一、整体架构图
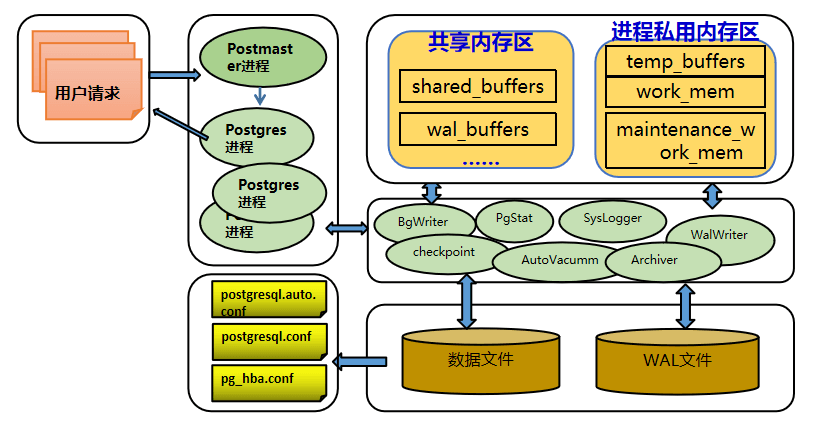
1、共享内存区
A、shared_buffers —-共享缓冲区
- 它表示数据缓冲区中数据块的个数,每个数据块的大小是8KB。
- 数据缓冲区位于数据库的共享内存中,它越大越好,不能小于128KB。
- 这个参数只有在启动数据库时,才能被设置。
- 默认值是128MB。
-
B、wal_buffers —- 日志缓存区的大小
可以降低IO,如果遇上比较多的并发短事务,应该和commit_delay一起用。
-
2、私有内存区
A、temp_buffers—-临时缓冲区
用于存放数据库会话访问临时表数据,系统默认值为8M。
可以在单独的session中对该参数进行设置,尤其是需要访问比较大的临时表时,将会有显著的性能提升。B、work_mem —- 工作内存或者操作内存
其负责内部的sort和hash操作,合适的work_mem大小能够保证这些操作在内存中进行。
C、maintenance_work_mem —-维护工作内存
主要是针对数据库的维护操作或者语句。
主要针对VACUUM、CREATE INDEX、ALTER TABLE ADD FOREIGN KEY等操作。
在对整个数据库进行VACUUM或者较大的index进行重建时,适当的调整该参数非常必要,PostgreSQL文档提示在启用了autoacuum功能的情况下,该参数不能配置的过大。3、主要进程

Postmaster进程
PG数据库的总控制进程,负责启动和关闭数据库实例,是一个指向PostgreS命令的链接,算是第一个PostgreS进程。Postmaster的主进程,还会fork出一些辅助子进程。 BgWriter(后台写)进程
- WaLWriter(预写式日志)进程
- AutoVAcuum(系统自动清理)
- SysLogger(系统日志)进程
- PgArch(归档)进程
- PgStat(统计数据收集)进程
-
4、进程通信-建立会话
建立会话的过程:
阶段一:客户端发起请求。
- 阶段二:该阶段由主服务Postmaster进程负责服务器是否接受客户端的host通信认证;服务器对客户端进行身份鉴别。
- 阶段三:阶段二通过之后,主服务进程为该客户端单独fork一个客户端工作进程PostgreS。
阶段四:客户端与PostgreS进程建立通信连接,由PostgreS进程负责后续所有的客户端请求操作,直至客户端退出后,该PostgreS进程消失。
二、物理结构-数据存储方式
a、目录结构
默认表空间的数据文件存放在base目录
- 在pg_xlog保存WAL日志,只能通过软链改变它的位置。
b、段(Segments)
- 每一个表和索引都存放到单独的数据文件中。
- 文件名是表或索引的文件结点(filenode)编号。
- 如果表或索引超过1GB就会被分割为多个段,第一个段以文件结点(filenode)编号命名,第二个以及之后的段以 filenode.1,filenode.2 形式命名。
c、Page(Block)和Buffer
在磁盘中称为page,内存中称为buffer默认为8k,可以在编译时指定block_size参数改变大小。
d、Relation:表示表或索引 。
e、Tuple(row):表中的行。
1、目录结构
show data_directory;||select name,setting from pg_settings where category='File Locations';

select oid,relfilenode from pg_class where relname='a';select pg_relation_filepath('a'::regclass);
2、空闲空间映射(FSM)
- 每一个表和索引(除了哈希索引)都有一个空闲空间映射(FSM)来保持对关系中可用空间的跟踪。
- 伴随主关系数据被存储在一个独立的关系分支中,以关系的文件节点号加上一个_fsm后缀命名。
- FSM文件是执行VACUUM操作时,或者是为了插入行而第一次查询FSM文件时才会创建。
- PostgreSQL使用了树形结构组织FSM文件。
FSM可以在数据插入时快速找到满足大小要求的空闲空间,从而复用空闲空间。
3、可见性映射(VM)
为了能加快VACUUM清理的速度和降低对系统I/O性能的影响,V8.4版本以后为每个数据文件加了一个后缀为“__vm “的文件。
- 每一个表都有一个可见性映射(VM)用来跟踪哪些页面只包含已知对所有活动事务可见的元组,它也跟踪哪些页面只包含未被冻结的元组。它随着主关系数据被存储在一个独立的关系分支中,以该关系的文件节点号加上一个_vm后缀命名。
- 有了这个文件后,通过VACUUM命令扫描这个文件时,如果发现VM文件中这个数据块上的位表示该数据块没有需要清理的行,则会跳过对这个数据块的扫描,从而加快VACUUM清理的速度。
pg_visibility模块可以被用来检查存储在可见性映射中的信息。
三、页结构
1、Page Header
Page的基本信息
- 指向空闲空间(free space)
-
2、ItemIdData(Row/Index Pointers)
一个记录偏移量/长度(offset/length)的数组
- 指向实际的记录(rows/index entries)
-
3、Free Space
未分配的空间
- 新指针(pointers )从这个区域的开头开始分配
新的记录(rows/index entries)从结尾开始分配
4、Items(Row/Index Entry)
-
5、Special
不同的索引访问方式相关的数据
- 在普通表中为空
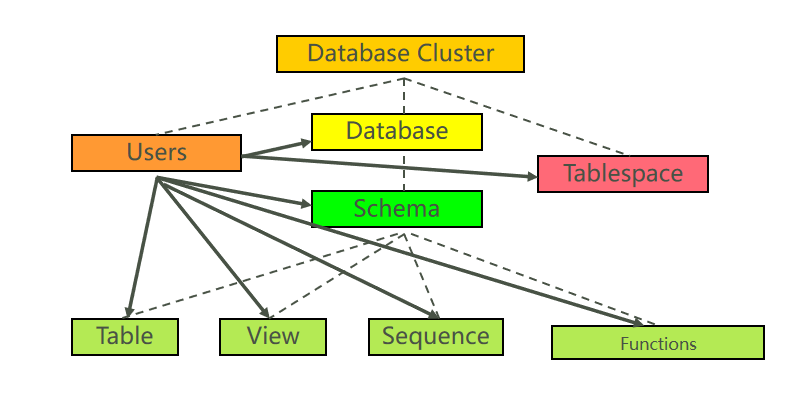
四、逻辑结构
[root@VM-0-9-centos ~]# mkdir -p /data/dbs/[root@VM-0-9-centos ~]# chown -R postgres.postgres /data/dbs/[root@VM-0-9-centos ~]# chmod -R 775 /data/dbs/[root@VM-0-9-centos ~]# su - postgresLast login: Tue Oct 26 15:32:33 CST 2021 on pts/3Last failed login: Tue Oct 26 15:33:34 CST 2021 on pts/3There was 1 failed login attempt since the last successful login.[postgres@VM-0-9-centos ~]$ mkdir /data/dbs/test_ts1
1、创建表空间

解决:需要提前建好表空间所在的目录,create tablespace不会自动创建表空间所在的目录。2、创建Database

3、切换数据库
查看当前连接的数据库。select current_catalog;


4、查看表空间

5、查看库

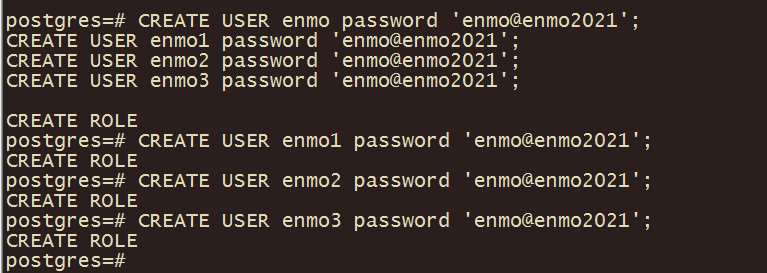
6、创建用户
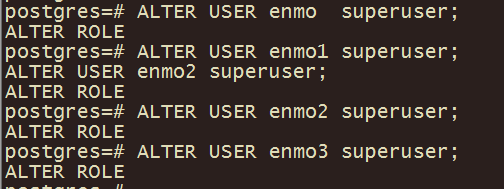
7、授权
8、查看用户

登录用户创建表:
1、用户enmo可以多次连接访问不同的数据库(testdb1、testdb2、testdb3);用户enmo可以在不同的数据库中创建数据库对象。
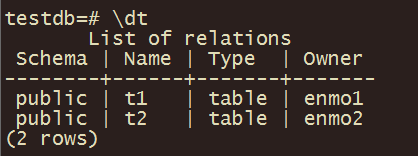
2、数据库testdb可以被用户enmo1、enmo2、enmo3访问(分别在数据库中创建了一张表、插入一行数据、进行查询)。也就是说一个数据库可以被多个用户来访问。
3、当用户enmo连接到数据库testdb1上时没法访问数据库testdb2上的表。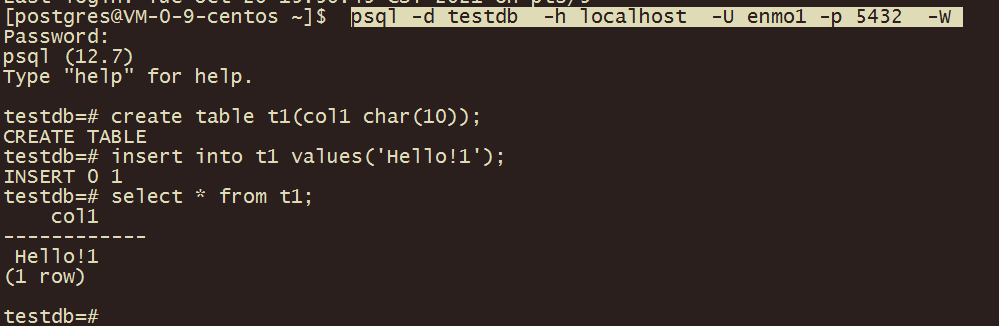

用户一次只能连接到一个数据库,没法访问其他数据库的对象。
9、创建模式
在当前数据库testdb下创建4个模式:
查看库下有哪些模式: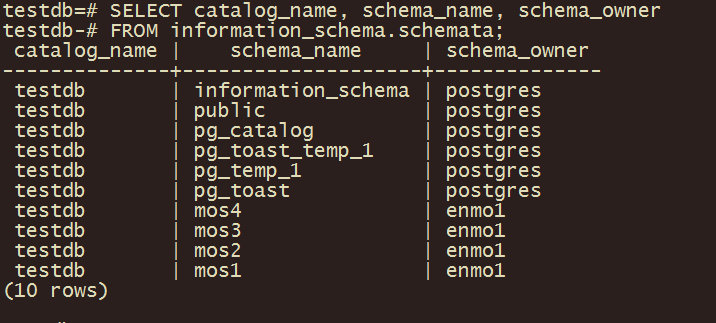

在不同模式下建表:

查看testdb数据库目前有哪些表:select table_catalog, table_schema, table_name, table_type from information_schema.tables where table_schema not in ('pg_catalog', 'information_schema','dbe_perf');

可以使用表名直接访问public的表(不需要加public模式名前缀)。
访问数据库下其他模式的表需要指定模式名前缀。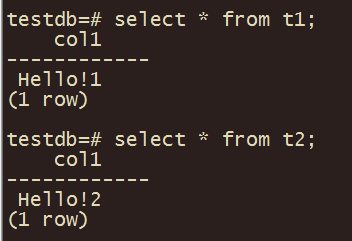
一个用户连接到数据库后,可以在这个数据库中创建多个模式。可以使用DatabaseName.SchemaName.TableName或者SchemaName.TableName来访问一个表。
默认情况下访问public模式下的表,可以不用添加模式名前缀。10、清理
\ldrop database **;\dudrop user ***;\dbdrop tablespace ***;


若有收获,就点个赞吧
0 人点赞
