1、Redis 概览
Redis 和 memcache 的区别,Redis 支持的数据类型应用场景
- redis 支持的数据结构更丰富(string,hash,list,set,zset)。memcache 只支持 key-value 的存储;
redis 原生支持集群,memcache 没有原生的集群模式。
2、Redis 单线程模型
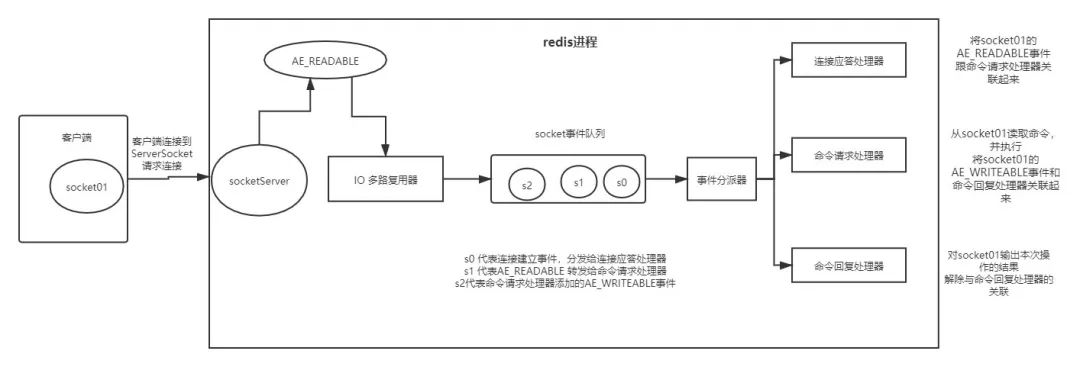
redis 单线程处理请求流程
redis 采用 IO 多路复用机制来处理请求,采用 reactor IO 模型, 处理流程如下:
首先接收到客户端的 socket 请求,多路复用器将 socket 转给连接应答处理器;
- 连接应答处理器将 AE_READABLE 事件与命令请求处理器关联(这里是把 socket 事件放入一个队列);
- 命令请求处理器从 socket 中读到指令,再内存中执行,并将 AE_WRITEABLE 事件与命令回复处理器关联;
- 命令回复处理器将结果返回给 socket,并解除关联。
redis 单线程效率高的原因
- 非阻塞 IO 复用(上图流程), I/O 多路复用分派事件,事件处理器处理事件(这个可以理解为注册的一段函数,定义了事件发生的时候应该执行的动作), 这里分派事件和处理事件其实都是同一个线程;
- 纯内存操作效率高;
- 单线程反而避免了多线程切换。
3、Redis 过期策略
对 key 设置有效期,redis 的删除策略:定期删除+惰性删除。
- 定期删除指的是 redis 默认每 100ms 就随机抽取一些设置了过期事件的 key ,检查是否过期,如果过期就删除。如果 redis 设置了 10 万个 key 都设置了过期时间,每隔几百毫秒就要检查 10 万个 key 那 CPU 负载就很高了,所以 redis 并不会每隔 100ms 就检查所有的 key,而是随机抽取一些 key 来检查。
- 但这样会导致有些 key 过期了并没有被删除,所以采取了惰性删除。意思是在获取某个 key 的时候发现过期了,如果 key 过期了就删除掉不会返回。
最大内存淘汰(maxmemory-policy)
如果 redis 内存占用太多,就会进行内存淘汰。有如下策略:
- noeviction:如果内存不足以写入数据, 新写入操作直接报错;
- allkeys-lru:内存不足以写入数据,移除最近最少使用的 key(最常用的策略);
- allkeys-random:内存不足随机移除几个 key;
- volatile-lru:在设置了过期时间的 key 中,移除最近最少使用;
volatile-random:设置了过期的时间的 key 中,随机移除几个。
4、Redis 主从模式保证高并发和高可用(哨兵模式)
读写分离
单机的 Redis 的 QPS 大概就在上万到几万不等,无法承受更高的并发。
读写分离保证高并发(10W+ QPS):对于缓存来说一般都是支撑高并发读,写请求都是比较少的。采用读写分离的架构(一主多从),master 负责接收写请求,数据同步到 slave 上提供读服务,如果遇到瓶颈只需要增加 slave 机器就可以水平扩容主从复制机制
redis replication 机制:
redis 采取异步复制到 slave 节点;
- slave 节点做复制操作的时候是不会 block 自己的,它会使用旧的数据集来提供服务,复制。完成后,删除旧的数据集,加载新的数据集,这个时候会暂停服务(时间很短暂);
- 如果采用了主从架构,master 需要开启持久化。如果 master 没有开启持久化(rdb 和 aof 都关闭了)。master 宕机重启后数据是空的,然后经过复制就把所有 slave 的数据也弄丢了。
即使采用高可用的的哨兵机制,可能 sentinal 还没有检测到 master failure,master 就自动重启了,还是会导致 slave 清空故障。
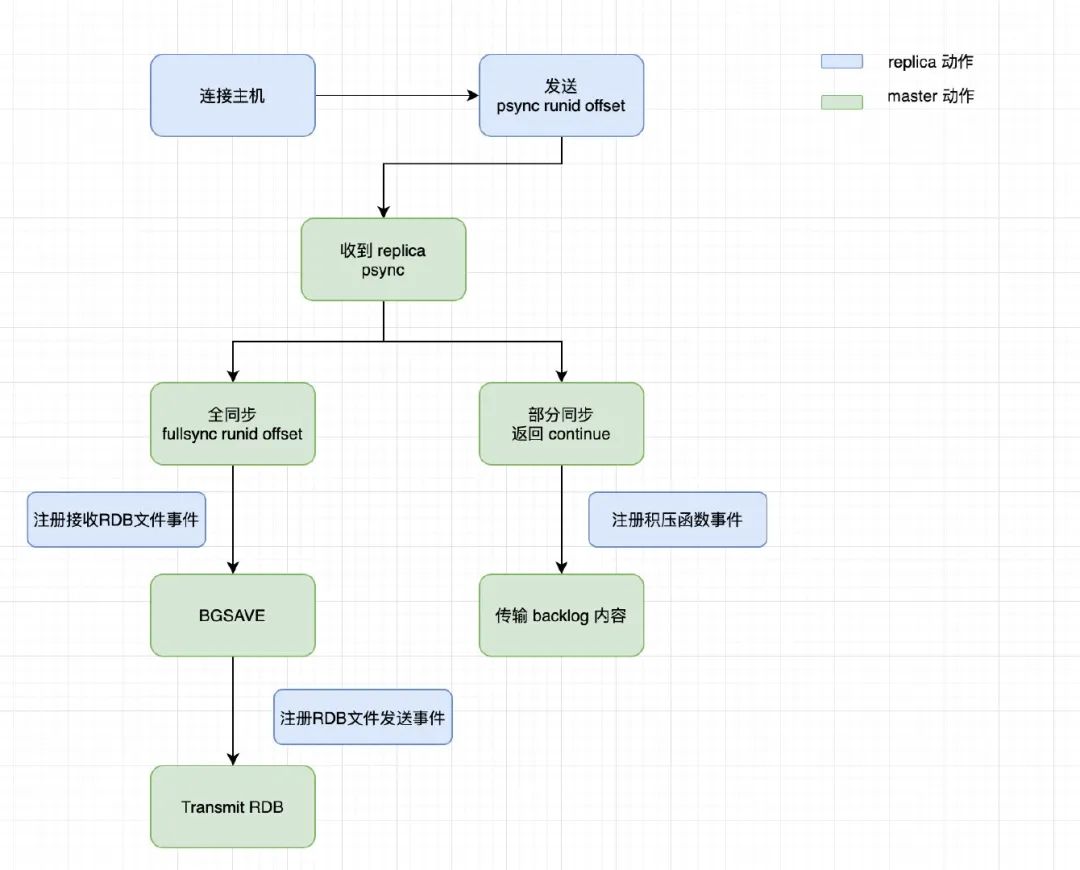
主从同步流程
- 当 slave 启动时会发送一个 psync 命令给 master;
- 如果是重新连接 master,则 master node 会复制给 slave 缺少的那部分数据;
- 如果是 slave 第一次连接 master,则会触发一次全量复制(full resynchronization)。开始 full resynchronization 的时候,master 会生成一份 rdb 快照,同时将客户端命令缓存在内存,rdb 生成完后,就发送给 slave,slave 先写入磁盘在加载到内存。然后 master 将缓存的命令发送给 slave。
哨兵(sentinal)模式介绍
哨兵是 redis 集群架构的一个重要组件,主要提供如下功能:
- 集群监控:负责监控 master 和 slave 是否正常工作;
- 消息通知:如果某个 redis 实例有故障, 哨兵负责发消息通知管理员;
- 故障转移:如果 master node 发生故障,会自动切换到 slave;
配置中心:如果故障转移发生了,通知客户端新的 master 地址。
哨兵的核心知识:
哨兵至少三个,保证自己的高可用;
- 哨兵+主从的部署架构是用来保证 redis 集群高可用的,并非保证数据不丢失;
- 哨兵(Sentinel)需要通过不断的测试和观察才能保证高可用。
为什么哨兵只有两个节点无法正常工作
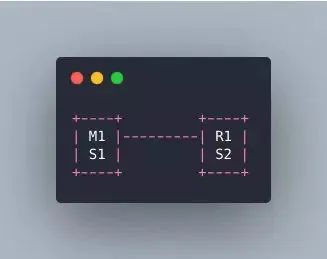
假设哨兵集群只部署了 2 个哨兵实例,quorum=1。
master 宕机的时候,s1 和 s2 只要有一个哨兵认为 master 宕机 j 就可以进行切换,并且会从 s1 和 s2 中选取一个来进行故障转移。这个时候是需要满足 majority,也就是大多数哨兵是运行的,2 个哨兵的 majority 是 2,如果 2 个哨兵都运行着就允许执行故障转移。如果 M1 所在的机器宕机了,那么 s1 哨兵也就挂了,只剩 s2 一个,没有 majorityl 来允许执行故障转移,虽然集群还有一台机器 R1,但是故障转移也不会执行。
如果是经典的三哨兵集群,如下: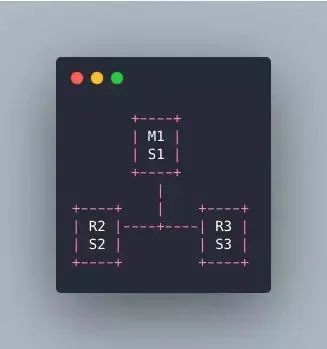
此时 majority 也是 2,就算 M1 所在的机器宕机了,哨兵还是剩下两个 s2 和 s3,它们满足 majority 就可以允许故障转移执行。哨兵核心底层原理
- sdown 和 odown 两种失败状态;
- sdown 是主观宕机,就是一个哨兵觉得 master 宕机了,达成条件是如果一个哨兵 ping master 超过了 is-master-down-after-milliseconds 指定的毫秒数后就认为主观宕机;
- odown 是客观宕机,如果一个哨兵在指定时间内收到了 majority(大多数) 数量的哨兵也认为那个 master 宕机了,就是客观宕机。
- 哨兵之间的互相发现:哨兵是通过 redis 的 pub/sub 实现的。
5、Redis 数据的恢复(Redis 的持久化)
RDB
RDB 原理
RDB(Redis DataBase)是将某一个时刻的内存快照(Snapshot),以二进制的方式写入磁盘的过程。
RDB 有两种方式 save 和 bgsave:
- save:执行就会触发 Redis 的持久化,但同时也是使 Redis 处于阻塞状态,直到 RDB 持久化完成,才会响应其他客户端发来的命令;
bgsave:bgsave 会 fork() 一个子进程来执行持久化,整个过程中只有在 fork() 子进程时有短暂的阻塞,当子进程被创建之后,Redis 的主进程就可以响应其他客户端的请求了。
RDB 配置
除了使用 save 和 bgsave 命令触发之外, RDB 支持自动触发。
自动触发策略可配置 Redis 在指定的时间内,数据发生了多少次变化时,会自动执行 bgsave 命令。在 redis 配置文件中配置:
在时间 m 秒内,如果 Redis 数据至少发生了 n 次变化,那么就自动执行BGSAVE命令。save m n
RDB 优缺点
RDB 的优点:
RDB 会定时生成多个数据文件,每个数据文件都代表了某个时刻的 redis 全量数据,适合做冷备,可以将这个文件上传到一个远程的安全存储中,以预定好的策略来定期备份 redis 中的数据;
- RDB 对 redis 对外提供读写服务的影响非常小,redis 是通过 fork 主进程的一个子进程操作磁盘 IO 来进行持久化的;
相对于 AOF,直接基于 RDB 来恢复 reids 数据更快。
RDB 的缺点:
如果使用 RDB 来恢复数据,会丢失一部分数据,因为 RDB 是定时生成的快照文件;
- RDB 每次来 fork 出子进程的时候,如果数据文件特别大,可能会影响对外提供服务,暂停数秒(主进程需要拷贝自己的内存表给子进程, 实例很大的时候这个拷贝过程会很长)。latest_fork_usec 代表 fork 导致的延时;Redis 上执行 INFO 命令查看 latest_fork_usec;当 RDB 比较大的时候, 应该在 slave 节点执行备份, 并在低峰期执行。
AOF
AOF 原理
redis 对每条写入命令进行日志记录,以 append-only 的方式写入一个日志文件,redis 重启的时候通过重放日志文件来恢复数据集。(由于运行久了 AOF 文件会越来越大,redis 提供一种 rewrite 机制,基于当前内存中的数据集,来构建一个更小的 AOF 文件,将旧的庞大的 AOF 文件删除)。rewrite 即把日志文件压缩, 通过 bgrewriteaof 触发重写。AOF rewrite 后台执行的方式和 RDB 有类似的地方,fork 一个子进程,主进程仍进行服务,子进程执行 AOF 持久化,数据被 dump 到磁盘上。与 RDB 不同的是,后台子进程持久化过程中,主进程会记录期间的所有数据变更(主进程还在服务),并存储在 server.aof_rewrite_buf_blocks 中;后台子进程结束后,Redis 更新缓存追加到 AOF 文件中,是 RDB 持久化所不具备的。
AOF 的工作流程如下:
- Redis 执行写命令后,把这个命令写入到 AOF 文件内存中(write 系统调用);
- Redis 根据配置的 AOF 刷盘策略,把 AOF 内存数据刷到磁盘上(fsync 系统调用);
根据 rewrite 相关的配置触发 rewrite 流程。
AOF 配置
appendonly:是否启用 AOF(yes | no);
- appendfsync:刷盘的机制:
- always:主线程每次执行写操作后立即刷盘,此方案会占用比较大的磁盘 IO 资源,但数据安全性最高;
- everysec:主线程每次写操作只写内存就返回,然后由后台线程每隔 1 秒执行一次刷盘操作(触发 fsync 系统调用),此方案对性能影响相对较小,但当 Redis 宕机时会丢失 1 秒的数据;
- no:主线程每次写操作只写内存就返回,内存数据什么时候刷到磁盘,交由操作系统决定,此方案对性能影响最小,但数据安全性也最低,Redis 宕机时丢失的数据取决于操作系统刷盘时机。
- auto-aof-rewrite-percentage:当 aof 文件相较于上一版本的 aof 文件大小的百分比达到多少时触发 AOF 重写。举个例子,auto-aof-rewrite-percentage 选项配置为 100,上一版本的 aof 文件大小为 100M,那么当我们的 aof 文件达到 200M 的时候,触发 AOF 重写;
- auto-aof-rewite-min-size:最小能容忍 aof 文件大小,超过这个大小必须进行 AOF 重写;
- no-appendfsync-on-rewrite:设置为 yes 表示 rewrite 期间对新写操作不 fsync,暂时存在内存中,等 rewrite 完成后再写入,默认为 no。
AOF 优缺点
AOF 的优点:
- 可以更好的保证数据不丢失,一般 AOF 每隔 1s 通过一个后台线程来执行 fsync(强制刷新磁盘页缓存),最多丢失 1s 的数据;
- AOF 以 append-only 的方式写入(顺序追加),没有磁盘寻址开销,性能很高;
- AOF 即使文件很大, 触发后台 rewrite 的操作的时候一般也不会影响客户端的读写,(rewrite 的时候会对其中指令进行压缩,创建出一份恢复需要的最小日志出来)。
在创建新的日志文件的时候,老的文件还是照常写入,当新的文件创建完成后再交换新老日志。但是还是有可能会影响到主线程的写入, 如: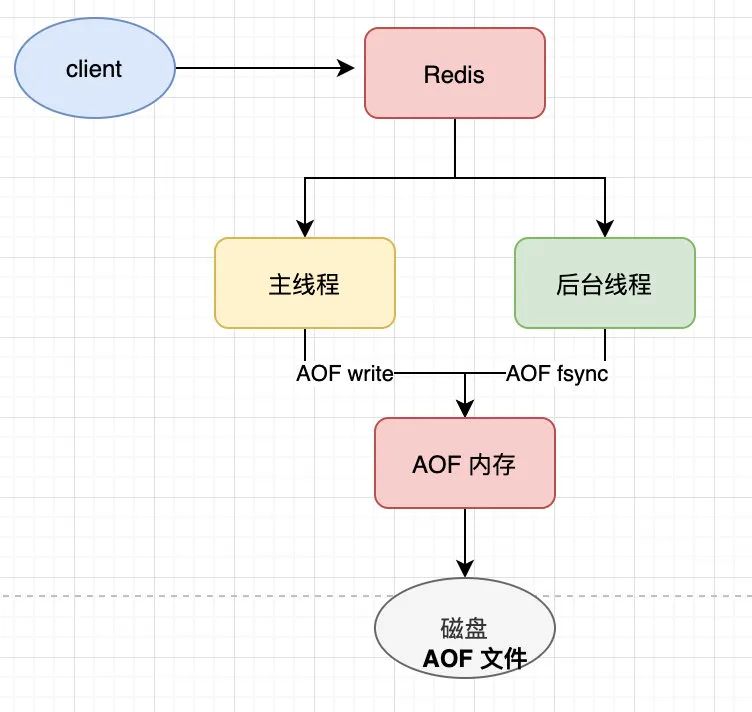
当磁盘的 IO 负载很高,那这个后台线程在执行 AOF fsync 刷盘操作(fsync 系统调用)时就会被阻塞住, ,紧接着,主线程又需要把数据写到文件内存中(write 系统调用),但此时的后台子线程由于磁盘负载过高,导致 fsync 发生阻塞,迟迟不能返回,那主线程在执行 write 系统调用时,也会被阻塞住,直到后台线程 fsync 执行完成后,主线程执行 write 才能成功返回。这时候主线程就无法响应客户端的请求, 可能会导致客户端请求 redis 超时。
AOF 日志文件通过非常可读的方式进行记录,这个特性适合做灾难性的误操作的紧急恢复,比如不小心使用 flushall 清空了所有数据,只要 rewrite 没有发生,就可以立即拷贝 AOF,将最后一条 flushall 命令删除,再回放 AOF 恢复数据。
AOF 的缺点:
同一份数据,因为 AOF 记录的命令会比 RDB 快照文件更大;
AOF 开启后,支持写的 QPS 会比 RDB 支持写的 QPS 要低,毕竟 AOF 有写磁盘的操作。
总结
总结 AOF 和 RDB 该如何选择:两者综合使用,将 AOF 配置成每秒 fsync 一次。RDB 作为冷备,AOF 用来保证数据不丢失的恢复第一选择,当 AOF 文件损坏或不可用的时候还可以使用 RDB 来快速恢复。
6、Redis 集群模式(redis cluster)
在主从部署模式上,虽然实现了一定程度的高并发,并保证了高可用,但是有如下限制:
master 数据和 slave 数据一模一样,master 的数据量就是集群的限制瓶颈;
- redis 集群的写能力也受到了 master 节点的单机限制。
在高版本的 Redis 已经原生支持集群(cluster)模式,可以多 master 多 slave 部署,横向扩展 Redis 集群的能力。Redis Cluster 支持 N 个 master node ,每个 master node 可以挂载多个 slave node。
redis cluster 介绍
- 自动将数据切片,每个 master 上放一部分数据;
- 提供内置的高可用支持,部分 master 不可用时还是能够工作;
redis cluster 模式下,每个 redis 要开放两个端口:6379 和 10000+以后的端口(如 16379)。16379 是用来节点之间通信的,使用的是 cluster bus 集群总线。cluster bus 用来做故障检测,配置更新,故障转移授权。
redis cluster 负载均衡
redis cluster 采用 一致性 hash+虚拟节点 来负载均衡。redis cluster 有固定的 16384 个 slot (2^14),对每个 key 做 CRC16 值计算,然后对 16384 mod。可以获取每个 key 的 slot。redis cluster 每个 master 都会持有部分 slot,比如 三个 master 那么 每个 master 就会持有 5000 多个 slot。hash slot 让 node 的添加和删除变得很简单,增加一个 master,就将其他 master 的 slot 移动部分过去,减少一个就分给其他 master,这样让集群扩容的成本变得很低。
cluster 基础通信原理(gossip 协议)
与集中式不同(如使用 zookeeper 进行分布式协调注册),redis cluster 使用的是 gossip 协议进行通信。并不是将集群元数据存储在某个节点上,而是不断的互相通信,保持整个集群的元数据是完整的。gossip 协议所有节点都持有一份元数据,不同节点的元数据发生了变更,就不断的将元数据发送给其他节点,让其他节点也进行元数据的变更。
集中式的好处:元数据的读取和更新时效性很好,一旦元数据变化就更新到集中式存储,缺点就是元数据都在一个地方,可能导致元数据的存储压力。
对于 gossip 来说:元数据的更新会有延时,会降低元数据的压力,缺点是操作是元数据更新可能会导致集群的操作有一些滞后。redis cluster 主备切换与高可用
判断节点宕机:如果有一个节点认为另外一个节点宕机,那就是 pfail,主观宕机。如果多个节点认为一个节点宕机,那就是 fail,客观宕机。跟哨兵的原理一样;
- 对宕机的 master,从其所有的 slave 中选取一个切换成 master node,再次之前会进行一次过滤,检查每个 slave 与 master 的断开时间,如果超过了 cluster-node-timeout * cluster-slave-validity-factor 就没有资格切换成 master;
- 从节点选取:每个从节点都会根据从 master 复制数据的 offset,来设置一个选举时间,offset 越大的从节点,选举时间越靠前,master node 开始给 slave 选举投票,如果大部分 master(n/2+1)都投给了某个 slave,那么选举通过(与 zk 有点像,选举时间类似于 epochid);
- 整个流程与哨兵类似,可以说 redis cluster 集成了哨兵的功能,更加的强大;
- Redis 集群部署相关问题 redis 机器的配置,多少台机器,能达到多少 qps?
- 机器标准:8 核+32G
- 集群:5 主+5 从(每个 master 都挂一个 slave)
- 效果:每台机器最高峰每秒大概 5W,5 台机器最多就是 25W,每个 master 都有一个从节点,任何一个节点挂了都有备份可切换成主节点进行故障转移
- 脑裂问题哨兵模式下:
- master 下 挂载了 3 个 slave,如果 master 由于网络抖动被哨兵认为宕机了,执行了故障转移,从 slave 里面选取了一个作为新的 master,这个时候老的 master 又恢复了,刚好又有 client 连的还是老的 master,就会产生脑裂,数据也会不一致,比如 incr 全局 id 也会重复。
- redis 对此的解决方案是:min-slaves-to-write 1 至少有一个 slave 连接 min-slaves-max-lag 10 slave 与 master 主从复制延迟时间如果连接到 master 的 slave 数小于最少 slave 的数量,并且主从复制延迟时间超过配置时间,master 就拒绝写入 12。client 连接 redis 多 tcp 连接的考量首先 redis server 虽然是单线程来处理请求, 但是他是多路复用的, 单 tcp 连接肯定是没有多 tcp 连接性能好, 多路复用一个 io 周期得到的就绪 io 事件越多, 处理的就越多。这也不是绝对的, 如果使用 pipeline 的方式传输, 单连接会比多连接性能好, 因为每一个 pipeline 的单次请求过多也会导致单周期到的命令太多, 性能下降多少个连接比较合适这个问题, redis cluser 控制在每个节点 100 个连接以内。

若有收获,就点个赞吧
0 人点赞
