MySQL
mysql中执行更新操作时,必然涉及到读、写内存、写磁盘的操作流程。mysql是通过什么样的操作去完成更新流程的优化?
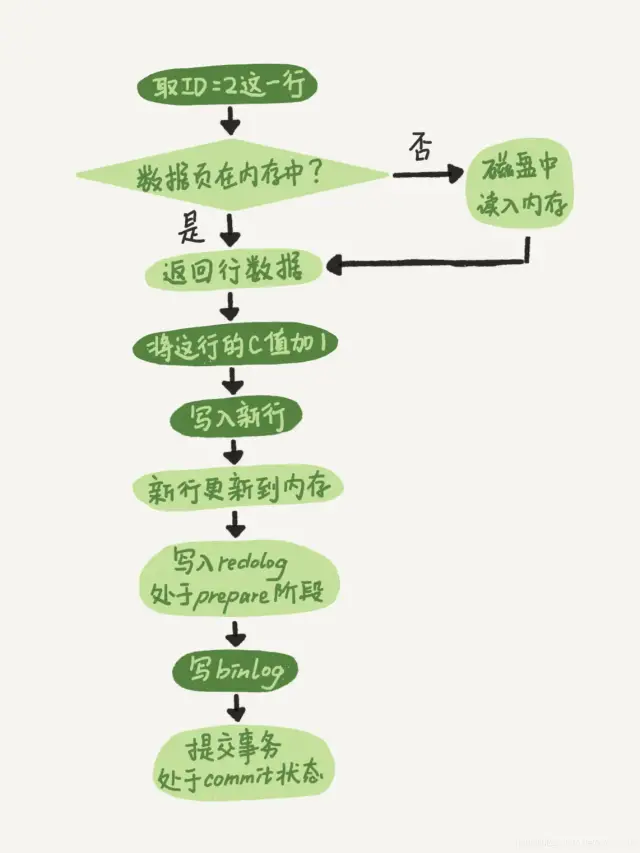
1、update语句执行流程
update T set c = c+1 where id = 2;
- 执行器先调用存储引擎的接口获取“id=2”的数据行。如果这一行所在的数据页在内存中,则存储引擎直接返回给执行器;否则需要存储引擎先去磁盘中获取数据,读取到内存中,然后再返回。
- 执行器拿到存储引擎返回的这行数据,对其进行更新操作,将c的值加+1,得到新的数据,在调用存储引擎接口,写入这行数据。
- 存储引擎收到执行器写入的这行数据的新结果,先将这条更新记录保存在内存(Buffer Pool)中,并将这条更新记录写入redo log Buffer,更新redo log的状态为prepare,随后向执行器返回结果。
- 执行器知道存储引擎已经将这条更新记录成功写入redo log Buffer(内存)后。
- 当事务提交时,redo log 调用fsync写入磁盘。
- 当事务提交时,binlog调用fsync写入磁盘。
- 在执行器写入binlog成功后,存储引擎将redo log的状态更新为commit,此时才算事务正在提交成功;
2、redo log详解
2.1 为什么要引入redo log
为了减少与磁盘的IO交互,在对数据库增改删操作时,实际主要都是针对内存里的Buffer Pool中的数据进行的。
最详细的MySQL事务特性及原理讲解!(一)
理解Mysql中的Buffer pool
InnoDB作为mysql的存储引擎,数据是存放在磁盘中的,但是每次读写数据需要磁盘IO,效率就很低。为此,InnoDB提供了缓存(Buffer Pool),Buffer Pool中包含了磁盘中部分数据页的映射,作为访问数据库的缓冲: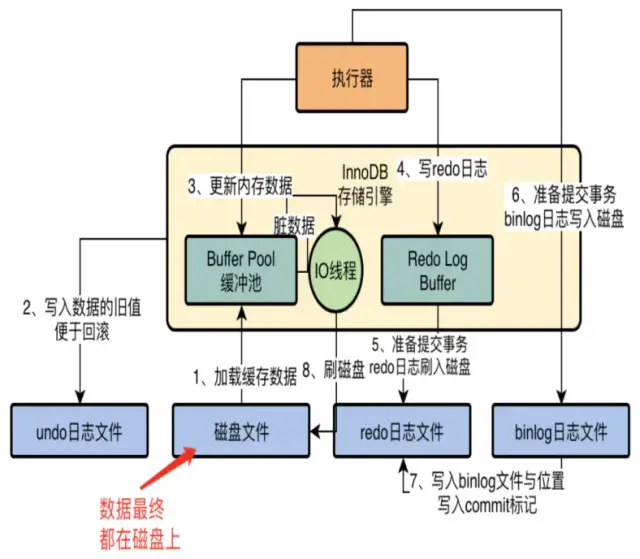
- 读取数据时,首先从Buffer Pool中读取,如果Buffer Pool中没有,则加载磁盘中的数据到Buffer Pool中;
- 写入数据的时候,会首先写入Buffer Pool,Buffer Pool中修改的数据会定期刷新到磁盘(这一过程被称为刷脏)。
Buffer Pool的使用大大提高了读写数据的效率,但是也带来了新的问题:如果mysql宕机,如何保证数据不丢失?
2.2 redo log如何保证数据不丢失?
在修改数据时,除了修改Buffer Pool中的数据,还会在redo log Buffer(内存)记录这次操作。当事务提交时,会调用fsync对redo log(磁盘)进行刷盘。重启时可以读取磁盘上的redo log中的数据,对数据库进行恢复。redo log采用的是WAL技术(Write-ahead logging,预写式日志)。所有修改先写入日志(redo log),在更新Buffer Pool,保证数据不会因为mysql宕机而丢失。
2.3 redo log也是写磁盘,比BufferPool写入磁盘优点是什么?
redo log也需要在事务提交时将日志写入磁盘,但是它要比Buffer Pool中修改的数据写入磁盘(即刷脏)要快:
- 刷脏是随机IO,每次修改数据位置都是随机,写redo log是追加操作,属于顺序IO;
刷脏是以数据页(Page)为单位,Mysql默认页大小为16KB,一个Page上一个小修改都要整页写入,而redo log中是精简的日志数据,无效IO大大减少。
2.4 Redo 的整体流程
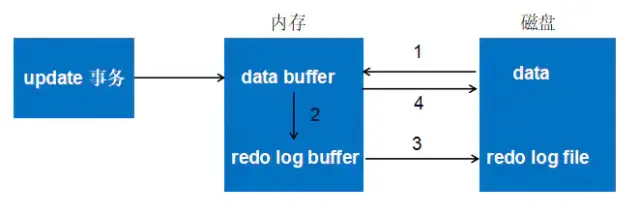
先将原始数据从磁盘中读入到内存(Buffer Pool)中,修改内存拷贝;
- 生成redo log并写入redo log buffer(内存),记录的是数据被修改后的值;
- 当事务commit时,将redo log中的内容刷新到redo log file(磁盘),对redo log file采用追加写的方式;
-
2.5 redo log的两阶段提交
redo log 采用是两阶段提交的方式最终commit,那么为什么采用两阶段提交的方式?
看上面的流程图,mysql在写redo log两阶段变更时会写bin log日志表。而记录binlog日志的目的:既可以用于数据恢复、binlog数据监听、主从库同步。那么redo log表采用两阶段提交的目的在于:保证binlog 和redo log文件的一致性。
若不采用两阶段提交: 先写redo log在写binlog
如果引擎写完redo log后,bin log还没有写。异常重启。主库使用redo log 日志将数据恢复。但binlog没有记录这个语句,那么从库根据binlog同步数据时依旧没有这条语句,造成了主从库的数据不一致性;
- 先写binlog在写redo log
写完binlog后异常重启,因为redo log没有些,主库恢复后没有这条事务。但是由于binlog中有这条记录,从库根据binlog日志同步数据时,也会有这条事务。依旧导致主从不一致。
3、redo log 和binlog
3.1 redo log和binlog的区别
- redo log是InnoDB存储引擎层面,而binlog是mysql server层面,所有存储引擎均可使用;
- redo log是InnoDB为了解决crash safe(系统崩溃后恢复),而binlog是定期存档,重要的作用是支持主从同步。
- redo log是物理日志,记录的是“在某个数据上做了什么修改”(修改的结果是什么),binlog是逻辑日志,记录的是这个语句的原始逻辑(操作语句是什么)。
- redo log是循环写,空间满时就会发生写覆盖;binlog是追加写,不会覆盖。
注:虽然redo log是物理日志,但是它并不是直接存储修改后的行数据本身(如果这样实现就更直接将数据写入磁盘没有区别了,也提高不了写数据效率的目的),实际上redo log中存储的内容格式:“xx表空间中yy数据页zz偏移量做了ww更新”。即只记录更新语句的简要信息,减少了写磁盘的数据量。
3.2 为什么redo log具有crash-safe能力,而binlog没有
redo log:是一个固定大小,“循环写”的日志文件,记录物理日志;
binlog:是一个无限大小,“追加写”的日志文件,记录的是逻辑日志;
redo log只会记录未刷盘的日志,已经刷入磁盘的数据都会从redo log这个固定大小的日志文件里删除;binlog是追加日志,保存的是全量的日志。
当数据库crash崩溃后,想要恢复:未刷盘但已经写入redo log和binlog的数据到内存时,binlog是无法实现的。虽然binlog拥有全量日志,但是没有标志让InnoDB判断哪些数据已经刷盘。
但redo log不一样,只要写入磁盘的数据,都会从redo log中抹除,数据库重启后,直接将redo log的数据恢复到内存。
4、写磁盘flush操作
InnoDB执行update更新操作是采用的“先写日志,在写磁盘”的策略。更新后的行数据本身先缓存在内存中,直将缩略的关键信息写入到redo log磁盘。但缓存在内存中的数据最终总是要写入到磁盘,这个操作叫做flush。
当内存数据页和磁盘数据页不一致的时候,称这个内存页为“脏页”。内存数据写入到磁盘后,内存和磁盘上的数据页的内容就一致了,称为“干净页”。flush操作也就是“刷脏页”。
4.1 触发数据库执行flush操作的四种情况:
4.1.1 当InnoDB的redo log写满时
此时系统会停止所有的更新操作,将环形的redo log中的“读指针”向前推,对应的所有脏页此时都会flush到磁盘上。
4.1.2 当系统的内存不足时
当需要新的内存页,但是内存不够用时,就需要淘汰一些内存页(一般是空出最长时间没有被访问的内存页),此时如果淘汰的是脏页,就需要先将脏页写到磁盘。
4.1.3 当mysql认为系统“空闲”时
mysql会在运行期间“见缝插针”的找机会刷一点脏页,以避免当读写业务繁忙时过快的占满系统内存或redo log空间。
4.1.4 当mysql正常关闭时
此时mysql会把内存中所有脏页都flush到磁盘上,这样mysql下次启动的时候就直接从磁盘上读取数据,启动速度更快(相比即从磁盘读取数据,又从磁盘读取redo log日志)。

若有收获,就点个赞吧
0 人点赞
