MySQL
如图: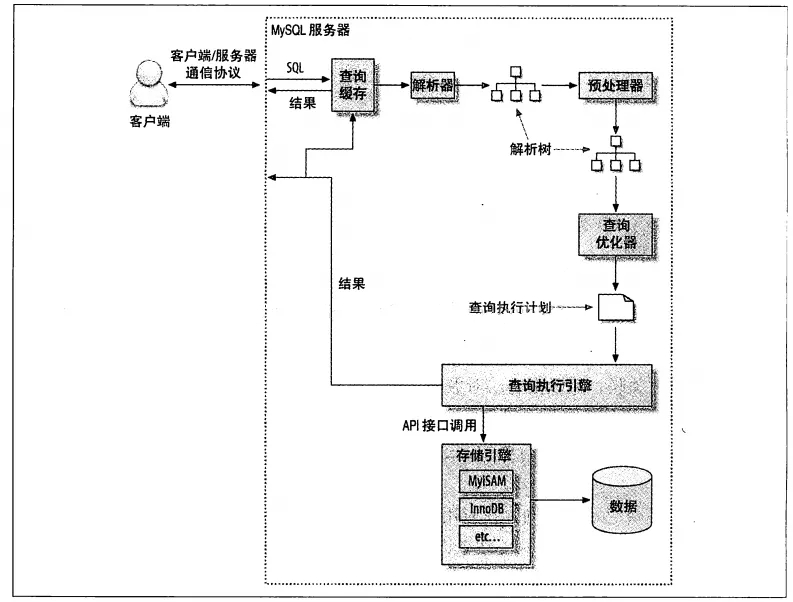
- 客户端发送一个查询给服务器。
- 服务器先检查查询缓存,如果命中,则直接返回缓存中的结果。如果没有没有命中,则进入下一阶段(解析器)。
- 服务器由解析器检查sql语法是否正确,然后由预处理器检查sql中的表和字段是否存在,最后由查询优器生成执行计划。这一步很耗资源。
- mysql根据优化器生成的执行计划,调用存储引擎的API来执行查询。
-
MySQL客户端和服务器之间的通信
在mysql服务器和客户端之间的通信时“半双工”的。就是在同一时刻要么由客户向Mysql服务器发送数据,要么由MySQL服务器向客户端发送数据。就像来回抛球游戏,任何时候只有一个人能控制球,而且只有控制球的人才能将球抛出去(发送消息)。
- 当客户端从MySQL服务器获取数据时,看起来像像是客户端向MySQL服务器拉取数据,但实际上是MySQL服务器向客户端推送数据。客户端不断的接受从服务推送过来的数据,客户端也没有办法让服务器停下来。
大多数连接MySQL的库函数都可以获取全部的结果集并缓存到内存中。MySQL通常需要等到数据全部推送给客户端后才能释放这条语句查询所暂用的资源。、
查询缓存
对执行计划的缓存
对于很多的数据库系统都能够缓存执行计划,对于完全相同的sql,可以使用已经已经存在的执行计划,从而跳过解析和生成执行计划的过程。
缓存查询计划通过JDBC的PreparedStatement进行说明。PreparedStatement是用来执行SQL查询语句的API之一,Java提供了Statement、PreparedStatement和CallableStatement三种方式来执行查询语句,其中Statement用于通用查询,PreparedStatement用于执行参数化查询,而CallableStatement则是用于存储过程。
Mysql执行计划的生成会占用相当多的CPU。理想的情况是,当多次发送一个statement到数据库,数据库应该对statement的存取方案进行重用。如果方案曾经被生成过的话,这将减少CPU的使用率。
数据库已经具有了类似的功能。它们通常会用如下方法对statement进行缓存。使用statement本身作为key并将存取方案存入与statement对应的缓存中。这样数据库引擎就可以对曾经执行过的statements中的存取方案进行重用。举个例子,如果发送一条包含SELECT a, b FROM t WHERE c = 2的statement到数据库,然后首先会将存取方案进行缓存。当再次发送相同的statement时,数据库会对先前使用过的存取方案进行重用,这样就降低了CPU的开销。
注意,这里使用了整个statement为key。也就是说,如果发送一个包含SELECT a, b FROM t WHERE c = 3的statement的话,缓存中不会没有与之对应的存取方案。这是因为“c=3”与曾经被缓存过的“c=2”不同。所以,举个例子:for (int i = 0; i < 1000; i++) {PreparedStatement ps = conn.prepareStatement("select a,b from t where c = " + i);ResultSet rs = Ps.executeQuery();rs.close();ps.close();}
在这里缓存不会被使用,因为每一次迭代都会发送一条包含不同SQL语句的statement给数据库。并且每一次迭代都会生成一个新的存取方案。现在来看看下一段代码:
PreparedStatement ps = conn.prepareStatement("select a,b from t where c = ?");for (int i = 0; i < 1000; i++) {ps.setInt(1, i);ResultSet rs = ps.executeQuery();rs.close();ps.close();}
这样就具有了更好的效率,这个
statement发送给数据库的是一条带有参数“?”的SQL语句。这样每次迭代会发送相同的statement到数据库,只是参数“c=?”不同。这种方法允许数据库重用statement的存取方案,这样就具有了更好的效率。这可以让应用程序速度更快,并且使用更少的CPU,这样数据库服务器就可以为更多的人提供服务。PreparedStatement是预编译的,对于批量处理可以大大提高效率. 也叫JDBC存储过程- 使用 Statement 对象。在对数据库只执行一次性存取的时侯,用
Statement对象进行处理。PreparedStatement对象的开销比Statement大,对于一次性操作并不会带来额外的好处。 statement每次执行sql语句,相关数据库都要执行sql语句的编译,preparedstatement是预编译的,preparedstatement支持批处理PreparedStatement可以防止SQL注入式攻击对完整的select查询结果的缓存
查询缓存的工作机制
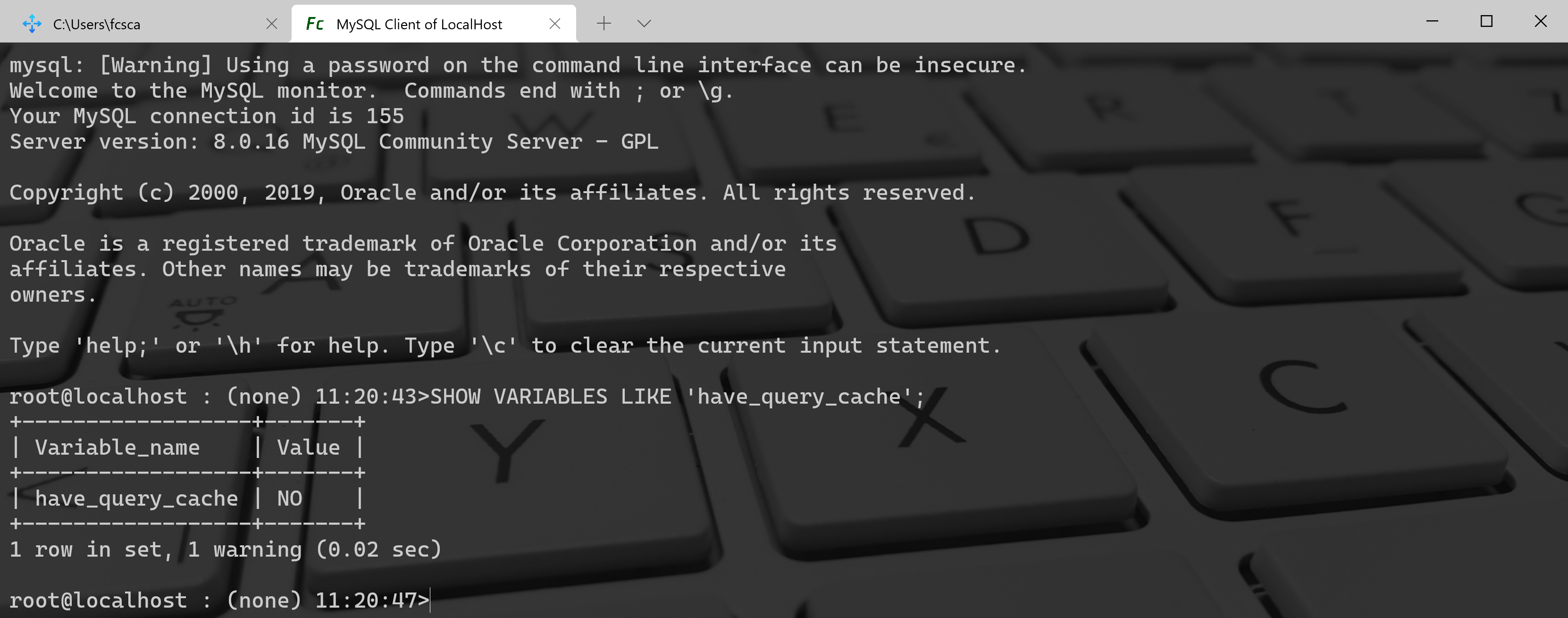
Mysql 判断是否命中缓存的办法很简单,首先会将要缓存的结果放在引用表中,然后使用查询语句,数据库名称,客户端协议的版本等因素算出一个hash值,这个hash值与引用表中的结果相关联。如果在执行查询时,根据一些相关的条件算出的hash值能与引用表中的数据相关联,则表示查询命中通过have_query_cache服务器系统变量指示查询缓存是否可用:mysql> SHOW VARIABLES LIKE 'have_query_cache';+------------------+-------+| Variable_name | Value |+------------------+-------+| have_query_cache | NO |+------------------+-------+
为了监视查询缓存性能,使用SHOW STATUS查看缓存状态变量:
| 变量名 | 值 | | —- | —- | | Qcache_free_blocks | 36 | | Qcache_free_memory | 138488 | | Qcache_hits | 79570 | | Qcache_inserts | 27087 | | Qcache_lowmem_prunes | 3114 | | Qcache_not_cached | 22989 | | Qcache_queries_in_cache | 415 | | Qcache_total_blocks | 912 |mysql> SHOW STATUS LIKE 'Qcache%';
查询缓存机制失效的场景
如果查询语句中包含一些不确定因素时(例如包含函数Current()),该查询不会被缓存,不确定因素主要包含以下情况。
引用了一些返回值不确定的函数 | 函数名 | 函数名 | 函数名 | 函数名 | | —- | —- | —- | —- | |
BENCHMARK()|CONNECTION_ID()|CURDATE()|CURRENT_DATE()| |CURRENT_TIME()|CURRENT_TIMESTAMP()|CURTIME()|DATABASE()| | 带一个参数的ENCRYPT()|FOUND_ROWS()|GET_LOCK()|LAST_INSERT_ID()| |LOAD_FILE()|MASTER_POS_WAIT()|NOW()|RAND()| |RELEASE_LOCK()|SYSDATE()| 不带参数的UNIX_TIMESTAMP()|USER()|引用自定义函数(UDFs)。
- 引用自定义变量
- 引用MySQL系统数据库中的表。
- 引用临时表
- 引用存储函数
- 任何包含列级别权限的表
- 不使用任何表
- 下面方式中的任何一种:
| 语句 | 是否缓存 |
| —- | —- |
|
SELECT ...IN SHARE MODE| 否 | |SELECT ...FOR UPDATE| 否 | |SELECT ...INTO OUTFILE ...| 否 | |SELECT ...INTO DUMPFILE ...| 否 | | `SELECT- FROM …WHERE autoincrement_col IS NULL` | 否 |
查询缓存的额外的消耗
如果使用查询缓存,在进行读写操作时会带来额外的资源消耗,消耗主要体现在以下几个方面:
- 查询的时候会检查是否命中缓存,这个消耗相对较小
- 如果没有命中查询缓存,MYSQL会判断该查询是否可以被缓存,而且系统中还没有对应的缓存,则会将其结果写入查询缓存
- 如果一个表被更改了,那么使用那个表的所有缓冲查询将不再有效,并且从缓冲区中移出。这包括那些映射到改变了的表的使用MERGE表的查询。一个表可以被许多类型的语句更改,例如
INSERT、UPDATE、DELETE、TRUNCATE、ALTER TABLE、DROP TABLE或DROP DATABASE。
对于InnoDB而言,事物的一些特性还会限制查询缓存的使用。当在事物A中修改了B表时,因为在事物提交之前,对B表的修改对其他的事物而言是不可见的。为了保证缓存结果的正确性,InnoDB采取的措施让所有涉及到该B表的查询在事物A提交之前是不可缓存的。如果A事物长时间运行,会严重影响查询缓存的命中率
查询缓存的空间不要设置的太大。
因为查询缓存是靠一个全局锁操作保护的,如果查询缓存配置的内存比较大且里面存放了大量的查询结果,当查询缓存失效的时候,会长时间的持有这个全局锁。因为查询缓存的命中检测操作以及缓存失效检测也都依赖这个全局锁,所以可能会导致系统僵死的情况。
查询缓存的配置参数
query_cache_limit
MYSQL能够缓存的最大查询结果,查询结果大于该值时不会被缓存。默认值是1048576(1MB)。如果某个查询的结果超出了这个值,Qcache_not_cached的值会加1,如果某个操作总是超出可以考虑在SQL中加上SQL_NO_CACHE来避免额外的消耗
query_cache_min_res_unit
查询缓存分配的最小块的大小(字节)。默认值是4096(4KB)
query_cache_size
为缓存查询结果分配的内存的数量,单位是字节,且数值必须是1024的整数倍。默认值是0,即禁用查询缓存。请注意即使query_cache_type设置为0也将分配此数量的内存。
query_cache_type
设置查询缓存类型,默认设为ON。设置GLOBAL值可以设置后面的所有客户端连接的类型。客户端可以设置SESSION值以影响他们自己对查询缓存的使用。
下面的表显示了可能的值:
| 选项 | 描述 |
| —- | —- |
| 0或OFF | 不要缓存或查询结果。请注意这样不会取消分配的查询缓存区。要想取消,应将query_cache_size设置为0。 |
| 1或ON | 缓存除了以SELECT
SQL_NO_CACHE开头的所有查询结果。 |
| 2或DEMAND | 只缓存以SELECT
SQL_NO_CACHE开头的查询结果。 |
query_cache_wlock_invalidate
一般情况,当客户端对MyISAM表进行WRITE锁定时,如果查询结果位于查询缓存中,则其它客户端未被锁定,可以对该表进行查询。将该变量设置为1,则可以对表进行WRITE锁定,使查询缓存内所有对该表进行的查询变得非法。这样当锁定生效时,可以强制其它试图访问表的客户端来等待。
查询缓存的优化流程
当开启了查询缓存的功能后,可以通过一些参数以及状态值来观察查询缓存的使用情况。
流程以及涉及到的参数参见下图: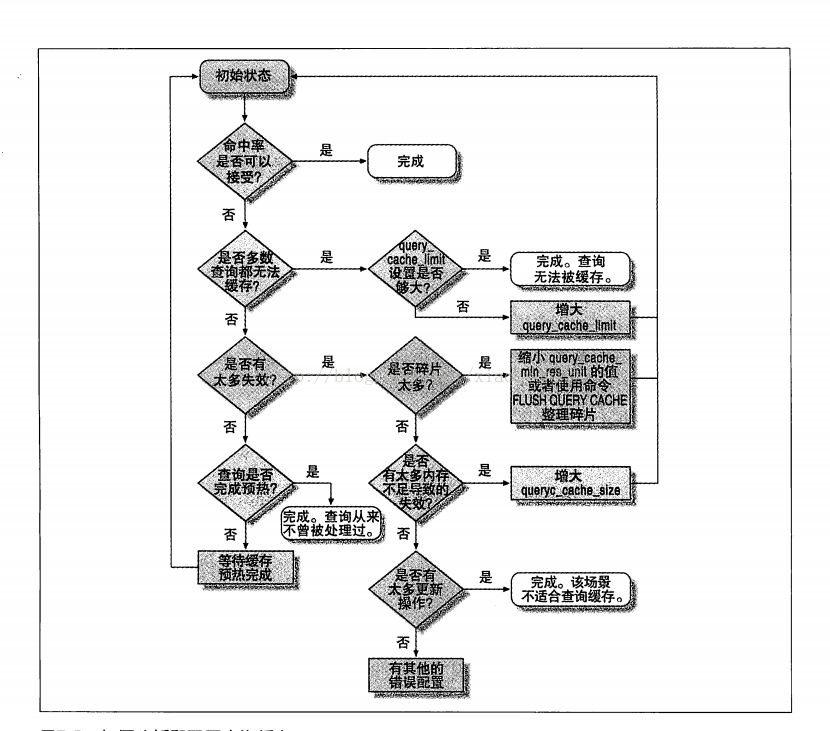
查询缓存的优化
除了上图提到的一些优化策略外,还可以通过下面的措施来提高查询缓存的效率
- 尽量用小表的简单替代大表的复杂查询
- 尽量用批量写入取代单条写入
- 控制
query_cache_size的大小,甚至是禁用查询缓存 - 通过DEMAND+SQL_CACHE/SQL_NO_CACHE来灵活控制某个select是否需要进行缓存
- 对于写密集型的应用,直接禁用查询缓存

若有收获,就点个赞吧
0 人点赞
