E%3C%2Fuse%3E%0A%3Cg%20transform%3D%22translate(536.7407076719577%2C0)%20scale(5.55165343915344%2C1)%22%3E%0A%20%3Cuse%20xlink%3Ahref%3D%22%23E1-MJSZ4-E154%22%3E%3C%2Fuse%3E%0A%3C%2Fg%3E%0A%3Cg%20transform%3D%22translate(2815%2C0)%22%3E%0A%20%3Cuse%20xlink%3Ahref%3D%22%23E1-MJSZ4-E151%22%3E%3C%2Fuse%3E%0A%20%3Cuse%20xlink%3Ahref%3D%22%23E1-MJSZ4-E150%22%20x%3D%22450%22%20y%3D%220%22%3E%3C%2Fuse%3E%0A%3C%2Fg%3E%0A%3Cg%20transform%3D%22translate(3769.4351521164026%2C0)%20scale(5.55165343915344%2C1)%22%3E%0A%20%3Cuse%20xlink%3Ahref%3D%22%23E1-MJSZ4-E154%22%3E%3C%2Fuse%3E%0A%3C%2Fg%3E%0A%20%3Cuse%20xlink%3Ahref%3D%22%23E1-MJSZ4-E153%22%20x%3D%226057%22%20y%3D%220%22%3E%3C%2Fuse%3E%0A%3C%2Fg%3E%0A%3Cg%20transform%3D%22translate(469%2C-1638)%22%3E%0A%20%3Cuse%20transform%3D%22scale(0.707)%22%20xlink%3Ahref%3D%22%23E1-MJMATHI-61%22%20x%3D%220%22%20y%3D%220%22%3E%3C%2Fuse%3E%0A%20%3Cuse%20transform%3D%22scale(0.707)%22%20xlink%3Ahref%3D%22%23E1-MJMATHI-73%22%20x%3D%22883%22%20y%3D%220%22%3E%3C%2Fuse%3E%0A%20%3Cuse%20transform%3D%22scale(0.707)%22%20xlink%3Ahref%3D%22%23E1-MJMATHI-69%22%20x%3D%221352%22%20y%3D%220%22%3E%3C%2Fuse%3E%0A%20%3Cuse%20transform%3D%22scale(0.707)%22%20xlink%3Ahref%3D%22%23E1-MJMATHI-6E%22%20x%3D%221698%22%20y%3D%220%22%3E%3C%2Fuse%3E%0A%20%3Cuse%20transform%3D%22scale(0.707)%22%20xlink%3Ahref%3D%22%23E1-MJMATHI-67%22%20x%3D%222298%22%20y%3D%220%22%3E%3C%2Fuse%3E%0A%20%3Cuse%20transform%3D%22scale(0.707)%22%20xlink%3Ahref%3D%22%23E1-MJMATHI-6C%22%20x%3D%222779%22%20y%3D%220%22%3E%3C%2Fuse%3E%0A%20%3Cuse%20transform%3D%22scale(0.707)%22%20xlink%3Ahref%3D%22%23E1-MJMATHI-65%22%20x%3D%223077%22%20y%3D%220%22%3E%3C%2Fuse%3E%0A%20%3Cuse%20transform%3D%22scale(0.707)%22%20xlink%3Ahref%3D%22%23E1-MJMATHI-64%22%20x%3D%223897%22%20y%3D%220%22%3E%3C%2Fuse%3E%0A%20%3Cuse%20transform%3D%22scale(0.707)%22%20xlink%3Ahref%3D%22%23E1-MJMATHI-69%22%20x%3D%224421%22%20y%3D%220%22%3E%3C%2Fuse%3E%0A%20%3Cuse%20transform%3D%22scale(0.707)%22%20xlink%3Ahref%3D%22%23E1-MJMATHI-72%22%20x%3D%224766%22%20y%3D%220%22%3E%3C%2Fuse%3E%0A%20%3Cuse%20transform%3D%22scale(0.707)%22%20xlink%3Ahref%3D%22%23E1-MJMATHI-65%22%20x%3D%225218%22%20y%3D%220%22%3E%3C%2Fuse%3E%0A%20%3Cuse%20transform%3D%22scale(0.707)%22%20xlink%3Ahref%3D%22%23E1-MJMATHI-63%22%20x%3D%225684%22%20y%3D%220%22%3E%3C%2Fuse%3E%0A%20%3Cuse%20transform%3D%22scale(0.707)%22%20xlink%3Ahref%3D%22%23E1-MJMATHI-74%22%20x%3D%226118%22%20y%3D%220%22%3E%3C%2Fuse%3E%0A%20%3Cuse%20transform%3D%22scale(0.707)%22%20xlink%3Ahref%3D%22%23E1-MJMATHI-69%22%20x%3D%226479%22%20y%3D%220%22%3E%3C%2Fuse%3E%0A%20%3Cuse%20transform%3D%22scale(0.707)%22%20xlink%3Ahref%3D%22%23E1-MJMATHI-6F%22%20x%3D%226825%22%20y%3D%220%22%3E%3C%2Fuse%3E%0A%20%3Cuse%20transform%3D%22scale(0.707)%22%20xlink%3Ahref%3D%22%23E1-MJMATHI-6E%22%20x%3D%227310%22%20y%3D%220%22%3E%3C%2Fuse%3E%0A%3C%2Fg%3E%0A%3C%2Fg%3E%0A%3Cg%20transform%3D%22translate(12%2C1138)%22%3E%0A%20%3Cuse%20xlink%3Ahref%3D%22%23E1-MJSZ4-E150%22%20x%3D%2223%22%20y%3D%220%22%3E%3C%2Fuse%3E%0A%3Cg%20transform%3D%22translate(561.6030150410874%2C0)%20scale(8.16873842537762%2C1)%22%3E%0A%20%3Cuse%20xlink%3Ahref%3D%22%23E1-MJSZ4-E154%22%3E%3C%2Fuse%3E%0A%3C%2Fg%3E%0A%3Cg%20transform%3D%22translate(3914%2C0)%22%3E%0A%20%3Cuse%20xlink%3Ahref%3D%22%23E1-MJSZ4-E153%22%3E%3C%2Fuse%3E%0A%20%3Cuse%20xlink%3Ahref%3D%22%23E1-MJSZ4-E152%22%20x%3D%22450%22%20y%3D%220%22%3E%3C%2Fuse%3E%0A%3C%2Fg%3E%0A%3Cg%20transform%3D%22translate(4893.473153699688%2C0)%20scale(8.16873842537762%2C1)%22%3E%0A%20%3Cuse%20xlink%3Ahref%3D%22%23E1-MJSZ4-E154%22%3E%3C%2Fuse%3E%0A%3C%2Fg%3E%0A%20%3Cuse%20xlink%3Ahref%3D%22%23E1-MJSZ4-E151%22%20x%3D%228256%22%20y%3D%220%22%3E%3C%2Fuse%3E%0A%3C%2Fg%3E%0A%3Cg%20transform%3D%22translate(158%2C1729)%22%3E%0A%20%3Cuse%20transform%3D%22scale(0.707)%22%20xlink%3Ahref%3D%22%23E1-MJMATHI-61%22%20x%3D%220%22%20y%3D%220%22%3E%3C%2Fuse%3E%0A%20%3Cuse%20transform%3D%22scale(0.707)%22%20xlink%3Ahref%3D%22%23E1-MJMATHI-73%22%20x%3D%22883%22%20y%3D%220%22%3E%3C%2Fuse%3E%0A%20%3Cuse%20transform%3D%22scale(0.707)%22%20xlink%3Ahref%3D%22%23E1-MJMATHI-69%22%20x%3D%221352%22%20y%3D%220%22%3E%3C%2Fuse%3E%0A%20%3Cuse%20transform%3D%22scale(0.707)%22%20xlink%3Ahref%3D%22%23E1-MJMATHI-6E%22%20x%3D%221698%22%20y%3D%220%22%3E%3C%2Fuse%3E%0A%20%3Cuse%20transform%3D%22scale(0.707)%22%20xlink%3Ahref%3D%22%23E1-MJMATHI-67%22%20x%3D%222298%22%20y%3D%220%22%3E%3C%2Fuse%3E%0A%20%3Cuse%20transform%3D%22scale(0.707)%22%20xlink%3Ahref%3D%22%23E1-MJMATHI-6C%22%20x%3D%222779%22%20y%3D%220%22%3E%3C%2Fuse%3E%0A%20%3Cuse%20transform%3D%22scale(0.707)%22%20xlink%3Ahref%3D%22%23E1-MJMATHI-65%22%20x%3D%223077%22%20y%3D%220%22%3E%3C%2Fuse%3E%0A%20%3Cuse%20transform%3D%22scale(0.707)%22%20xlink%3Ahref%3D%22%23E1-MJMATHI-63%22%20x%3D%223897%22%20y%3D%220%22%3E%3C%2Fuse%3E%0A%20%3Cuse%20transform%3D%22scale(0.707)%22%20xlink%3Ahref%3D%22%23E1-MJMATHI-6F%22%20x%3D%224331%22%20y%3D%220%22%3E%3C%2Fuse%3E%0A%20%3Cuse%20transform%3D%22scale(0.707)%22%20xlink%3Ahref%3D%22%23E1-MJMATHI-6E%22%20x%3D%224816%22%20y%3D%220%22%3E%3C%2Fuse%3E%0A%20%3Cuse%20transform%3D%22scale(0.707)%22%20xlink%3Ahref%3D%22%23E1-MJMATHI-76%22%20x%3D%225417%22%20y%3D%220%22%3E%3C%2Fuse%3E%0A%20%3Cuse%20transform%3D%22scale(0.707)%22%20xlink%3Ahref%3D%22%23E1-MJMATHI-6F%22%20x%3D%225902%22%20y%3D%220%22%3E%3C%2Fuse%3E%0A%20%3Cuse%20transform%3D%22scale(0.707)%22%20xlink%3Ahref%3D%22%23E1-MJMATHI-6C%22%20x%3D%226388%22%20y%3D%220%22%3E%3C%2Fuse%3E%0A%20%3Cuse%20transform%3D%22scale(0.707)%22%20xlink%3Ahref%3D%22%23E1-MJMATHI-75%22%20x%3D%226686%22%20y%3D%220%22%3E%3C%2Fuse%3E%0A%20%3Cuse%20transform%3D%22scale(0.707)%22%20xlink%3Ahref%3D%22%23E1-MJMATHI-74%22%20x%3D%227259%22%20y%3D%220%22%3E%3C%2Fuse%3E%0A%20%3Cuse%20transform%3D%22scale(0.707)%22%20xlink%3Ahref%3D%22%23E1-MJMATHI-69%22%20x%3D%227620%22%20y%3D%220%22%3E%3C%2Fuse%3E%0A%20%3Cuse%20transform%3D%22scale(0.707)%22%20xlink%3Ahref%3D%22%23E1-MJMATHI-6F%22%20x%3D%227966%22%20y%3D%220%22%3E%3C%2Fuse%3E%0A%20%3Cuse%20transform%3D%22scale(0.707)%22%20xlink%3Ahref%3D%22%23E1-MJMATHI-6E%22%20x%3D%228451%22%20y%3D%220%22%3E%3C%2Fuse%3E%0A%20%3Cuse%20transform%3D%22scale(0.707)%22%20xlink%3Ahref%3D%22%23E1-MJMATHI-67%22%20x%3D%229405%22%20y%3D%220%22%3E%3C%2Fuse%3E%0A%20%3Cuse%20transform%3D%22scale(0.707)%22%20xlink%3Ahref%3D%22%23E1-MJMATHI-72%22%20x%3D%229886%22%20y%3D%220%22%3E%3C%2Fuse%3E%0A%20%3Cuse%20transform%3D%22scale(0.707)%22%20xlink%3Ahref%3D%22%23E1-MJMATHI-6F%22%20x%3D%2210337%22%20y%3D%220%22%3E%3C%2Fuse%3E%0A%20%3Cuse%20transform%3D%22scale(0.707)%22%20xlink%3Ahref%3D%22%23E1-MJMATHI-75%22%20x%3D%2210823%22%20y%3D%220%22%3E%3C%2Fuse%3E%0A%20%3Cuse%20transform%3D%22scale(0.707)%22%20xlink%3Ahref%3D%22%23E1-MJMATHI-70%22%20x%3D%2211395%22%20y%3D%220%22%3E%3C%2Fuse%3E%0A%3C%2Fg%3E%0A%3C%2Fg%3E%0A%3C%2Fg%3E%0A%3C%2Fsvg%3E#card=math&code=N%20%5Ctimes%20%5Coverbrace%7B%0Akc%5E2%20%5Ctimes%20%0A%5Cunderbrace%7B%0AC%2FN%20%5Ctimes%20H%20%5Ctimes%20W%0A%7D%7Ba%20%5C%20single%20%5C%20direction%7D%0A%7D%5E%7Ba%20%5C%20single%20%5C%20convolution%20%5C%20group%7D&id=X5wRI),输出为
%22%20aria-hidden%3D%22true%22%3E%0A%20%3Cuse%20xlink%3Ahref%3D%22%23E1-MJMATHI-4E%22%20x%3D%220%22%20y%3D%220%22%3E%3C%2Fuse%3E%0A%20%3Cuse%20xlink%3Ahref%3D%22%23E1-MJMAIN-D7%22%20x%3D%221110%22%20y%3D%220%22%3E%3C%2Fuse%3E%0A%3Cg%20transform%3D%22translate(2111%2C0)%22%3E%0A%20%3Cuse%20xlink%3Ahref%3D%22%23E1-MJMATHI-6B%22%20x%3D%220%22%20y%3D%220%22%3E%3C%2Fuse%3E%0A%20%3Cuse%20transform%3D%22scale(0.707)%22%20xlink%3Ahref%3D%22%23E1-MJMAIN-32%22%20x%3D%22737%22%20y%3D%22488%22%3E%3C%2Fuse%3E%0A%20%3Cuse%20transform%3D%22scale(0.707)%22%20xlink%3Ahref%3D%22%23E1-MJMATHI-63%22%20x%3D%22737%22%20y%3D%22-211%22%3E%3C%2Fuse%3E%0A%20%3Cuse%20xlink%3Ahref%3D%22%23E1-MJMAIN-D7%22%20x%3D%221197%22%20y%3D%220%22%3E%3C%2Fuse%3E%0A%3Cg%20transform%3D%22translate(2198%2C0)%22%3E%0A%20%3Cuse%20xlink%3Ahref%3D%22%23E1-MJMATHI-43%22%20x%3D%220%22%20y%3D%220%22%3E%3C%2Fuse%3E%0A%20%3Cuse%20xlink%3Ahref%3D%22%23E1-MJMAIN-2F%22%20x%3D%22760%22%20y%3D%220%22%3E%3C%2Fuse%3E%0A%20%3Cuse%20xlink%3Ahref%3D%22%23E1-MJMATHI-4E%22%20x%3D%221261%22%20y%3D%220%22%3E%3C%2Fuse%3E%0A%20%3Cuse%20xlink%3Ahref%3D%22%23E1-MJMAIN-D7%22%20x%3D%222371%22%20y%3D%220%22%3E%3C%2Fuse%3E%0A%20%3Cuse%20xlink%3Ahref%3D%22%23E1-MJMATHI-48%22%20x%3D%223372%22%20y%3D%220%22%3E%3C%2Fuse%3E%0A%20%3Cuse%20xlink%3Ahref%3D%22%23E1-MJMAIN-D7%22%20x%3D%224483%22%20y%3D%220%22%3E%3C%2Fuse%3E%0A%20%3Cuse%20xlink%3Ahref%3D%22%23E1-MJMATHI-57%22%20x%3D%225483%22%20y%3D%220%22%3E%3C%2Fuse%3E%0A%3Cg%20transform%3D%22translate(-56%2C-765)%22%3E%0A%20%3Cuse%20xlink%3Ahref%3D%22%23E1-MJSZ4-E152%22%20x%3D%2223%22%20y%3D%220%22%3E%3C%2Fuse%3E%0A%3Cg%20transform%3D%22translate(536.7407076719577%2C0)%20scale(5.55165343915344%2C1)%22%3E%0A%20%3Cuse%20xlink%3Ahref%3D%22%23E1-MJSZ4-E154%22%3E%3C%2Fuse%3E%0A%3C%2Fg%3E%0A%3Cg%20transform%3D%22translate(2815%2C0)%22%3E%0A%20%3Cuse%20xlink%3Ahref%3D%22%23E1-MJSZ4-E151%22%3E%3C%2Fuse%3E%0A%20%3Cuse%20xlink%3Ahref%3D%22%23E1-MJSZ4-E150%22%20x%3D%22450%22%20y%3D%220%22%3E%3C%2Fuse%3E%0A%3C%2Fg%3E%0A%3Cg%20transform%3D%22translate(3769.4351521164026%2C0)%20scale(5.55165343915344%2C1)%22%3E%0A%20%3Cuse%20xlink%3Ahref%3D%22%23E1-MJSZ4-E154%22%3E%3C%2Fuse%3E%0A%3C%2Fg%3E%0A%20%3Cuse%20xlink%3Ahref%3D%22%23E1-MJSZ4-E153%22%20x%3D%226057%22%20y%3D%220%22%3E%3C%2Fuse%3E%0A%3C%2Fg%3E%0A%3Cg%20transform%3D%22translate(469%2C-1638)%22%3E%0A%20%3Cuse%20transform%3D%22scale(0.707)%22%20xlink%3Ahref%3D%22%23E1-MJMATHI-61%22%20x%3D%220%22%20y%3D%220%22%3E%3C%2Fuse%3E%0A%20%3Cuse%20transform%3D%22scale(0.707)%22%20xlink%3Ahref%3D%22%23E1-MJMATHI-73%22%20x%3D%22883%22%20y%3D%220%22%3E%3C%2Fuse%3E%0A%20%3Cuse%20transform%3D%22scale(0.707)%22%20xlink%3Ahref%3D%22%23E1-MJMATHI-69%22%20x%3D%221352%22%20y%3D%220%22%3E%3C%2Fuse%3E%0A%20%3Cuse%20transform%3D%22scale(0.707)%22%20xlink%3Ahref%3D%22%23E1-MJMATHI-6E%22%20x%3D%221698%22%20y%3D%220%22%3E%3C%2Fuse%3E%0A%20%3Cuse%20transform%3D%22scale(0.707)%22%20xlink%3Ahref%3D%22%23E1-MJMATHI-67%22%20x%3D%222298%22%20y%3D%220%22%3E%3C%2Fuse%3E%0A%20%3Cuse%20transform%3D%22scale(0.707)%22%20xlink%3Ahref%3D%22%23E1-MJMATHI-6C%22%20x%3D%222779%22%20y%3D%220%22%3E%3C%2Fuse%3E%0A%20%3Cuse%20transform%3D%22scale(0.707)%22%20xlink%3Ahref%3D%22%23E1-MJMATHI-65%22%20x%3D%223077%22%20y%3D%220%22%3E%3C%2Fuse%3E%0A%20%3Cuse%20transform%3D%22scale(0.707)%22%20xlink%3Ahref%3D%22%23E1-MJMATHI-64%22%20x%3D%223897%22%20y%3D%220%22%3E%3C%2Fuse%3E%0A%20%3Cuse%20transform%3D%22scale(0.707)%22%20xlink%3Ahref%3D%22%23E1-MJMATHI-69%22%20x%3D%224421%22%20y%3D%220%22%3E%3C%2Fuse%3E%0A%20%3Cuse%20transform%3D%22scale(0.707)%22%20xlink%3Ahref%3D%22%23E1-MJMATHI-72%22%20x%3D%224766%22%20y%3D%220%22%3E%3C%2Fuse%3E%0A%20%3Cuse%20transform%3D%22scale(0.707)%22%20xlink%3Ahref%3D%22%23E1-MJMATHI-65%22%20x%3D%225218%22%20y%3D%220%22%3E%3C%2Fuse%3E%0A%20%3Cuse%20transform%3D%22scale(0.707)%22%20xlink%3Ahref%3D%22%23E1-MJMATHI-63%22%20x%3D%225684%22%20y%3D%220%22%3E%3C%2Fuse%3E%0A%20%3Cuse%20transform%3D%22scale(0.707)%22%20xlink%3Ahref%3D%22%23E1-MJMATHI-74%22%20x%3D%226118%22%20y%3D%220%22%3E%3C%2Fuse%3E%0A%20%3Cuse%20transform%3D%22scale(0.707)%22%20xlink%3Ahref%3D%22%23E1-MJMATHI-69%22%20x%3D%226479%22%20y%3D%220%22%3E%3C%2Fuse%3E%0A%20%3Cuse%20transform%3D%22scale(0.707)%22%20xlink%3Ahref%3D%22%23E1-MJMATHI-6F%22%20x%3D%226825%22%20y%3D%220%22%3E%3C%2Fuse%3E%0A%20%3Cuse%20transform%3D%22scale(0.707)%22%20xlink%3Ahref%3D%22%23E1-MJMATHI-6E%22%20x%3D%227310%22%20y%3D%220%22%3E%3C%2Fuse%3E%0A%3C%2Fg%3E%0A%3C%2Fg%3E%0A%3Cg%20transform%3D%22translate(12%2C1138)%22%3E%0A%20%3Cuse%20xlink%3Ahref%3D%22%23E1-MJSZ4-E150%22%20x%3D%2223%22%20y%3D%220%22%3E%3C%2Fuse%3E%0A%3Cg%20transform%3D%22translate(561.6030150410874%2C0)%20scale(8.16873842537762%2C1)%22%3E%0A%20%3Cuse%20xlink%3Ahref%3D%22%23E1-MJSZ4-E154%22%3E%3C%2Fuse%3E%0A%3C%2Fg%3E%0A%3Cg%20transform%3D%22translate(3914%2C0)%22%3E%0A%20%3Cuse%20xlink%3Ahref%3D%22%23E1-MJSZ4-E153%22%3E%3C%2Fuse%3E%0A%20%3Cuse%20xlink%3Ahref%3D%22%23E1-MJSZ4-E152%22%20x%3D%22450%22%20y%3D%220%22%3E%3C%2Fuse%3E%0A%3C%2Fg%3E%0A%3Cg%20transform%3D%22translate(4893.473153699688%2C0)%20scale(8.16873842537762%2C1)%22%3E%0A%20%3Cuse%20xlink%3Ahref%3D%22%23E1-MJSZ4-E154%22%3E%3C%2Fuse%3E%0A%3C%2Fg%3E%0A%20%3Cuse%20xlink%3Ahref%3D%22%23E1-MJSZ4-E151%22%20x%3D%228256%22%20y%3D%220%22%3E%3C%2Fuse%3E%0A%3C%2Fg%3E%0A%3Cg%20transform%3D%22translate(158%2C1729)%22%3E%0A%20%3Cuse%20transform%3D%22scale(0.707)%22%20xlink%3Ahref%3D%22%23E1-MJMATHI-61%22%20x%3D%220%22%20y%3D%220%22%3E%3C%2Fuse%3E%0A%20%3Cuse%20transform%3D%22scale(0.707)%22%20xlink%3Ahref%3D%22%23E1-MJMATHI-73%22%20x%3D%22883%22%20y%3D%220%22%3E%3C%2Fuse%3E%0A%20%3Cuse%20transform%3D%22scale(0.707)%22%20xlink%3Ahref%3D%22%23E1-MJMATHI-69%22%20x%3D%221352%22%20y%3D%220%22%3E%3C%2Fuse%3E%0A%20%3Cuse%20transform%3D%22scale(0.707)%22%20xlink%3Ahref%3D%22%23E1-MJMATHI-6E%22%20x%3D%221698%22%20y%3D%220%22%3E%3C%2Fuse%3E%0A%20%3Cuse%20transform%3D%22scale(0.707)%22%20xlink%3Ahref%3D%22%23E1-MJMATHI-67%22%20x%3D%222298%22%20y%3D%220%22%3E%3C%2Fuse%3E%0A%20%3Cuse%20transform%3D%22scale(0.707)%22%20xlink%3Ahref%3D%22%23E1-MJMATHI-6C%22%20x%3D%222779%22%20y%3D%220%22%3E%3C%2Fuse%3E%0A%20%3Cuse%20transform%3D%22scale(0.707)%22%20xlink%3Ahref%3D%22%23E1-MJMATHI-65%22%20x%3D%223077%22%20y%3D%220%22%3E%3C%2Fuse%3E%0A%20%3Cuse%20transform%3D%22scale(0.707)%22%20xlink%3Ahref%3D%22%23E1-MJMATHI-63%22%20x%3D%223897%22%20y%3D%220%22%3E%3C%2Fuse%3E%0A%20%3Cuse%20transform%3D%22scale(0.707)%22%20xlink%3Ahref%3D%22%23E1-MJMATHI-6F%22%20x%3D%224331%22%20y%3D%220%22%3E%3C%2Fuse%3E%0A%20%3Cuse%20transform%3D%22scale(0.707)%22%20xlink%3Ahref%3D%22%23E1-MJMATHI-6E%22%20x%3D%224816%22%20y%3D%220%22%3E%3C%2Fuse%3E%0A%20%3Cuse%20transform%3D%22scale(0.707)%22%20xlink%3Ahref%3D%22%23E1-MJMATHI-76%22%20x%3D%225417%22%20y%3D%220%22%3E%3C%2Fuse%3E%0A%20%3Cuse%20transform%3D%22scale(0.707)%22%20xlink%3Ahref%3D%22%23E1-MJMATHI-6F%22%20x%3D%225902%22%20y%3D%220%22%3E%3C%2Fuse%3E%0A%20%3Cuse%20transform%3D%22scale(0.707)%22%20xlink%3Ahref%3D%22%23E1-MJMATHI-6C%22%20x%3D%226388%22%20y%3D%220%22%3E%3C%2Fuse%3E%0A%20%3Cuse%20transform%3D%22scale(0.707)%22%20xlink%3Ahref%3D%22%23E1-MJMATHI-75%22%20x%3D%226686%22%20y%3D%220%22%3E%3C%2Fuse%3E%0A%20%3Cuse%20transform%3D%22scale(0.707)%22%20xlink%3Ahref%3D%22%23E1-MJMATHI-74%22%20x%3D%227259%22%20y%3D%220%22%3E%3C%2Fuse%3E%0A%20%3Cuse%20transform%3D%22scale(0.707)%22%20xlink%3Ahref%3D%22%23E1-MJMATHI-69%22%20x%3D%227620%22%20y%3D%220%22%3E%3C%2Fuse%3E%0A%20%3Cuse%20transform%3D%22scale(0.707)%22%20xlink%3Ahref%3D%22%23E1-MJMATHI-6F%22%20x%3D%227966%22%20y%3D%220%22%3E%3C%2Fuse%3E%0A%20%3Cuse%20transform%3D%22scale(0.707)%22%20xlink%3Ahref%3D%22%23E1-MJMATHI-6E%22%20x%3D%228451%22%20y%3D%220%22%3E%3C%2Fuse%3E%0A%20%3Cuse%20transform%3D%22scale(0.707)%22%20xlink%3Ahref%3D%22%23E1-MJMATHI-67%22%20x%3D%229405%22%20y%3D%220%22%3E%3C%2Fuse%3E%0A%20%3Cuse%20transform%3D%22scale(0.707)%22%20xlink%3Ahref%3D%22%23E1-MJMATHI-72%22%20x%3D%229886%22%20y%3D%220%22%3E%3C%2Fuse%3E%0A%20%3Cuse%20transform%3D%22scale(0.707)%22%20xlink%3Ahref%3D%22%23E1-MJMATHI-6F%22%20x%3D%2210337%22%20y%3D%220%22%3E%3C%2Fuse%3E%0A%20%3Cuse%20transform%3D%22scale(0.707)%22%20xlink%3Ahref%3D%22%23E1-MJMATHI-75%22%20x%3D%2210823%22%20y%3D%220%22%3E%3C%2Fuse%3E%0A%20%3Cuse%20transform%3D%22scale(0.707)%22%20xlink%3Ahref%3D%22%23E1-MJMATHI-70%22%20x%3D%2211395%22%20y%3D%220%22%3E%3C%2Fuse%3E%0A%3C%2Fg%3E%0A%3C%2Fg%3E%0A%3C%2Fg%3E%0A%3C%2Fsvg%3E#card=math&code=N%20%5Ctimes%20%5Coverbrace%7B%0Akc%5E2%20%5Ctimes%20%0A%5Cunderbrace%7B%0AC%2FN%20%5Ctimes%20H%20%5Ctimes%20W%0A%7D%7Ba%20%5C%20single%20%5C%20direction%7D%0A%7D%5E%7Ba%20%5C%20single%20%5C%20convolution%20%5C%20group%7D&id=X5wRI),输出为 。对于这
。对于这 组特征,每组中直接用深度分离卷积,卷积参数为
组特征,每组中直接用深度分离卷积,卷积参数为 。于是这部分的计算量为
。于是这部分的计算量为 ,也就是N间不共享,组内C/N通道之间也不共享。
,也就是N间不共享,组内C/N通道之间也不共享。
- 按照表格中仍然保留了原始空间聚合操作的计算量(
- 此时的参数量包含两部分:
 :N组
:N组 卷积。
卷积。 :N组
:N组 的深度分离卷积。
的深度分离卷积。
- 先通过全连接层将通道数进行扩张,从而变换对应于不同偏移方向的多个点的特征。由于目的是为了等效
自注意力部分:
额外阅读:清华大学提出ACmix | 这才是Self-Attention与CNN正确的融合范式,性能速度全面提升https://mp.weixin.qq.com/s/fJKF0zfDec_mGKD2hVaGOQ
- 论文:https://arxiv.org/abs/2111.14556
- 代码:
- Pytorch中Spatial-Shift-Operation的5种实现策略:https://www.yuque.com/go/doc/60967298
- NewConv:https://www.yuque.com/go/doc/2609742
 。
。

若有收获,就点个赞吧
0 人点赞
