1、什么是分库分表
就是把原本存储于一个库的数据分块存储到多个库上,把原本存储于一个表的数据分块存储到多个表上。
2、为什么分库分表
数据库中的数据量不一定是可控的,在未进行分库分表的情况下,随着时间和业务的发展,库中的表会越来越多,表中的数据量也会越来越大,相应地,数据操作,增删改查的开销也会越来越大;另外,由于无法进行分布式式部署,而一台服务器的资源(CPU、磁盘、内存、IO等)是有限的,最终数据库所能承载的数据量、数据处理能力都将遭遇瓶颈。
3、分库分表的实施策略
分库分表有垂直切分和水平切分两种。
- 垂直切分,即将表按照功能模块、关系密切程度划分出来,部署到不同的库上。例如,建立定义数据库workDB、商品数据库payDB、用户数据库userDB等,分别用于存储项目数据定义表、商品定义表、用户数据表等。
- 水平切分,当一个表中的数据量过大时,可以把该表的数据按照某种规则,例如userID散列,进行划分,然后存储到多个结构相同的表,和不同的库上。
例如,userDB中的用户数据表中,每一个表的数据量都很大,就可以把userDB切分为结构相同的多个userDB:part0DB、part1DB等,再将userDB上的用户数据表userTable,切分为很多userTable:userTable0、userTable1等,然后将这些表按照一定的规则存储到多个userDB上。
应该使用哪一种方式来实施数据库分库分表,这要看数据库中数据量的瓶颈所在,并综合项目的业务类型进行考虑。
如果数据库是因为表太多而造成海量数据,并且项目的各项业务逻辑划分清晰、低耦合,那么规则简单明了、容易实施的垂直切分必是首选。
而如果数据库中的表并不多,但单表的数据量很大、或数据热度很高,这种情况之下就应该选择水平切分,水平切分比垂直切分要复杂一些,它将原本逻辑上属于一体的数据进行了物理分割,除了在分割时要对分割的粒度做好评估,考虑数据平均和负载平均,后期也将对项目人员及应用程序产生额外的数据管理负担。
面对数据递增,解决方案通常是分库分表,冷热数据分离
- 垂直拆分——主要是字段的拆分
-
4、分库分表常用的原理策略
Mycat
官网:http://www.mycat.io
mycat是一个中间件代理层,对研发无感知
1、一个彻底开源的,面向企业应用开发的大数据库集群
2、支持事务、ACID、可以替代MySQL的加强版数据库
3、一个可以视为MySQL集群的企业级数据库,用来替代昂贵的Oracle集群
4、一个融合内存缓存技术、NoSQL技术、HDFS大数据的新型SQL Server
5、结合传统数据库和新型分布式数据仓库的新一代企业级数据库产品
6、一个新颖的数据库中间件产品优点:
开发无感知
- 增删节点程序不需要重启
-
缺点:
性能下降没因为多了一层
-
MyCat经典实用场景
单纯的读写分离,此时配置最为简单,支持读写分离,主从切换
- 分表分库,对于超过1000 万的表进行分片,最大支持1000 亿的单表分片
- 多租户应用,每个应用一个库,但应用程序只连接Mycat,从而不改造程序本身,实现多租户化
- 报表系统,借助于Mycat的分表能力,处理大规模报表的统计
- 替代Hbase,分析大数据作为海量数据实时查询的一种简单有效方案,比如100 亿条频繁查询的记录需要在3 秒内查询出来结果,除了基于主键的查询,还可能存在范围查询或其他属性查询,此时Mycat 可能是最简单有效的选择
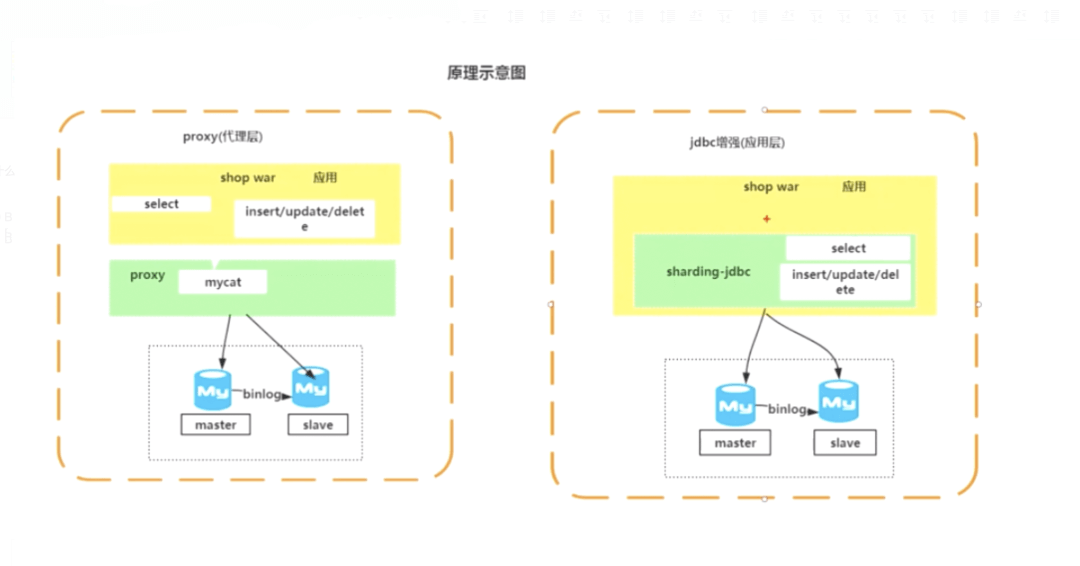
mycat的使用对研发是无感知的,但是运维成本较大,涉及到一些概念
逻辑库(sehema),逻辑表(table),配置分片(dataNode),配置物理库分片映射(dataHost)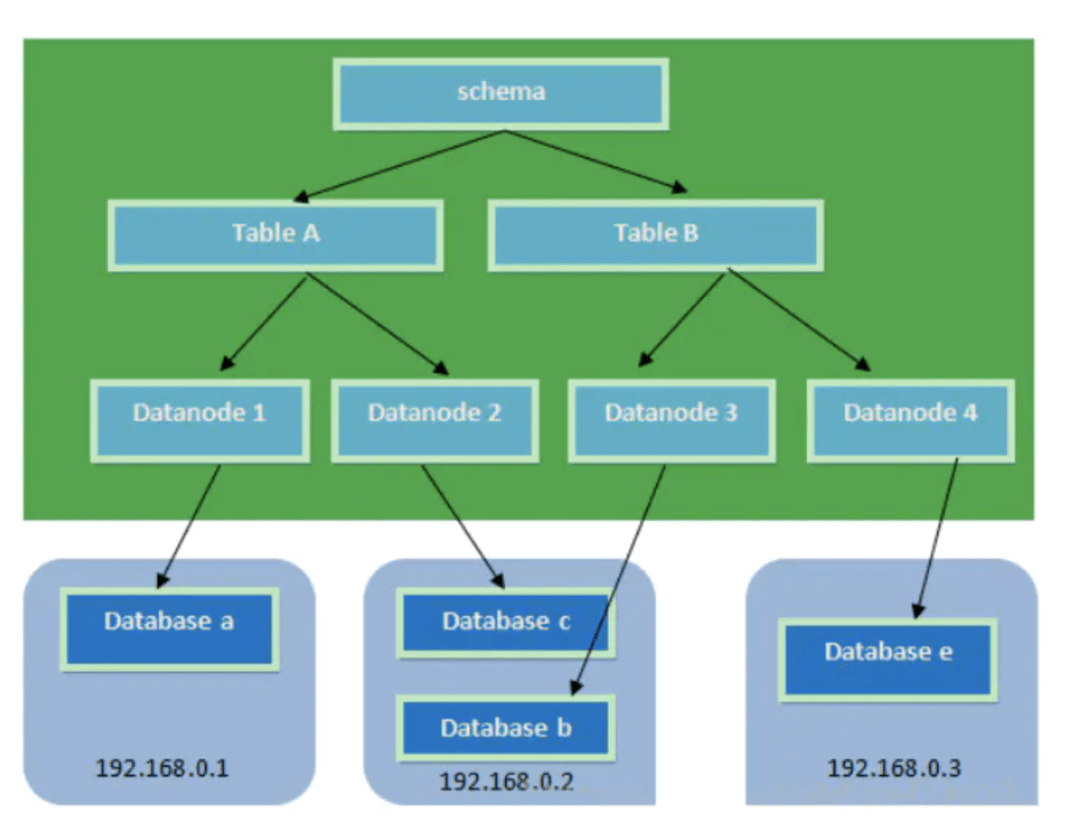
需要了解一点,集中式的Proxy其实现非常复杂,这要从MySQL处理SQL语句的原理说起,因为不是本文要论述的重点,因此只是简单的提及几点:
- SQL语句要被Parser解析成抽象语法树
- SQL要被优化器解析出执行计划
- SQL语句完成解析后,发给存储引擎
只要有解析的过程,其性能损耗就是比较可观的,也可以认为这是一种重量级的解决方案。
ShardingJdbc
官网:http://shardingsphere.apache.org/index_zh.html
定位为轻量级Java框架,在Java的JDBC层提供的额外服务。它使用客户端直连数据库,以jar包形式提供服务,无需额外部署和依赖,可理解为增强版的JDBC驱动,完全兼容JDBC和各种ORM框架。
1、适用于任何基于JDBC的ORM框架,如:JPA, Hibernate, Mybatis, Spring JDBC Template或直接使用JDBC。
2、支持任何第三方的数据库连接池,如:DBCP, C3P0, BoneCP, Druid, HikariCP等。
3、支持任意实现JDBC规范的数据库。目前支持MySQL,Oracle,SQLServer,PostgreSQL以及任何遵循SQL92标准的数据库。
优点:
ShardingJdbc是ShardingSphere中关于jdbc增强方式的一种,而且ShardingSphere已经孵化为apache顶级项目
每一个服务都持有一个Sharing-JDBC,这个JDBC以Jar包的形式提供,基本上可以认为是一个增强版的jdbc驱动,需要一些分库分表的配置,业务开发人员不需要去对代码进行任何的修改。可以很轻松的移植到SpringBoot,ORM等框架上
但是这个结构也不是完美的,每一个服务持有一个proxy意味着会在MySQL服务端新建大量的连接,维持连接会增加MySQL服务器的负载,虽然这种负载提升一般无法察觉。
ShardingJdbc中涉及到基础概念
逻辑表、真实表、数据节点——每张真实表
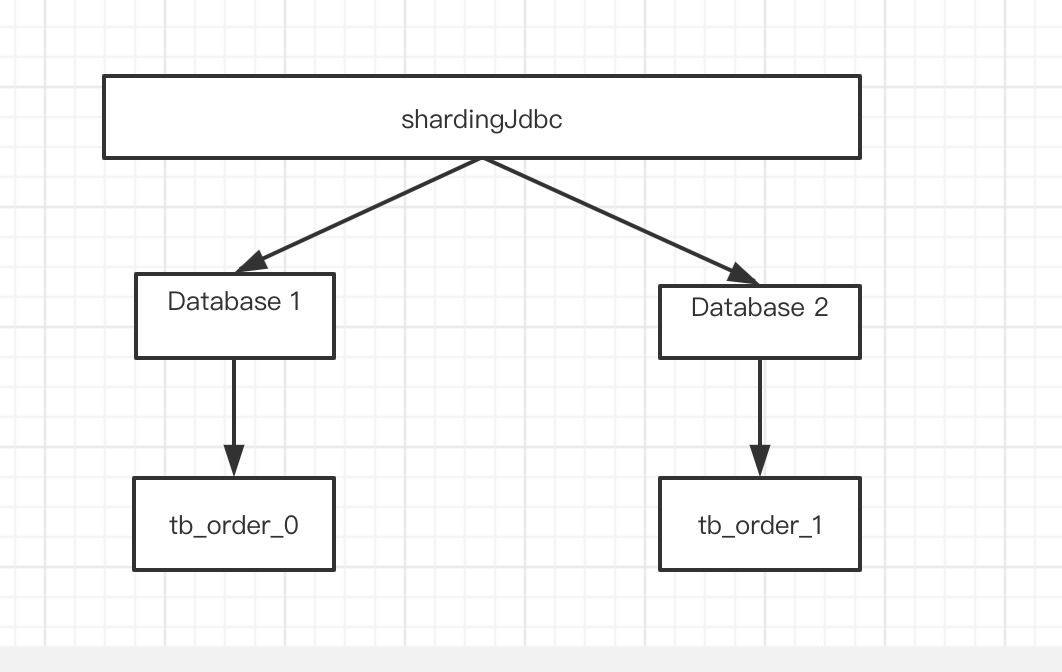
逻辑表
即水平拆分的表的总称。比如订单业务会被拆分成t_order0,t_order1两张表,但是他们同属于一个逻辑表:t_order
绑定表
分片规则一直的主表和子表。比如还是上面的t_order表,其分片键是order_id,其子表t_order_item的分片键也是order_id。在规则配置时将两个表配置成绑定关系,就不会在查询时出现笛卡尔积。
广播表
有一些表是没有分片的必要的,比如省份信息表,全国也就30多条数据,这种表在每一个节点上都是一样的,这种表叫做广播表。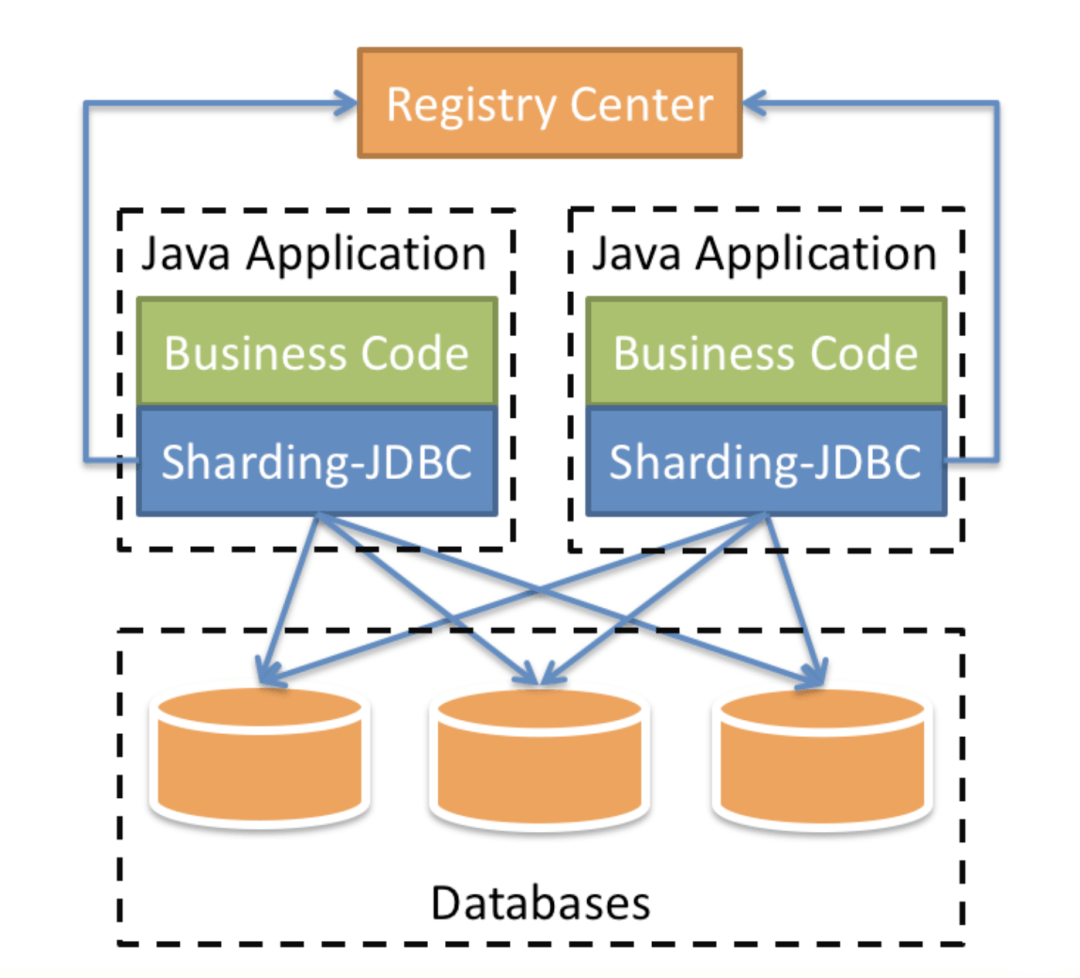
简单来说
1)mycat是一个中间件的第三方应用,sharding-jdbc是一个jar包
2)使用mycat时不需要改代码,而使用sharding-jdbc时需要修改代码
5、关于分表策略通常分为三种
1、取模
2、范围分表-通常是时间
3、城市-有明显业务特征的分表
时间范围策略通常用于冷热数据分离,例如美团限查近3个月的订单,量体比较大,而且历史数据使用相对较少
城市这种分表策略,类似于多租户的概念,业务处理场景一样,但是数据独立
总结
主要是简单介绍下什么是分库分表,分库分表的实施策略,以及分库分表通用原理。研究这些内容,主要是公司业务数据增长速度过快,单表数据过于庞大,而且如果只做冷热数据分离不够友好,而且不能解决目前业务的发展问题,打算利用分表来实现,而且结合自身业务以及两种框架原理,本着符合业务场景,可靠度高,接入成本低,具有良好的文档,活跃的社区的原则,打算采用shardingJdbc,涉及到分表策略选择使用城市的维度。

若有收获,就点个赞吧
0 人点赞
