环境说明
Linux(CentOS7.3)-Redis6.0.5源码编译版
要判断一个元素是否存在,通常会怎么做?一般的做法都是将其保存起来然后通过比较确认,一共会有如下几种情况:
- 如果使用线性表或者数组存储,则查找的时间复杂度为 O(n)。
- 如果使用树存储,则查找的时间复杂度为 O(logn)。
- 如果使用哈希表存储,则查找的时间复杂度为 O(log(n/m)),m 为哈希分桶数。
对于上述三种情况相信大部分人都倾向于哈希表,因为其时间复杂度最低(在极端情况下时间复杂度可以为 O(1) ),但是哈希表也有缺陷,例如存储容量占比高,考虑到负载因子的存在,通常存储空间都不会被用完。当然无论是哈希表、树、线性表,一旦元素的数量极多时,查询的速度会变得很慢,而且占用的空间也会大到无法想象。那么有办法解决没有呢?答案是有,布隆过滤器就是解决该问题的利器。
布隆过滤器的设计思想
布隆过滤器是一个由 一个长度为 M 比特的位数组(bit array)与 K 个哈希函数(hash function) 组成的数据结构。布隆过滤器主要用于用于检索一个元素是否在一个集合中。
数组中的元素初始值都是 0 ,所有哈希函数可以把输入的数据均匀低散列。图例如下: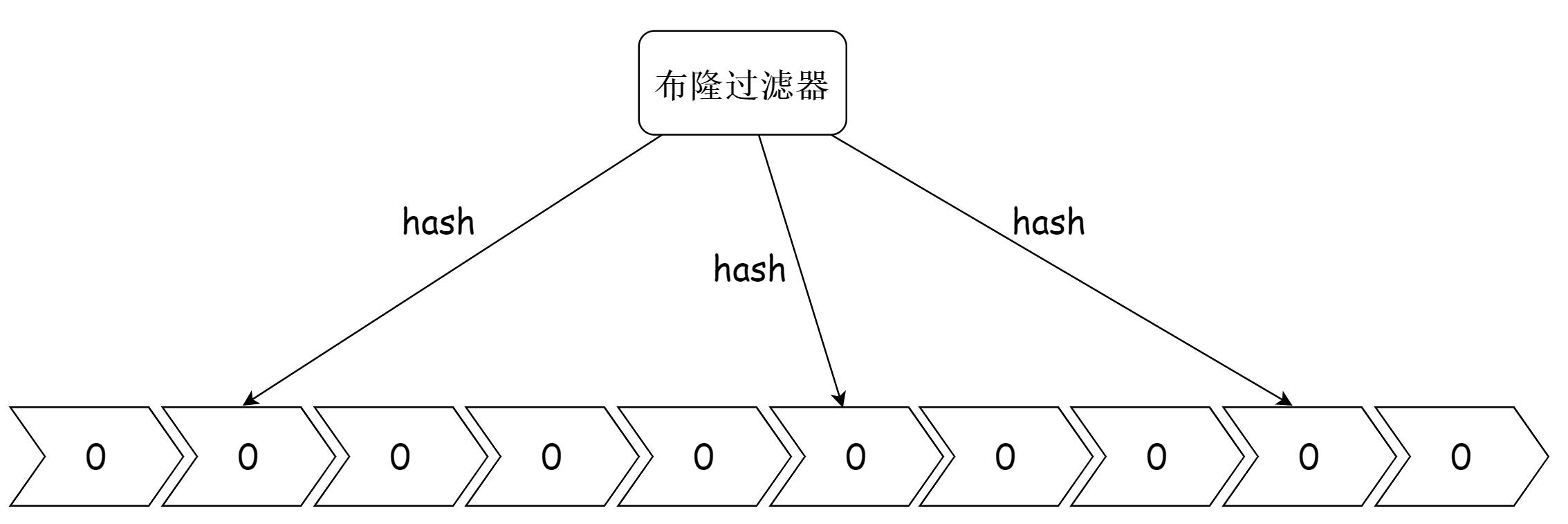
当要插入一个元素时,将其输入 K 个哈希函数,产生 K 个哈希值,同时以这些哈希值作为位数组的下标,将这些下标对应的比特值设置为 1。
当要查询一个元素时,同样是将其输入 K 个哈希函数,产生 K 个哈希值,然后检查这些哈希值中对应的比特值。如果有任意一个比特值为 0,则表明该元素一定不存在,如果所有比特值都是 1,则表明该元素可能存在,为什么不是一定存在呢?因为一个比特值为 1 有可能会受到其他元素的影响。所以 布隆过滤器是用于检测一个元素是否一定不存在或者有可能存在。
假如有一个布隆过滤器长度为 10,有 3 个哈希函数。这时将“布”插入到布隆过滤器中,经过三个哈希函数得到的哈希值为 3、6、9,则如下: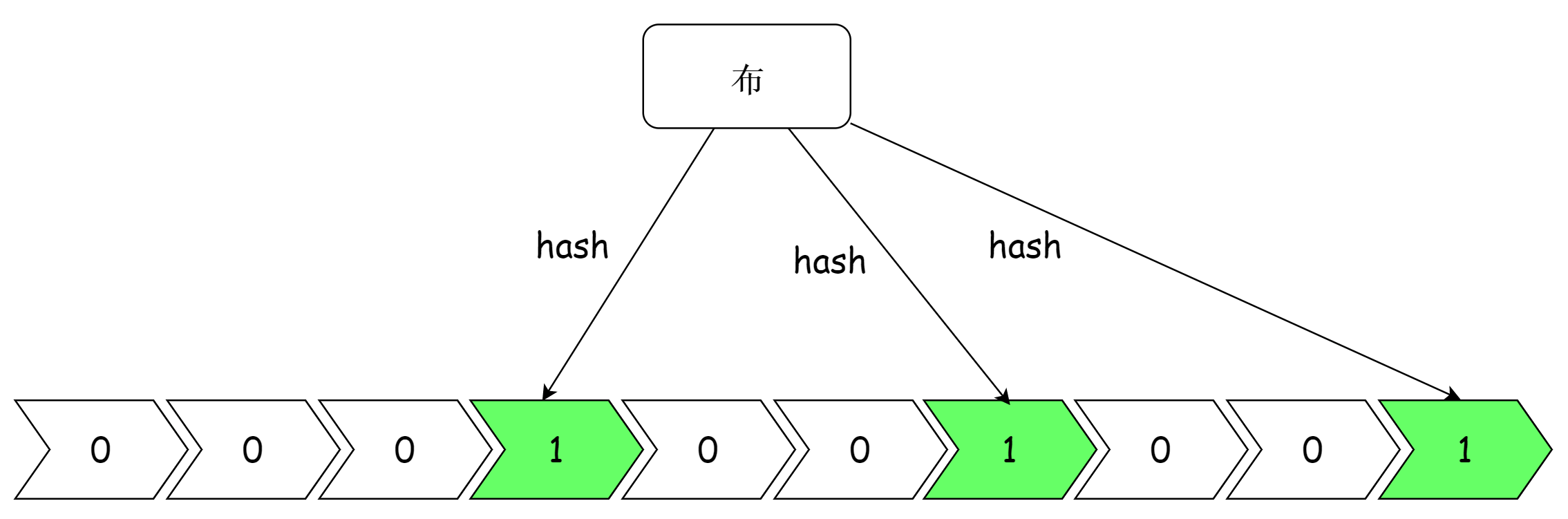
再存一个值:“隆”,假设得到的哈希值为 1 6 8,如下: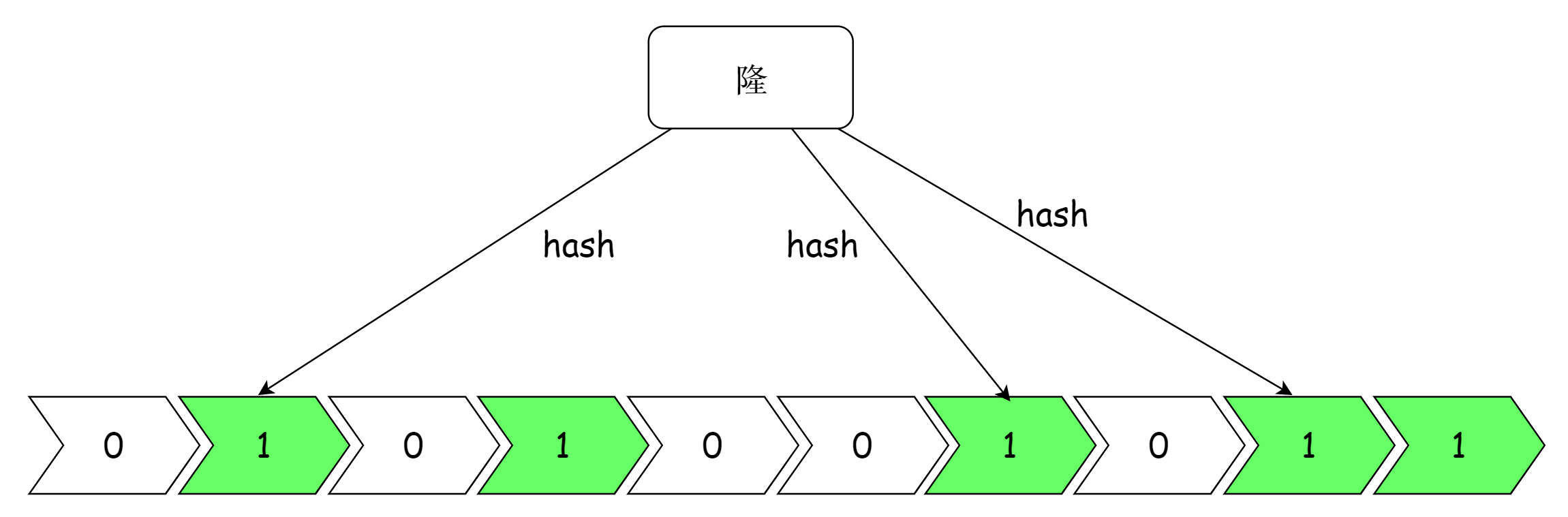
再查下 “Redis”,假设返回的哈希值为 1 5 7,得到的比特值为 1 0 0 ,所以可以很确切地说“Redis“这个值一定不存在,如果查询 “Java” 得到的哈希值为 1 6 9,比特值为 1 1 1,那么是否可以说一定存在呢?答案是不可以,只能说 “Java” 这个值有可能存在。因为随着数据的增多,越来越多位置的比特值被设置为 1,有可能存在某个值从来没有被存储,但是哈希函数返回的位值都为 1 。
优缺点
布隆过滤器的优点显而易见:
- 不需要存储数据,只用比特表示,因此在空间占用率上有巨大的优势
- 检索效率搞,插入和查询的时间复杂度都为 O(K)(K 表示哈希函数的个数)
- 哈希函数之间相互独立,可以在硬件指令层次并行计算,因此效率较高。
缺点:
- 存在不确定的因素,无法判断一个元素是否一定存在,所以不适合要求 100% 准确率的场景
-
布隆过滤器的实例(或实现)
引入Guavajar包即可使用,其中pom依赖如下
<dependency><groupId>com.google.guava</groupId><artifactId>guava</artifactId><version>25.1-jre</version></dependency>
使用示例
public static void main(String... args){/*** 创建一个插入对象为一亿,误报率为0.01%的布隆过滤器*/BloomFilter<CharSequence> bloomFilter = BloomFilter.create(Funnels.stringFunnel(Charset.forName("utf-8")), 100000000, 0.0001);bloomFilter.put("死");bloomFilter.put("磕");bloomFilter.put("Redis");System.out.println(bloomFilter.mightContain("Redis"));System.out.println(bloomFilter.mightContain("Java"));}
Redis中的布隆过滤器(只能使用在可写入的主节点,不能使用在只读的从节点)
Redis 官方提供的布隆过滤器到了 Redis 4.0 提供了插件功能之后才正式登场。布隆过滤器作为一个插件加载到 Redis Server 中,给 Redis 提供了强大的布隆去重功能。
先安装wget https://github.com/RedisBloom/RedisBloom/archive/v2.2.1.tar.gztar -zxvf v2.2.1.tar.gzcd RedisBloom-2.2.1make
执行完成之后,在 RedisBloom-2.2.1 目录结构中会多一个
rebloom.so的文件。然后需要在 Redis 配置文件中加入该模块即可。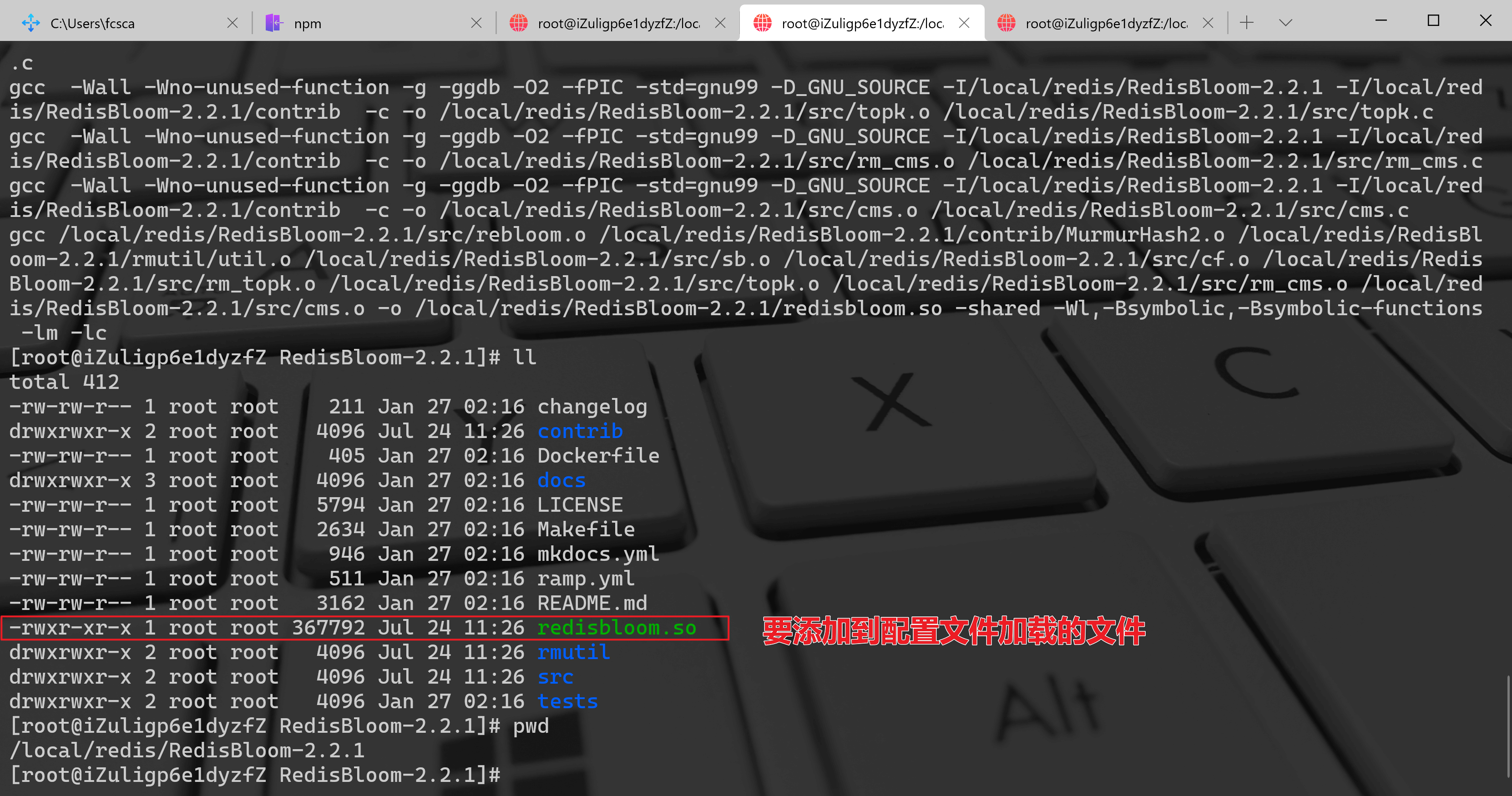
################################## MODULES ###################################### Load modules at startup. If the server is not able to load modules# it will abort. It is possible to use multiple loadmodule directives.## loadmodule /path/to/my_module.so# loadmodule /path/to/other_module.soloadmodule /local/redis/RedisBloom-2.2.1/redisbloom.so
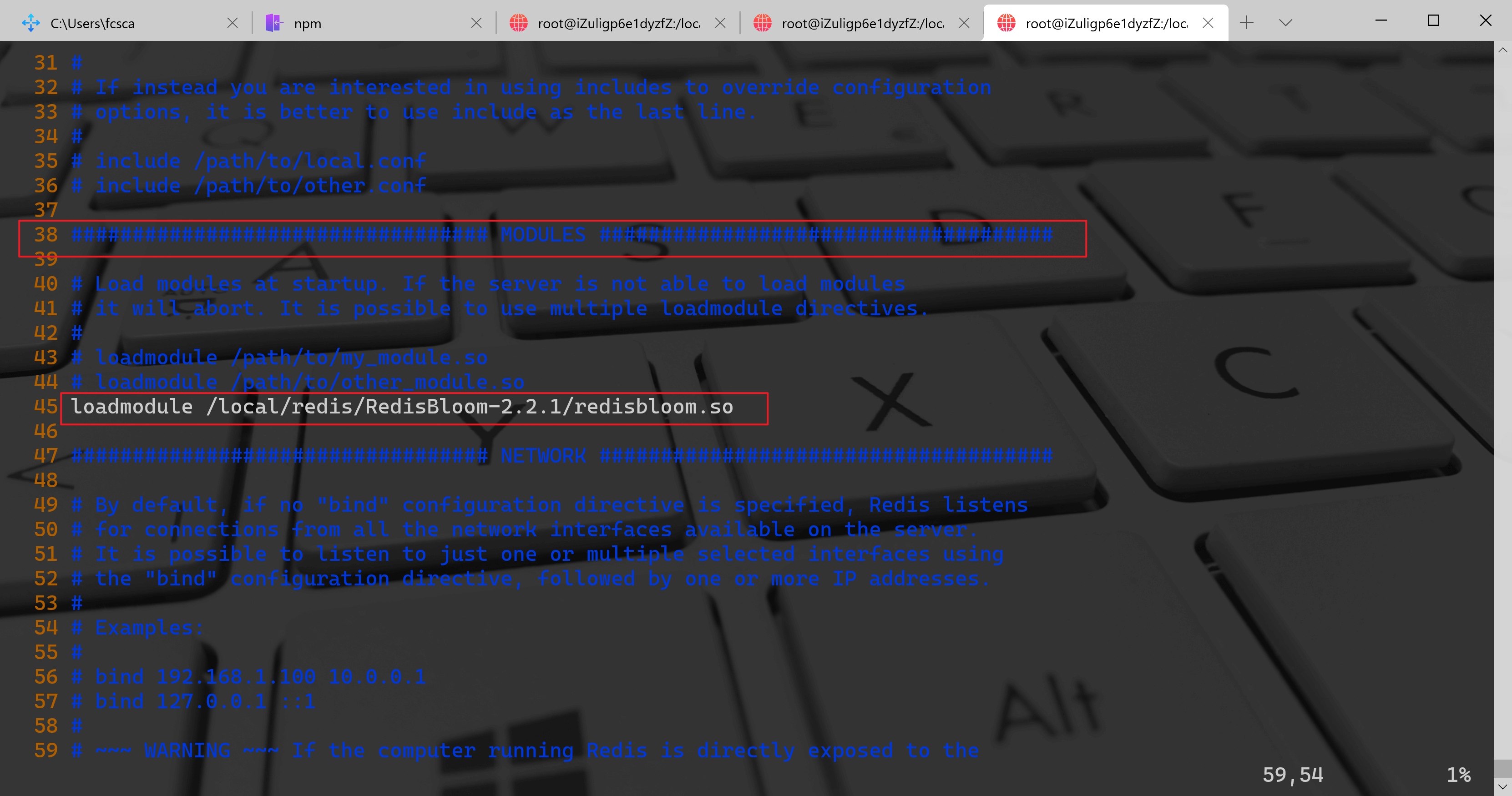
然后重启 Redis 即可测试。
Redis 布隆过滤器主要就两个命令: bf.add 添加元素到布隆过滤器中:
bf.add key value1。- bf.exists 判断某个元素是否在过滤器中:
bf.exists key value1。
上面说过布隆过滤器存在误判的情况,在 Redis 中有两个值决定布隆过滤器的准确率:
- error_rate :允许布隆过滤器的错误率,这个值越低过滤器的位数组的大小越大,占用空间也就越大。
- initial_size :布隆过滤器可以储存的元素个数,当实际存储的元素个数超过这个值之后,过滤器的准确率会下降。
redis 中有一个命令可以来设置这两个值:bf.reserve key 0.01100
三个参数的含义:
第一个值是过滤器的名字。
第二个值为 errorrate 的值。
第三个值为 initialsize 的值
下面简单演示下:
在缓存的应用中,布隆过滤器也是解决缓存穿透的解决方案。

若有收获,就点个赞吧
0 人点赞
