1、统计计算函数
相对于单行函数,也可称之为多行函数,它的输入是多个行构成得一个行集(这个行集可以是 一张表的所有行,也可以是按照某个维度进行分组后的某一组行),而输出都是一个值; 比如常见的一些分组计算需求:求某个部门的薪资总和,薪资平均值,薪资最大值等等。
- 求和 (SUM)
- 求平均值(AVG)
- 计数(COUNT)
- 求标准差(STDDEV)
- 求方差(VARIANCE)
- 求最大值(MAX)
求最小值(MIN) ```sql 遍历表的各行数据,统计完后再返回结果
sum
1 求员工工资总和
select sum(sal) from emp;
count
1 求员工数量,有奖金的员工数
select count(*) 员工数量, count(comm) from empcount(*) 只要一行有数据就统计count(comm) 只有comm 不是null才统计【结论】:NULL不会参与统计函数的统计
2 求工作岗位数量 统计去重
select count(distinct job) from emp;
max/min
求员工最高工资和最低工资
avg
求员工平均工资select avg(sal) from emp;求员工平均奖金(三种方式)select avg(comm) ,sum(comm)/count(*) ,sum(comm)/count(comm) from emp;
<a name="aQhHE"></a>### A、SQL中使用分组计算函数的语法```sqlSELECT [column,] group_function(column), ...FROM table[WHERE condition][GROUP BY column][ORDER BY column];
B、AVG、MAX、MIN、SUM对数值进行计算
SELECT AVG(salary), MAX(salary), MIN(salary), SUM(salary)FROM employeesWHERE job_id LIKE '%REP%';
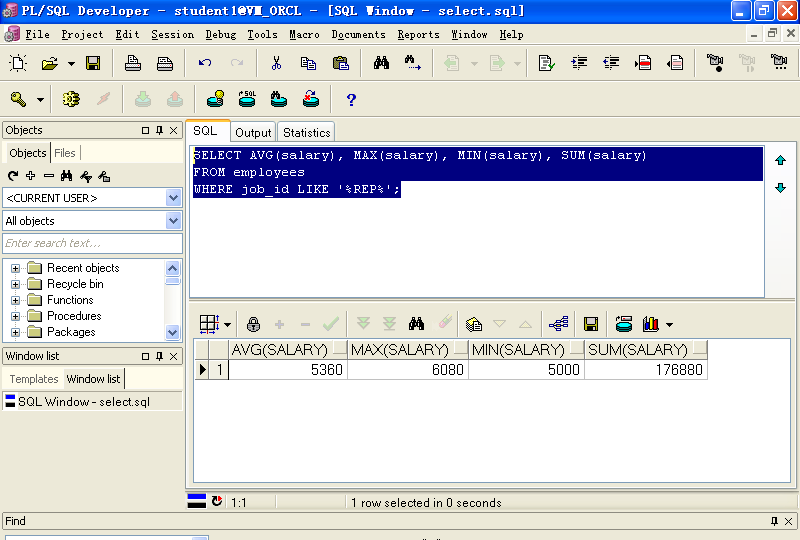
C、MAX、MIN对日期进行计算
SELECT MIN(hire_date), MAX(hire_date)FROM employees;
 :::danger
备注:MIN,MAX 可用于任何数据类型,但AVG , SUM,STDDEV,VARIANCE仅适用于数值型字段。
:::
:::danger
备注:MIN,MAX 可用于任何数据类型,但AVG , SUM,STDDEV,VARIANCE仅适用于数值型字段。
:::
D、COUNT函数
| 函数用法 | 意义 |
|---|---|
COUNT(*) |
返回满足选择条件的所有行的行数,包括值为空的行和重复的行。 |
COUNT(expr) |
返回满足选择条件的且表达式不为空行数。 |
COUNT(DISTINCT expr) |
返回满足选择条件的且表达式不为空,且不重复的行数。 |
**SELECT COUNT(1)** 和 **SELECT COUNT(*)**, **SELECT COUNT(column1)** 返回的结果一样
2、使用GROUP BY子句进行分组统计
select ...from ...where ...group by 列1,列2.... --根据某列、多列进行分组having condorder by1 查询各部门平均工资select deptno , avg(sal)from empgroup by deptno【结论】:统计函数在有分组的情况下,统计的就是每个分组里边多行数据没有分组的情况下,就是统计全表在select 中出现的列,必须在group by中出现 ,除了统计函数2 查询平均薪水大于2000的部门select deptno , avg(sal)from empwhere avg(sal) > 2000group by deptno第 3 行出现错误:ORA-00934: 此处不允许使用分组函数where 里边不允许使用分组函数进行判断使用havingselect deptno , avg(sal)from empgroup by deptnohaving avg(sal) > 20003 求10号部门员工的平均薪水select deptno , avg(sal)from empwhere deptno = 10group by deptnohavingselect deptno , avg(sal)from empgroup by deptnohaving deptno = 104 having与where的区别select ..from empwhere condgroup ...havin condorder by ...where能做的having也能做,where不能做的having也能做结论:能用where就别用having1 从from 的表 emp 拿出数据2 逐行筛选,通过where条件来筛选 , 结果集13 分组,并且计算统计函数 ,结果集24 再进行筛选,having的条件,通过having的条件就留下,得到结果集35 排序 得到结果集如果一开始不通过where筛选,后边计算量大
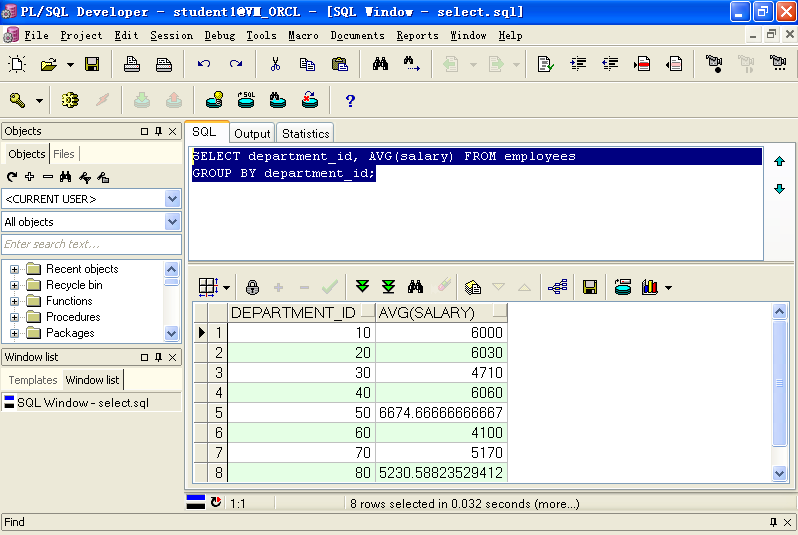
1.可以按照某一个字段分组,也可以按照多个字段的组合进行分组
SELECT department_id, AVG(salary) FROM employeesGROUP BY department_id;
SELECT department_id dept_id, job_id, SUM(salary),AVG(salary)FROM employeesGROUP BY department_id, job_id;
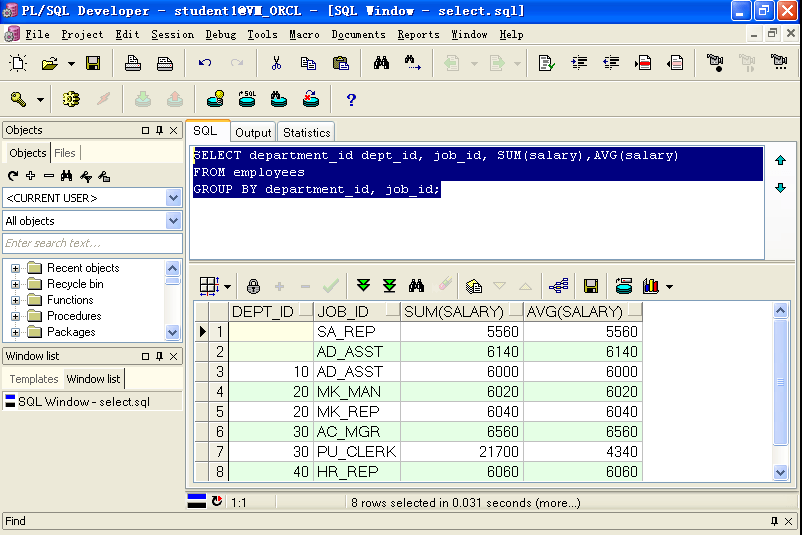
2.SELECT 查询语句中同时选择分组计算函数表达式和其他独立字段时 ,其他字段必须出现在Group By子 句中,否则不合法。
错误的写法
SELECT department_id, COUNT(last_name)FROM employees;
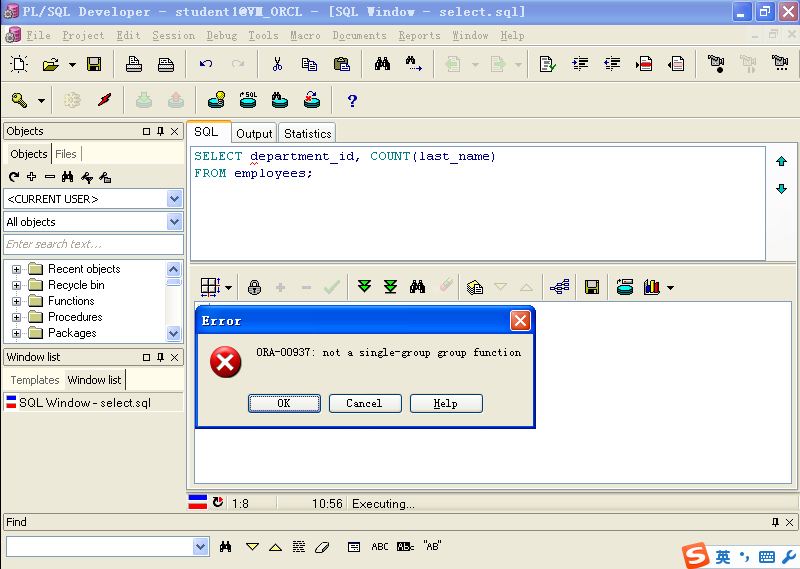
正确的写法
SELECT department_id, count(last_name) FROM employeesGROUP BY department_id;

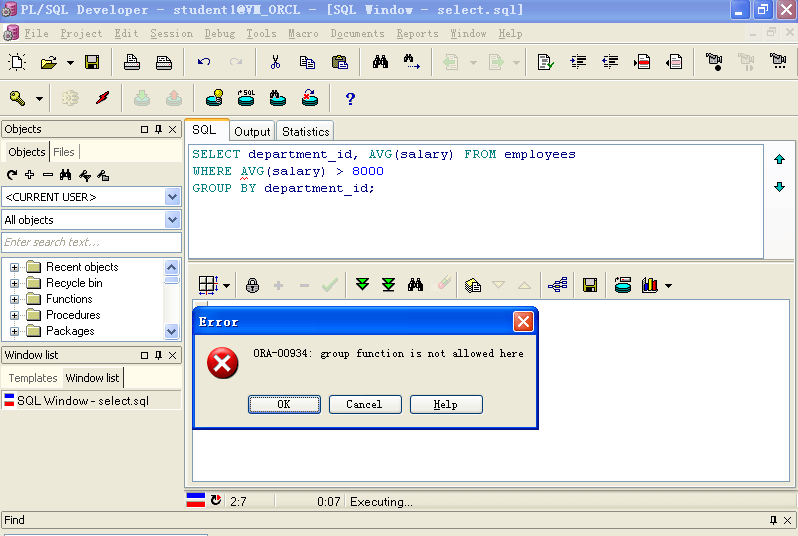
3.不能在Where 条件中使用分组计算函数表达式,当出现这样的需求的时候,使用Having 子句。
错误写法
SELECT department_id, AVG(salary) FROM employeesWHERE AVG(salary) > 8000GROUP BY department_id;
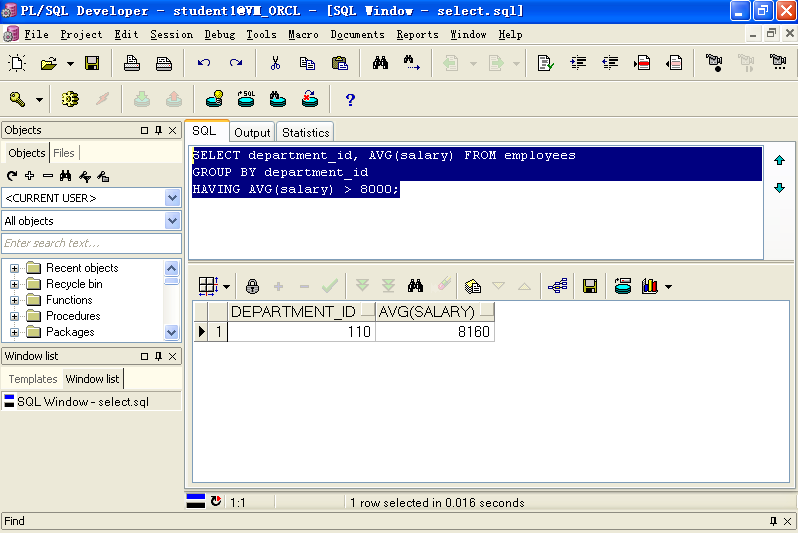
正确的写法
SELECT department_id, AVG(salary) FROM employeesGROUP BY department_idHAVING AVG(salary) > 8000;
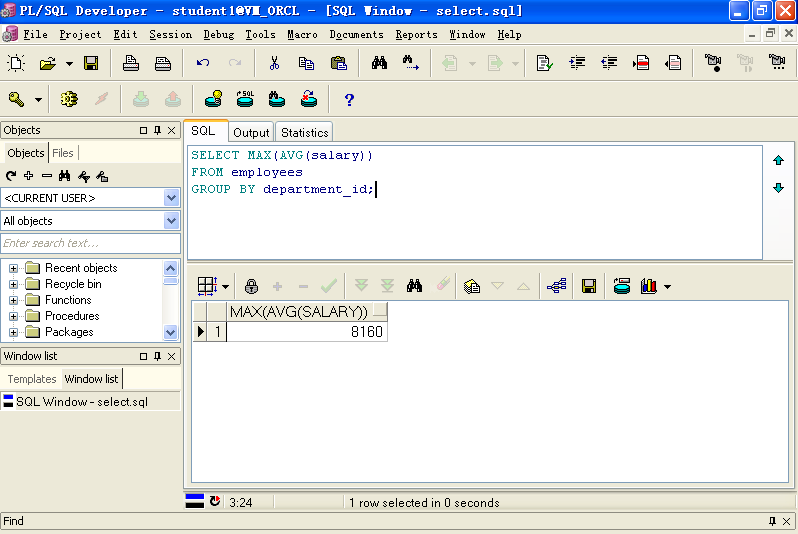
4.分组计算函数也可嵌套使用
SELECT MAX(AVG(salary))FROM employeesGROUP BY department_id;
3、GROUP BY语句增强
A.使用Rollup产生常规分组汇总行以及分组小计
SELECT department_id, job_id, SUM(salary)FROM employeesWHERE department_id < 60GROUP BY ROLLUP(department_id, job_id);
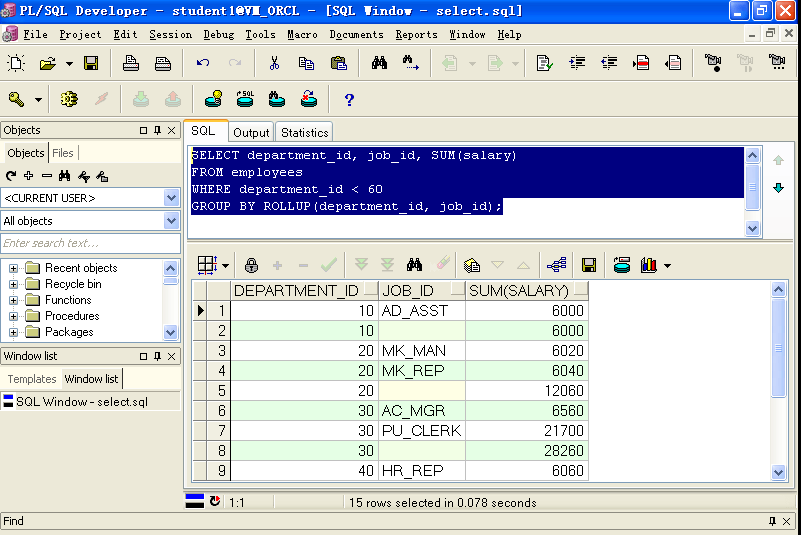
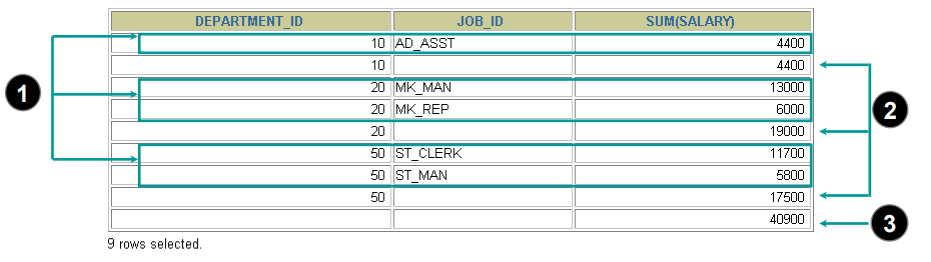
Rollup 后面跟了n个字段,就将进行n+1次分组,从右到左每次减少一个字段进行分组;然后进行 union
B.Cube产生Rollup结果集+多维度的交叉表数据源
SELECT department_id, job_id, SUM(salary)FROM employeesWHERE department_id < 60GROUP BY CUBE (department_id, job_id) ;
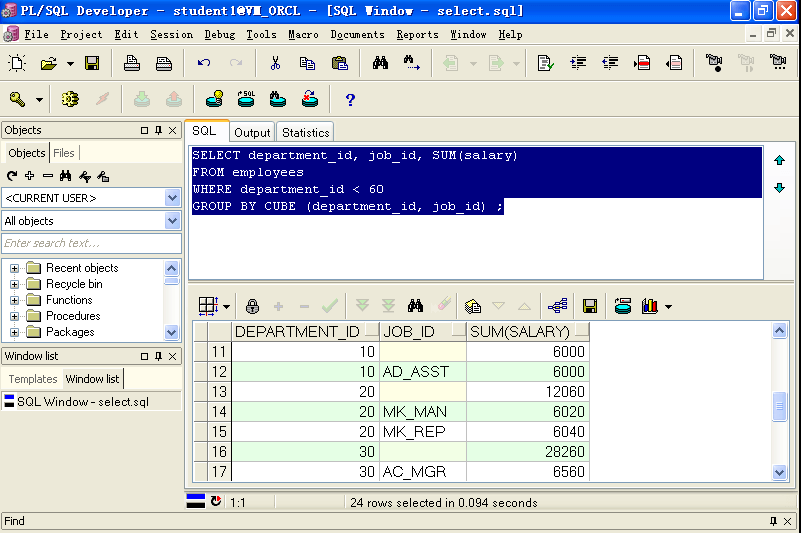
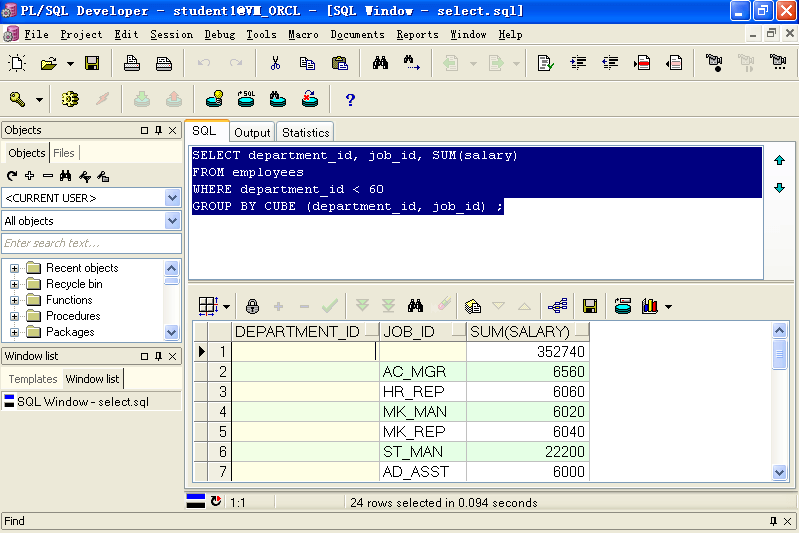
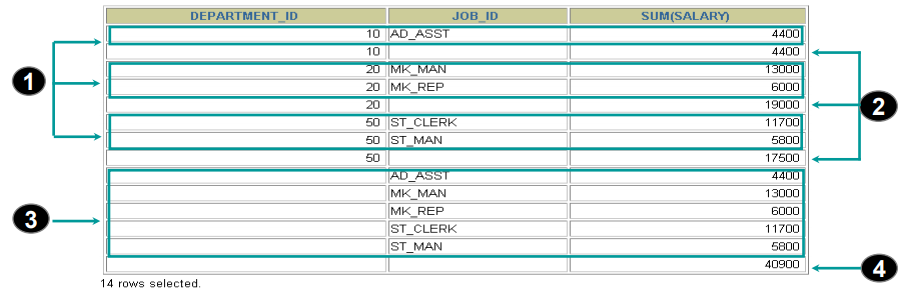
C.GROUPING函数
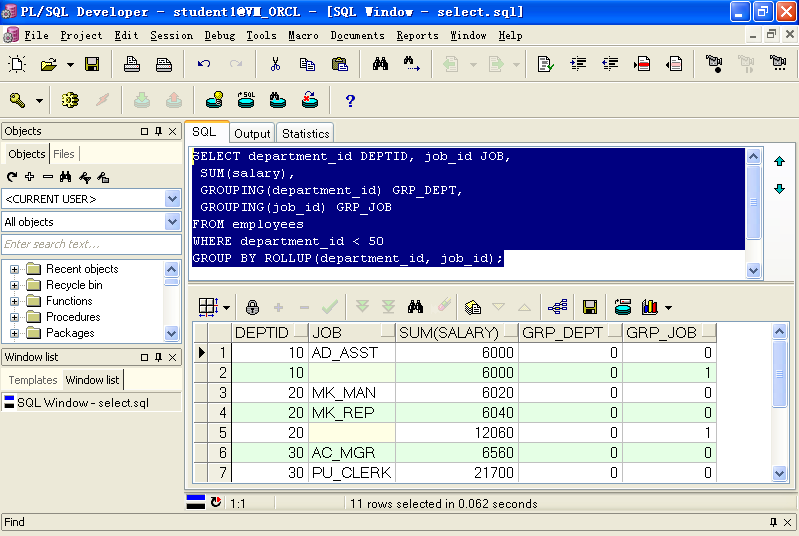
Rollup 和 Cube有点抽象,他分别相当于n+1 和 2的n次方常规 Group by 运 算;那么在Rollup 和 Cube的结果集中如何很明确的看出哪些行是针对那些列或者列的组合进行 分组运算的结果的? 答案是可以使用Grouping 函数; 没有被Grouping用到返回1,否则返回0
SELECT department_id DEPTID, job_id JOB,SUM(salary),GROUPING(department_id) GRP_DEPT,GROUPING(job_id) GRP_JOBFROM employeesWHERE department_id < 50GROUP BY ROLLUP(department_id, job_id);
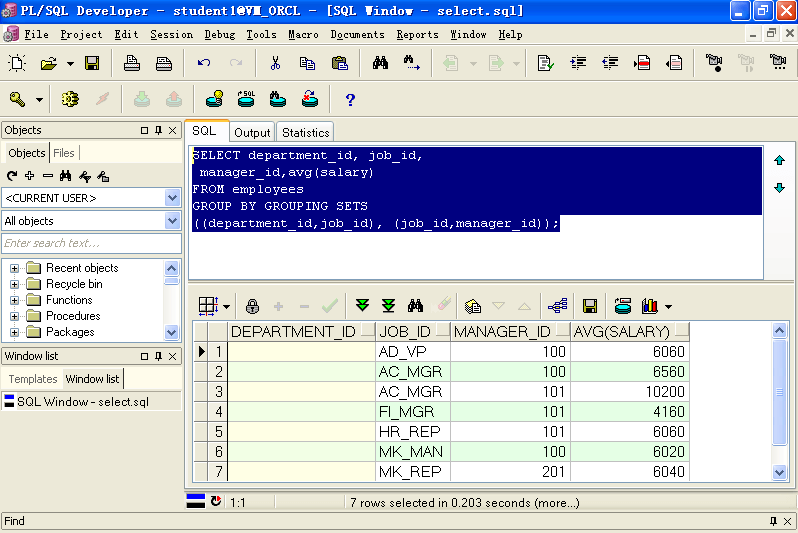
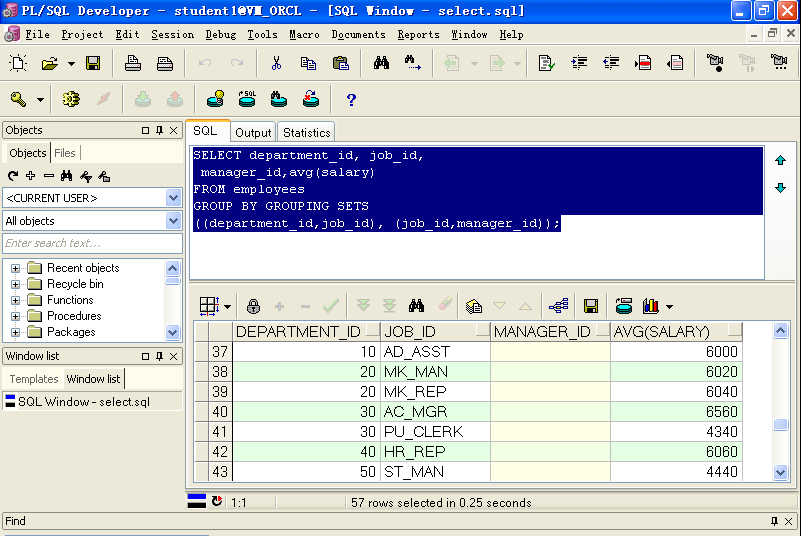
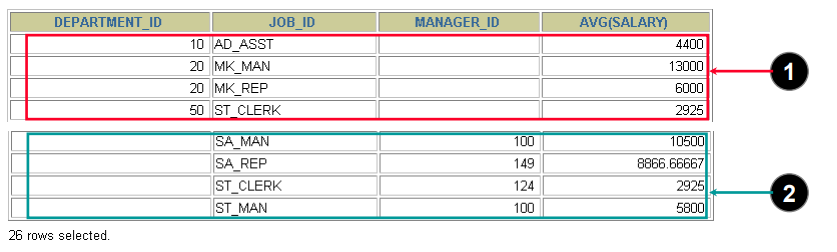
D.使用Grouping Set来代替多次UNION
SELECT department_id, job_id,manager_id,avg(salary)FROM employeesGROUP BY GROUPING SETS((department_id,job_id), (job_id,manager_id));

若有收获,就点个赞吧
0 人点赞
