原文: https://howtodoinjava.com/spring-batch/multiresourceitemreader-read-multiple-csv-files-example/
学习使用MultiResourceItemReader类从文件系统或资源文件夹中读取多个 CSV 文件。 这些文件可能具有第一行作为标题,因此不要忘记跳过第一行。
项目结构
在此项目中,我们将:
- 从
input/*.csv读取 3 个 CSV 文件。 - 将数据写入控制台。
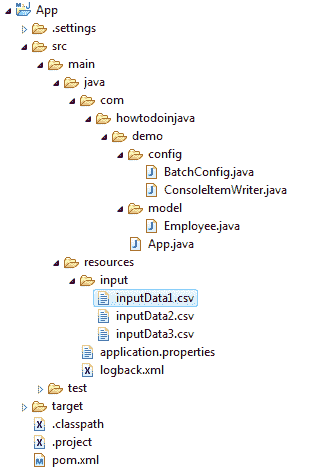
项目结构
使用MultiResourceItemReader读取 CSV 文件
您需要使用MultiResourceItemReader从 CSV 文件中读取行。 它从多个资源顺序读取项目。
BatchConfig.java
@Value("input/inputData*.csv")private Resource[] inputResources;@Beanpublic Job readCSVFilesJob() {return jobBuilderFactory.get("readCSVFilesJob").incrementer(new RunIdIncrementer()).start(step1()).build();}@Beanpublic Step step1() {return stepBuilderFactory.get("step1").<Employee, Employee>chunk(5).reader(multiResourceItemReader()).writer(writer()).build();}@Beanpublic MultiResourceItemReader<Employee> multiResourceItemReader(){MultiResourceItemReader<Employee> resourceItemReader = new MultiResourceItemReader<Employee>();resourceItemReader.setResources(inputResources);resourceItemReader.setDelegate(reader());return resourceItemReader;}@Beanpublic FlatFileItemReader<Employee> reader(){//Create reader instanceFlatFileItemReader<Employee> reader = new FlatFileItemReader<Employee>();//Set number of lines to skips. Use it if file has header rows.reader.setLinesToSkip(1);//Configure how each line will be parsed and mapped to different valuesreader.setLineMapper(new DefaultLineMapper() {{//3 columns in each rowsetLineTokenizer(new DelimitedLineTokenizer() {{setNames(new String[] { "id", "firstName", "lastName" });}});//Set values in Employee classsetFieldSetMapper(new BeanWrapperFieldSetMapper<Employee>() {{setTargetType(Employee.class);}});}});return reader;}
Employee.java
public class Employee {String id;String firstName;String lastName;//public setter and getter methods}
inputData1.csv
id,firstName,lastName1,Lokesh,Gupta2,Amit,Mishra3,Pankaj,Kumar4,David,Miller
inputData2.csv
id,firstName,lastName5,Ramesh,Gupta6,Vineet,Mishra7,Amit,Kumar8,Dav,Miller
inputData3.csv
id,firstName,lastName9,Vikas,Kumar10,Pratek,Mishra11,Brian,Kumar12,David,Cena
将读取的行写入控制台
创建实现ItemWriter接口的ConsoleItemWriter类。
ConsoleItemWriter.java
import java.util.List;import org.springframework.batch.item.ItemWriter;public class ConsoleItemWriter<T> implements ItemWriter<T> {@Overridepublic void write(List<? extends T> items) throws Exception {for (T item : items) {System.out.println(item);}}}
使用ConsoleItemWriter作为编写器。
BatchConfig.java
@Beanpublic ConsoleItemWriter<Employee> writer(){return new ConsoleItemWriter<Employee>();}
Maven 依赖
查看项目依赖项。
pom.xml
<project xmlns="http://maven.apache.org/POM/4.0.0"xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd;<modelVersion>4.0.0</modelVersion><groupId>com.howtodoinjava</groupId><artifactId>App</artifactId><version>0.0.1-SNAPSHOT</version><packaging>jar</packaging><name>App</name><url>http://maven.apache.org</url><parent><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-parent</artifactId><version>2.0.3.RELEASE</version></parent><properties><project.build.sourceEncoding>UTF-8</project.build.sourceEncoding></properties><dependencies><dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-batch</artifactId></dependency><dependency><groupId>com.h2database</groupId><artifactId>h2</artifactId><scope>runtime</scope></dependency></dependencies><build><plugins><plugin><groupId>org.springframework.boot</groupId><artifactId>spring-boot-maven-plugin</artifactId></plugin></plugins></build><repositories><repository><id>repository.spring.release</id><name>Spring GA Repository</name><url>http://repo.spring.io/release</url></repository></repositories></project>
示例
在运行该应用程序之前,请查看BatchConfig.java的完整代码。
BatchConfig.java
package com.howtodoinjava.demo.config;import org.springframework.batch.core.Job;import org.springframework.batch.core.Step;import org.springframework.batch.core.configuration.annotation.EnableBatchProcessing;import org.springframework.batch.core.configuration.annotation.JobBuilderFactory;import org.springframework.batch.core.configuration.annotation.StepBuilderFactory;import org.springframework.batch.core.launch.support.RunIdIncrementer;import org.springframework.batch.item.file.FlatFileItemReader;import org.springframework.batch.item.file.MultiResourceItemReader;import org.springframework.batch.item.file.mapping.BeanWrapperFieldSetMapper;import org.springframework.batch.item.file.mapping.DefaultLineMapper;import org.springframework.batch.item.file.transform.DelimitedLineTokenizer;import org.springframework.beans.factory.annotation.Autowired;import org.springframework.beans.factory.annotation.Value;import org.springframework.context.annotation.Bean;import org.springframework.context.annotation.Configuration;import org.springframework.core.io.Resource;import com.howtodoinjava.demo.model.Employee;@Configuration@EnableBatchProcessingpublic class BatchConfig{@Autowiredprivate JobBuilderFactory jobBuilderFactory;@Autowiredprivate StepBuilderFactory stepBuilderFactory;@Value("input/inputData*.csv")private Resource[] inputResources;@Beanpublic Job readCSVFilesJob() {return jobBuilderFactory.get("readCSVFilesJob").incrementer(new RunIdIncrementer()).start(step1()).build();}@Beanpublic Step step1() {return stepBuilderFactory.get("step1").<Employee, Employee>chunk(5).reader(multiResourceItemReader()).writer(writer()).build();}@Beanpublic MultiResourceItemReader<Employee> multiResourceItemReader(){MultiResourceItemReader<Employee> resourceItemReader = new MultiResourceItemReader<Employee>();resourceItemReader.setResources(inputResources);resourceItemReader.setDelegate(reader());return resourceItemReader;}@SuppressWarnings({ "rawtypes", "unchecked" })@Beanpublic FlatFileItemReader<Employee> reader(){//Create reader instanceFlatFileItemReader<Employee> reader = new FlatFileItemReader<Employee>();//Set number of lines to skips. Use it if file has header rows.reader.setLinesToSkip(1);//Configure how each line will be parsed and mapped to different valuesreader.setLineMapper(new DefaultLineMapper() {{//3 columns in each rowsetLineTokenizer(new DelimitedLineTokenizer() {{setNames(new String[] { "id", "firstName", "lastName" });}});//Set values in Employee classsetFieldSetMapper(new BeanWrapperFieldSetMapper<Employee>() {{setTargetType(Employee.class);}});}});return reader;}@Beanpublic ConsoleItemWriter<Employee> writer(){return new ConsoleItemWriter<Employee>();}}
App.java
package com.howtodoinjava.demo;import org.springframework.batch.core.Job;import org.springframework.batch.core.JobParameters;import org.springframework.batch.core.JobParametersBuilder;import org.springframework.batch.core.launch.JobLauncher;import org.springframework.beans.factory.annotation.Autowired;import org.springframework.boot.SpringApplication;import org.springframework.boot.autoconfigure.SpringBootApplication;import org.springframework.scheduling.annotation.EnableScheduling;import org.springframework.scheduling.annotation.Scheduled;@SpringBootApplication@EnableSchedulingpublic class App{@AutowiredJobLauncher jobLauncher;@AutowiredJob job;public static void main(String[] args){SpringApplication.run(App.class, args);}@Scheduled(cron = "0 */1 * * * ?")public void perform() throws Exception{JobParameters params = new JobParametersBuilder().addString("JobID", String.valueOf(System.currentTimeMillis())).toJobParameters();jobLauncher.run(job, params);}}
application.properties
#Disable batch job's auto startspring.batch.job.enabled=falsespring.main.banner-mode=off
运行应用程序
将应用程序作为 Spring 运行应用程序运行,并观察控制台。 批处理作业将在每分钟开始时开始。 它将读取输入文件,并在控制台中打印读取的值。
Console
2018-07-10 15:32:26 INFO - Starting App on XYZ with PID 4596 (C:\Users\user\workspace\App\target\classes started by zkpkhua in C:\Users\user\workspace\App)2018-07-10 15:32:26 INFO - No active profile set, falling back to default profiles: default2018-07-10 15:32:27 INFO - Refreshing org.springframework.context.annotation.AnnotationConfigApplicationContext@3c9d0b9d: startup date [Tue Jul 10 15:32:27 IST 2018]; root of context hierarchy2018-07-10 15:32:28 INFO - HikariPool-1 - Starting...2018-07-10 15:32:29 INFO - HikariPool-1 - Start completed.2018-07-10 15:32:29 INFO - No database type set, using meta data indicating: H22018-07-10 15:32:29 INFO - No TaskExecutor has been set, defaulting to synchronous executor.2018-07-10 15:32:29 INFO - Executing SQL script from class path resource [org/springframework/batch/core/schema-h2.sql]2018-07-10 15:32:29 INFO - Executed SQL script from class path resource [org/springframework/batch/core/schema-h2.sql] in 68 ms.2018-07-10 15:32:30 INFO - Registering beans for JMX exposure on startup2018-07-10 15:32:30 INFO - Bean with name 'dataSource' has been autodetected for JMX exposure2018-07-10 15:32:30 INFO - Located MBean 'dataSource': registering with JMX server as MBean [com.zaxxer.hikari:name=dataSource,type=HikariDataSource]2018-07-10 15:32:30 INFO - No TaskScheduler/ScheduledExecutorService bean found for scheduled processing2018-07-10 15:32:30 INFO - Started App in 4.036 seconds (JVM running for 4.827)2018-07-10 15:33:00 INFO - Job: [SimpleJob: [name=readCSVFilesJob]] launched with the following parameters: [{JobID=1531216980005}]2018-07-10 15:33:00 INFO - Executing step: [step1]Employee [id=1, firstName=Lokesh, lastName=Gupta]Employee [id=2, firstName=Amit, lastName=Mishra]Employee [id=3, firstName=Pankaj, lastName=Kumar]Employee [id=4, firstName=David, lastName=Miller]Employee [id=5, firstName=Ramesh, lastName=Gupta]Employee [id=6, firstName=Vineet, lastName=Mishra]Employee [id=7, firstName=Amit, lastName=Kumar]Employee [id=8, firstName=Dav, lastName=Miller]Employee [id=9, firstName=Vikas, lastName=Kumar]Employee [id=10, firstName=Pratek, lastName=Mishra]Employee [id=11, firstName=Brian, lastName=Kumar]Employee [id=12, firstName=David, lastName=Cena]2018-07-10 15:33:00 INFO - Job: [SimpleJob: [name=readCSVFilesJob]] completed with the following parameters: [{JobID=1531216980005}] and the following status: [COMPLETED]
将我的问题放在评论部分。
学习愉快!

若有收获,就点个赞吧
0 人点赞
