分析函数over()
分析函数用于计算基于组的某种聚合值,它和聚合函数的不同之处是对于每个组返回多行,而聚合函数对于每个组只返回一行。
常见的分析函数如下:
row_number() over(partition by ... order by ...)rank() over(partition by ... order by ...)dense_rank() over(partition by ... order by ...)sum() over(partition by ... order by ...)first_value() over(partition by ... order by ...)last_value() over(partition by ... order by ...)count() over(partition by ... order by ...):求分组后的总数。max() over(partition by ... order by ...):求分组后的最大值。min() over(partition by ... order by ...):求分组后的最小值。avg() over(partition by ... order by ...):求分组后的平均值。lag() over(partition by ... order by ...):取出前n行数据。lead() over(partition by ... order by ...):取出后n行数据。ratio_to_report() over(partition by ... order by ...):Ratio_to_report() 括号中就是分子,over() 括号中就是分母。percent_rank() over(partition by ... order by ...):
1、分组排序
A.row_number()
rank() over(partition by column1 ORDER BY column2)
column1:依据分组的列
column2:依据排序的列
select prov_name, city_name, val_cnt,row_number() over(partition by prov_name ORDER BY val_cnt) AS restfrom test_orer_partition_by;

B.rank()
rank() over(partition by column1 ORDER BY column2)
column1:依据分组的列
column2:依据排序的列
select prov_name, city_name, val_cnt,rank() over(partition by prov_name) AS restfrom test_orer_partition_by;

C.dense_rank()
dense_rank() over(partition by column1 ORDER BY column2)
column1:依据分组的列
column2:依据排序的列
select prov_name, city_name, val_cnt,dense_rank() over(partition by prov_name ORDER BY val_cnt) AS restfrom test_orer_partition_by;

2、聚合函数(sum、avg、count、max、min、first_value、last_value)
A.sum()
sum() over([partition by prov_name [ORDER BY val_cnt]])
有**order by**;按照排序连续累加;
无**order by**,计算**partition by**后的和;**over()**中没有**partition by**,计算所有数据总和
select prov_name, city_name, val_cnt,sum(val_cnt) over(partition by prov_name ORDER BY val_cnt) AS rstfrom test_orer_partition_by ;
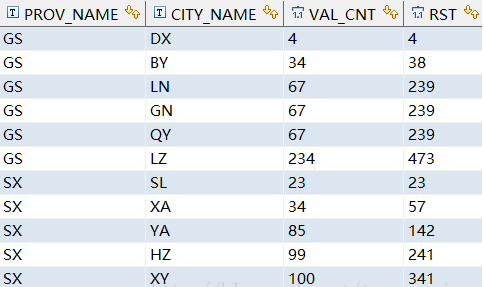
select prov_name, city_name, val_cnt,sum(val_cnt) over(partition by prov_name) AS rstfrom test_orer_partition_by ;

select prov_name, city_name, val_cnt,sum(val_cnt) over() AS rstfrom test_orer_partition_by ;

3、分许函数(lag、lead)
lag、lead有三个参数,第一个是表达式或字段,第二个是偏移量,第三个是为控制赋值
A.lead
lead() over([partition by prov_name [ORDER BY val_cnt]])
select prov_name, city_name, val_cnt,lead(val_cnt, 1) over(partition BY prov_name ORDER BY val_cnt) AS rstfrom test_orer_partition_by ;
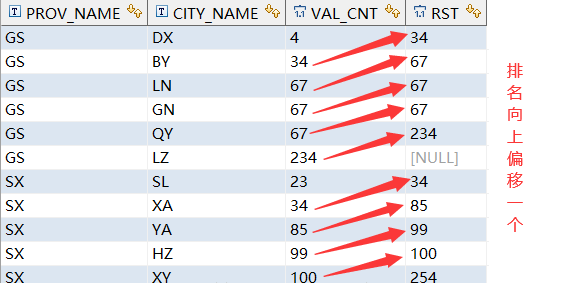
select prov_name, city_name, val_cnt,lead(val_cnt, 2) over(partition BY prov_name ORDER BY val_cnt) AS rstfrom test_orer_partition_by ;

B.lag
lag与lead用法相同,只是偏移顺序相反

若有收获,就点个赞吧
0 人点赞
