最早的数据库都是单机的,其最大的痛点是啥?
无法线性扩展。
磁盘能力无法线性扩展,内存能力无法线性扩展,计算能力无法线性扩展。
如今,喜欢创造概念的架构师们,把这种架构称为“Shared Everything”架构。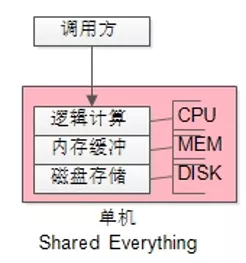
如上图所示,DISK/MEM/CPU 都耦合在一个DBMS进程内,必须部署在一台服务器上,完全处于竞争态,无法线性扩展,并行处理较差。
数据库单机部署,就是典型的“Shared Everything”架构。
如何来提升系统的并行能力呢?
最容易想到的,就是把无状态的逻辑计算部分,从DBMS进程内拆分出来,做成可扩展的微服务集群,实现“计算与存储分离”。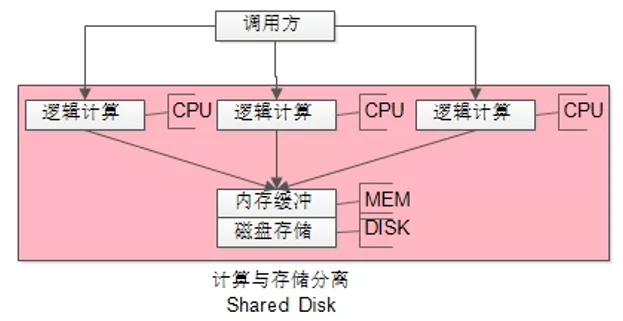
如上图所示:
(1)CPU逻辑计算拆分出了独立的进程,可以集群部署,能够线程扩展;
(2)DISK/MEM 仍耦合在一个进程内,仍处于竞争态,无法线性扩展;
Oracle Rac,就是典型的“Shared Disk”架构,核心思路是“计算与存储分离”。
存储部分磁盘IO仍有集中的资源竞争,还有没有进一步的优化空间呢?
最容易想到的,就是把数据打散,分布到不同的数据库实例上,每部分数据享有单独的资源。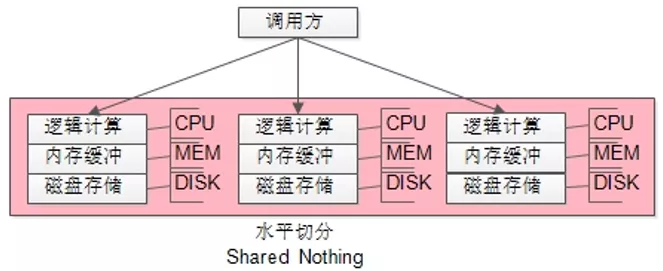
如上图所示:
(1)把整体数据存储分为了N份,每份之间没有交集;
(2)每份数据的 DISK/MEM/CPU 都在一个DBMS进程内,部署在一台服务器上;
(3)每份数据的资源之间的没有竞争;
没错,这就是“水平切分”,它是典型的”Shared Nothing”架构。
对 Shared Everything/Disk/Nothing 这些高大上的名词。
水平切分存在什么问题呢?
水平切分虽然是一种可扩展架构,能够实现线性扩展资源,但它会使得调用方失去数据的全局视野,使得调用方能力受限:
(1)无法实现全局JOIN;
(2)无法实现全局排序;
(3)无法支持集函数;
(4)原访问一次DBMS的操作,需要调用多次;
(5)…
并把一些原本属于DBMS职责的工作,转嫁到调用方。
如何解决“线性扩展能力”,同时又解决“失去全局视野”与“调用方能力受限”的问题呢?
最容易想到的方案是,数据库主从集群,每份数据都进行复制,每个实例都独享 DISK/MEM/CPU 资源,避免实例之间的资源竞争。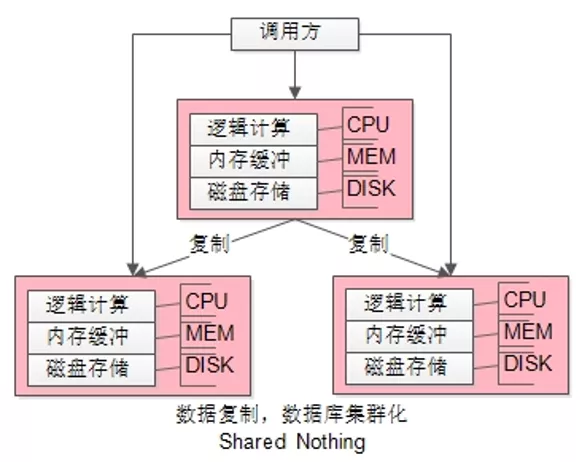
如上图所示:
(1)把整体数据存储分复制了N份,每份之间数据都一样;
(2)每份数据的 DISK/MEM/CPU 都在一个DBMS进程内,部署在一台服务器上;
(3)每份数据的资源之间的没有竞争;
理想很丰满,现实很骨干,思路没问题,但实际执行“复制”的过程中,会碰到一些问题。
以MySQL为例,有3种常见的复制方式:
(1)异步复制;
(2)半同步复制;
(3)组复制;
第一种,异步复制(Asynchronous Replication)
又叫主从复制(Primary-Secondary Replication),是互联网公司用的最多的数据复制与数据库集群化方法,它的思路是,从库执行串行化后的主库事务。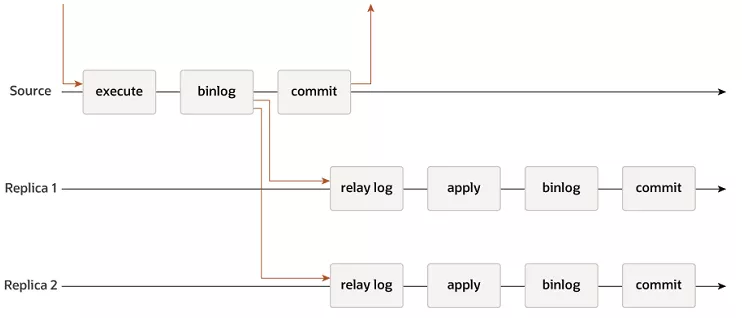
其核心原理如上图所示:
(1)第一条时间线:主库时间线;
- 主库执行事务
- 主库事务串行化binlog
- binlog同步给从库
- 主库事务提交完成(2)第二条/第三条时间线:从库时间线;
- 收到relay log
- 执行和主库一样的事务
- 生成自己的binlog(还可以继续二级从库)
- 从库事务提交完成
从这个时间线可以看到:
(1)主库事务提交;
(2)从库事务执行;
是并行执行的,主库并不能保证从库的事务一定执行成功,甚至不能保证从库一定收到相关的请求,这也是其称作“异步复制”的原因。第二种,半同步复制(Semi-synchronous Replication)
为了解决异步复制中“不能保证从库一定收到请求”等问题,对异步复制做了升级。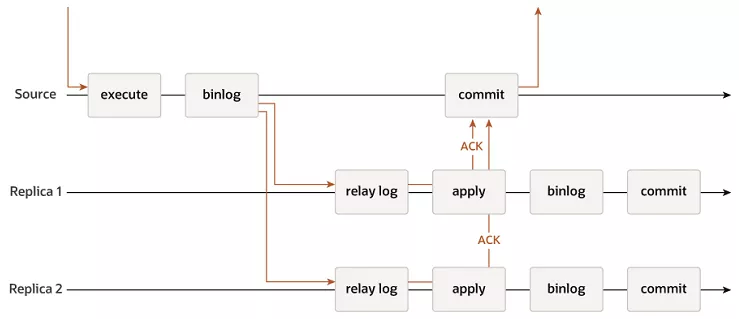
其核心原理如上图所示:(1)第一条时间线:主库时间线;
- 主库执行事务
- 主库事务串行化binlog
- binlog同步给从库
- 等从库确认收到请求,主库事务才提交完成(2)第二条/第三条时间线:从库时间线;
- 收到relay log
- 执行和主库一样的事务,并给主库一个确认
- 生成自己的binlog(还可以继续二级从库)
- 从库事务提交完成
从这个时间线可以看到:
(1)主库收到从库的ACK,才会提交;
(2)从库收到请求后,事务提交前,会给主库一个ACK;
半同步复制存在什么问题呢?
(1)主库的性能,会受到较大的影响,事务提交之前,中间至少要等待2个主从之间的网络TTL;
(2)从库仍然有延时,主从之间数据仍然不一致;
(3)主从角色有差异,主节点仍然是单点;
大数据量,高并发量的互联网业务,一般不使用“半同步复制”,更多的公司仍然使用“异步复制”的模式。
最后是MySQL5.7里,新提出的MySQL组复制。第三种,组复制(MySQL Group Replication,MGR)
MGR有一些帅气的能力:
(1)解决了单点写入的问题,一个分组内的所有节点都能够写入;
(2)最终一致性,缓解了一致性问题,可以认为大部分实例的数据都是最新的;
(3)高可用,系统故障时(即使是脑裂),系统依然可用;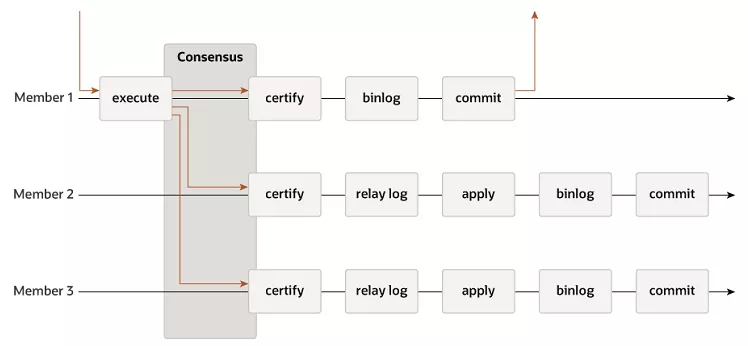
如上图所示:
(1)首先,分组内的MySQL实例不再是“主从”关系,而是对等的“成员”关系,故每个节点都可以写入;
(2)其次,增加了一个协商共识的认证(certify)环节,多数节点达成一致的事务才能提交;
画外音:Garela也是此类机制。
和MySQL传统的复制不同,MGR的核心是分布式共识算法,类似于Paxos。三类常见数据库架构
Shared Everything:数据库单机系统,资源竞争;
Shared Disk:Oracle Rac,计算与存储分离;
Shared Nothing:水平切分,复制集群,资源完全隔离;三类常见复制方式
异步复制:传统主从,互联网公司最常用;
半同步复制:从库确认,主库才提交;
组复制:MySQL 5.7的新功能,核心在于分布式共识算法;

若有收获,就点个赞吧
0 人点赞
