本文所使用到的文件在这里附件.zip。
第一章:主机规划
| 主机名称(hostname) | IP 地址 | 操作系统 |
|---|---|---|
| node1 | 192.168.65.100 | CentOS 7.9 |
| node2 | 192.168.65.101 | CentOS 7.9 |
| node3 | 192.168.65.102 | CentOS 7.9 |
| lb-master | 192.168.65.103 | CentOS 7.9 |
| lb-slave | 192.168.65.104 | CentOS 7.9 |
注意:
- 需要将所有机器上的防火墙关闭。
- VIP 是 192.168.65.222 。
第二章:普通集群
2.1 概述
- 单机版的 RabbitMQ 是无法满足真实应用的要求的:
- 如果单机版的 RabbitMQ 服务器遇到内存奔溃、主板故障等情况,那该怎么办?
- 单台 RabbitMQ 服务器可以满足每秒 1000 条消息的吞吐量,但是如果应用需要 RabbitMQ 服务满足每秒 10 万条消息的吞吐量呢?
- 搭建 RabbitMQ 集群才是解决实际问题的关键所在。
2.2 搭建原理
- RabbitMQ 是基于 Erlang 编写的,Erlang 语言天生具备分布式特性(通过同步 Erlang 集群各个节点的 magic cookie 来实现的)。所以,RabbitMQ 天然支持集群,这使得 RabbitMQ 本身不需要像 ActiveMQ、Kakfa 那样通过 Zookeeper 来实现 HA 方案和保存集群的元数据。
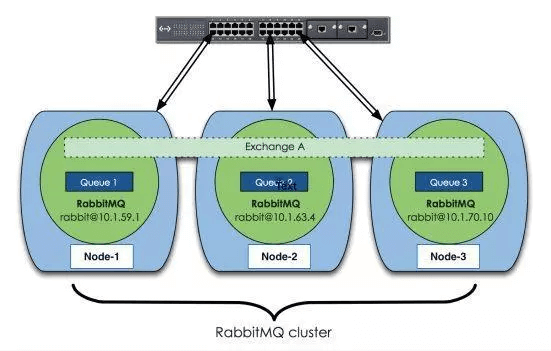
- RabbitMQ集群会始终同步四种类型的内部元数据:
- ① 队列元数据:队列名称和它的属性。
- ② 交换器元数据:交换器名称、类型和属性。
- ③ 绑定元数据:一张简单的表格展示了如何将消息路由到队列。
- ④ vhost元数据:为vhost内的队列、交换器和绑定提供命名空间和安全属性。
- 因此,当用户访问其中任何一个 RabbitMQ 节点时,通过 rabbitmqctl 查询到的 queue 、user 、exchange 、vhost 等信息都是相同的。
- RabbitMQ 为什么不同步集群中的所有 Queue ?主要原因是 RabbitMQ 的设计者是基于集群本身的性能和存储空间来考虑的,如果每个集群都拥有所有 Queue 的完全数据拷贝,那么每个节点的存储空间会变得非常大,集群的消息积压能力会变得很弱;其次是性能原因,消息的发布者需要将消息复制到集群中的每个节点,对于持久化消息来说,网络和磁盘同步复制的开销会变得非常大。
2.3 搭建步骤
2.3.1 设置主机名
- 命令:
hostnamectl set-hostname <hostname>
- 示例:
# 192.168.65.100hostnamectl set-hostname node1
# 192.168.65.101hostnamectl set-hostname node2
# 192.168.65.102hostnamectl set-hostname node3

2.3.2 主机名解析
- 为了方便后面集群节点间的直接调用,需要配置一下主机名解析,企业中推荐使用内部的 DNS 服务器。
cat >> /etc/hosts << EOF192.168.65.100 node1192.168.65.101 node2192.168.65.102 node3EOF

2.3.3 安装 Erlang
- 下载安装包(三台机器都执行):
wget --content-disposition https://packagecloud.io/rabbitmq/erlang/packages/el/7/erlang-22.3.1-1.el7.x86_64.rpm/download.rpm
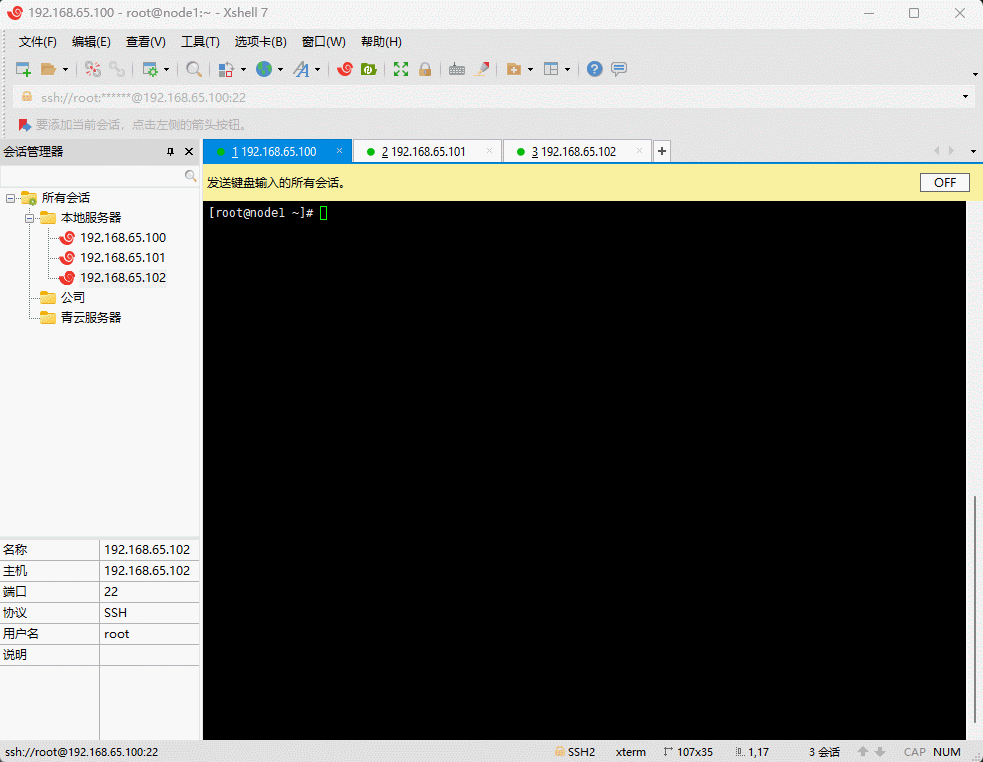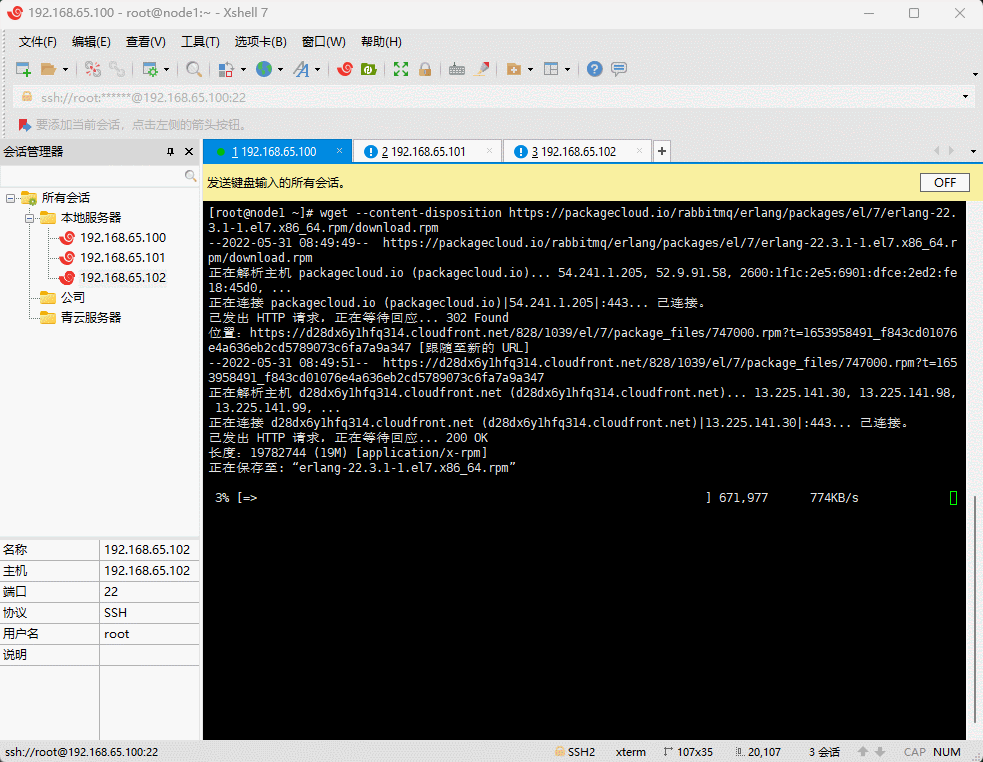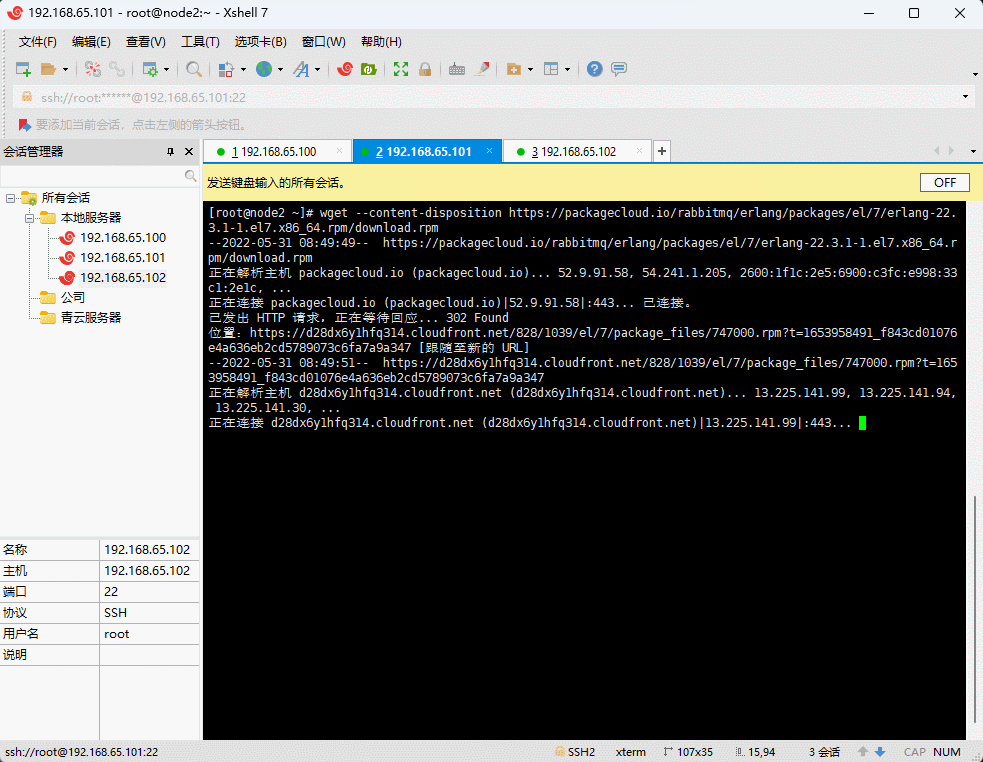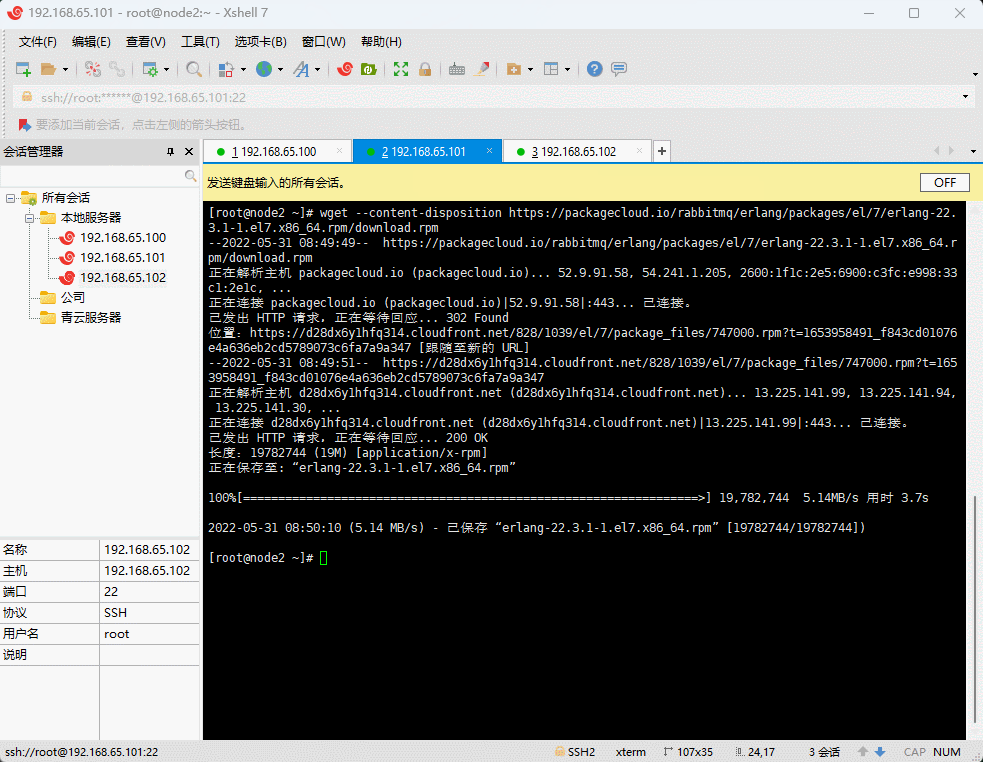
- 安装(三台机器都执行):
rpm -ivh erlang-22.3.1-1.el7.x86_64.rpm

2.3.4 安装 RabbitMQ
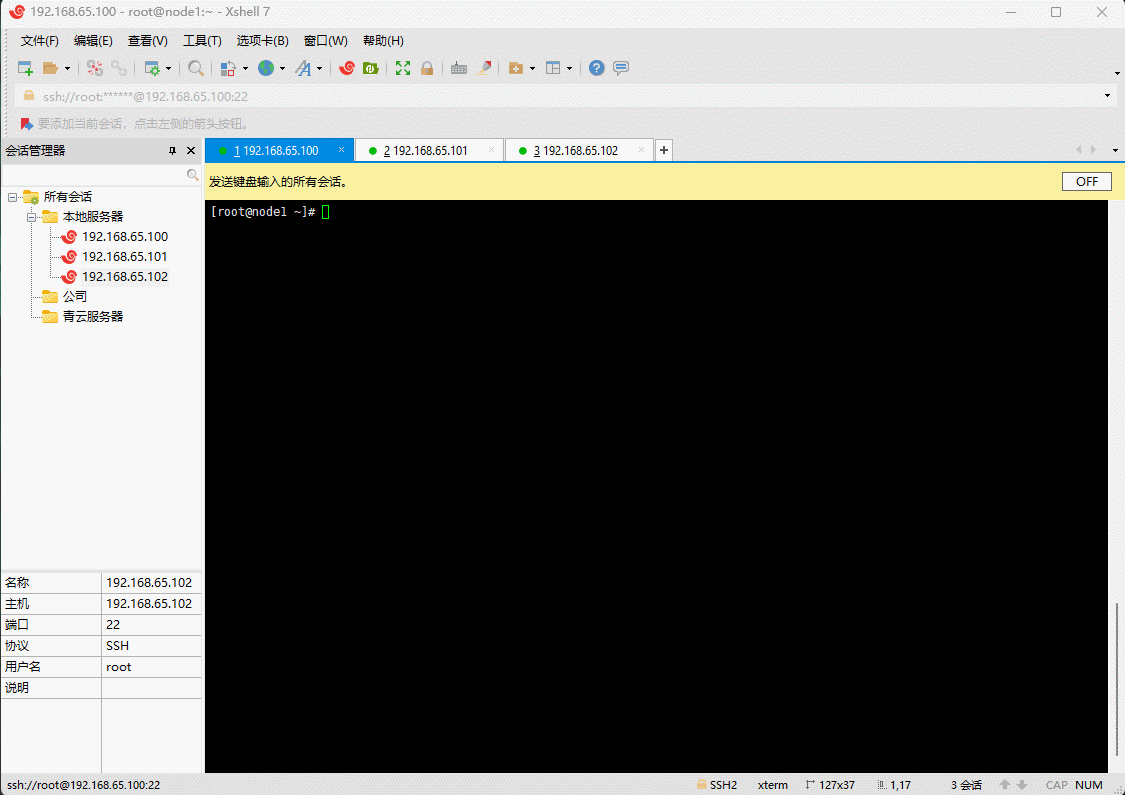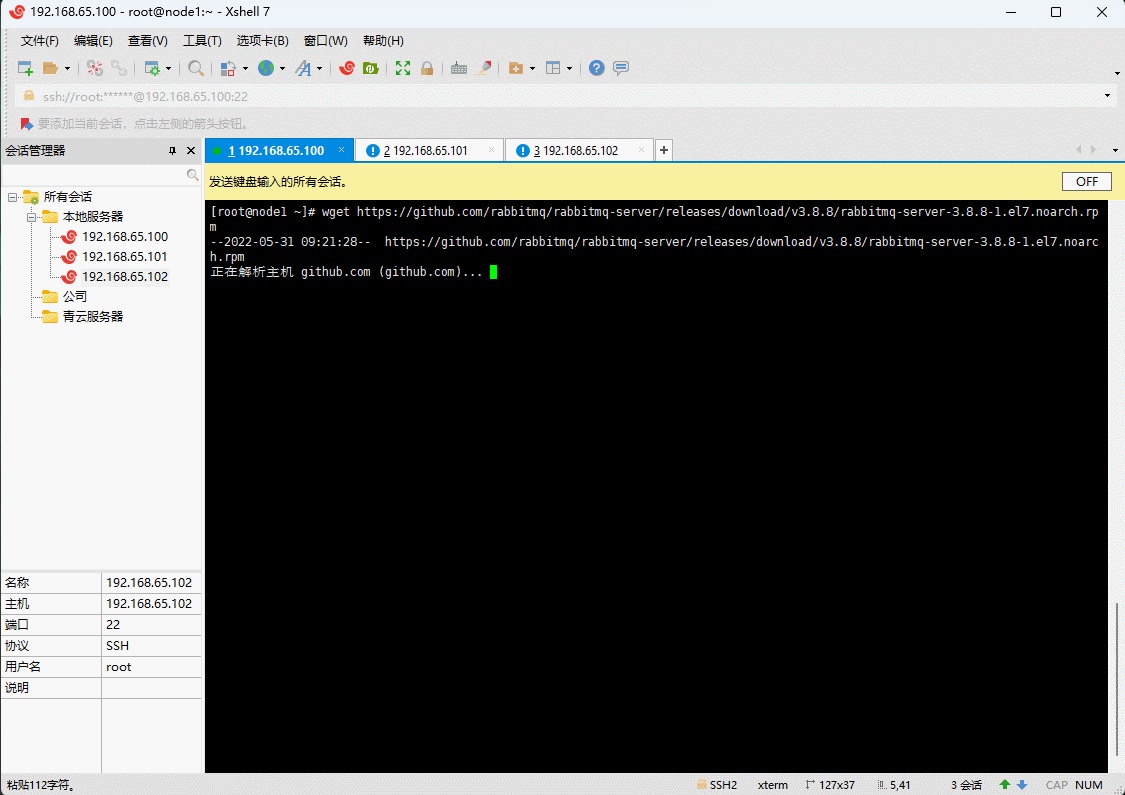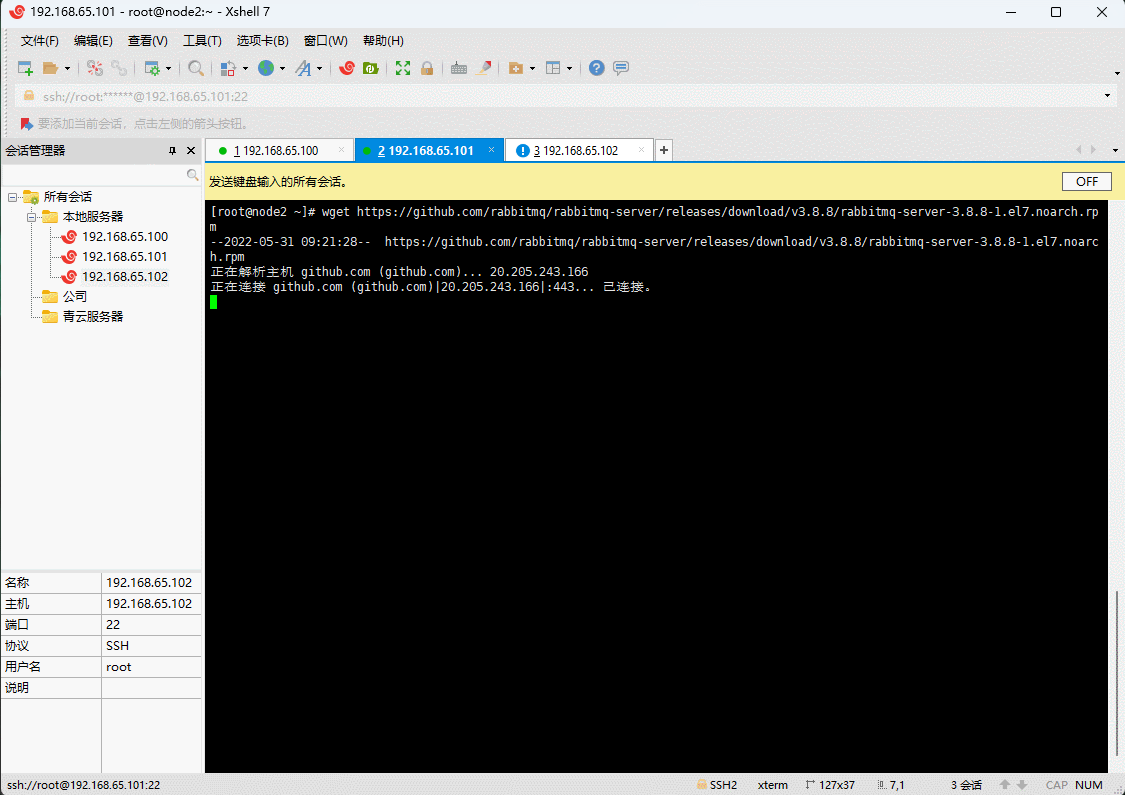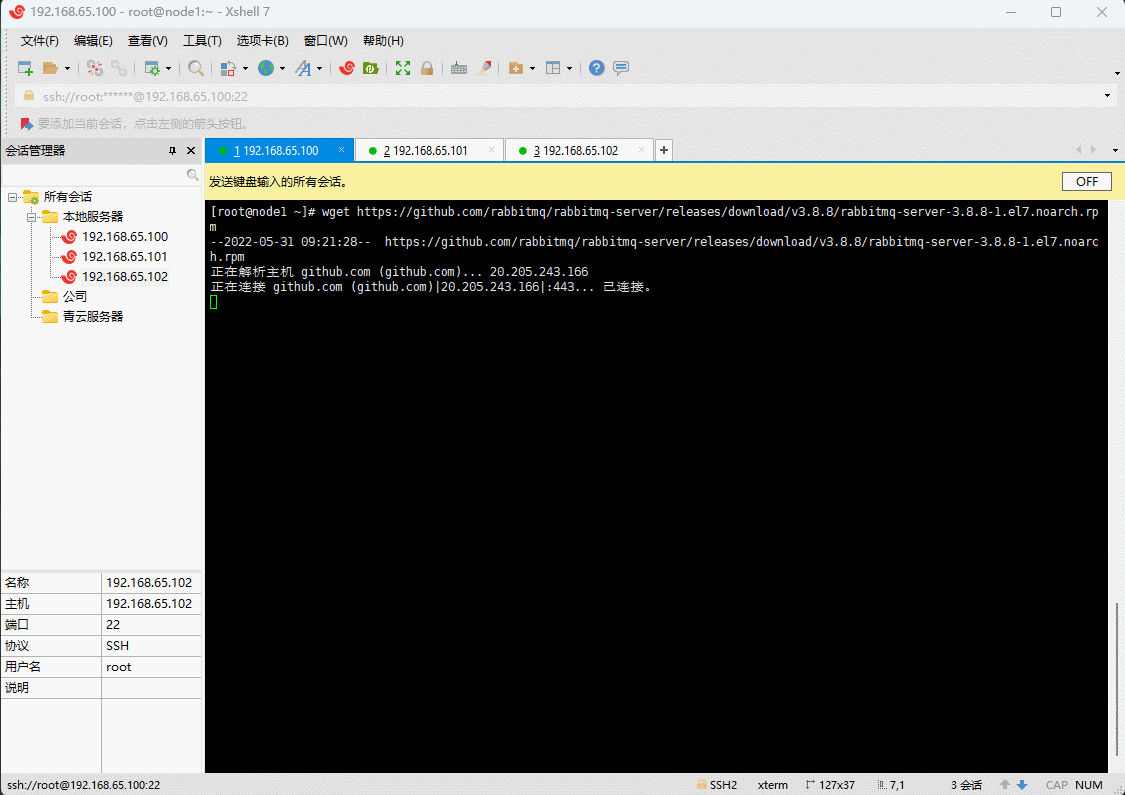
- 下载安装包(三台机器都执行):
wget https://github.com/rabbitmq/rabbitmq-server/releases/download/v3.8.8/rabbitmq-server-3.8.8-1.el7.noarch.rpm
- 安装依赖(三台机器都执行):
yum -y install socat
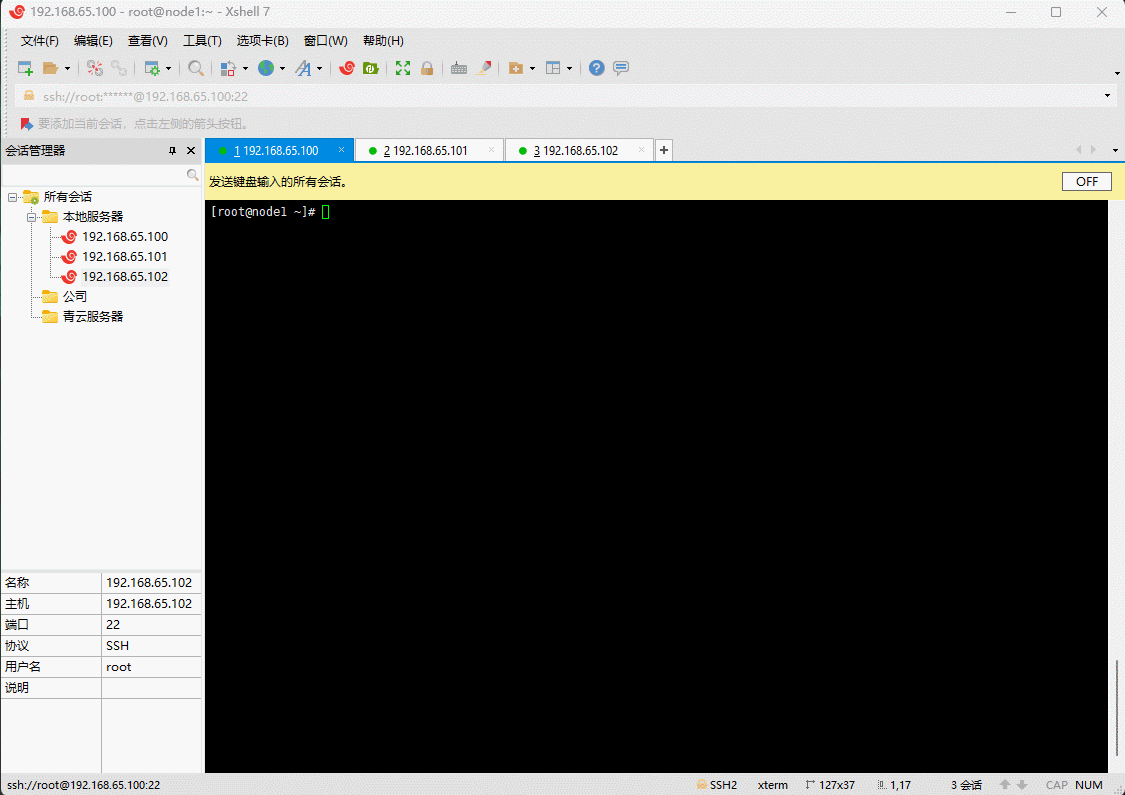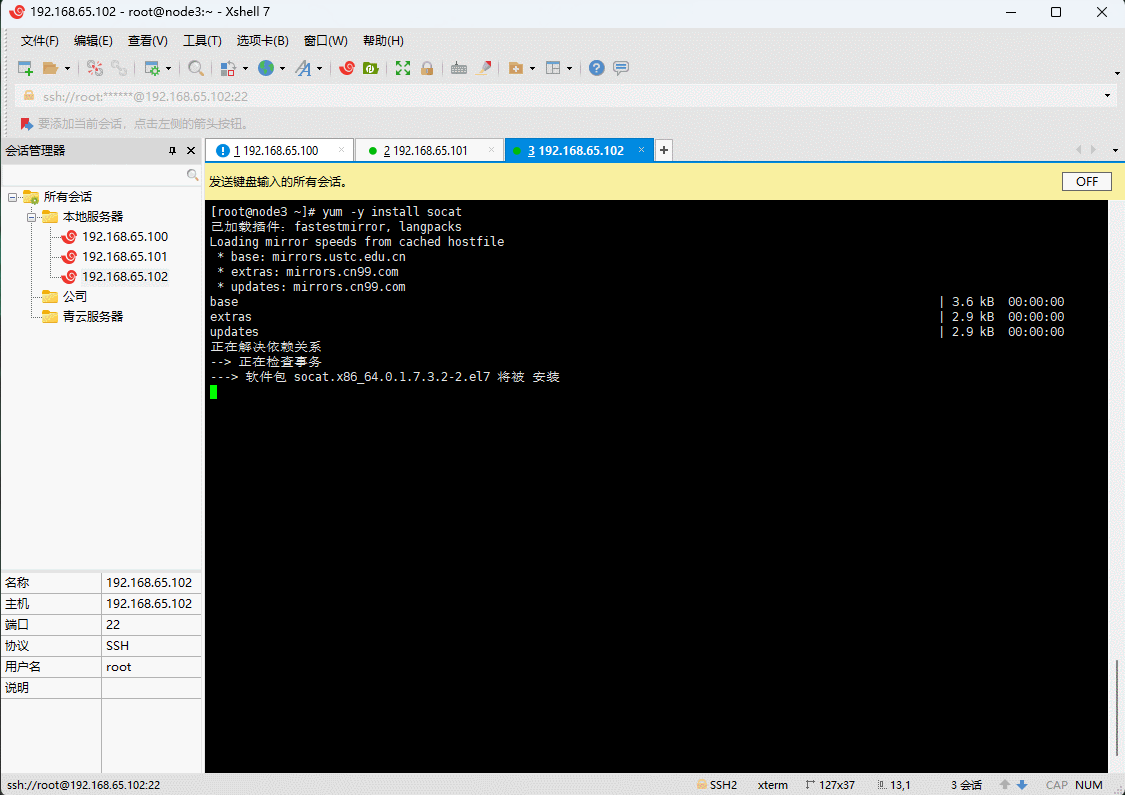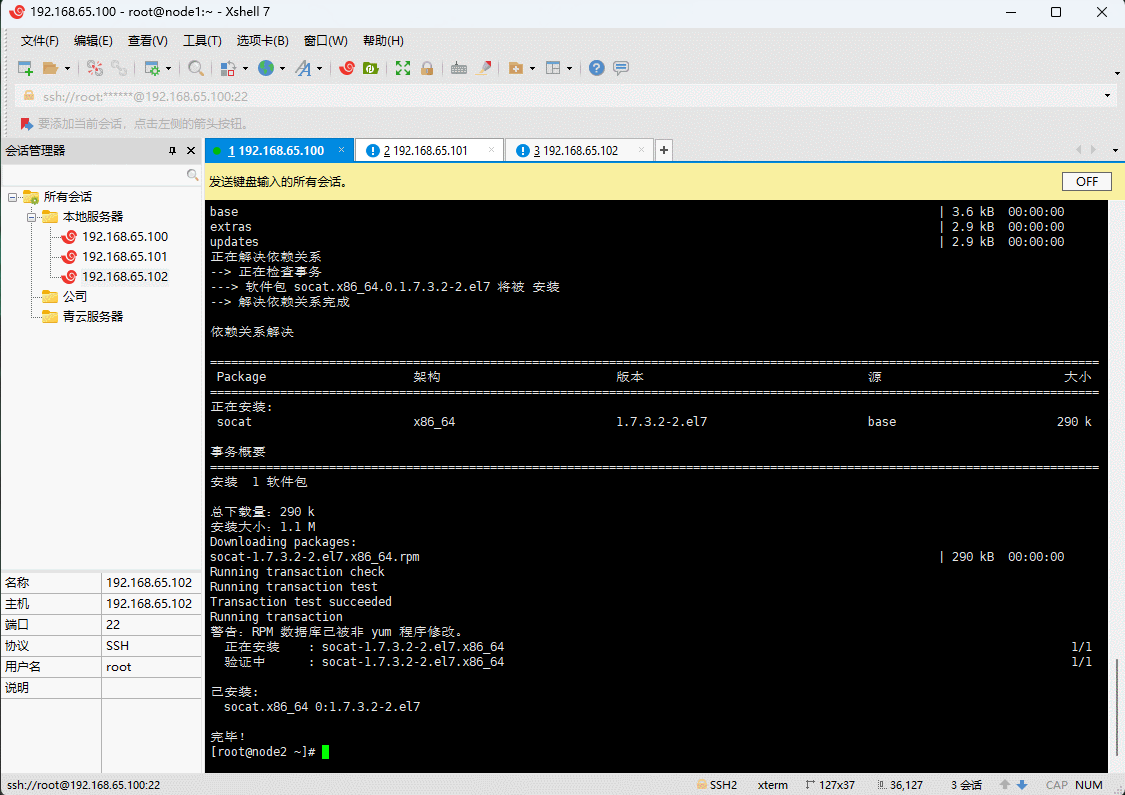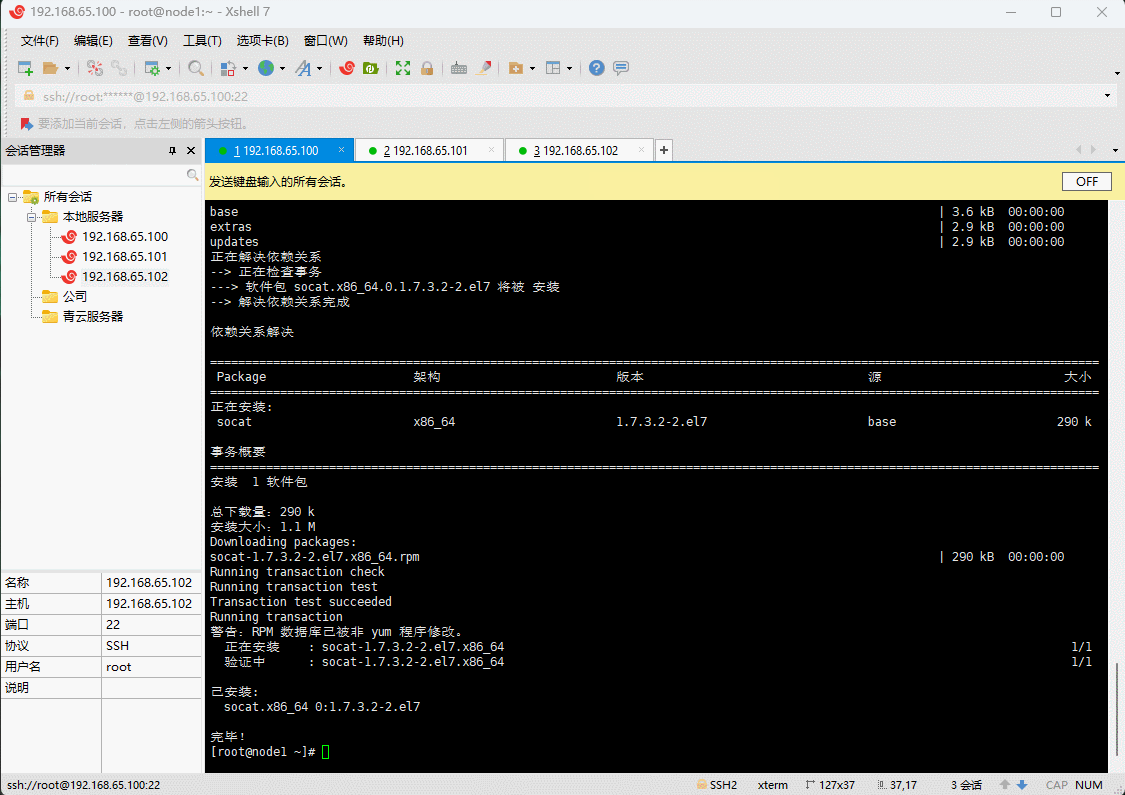
- 安装(三台机器都执行):
rpm -ivh rabbitmq-server-3.8.8-1.el7.noarch.rpm

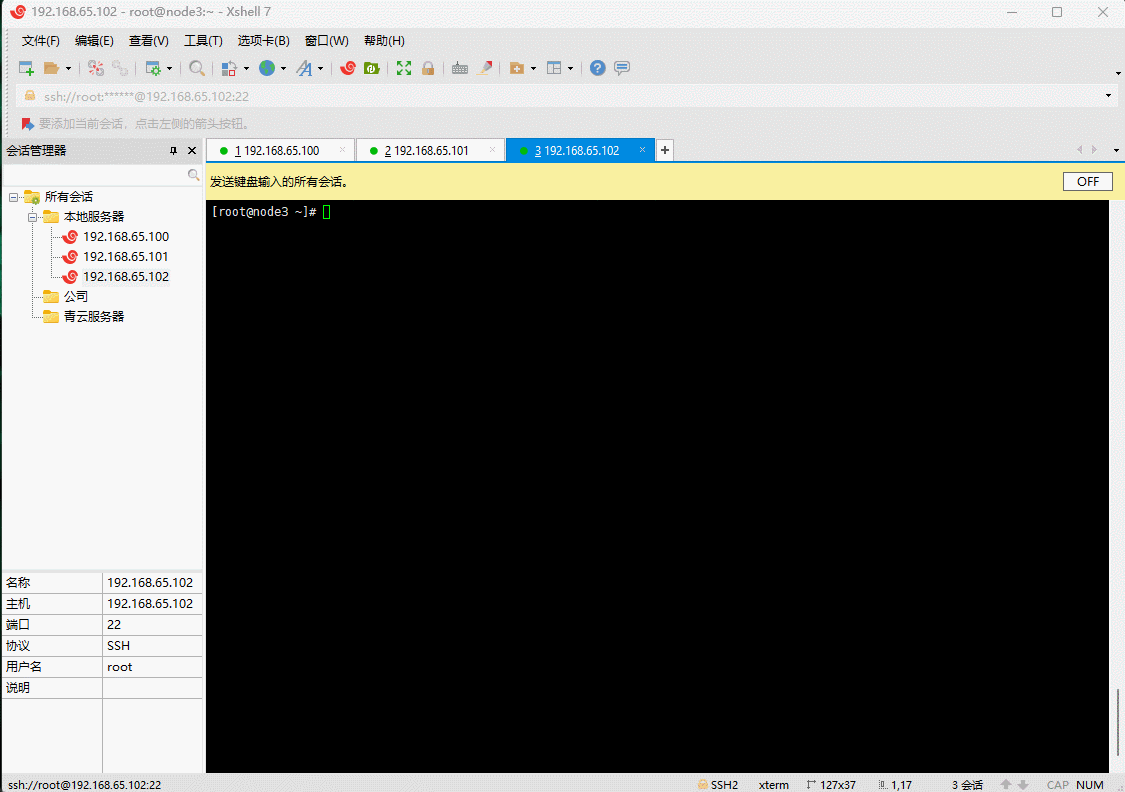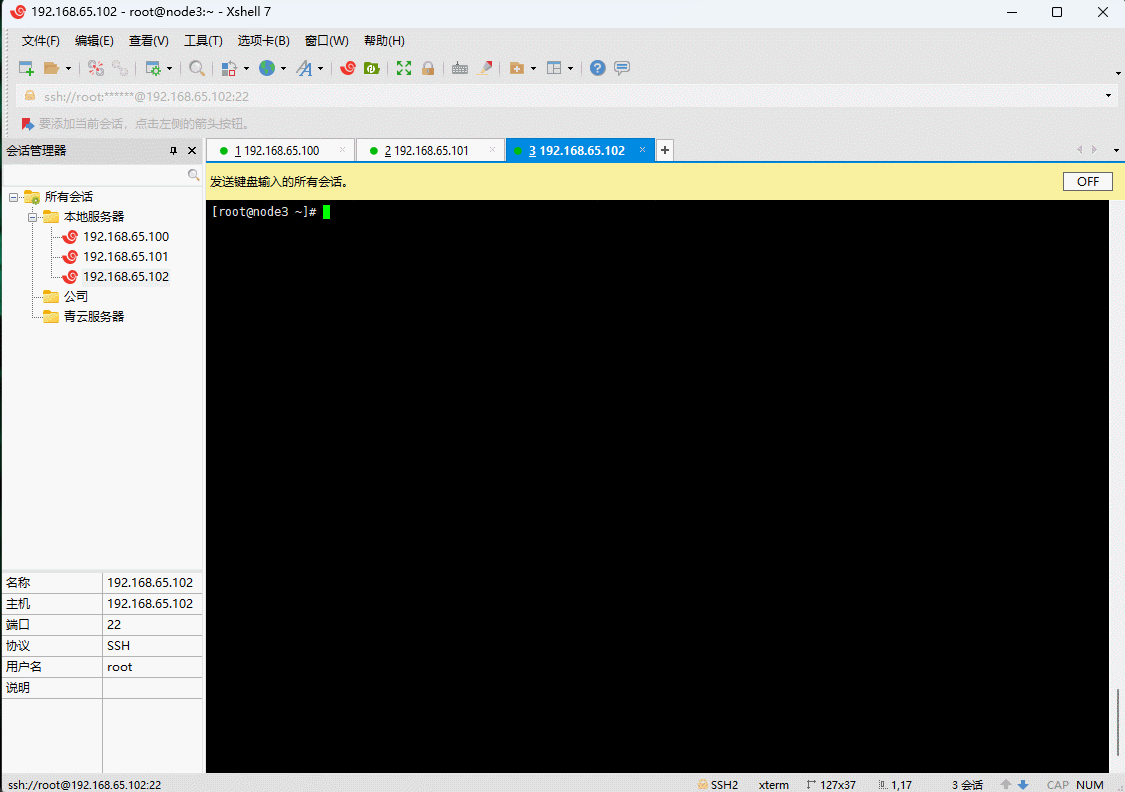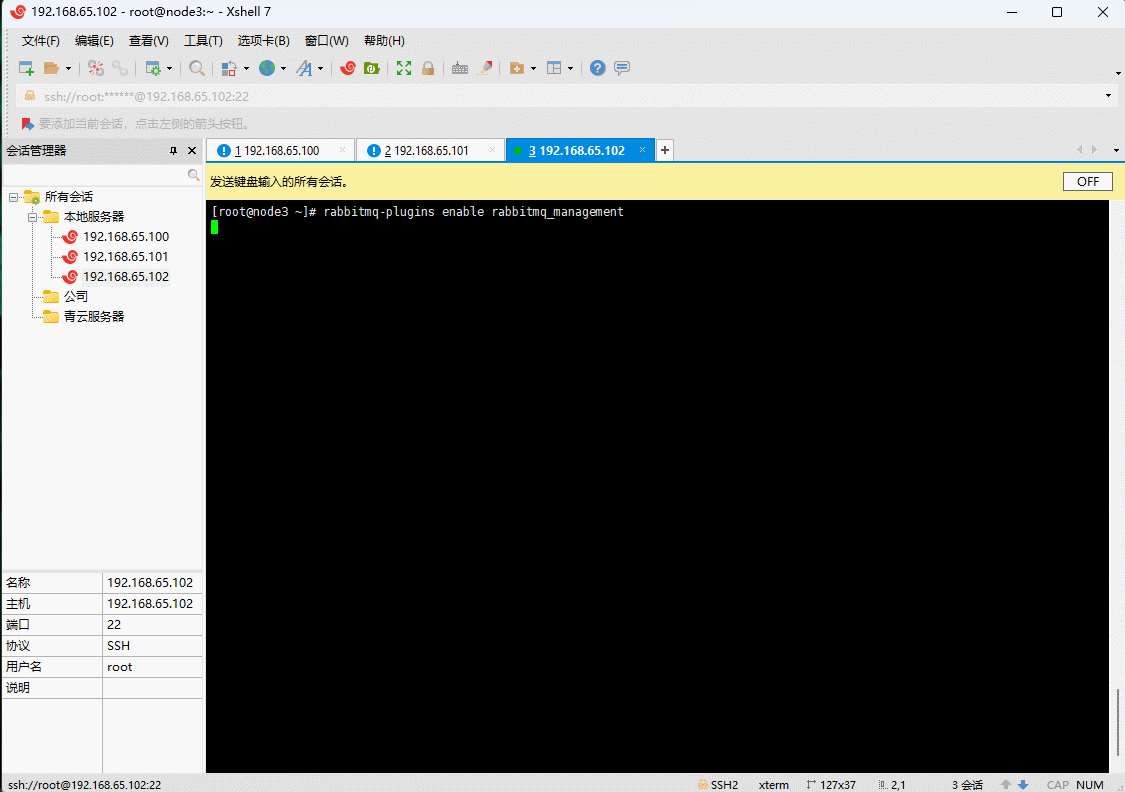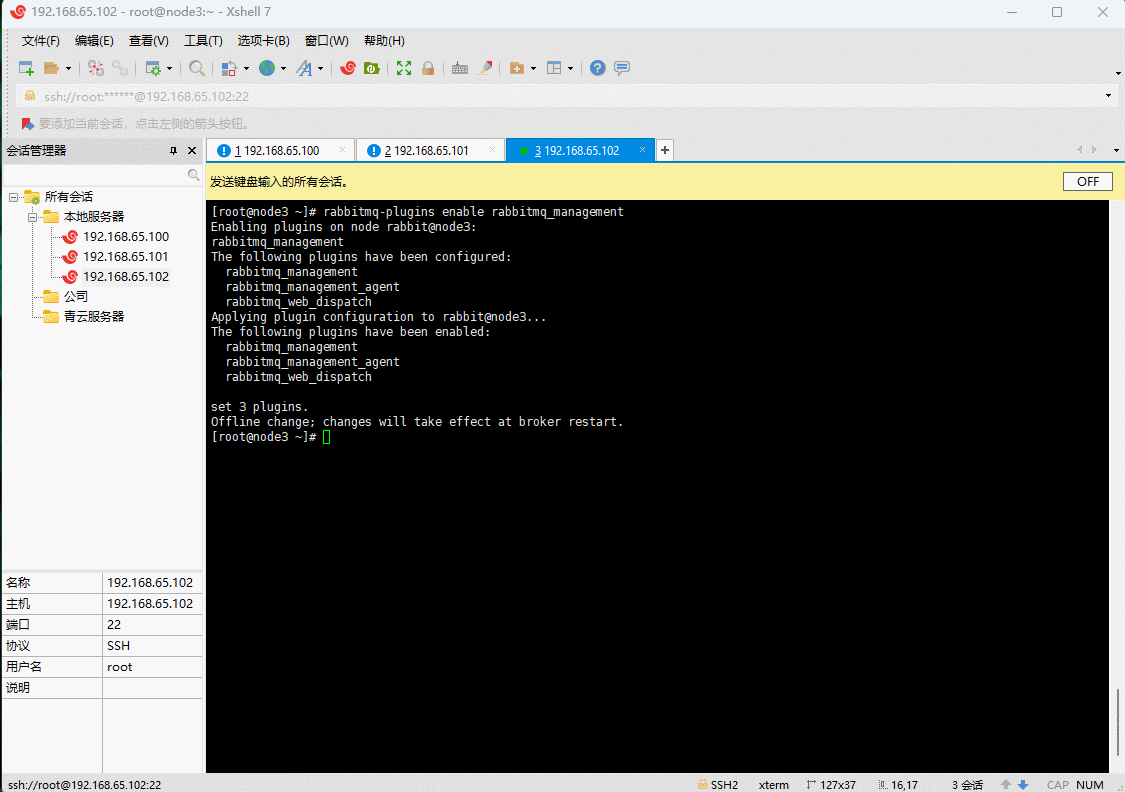
- 开启管理界面(三台机器都执行):
rabbitmq-plugins enable rabbitmq_management
- 配置远程可以使用 guest 登录 RabbitMQ(三台机器都执行):
vim /etc/rabbitmq/rabbitmq.conf
loopback_users = none
- 启动 RabbitMQ(三台机器都执行):
systemctl start rabbitmq-server
systemctl enable rabbitmq-server

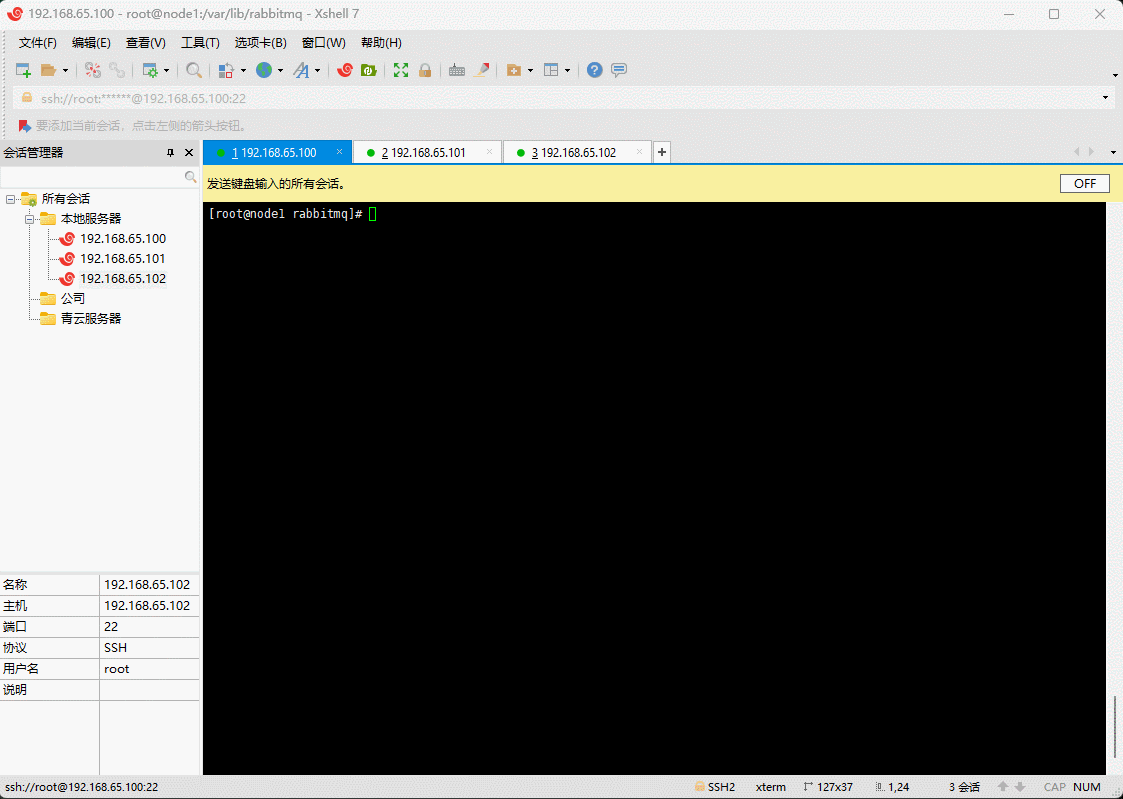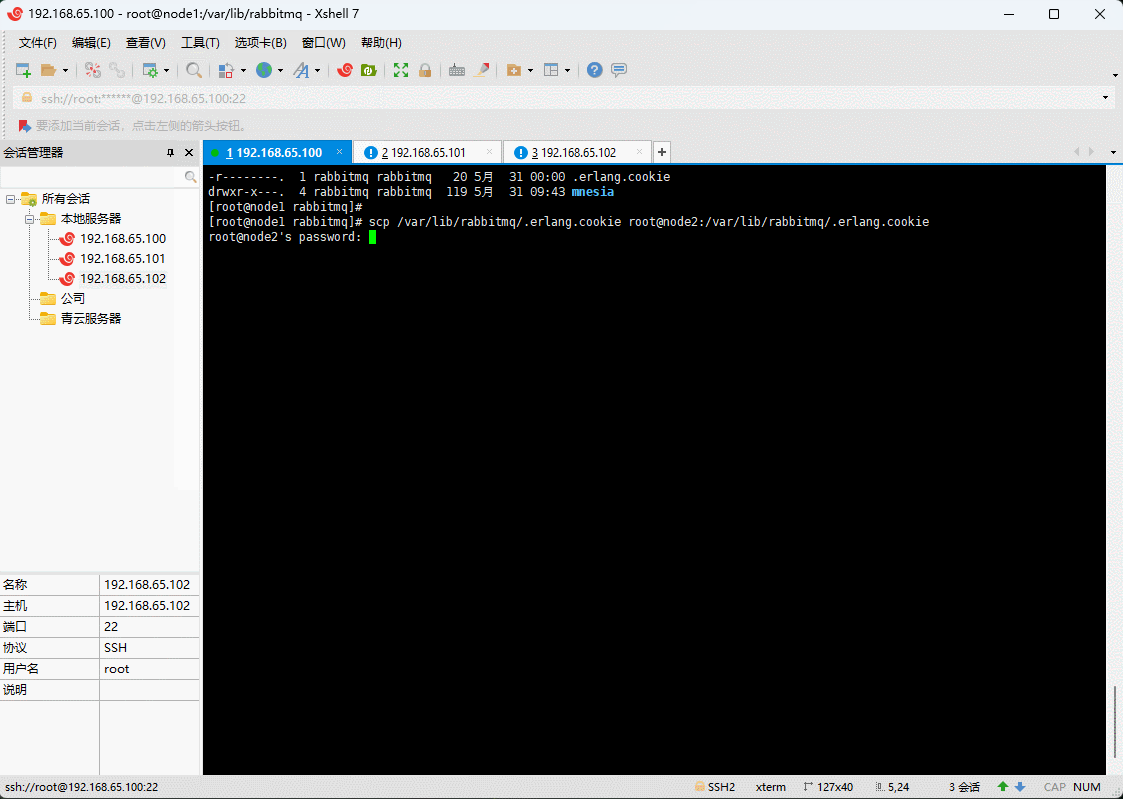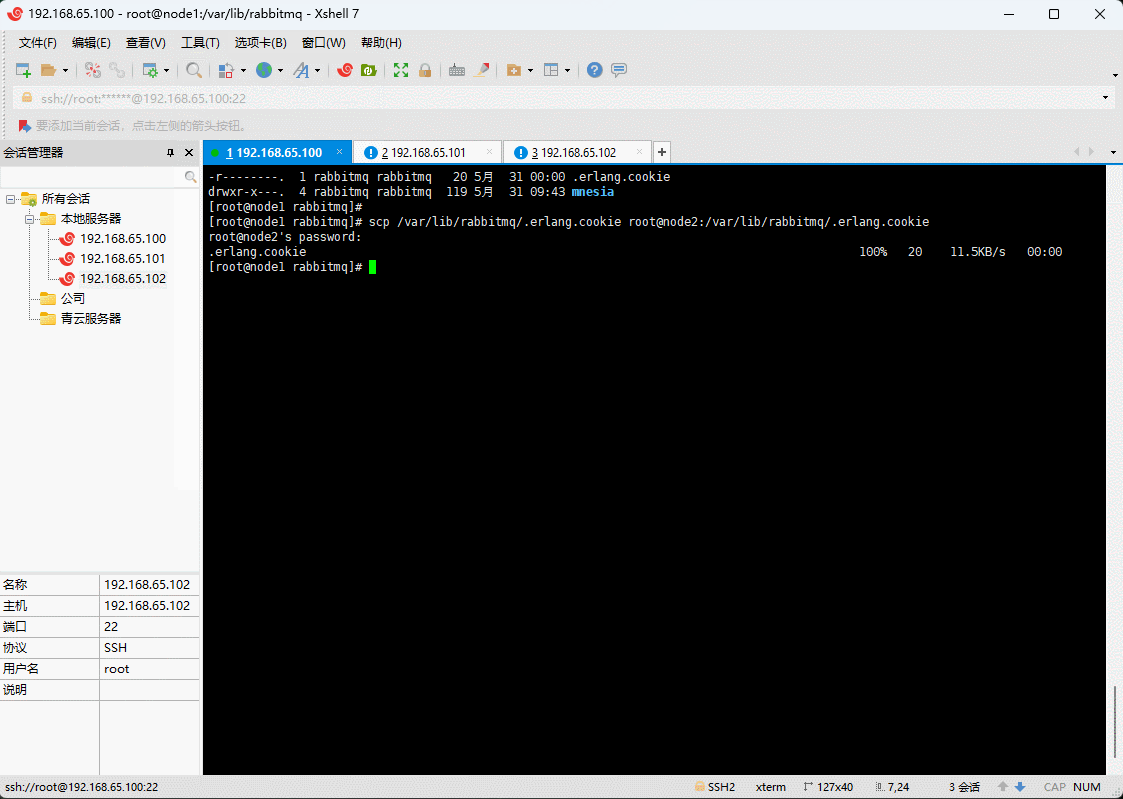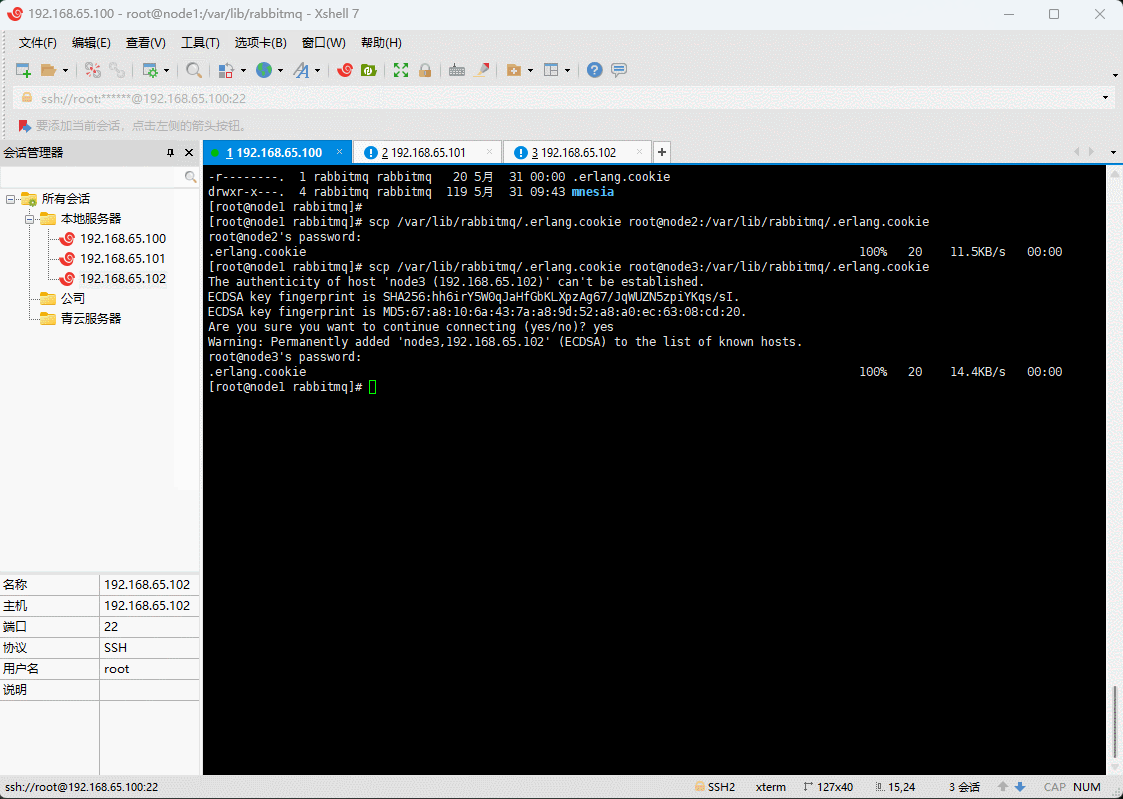
2.3.5确保各个节点的 cookie 一致
- 在 node1 节点执行如下的命令:
scp /var/lib/rabbitmq/.erlang.cookie root@node2:/var/lib/rabbitmq/.erlang.cookie
scp /var/lib/rabbitmq/.erlang.cookie root@node3:/var/lib/rabbitmq/.erlang.cookie
2.3.6 重启 RabbitMQ 服务
- 重启 RabbitMQ 服务,顺带重启 Erlang 虚拟机和 RabbitMQ 应用程序(三台机器都执行):
rabbitmq-server -detached
systemctl restart rabbitmq-server

2.3.7 将 node2 节点加入到 node1 节点上
- 命令(node2 机器执行):
# (rabbitmqctl stop 会将 Erlang 虚拟机关闭,rabbitmqctl stop_app 只关闭 RabbitMQ 服务rabbitmqctl stop_app
rabbitmqctl reset
rabbitmqctl join_cluster rabbit@node1
rabbitmqctl start_app

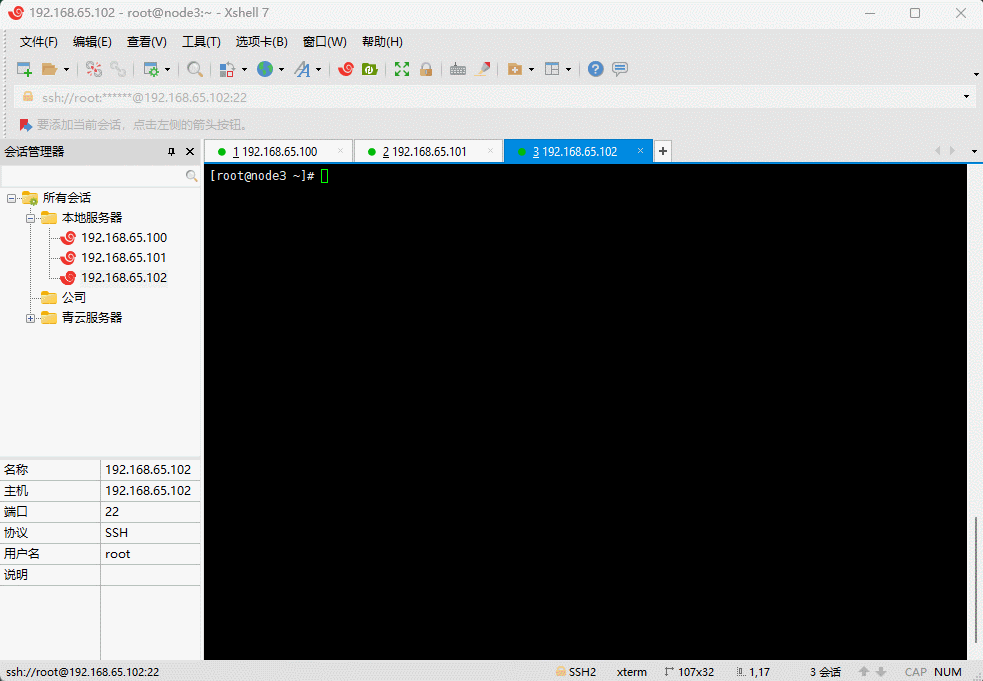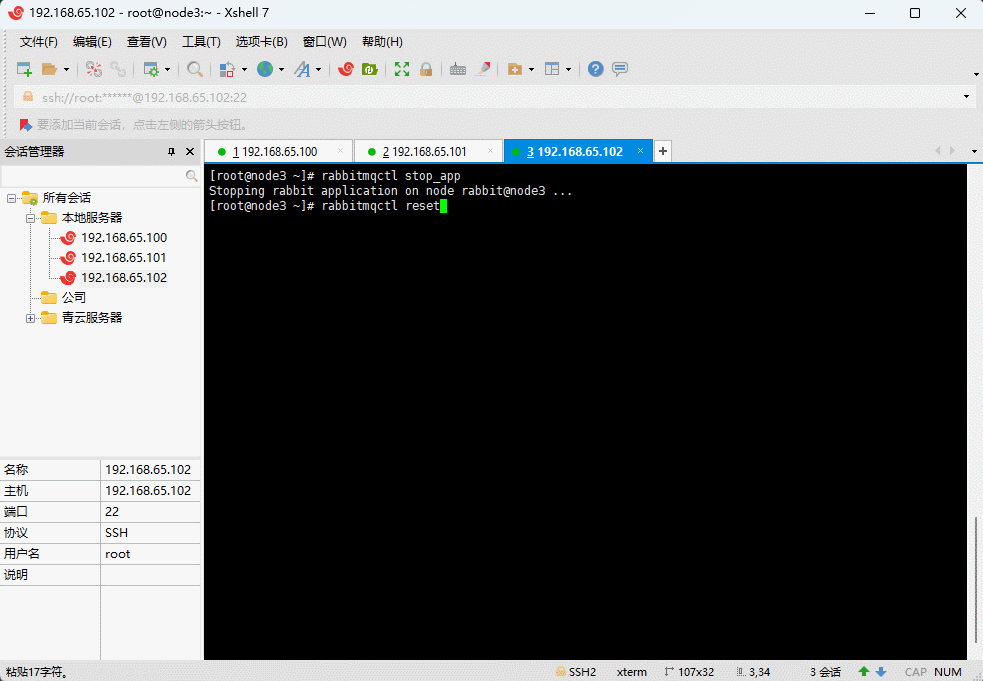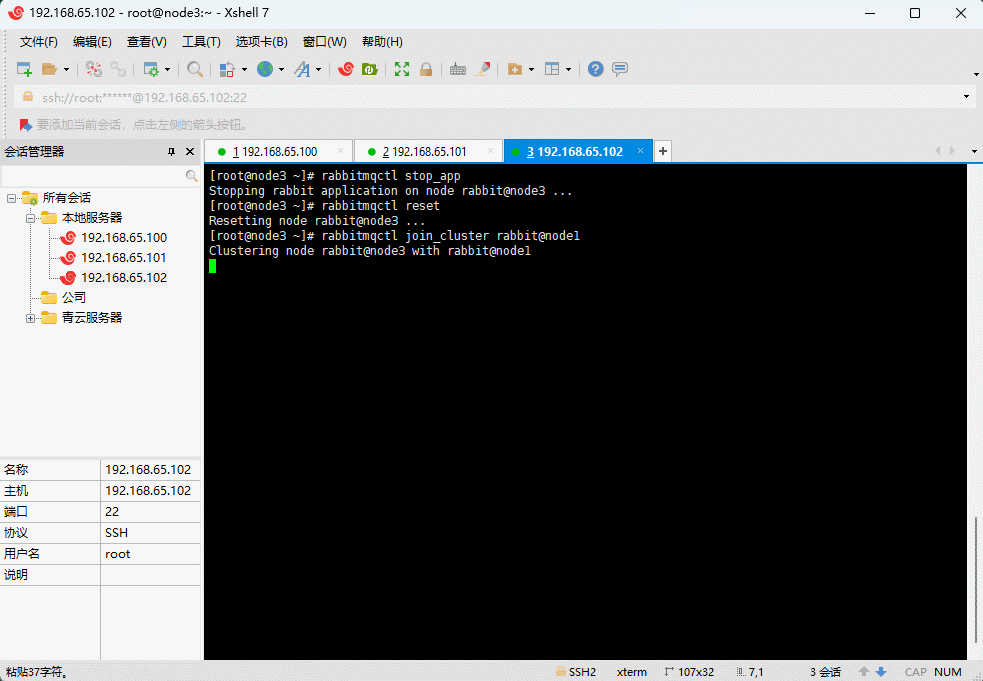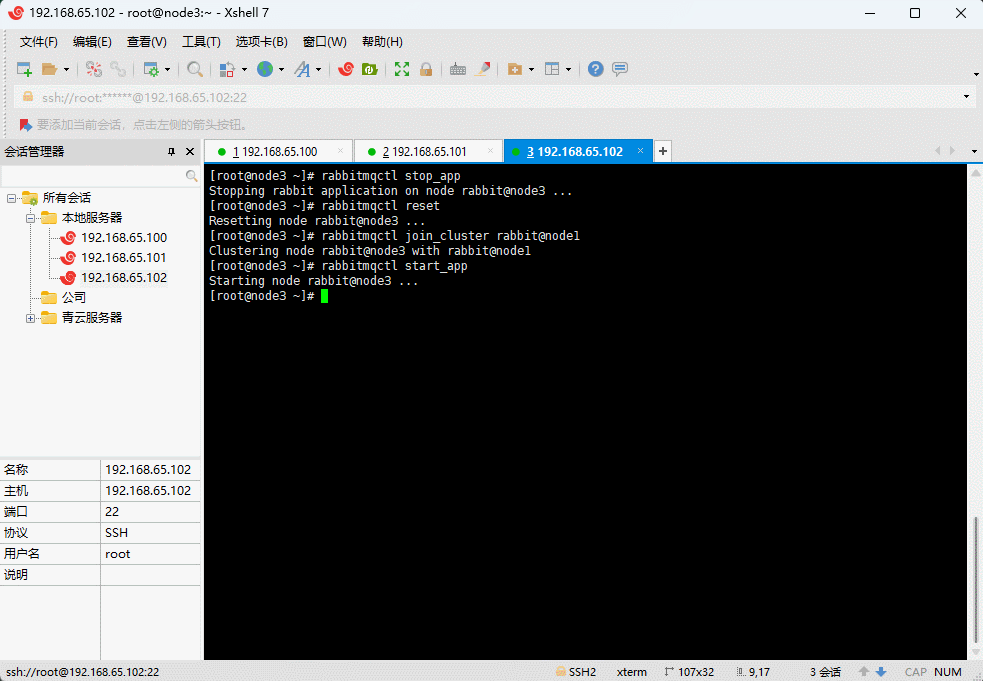
2.3.8 将 node3 节点加入到 node1 节点上
- 命令(node3 机器执行):
rabbitmqctl stop_app
rabbitmqctl reset
rabbitmqctl join_cluster rabbit@node1
rabbitmqctl start_app
2.3.9 查看集群状态
- 在任意一台机器上执行如下的命令:
rabbitmqctl cluster_status

- 登录任意一台机器的控制台界面:
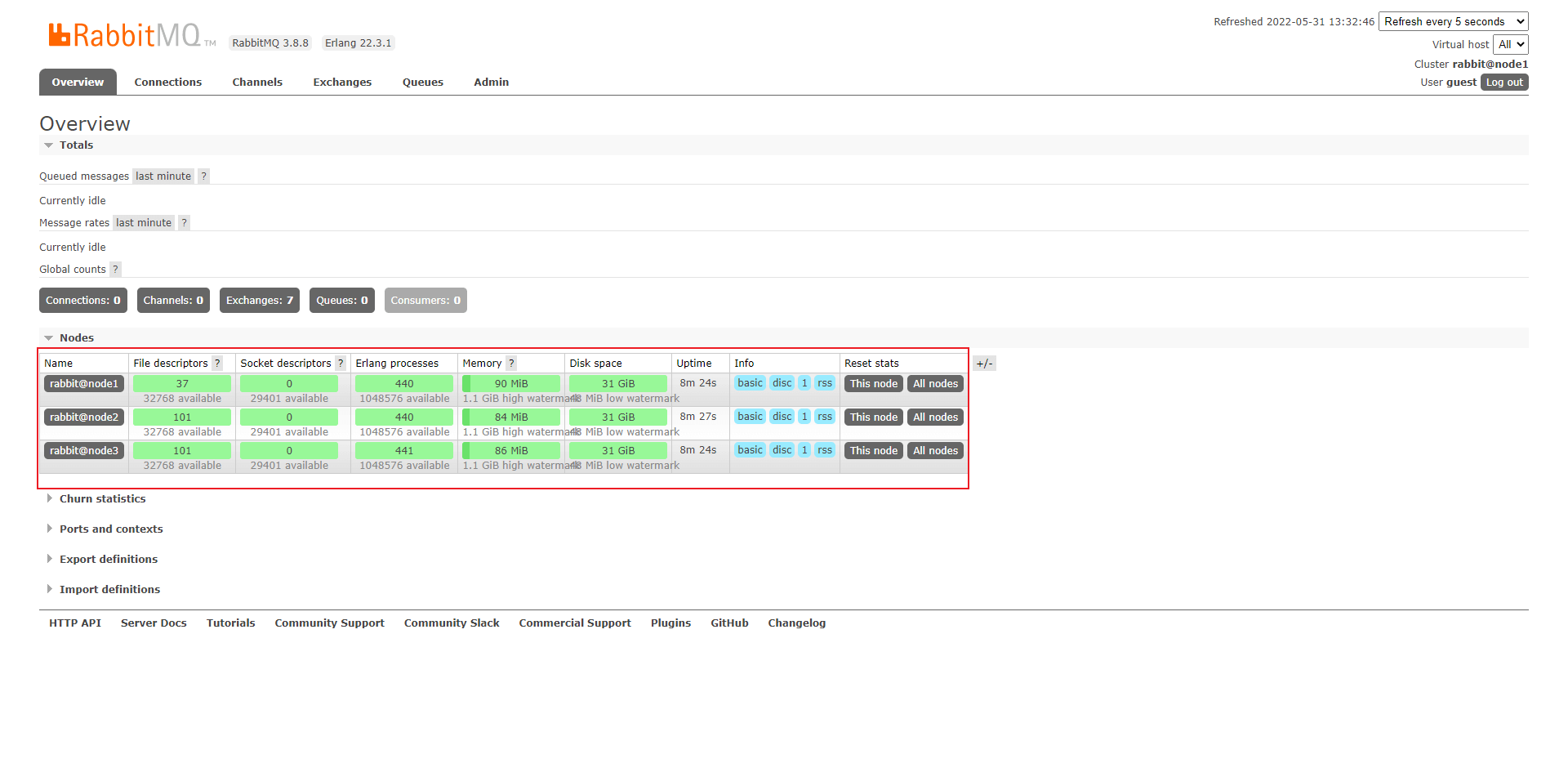
2.3.10 创建用户
任意机器执行如下的命令即可。
- 创建账号:
rabbitmqctl add_user admin 123
- 设置用户角色:
rabbitmqctl set_user_tags admin administrator
- 设置用户权限:
rabbitmqctl set_permissions -p "/" admin ".*" ".*" ".*"
2.3.11 解除集群节点
将 node2 从集群中脱离。
- 在 node2 上执行如下的命令:
rabbitmqctl stop_app
rabbitmqctl reset
rabbitmqctl start_app
rabbitmqctl cluster_status
- 在 node1 节点上执行:
rabbitmqctl forget_cluster_node rabbit@node2
注意:普通集群仅仅解决了 RabbitMQ 集群的可扩展。
第三章:镜像队列
3.1 概述
- 如果 RabbitMQ 集群中只有一个 Broker 节点,那么该节点的失效将导致整体服务的临时性不可用,并且也可能会导致消息的丢失。可以将所有消息都设置为持久化,并且对应队列的durable属性也设置为true,但是这样仍然无法避免由于缓存导致的问题:因为消息在发送之后和被写入磁盘井执行刷盘动作之间存在一个短暂却会产生问题的时间窗。通过 publisherconfirm 机制能够确保客户端知道哪些消息己经存入磁盘,尽管如此,一般不希望遇到因单点故障导致的服务不可用。
- 引入镜像队列(Mirror Queue)的机制,可以将队列镜像到集群中的其他 Broker 节点之上,如果集群中的一个节点失效了,队列能自动地切换到镜像中的另一个节点上以保证服务的可用性。
3.2 搭建步骤
- 在任意一台机器上执行如下的命令:
rabbitmqctl set_policy [-p Vhost] Name Pattern Definition [Priority]
- 参数:
-p Vhost: 可选参数,针对指定 vhost下的 queue 进行设置。Pattern: queue 的匹配模式(正则表达式)。Definition:镜像定义,包括三个部分 ha-mode,、ha-params、ha-sync-mode。ha-mode:指明镜像队列的模式,有效值为 all 、exactly、nodes 。- all:表示在集群中所有的节点上进行镜像。
- exactly:表示在指定个数的节点上进行镜像,节点的个数由 ha-params 指定。
- nodes:表示在指定的节点上进行镜像,节点名称通过 ha-params 指定。
ha-params:ha-mode 模式需要用到的参数。ha-sync-mode:进行队列中消息的同步方式,有效值为 automatic 和 manual 。
priority:可选参数,policy 的优先级。
- 示例:
rabbitmqctl set_policy ha-two "^" '{"ha-mode":"exactly","ha-params":2,"ha-sync-mode":"automatic"}'
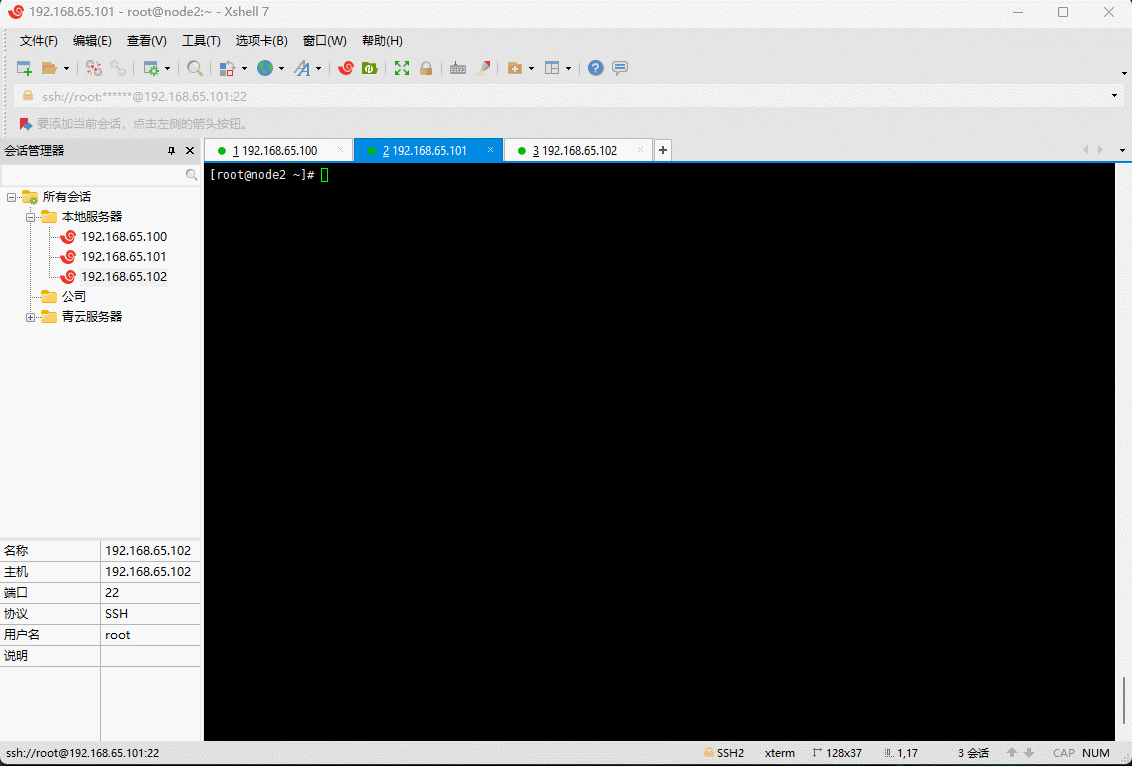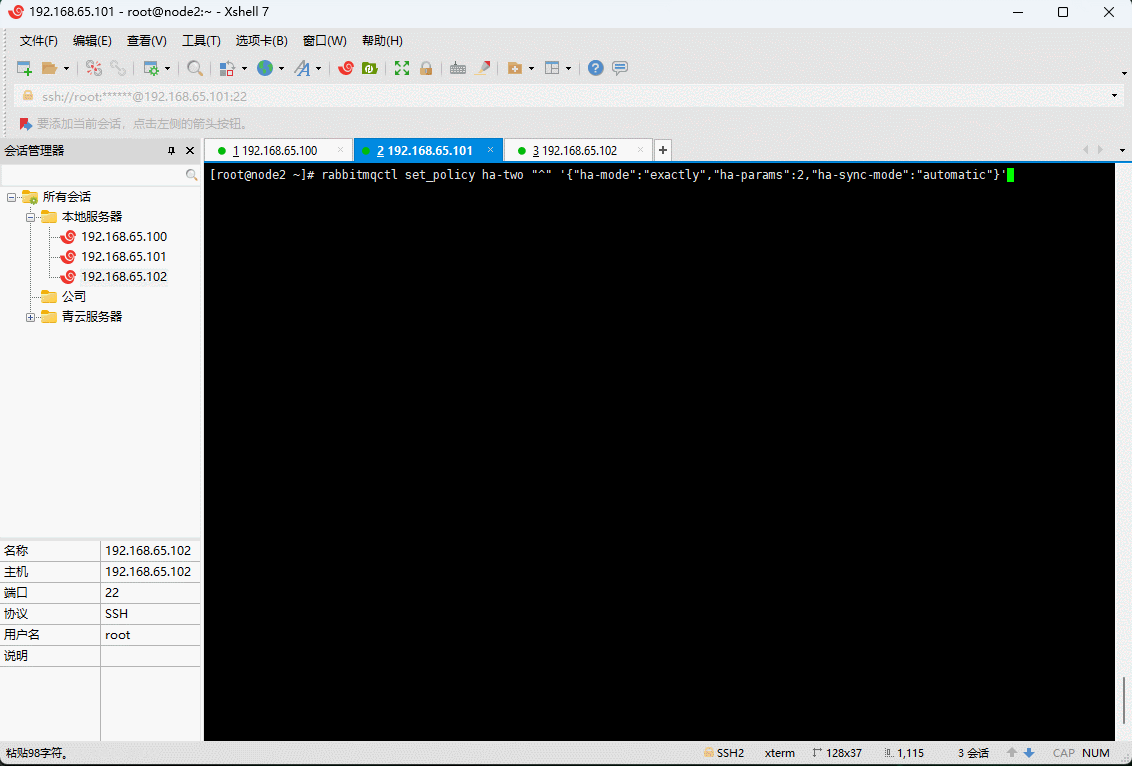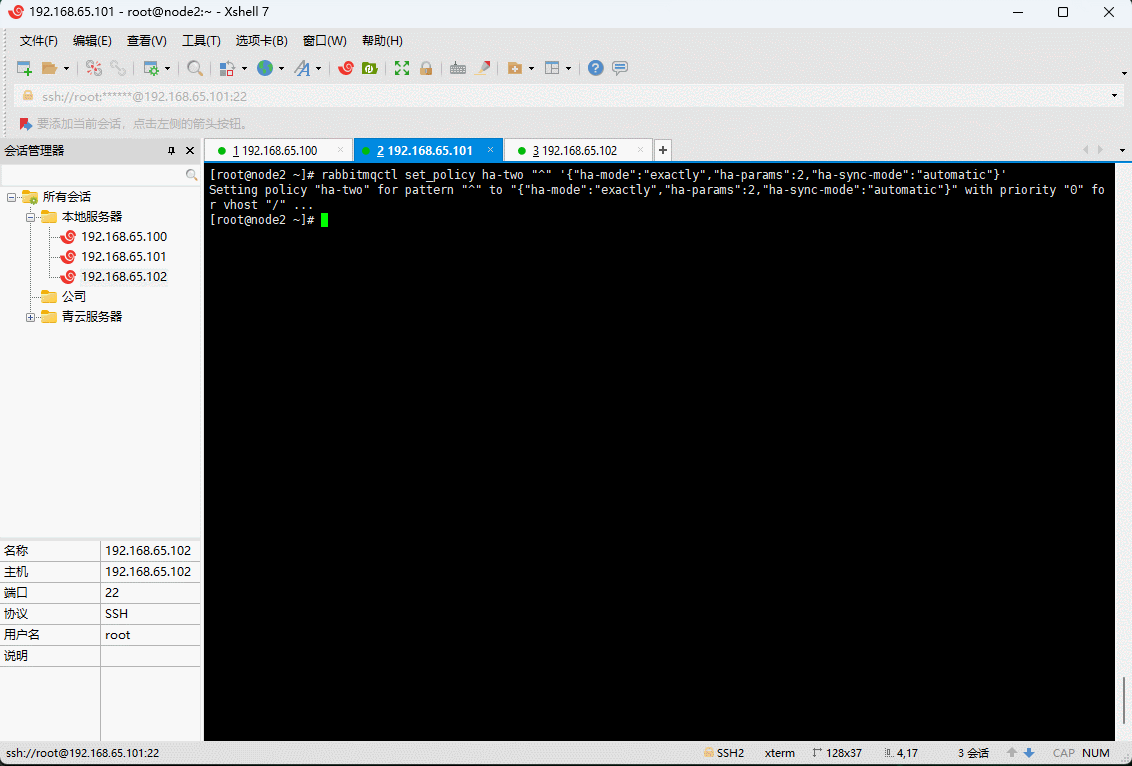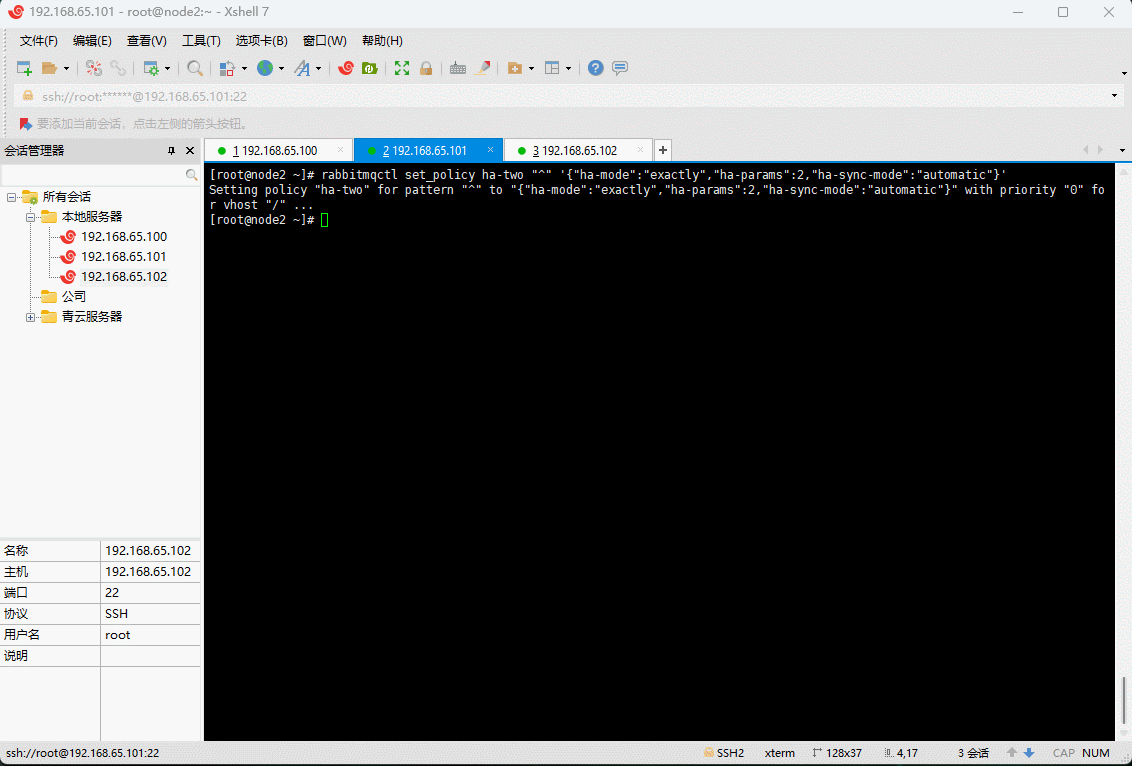
- 如果是界面,操作如下:
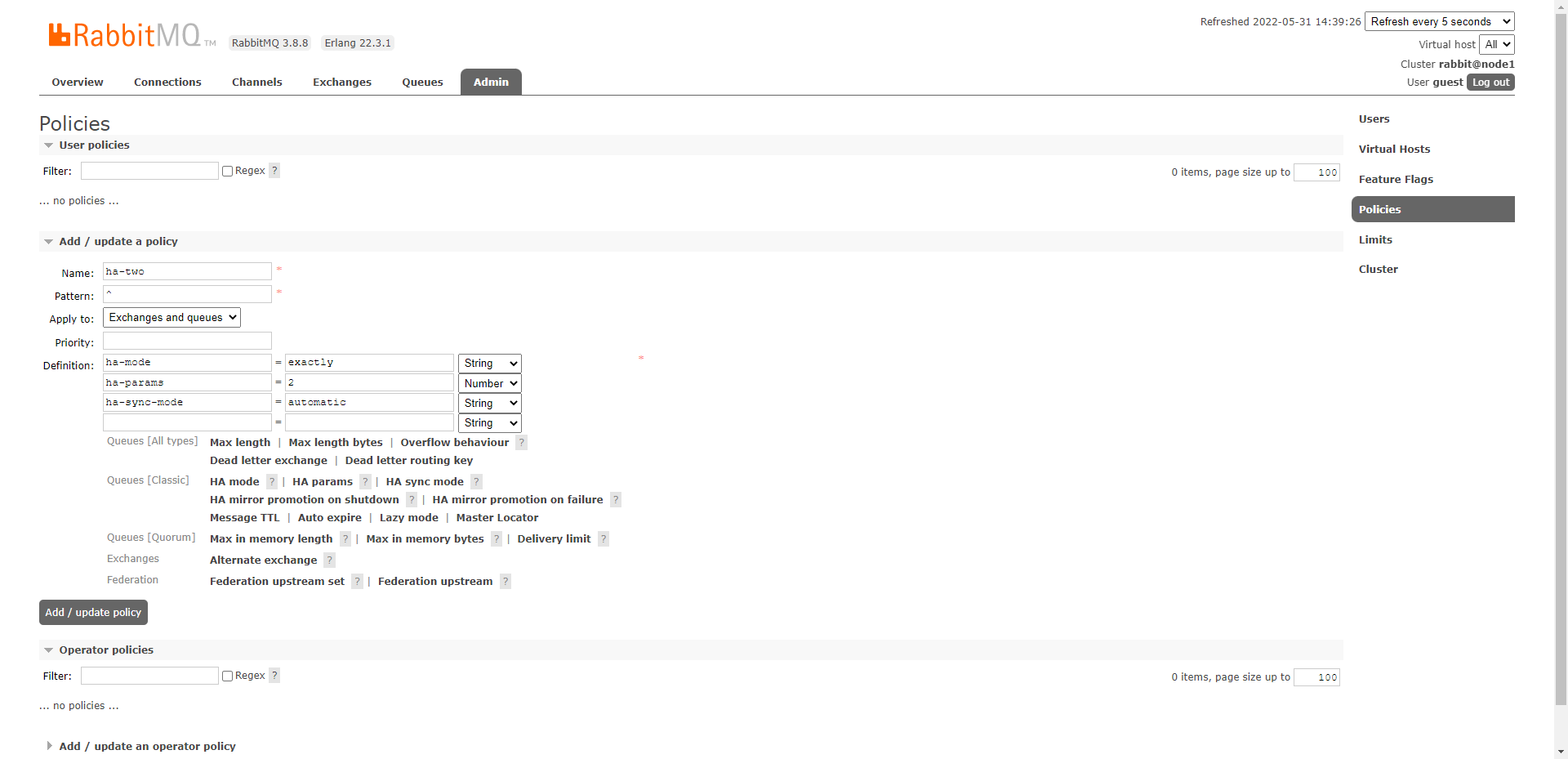
注意:镜像队列在普通集群的基础上解决了 RabbitMQ 集群的数据冗余。
第四章:Haprox + Keepalive 实现高可用负载均衡
4.1 架构图
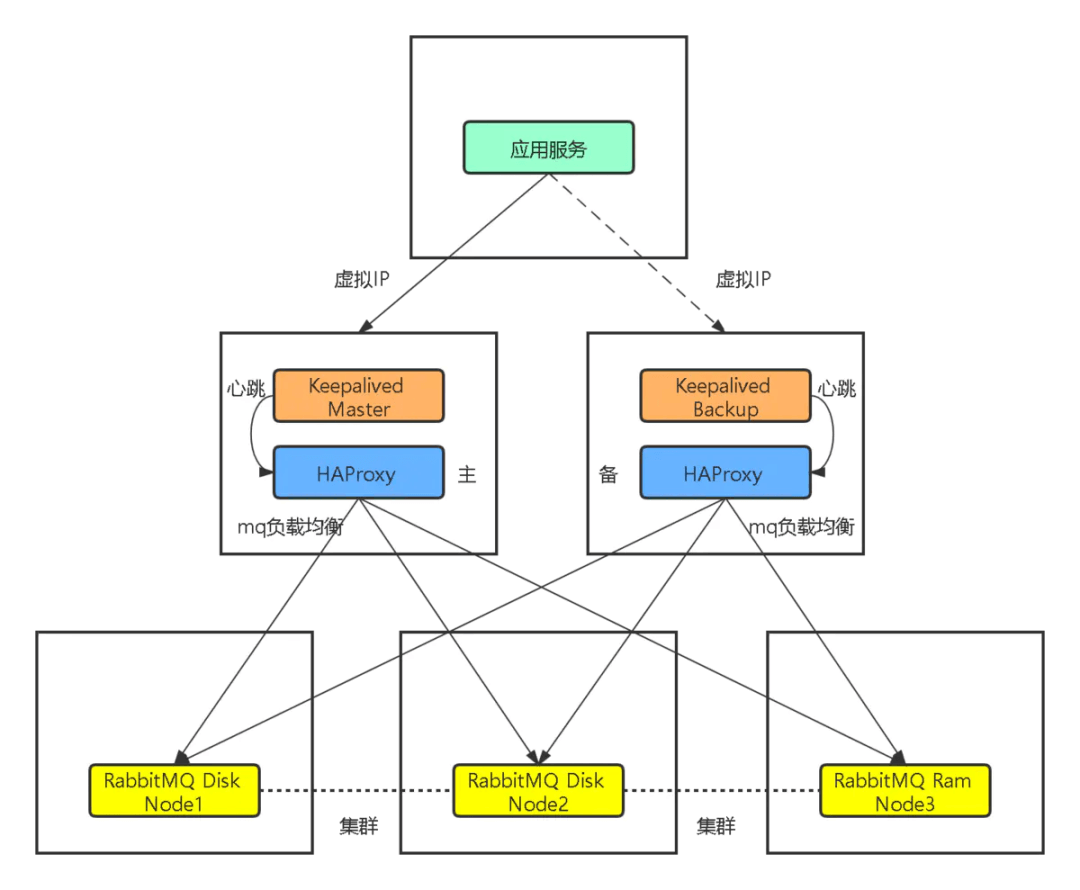
4.2 Haproxy 实现负载均衡
4.2.1 概述
- HAProxy 提供高可用性、负载均衡及基于 TCP、HTTP 应用的代理,支持虚拟主机,它是免费、快速并且可靠的一种解决方案,包括 Twitter、Reddit、StackOverflow、GitHub 在内的多家知名互联网公司在使用。
- HAProxy 实现了一种事件驱动、单一进程模型,此模型支持非常大的井发连接数。
4.2.2 搭建步骤
- 修改 hostname :
# 192.168.65.103hostnamectl set-hostname lb-master
# 192.168.65.104hostnamectl set-hostname lb-slave
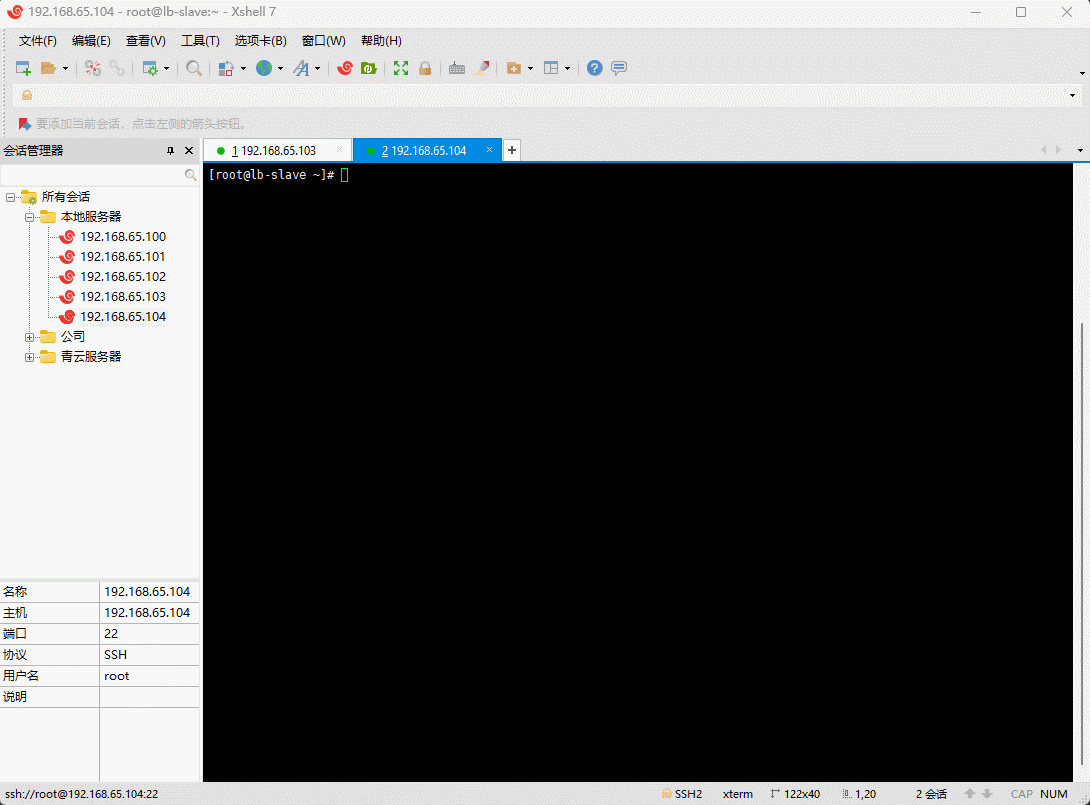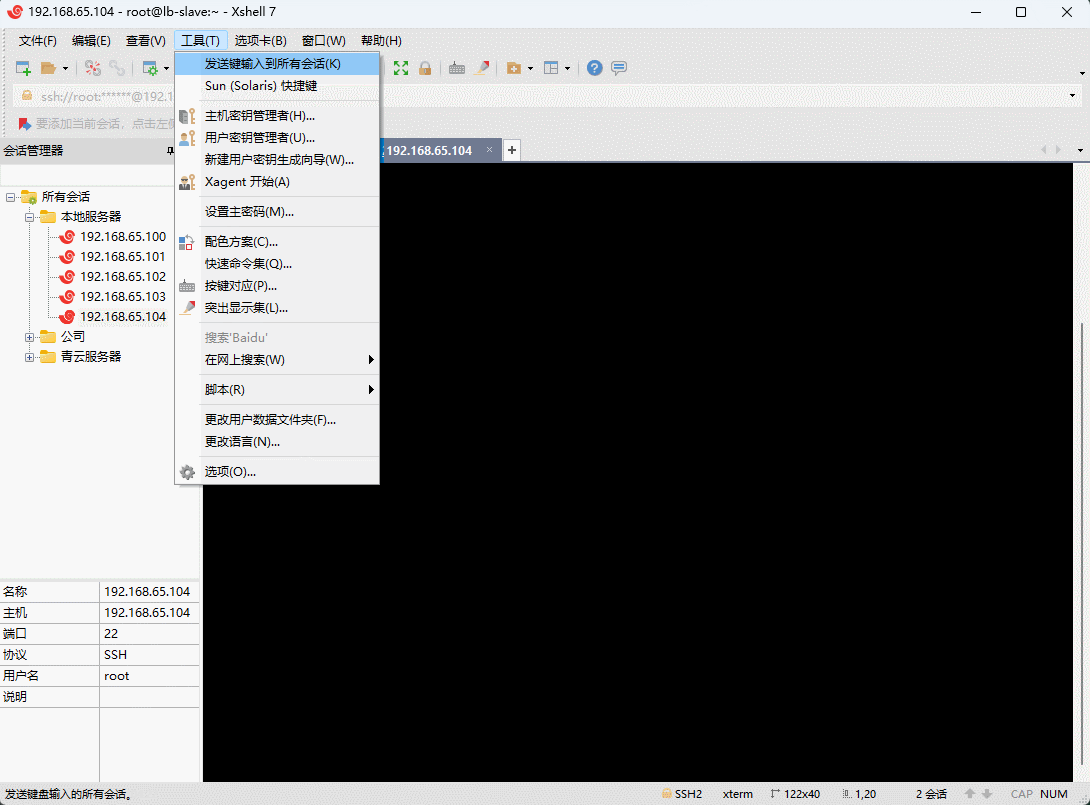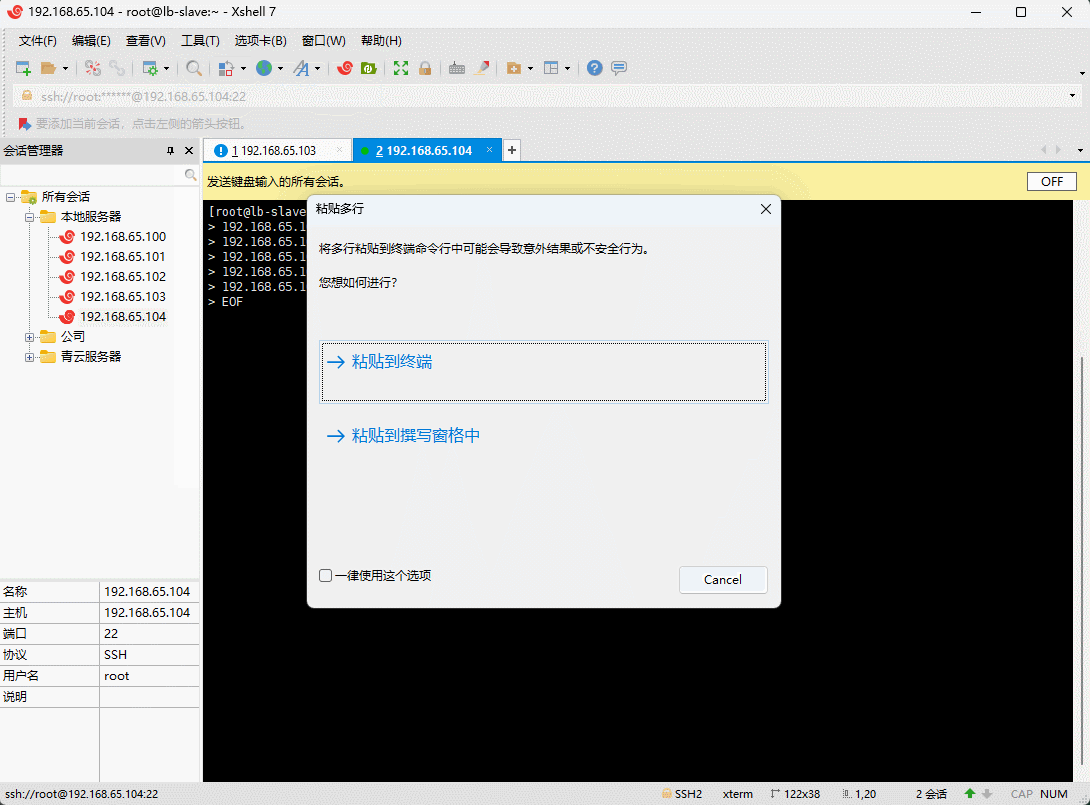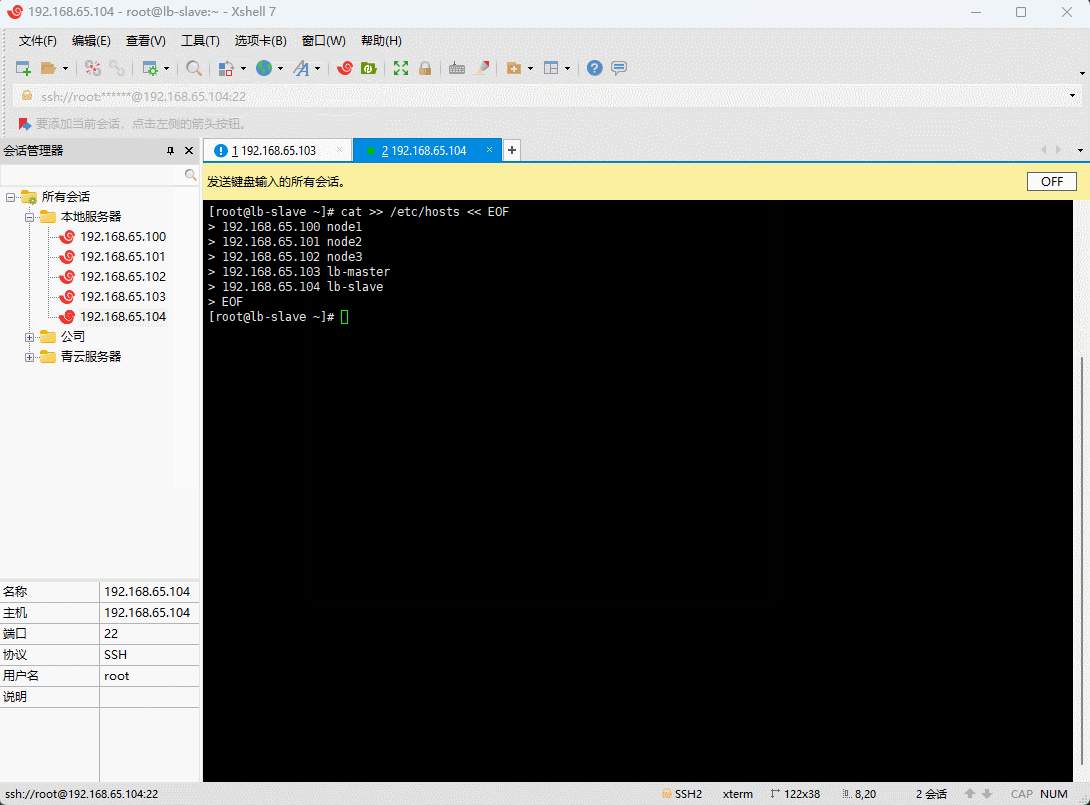
- 配置 hosts ,让其能识别 RabbitMQ 集群的节点(lb-master 和 lb-slave 机器执行):
cat >> /etc/hosts << EOF192.168.65.100 node1192.168.65.101 node2192.168.65.102 node3192.168.65.103 lb-master192.168.65.104 lb-slaveEOF
- 下载 haproxy(lb-master 和 lb-slave 机器执行):
yum -y install haproxy
- 修改 haproxy.cfg 配置文件(lb-master 和 lb-slave 机器执行):
vi /etc/haproxy/haproxy.cfg
global# 日志输出配置、所有日志都记录在本机,通过 local0 进行输出log 127.0.0.1 local0 info# 最大连接数maxconn 4096daemon# 默认配置defaults# 应用全局的日志配置log global# 使用4层代理模式,7层代理模式则为"http"mode tcp# 日志类别option tcplog# 不记录健康检查的日志信息option dontlognull# 3次失败则认为服务不可用retries 3# 每个进程可用的最大连接数maxconn 2000# 连接超时timeout connect 5s# 客户端超时timeout client 120s# 服务端超时timeout server 120s# 绑定配置listen rabbitmq_clusterbind :5672# 配置 TCP 模式mode tcp# 采用加权轮询的机制进行负载均衡balance roundrobin# RabbitMQ 集群节点配置server node1 node1:5672 check inter 5000 rise 2 fall 3 weight 1server node2 node2:5672 check inter 5000 rise 2 fall 3 weight 1server node3 node3:5672 check inter 5000 rise 2 fall 3 weight 1# RabbitMQ 控制台listen rabbitmq_adminbind :15672mode tcpbalance roundrobinserver node1 node1:15672server node2 node2:15672server node3 node3:15672# 配置监控页面listen monitorbind :8888mode httpoption httplogstats enablestats uri /statsstats refresh 5s
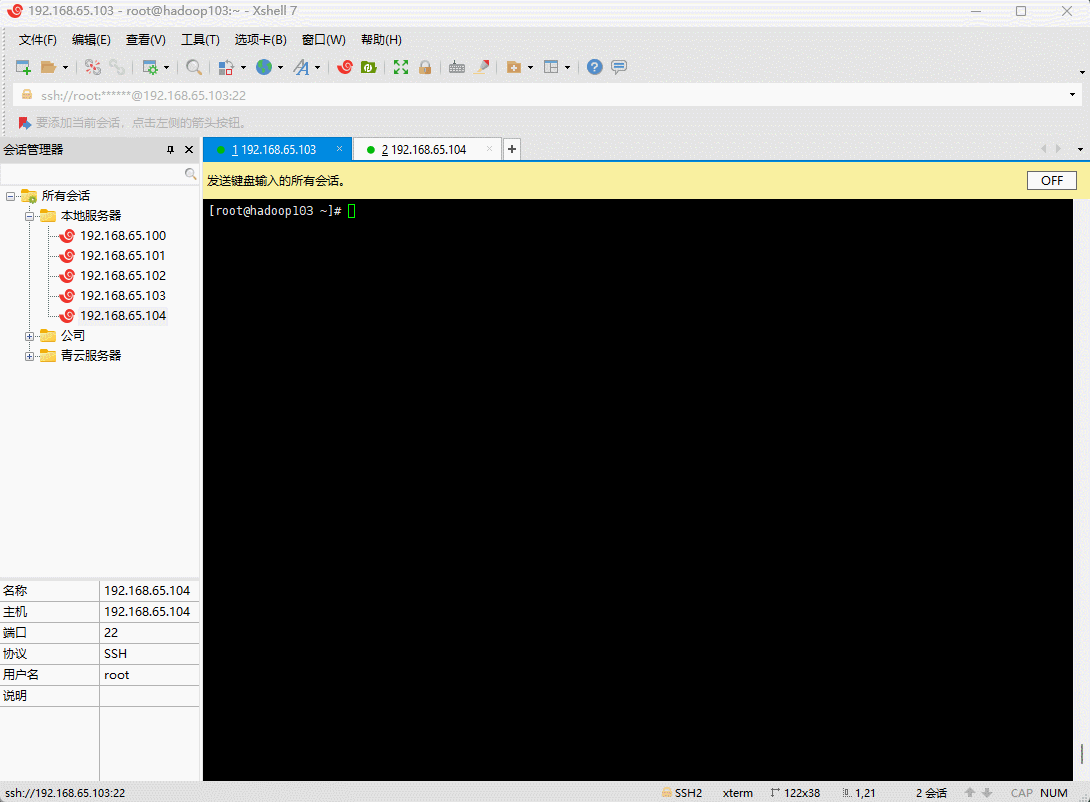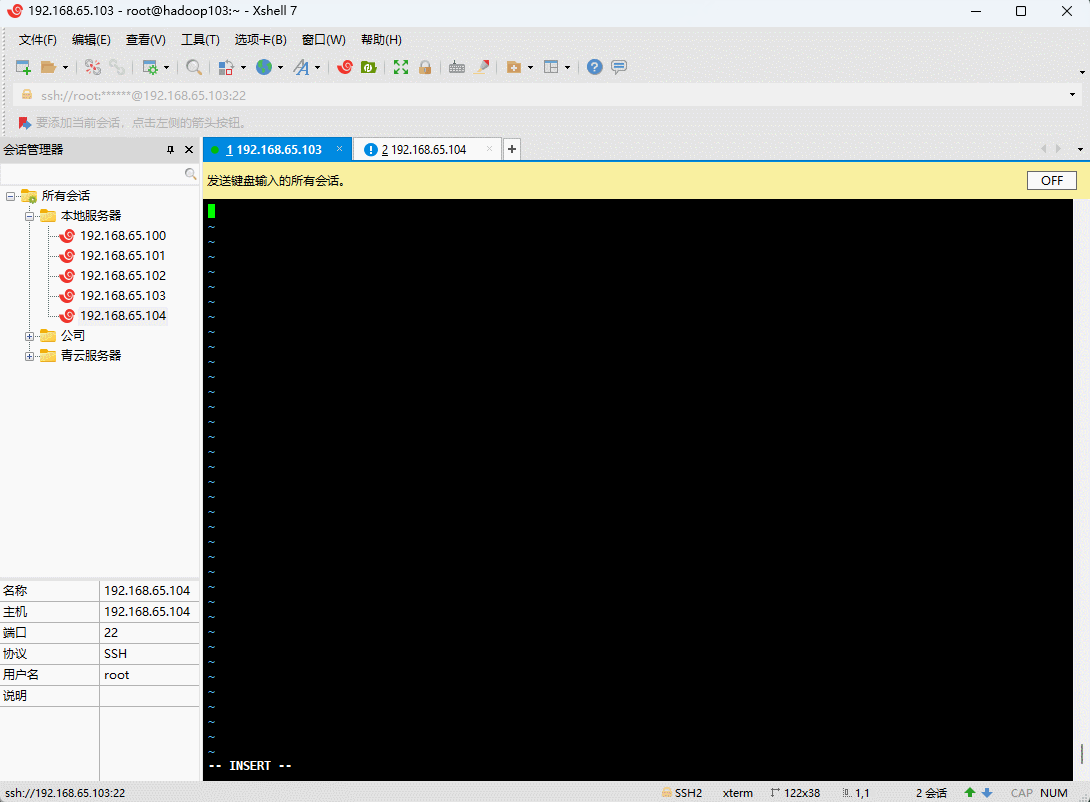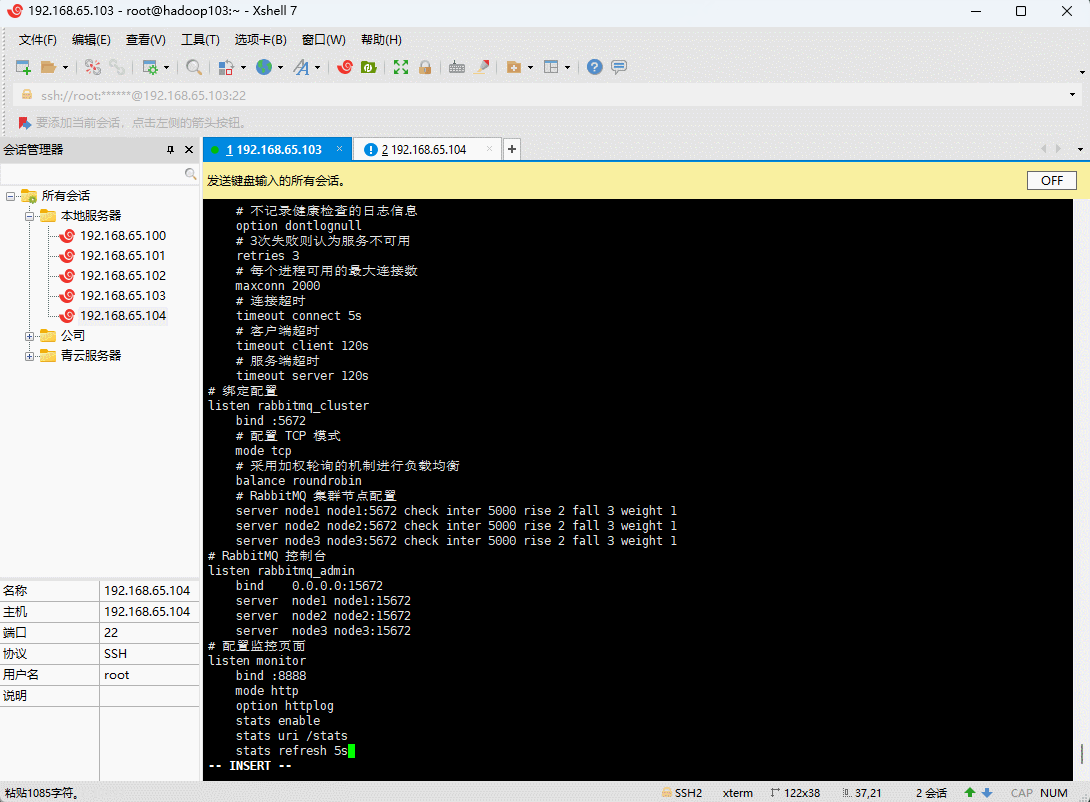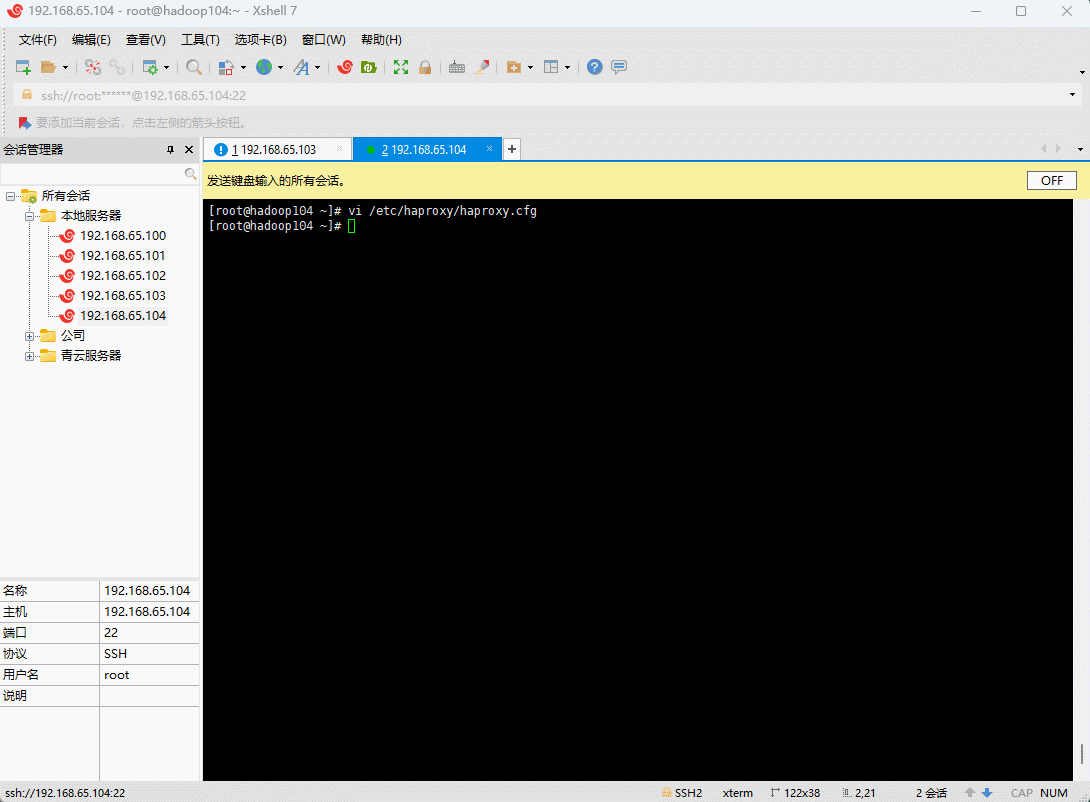
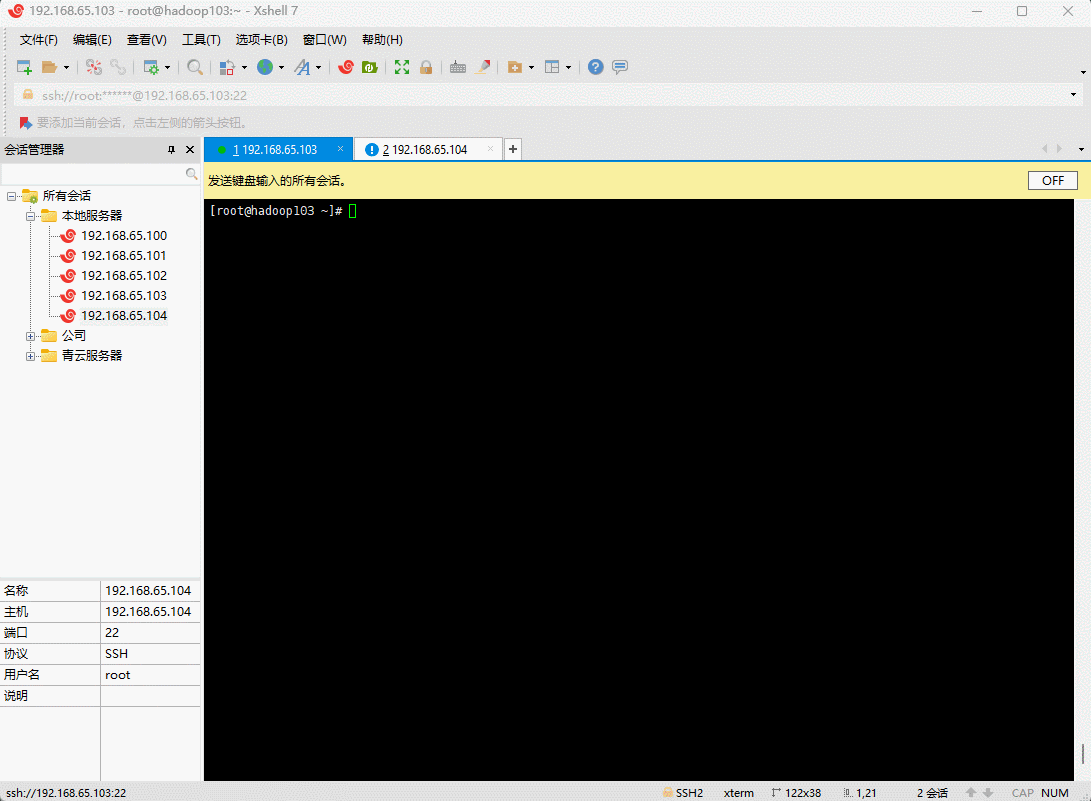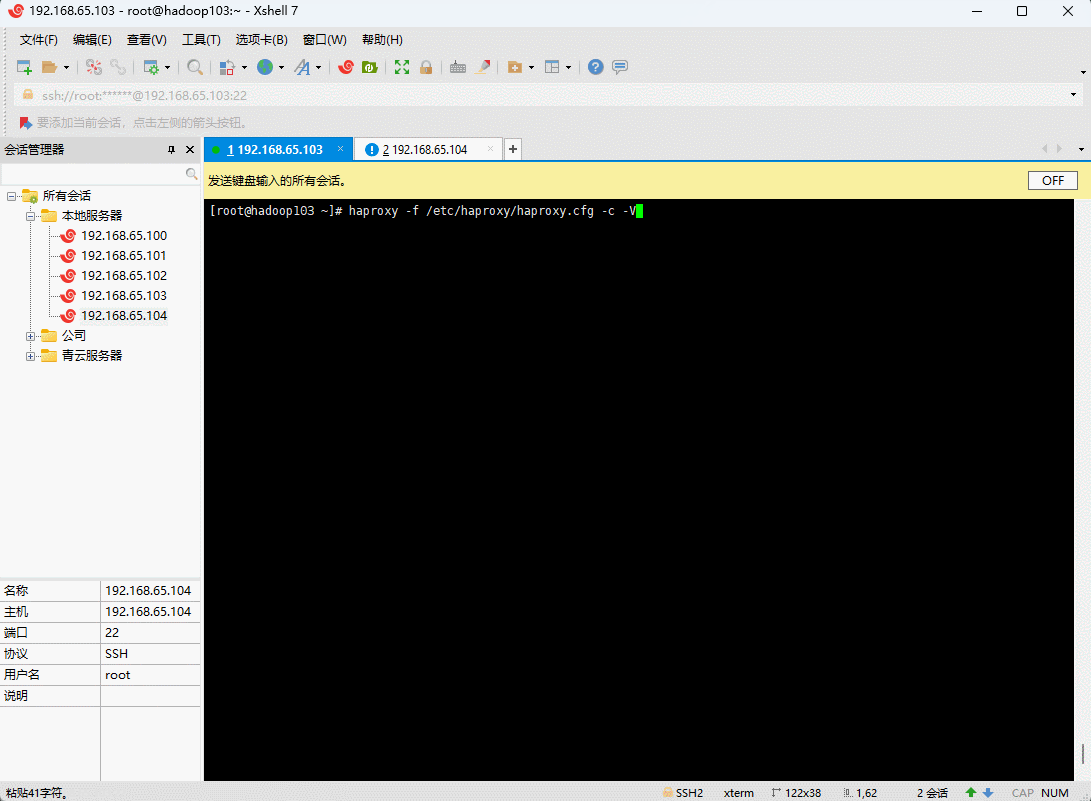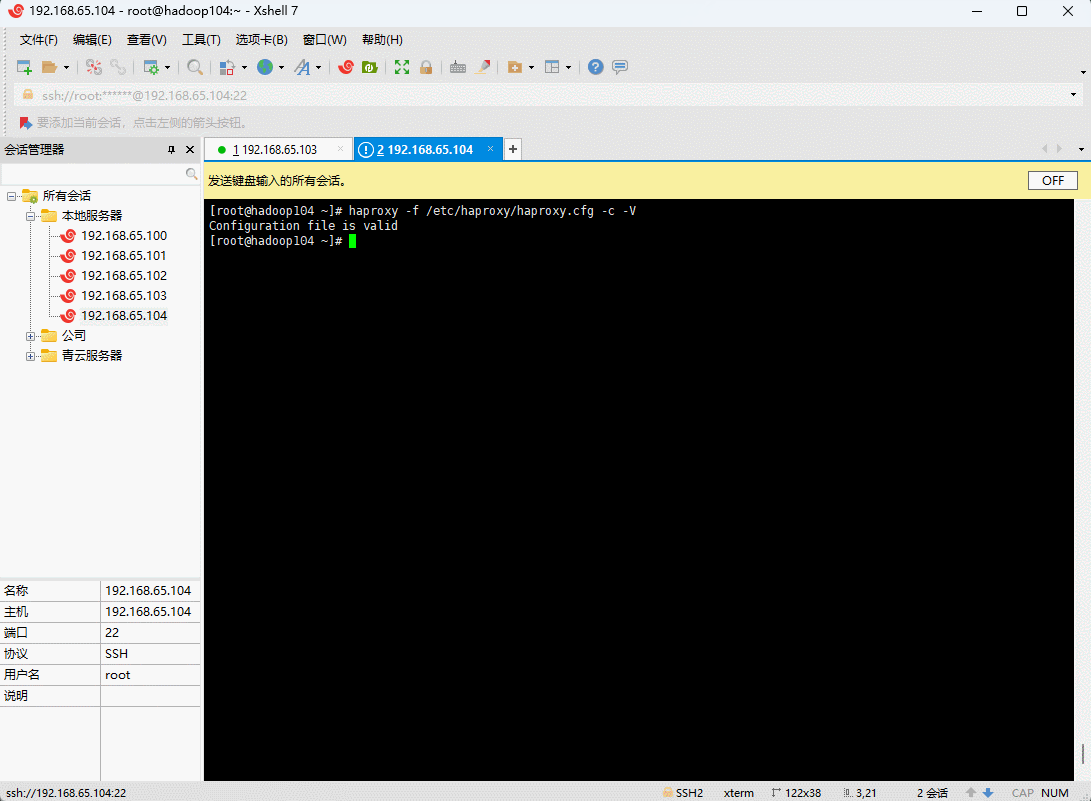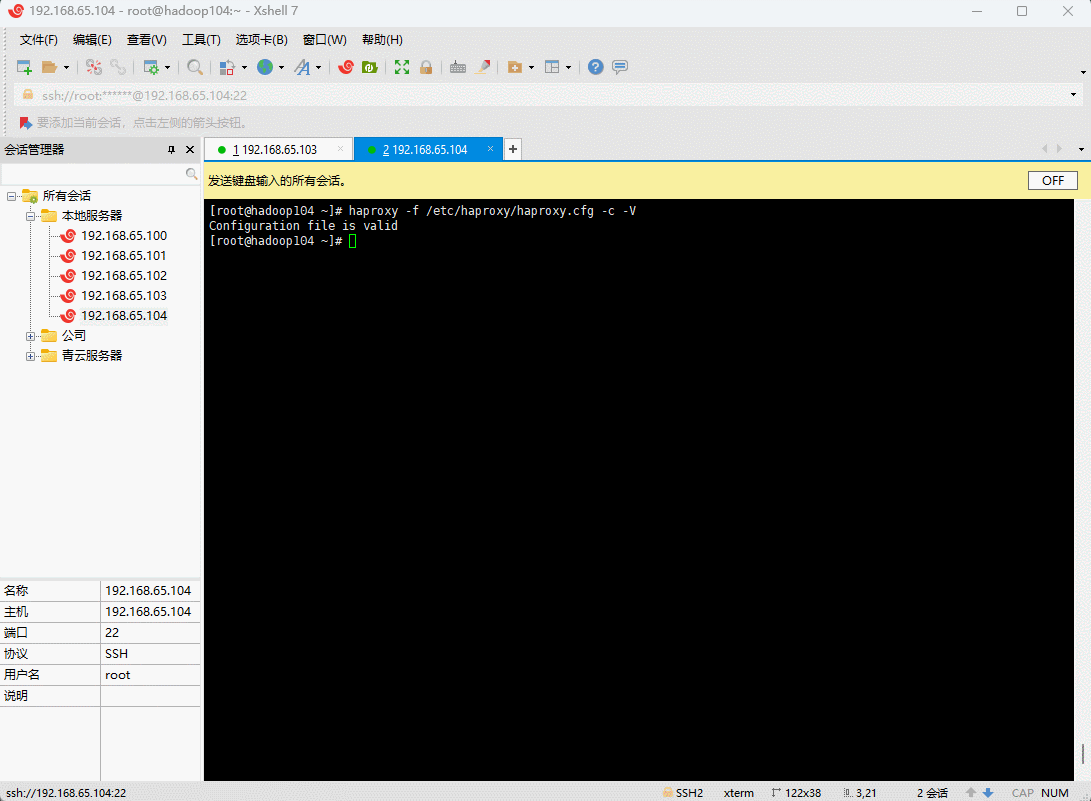
- 验证 haproxy 配置:
haproxy -f /etc/haproxy/haproxy.cfg -c -V
- 关闭 SELinux :
getenforce
sed -i 's/enforcing/disabled/' /etc/selinux/config
setenforce 0
- 运行 haproxy :
systemctl daemon-reload
systemctl start haproxy

- 访问地址:
http://192.168.65.103:8888/stats
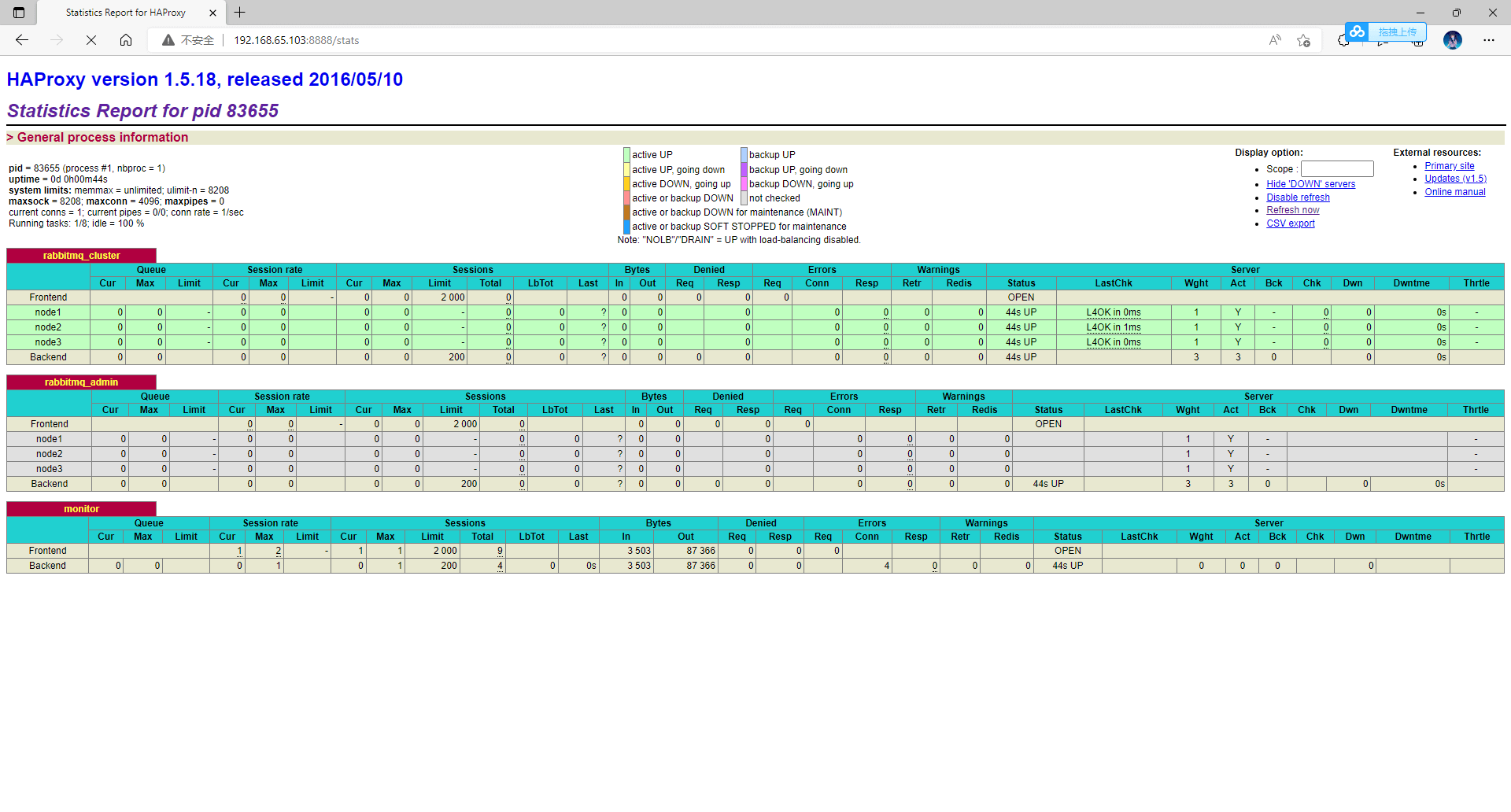
4.3 Keepalived 实现双机(主备)热备
4.3.1 概述
- 如果前面配置的 HAProxy 主机突然宕机或者网卡失效,那么虽然 RbbitMQ 集群没有任何故障,但是对于外界的客户端来说所有的连接都会被断开结果将是灾难性的。为了确保负载均衡服务的可靠性同样显得十分重要,这里就要引入 Keepalived 它能够通过自身健康检查、资源接管功能做高可用(双机热备),实现故障转移。
4.3.2 搭建步骤
- 下载 Keepalived(lb-master 和 lb-slave 机器执行):
yum -y install keepalived

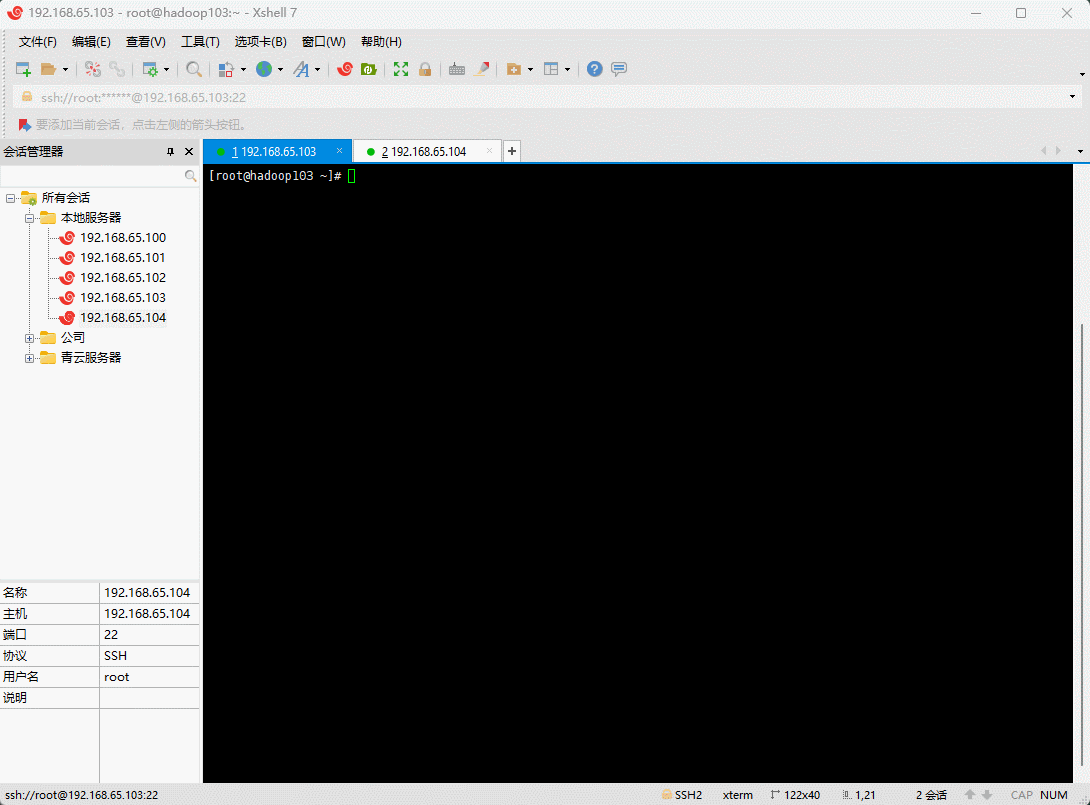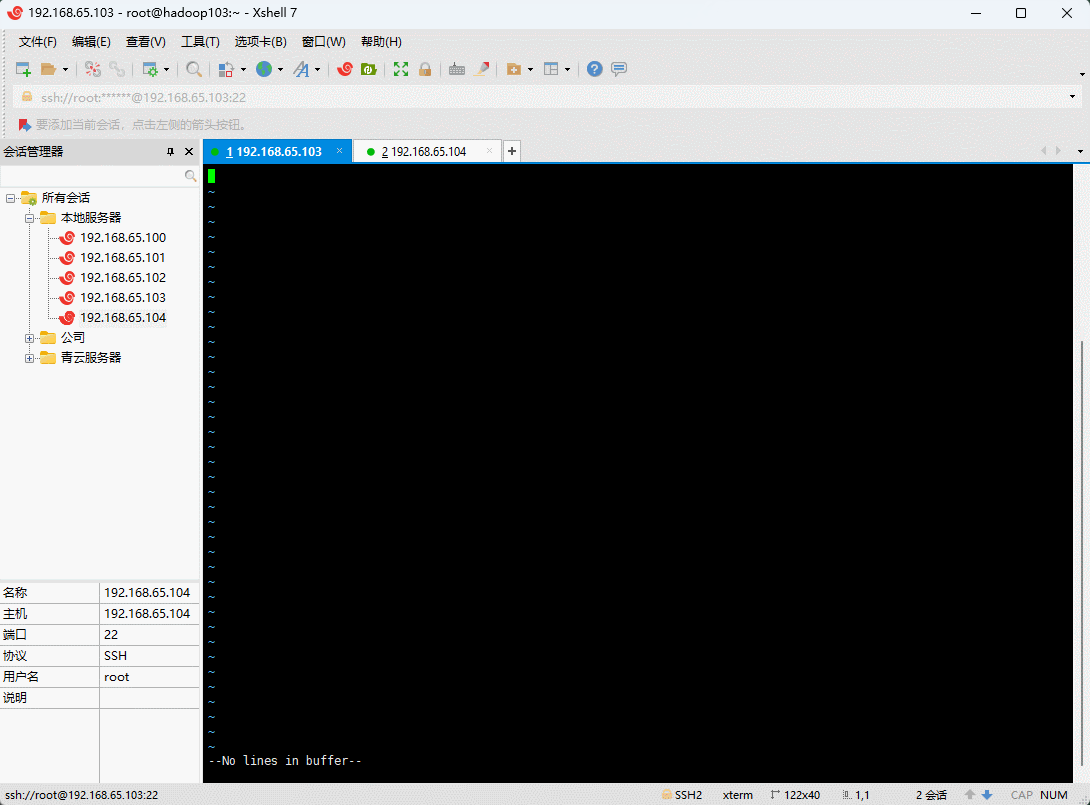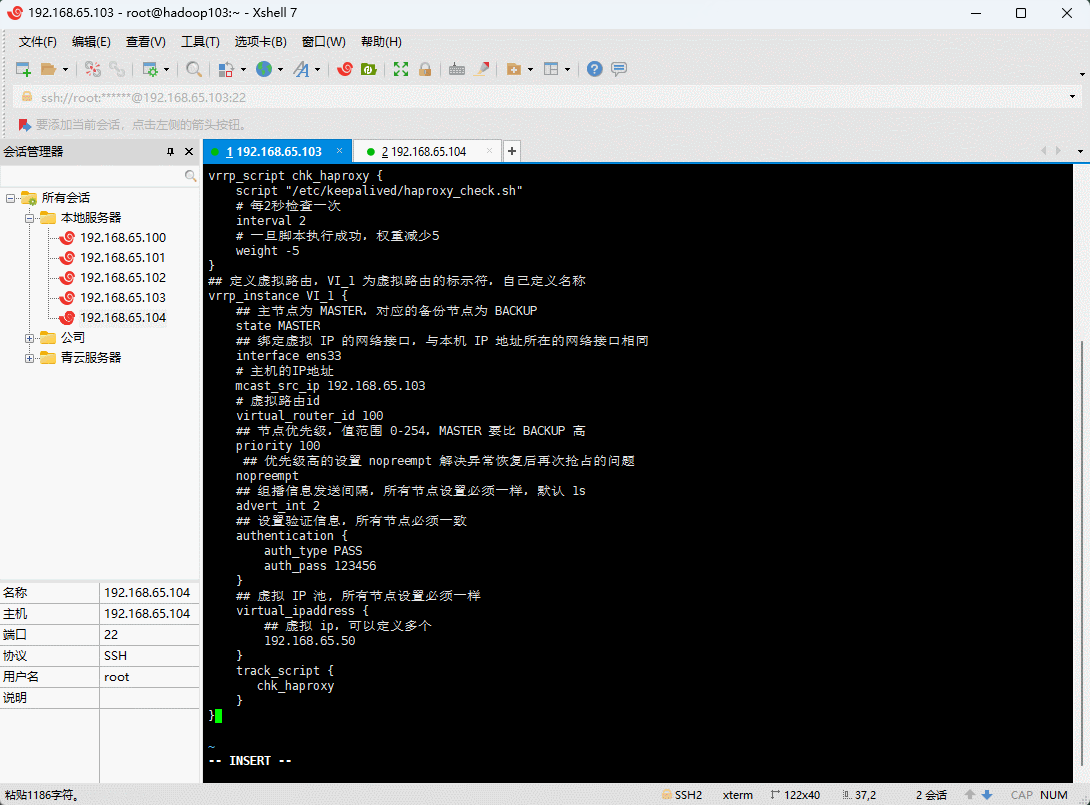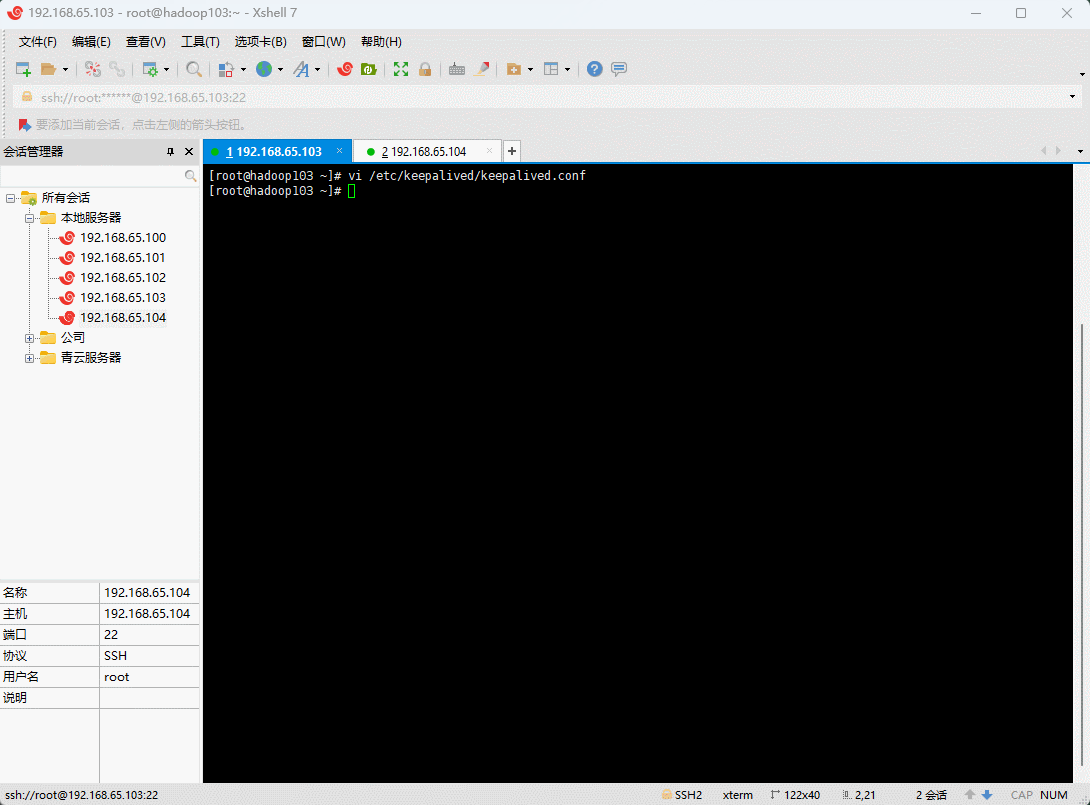
- 在 lb-master 节点的机器上修改 keepalived.conf 配置文件:
vi /etc/keepalived/keepalived.conf
! Configuration File for keepalivedglobal_defs {## 标识本节点的字条串,通常为 hostnamerouter_id lb-mastervrrp_skip_check_adv_addr# vrrp_strictvrrp_garp_interval 0vrrp_gna_interval 0}## 检测脚本## keepalived 会定时执行脚本并对脚本执行的结果进行分析,动态调整 vrrp_instance 的优先级。如果脚本执行结果为 0,并且 weight 配置的值大于 0,则优先级相应的增加。如果脚本执行结果非 0,并且 weight配置的值小于 0,则优先级相应的减少。其他情况,维持原本配置的优先级,即配置文件中 priority 对应的值。vrrp_script chk_haproxy {script "/etc/keepalived/haproxy_check.sh"# 每2秒检查一次interval 2# 一旦脚本执行成功,权重减少20weight -20}## 定义虚拟路由,VI_1 为虚拟路由的标示符,自己定义名称vrrp_instance VI_1 {## 主节点为 MASTER,对应的备份节点为 BACKUPstate MASTER## 绑定虚拟 IP 的网络接口,与本机 IP 地址所在的网络接口相同interface ens33# 主机的IP地址mcast_src_ip 192.168.65.103# 虚拟路由id ,必须和备机一致virtual_router_id 100## 节点优先级,值范围 0-254,MASTER 要比 BACKUP 高priority 100## 优先级高的设置 nopreempt 解决异常恢复后再次抢占的问题nopreempt## 组播信息发送间隔,所有节点设置必须一样,默认 1sadvert_int 1## 设置验证信息,所有节点必须一致authentication {auth_type PASSauth_pass 123456}## 虚拟 IP 池, 所有节点设置必须一样virtual_ipaddress {## 虚拟 ip,可以定义多个192.168.65.222}track_script {chk_haproxy}}
- 在 lb-slave 节点的机器上修改 keepalived.conf 配置文件:
vi /etc/keepalived/keepalived.conf
! Configuration File for keepalivedglobal_defs {router_id lb-slavevrrp_skip_check_adv_addr# vrrp_strictvrrp_garp_interval 0vrrp_gna_interval 0}vrrp_script chk_haproxy {script "/etc/keepalived/haproxy_check.sh"interval 2weight -20}vrrp_instance VI_1 {state BACKUPinterface ens33mcast_src_ip 192.168.65.104virtual_router_id 100priority 50advert_int 1authentication {auth_type PASSauth_pass 123456}virtual_ipaddress {192.168.65.222}track_script {chk_haproxy}}
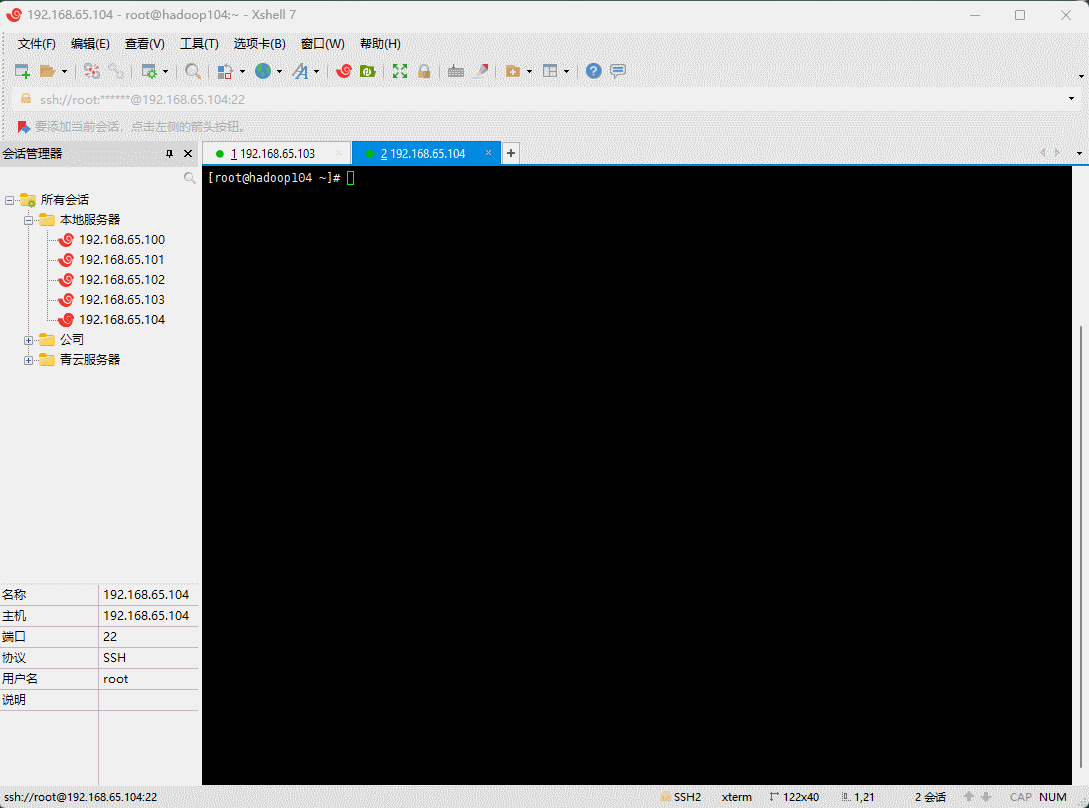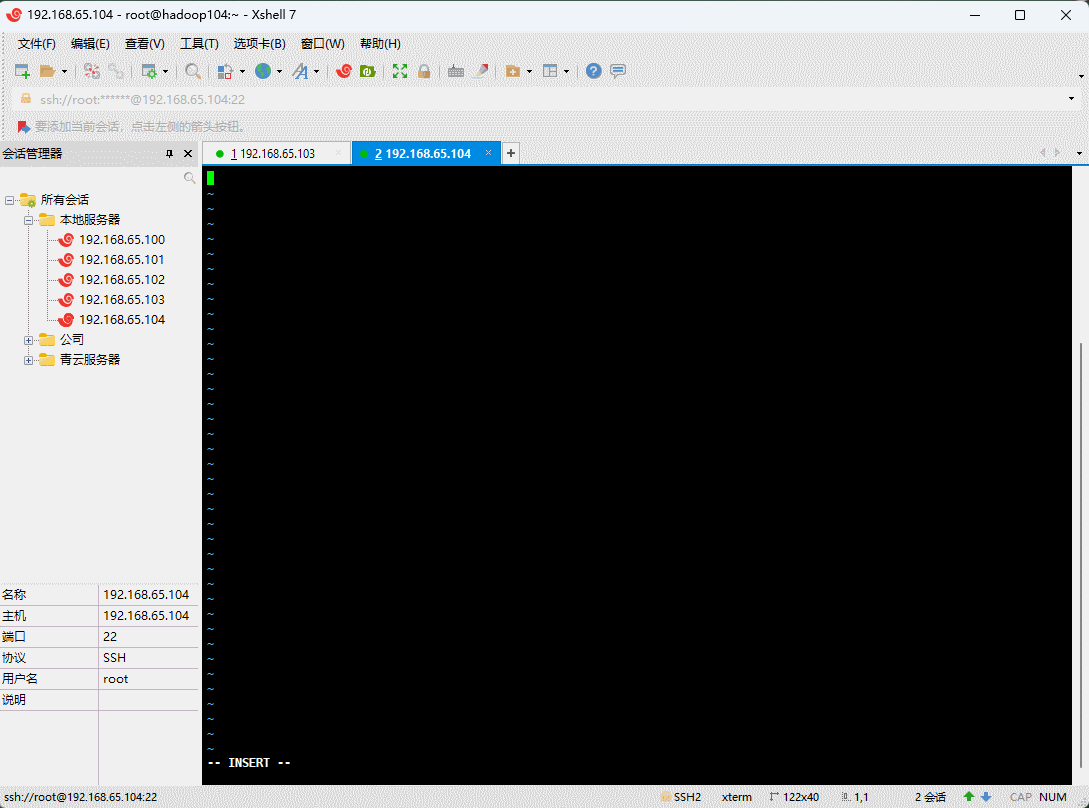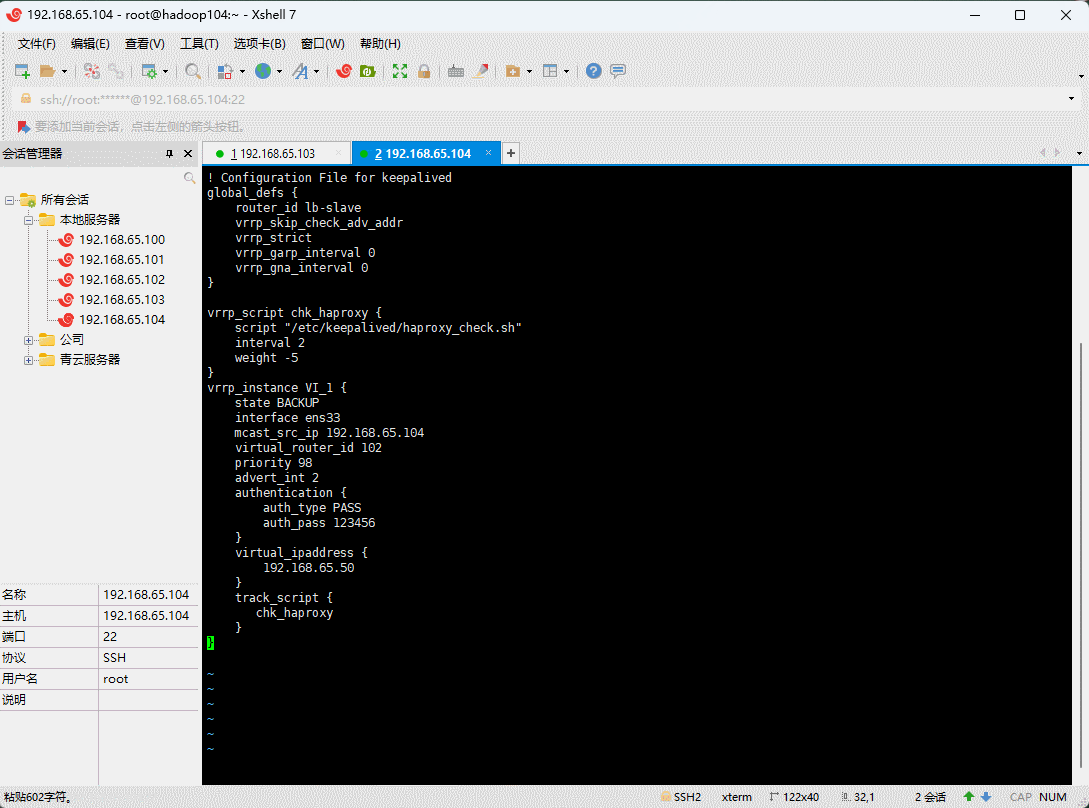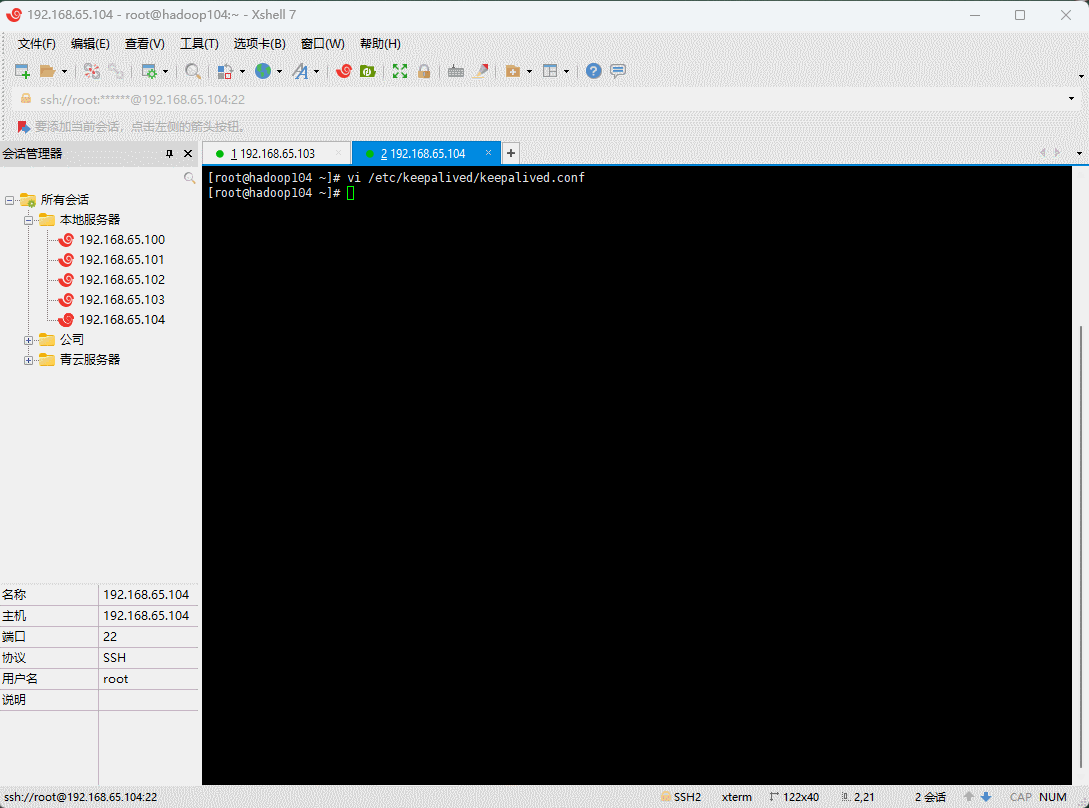
- 创建检测脚本文件(lb-master 和 lb-slave 机器执行):
vi /etc/keepalived/haproxy_check.sh
#!/bin/bashCOUNT=`ps -C haproxy --no-header |wc -l`if [ $COUNT -eq 0 ];thensystemctl start haproxysleep 2if [ `ps -C haproxy --no-header |wc -l` -eq 0 ];thensystemctl stop keepalivedfifi
- 修改健康检测脚本执行权限(lb-master 和 lb-slave 机器执行):
chmod +x /etc/keepalived/haproxy_check.sh
- 启动 keepalived(lb-master 和 lb-slave 机器执行):
systemctl daemon-reload
systemctl enable --now haproxy
systemctl enable --now keepalived
- 测试:
arp -n
ping -c 4 192.168.65.222
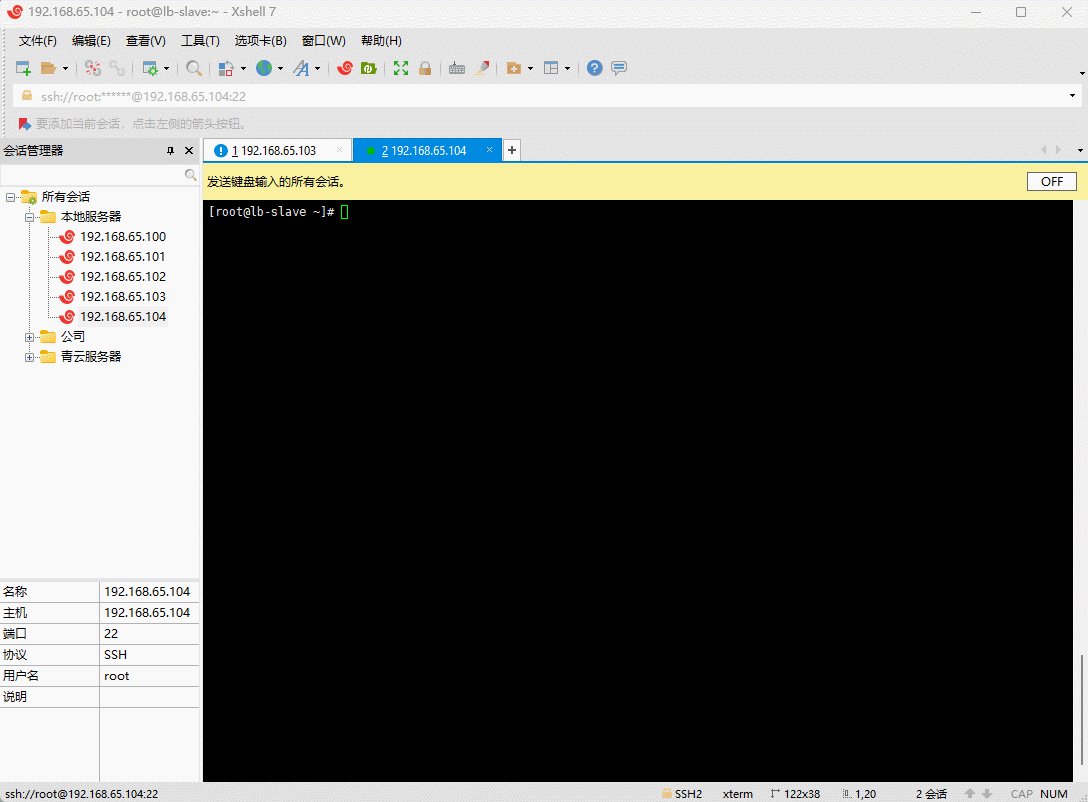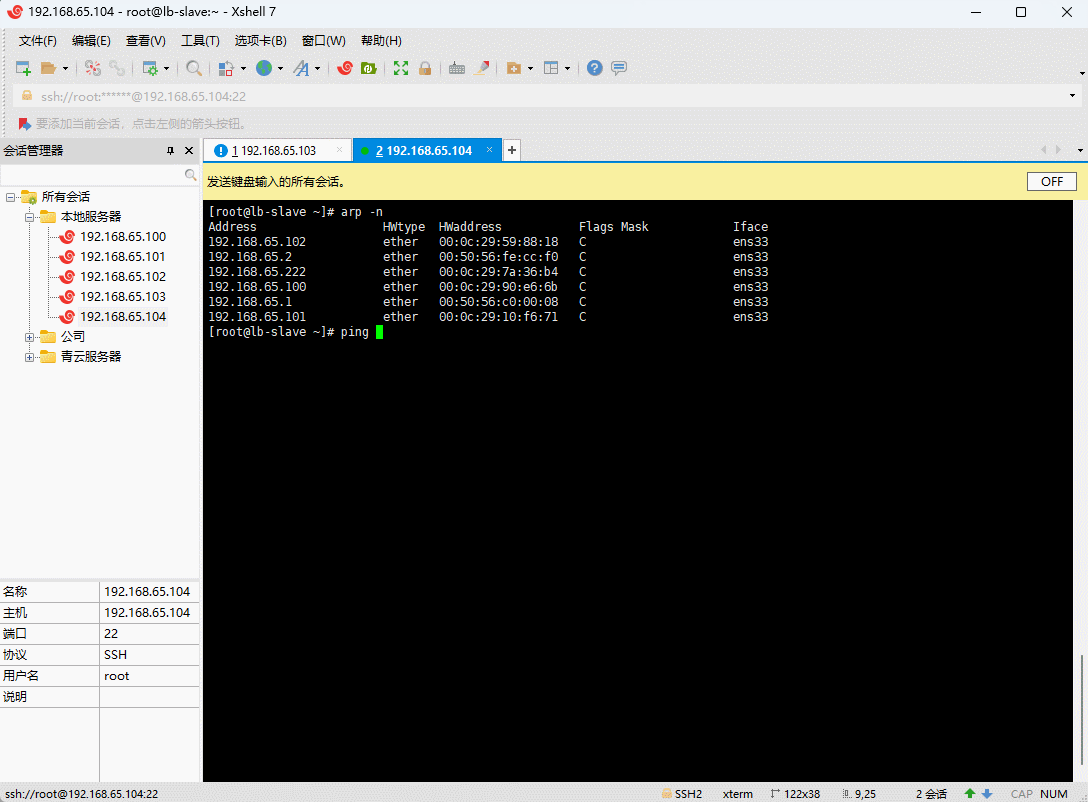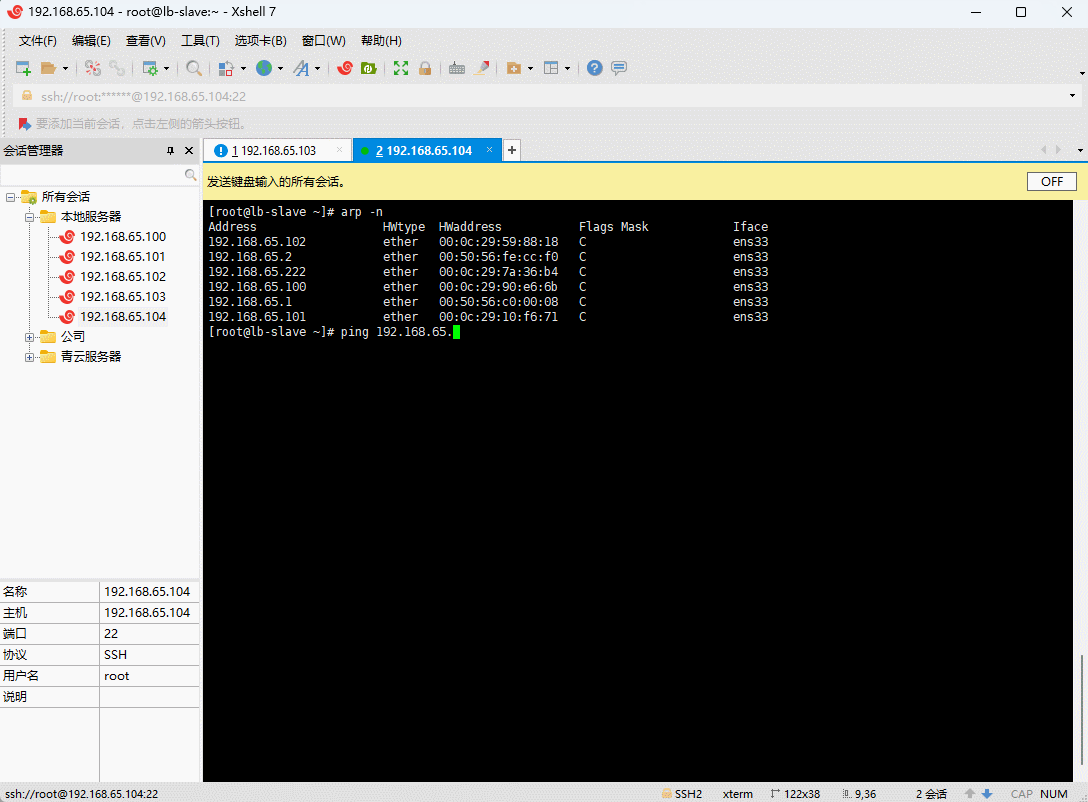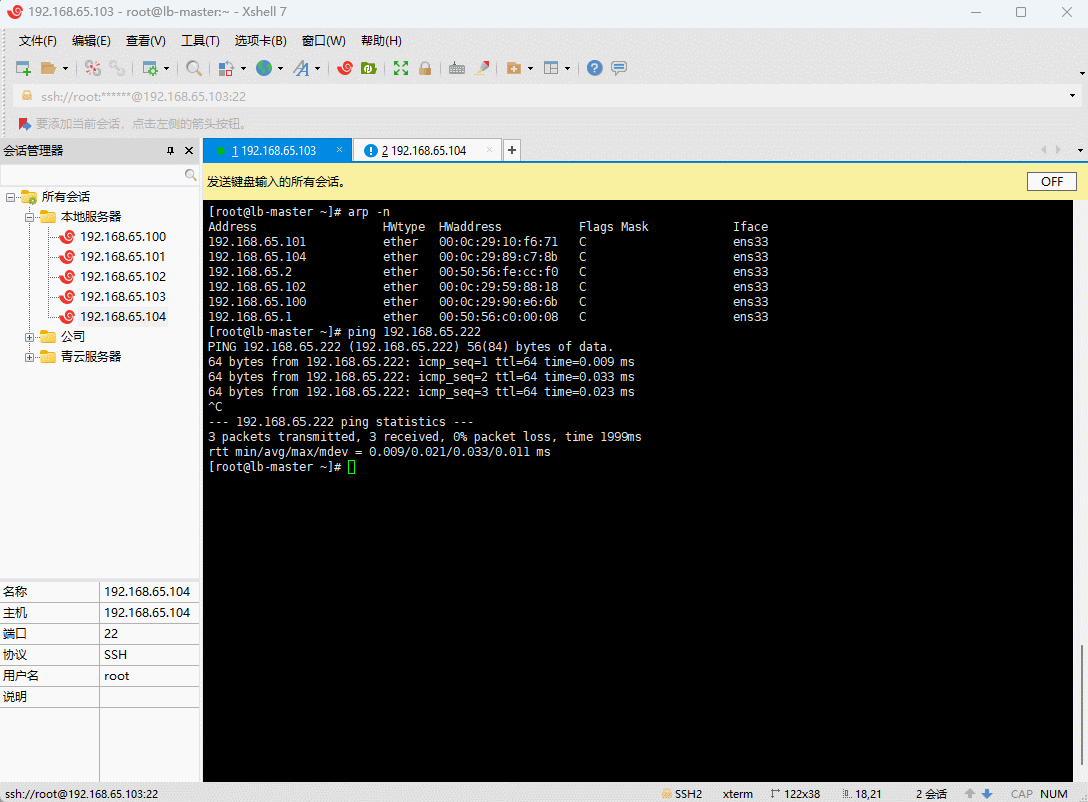
- 模拟 keepalived 宕机(lb-master 执行):
systemctl stop keepalived
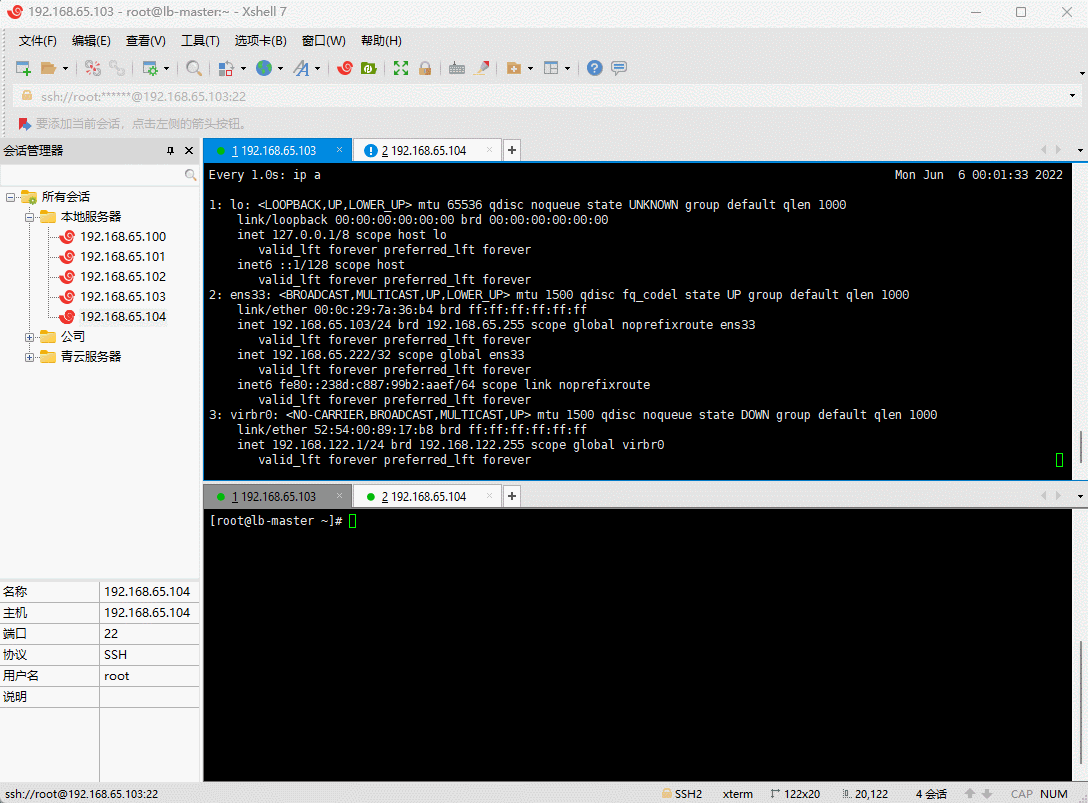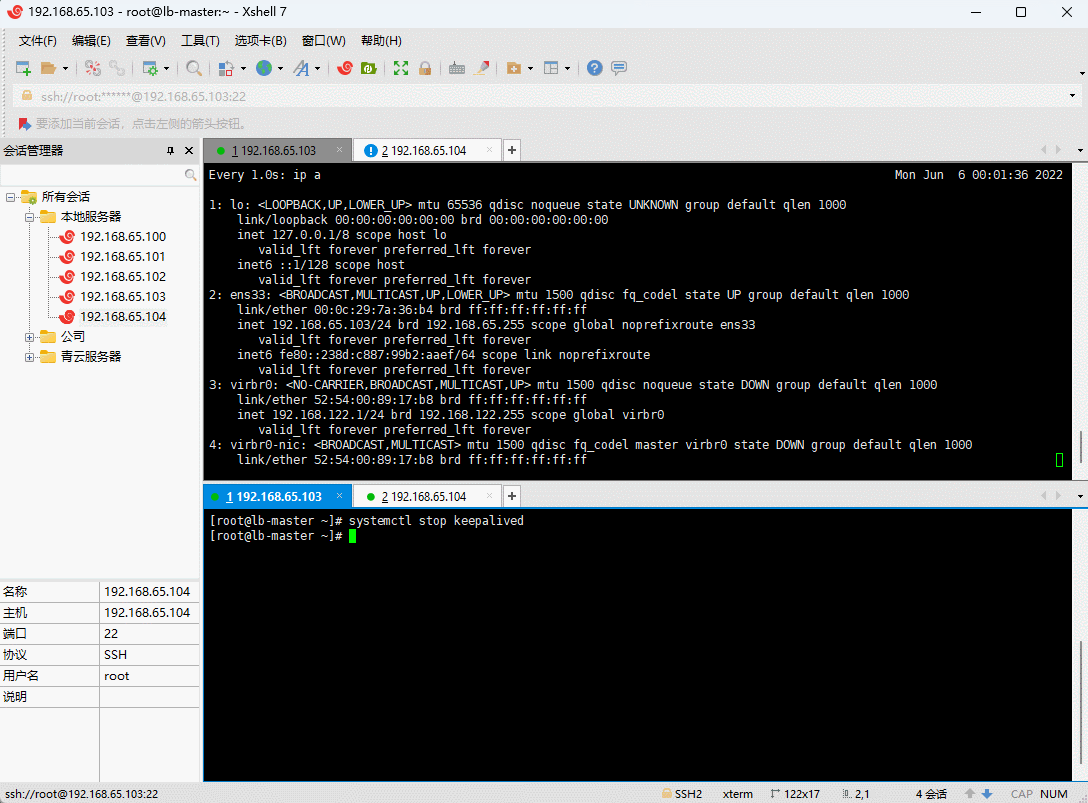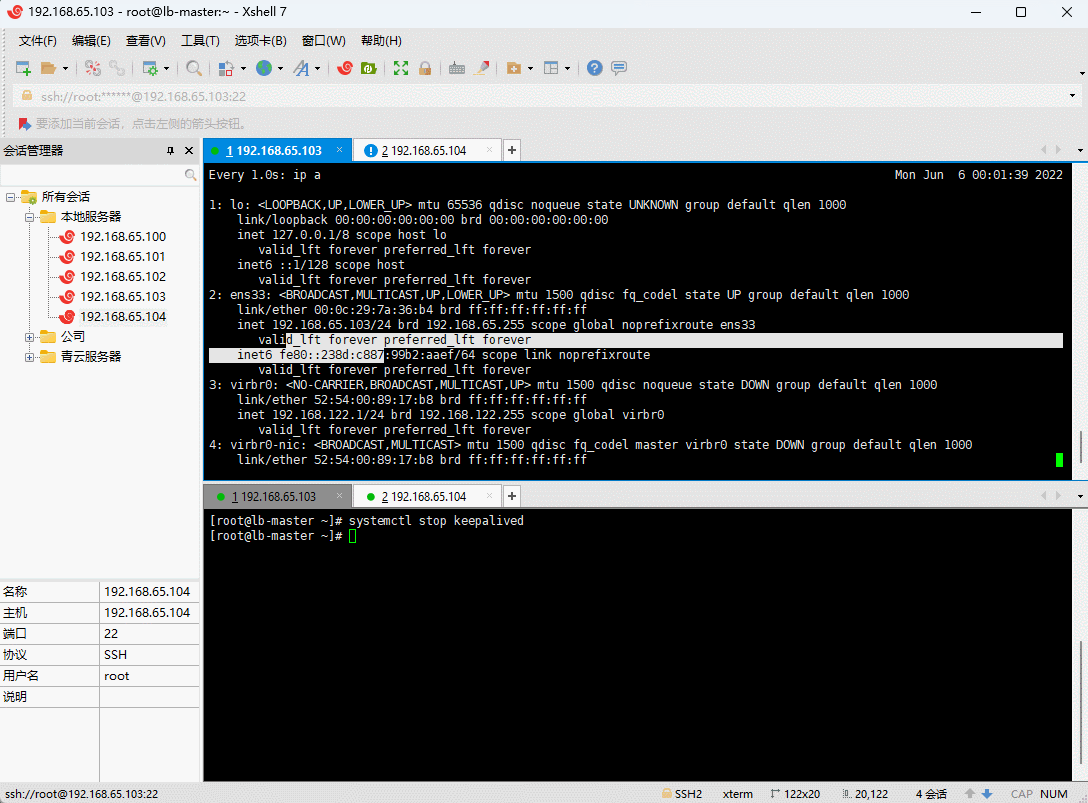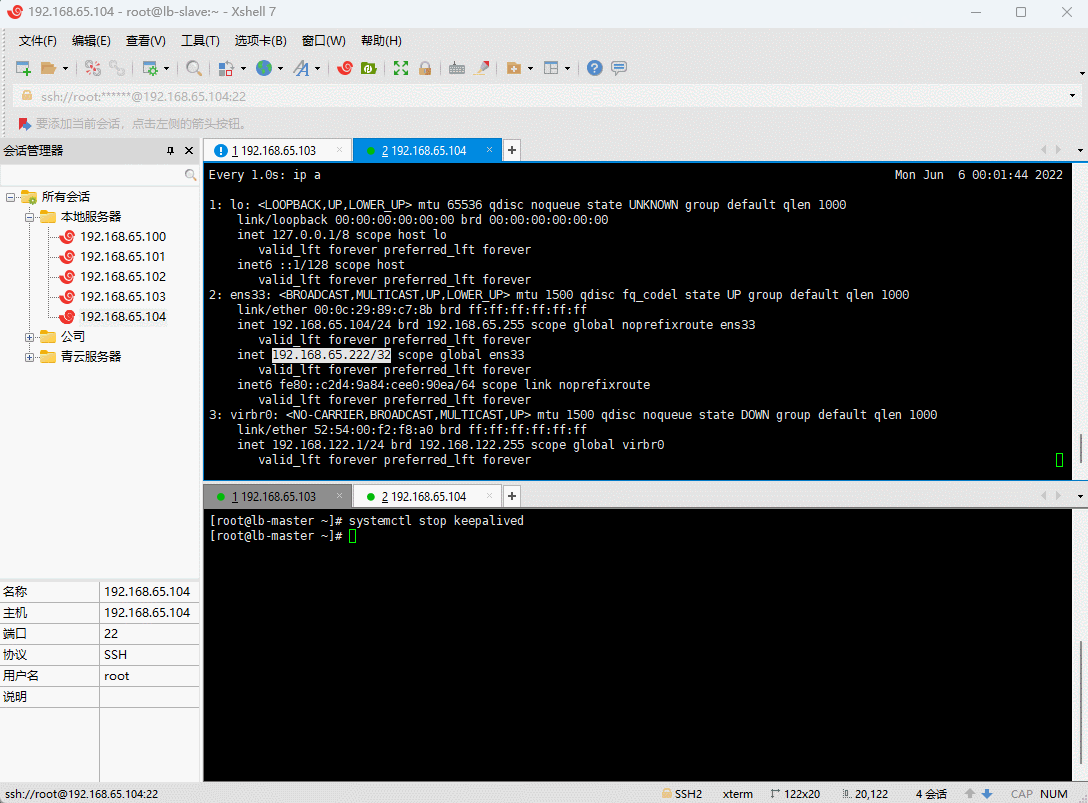
注意:Haprox + Keepalive 解决了RabbitMQ 集群的高可用。
4.4 总结
- RabbitMQ 集群 + 镜像队列+ Haproxy + Keepalived 可以解决 RabbitMQ 的
可扩展、数据冗余和高可用。

若有收获,就点个赞吧
0 人点赞
