1、子查询语法
SELECT select_listFROM table1WHERE expr operator(SELECT select_listFROM table1);
SELECT last_nameFROM employeesWHERE salary >(SELECT salaryFROM employeesWHERE last_name = 'Abel');
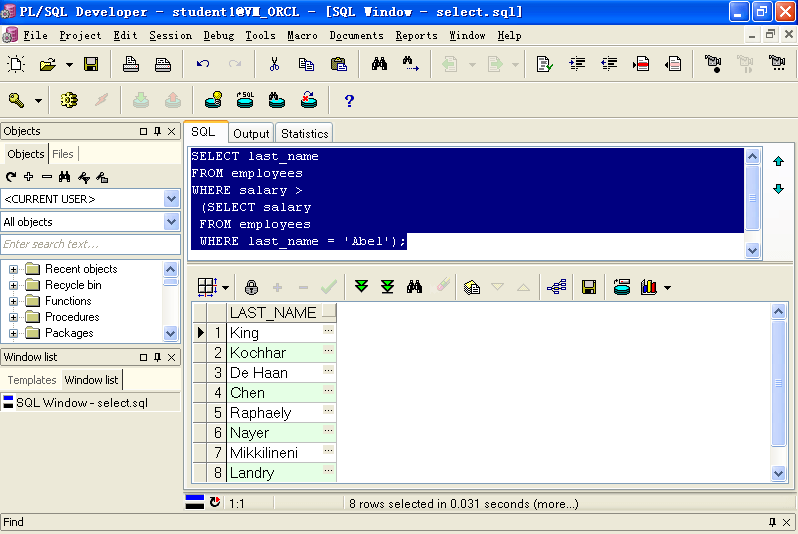
2、子查询注意点
单行比较必须对应单行子查询(返回单一结果值的查询); 比如= , >
多行比较必须对应多行子查询(返回一个数据集合的查询);比如 IN , > ANY, > ALL 等
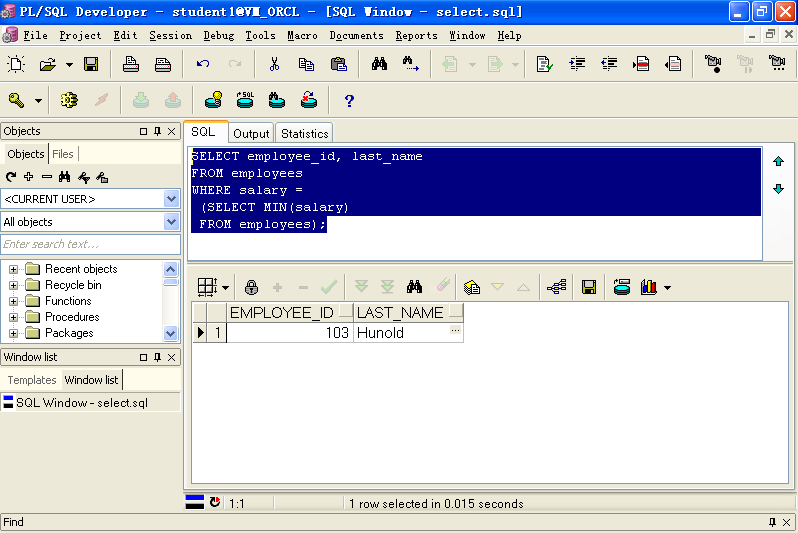
A.单行子查询
SELECT employee_id, last_nameFROM employeesWHERE salary =(SELECT MIN(salary)FROM employees);
B.多行子查询
SELECT employee_id, last_name, job_id, salaryFROM employeesWHERE salary < ANY(SELECT salaryFROM employeesWHERE job_id = 'IT_PROG')AND job_id <> 'IT_PROG';
3、子查询进阶
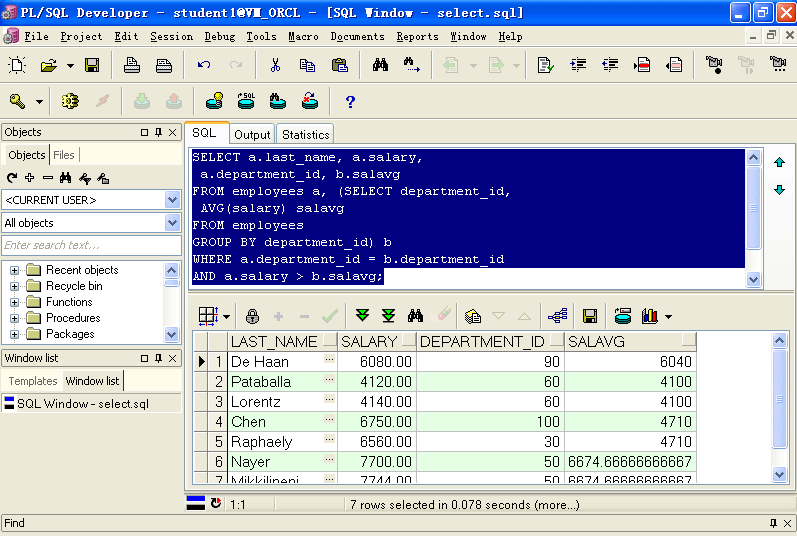
A.非相关子查询当作一张表来用
SELECT a.last_name, a.salary,a.department_id, b.salavgFROM employees a, (SELECT department_id,AVG(salary) salavgFROM employeesGROUP BY department_id) bWHERE a.department_id = b.department_idAND a.salary > b.salavg;
B.子查询中参考了外部主查询中的表
SELECT last_name, salary, department_idFROM employees outerWHERE salary > (SELECT AVG(salary)FROM employeesWHERE department_id =outer.department_id) ;
SELECT e.employee_id, last_name,e.job_idFROM employees eWHERE 2 <= (SELECT COUNT(*)FROM job_historyWHERE employee_id = e.employee_id);
C.使用Exists操作
SELECT employee_id, last_name, job_id, department_idFROM employees outerWHERE EXISTS ( SELECT 'X'FROM employeesWHERE manager_id =outer.employee_id);SELECT employee_id,last_name,job_id,department_idFROM employeesWHERE employee_id IN (SELECT manager_idFROM employeesWHERE manager_id IS NOT NULL);
D.使用Not Exists操作
SELECT department_id, department_nameFROM departments dWHERE NOT EXISTS (SELECT 'X'FROM employeesWHERE department_id= d.department_id);SELECT department_id, department_nameFROM departmentsWHERE department_id NOT IN (SELECT department_idFROM employees);
注意:Not In 里面只要有一个NULL ,就不成立了,这是很容易出错的地方; 正确的方法请在后 面的子查询中加上where department_id is not null;
E.在Update 语句中使用相关子查询
ALTER TABLE employeesADD(department_name VARCHAR2(14));UPDATE employees eSET department_name =(SELECT department_nameFROM departments dWHERE e.department_id = d.department_id);
F.在DELETE 语句中使用相关子查询
DELETE FROM job_history JHWHERE employee_id =(SELECT employee_idFROM employees EWHERE JH.employee_id = E.employee_idAND start_date =(SELECT MIN(start_date)FROM job_history JHWHERE JH.employee_id = E.employee_id)AND 5 > (SELECT COUNT(*)FROM job_history JHWHERE JH.employee_id = E.employee_idGROUP BY employee_idHAVING COUNT(*) >= 4));
I.使用WITH子句
WITHdept_costs AS (SELECT d.department_name, SUM(e.salary) AS dept_totalFROM employees e, departments dWHERE e.department_id = d.department_idGROUP BY d.department_name),avg_cost AS (SELECT SUM(dept_total)/COUNT(*) AS dept_avgFROM dept_costs)SELECT *FROM dept_costsWHERE dept_total >(SELECT dept_avgFROM avg_cost)ORDER BY department_name;
使用WITH好处:
1)如果在后面多次使用则可以简化SQL ;
2)适当提高性能;

若有收获,就点个赞吧
0 人点赞
