第一章:ResourceQuotas(资源配额)
1.1 简介
- 当多个用户或团队共享具有固定节点数目的集群时,人们会担心
有人使用超过其基于公平原则所分配到的资源量。
资源配额是帮助管理员解决这一问题的工具。 - 资源配额,通过
ResourceQuota对象来定义,对每个命名空间的资源消耗总量提供限制。 它可以限制命名空间中某种类型的对象的总数目上限,也可以限制命令空间中的 Pod 可以使用的计算资源的总上限。 - 资源配额的工作方式如下:
- 不同的团队可以在不同的命名空间下工作,目前这是非约束性的,在未来的版本中可能会通过 ACL (Access Control List 访问控制列表) 来实现强制性约束。
集群管理员可以为每个命名空间创建一个或多个 ResourceQuota 对象。- 当用户在命名空间下创建资源(如 Pod、Service 等)时,Kubernetes 的配额系统会跟踪集群的资源使用情况,
以确保使用的资源用量不超过 ResourceQuota 中定义的硬性资源限额。 - 如果资源创建或者更新请求违反了配额约束,那么该请求会报错(HTTP 403 FORBIDDEN), 并在消息中给出有可能违反的约束。
- 如果命名空间下的计算资源 (如
cpu和memory)的配额被启用,则用户必须为 这些资源设定请求值(request)和约束值(limit),否则配额系统将拒绝 Pod 的创建。 提示: 可使用LimitRanger准入控制器来为没有设置计算资源需求的 Pod 设置默认值。
1.2 计算资源配额
- 用户可以对给定命名空间下的可被请求的 计算资源 总量进行限制。
| 资源名称 | 描述 |
| —- | —- |
|
limits.cpu| 所有非终止状态的 Pod,其 CPU 限额总量不能超过该值。 | |limits.memory| 所有非终止状态的 Pod,其内存限额总量不能超过该值。 | |requests.cpu| 所有非终止状态的 Pod,其 CPU 需求总量不能超过该值。 | |requests.memory| 所有非终止状态的 Pod,其内存需求总量不能超过该值。 | |hugepages-<size>| 对于所有非终止状态的 Pod,针对指定尺寸的巨页请求总数不能超过此值。 | |cpu| 与requests.cpu
相同。 | |memory| 与requests.memory
相同。 |
- 示例:
apiVersion: v1kind: ResourceQuotametadata:name: mem-cpunamespace: default # 限制 default 名称空间spec:hard:requests.cpu: "1"requests.memory: 1Gilimits.cpu: "2"limits.memory: 2Gi
1.3 扩展资源的资源配额
- 除上述资源外,在 Kubernetes 1.10 版本中,还添加了对 扩展资源 的支持。
- 由于扩展资源不可超量分配,因此没有必要在配额中为同一扩展资源同时指定
requests和limits。 对于扩展资源而言,目前仅允许使用前缀为requests.的配额项。 - 以 GPU 拓展资源为例,如果资源名称为
nvidia.com/gpu,并且要将命名空间中请求的 GPU 资源总数限制为 4,则可以如下定义配额:
requests.nvidia.com/gpu: 4
- 有关更多详细信息,请参阅查看和设置配额。
1.4 存储资源配额
- 用户可以对给定命名空间下的 存储资源 总量进行限制。
- 此外,还可以根据相关的存储类(Storage Class)来限制存储资源的消耗。
| 资源名称 | 描述 |
| —- | —- |
|
requests.storage| 所有 PVC,存储资源的需求总量不能超过该值。 | |persistentvolumeclaims| 在该命名空间中所允许的 PVC
总量。 | |<storage-class-name>.storageclass.storage.k8s.io/requests.storage| 在所有与<storage-class-name>
相关的持久卷申领中,存储请求的总和不能超过该值。 | |<storage-class-name>.storageclass.storage.k8s.io/persistentvolumeclaims| 在与 storage-class-name 相关的所有持久卷申领中,命名空间中可以存在的持久卷申领
总数。 |
- 例如,如果一个操作人员针对
gold存储类型与bronze存储类型设置配额, 操作人员可以定义如下配额:gold.storageclass.storage.k8s.io/requests.storage: 500Gibronze.storageclass.storage.k8s.io/requests.storage: 100Gi
- 在 Kubernetes 1.8 版本中,本地临时存储的配额支持已经是 Alpha 功能:
| 资源名称 | 描述 |
| —- | —- |
|
requests.ephemeral-storage| 在命名空间的所有 Pod 中,本地临时存储请求的总和不能超过此值。 | |limits.ephemeral-storage| 在命名空间的所有 Pod 中,本地临时存储限制值的总和不能超过此值。 | |ephemeral-storage| 与requests.ephemeral-storage
相同。 |
注意:如果所使用的是 CRI 容器运行时,容器日志会被计入临时存储配额。 这可能会导致存储配额耗尽的 Pods 被意外地驱逐出节点。 参考日志架构 了解详细信息。
1.5 对象数量配额
- 你可以使用以下语法对所有标准的、命名空间域的资源类型进行配额设置:
count/<resource>.<group>:用于非核心(core)组的资源。count/<resource>:用于核心组的资源。
- 这是用户可能希望利用对象计数配额来管理的一组资源示例。
count/persistentvolumeclaimscount/servicescount/secretscount/configmapscount/replicationcontrollerscount/deployments.appscount/replicasets.appscount/statefulsets.appscount/jobs.batchcount/cronjobs.batch
- 相同语法也可用于自定义资源。 例如,要对
example.comAPI 组中的自定义资源widgets设置配额,请使用count/widgets.example.com。 - 当使用
count/*资源配额时,如果对象存在于服务器存储中,则会根据配额管理资源。 这些类型的配额有助于防止存储资源耗尽。例如,用户可能想根据服务器的存储能力来对服务器中 Secret 的数量进行配额限制。 集群中存在过多的 Secret 实际上会导致服务器和控制器无法启动。 用户可以选择对 Job 进行配额管理,以防止配置不当的 CronJob 在某命名空间中创建太多 Job 而导致集群拒绝服务。 - 对有限的一组资源上实施一般性的对象数量配额也是可能的。 此外,还可以进一步按资源的类型设置其配额。
| 资源名称 | 描述 |
| —- | —- |
|
configmaps| 在该命名空间中允许存在的 ConfigMap 总数上限。 | |persistentvolumeclaims| 在该命名空间中允许存在的 PVC
的总数上限。 | |pods| 在该命名空间中允许存在的非终止状态的 Pod 总数上限。Pod 终止状态等价于 Pod 的.status.phase in (Failed, Succeeded)
为真。 | |replicationcontrollers| 在该命名空间中允许存在的 ReplicationController 总数上限。 | |resourcequotas| 在该命名空间中允许存在的 ResourceQuota 总数上限。 | |services| 在该命名空间中允许存在的 Service 总数上限。 | |services.loadbalancers| 在该命名空间中允许存在的 LoadBalancer 类型的 Service 总数上限。 | |services.nodeports| 在该命名空间中允许存在的 NodePort 类型的 Service 总数上限。 | |secrets| 在该命名空间中允许存在的 Secret 总数上限。 |
例如,
pods配额统计某个命名空间中所创建的、非终止状态的Pod个数并确保其不超过某上限值。 用户可能希望在某命名空间中设置pods配额,以避免有用户创建很多小的 Pod, 从而耗尽集群所能提供的 Pod IP 地址。示例:
apiVersion: v1kind: ResourceQuotametadata:name: pods-rqnamespace: default # 限制 default 名称空间spec:hard:pods: "3" # 限制 Pod 的数量
1.6 基于优先级类(PriorityClass)来设置资源配额
- Pod 可以创建为特定的优先级。 通过使用配额规约中的
scopeSelector字段,用户可以根据 Pod 的优先级控制其系统资源消耗。 - 仅当配额规范中的
scopeSelector字段选择到某 Pod 时,配额机制才会匹配和计量 Pod 的资源消耗。 如果配额对象通过
scopeSelector字段设置其作用域为优先级类,则配额对象只能 跟踪以下资源:podscpumemoryephemeral-storagelimits.cpulimits.memorylimits.ephemeral-storagerequests.cpurequests.memoryrequests.ephemeral-storage
示例:创建一个配额对象,并将其与具有特定优先级的 Pod 进行匹配
# 集群中的 Pod 可取三个优先级类之一,即 "low"、"medium"、"high"# 为每个优先级创建一个配额对象apiVersion: v1kind: Listitems:- apiVersion: v1kind: ResourceQuotametadata:name: pods-highspec:hard:cpu: "1000"memory: 200Gipods: "10"scopeSelector:matchExpressions:- operator : InscopeName: PriorityClassvalues: ["high"]- apiVersion: v1kind: ResourceQuotametadata:name: pods-mediumspec:hard:cpu: "10"memory: 20Gipods: "10"scopeSelector:matchExpressions:- operator : InscopeName: PriorityClassvalues: ["medium"]- apiVersion: v1kind: ResourceQuotametadata:name: pods-lowspec:hard:cpu: "5"memory: 10Gipods: "10"scopeSelector:matchExpressions:- operator : InscopeName: PriorityClassvalues: ["low"]
apiVersion: v1kind: Podmetadata:name: high-priorityspec:containers:- name: high-priorityimage: ubuntucommand: ["/bin/sh"]args: ["-c", "while true; do echo hello; sleep 10;done"]resources:requests:memory: "10Gi"cpu: "500m"limits:memory: "10Gi"cpu: "500m"priorityClassName: high # priorityClassName 指的是什么,就优先使用这个优先级的配额约束。
第二章:LimitRange(限制范围)
2.1 简介
- 默认情况下, Kubernetes 集群上的容器运行使用的计算资源没有限制。
- 使用资源配额,集群管理员可以以名字空间为单位,限制其资源的使用与创建。
- 在命名空间中,一个 Pod 或 Container 最多能够使用命名空间的资源配额所定义的 CPU 和内存用量。
- 有人担心,一个 Pod 或 Container 会垄断所有可用的资源。 LimitRange 是在命名空间内限制资源分配(给多个 Pod 或 Container)的策略对象,例如:资源额度 ResourceQuotas 设置为 requests.cpu 为 1 ,requests.memory 为 1Gi ,但是有人的 Pod 直接设置为 requests.cpu 为 1,requests.memory 为 1Gi,那么其他人就不能再创建 Pod 了,所以需要使用 LimitRange 对资源配额设置区间(最小和最大)。
- 一个 LimitRange(限制范围) 对象提供的限制能够做到:
- 在一个命名空间中实施对每个 Pod 或 Container 最小和最大的资源使用量的限制。
- 在一个命名空间中实施对每个 PersistentVolumeClaim 能申请的最小和最大的存储空间大小的限制。
- 在一个命名空间中实施对一种资源的申请值和限制值的比值的控制。
- 设置一个命名空间中对计算资源的默认申请/限制值,并且自动的在运行时注入到多个 Container 中。
2.2 实战
- 示例:为命名空间配置 CPU 最小和最大约束
apiVersion: v1kind: LimitRangemetadata:name: cpu-min-max-demo-lrnamespace: default # 限制 default 命名空间spec:limits:- max:cpu: "800m"min:cpu: "200m" # Pod 中的容器的 cpu 的范围是 200m~800mtype: Container
- 示例:配置命名空间的最小和最大内存约束
apiVersion: v1kind: LimitRangemetadata:name: mem-min-max-demo-lrnamespace: default # 限制 default 命名空间spec:limits:- max:memory: 1Gimin:memory: 500Mi # Pod 中的容器的 memory 的范围是 500Mi~1Gitype: Container
- 示例:为命名空间配置默认的 CPU 请求和限制
apiVersion: v1kind: LimitRangemetadata:name: cpu-limit-rangenamespace: default # 限制 default 命名空间spec:limits:- default:cpu: 1defaultRequest:cpu: 500m # 声明了一个默认的 CPU 请求和一个默认的 CPU 限制type: Container
- 示例:为命名空间配置默认的内存请求和限制
apiVersion: v1kind: LimitRangemetadata:name: mem-limit-rangenamespace: default # 限制 default 命名空间spec:limits:- default:memory: 512MidefaultRequest:memory: 256Mi # 为命名空间配置默认的内存请求和限制type: Container
- 示例:限制存储消耗
apiVersion: v1kind: LimitRangemetadata:name: storagelimitsspec:limits:- type: PersistentVolumeClaimmax:storage: 2Gimin:storage: 1Gi
apiVersion: v1kind: ResourceQuotametadata:name: storagequotaspec:hard:persistentvolumeclaims: "5" # 限制 PVC 数目和累计存储容量requests.storage: "5Gi"
第三章:调度原理
3.1 概述
- 在默认情况下,一个 Pod 在哪个 Node 节点上运行,是由 Scheduler 组件采用相应的算法计算出来的,这个过程是不受人工控制的。但是在实际使用中,这并不满足需求,因为很多情况下,我们想控制某些 Pod 到达某些节点上,那么应该怎么做?这就要求了解 Kubernetes 对 Pod 的调度规则,Kubernetes 提供了四大类调度方式:
- 自动调度(默认):运行在哪个 Node 节点上完全由 Scheduler 经过一系列的算法计算得出。
- 定向调度:NodeName、NodeSelector。
- 亲和性调度:NodeAffinity、PodAffinity、PodAntiAffinity。
- 污点(容忍)调度:Taints、Toleration。
3.2 定向调度
3.2.1 概述
- 定向调度,指的是利用在 Pod 上声明的 nodeName 或 nodeSelector ,以此将 Pod 调度到期望的 Node 节点上。
注意:这里的调度是强制的,这就意味着即使要调度的目标 Node 不存在,也会向上面进行调度,只不过 Pod 运行失败而已。
3.2.2 nodeName(不建议)
nodeName是节点选择约束的最简单方法,但是由于其自身限制,通常不使用它。nodeName是 PodSpec 的一个字段。 如果它不为空,调度器将忽略 Pod,并且给定节点上运行的 kubelet 进程尝试执行该 Pod。 因此,如果nodeName在 Pod 的 Spec 中指定了,则它优先于 nodeSelector 。使用
nodeName来选择节点的一些限制:- 如果指定的节点不存在,
- 如果指定的节点没有资源来容纳 Pod,Pod 将会调度失败并且其原因将显示为, 比如 OutOfmemory 或 OutOfcpu。
- 云环境中的节点名称并非总是可预测或稳定的。
示例:
vi k8s-node-name.yaml
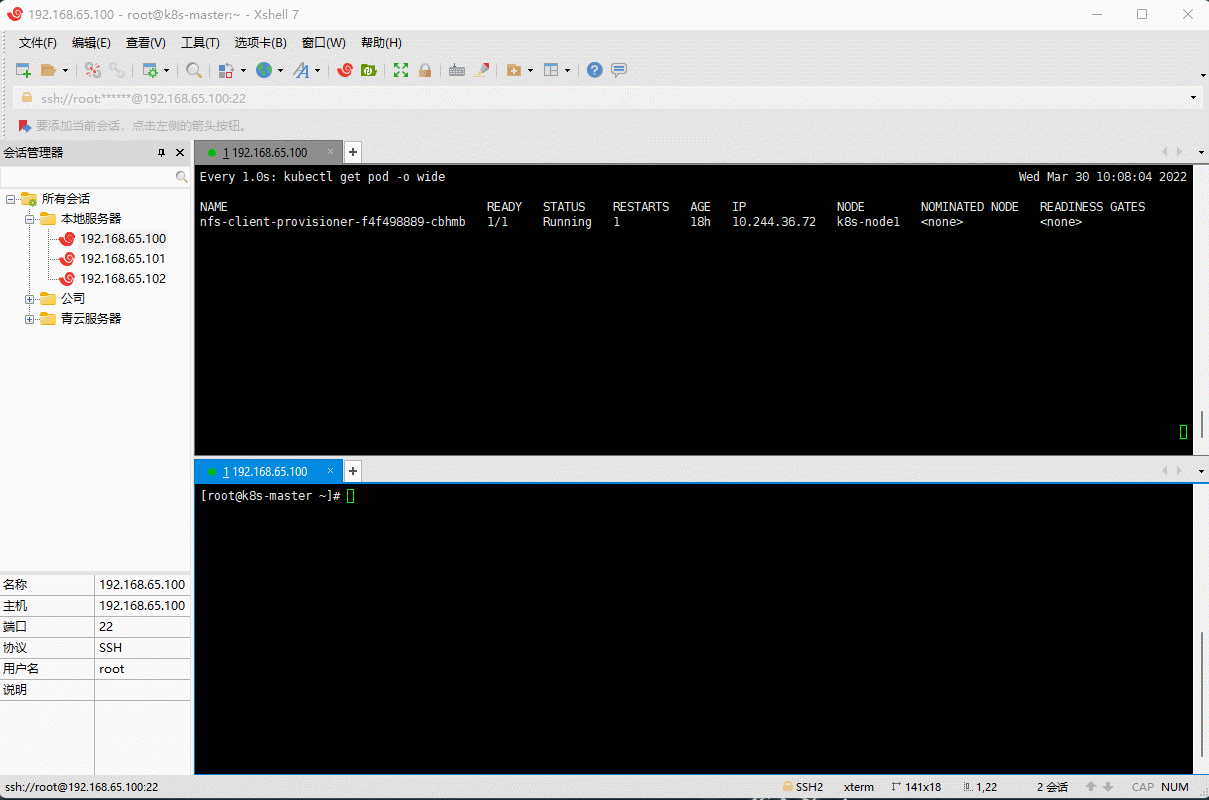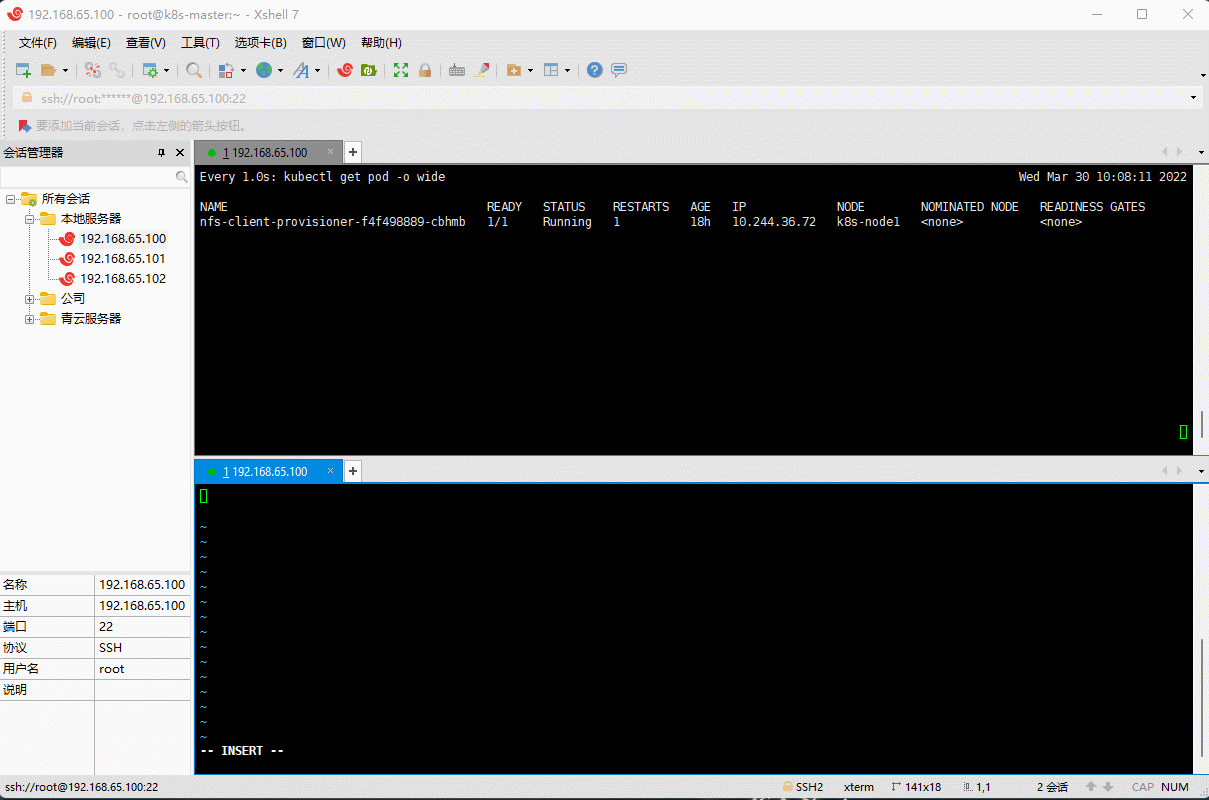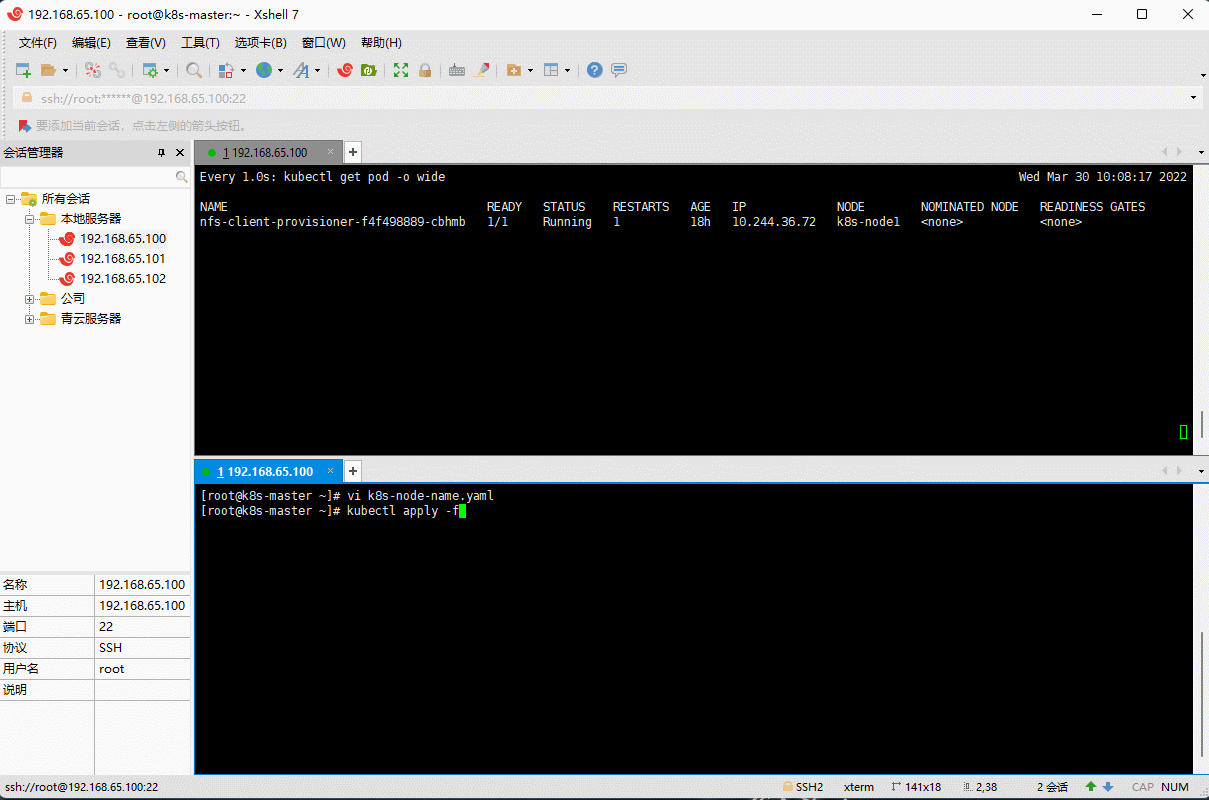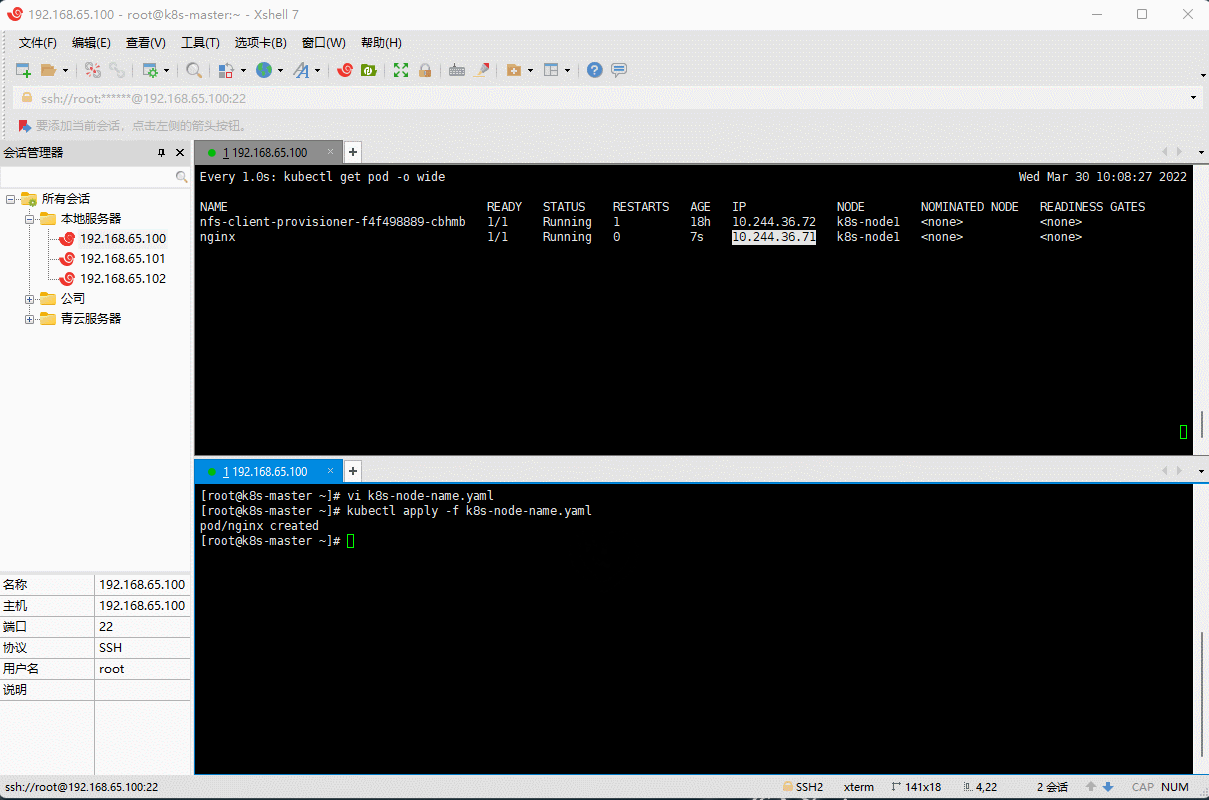
apiVersion: v1kind: Podmetadata:name: nginxnamespace: defaultlabels:app: nginxspec:nodeName: k8s-node1 # 指定调度到k8s-node1节点上containers:- name: nginximage: nginx:1.20.2resources:limits:cpu: 200mmemory: 500Mirequests:cpu: 100mmemory: 200Miports:- containerPort: 80name: httpvolumeMounts:- name: localtimemountPath: /etc/localtimevolumes:- name: localtimehostPath:path: /usr/share/zoneinfo/Asia/ShanghairestartPolicy: Always
kubectl apply -f k8s-node-name.yaml
3.2.3 nodeSelector
nodeSelector是节点选择约束的最简单推荐形式。nodeSelector是 PodSpec 的一个字段。 它包含键值对的映射。为了使 pod 可以在某个节点上运行,该节点的标签中 必须包含这里的每个键值对(它也可以具有其他标签)。 最常见的用法的是一对键值对。- 除了自己 添加 的标签外,节点还预制了一组标准标签。 参见这些常用的标签,注解以及污点:
[kubernetes.io/hostname](https://kubernetes.io/zh/docs/reference/kubernetes-api/labels-annotations-taints/#kubernetes-io-hostname)[failure-domain.beta.kubernetes.io/zone](https://kubernetes.io/zh/docs/reference/kubernetes-api/labels-annotations-taints/#failure-domainbetakubernetesiozone)[failure-domain.beta.kubernetes.io/region](https://kubernetes.io/zh/docs/reference/kubernetes-api/labels-annotations-taints/#failure-domainbetakubernetesioregion)[topology.kubernetes.io/zone](https://kubernetes.io/zh/docs/reference/kubernetes-api/labels-annotations-taints/#topologykubernetesiozone)[topology.kubernetes.io/region](https://kubernetes.io/zh/docs/reference/kubernetes-api/labels-annotations-taints/#topologykubernetesiozone)[beta.kubernetes.io/instance-type](https://kubernetes.io/zh/docs/reference/kubernetes-api/labels-annotations-taints/#beta-kubernetes-io-instance-type)[node.kubernetes.io/instance-type](https://kubernetes.io/zh/docs/reference/kubernetes-api/labels-annotations-taints/#nodekubernetesioinstance-type)[kubernetes.io/os](https://kubernetes.io/zh/docs/reference/kubernetes-api/labels-annotations-taints/#kubernetes-io-os)[kubernetes.io/arch](https://kubernetes.io/zh/docs/reference/kubernetes-api/labels-annotations-taints/#kubernetes-io-arch)
注意:这些标签的值是特定于云供应商的,因此不能保证可靠。 例如,
kubernetes.io/hostname的值在某些环境中可能与节点名称相同, 但在其他环境中可能是一个不同的值。
- 示例:
# 给 k8s-node2 打上标签kubectl label node k8s-node2 nodeevn=pro
vi k8s-node-selector.yaml
apiVersion: v1kind: Podmetadata:name: nginxnamespace: defaultlabels:app: nginxspec:nodeSelector:nodeevn: pro # 指定调度到 nodeevn = pro 标签的 Node 节点上containers:- name: nginximage: nginx:1.20.2resources:limits:cpu: 200mmemory: 500Mirequests:cpu: 100mmemory: 200Miports:- containerPort: 80name: httpvolumeMounts:- name: localtimemountPath: /etc/localtimevolumes:- name: localtimehostPath:path: /usr/share/zoneinfo/Asia/ShanghairestartPolicy: Always
kubectl apply -f k8s-node-selector.yaml
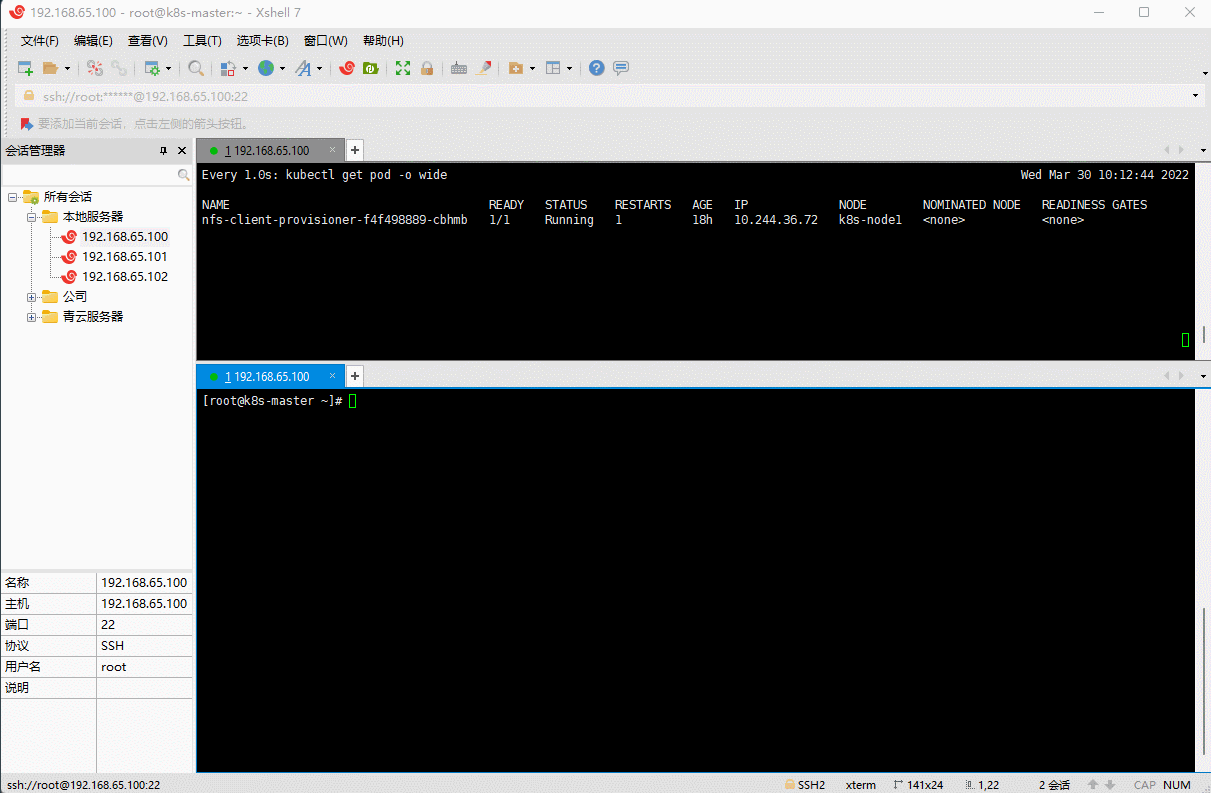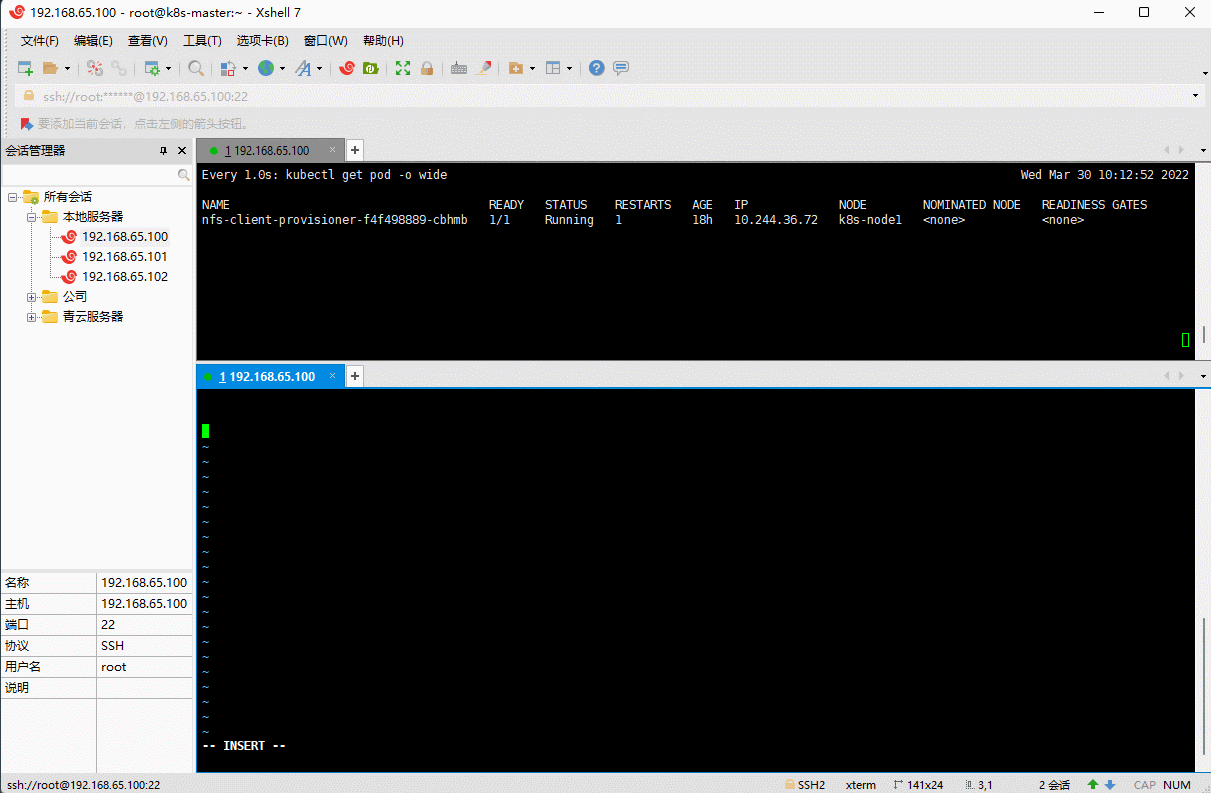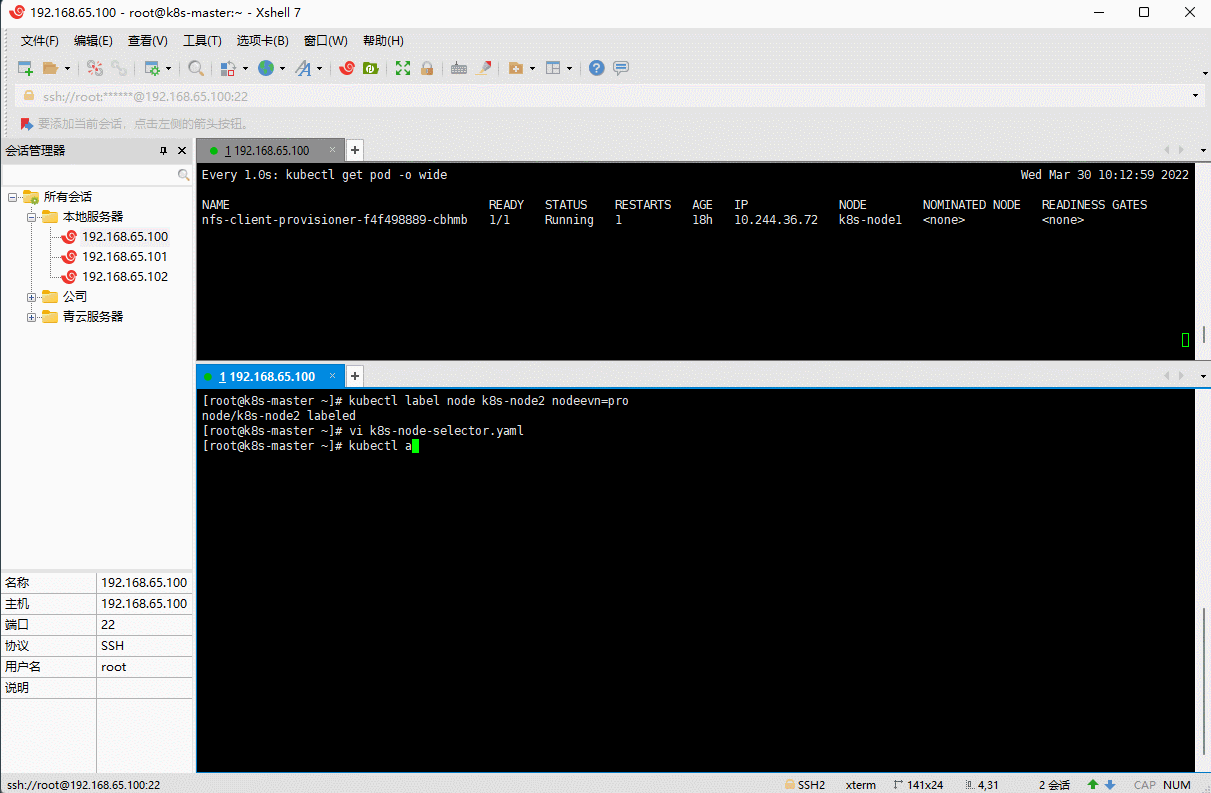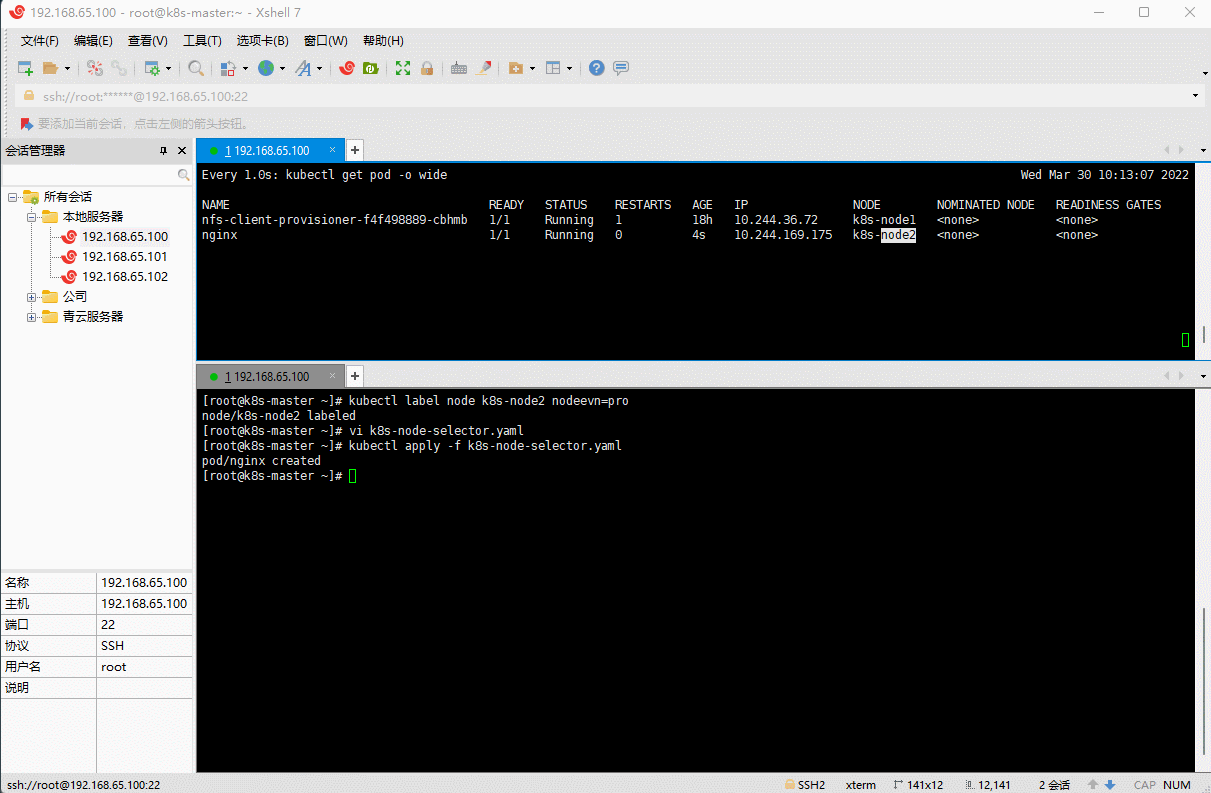
3.3 亲和性调度
3.3.1 概述
- 虽然定向调度的两种方式,使用起来非常方便,但是也有一定的问题,那就是如果没有满足条件的 Node,那么 Pod 将不会被运行,即使在集群中还有可用的 Node 列表也不行,这就限制了它的使用场景。
- 基于上面的问题,Kubernetes 还提供了一种亲和性调度(Affinity)。它在 nodeSelector 的基础之上进行了扩展,可以通过配置的形式,实现优先选择满足条件的 Node 进行调度,如果没有,也可以调度到不满足条件的节点上,使得调度更加灵活。
- Affinity 主要分为三类:
- nodeAffinity(node亲和性):以 Node 为目标,解决 Pod可 以调度到那些 Node 的问题。
- podAffinity(pod亲和性):以 Pod 为目标,解决 Pod 可以和那些已存在的 Pod 部署在同一个拓扑域中的问题。
- podAntiAffinity(pod反亲和性):以 Pod 为目标,解决 Pod 不能和那些已经存在的 Pod 部署在同一拓扑域中的问题。
关于亲和性和反亲和性的使用场景的说明:
- 亲和性:如果两个应用频繁交互,那么就有必要利用亲和性让两个应用尽可能的靠近,这样可以较少因网络通信而带来的性能损耗。
- 反亲和性:当应用采用多副本部署的时候,那么就有必要利用反亲和性让各个应用实例打散分布在各个 Node 上,这样可以提高服务的高可用性。
3.3.2 nodeAffinity
- nodeAffinity 概念上类似于
nodeSelector,它使你可以根据节点上的标签来约束 Pod 可以调度到哪些节点。 - 和 nodeSelector 的区别:
- 引入了运算符:In、NotIn、Exists、DoesNotExist、 Gt、 Lt。
- 支持
硬性过滤和软性评分:- 硬件过滤支持指定
多条件之间的逻辑或运算; - 软件评分规则支持
设置条件权重。
- 硬件过滤支持指定
- nodeAffinity 的可选配置项:
pod.spec.affinity.nodeAffinityrequiredDuringSchedulingIgnoredDuringExecution # Node节点必须满足指定的所有规则才可以,硬性过滤nodeSelectorTerms # 节点选择列表matchFields # 按节点字段列出的节点选择器要求列表matchExpressions # 按节点标签列出的节点选择器要求列表(推荐)key # 键values # 值operator # 关系符 支持Exists, DoesNotExist, In, NotIn, Gt, LtpreferredDuringSchedulingIgnoredDuringExecution # 优先调度到满足指定的规则的Node,软性评分 (倾向)preference # 一个节点选择器项,与相应的权重相关联matchFields # 按节点字段列出的节点选择器要求列表matchExpressions # 按节点标签列出的节点选择器要求列表(推荐)key # 键values # 值operator # 关系符 支持In, NotIn, Exists, DoesNotExist, Gt, Ltweight # 倾向权重,在范围1-100。
注意:
- 如果我们修改或删除 Pod 调度到节点的标签,Pod 不会被删除;换言之,亲和调度只是在 Pod 调度期间有效。
- 如果同时定义了 nodeSelector 和 nodeAffinity ,那么必须两个条件都满足,Pod 才能运行在指定的 Node 上。
- 如果 nodeAffinity 指定了多个 nodeSelectorTerms ,那么只需要其中一个能够匹配成功即可。
- 如果一个 nodeSelectorTerms 中有多个 matchExpressions ,则一个节点必须满足所有的才能匹配成功。
- 示例:硬性过滤
# 给 k8s-node1 和 k8s-nodes 打上标签kubectl label node k8s-node1 disktype=ssdkubectl label node k8s-node2 disktype=hdd
vi k8s-node-affinity-required.yaml
apiVersion: v1kind: Podmetadata:name: nginxnamespace: defaultlabels:app: nginxspec:containers:- name: nginximage: nginx:1.20.2resources:limits:cpu: 200mmemory: 500Mirequests:cpu: 100mmemory: 200Miports:- containerPort: 80name: httpvolumeMounts:- name: localtimemountPath: /etc/localtimevolumes:- name: localtimehostPath:path: /usr/share/zoneinfo/Asia/Shanghaiaffinity:nodeAffinity:# DuringScheduling(调度期间有效)IgnoredDuringExecution(执行期间忽略,执行期间:Pod 运行期间)requiredDuringSchedulingIgnoredDuringExecution: # 硬性过滤:Node 节点必须满足指定的所有规则才可以nodeSelectorTerms:- matchExpressions: # 所有 matchExpressions 满足条件才行- key: disktypeoperator: In # 支持 Exists, DoesNotExist, In, NotIn, Gt, Ltvalues:- ssd- hddrestartPolicy: Always
kubectl apply -f k8s-node-affinity-required.yaml
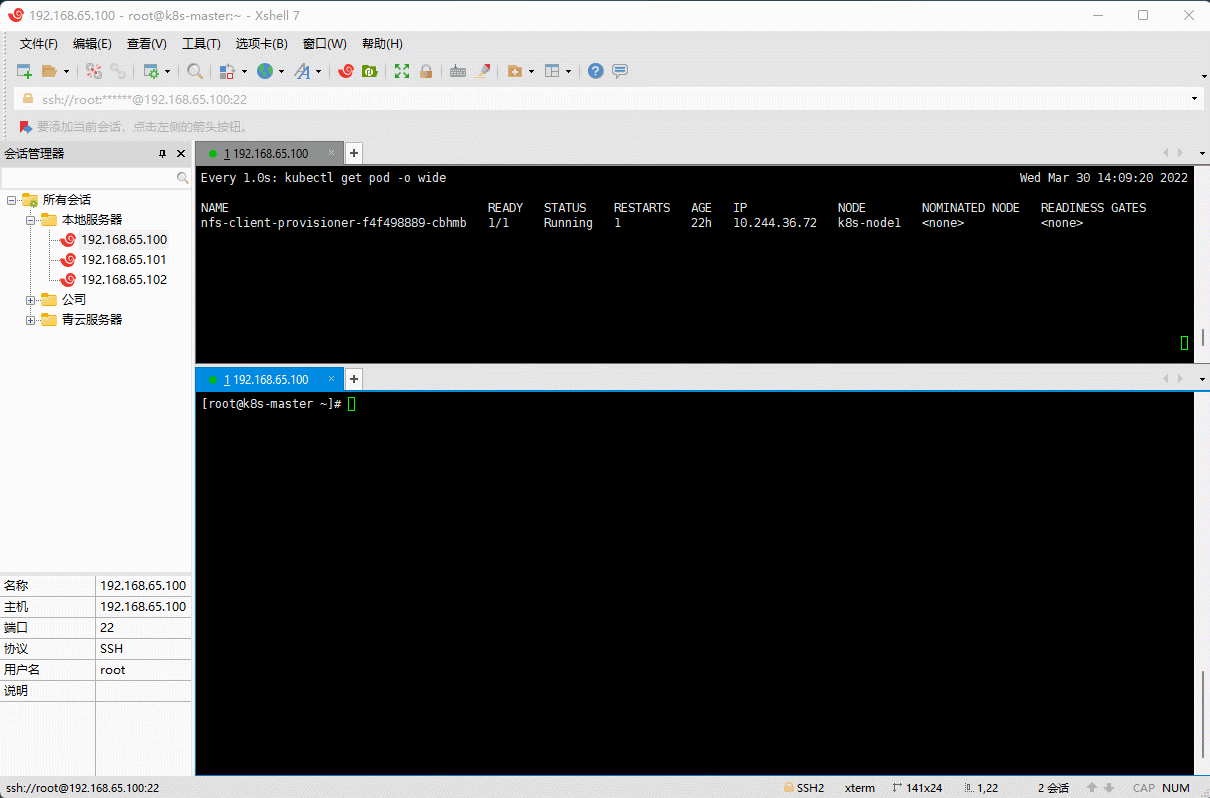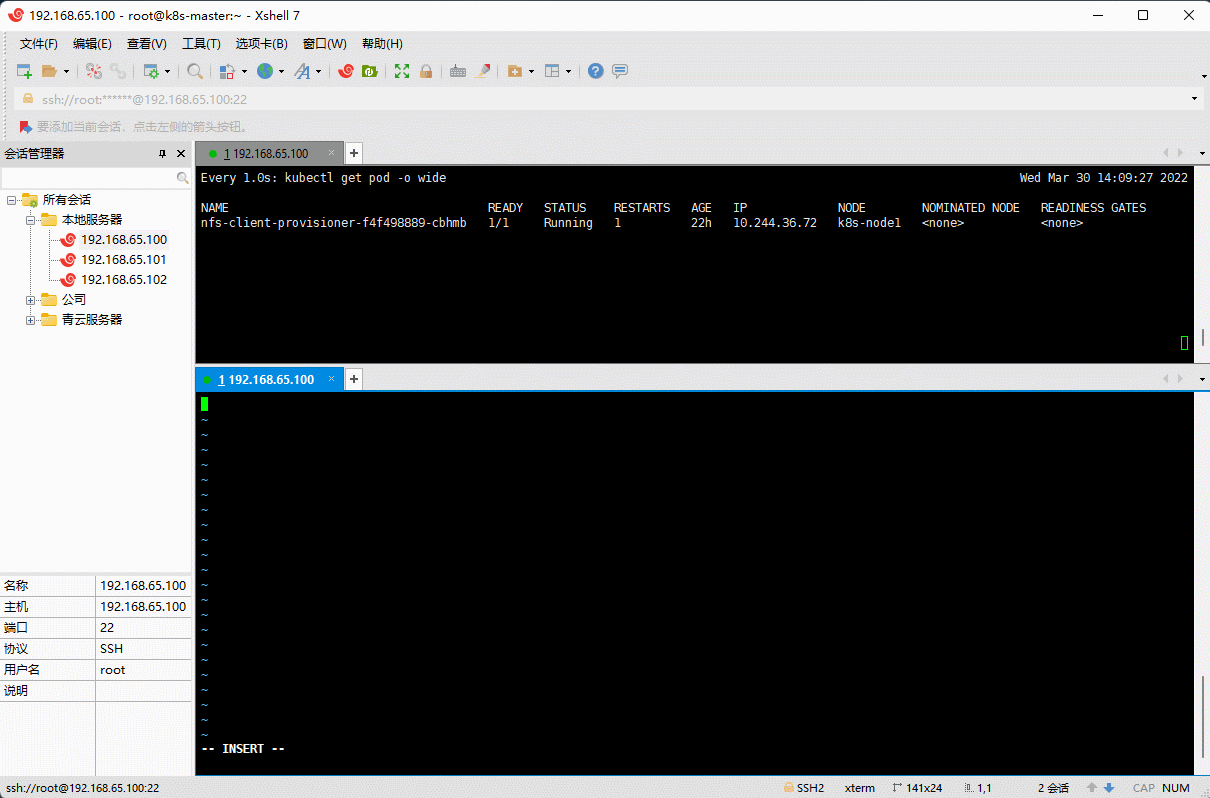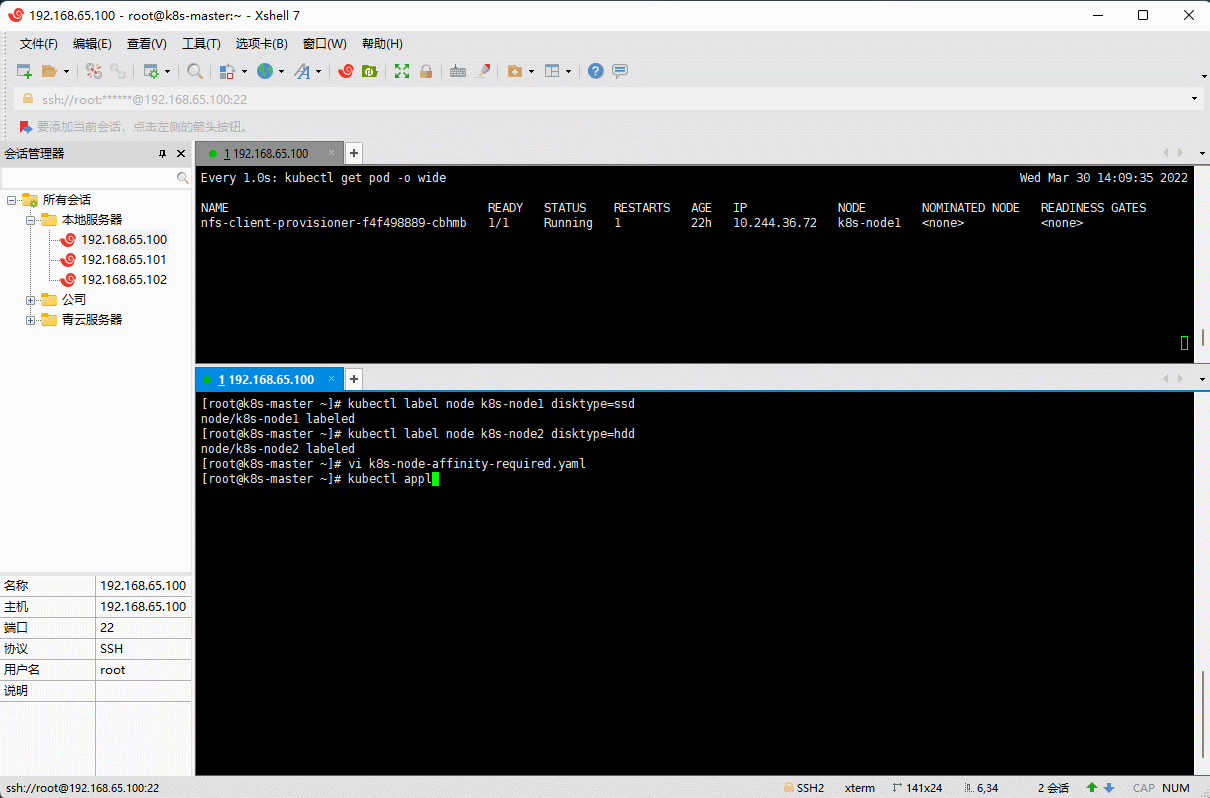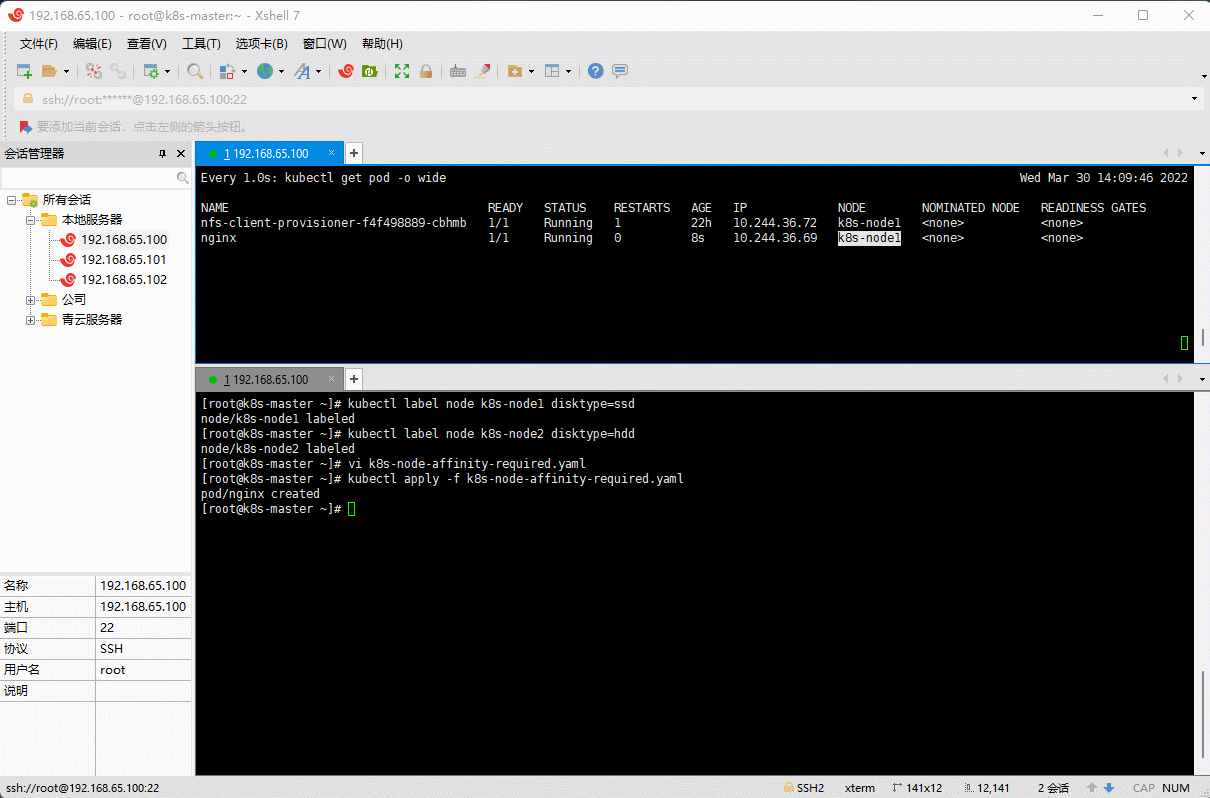
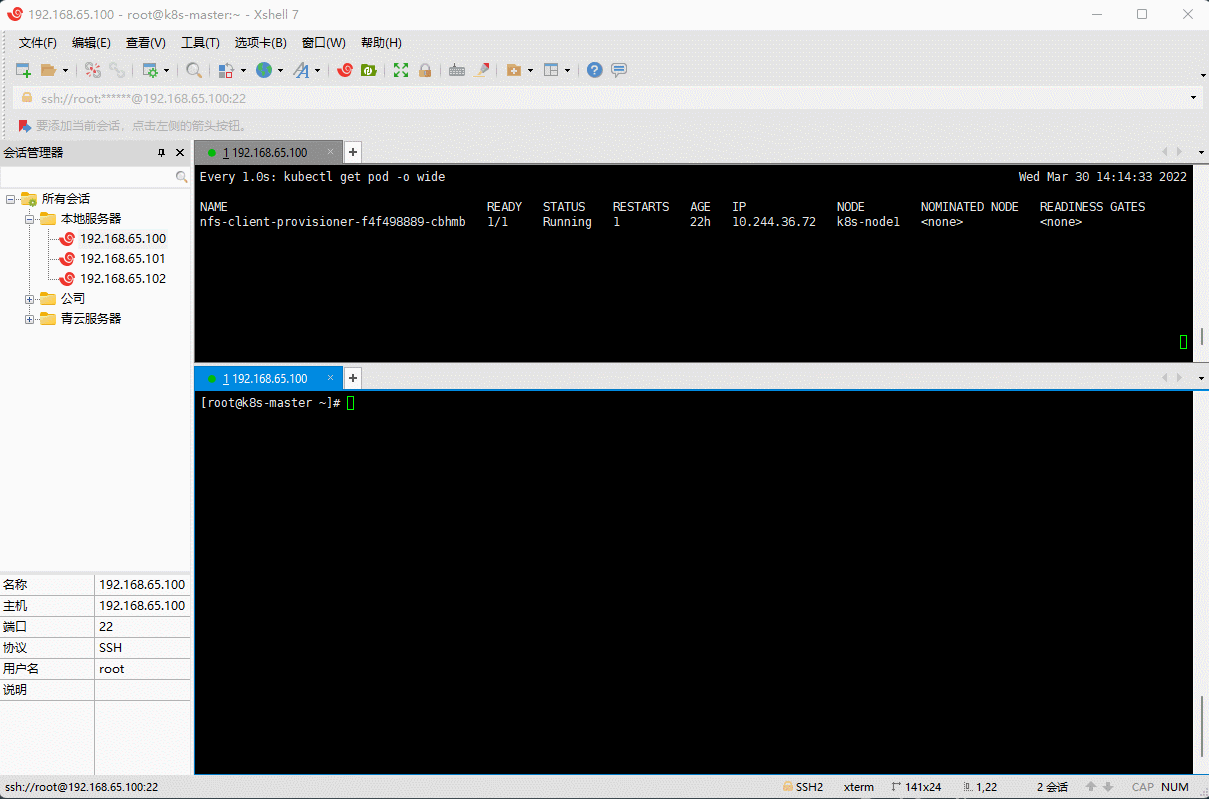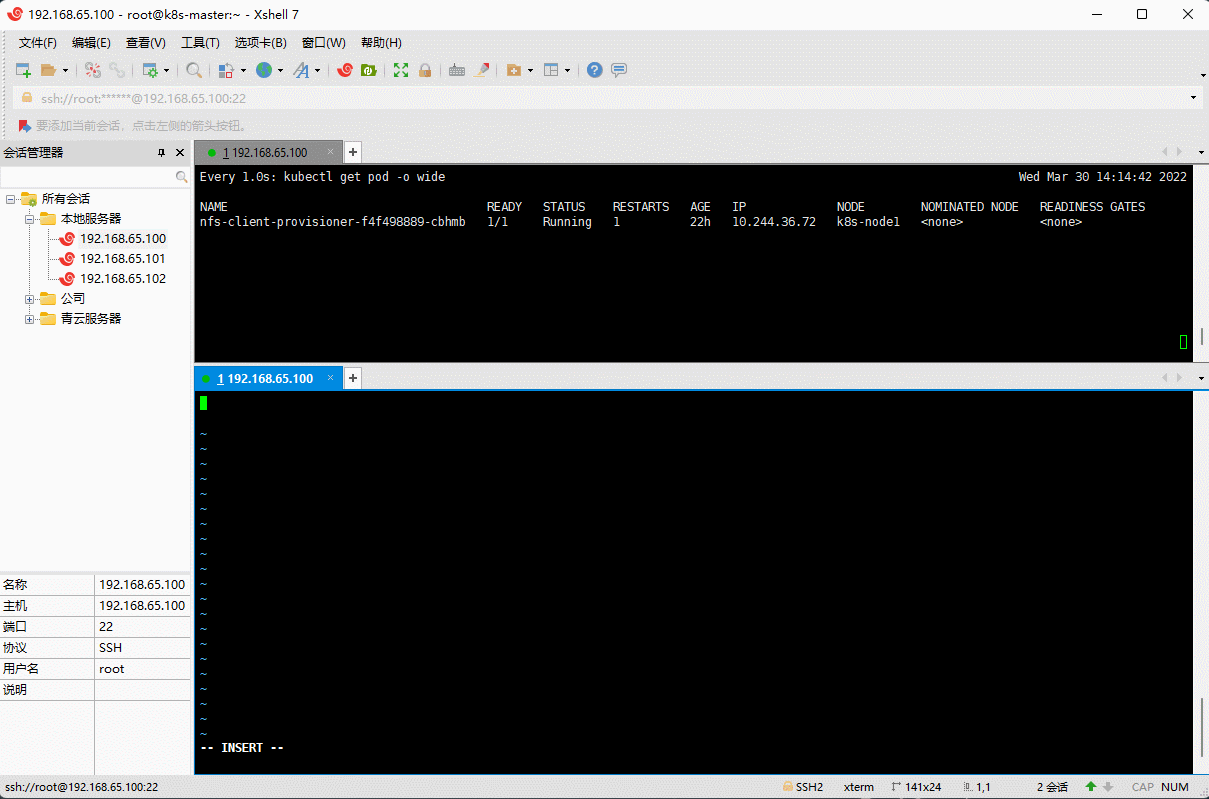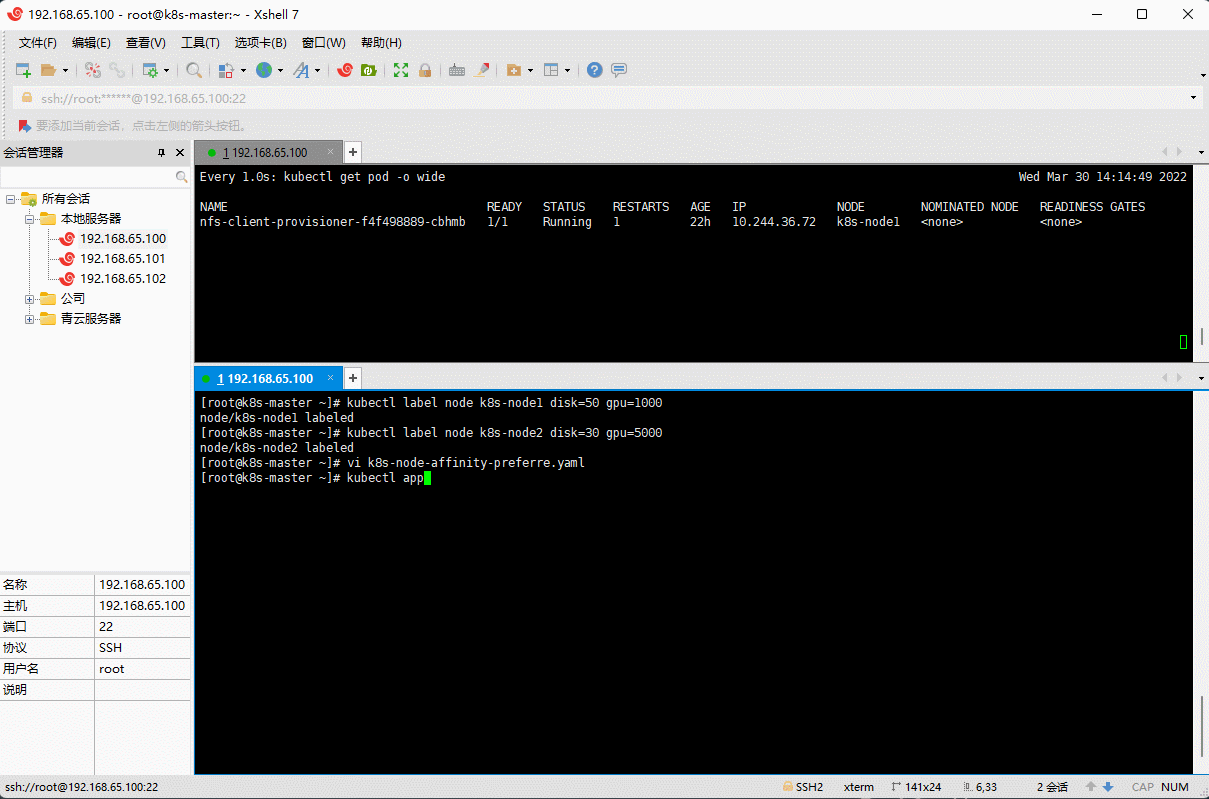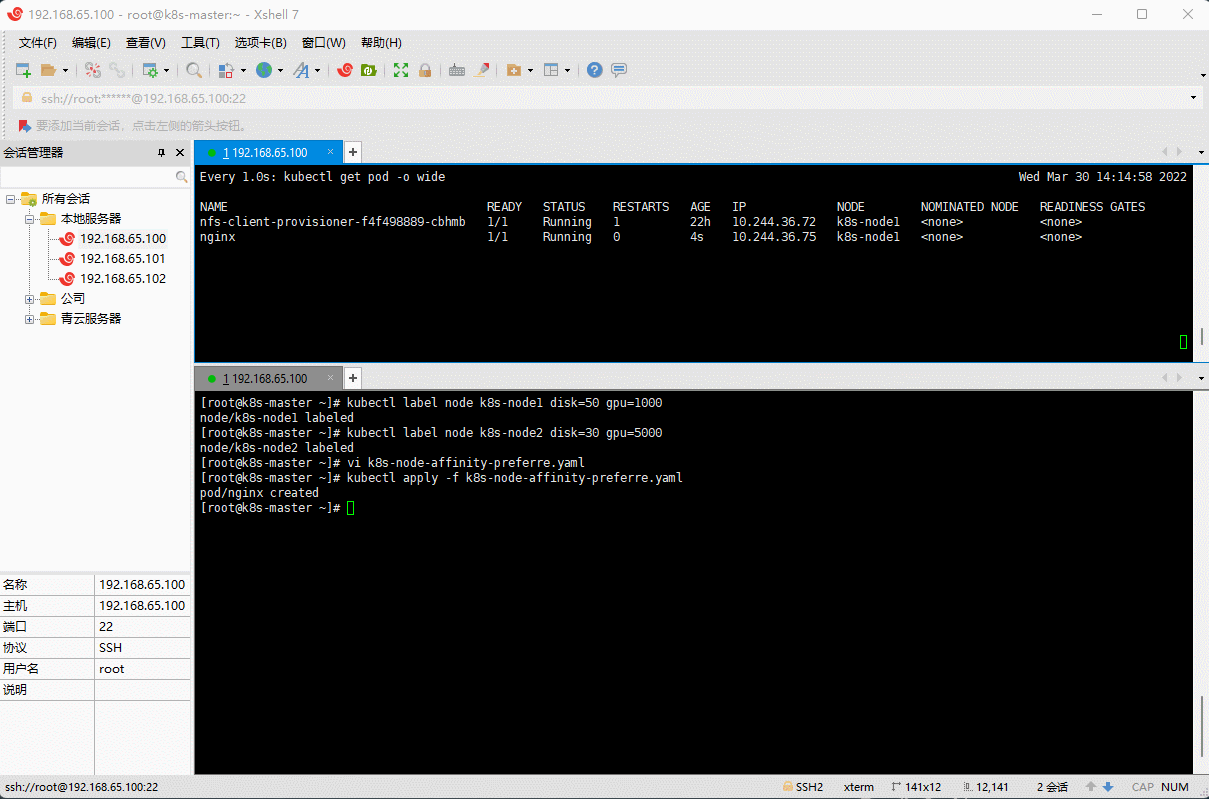
- 示例:软性评分
# 给 k8s-node1 和 k8s-nodes 打上标签kubectl label node k8s-node1 disk=50 gpu=1000kubectl label node k8s-node2 disk=30 gpu=5000
vi k8s-node-affinity-preferre.yaml
apiVersion: v1kind: Podmetadata:name: nginxnamespace: defaultlabels:app: nginxspec:containers:- name: nginximage: nginx:1.20.2resources:limits:cpu: 200mmemory: 500Mirequests:cpu: 100mmemory: 200Miports:- containerPort: 80name: httpvolumeMounts:- name: localtimemountPath: /etc/localtimevolumes:- name: localtimehostPath:path: /usr/share/zoneinfo/Asia/Shanghaiaffinity:nodeAffinity:# DuringScheduling(调度期间有效)IgnoredDuringExecution(执行期间忽略,执行期间:Pod 运行期间)preferredDuringSchedulingIgnoredDuringExecution: # 软性评分:优先调度到满足指定的规则的 Node- weight: 90 # 权重preference: # 一个节点选择器项,与相应的权重相关联matchExpressions:- key: diskoperator: Gtvalues:- "40"- weight: 10 # 权重preference: # 一个节点选择器项,与相应的权重相关联matchExpressions:- key: gpuoperator: Gtvalues:- "4000"restartPolicy: Always
kubectl apply -f k8s-node-affinity-preferre.yaml
3.3.3 podAffinity 和 podAntiAffinity
- podAffinity 主要实现以运行的 Pod 为参照,实现让新创建的 Pod 和参照的 Pod 在一个区域的功能。
- podAntiAffinity 主要实现以运行的 Pod 为参照,让新创建的 Pod 和参照的 Pod 不在一个区域的功能。
- PodAffinity 的可选配置项:
pod.spec.affinity.podAffinityrequiredDuringSchedulingIgnoredDuringExecution 硬限制namespaces 指定参照pod的namespacetopologyKey 指定调度作用域labelSelector 标签选择器matchExpressions 按节点标签列出的节点选择器要求列表(推荐)key 键values 值operator 关系符 支持In, NotIn, Exists, DoesNotExist.matchLabels 指多个matchExpressions映射的内容preferredDuringSchedulingIgnoredDuringExecution 软限制podAffinityTerm 选项namespacestopologyKeylabelSelectormatchExpressionskey 键values 值operatormatchLabelsweight 倾向权重,在范围1-1
注意:topologyKey 用于指定调度的作用域,例如:
- 如果指定为 kubernetes.io/hostname(可以通过 kubectl get node —show-labels 查看),那就是以 Node 节点为区分范围。
- 如果指定为 kubernetes.io/os,则以 Node 节点的操作系统类型来区分。
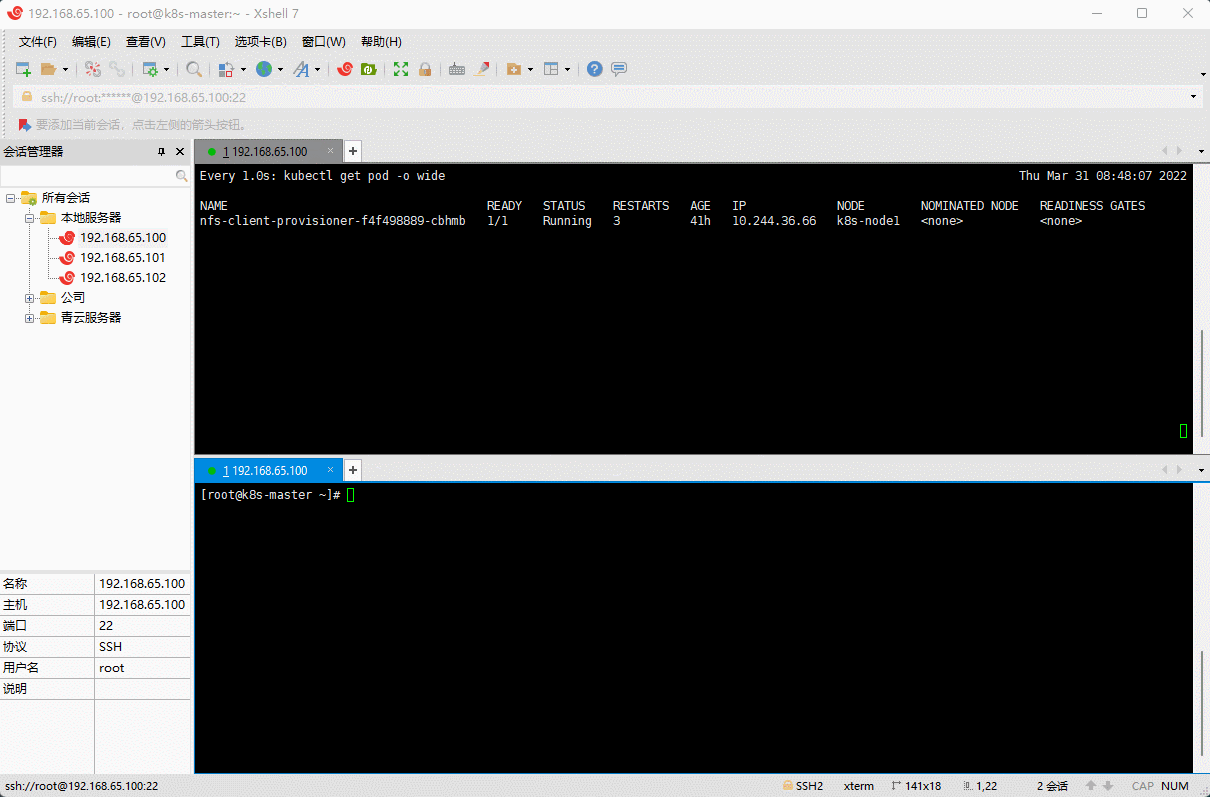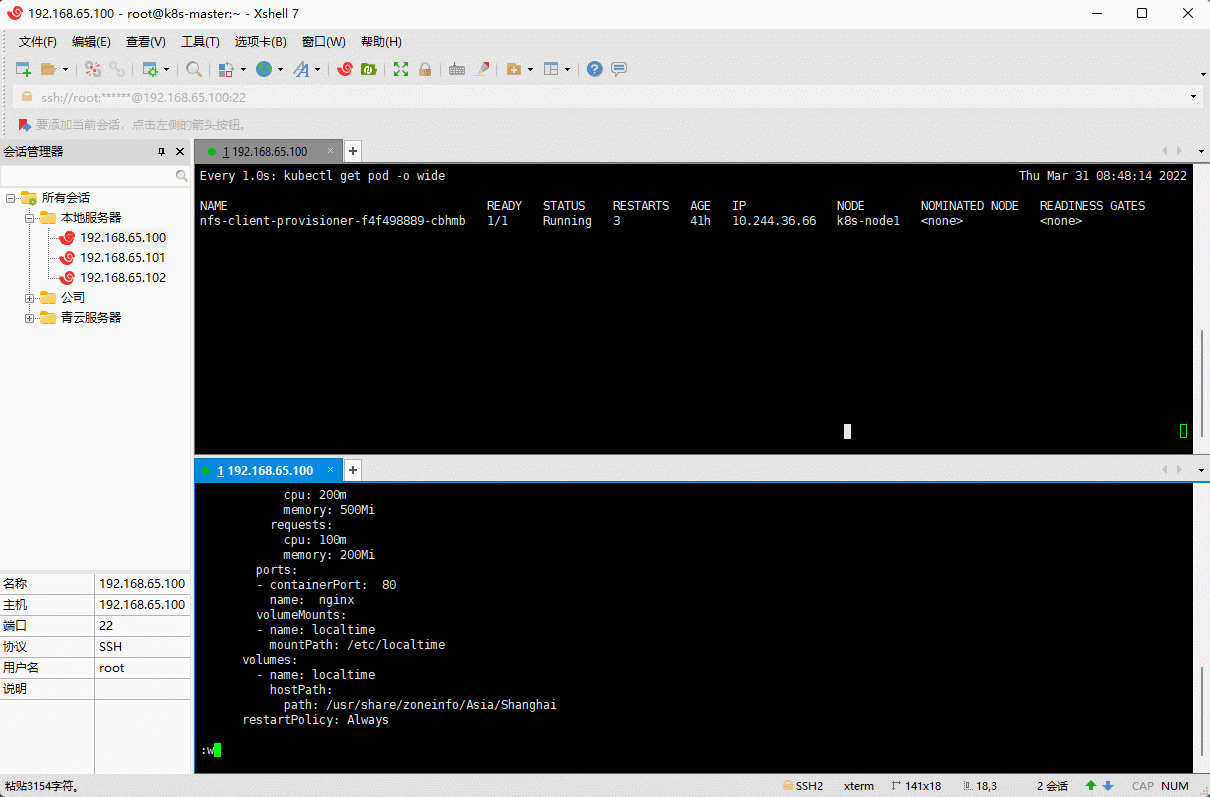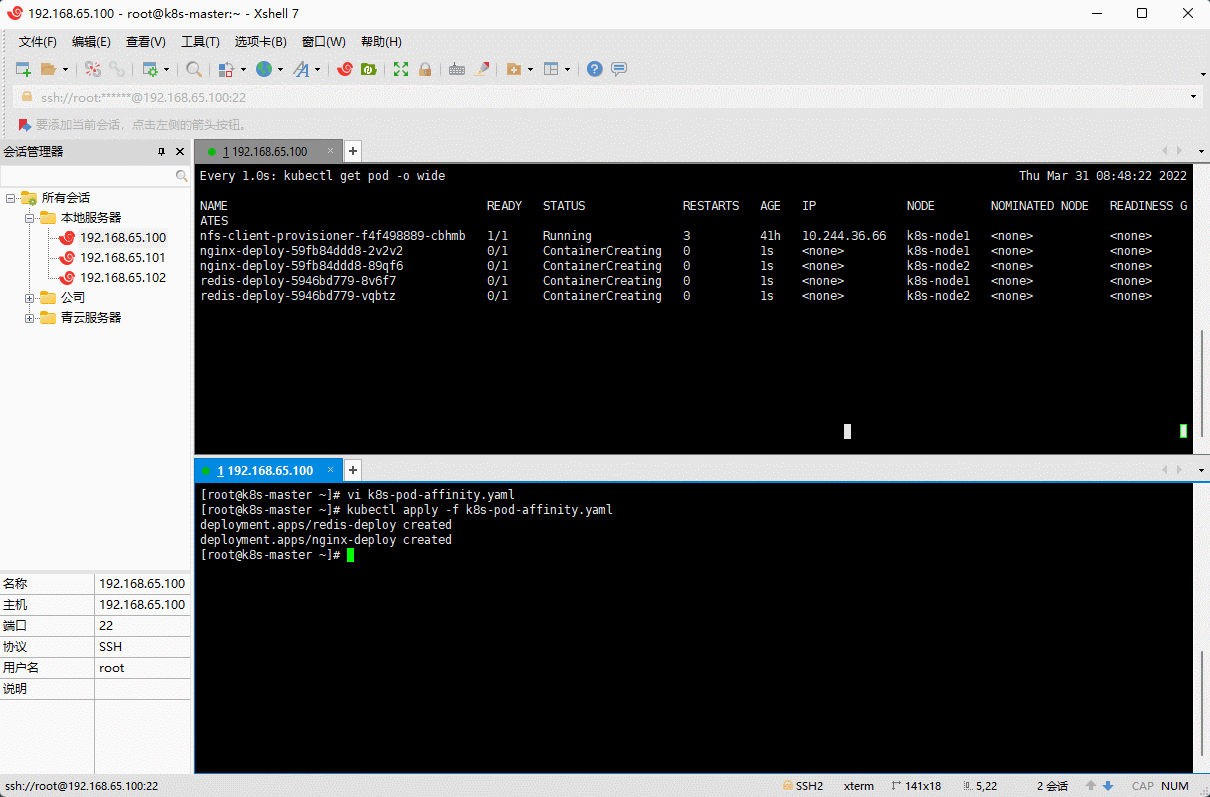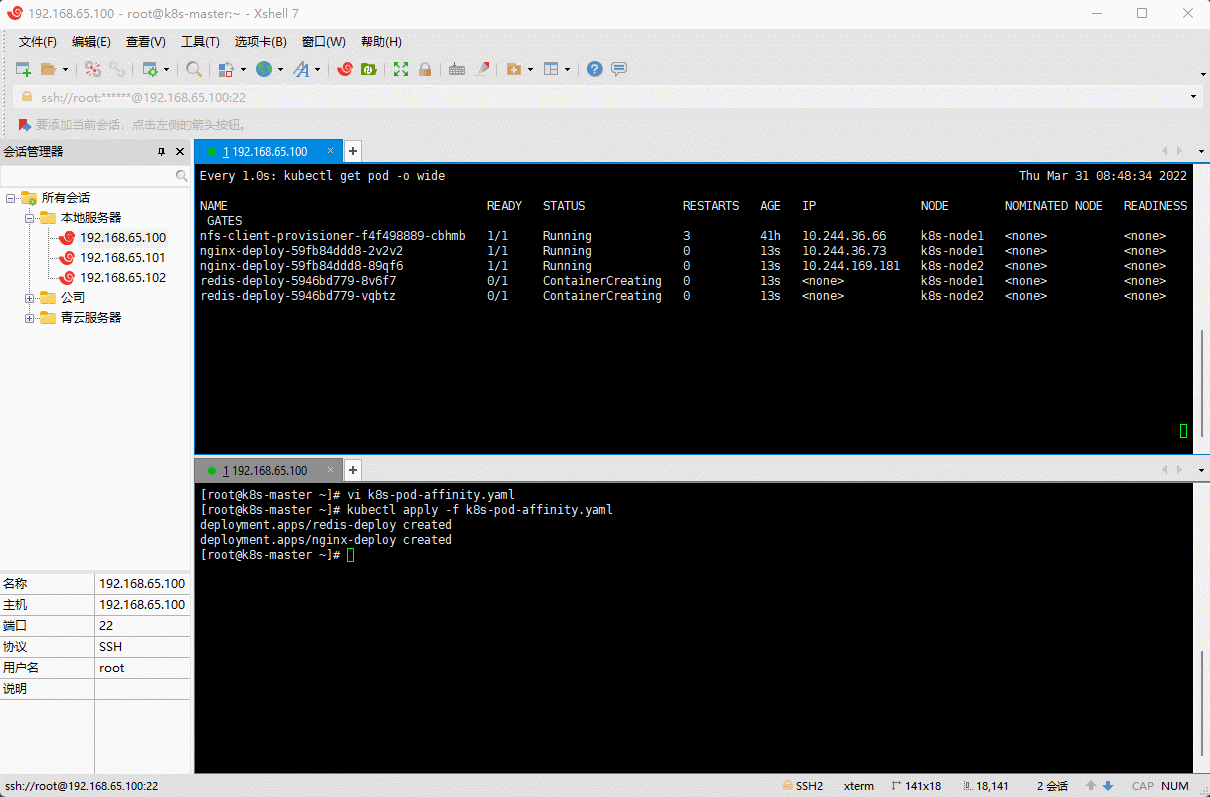
- 示例:在一个两节点的集群中,部署一个使用 redis 的 WEB 应用程序,并期望 web-server 尽可能和 redis 在同一个节点上。
vi k8s-pod-affinity.yaml
apiVersion: apps/v1kind: Deploymentmetadata:name: redis-deploynamespace: defaultlabels:app: redis-deployspec:selector:matchLabels:app: storereplicas: 2template:metadata:labels:app: storespec:affinity: # 亲和性配置podAntiAffinity: # Pod 反亲和性,符合以下指定条件不会被调度过去requiredDuringSchedulingIgnoredDuringExecution: # 硬限制- labelSelector:matchExpressions:- key: appoperator: Invalues:- storetopologyKey: kubernetes.io/hostname # 拓扑键,划分逻辑区域。# node 节点以 kubernetes.io/hostname 为拓扑网络,如果 kubernetes.io/hostname 相同,就认为是同一个东西。# 亲和就是都放在这个逻辑区域,反亲和就是必须避免放在同一个逻辑区域。containers:- name: redis-serverimage: redis:5.0.14-alpineresources:limits:memory: 500Micpu: 1requests:memory: 250Micpu: 500mports:- containerPort: 2375name: redisvolumeMounts:- name: localtimemountPath: /etc/localtimevolumes:- name: localtimehostPath:path: /usr/share/zoneinfo/Asia/ShanghairestartPolicy: Always---apiVersion: apps/v1kind: Deploymentmetadata:name: nginx-deploynamespace: defaultlabels:app: nginx-deployspec:selector:matchLabels:app: web-storereplicas: 2template:metadata:labels:app: web-storespec:affinity: # 亲和性配置podAffinity: # Pod 亲和性,符合以下指定条件会被调度过去requiredDuringSchedulingIgnoredDuringExecution: # 硬限制- labelSelector:matchExpressions:- key: appoperator: Invalues:- storetopologyKey: kubernetes.io/hostname # 拓扑键,划分逻辑区域。# node 节点以 kubernetes.io/hostname 为拓扑网络,如果 kubernetes.io/hostname 相同,就认为是同一个东西。# 亲和就是都放在这个逻辑区域,反亲和就是必须避免放在同一个逻辑区域。podAntiAffinity: # Pod 反亲和性,符合以下指定条件不会被调度过去requiredDuringSchedulingIgnoredDuringExecution: # 硬限制- labelSelector:matchExpressions:- key: appoperator: Invalues:- web-storetopologyKey: kubernetes.io/hostname # 拓扑键,划分逻辑区域。# node 节点以 kubernetes.io/hostname 为拓扑网络,如果 kubernetes.io/hostname 相同,就认为是同一个东西。# 亲和就是都放在这个逻辑区域,反亲和就是必须避免放在同一个逻辑区域。containers:- name: nginximage: nginx:1.20.2resources:limits:cpu: 200mmemory: 500Mirequests:cpu: 100mmemory: 200Miports:- containerPort: 80name: nginxvolumeMounts:- name: localtimemountPath: /etc/localtimevolumes:- name: localtimehostPath:path: /usr/share/zoneinfo/Asia/ShanghairestartPolicy: Always
kubectl apply -f k8s-pod-affinity.yaml
3.4 污点和容忍调度
3.4.1 污点
- 前面的调度方式都是站在 Pod 的角度上,通过在 Pod 上添加属性,来确定 Pod 是否要调度到指定的 Node 上,其实我们也可以站在 Node 的角度上,通过在 Node 上添加
污点属性,来决定是否运行 Pod 调度过来。 - Node 被设置了污点之后就和 Pod 之间存在了一种相斥的关系,进而拒绝 Pod 调度进来,甚至可以将已经存在的 Pod 驱逐出去。
- 污点的格式为:
key=value:effect# key 和 value 是污点的标签及对应的值# effect 描述污点的作用
- effect 支持如下的三个选项:
- PreferNoSchedule:Kubernetes 将尽量避免把 Pod 调度到具有该污点的 Node 上,除非没有其他节点可以调度;换言之,尽量不要来,除非没办法。
- NoSchedule:Kubernets 将不会把 Pod 调度到具有该污点的 Node 上,但是不会影响当前 Node 上已经存在的 Pod ;换言之,新的不要来,在这的就不要动。
- NoExecute:Kubernets 将不会将 Pod 调度到具有该污点的 Node 上,同时会将 Node 上已经存在的 Pod 驱逐;换言之,新的不要来,这这里的赶紧走。
注意:NoExecute 一般用于实际生产环境中的 Node 节点的上下线。
- 语法:设置污点
kubectl taint node xxx key=value:effect
- 语法:去除污点
kubectl taint node xxx key:effect-
- 语法:去除所有污点
kubectl taint node xxx key-
- 语法:查看污点
kubectl describe node xxx | grep -i taints
- 证明:kubeadm 安装的集群上 k8s-master 有污点
kubectl describe node k8s-master | grep -i taints
- 示例:演示污点效果(为了演示效果更为明显,暂时停止 k8s-node2 节点)
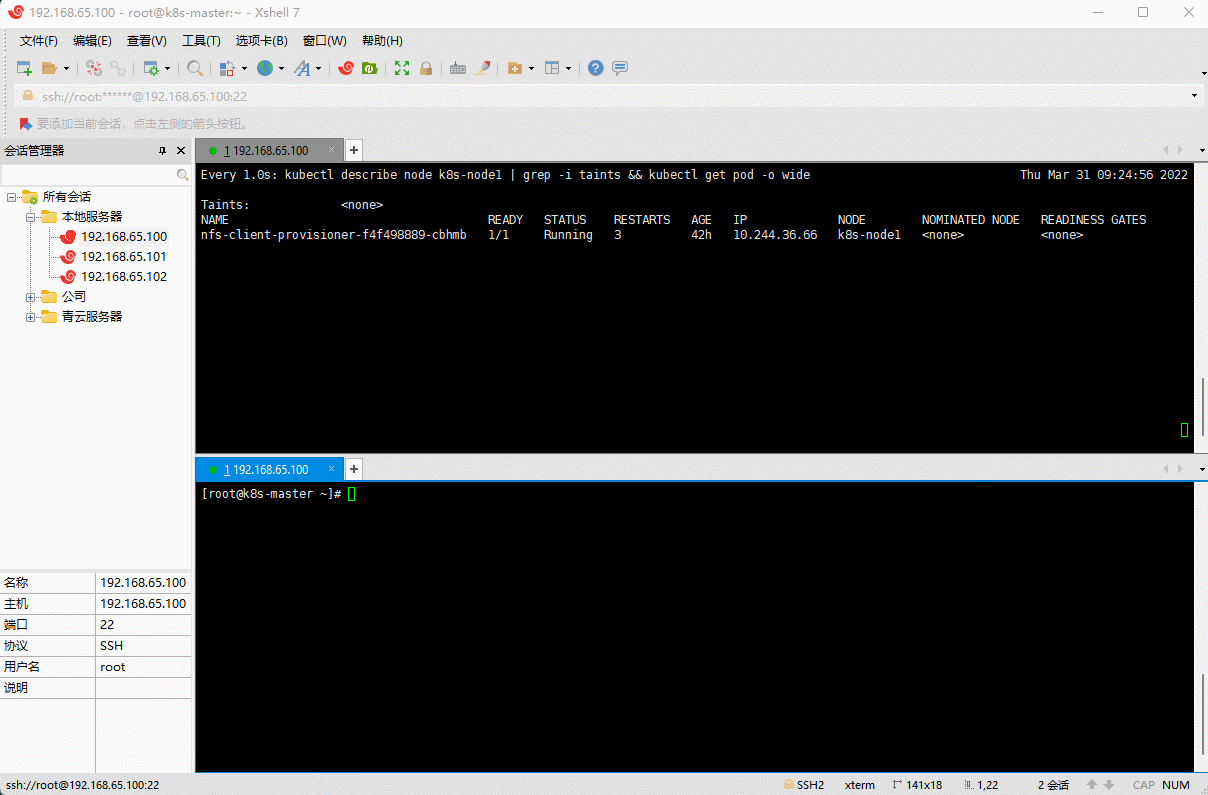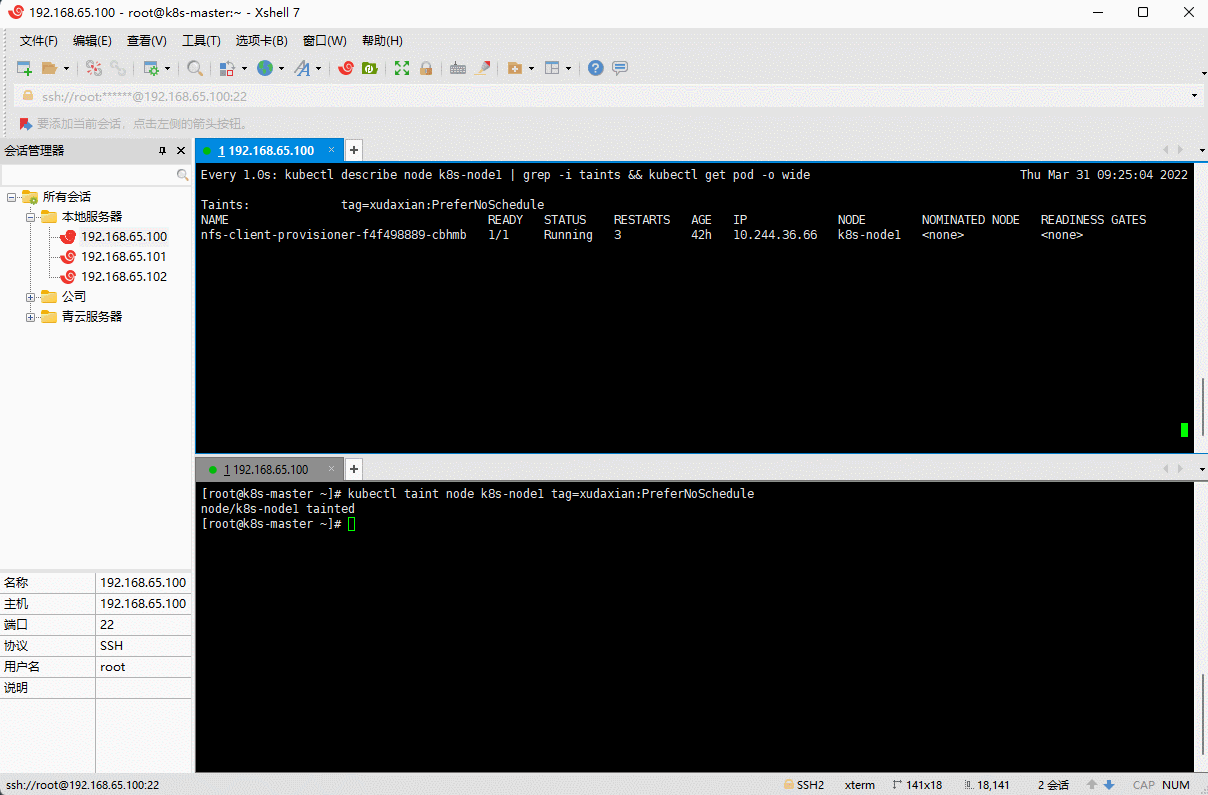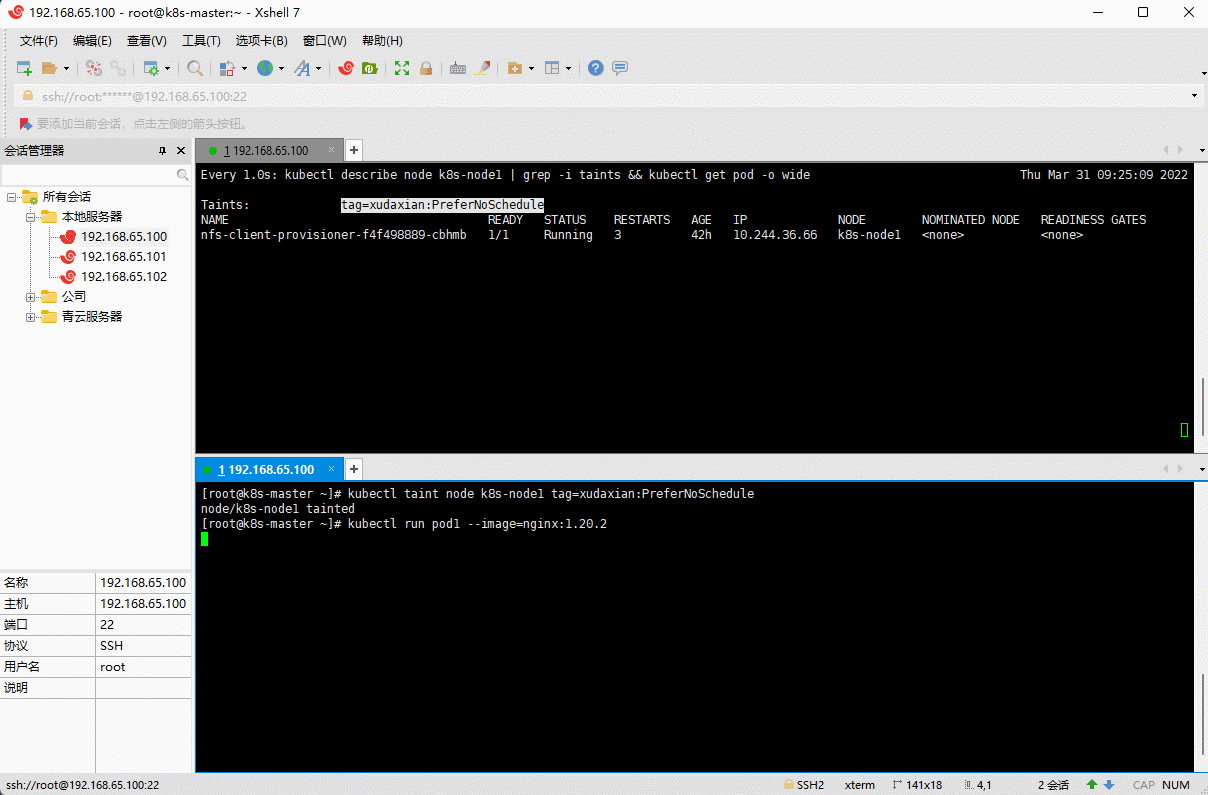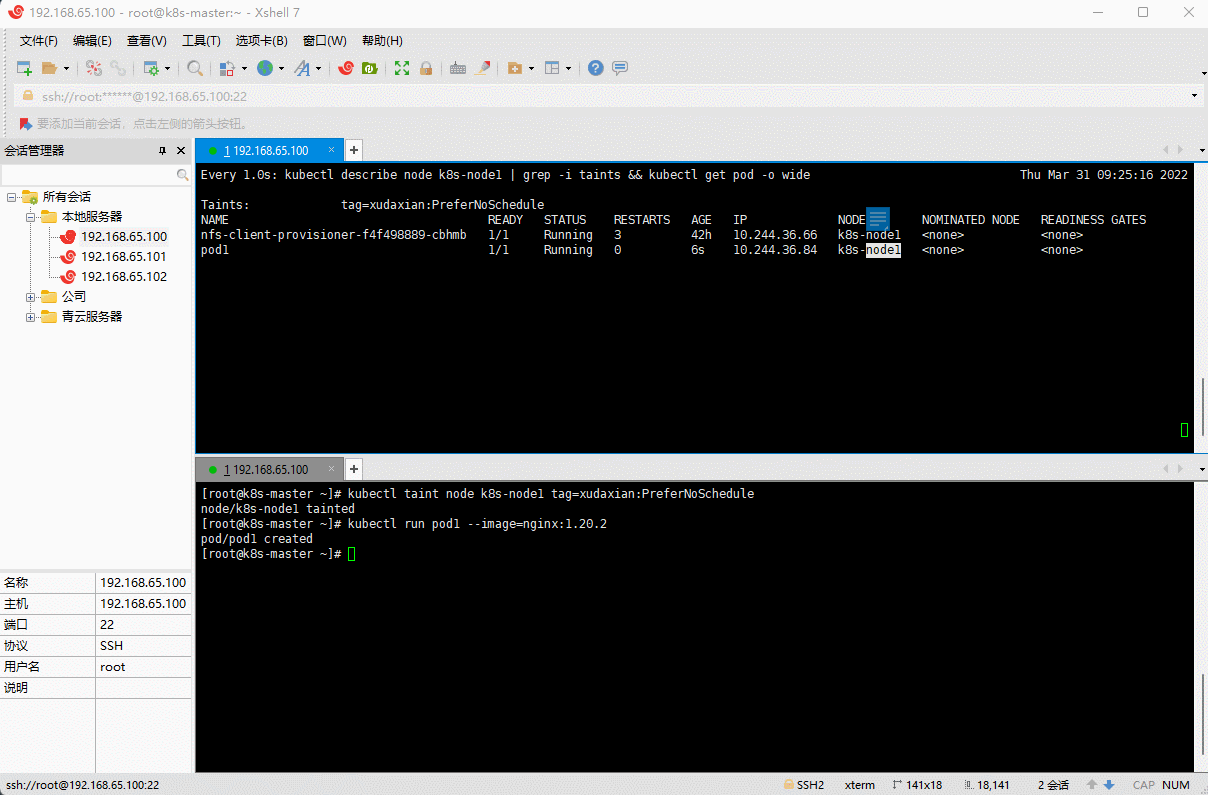
- ① 为 k8s-node1 设置污点
tag=xudaxian:PreferNoSchedule,然后创建 Pod1 (Pod1 可以运行)
kubectl taint node k8s-node1 tag=xudaxian:PreferNoSchedule
kubectl run pod1 --image=nginx:1.20.2
- ② 修改 k8s-node1 节点的污点为
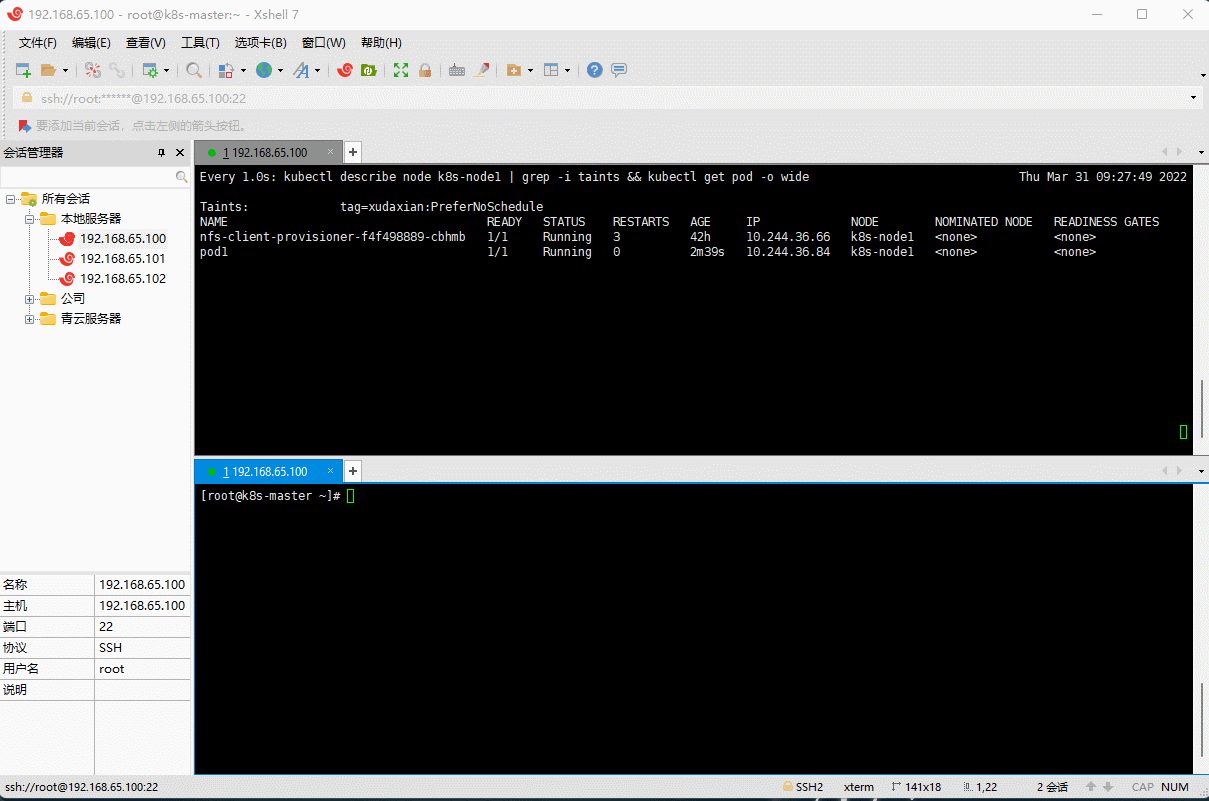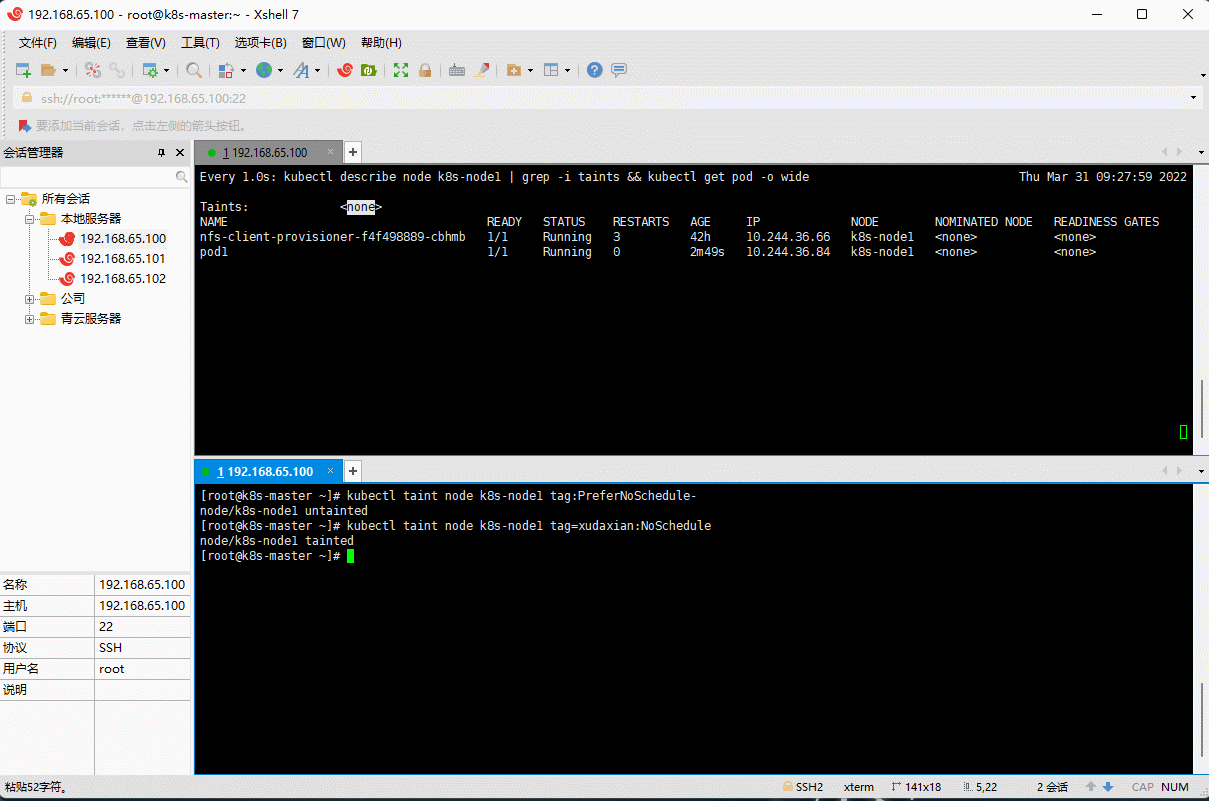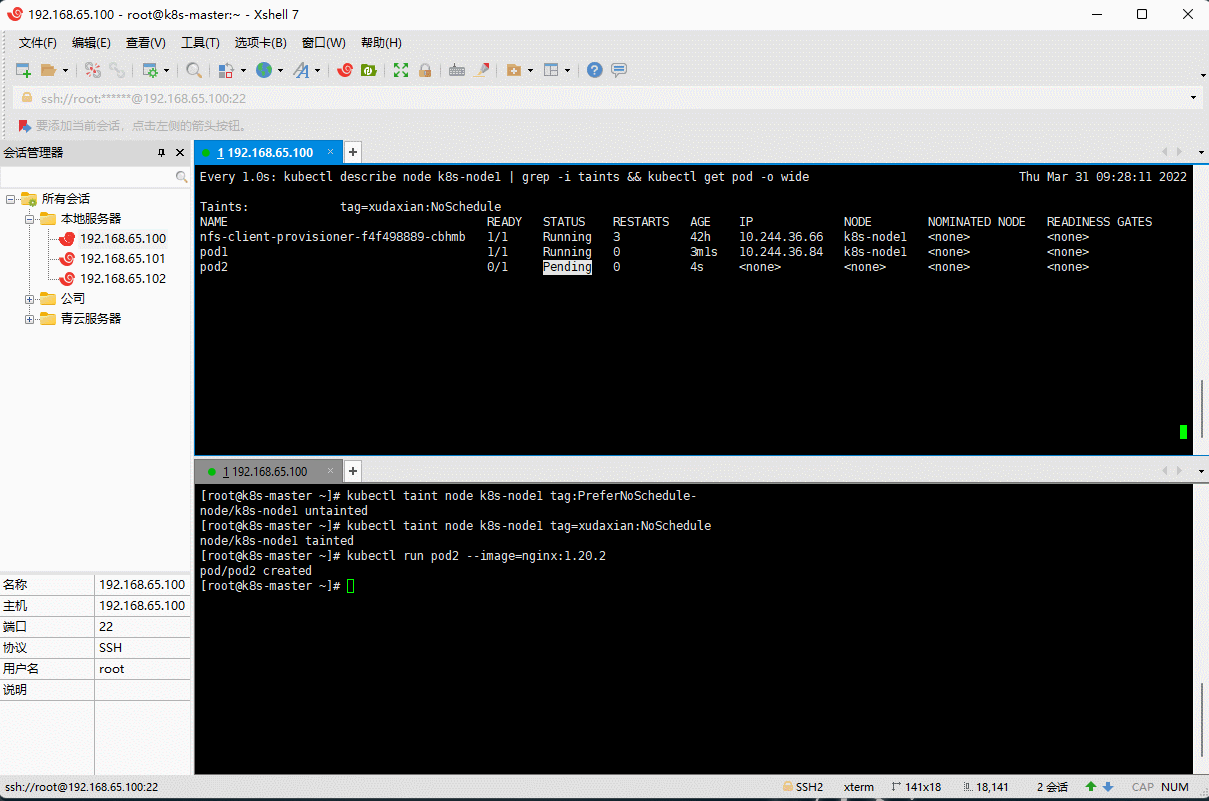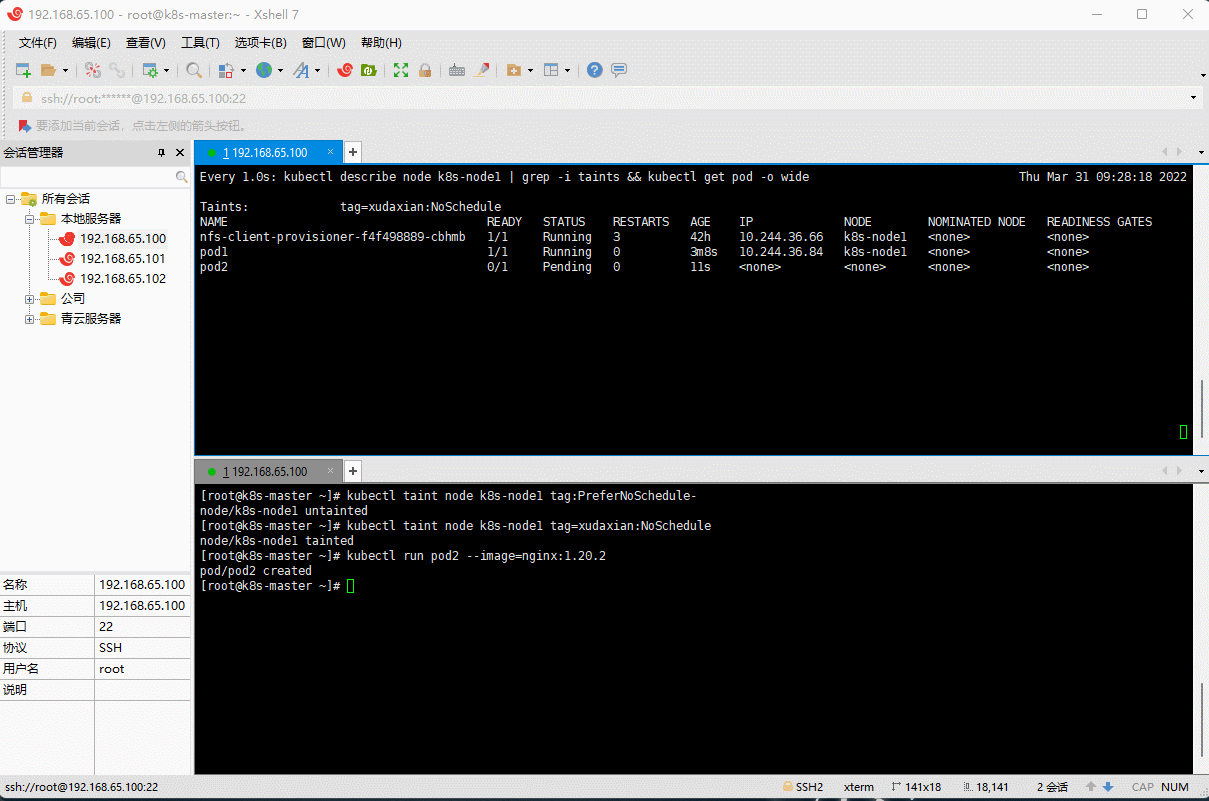
tag=xudaxian:NoSchedule,然后创建Pod2(Pod1 可以正常运行,Pod2 失败)。
# 取消污点kubectl taint node k8s-node1 tag:PreferNoSchedule-# 设置污点kubectl taint node k8s-node1 tag=xudaxian:NoSchedule
kubectl run pod2 --image=nginx:1.20.2
- ③ 修改 k8s-node1 节点的污点为
tag=xudaxian:NoExecute,然后创建 Pod3(Pod1、Pod2、Pod3失败)。
# 取消污点kubectl taint node k8s-node1 tag:NoSchedule-# 设置污点kubectl taint node k8s-node1 tag=xudaxian:NoExecute
kubectl run pod3 --image=nginx:1.20.2

3.4.2 容忍
- 上面介绍了污点的作用,我们可以在 Node上 添加污点用来拒绝 Pod 调度上来,但是如果就是想让一个 Pod 调度到一个有污点的 Node 上去,这时候应该怎么做?这就需要使用到容忍。
污点就是拒绝,容忍就是忽略,Node 通过污点拒绝 Pod 调度上去,Pod 通过容忍忽略拒绝。
- 容忍的详细配置:
kubectl explain pod.spec.tolerations......FIELDS:key # 对应着要容忍的污点的键,空意味着匹配所有的键value # 对应着要容忍的污点的值operator # key-value的运算符,支持Equal和Exists(默认)effect # 对应污点的effect,空意味着匹配所有影响tolerationSeconds # 容忍时间, 当effect为NoExecute时生效,表示pod在Node上的停留时间
- 污点和容忍的匹配:
- 当满足如下条件的时候,Kubernetes 认为污点和容忍匹配:
- 键(key)相同。
- 效果(effect)相同。
- 污点的 operator 为:
- Exists ,此时污点中不应该指定 value 。
- Equal,此时容忍的 value 应该和污点的 value 相同。
- 如果不指定 operator ,默认为 Equal 。
- 当满足如下条件的时候,Kubernetes 认为污点和容忍匹配:
- 特殊情况:
- 容忍中没有定义 key ,但是定义了 operator 为 Exists ,Kubernetes 则认为此容忍匹配所有的污点,如: ```yaml tolerations:
operator: Exists
最终,所有有污点的机器我们都能容忍,Pod 都可以调度。
- 容忍中没有定义 effect,但是定义了 key,Kubernetes 认为此容忍匹配所有 effect ,如:```yamltolerations: # 容忍- key: "tag" # 要容忍的污点的keyoperator: Exists # 操作符# 最终,有这个污点的机器我们可以容忍,Pod 都可以调度。
- 示例:
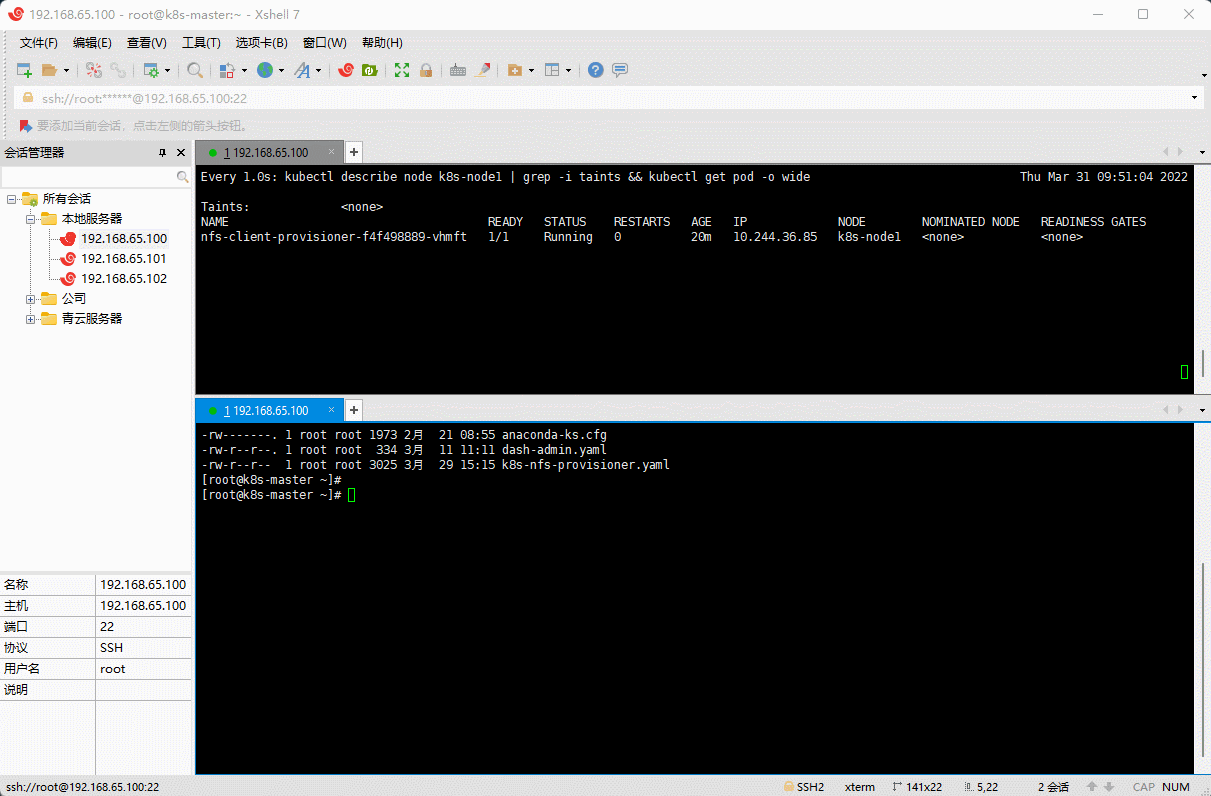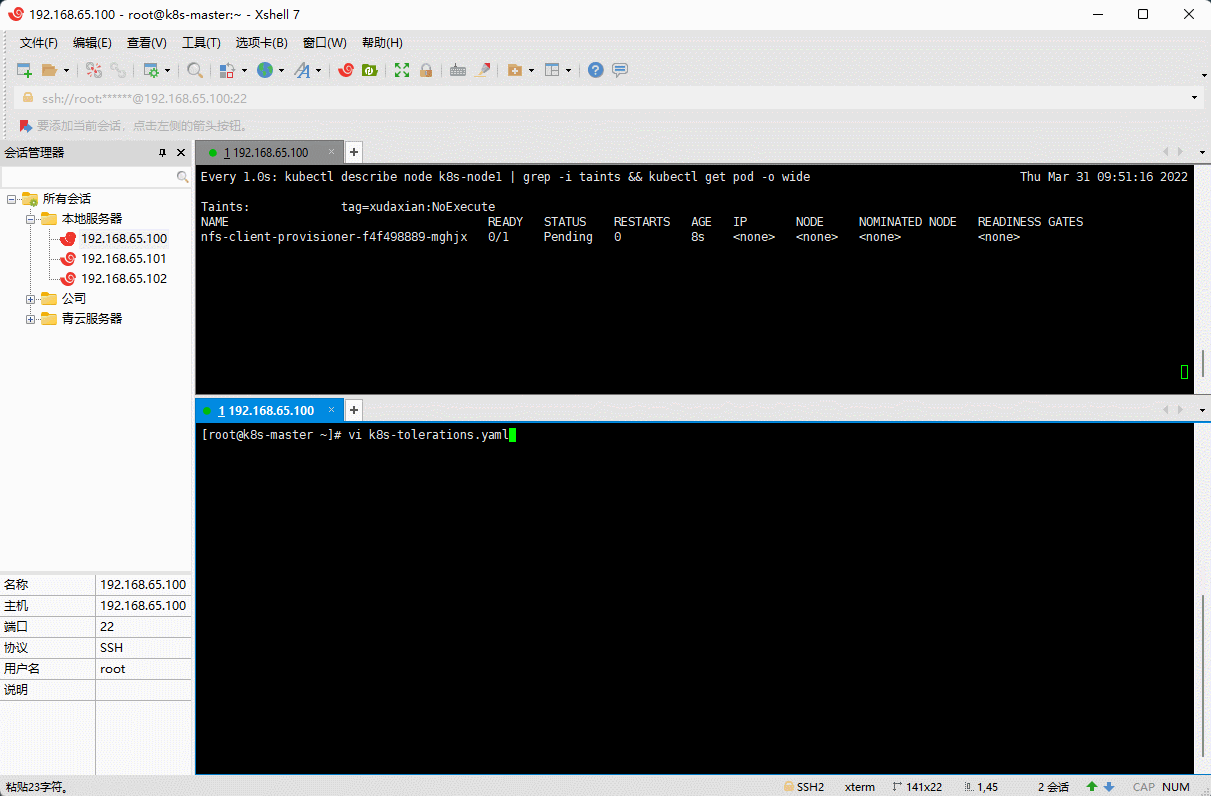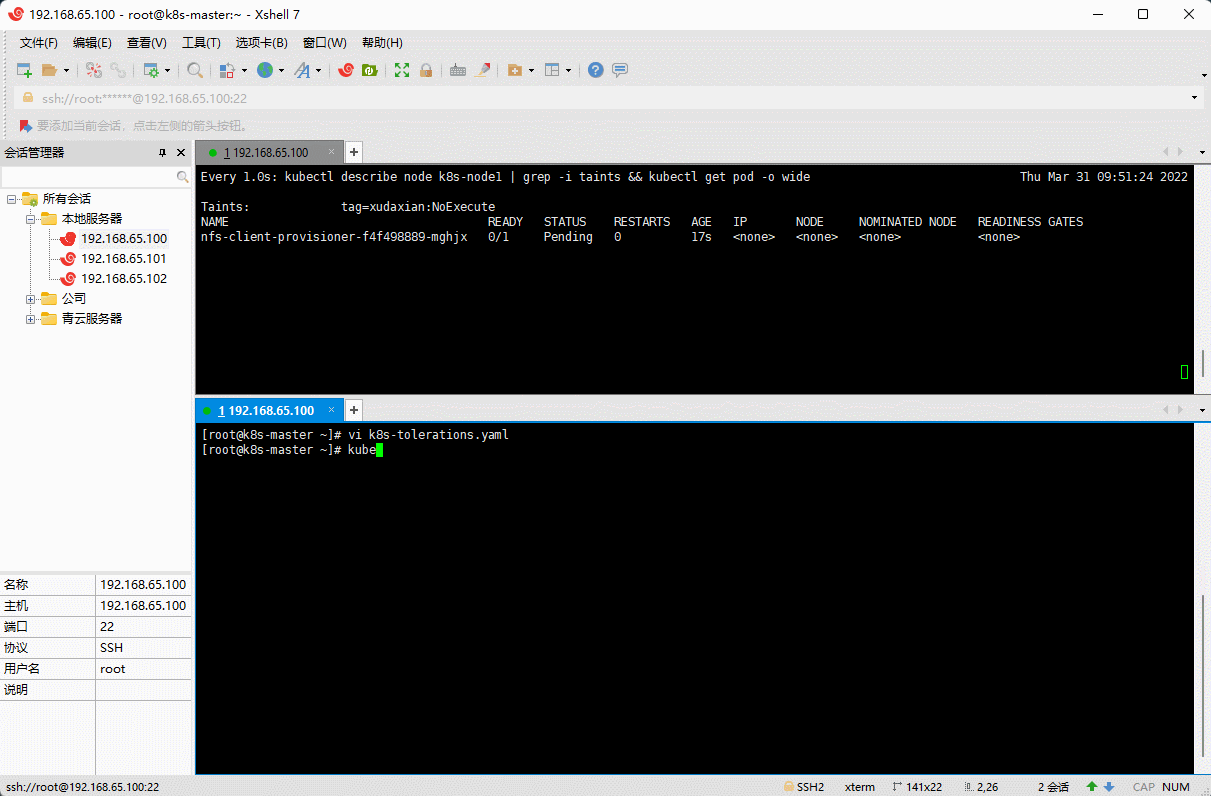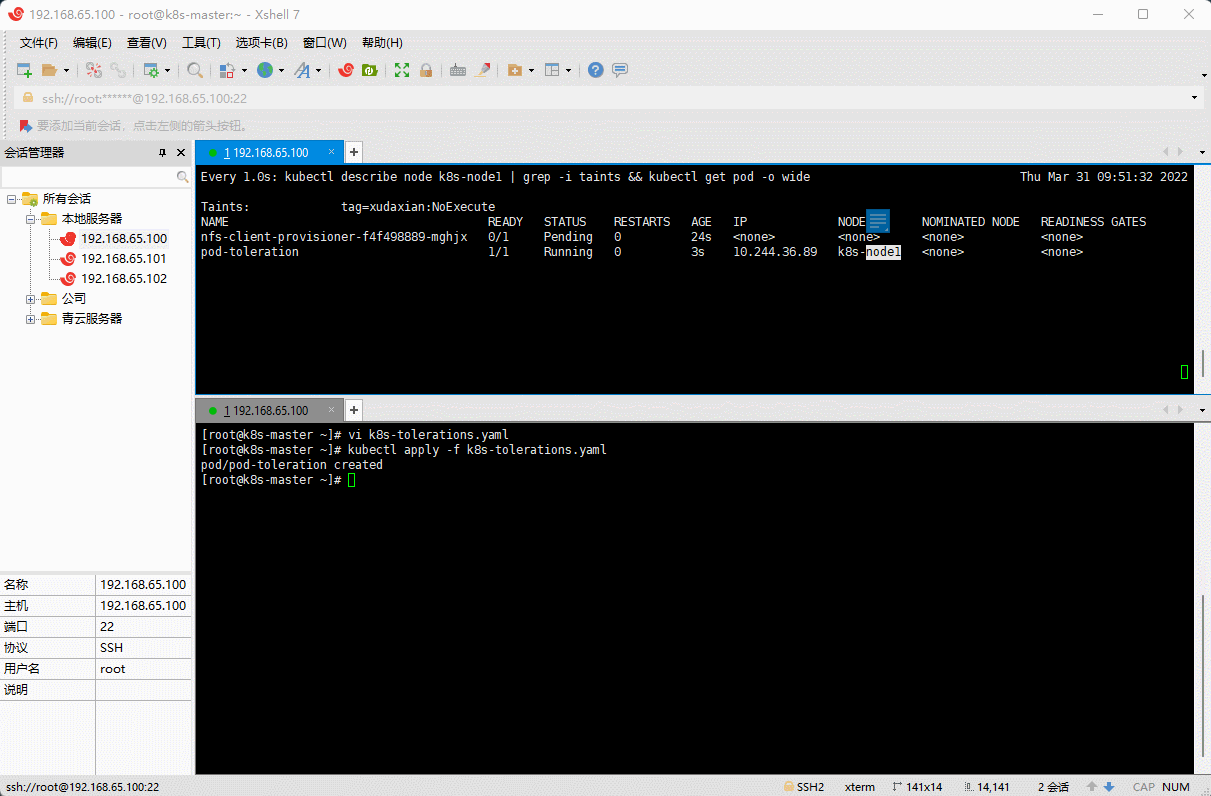
# 设置污点kubectl taint node k8s-node1 tag=xudaxian:NoExecute
vi k8s-tolerations.yaml
apiVersion: v1kind: Podmetadata:name: pod-tolerationspec:containers: # 容器配置- name: nginximage: nginx:1.20.2imagePullPolicy: IfNotPresentports:- name: nginx-portcontainerPort: 80protocol: TCPtolerations: # 容忍- key: "tag" # 要容忍的污点的keyoperator: Equal # 操作符value: "xudaxian" # 要容忍的污点的valueeffect: NoExecute # 添加容忍的规则,这里必须和标记的污点规则相同
kubectl apply -f k8s-tolerations.yaml

若有收获,就点个赞吧
0 人点赞
