MySQL 字符集
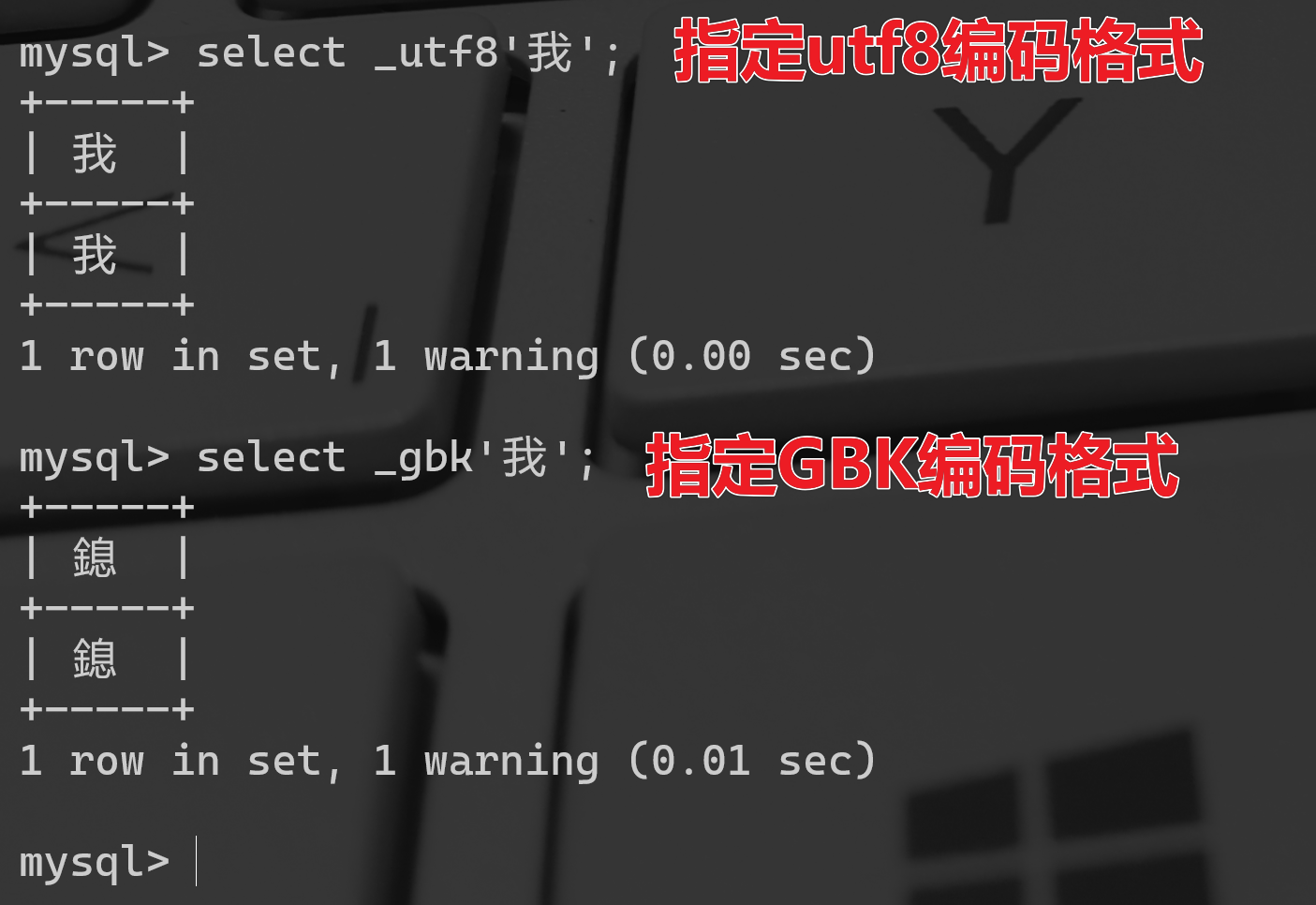
使用MySQL客户端书写SQL语句的时候,可以在字符串前边加_charset_name的符号,其中的charset_name对应着某个具体的字符集,这样可以看到MySQL Server端返回响应设置编码的结果
mysql> select _utf8'我';+-----+| 我 |+-----+| 我 |+-----+1 row in set, 1 warning (0.00 sec)mysql> select _gbk'我';+-----+| 鎴 |+-----+| 鎴 |+-----+1 row in set, 1 warning (0.01 sec)
原因**
MySQL是一个C/S架构的软件,可以有很多客户端连接到服务器进行交互。客户端发送给服务器的请求以及服务器发送给客户端的响应本质上都是一个二进制的字节串,从客户端发送一个请求到服务器,服务器处理完成之后再把响应返回给客户端的过程其实发生了很多字符集转换过程。
- 首先请求会被MySQL客户端编码为字节序列之后通过网络传输到服务器。
对于MySQL自带的客户端来说,这个编码过程使用的字符集和使用的操作系统的默认字符集是一样的,类Unix系统的默认字符集就是utf8,Windows系统的默认字符集就是gbk。 - 服务器收到字节序列请求之后,会认为该字节串是按照
character_set_client系统变量编码的,之后将其从character_set_client转换到character_set_connection,之后进行更深入的处理。 - 最后再将响应发送到客户端的时候,又会按照
character_set_results进行编码。 - 客户端收到响应字节串之后,按照本客户端规定的字符集进行解码。
对于MySQL自带的客户端来说,这个解码过程使用的字符集和使用的操作系统的默认字符集是一样的,类Unix系统的默认字符集就是utf8,Windows系统的默认字符集就是gbk。
总结一下这几个涉及到的通信字符集系统变量:
| 系统变量 | 描述 |
|---|---|
character_set_client |
服务器解码请求时使用的字符集 |
character_set_connection |
服务器处理请求时会把请求字符串从character_set_client转为character_set_connection |
character_set_results |
服务器向客户端返回数据时使用的字符集 |
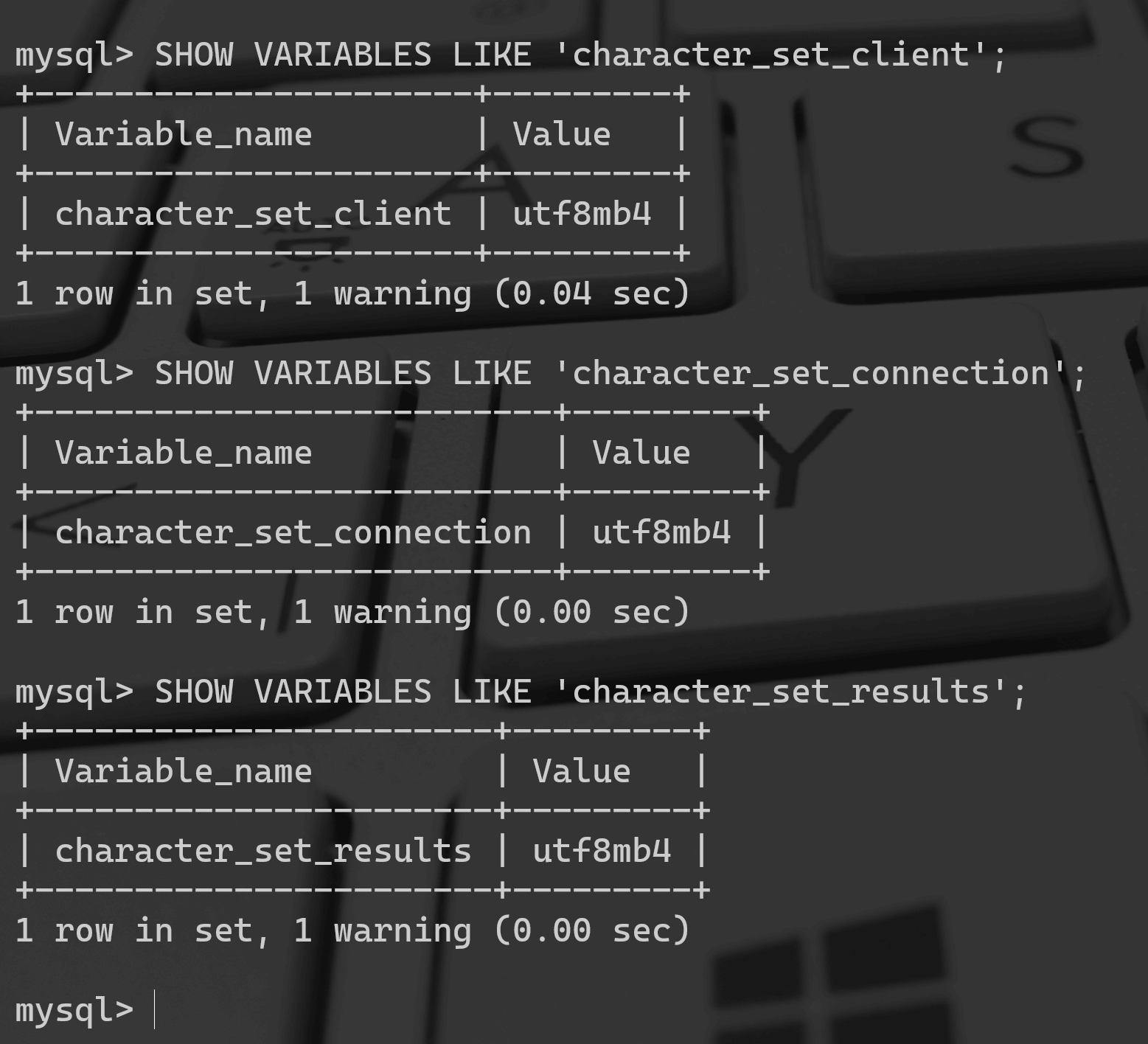
现在系统中的这几个系统变量设置的值都是utf8mb4 (对utf8格式的增强,MySQL的utf8有bug,后期使用utf8mb4才是完整版):
mysql> SHOW VARIABLES LIKE 'character_set_client';+----------------------+---------+| Variable_name | Value |+----------------------+---------+| character_set_client | utf8mb4 |+----------------------+---------+1 row in set, 1 warning (0.04 sec)mysql> SHOW VARIABLES LIKE 'character_set_connection';+--------------------------+---------+| Variable_name | Value |+--------------------------+---------+| character_set_connection | utf8mb4 |+--------------------------+---------+1 row in set, 1 warning (0.00 sec)mysql> SHOW VARIABLES LIKE 'character_set_results';+-----------------------+---------+| Variable_name | Value |+-----------------------+---------+| character_set_results | utf8mb4 |+-----------------------+---------+1 row in set, 1 warning (0.00 sec)
如果使用了_charset_name前缀,意味着禁止服务器将后续字节从character_set_client转换到character_set_connection,而是默认使用_charset_name代表的字符集作为它后续字节的字符集。所以
- 客户端发送请求时会将字符’我’按照
utf8进行编码,也就是:0xE68891。 - 服务器收到请求后发现有前缀
_gbk,则不会将其后边的字节0xE68891进行从character_set_client到character_set_connection的转换,而是直接把0xE68891认为是某个字符串由gbk编码后得到的字节序列。 - 然后再把上述
0xE68891从gbk转换为character_set_results,也就是utf8。0xE688在gbk中代表汉字'鎴',而0x91无法解码。 - 之后将汉字
'鎴'再按照utf8进行编码,得到的结果就是E98EB4,把它发送到客户端。 - 客户端收到之后再解码到屏幕上,解码也使用
utf8字符集,所以就出现了鎴。
以上文字内容的流程图: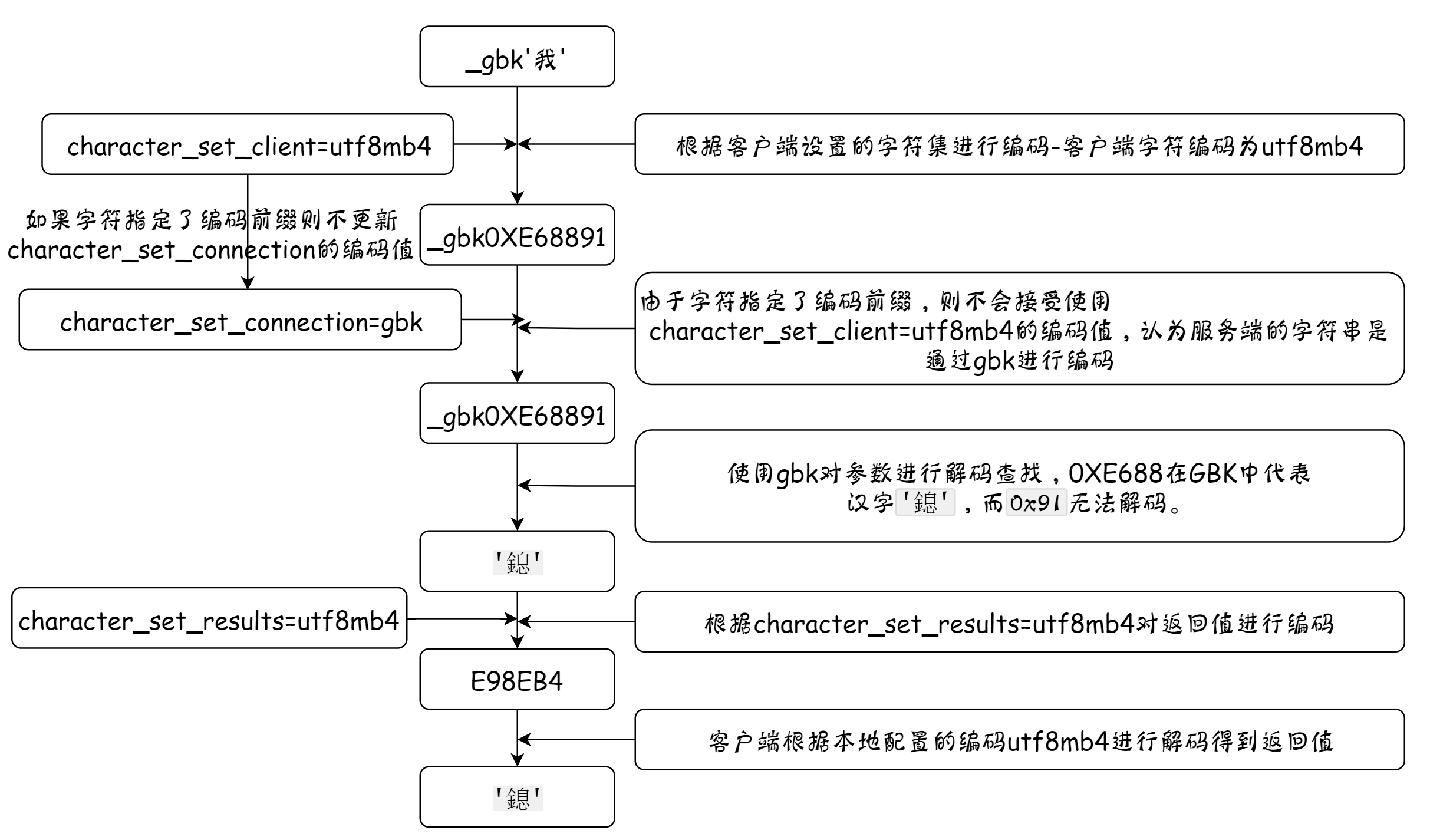
执行 show warnings; 发现解码警告,因为gbk格式解码找不到对应的字符,只能匹配返回前面的内容,后面的不能解析便warning;
mysql> show warnings;+---------+------+--------------------------------------------------------------------------------------------+| Level | Code | Message |+---------+------+--------------------------------------------------------------------------------------------+| Warning | 1366 | Incorrect string value: '\xD6\xD0\xB9\xFA\xB1\xEA...' for column 'VARIABLE_VALUE' at row 1 |+---------+------+--------------------------------------------------------------------------------------------+1 row in set (0.00 sec)

扩展
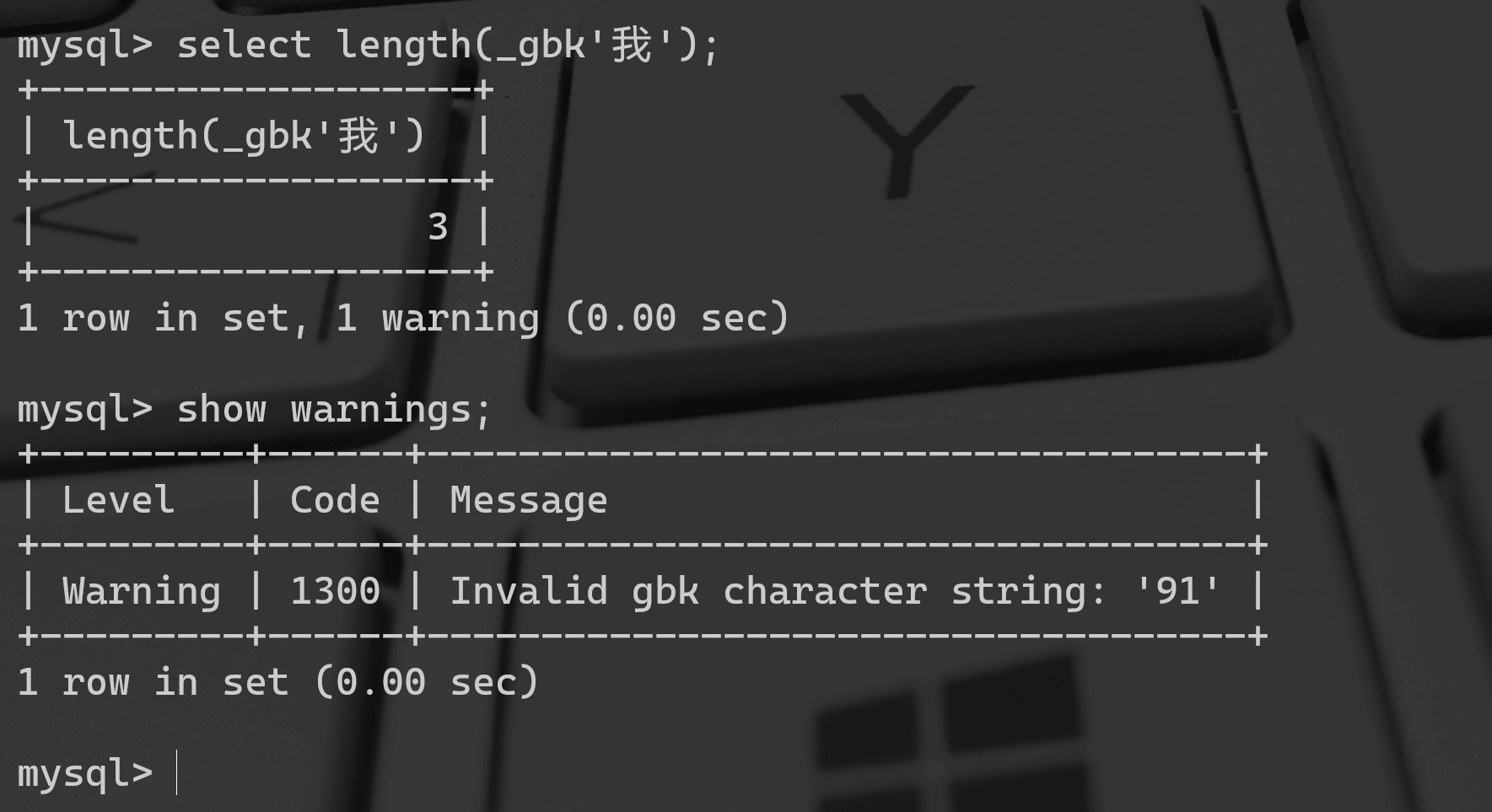
在本机环境执行 select length(_gbk'我');
mysql> select length(_gbk'我');+-------------------+| length(_gbk'我') |+-------------------+| 3 |+-------------------+1 row in set, 1 warning (0.00 sec)

因为’我’前边加了_gbk,所以不会经历从character_set_client到character_set_connection的转换过程,而是直接把0xE68891当作是一个采用gbk编码的字节串。这个字节串中有3个字节,当然结果就返回3了(虽然0x91这个字节在gbk字符集中是无效的,可以看到上边查询语句中也给出了Warning)。
mysql> show warnings;+---------+------+------------------------------------+| Level | Code | Message |+---------+------+------------------------------------+| Warning | 1300 | Invalid gbk character string: '91' |+---------+------+------------------------------------+1 row in set (0.00 sec)

若有收获,就点个赞吧
0 人点赞
