1 主从复制
1.1 主从复制简介
1.1.1 互联网的 三高架构
- 高并发:可以保证系统能同时并发处理很多请求。
- 高性能:程序处理速度非常快,所占内存少,cpu 占用率低。
- 高可用:系统 7 * 24 小时,不宕机。
1.1.2 互联网三高架构之高可用
- 可用性:一年中应用服务正常运行的时间占全年时间的百分比。
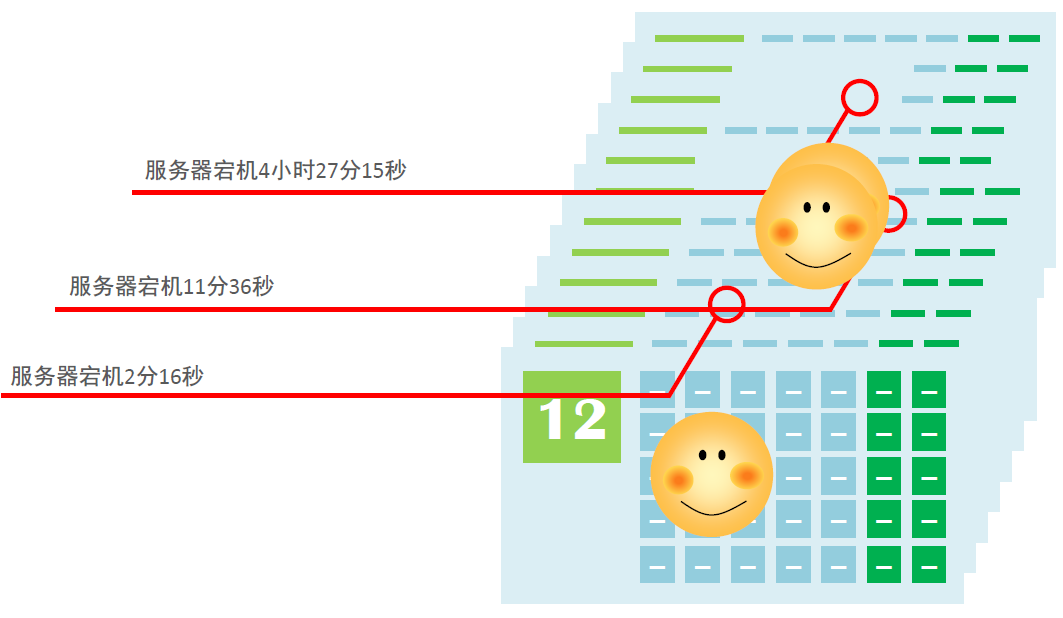
- 上图描述了应用服务在全年宕机的时间,我们将这些时间加到一起就是全年应用服务不可用的时间。
- 全年应用服务不可用的时间 = 4小时27分15秒 + 11分36秒+2分16秒 + 2分16秒 = 16867 秒。
- 全年的总时间 = 365 24 3600 = 31536000 秒。
- 可用性 = ((31536000 - 16867 )/ 31536000 )* 100 % = 99.9465151 %。
- 业界可用性目标是
5个9,即99.999%,即服务器年宕机时长低于315秒,约5.25分钟。
1.1.3 单机 Redis 的风险和问题
- 问题一:机器故障
- 现象:硬盘故障、系统崩溃。
- 本质:数据丢失,可能会业务造成灾难性打击。
- 结论:基本上会放弃使用 Redis 。
- 问题二:容量瓶颈
- 现象:内存不足,从 16 G 升级到 64 G ,从 64 G 升级到 128 G,无限升级内存。
- 本质:穷,硬件条件跟不上。
- 结论:基本上会放弃使用 Redis 。
- 结论:为了避免单点 Redis 服务器故障,准备多台服务器,互相连通。将数据复制多个副本保存在不同的服务器上,
连接在一起,并保证数据是同步的。即使有其中的一台服务器宕机了,其他的服务器依然可以继续提供服务,实现 Redis 的高可用,同时实现数据冗余备份。
1.1.4 多台服务器的连接方案
- 收集数据(写):master。
- 也可以称为:主服务器、主节点、主库。
- 连接的客户端称为:主客户端。
- 提供数据(读):slave。
- 也可以称为:从服务器、从节点、从库。
- 连接的客户端称为:从客户端。
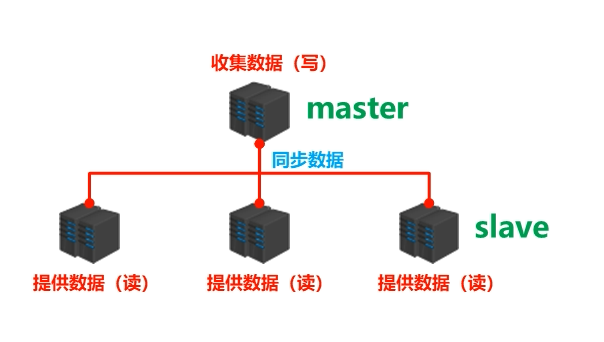
- 需要解决的问题:数据同步。
- 核心工作:将 master 的数据复制到 slave 中。
1.1.5 主从复制
- 主从复制:将 master 中的数据即时、有效的复制到 slave 中。
- 特征:一个 master 可以有多个 slave ,一个 slave 只能对应一个 master 。
- 职责:
- master:
- 写数据。
- 执行写操作的时候,将出现变化的数据自动同步到 slave 中。
- 读数据(可忽略)。
- slave:
- 读数据。
- 写数据(禁止)。
- master:
1.1.6 主从复制的作用
- ① 读写分离:master 写、slave 读,提高服务器的读写负载能力。
- ② 负载均衡:基于主从结构、配合读写分离,由 slave 分担 master 负载,并根据需求的变化,改变 slave 的数量,通过多个从节点分担数据读取负载,大大提高 Redis 服务器并发量和数据吞吐量。
- ③ 故障恢复:当 master 出现问题的时候,由 slave 提供服务,实现快速的故障恢复。
- ④ 数据冗余:实现数据热备份,是持久化之外的一种数据冗余方式。
- ⑤ 高可用基石:基于主从复制,构建哨兵模式和集群,实现 Redis 的高可用方案。
1.2 主从复制工作流程
1.2.1 主从复制过程
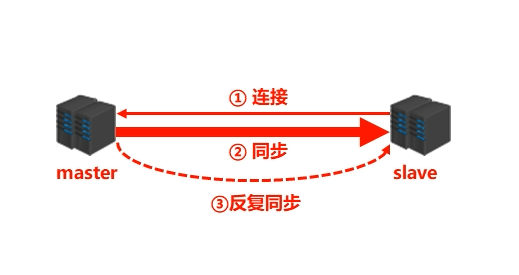
- 主从复制过程大体可以分为 3 个阶段:
- ① 建立连接阶段(即准备阶段)。
- ② 数据同步阶段。
- ③ 命令传播阶段。
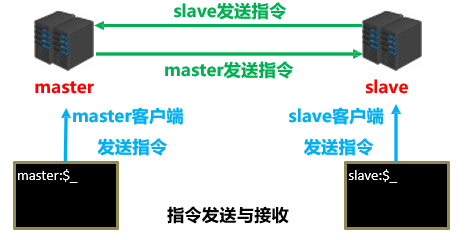
- 命令传播有 4 种,如下图所示:
1.2.2 准备工作
| 机器 | 角色 | 操作系统 |
|---|---|---|
| 192.168.65.100 | master | CentOS 7.9 |
| 192.168.65.101 | slave | CentOS 7.9 |
| 192.168.65.102 | slave | CentOS 7.9 |
学习过程中,可以将 Linux 服务器上的防火墙关闭,确保这三台机器能互相通信。
1.2.3 搭建主从复制
- 三台机器关闭防火墙:
systemctl stop firewalld
systemctl disable firewalld
- 三台机器都需要下载 Redis 的压缩包,并解压:
cd /opt
wget https://download.redis.io/releases/redis-5.0.10.tar.gz
tar -zxvf redis-5.0.10.tar.gz
- 三台机器都需要进入 Redis 的解压目录:
cd redis-5.0.10
- 三台机器都需要安装 c 语言编译环境:
yum -y install gcc-c++
- 三台机器修改 Redis 安装的目录路径:
vim src/Makefile
# 就 Redis 自身而言是不需要修改的,这里修改的目的是让 Redis 的运行程序不要和其他文件混杂在一起。PREFIX?=/usr/local/redis
- 三台机器编译安装 Redis:
make && make install
- 三台机器复制 redis.conf 文件到 /usr/local/redis :
cp redis.conf /usr/local/redis/
- 修改 192.168.65.100(master) 机器上的 Redis 的配置文件:
cd /usr/local/redis/
vim redis.conf
# 需要注释掉 bind# bind 127.0.0.1# 将保护模式关闭protected-mode no# 需要以守护进程方式启动daemonize yes# 需要配置日志logfile "/usr/local/redis/redis.logs"# 需要配置 rdb 文件的目录dir /usr/local/redis# 将 AOF 功能打开appendonly yes# 其他配置保存默认
- 修改 192.168.65.101 和 192.168.65.102(slave) 机器上的 Redis 的配置文件:
cd /usr/local/redis/
vim redis.conf
# 需要注释掉 bind# bind 127.0.0.1# 将保护模式关闭protected-mode no# 需要以守护进程方式启动daemonize yes# 需要配置日志logfile "/usr/local/redis/redis.logs"# 需要配置 rdb 文件的目录dir /usr/local/redis# 将 AOF 功能打开appendonly yes# 增加配置slaveof 192.168.65.100 6379# 其他配置保存默认
- 分别启动三台机器上的 Redis 服务(先启动 master 机器上的 Redis 服务,再 启动 slave 机器上的 Redis 服务):
/usr/local/redis/bin/redis-server /usr/local/redis/redis.conf
- 分别使用各自机器上 redis-cli 连接各自的 Redis 服务:
/usr/local/redis/bin/redis-cli
- 使用 info replication 查看主从复制信息:
info replication
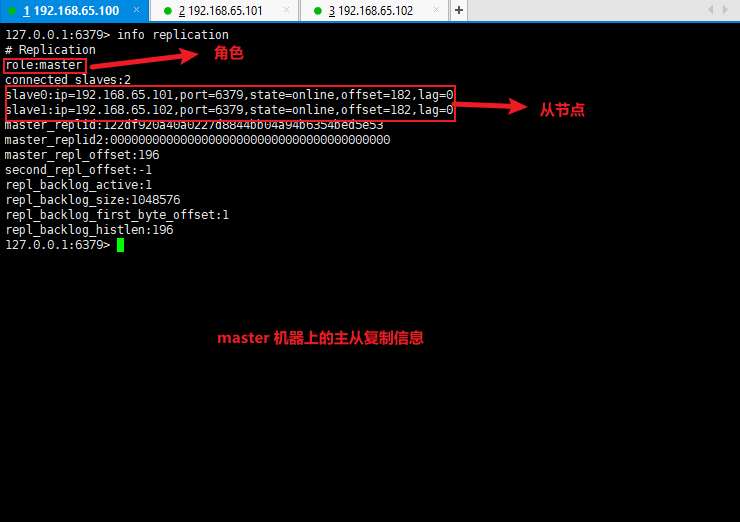
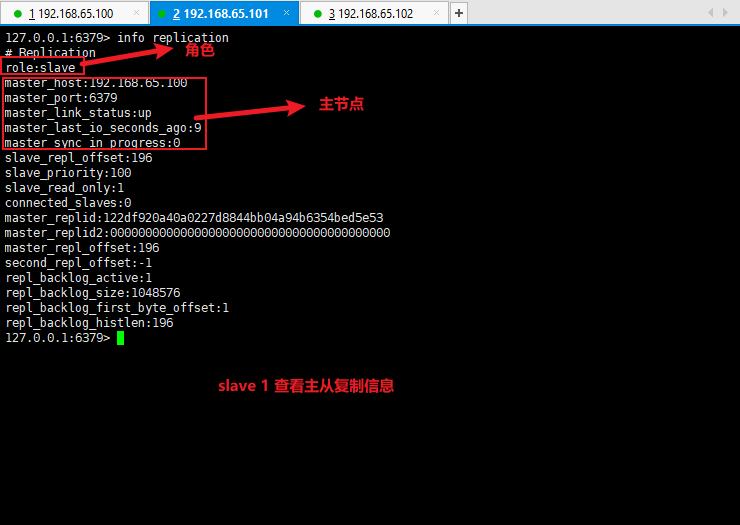
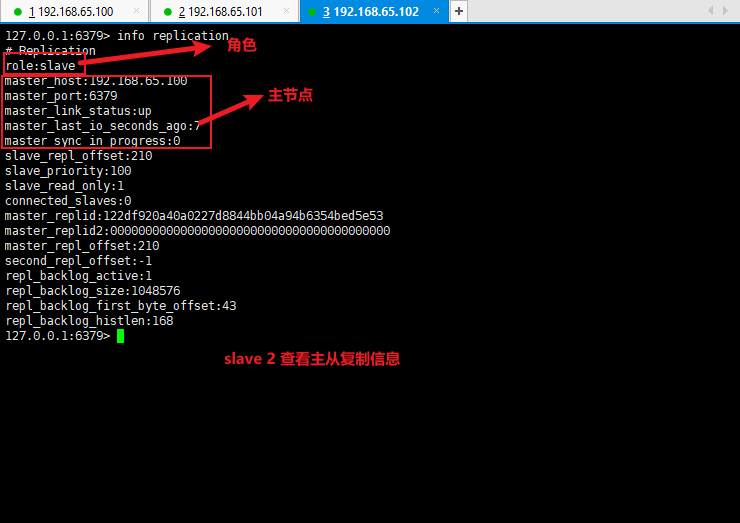
- 测试主从复制是否搭建成功:
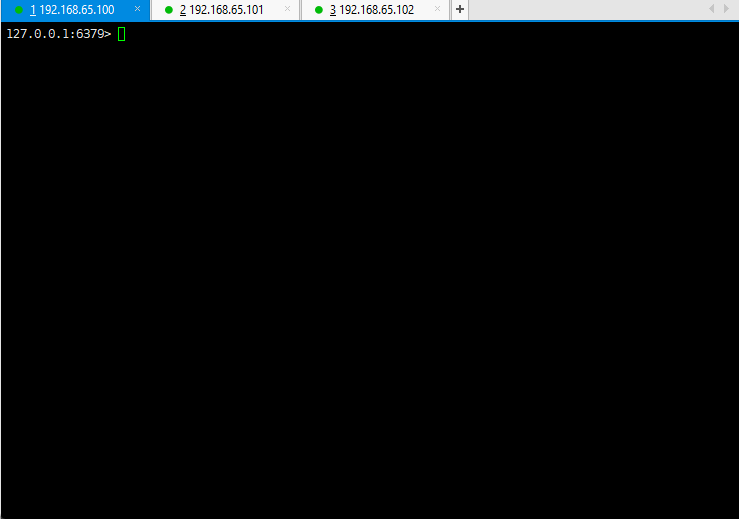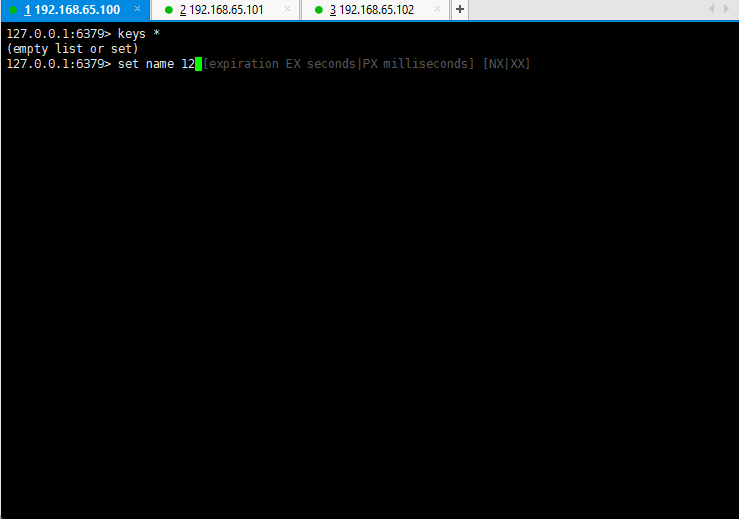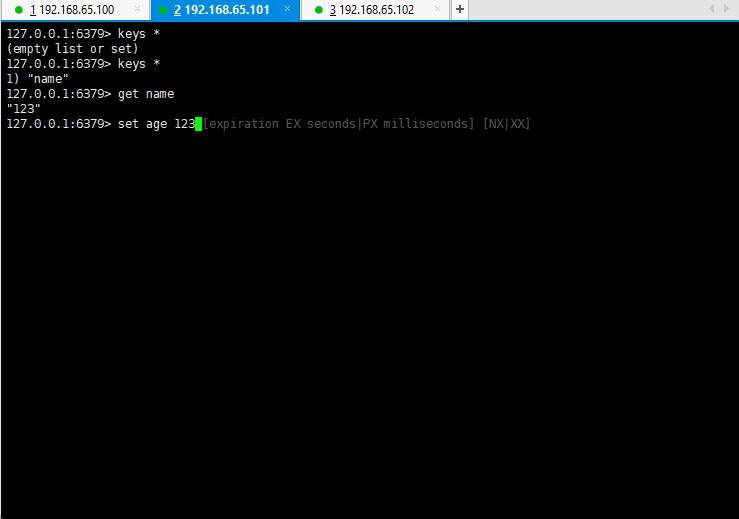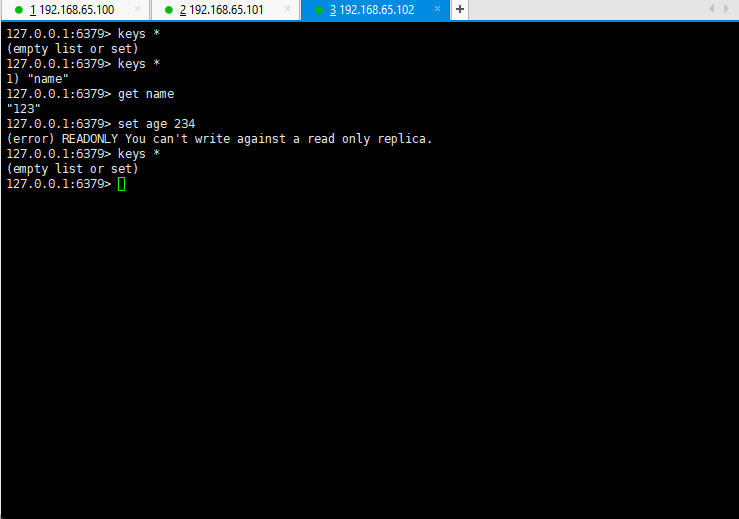
1.2.4 搭建主从复制的细节
slave 连接 master 的方式(无认证『需要用户名或密码登录』方式):
① 客户端发送命令:
# 可以,但是不推荐slaveof <master.ip> <master.port>
② 客户端启动服务器,增加连接参数:
# 可以,但是不推荐./redis-server -slaveof <master.ip> <master.port>
③ 客户端服务器配置(推荐):
# 直接在配置文件中配置,推荐,上面的案例中就使用的此种方式slaveof <master.ip> <master.port>
slave 主动断开连接(客户端发送命令):
slaveof no one
slave 连接 master 的方式(认证方式):
master 配置文件中设置密码(推荐):
# 推荐# 需要注释掉 bind# bind 127.0.0.1# 将保护模式开启protected-mode yes# 设置密码requirepass <password>
master 客户端发送命令设置密码:
config set requirepass <password>
config get requirepass
slave 客户端发送命令设置密码:
auth <password>
slave 配置文件设置密码(推荐):
masterauth <password>
其余的和
slave 连接 master 的方式(无认证『需要用户名或密码登录』方式)相同。- 启动客户端设置密码:
./redis-cli -a <password>
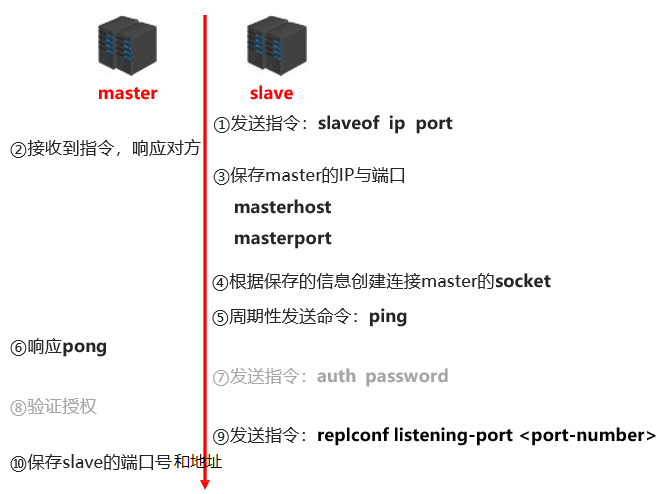
1.2.5 主从复制阶段一:建立连接阶段工作流程
- 建立 salve 到 master 的连接,使得 master 能够识别到 slave ,并保存 slave 的 IP 和 端口号。
- 步骤:
- 步骤 1 :slave 设置 master 的地址和端口,连接成功后,在 slave 端保存 master 的信息。
- 步骤 2 :slave 根据 保存的信息创建连接到 master 的 socket 连接。
- 步骤 3 :slave 周期性的发送 ping 命令。
- 步骤 4 :如果 master 开启了授权验证,那么 slave 还需要发送
auth password指令,进行身份验证。 - 步骤 5 :slave 发送 端口信息给 master,master 保存对应的 IP 和 端口。
- 至此,连接成功。
- 当前状态:
- slave :保存 master 的地址和端口号。
- master:保存 slave 的地址和端口号。
- 总体:master 和 slave 之间创建了连接的 socket 。
1.2.6 主从复制阶段二:数据同步阶段工作流程
- 将 slave 的数据库状态更新成 master 当前的数据库状态。
- 步骤:
- 步骤 1 :slave 请求同步数据。
- 步骤 2 :master 创建 RDB 文件,同步数据。
- 步骤 3 :slave 接收 RDB 文件,清空旧的数据,执行 RDB 文件恢复过程。
- 步骤 4 :slave 请求部分同步数据。
- 步骤 5 :master 发送复制缓冲区信息,slave 恢复部分同步数据。
- 至此,数据同步工作完成。
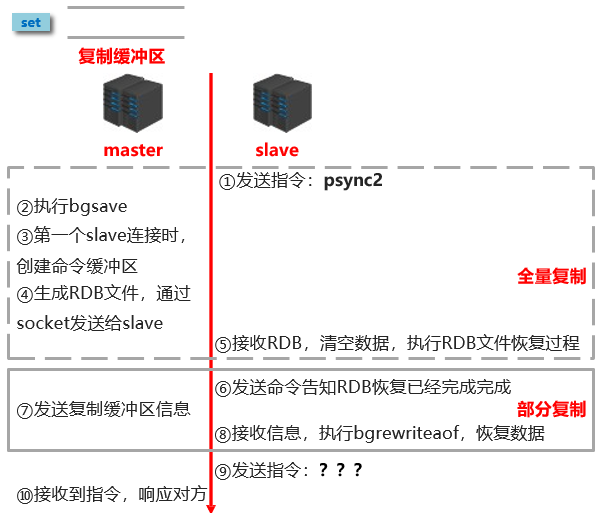
- 状态:
- slave:具有 master 端全部的数据,包含 RDB 过程接收的数据。
- master:保存 slave 当前数据同步的位置。
- 总体:master 和 slave 之间完成了数据复制工作。
- 数据同步阶段 master 说明:
- ① 如果 master 数据量巨大,数据同步阶段应该避开流量高峰期,避免造成 master 阻塞,影响业务正常执行。
- ② 复制缓冲区大小设定不合理,会导致数据溢出。如:进行全量复制周期太长,进行部分复制时发现数据已经存在丢失的情况,必须进行第二次全量复制,导致 slave 陷入死循环状态。
master 端修改 redis.conf 文件:
repl-backlog-size ?mb
怎么修改?master 单机内存占用主机内存的比例不能过大,建议使用 50 % ~ 70 %的内存,留下 30 % ~ 50 % 的内存用于执行 bgsave 命令和创建复制缓冲区。
- 数据同步阶段 slave 说明:
① 为避免 slave 进行全量复制、部分复制的时候服务器响应阻塞或数据不同步,建议在此期间关闭对外服务。
# yes 表示主从复制中,从服务器可以响应客户端请求;# no 表示主从复制中,从服务器将阻塞所有请求,有客户端请求时返回“SYNC with master in progress”;slave-serve-stale-data yes|no
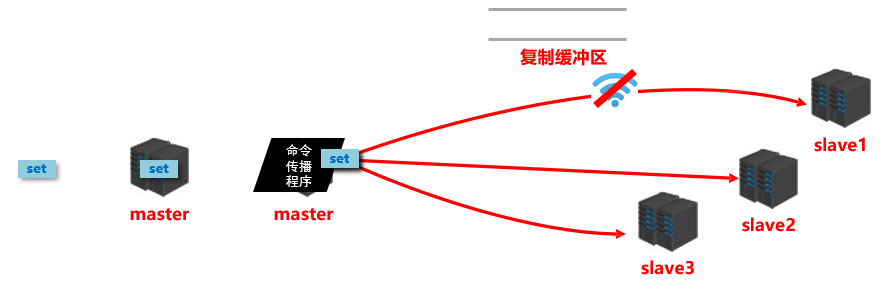
② 数据同步阶段,master 发送给 slave 的信息可以理解为 master 是 slave 的一个客户端,主动向 slave 发送命令。
- ③ 多个 slave 同时对 master请求数据同步,master 发送的 RDB 文件增多,会对带宽造成巨大冲击,如果 master 带宽不足,那么数据同步需要根据业务需求,适量错峰。
- ④ slave 过多的时候,建议调整拓扑结构,由一主多从变为树状结构,中间的节点既是 master,也是 slave。需要注意的是,使用树状结构时,由于层次深度,导致深度越高的 slave 和最顶层的 master 间数据同步延迟较大,数据一致性较差,应该慎重选择。
1.2.7 主从复制阶段三:命令传播阶段工作流程
- 当 master 数据库状态被修改后,导致主从服务器数据库状态不一致,此时需要让主从数据同步到一致的状态,同步的动作称为命令传播。
- master 将接收到的数据变更命令发送给 slave , slave 接收命令后执行命令。
- 命令传播阶段出现断网现象:
- 网络闪断闪连:忽略。
- 长时间网络中断:全量复制。
- 短时间网络中断:部分复制。
- 部分复制的三个核心要素:
- ① 服务器的运行 id (run id)。
- 概念:服务运行 id 是每一台服务器每次运行的身份标识码,一台服务器多次运行可以生成多个运行的 id 。
- 组成:运行 id 由 40 位字符串组成,是一个随机的十六进制字符。如:ad4216aa881930e5f3380679d87324196cfe0866 。
- 作用:运行 id 被用于在服务器进行传输的时候,谁别身份。如果想两次操作均对同一台服务器进行,必须每次操作携带对应的运行 id ,用于对方识别。
- 实现方式:运行 id 在每台服务器启动的时候自动生成的,master 在首次连接 slave 的时候,会将自己的运行 id 发送给 slave ,slave 保存此 id ,通过 Info server 命令,可以查看节点的运行 id 。
- ② 主服务器的复制积压缓冲区。
- 概念:复制缓冲区,又名复制积压缓冲区,是一个先进先出(FIFO)的队列,用于存储服务器执行过的命令,每次传播命令,master 都会将传播的命令记录下来,并存储在复制缓冲区。
- ① 服务器的运行 id (run id)。
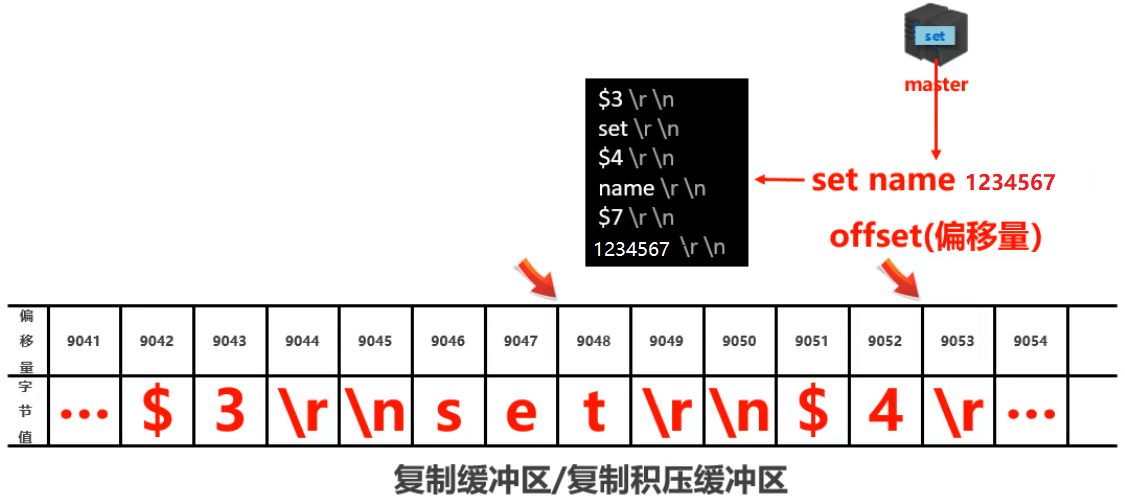
- 复制缓冲区内部工作原理:- 组成:- 偏移量。- 字节值。- 工作原理:- 通过 offset 区别不同的 slave 当前数据传播的差异。- master 记录已发送的信息对应的 offset 。- slave 记录已接收的信息对应的 offset 。
- 由来:每台服务器启动的时候,如果开启 AOF 或被连接称为 master 节点,就会创建复制缓冲区。- 作用:用于保存 master 接收到的所有指令(仅影响数据变更的指令,如:set、select 等)。- 数据来源:当 master 接收到主客户端的指令的时候,除了将指令执行,还会将指令存储到缓冲区中。
- ③ 主从服务器的复制偏移量:
- 概念:一个数字,描述复制缓冲区中的指令字节位置。
- 分类:
- master 复制偏移量:记录发送给所有 slave 的指令对应字节的位置(多个)。
- slave 复制偏移量:记录 slave 接收 master 发送过来的指令字节对应的位置(一个)。
- 数据来源:
- master 端:发送一次记录一次。
- slave 端:接收一次记录一次。
- 作用:同步信息,比对 master 和 slave 的差异,当 slave 断线后,恢复数据使用。
1.2.8 数据同步 + 命令传播阶段工作流程
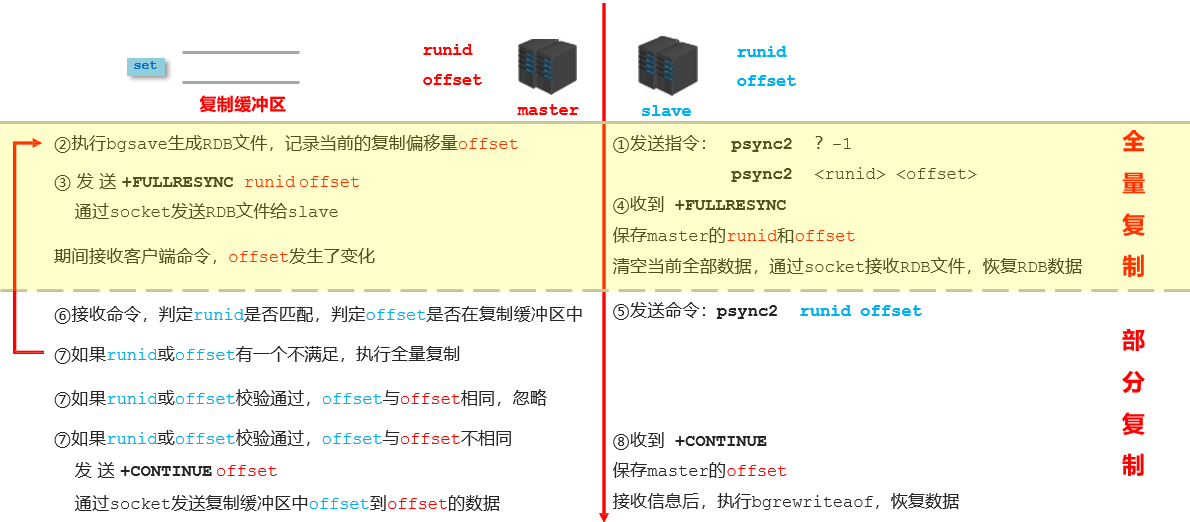
1.2.9 心跳机制
- 进入命令传播阶段后,master 和 slave 之间需要进行信息交换,使用心跳机制进行维护,实现双方连接保持在线。
- master 心跳:
- 指令:ping 。
- 周期:由 repl-ping-replica-period 决定,默认为 10 。
- 作用:判断 slave 是否在线。
- 查询:info replication,获取 slave 最后一次连接时间间隔,lag 项位置在 0 或 1 视为正常。
- slave 心跳任务:
- 执行:replconf ack {offset} 。
- 周期:1 秒。
- 作用 1 :汇报 slave 自己的复制偏移量,获取最新的数据变更指令。
- 作用 2 :判断master 是否在线。
心跳阶段注意事项:
当 slave 多数掉线,或延迟过高时,master 为保证数据的稳定性,将拒绝所有信息同步操作。
min-slaves-to-write 2min-slaves-max-lag 8# slave 数量少于 2 个,或者所有 slave 的延迟都大于等于 8 秒的时候,强制关闭 master 的写功能,停止数据同步
slave 数量由 slave 发送 replconf ack 命令确认。
- slave 延迟由 slave 发送 replconf ack 命令确认。
1.2.10 主从复制工作完整流程

1.3 主从复制常见问题
1.3.1 频繁的全量复制(1)
- 伴随着系统的运行,master 的数据量会越来越大,一旦发生 master 重启,run id 将发生变化,会导致全部 slave 全量复制操作。
- 内部优化调整方案:
- ① master 内部创建 master_replid 变量,使用 run id 相同的策略生成,长度 41 位,并发送给所有 slave 。
- ② 在 master 关闭时执行 shutdown save 命令,进行 RDB 持久化,将 run id 和 offset 保存到 RDB 文件中。
- repl-id 、repl-offset。
- 通过 redis-check-rdb 命令可以查看该信息。

- ③ master 重启后加载 RDB 文件,恢复数据。
- 重启后,将 RDB 文件中保存的 repl-id 和 repl-offset 加载到内存中。
- master_replid = repl-id 。
- master_repl_offset = repl-offset 。
- 通过 info 命令可以查看该信息。
- 作用:本机保存上次的 run id,重启后恢复该值,使得所有的 slave 认为还是之前的 master 。
1.3.2 频繁的全量复制(2)
- 问题现象:网络环境不佳,出现网络中断,slave 不提供服务。
- 问题原因:赋值缓冲区过小,断网后 slave 的 offset 越界,触发全量复制。
- 最终结果:slave 反复进行全量复制。
- 解决方案:修改复制缓冲区大小(repl-backlog-size)。
- 建议设置:
- ① 测算从 master 到 slave 的重连平均时长 second 。
- ② 获取 master 平均每秒产生写命令数据总量 write_size_per_second 。
- ③ 最优复制缓冲区空间 = 2 second write_size_per_second 。
1.3.3 频繁的网络中断(1)
- 问题现象:master 的 CPU 占用过高或 slave 频繁断开连接。
- 问题原因:
- ① slave 每秒发送 replconf ack 命令到 master 。
- ② 当 slave 接收到了慢查询(keys *,hgetall 等),会大量占用 CPU 性能。
- ③ master 每 1 秒调用复制定时函数 replicationCron(),比对 slave发现长时间没有进行响应。
- 最终结果:master 各种资源(输出缓冲区、带宽、连接等)被严重占用。
- 解决方案:通过设置合理的超时时间,确认是否释放 slave 。
# 该参数定义了超时时间的阈值(默认为 60 秒),超过该值,释放 slaverepl-timeout seconds
1.3.4 频繁的网络中断(2)
- 问题现象:slave 和 master 连接断开。
- 问题原因:
- ① master 发送 ping 指令频率较低。
- ② master 设定超时时间较短。
- ③ ping 指令在网络中存在丢包。
- 解决方案:提高 ping 指令发送的频率。
# 超时时间 repl-time 的时间至少是 ping 指令频度的 5 ~ 10 倍,否则 slave 很容易判断超时repl-ping-slave-period seconds
1.3.4 数据不一致
- 问题现象:多个 slave 获取相同数据不同步。
- 问题原因:网络信息不同步,数据发送有延迟。
- 解决方案:
- ① 优化主从间的网络环境,通常放置在同一个机房部署,如果使用阿里云等云服务器的时候需要注意此现象。
- ② 监控主从节点延迟(通过 offset)判断,如果 slave 延迟过大,暂时屏蔽程序对该 slave 的数据访问。
# 开启后仅响应 info、slaveof 等少数命令(慎用,除非对数据一致性要求很高)slave-serve-stale-data yes|no
2 哨兵模式
2.1 哨兵简介
2.1.1 哨兵概念
- 如果 Redis 的 master 宕机了,此时应该怎么办?
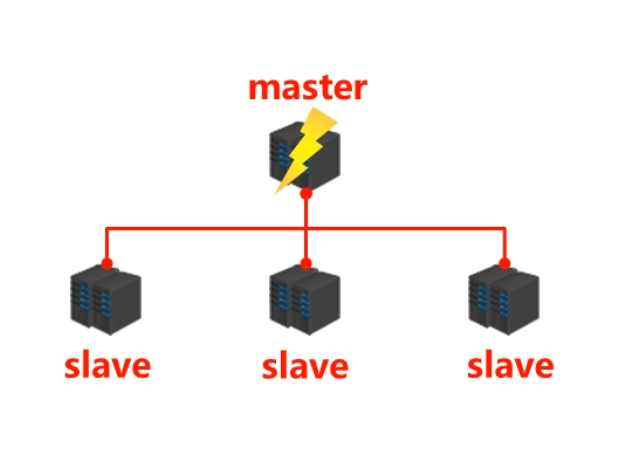
- 需要从一堆 slave 中重新选举出一个新的 master,那么整个操作过程是怎么样的?会出现什么问题?
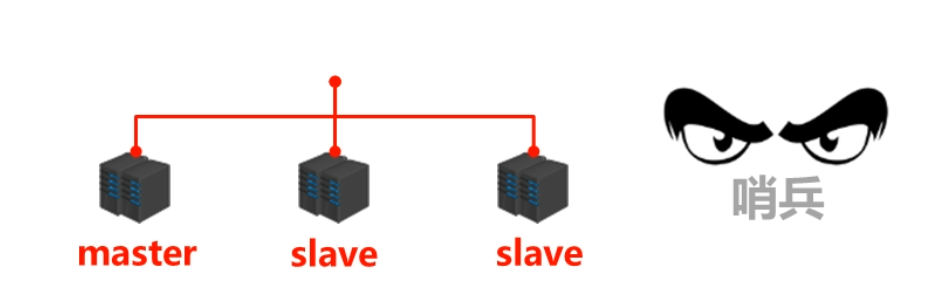
- 操作过程:
- ① 将宕机的 master 下线。
- ② 找一个 slave 作为 master 。
- ③ 通过所有的 slave 连接到新的 master 。
- ④ 启动新的 master 和 slave 。
- ⑤ 全量复制 N + 部分复制 N 。
- 出现问题:
- ① 谁来确认 master 宕机了。
- ② 找一个主节点?怎么找?
- ③ 修改配置后,原始的主节点恢复后怎么办?
- 要实现上面的功能,就需要哨兵。
2.1.2 哨兵简介
- 哨兵(Sentinel)是一个分布式系统,用于对主从结构中的每台服务器进行
监控,当出现故障的时候通过投票机制选择新的 master并将所有的 slave 连接到新的 master 。
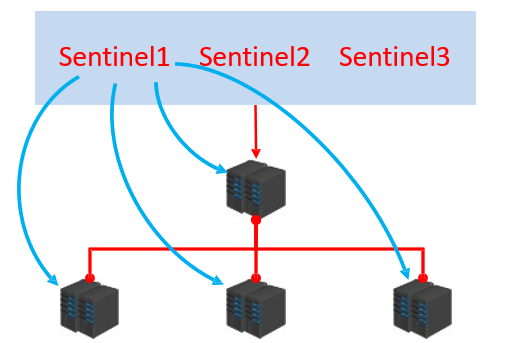
2.1.3 哨兵作用
- ① 监控:
- 不断的检查 master 和 slave 是否正常运行。
- master 存活检测、master 和 slave 运行情况检测。
- ② 通知(提醒):当被监控的服务器出现问题的时候,向其他(哨兵间、客户端)发送通知。
- ③ 自动故障转移:断开 master 和 slave 之间的连接,选取一个 slave 作为 master ,将其它 slave 连接到新的 master 上,并告知客户端新的服务器地址。
注意:
- 哨兵也是一台 Redis 服务器,只是不提供数据服务。
- 通常哨兵配置数量为单数。
2.2 搭建哨兵
- ① 配置一主二从的主从结构(略)。 | 机器 | 角色 | 操作系统 | 是否配置哨兵 | | —- | —- | —- | —- | | 192.168.65.100 | master | CentOS 7.9 | 是 | | 192.168.65.101 | slave | CentOS 7.9 | 是 | | 192.168.65.102 | slave | CentOS 7.9 | 是 |
- ② 配置三个哨兵(三台机器复制 sentinel 文件到 /usr/local/redis):
cd /opt/redis-5.0.10
cp sentinel.conf /usr/local/redis
sentinel.conf 中重要的配置如下:
设置哨兵监听的主服务信息,sentinel_number 表示参与投票的哨兵的数量(通常为哨兵数量 / 2 + 1):
sentinel monitor master_name 127.0.0.1 6379 2
设置判定主服务器宕机时长,该设置控制是否进行主从切换:
sentinel down-after-milliseconds mymaster 30000
设置故障切换的最大超时时间:
sentinel failover-timeout mymaster 180000
设置主从切换后,同时进行数据同步的slave数量,数值越大,要求网络资源越高,数值越小,同步时间越长:
sentinel parallel-syncs mymaster 1
修改三台机器上的 Sentinel 的配置:
cd /usr/local/redis
vim sentinel.conf
port 26379daemonize yespidfile /var/run/redis-sentinel.pidlogfile "/usr/local/redis/sentinel.logs"dir /usr/local/redis/sentinel monitor mymaster 127.0.0.1 6379 2sentinel down-after-milliseconds mymaster 30000sentinel parallel-syncs mymaster 1sentinel failover-timeout mymaster 180000sentinel deny-scripts-reconfig yes
- ③ 启动哨兵(三台机器都运行此命令,先启动主机,再启动从机,最后再启动哨兵):
/usr/local/redis/bin/redis-sentinel /usr/local/redis/sentinel.conf
2.3 工作原理
2.3.1 哨兵在进行主从切换过程中经历三个阶段
- ① 监控。
- ② 通知。
- ③ 故障转移。
2.3.2 监控阶段
- 用于同步各个节点的状态信息。
- 获取各个 sentinel 的状态(是否在线)。
- 获取 master 的状态:
- master 属性:run id 和 role :master。
- 各个 slave 的详细信息。
- 获取所有 slave 的状态(根据 master 中的 slave 信息)
- slave 属性:
- run id。
- role :slave 。
- master_host、master_port。
- offset。
- ……
- slave 属性:
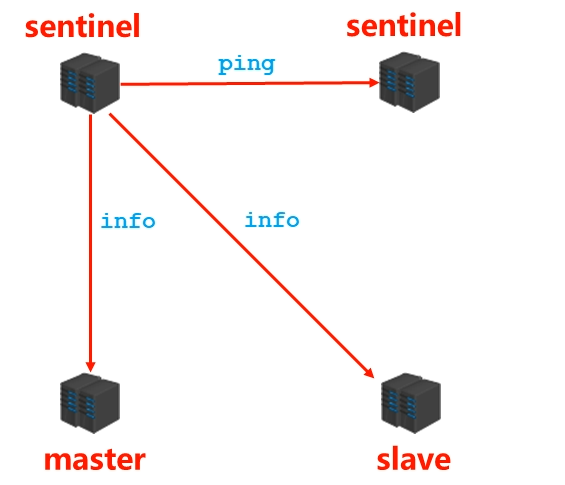
2.3.3 通知阶段
- sentinel 在通知阶段要不断的去获取 master/slave 的信息,然后在各个 sentinel 之间进行共享,具体的流程如下:
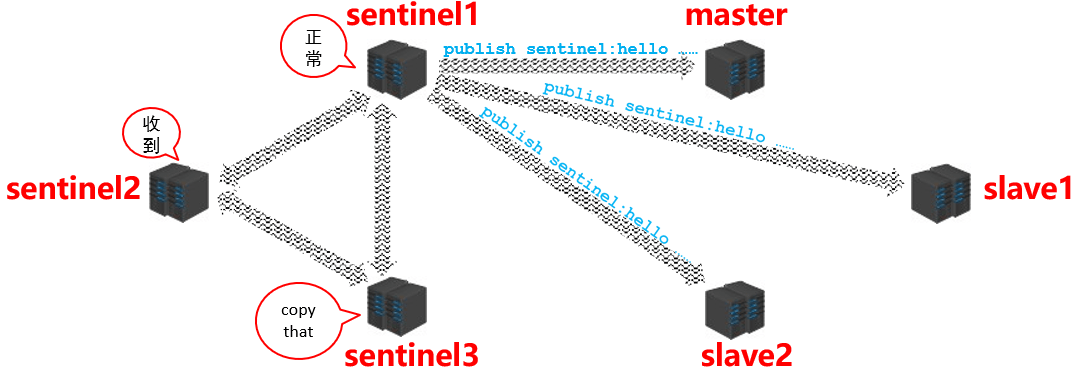
2.3.4 故障转移
- 当 master 宕机后 sentinel 是如何知晓并判断出 master 是真的宕机了呢?我们来看具体的操作流程:
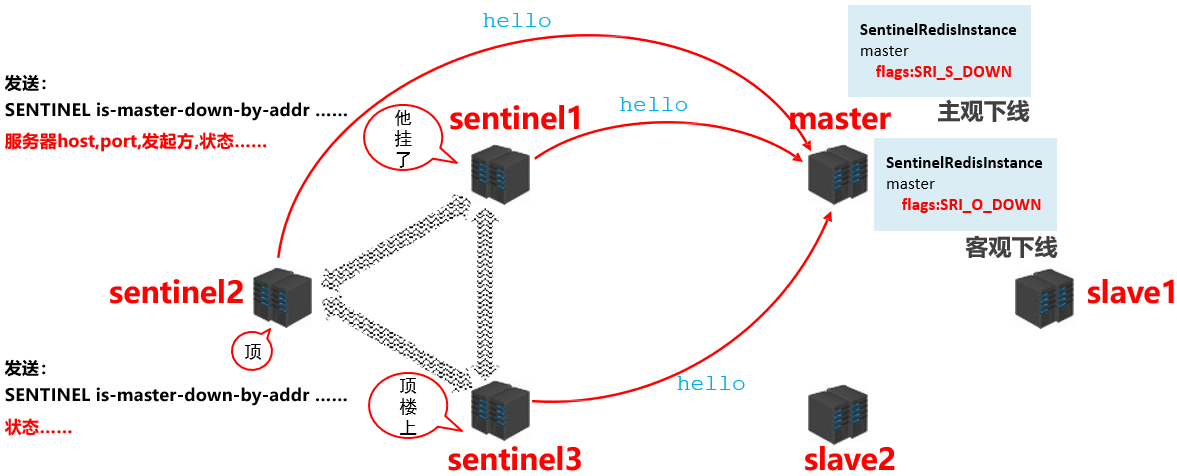
- 当 sentinel 认定 master 下线之后,此时需要决定更换 master,那这件事由哪个 sentinel 来做呢?这时候 sentinel 之间要进行选举,如下图所示:
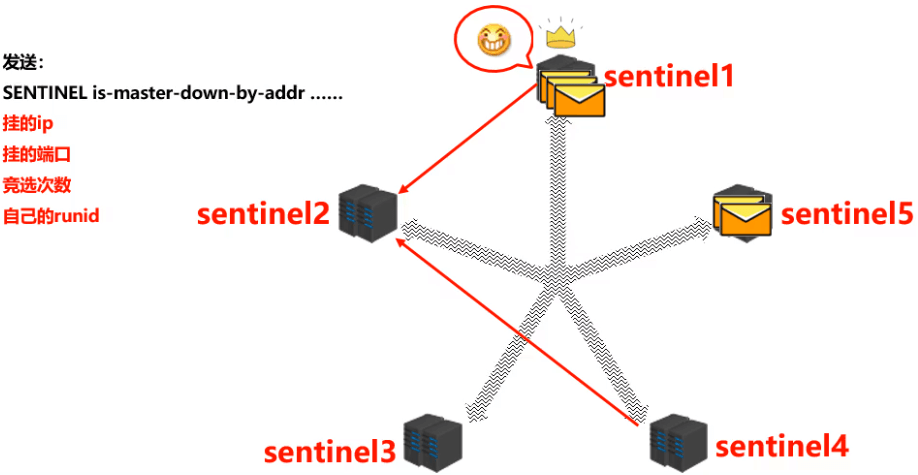
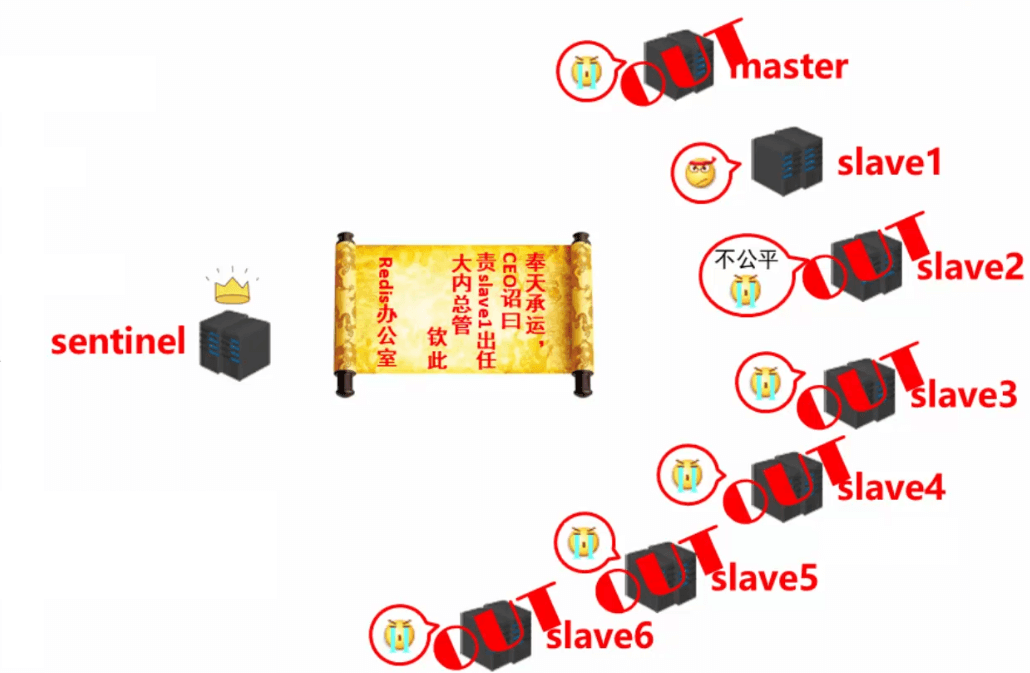
- 由选举胜出的 sentinel 去从slave中选一个新的 master 出来的工作:
- 不在线的 OUT 。
- 响应慢的 OUT 。
- 与原 master 断开时间久的 OUT 。
- 优先原则:优先级、offset、run id 。
- 选出新的master之后,发送指令( sentinel )给其他的 slave:
- 向新的 master 发送 slaveof no one 。
- 向其他 slave 发送 slaveof 新masterIP 端口。
2.3.6 总结
- 监控:同步信息。
- 通知:保持联通。
- 故障转移:
- 发现问题。
- 竞选负责人。
- 优选新 master 。
- 新 master 上任,其他 slave 切换 master ,原来的 master 作为 slave 故障恢复后连接。
2.4 SpringBoot 整合 Redis 的 哨兵模式
2.4.1 准备工作
- IDEA 2021+。
- JDK 11。
- Maven 3.8。
- SpringBoot 2.6.1。
Redis 5.0.10。
pom.xml
<?xml version="1.0" encoding="UTF-8"?><project xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xmlns="http://maven.apache.org/POM/4.0.0"xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 https://maven.apache.org/xsd/maven-4.0.0.xsd"><modelVersion>4.0.0</modelVersion><parent><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-parent</artifactId><version>2.6.1</version><relativePath/></parent><groupId>com.example</groupId><artifactId>redis</artifactId><version>1.0</version><name>redis</name><description>redis</description><properties><java.version>11</java.version><skipTests>true</skipTests></properties><dependencies><dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-data-redis</artifactId></dependency><dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-web</artifactId></dependency><dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-test</artifactId><scope>test</scope></dependency><dependency><groupId>org.projectlombok</groupId><artifactId>lombok</artifactId><optional>true</optional></dependency><dependency><groupId>cn.hutool</groupId><artifactId>hutool-all</artifactId><version>5.7.17</version></dependency><dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-thymeleaf</artifactId></dependency></dependencies><build><plugins><plugin><groupId>org.springframework.boot</groupId><artifactId>spring-boot-maven-plugin</artifactId><version>2.6.1</version><configuration><excludes><exclude><groupId>org.projectlombok</groupId><artifactId>lombok</artifactId></exclude></excludes></configuration></plugin><plugin><groupId>org.apache.maven.plugins</groupId><artifactId>maven-compiler-plugin</artifactId><version>3.8.1</version></plugin></plugins></build><repositories><repository><id>aliyunmaven</id><url>https://maven.aliyun.com/repository/public</url><releases><enabled>true</enabled></releases><snapshots><enabled>true</enabled></snapshots></repository><repository><id>spring</id><url>https://maven.aliyun.com/repository/spring</url><releases><enabled>true</enabled></releases><snapshots><enabled>true</enabled></snapshots></repository><repository><id>spring-releases</id><url>https://repo.spring.io/libs-release</url><releases><enabled>true</enabled></releases><snapshots><enabled>true</enabled></snapshots></repository></repositories><pluginRepositories><pluginRepository><id>spring-releases</id><url>https://repo.spring.io/libs-release</url></pluginRepository></pluginRepositories></project>
2.4.2 配置文件
- application.yml
server:port: 18082spring:redis: # redisdatabase: 0 # 数据库索引,默认为 0timeout: 1800000 # 连接超时时间(毫秒),默认为 0 ,表示永不超时lettuce:pool:max-active: 20 # 连接池的最大连接数(负数表示没有限制)max-wait: -1 # 连接池的最大阻塞等待时间(负数表示没有限制)max-idle: 5 # 连接池的最大空闲连接min-idle: 0 # 连接池的最小空闲连接client-type: lettuce# sentinel 配置sentinel:master: mymasternodes:- 192.168.65.100:26379- 192.168.65.101:26379- 192.168.65.102:26379
2.4.3 配置类
package com.github.fairy.era.redis.config;import com.fasterxml.jackson.annotation.JsonAutoDetect;import com.fasterxml.jackson.annotation.JsonTypeInfo;import com.fasterxml.jackson.annotation.PropertyAccessor;import com.fasterxml.jackson.databind.ObjectMapper;import com.fasterxml.jackson.databind.jsontype.impl.LaissezFaireSubTypeValidator;import org.springframework.cache.CacheManager;import org.springframework.cache.annotation.CachingConfigurationSelector;import org.springframework.cache.annotation.EnableCaching;import org.springframework.context.annotation.Bean;import org.springframework.context.annotation.Configuration;import org.springframework.data.redis.cache.RedisCacheConfiguration;import org.springframework.data.redis.cache.RedisCacheManager;import org.springframework.data.redis.connection.RedisConnectionFactory;import org.springframework.data.redis.core.RedisTemplate;import org.springframework.data.redis.serializer.Jackson2JsonRedisSerializer;import org.springframework.data.redis.serializer.RedisSerializationContext;import org.springframework.data.redis.serializer.RedisSerializer;import org.springframework.data.redis.serializer.StringRedisSerializer;import java.time.Duration;/*** @author 许大仙* @version 1.0* @since 2021-12-13 11:02*/@Configuration@EnableCachingpublic class RedisConfig extends CachingConfigurationSelector {@Beanpublic RedisTemplate<String, Object> redisTemplate(RedisConnectionFactory factory) {RedisTemplate<String, Object> template = new RedisTemplate<>();RedisSerializer<String> stringSerializer = new StringRedisSerializer();Jackson2JsonRedisSerializer jackson2JsonRedisSerializer = new Jackson2JsonRedisSerializer(Object.class);ObjectMapper om = new ObjectMapper();om.setVisibility(PropertyAccessor.ALL, JsonAutoDetect.Visibility.ANY);om.activateDefaultTyping(LaissezFaireSubTypeValidator.instance, ObjectMapper.DefaultTyping.NON_FINAL, JsonTypeInfo.As.PROPERTY);jackson2JsonRedisSerializer.setObjectMapper(om);template.setConnectionFactory(factory);// key序列化方式template.setKeySerializer(stringSerializer);template.setHashKeySerializer(stringSerializer);// value序列化template.setValueSerializer(jackson2JsonRedisSerializer);// value hashmap序列化template.setHashValueSerializer(jackson2JsonRedisSerializer);template.afterPropertiesSet();return template;}@Beanpublic CacheManager cacheManager(RedisConnectionFactory factory) {RedisSerializer<String> redisSerializer = new StringRedisSerializer();Jackson2JsonRedisSerializer jackson2JsonRedisSerializer = new Jackson2JsonRedisSerializer(Object.class);// 解决查询缓存转换异常的问题ObjectMapper om = new ObjectMapper();om.setVisibility(PropertyAccessor.ALL, JsonAutoDetect.Visibility.ANY);om.activateDefaultTyping(LaissezFaireSubTypeValidator.instance, ObjectMapper.DefaultTyping.NON_FINAL, JsonTypeInfo.As.PROPERTY);jackson2JsonRedisSerializer.setObjectMapper(om);// 配置序列化(解决乱码的问题),过期时间600秒RedisCacheConfiguration config = RedisCacheConfiguration.defaultCacheConfig().entryTtl(Duration.ofSeconds(600)).serializeKeysWith(RedisSerializationContext.SerializationPair.fromSerializer(redisSerializer)).serializeValuesWith(RedisSerializationContext.SerializationPair.fromSerializer(jackson2JsonRedisSerializer)).disableCachingNullValues();RedisCacheManager cacheManager = RedisCacheManager.builder(factory).cacheDefaults(config).build();return cacheManager;}}
2.4.4 启动类
package com.github.fairy.era.redis;import org.springframework.boot.SpringApplication;import org.springframework.boot.autoconfigure.SpringBootApplication;/*** @author 许大仙*/@SpringBootApplicationpublic class RedisApplication {public static void main(String[] args) {SpringApplication.run(RedisApplication.class, args);}}
2.4.5 测试类
package com.github.fairy.era.redis;import lombok.RequiredArgsConstructor;import org.junit.jupiter.api.Test;import org.springframework.beans.factory.annotation.Autowired;import org.springframework.boot.test.context.SpringBootTest;import org.springframework.data.redis.core.RedisTemplate;/*** @author 许大仙* @version 1.0* @since 2021-12-14 10:39*/@SpringBootTest(classes = RedisApplication.class)@RequiredArgsConstructorpublic class RedisTest {@Autowiredprivate RedisTemplate<String, String> redisTemplate;@Testpublic void test() {redisTemplate.opsForValue().set("name", "张三");String name = redisTemplate.opsForValue().get("name");System.out.println("name = " + name);}}
3 集群
3.1 问题引入
- 现状问题:业务发展过程中遇到的峰值瓶颈
- Redis 提供的服务 QPS 可以到达 10 万/秒,当前业务 QPS 已经达到 20 万/秒。
- 内存单机容量到达 256 G,当前业务需求内容容量 1 T。
- 使用集群的方式可以快速解决上述问题。
3.2 集群简介
- 集群就是使用网络将若干台计算机联通起来,并提供统一的管理方式,使其对外呈现单机的服务效果。
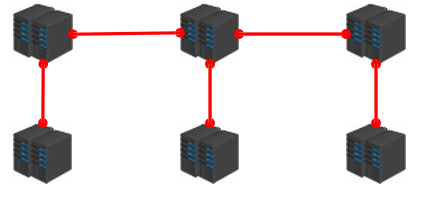
- 集群作用:
- ① 分散单台服务器的访问压力,实现负载均衡。
- ② 分散单台服务器的存储压力,实现可扩展性。
- ③ 降低单台服务器宕机带来的业务灾难。
3.3 Redis 集群结构设计
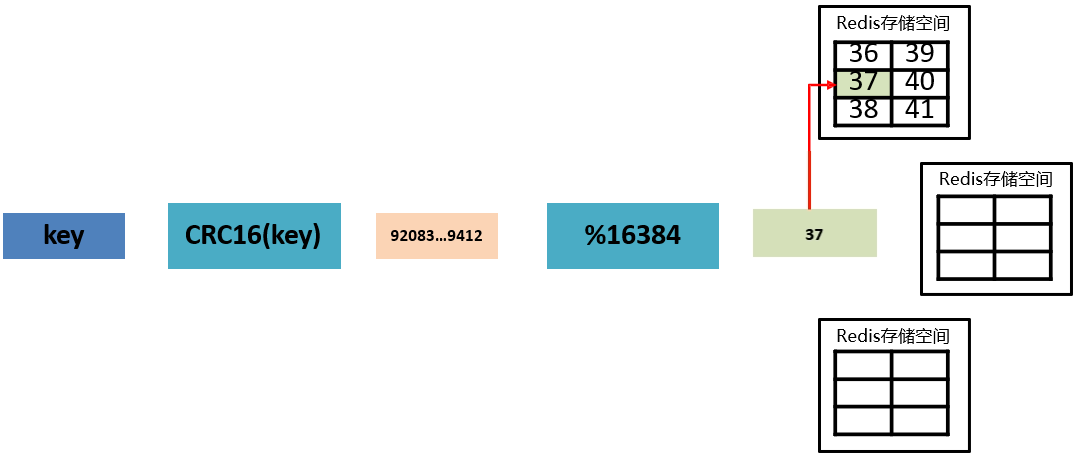
3.3.1 数据存储设计
- ① 通过算法设计,计算出 key 应该保存的位置。
- ② 将所有的存储空间切割成 16384 份,每台主机保存一部分。
注意:每份代表的是一个存储空间,不是一个 key 的保存空间。
- ③ 将 key 按照计算出的结果放到对应的存储空间。
- 那么 Redis 集群是如何增强可扩展性的呢?比如,我们需要增加一个集群节点:
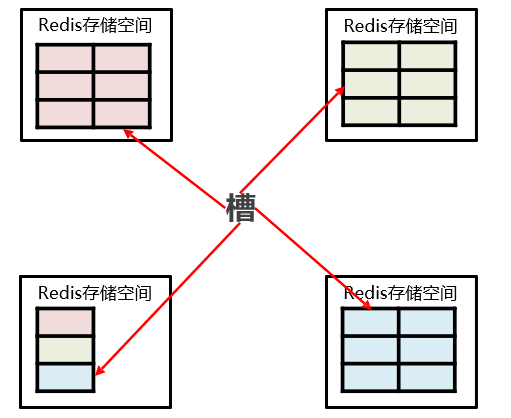
- 其实,增加一个节点,就是从原来的节点中根据算法将一些存储空间(上面说的份,如:37 对应的存储空间,也称为槽)移入到新的节点;换言之,如果减去一个节点,就将这个节点的槽移入到剩下的节点中。
注意:Redis 集群采用的是无中心化结构。
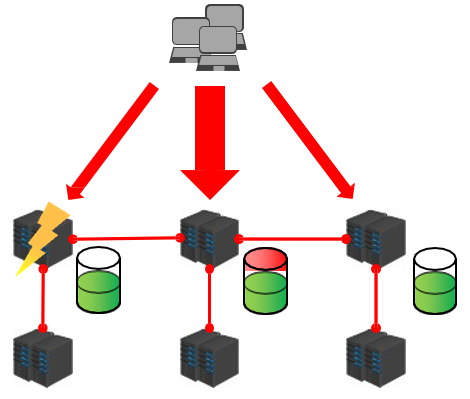
3.3.2 集群内部的通信设计
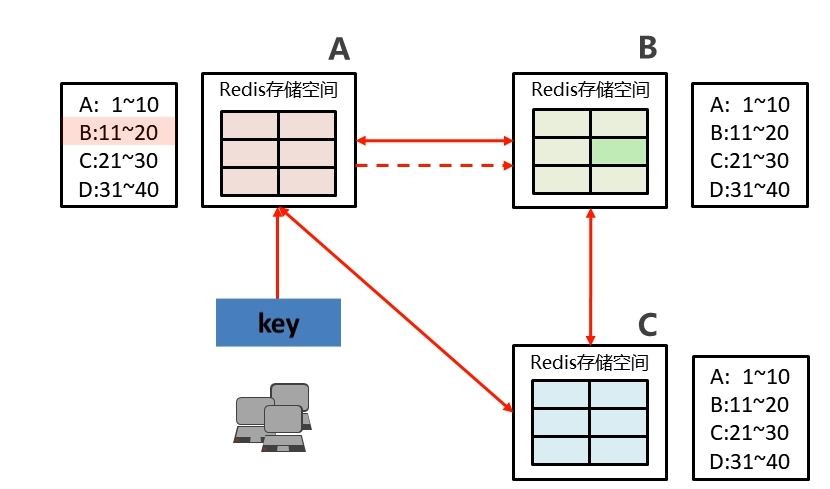
- 当我们需要查找数据的时候,集群是如何操作的?
- ① 各个数据库相互通信,保存各个库中的槽的编号数据。
- ② 一次命中,直接返回。
- ② 一次没有命中,告知具体位置。
3.4 cluster 集群结构搭建
3.4.1 准备工作
| 机器 | 操作系统 |
|---|---|
| 192.168.65.100 | CentOS 7.9 |
| 192.168.65.101 | CentOS 7.9 |
| 192.168.65.102 | CentOS 7.9 |
| 192.168.65.103 | CentOS 7.9 |
| 192.168.65.104 | CentOS 7.9 |
| 192.168.65.105 | CentOS 7.9 |
3.4.2 关闭防火墙、下载和解压
- 关闭 6 台机器的防火墙,确保所有机器能互相联通:
systemctl stop firewalld
systemctl disable firewalld
- 6 台机器都需要下载 Redis 的压缩包,并解压:
cd /opt
wget https://download.redis.io/releases/redis-5.0.10.tar.gz
tar -zxvf redis-5.0.10.tar.gz
3.4.3 编译安装
- 6 台机器都需要进入 Redis 的解压目录:
cd redis-5.0.10/
- 6 台机器都需要安装 c 语言编译环境:
yum -y install gcc-c++
- 6 台机器修改 Redis 安装的目录路径:
vim src/Makefile
# 就 Redis 自身而言是不需要修改的,这里修改的目的是让 Redis 的运行程序不要和其他文件混杂在一起。PREFIX?=/usr/local/redis
- 6 台机器编译安装 Redis:
make && make install
- 6 台机器配置环境变量:
vim /etc/profile
# ======================== 添加如下内容 ========================# REDIS HOMEexport REDIS_HOME=/usr/local/redisexport PATH=$REDIS_HOME/bin:$PATH
# 执行生效source /etc/profile
3.4.4 拷贝配置文件
- 6 台机器复制 redis.conf 文件到 /usr/local/redis :
cp redis.conf /usr/local/redis/
3.4.5 修改配置文件
- 6 台机器修改配 redis.conf 配置文件:
vim /usr/local/redis/redis.conf
## =========================== 修改内容说明如下 ===========================# 需要注释掉 bind# bind 0.0.0.0# 将保护模式关闭protected-mode no# 需要以守护进程方式启动daemonize yes# 设置 redis 服务日志存储路径logfile "/usr/local/redis/redis.logs"# 需要配置 Redis 持久化文件的目录dir /usr/local/redis# 将 AOF 功能打开appendonly yes# 启动Redis Clustercluster-enabled yes# Redis服务配置保存文件名称cluster-config-file nodes-6379.conf# 超时时间cluster-node-timeout 15000# 其他配置保存默认
3.4.6 启动 Redis 服务
- 6 台机器启动 Redis 服务:
redis-server /usr/local/redis/redis.conf
3.4.7 启动集群
- 任选一台机器执行如下命令,创建集群:
redis-cli --cluster create --cluster-replicas 1 192.168.65.100:6379 192.168.65.101:6379 192.168.65.102:6379 192.168.65.103:6379 192.168.65.104:6379 192.168.65.105:6379
注意:
--replicas 1采用最简单的方式配置集群,一台主机,一台从机,正好三组。

- 信息如下:
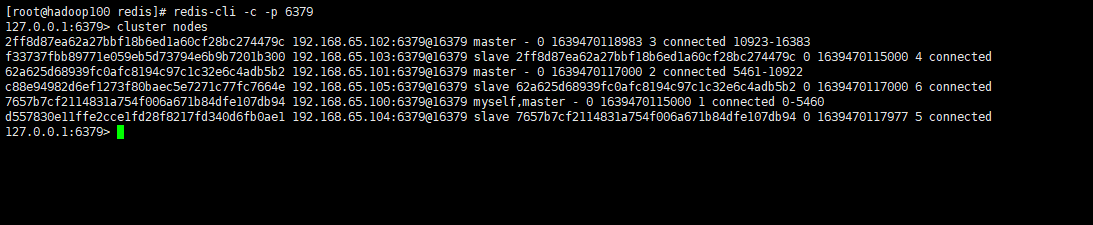
>>> Performing hash slots allocation on 6 nodes...## ====== 进行Slot槽范文划分 ======Master[0] -> Slots 0 - 5460Master[1] -> Slots 5461 - 10922Master[2] -> Slots 10923 - 16383## ====== 主从分配,一主一从 ======Adding replica 192.168.65.104:6379 to 192.168.65.100:6379Adding replica 192.168.65.105:6379 to 192.168.65.101:6379Adding replica 192.168.65.103:6379 to 192.168.65.102:6379## ====== 主从节点配对信息 ======M: 7657b7cf2114831a754f006a671b84dfe107db94 192.168.65.100:6379slots:[0-5460] (5461 slots) masterM: 62a625d68939fc0afc8194c97c1c32e6c4adb5b2 192.168.65.101:6379slots:[5461-10922] (5462 slots) masterM: 2ff8d87ea62a27bbf18b6ed1a60cf28bc274479c 192.168.65.102:6379slots:[10923-16383] (5461 slots) masterS: f33737fbb89771e059eb5d73794e6b9b7201b300 192.168.65.103:6379replicates 2ff8d87ea62a27bbf18b6ed1a60cf28bc274479cS: d557830e11ffe2cce1fd28f8217fd340d6fb0ae1 192.168.65.104:6379replicates 7657b7cf2114831a754f006a671b84dfe107db94S: c88e94982d6ef1273f80baec5e7271c77fc7664e 192.168.65.105:6379replicates 62a625d68939fc0afc8194c97c1c32e6c4adb5b2## ====== 是否同意上述划分,一般都是yes ======Can I set the above configuration? (type 'yes' to accept): yes## ====== 节点配置更新,进入集群,主从节点,高可用 ======>>> Nodes configuration updated>>> Assign a different config epoch to each node>>> Sending CLUSTER MEET messages to join the clusterWaiting for the cluster to join.>>> Performing Cluster Check (using node 192.168.65.100:6379)M: 7657b7cf2114831a754f006a671b84dfe107db94 192.168.65.100:6379slots:[0-5460] (5461 slots) master1 additional replica(s)M: 2ff8d87ea62a27bbf18b6ed1a60cf28bc274479c 192.168.65.102:6379slots:[10923-16383] (5461 slots) master1 additional replica(s)S: f33737fbb89771e059eb5d73794e6b9b7201b300 192.168.65.103:6379slots: (0 slots) slavereplicates 2ff8d87ea62a27bbf18b6ed1a60cf28bc274479cM: 62a625d68939fc0afc8194c97c1c32e6c4adb5b2 192.168.65.101:6379slots:[5461-10922] (5462 slots) master1 additional replica(s)S: c88e94982d6ef1273f80baec5e7271c77fc7664e 192.168.65.105:6379slots: (0 slots) slavereplicates 62a625d68939fc0afc8194c97c1c32e6c4adb5b2S: d557830e11ffe2cce1fd28f8217fd340d6fb0ae1 192.168.65.104:6379slots: (0 slots) slavereplicates 7657b7cf2114831a754f006a671b84dfe107db94[OK] All nodes agree about slots configuration.>>> Check for open slots...>>> Check slots coverage...[OK] All 16384 slots covered.
3.4.8 测试集群
- 任选一台机器,使用 redis-cli 客户端命令连接 Redis 服务:
redis-cli -c -p 6379
- 查看集群信息:
cluster nodes
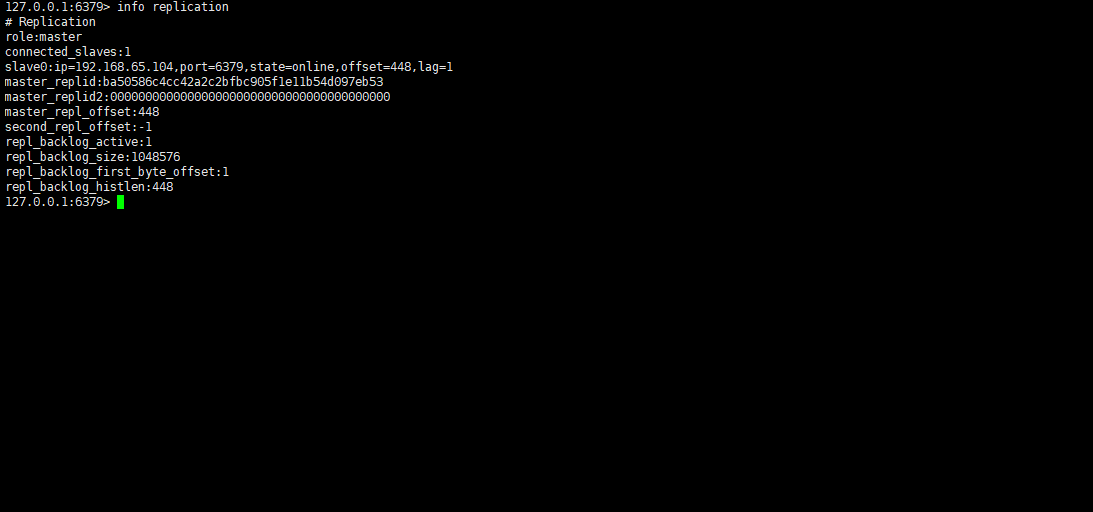
- 查看主从信息:
info replication
3.4.9 在集群中插入值
- 在 redis-cli 每次录入、查询键值,redis 都会计算出该 key 应该送往的插槽,如果不是该客户端对应服务器的插槽,redis 会报错,并告知应前往的 redis 实例地址和端口。
- redis-cli 客户端提供了 –c 参数实现自动重定向。
- 集群中,不能使用 mset、mget 等多键命令:
mset k1 v1 k2 v2
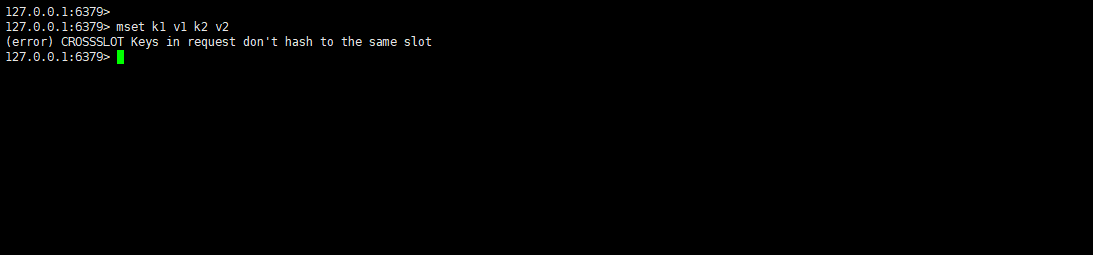
- 可以通过 {} 来定义组的概念,从而使 key 中 {} 内相同内容的键值对放到一个 slot 中去:
mset k1{user} v1 k2{user} v2

3.4.10 故障恢复
- 如果主节点下线,那么从节点可以自动升为主节点,但是如果超过 15 秒就会失败。
- 主节点宕机然后又恢复后,会自动变为从节点。
- 如果所有某一段插槽的主从节点都宕掉,如果配置文件 redis.conf 中的 cluster-require-full-coverage 为 yes ,整个集群都会挂掉;如果配置文件 redis.conf 中的 cluster-require-full-coverage 为 no,那么该插槽数据全都不能使用,也无法存储。
3.4.11 Redis 集群管理
- redis-cli 集群帮助命令:
redis-cli --cluster help

- 在实际开发中,可能由于 Redis 集群中节点宕机或增加新节点,需要操作命令管理,主要操作如下:
- 添加新主节点:
# new_host:new_port 要向集群中添加新的主节点# existing_host:existing_port 原集群中任意节点redis-cli --cluster add-node new_host:new_port existing_host:existing_port
- 添加新从节点:
# new_host:new_port 要向集群中添加新的主节点# existing_host:existing_port 原集群中任意节点# node_id 要添加到哪一个主节点,id是****redis-cli --cluster add-node new_host:new_port existing_host:existing_port --cluster-slave --cluster-master-id node_id
- 删除节点:
redis-cli --cluster del-node host:port node_id
- hash 槽重新分配:添加新节点后,需要对新添加的主节点进行 hash 槽重新分配,此时主节点才能存储数据,Redis 一共有 16384 个槽:
redis-cli --cluster reshard host:port --cluster-from node_id --cluster-to node_id --cluster-slots <arg> --cluster-yes
3.5 Redis 集群的优缺点
- 优点:
- 实现扩容。
- 分摊压力。
- 无中心配置相对简单。
- 缺点:
- 多键操作是不被支持的。
- 多键的 Redis 事务是不被支持的。lua 脚本不被支持。
- 由于集群方案出现较晚,很多公司已经采用了其他的集群方案,而代理或者客户端分片的方案想要迁移至 redis cluster,需要整体迁移而不是逐步过渡,复杂度较大。
3.6 SpringBoot 整合 Redis 集群
3.6.1 准备工作
- IDEA 2021+。
- JDK 11。
- Maven 3.8。
- SpringBoot 2.6.1。
Redis 5.0.10。
pom.xml
<?xml version="1.0" encoding="UTF-8"?><project xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xmlns="http://maven.apache.org/POM/4.0.0"xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 https://maven.apache.org/xsd/maven-4.0.0.xsd"><modelVersion>4.0.0</modelVersion><parent><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-parent</artifactId><version>2.6.1</version><relativePath/></parent><groupId>com.example</groupId><artifactId>redis</artifactId><version>1.0</version><name>redis</name><description>redis</description><properties><java.version>11</java.version><skipTests>true</skipTests></properties><dependencies><dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-data-redis</artifactId></dependency><dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-web</artifactId></dependency><dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-test</artifactId><scope>test</scope></dependency><dependency><groupId>org.projectlombok</groupId><artifactId>lombok</artifactId><optional>true</optional></dependency><dependency><groupId>cn.hutool</groupId><artifactId>hutool-all</artifactId><version>5.7.17</version></dependency><dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-thymeleaf</artifactId></dependency></dependencies><build><plugins><plugin><groupId>org.springframework.boot</groupId><artifactId>spring-boot-maven-plugin</artifactId><version>2.6.1</version><configuration><excludes><exclude><groupId>org.projectlombok</groupId><artifactId>lombok</artifactId></exclude></excludes></configuration></plugin><plugin><groupId>org.apache.maven.plugins</groupId><artifactId>maven-compiler-plugin</artifactId><version>3.8.1</version></plugin></plugins></build><repositories><repository><id>aliyunmaven</id><url>https://maven.aliyun.com/repository/public</url><releases><enabled>true</enabled></releases><snapshots><enabled>true</enabled></snapshots></repository><repository><id>spring</id><url>https://maven.aliyun.com/repository/spring</url><releases><enabled>true</enabled></releases><snapshots><enabled>true</enabled></snapshots></repository><repository><id>spring-releases</id><url>https://repo.spring.io/libs-release</url><releases><enabled>true</enabled></releases><snapshots><enabled>true</enabled></snapshots></repository></repositories><pluginRepositories><pluginRepository><id>spring-releases</id><url>https://repo.spring.io/libs-release</url></pluginRepository></pluginRepositories></project>
3.6.2 配置文件
- application.yml
server:port: 18082spring:redis: # redisdatabase: 0 # 数据库索引,默认为 0timeout: 1800000 # 连接超时时间(毫秒),默认为 0 ,表示永不超时lettuce:pool:max-active: 20 # 连接池的最大连接数(负数表示没有限制)max-wait: -1 # 连接池的最大阻塞等待时间(负数表示没有限制)max-idle: 5 # 连接池的最大空闲连接min-idle: 0 # 连接池的最小空闲连接client-type: lettucecluster:max-redirects: 3 # 获取失败 最大重定向次数nodes:- 192.168.65.100:6379- 192.168.65.101:6379- 192.168.65.102:6379- 192.168.65.103:6379- 192.168.65.104:6379- 192.168.65.105:6379
3.6.3 配置类
package com.github.fairy.era.redis.config;import com.fasterxml.jackson.annotation.JsonAutoDetect;import com.fasterxml.jackson.annotation.JsonTypeInfo;import com.fasterxml.jackson.annotation.PropertyAccessor;import com.fasterxml.jackson.databind.ObjectMapper;import com.fasterxml.jackson.databind.jsontype.impl.LaissezFaireSubTypeValidator;import org.springframework.cache.CacheManager;import org.springframework.cache.annotation.CachingConfigurationSelector;import org.springframework.cache.annotation.EnableCaching;import org.springframework.context.annotation.Bean;import org.springframework.context.annotation.Configuration;import org.springframework.data.redis.cache.RedisCacheConfiguration;import org.springframework.data.redis.cache.RedisCacheManager;import org.springframework.data.redis.connection.RedisConnectionFactory;import org.springframework.data.redis.core.RedisTemplate;import org.springframework.data.redis.serializer.Jackson2JsonRedisSerializer;import org.springframework.data.redis.serializer.RedisSerializationContext;import org.springframework.data.redis.serializer.RedisSerializer;import org.springframework.data.redis.serializer.StringRedisSerializer;import java.time.Duration;/*** @author 许大仙* @version 1.0* @since 2021-12-13 11:02*/@Configuration@EnableCachingpublic class RedisConfig extends CachingConfigurationSelector {@Beanpublic RedisTemplate<String, Object> redisTemplate(RedisConnectionFactory factory) {RedisTemplate<String, Object> template = new RedisTemplate<>();RedisSerializer<String> stringSerializer = new StringRedisSerializer();Jackson2JsonRedisSerializer jackson2JsonRedisSerializer = new Jackson2JsonRedisSerializer(Object.class);ObjectMapper om = new ObjectMapper();om.setVisibility(PropertyAccessor.ALL, JsonAutoDetect.Visibility.ANY);om.activateDefaultTyping(LaissezFaireSubTypeValidator.instance, ObjectMapper.DefaultTyping.NON_FINAL, JsonTypeInfo.As.PROPERTY);jackson2JsonRedisSerializer.setObjectMapper(om);template.setConnectionFactory(factory);// key序列化方式template.setKeySerializer(stringSerializer);template.setHashKeySerializer(stringSerializer);// value序列化template.setValueSerializer(jackson2JsonRedisSerializer);// value hashmap序列化template.setHashValueSerializer(jackson2JsonRedisSerializer);template.afterPropertiesSet();return template;}@Beanpublic CacheManager cacheManager(RedisConnectionFactory factory) {RedisSerializer<String> redisSerializer = new StringRedisSerializer();Jackson2JsonRedisSerializer jackson2JsonRedisSerializer = new Jackson2JsonRedisSerializer(Object.class);// 解决查询缓存转换异常的问题ObjectMapper om = new ObjectMapper();om.setVisibility(PropertyAccessor.ALL, JsonAutoDetect.Visibility.ANY);om.activateDefaultTyping(LaissezFaireSubTypeValidator.instance, ObjectMapper.DefaultTyping.NON_FINAL, JsonTypeInfo.As.PROPERTY);jackson2JsonRedisSerializer.setObjectMapper(om);// 配置序列化(解决乱码的问题),过期时间600秒RedisCacheConfiguration config = RedisCacheConfiguration.defaultCacheConfig().entryTtl(Duration.ofSeconds(600)).serializeKeysWith(RedisSerializationContext.SerializationPair.fromSerializer(redisSerializer)).serializeValuesWith(RedisSerializationContext.SerializationPair.fromSerializer(jackson2JsonRedisSerializer)).disableCachingNullValues();RedisCacheManager cacheManager = RedisCacheManager.builder(factory).cacheDefaults(config).build();return cacheManager;}}
3.6.4 启动类
package com.github.fairy.era.redis;import org.springframework.boot.SpringApplication;import org.springframework.boot.autoconfigure.SpringBootApplication;/*** @author xuwei*/@SpringBootApplicationpublic class RedisApplication {public static void main(String[] args) {SpringApplication.run(RedisApplication.class, args);}}
3.6.5 测试类
package com.github.fairy.era.redis;import lombok.RequiredArgsConstructor;import org.junit.jupiter.api.Test;import org.springframework.beans.factory.annotation.Autowired;import org.springframework.boot.test.context.SpringBootTest;import org.springframework.data.redis.core.RedisTemplate;/*** @author 许大仙* @version 1.0* @since 2021-12-14 10:39*/@SpringBootTest(classes = RedisApplication.class)@RequiredArgsConstructorpublic class RedisTest {@Autowiredprivate RedisTemplate<String, String> redisTemplate;@Testpublic void test() {redisTemplate.opsForValue().set("name", "张三");String name = redisTemplate.opsForValue().get("name");System.out.println("name = " + name);}}

若有收获,就点个赞吧
0 人点赞
