MySQL数据存储和查询流程
假如现在建了如下一张表
CREATE TABLE `student` (`id` int(11) NOT NULL AUTO_INCREMENT COMMENT '学号',`name` varchar(10) NOT NULL COMMENT '学生姓名',`age` int(11) NOT NULL COMMENT '学生年龄',PRIMARY KEY (`id`),KEY `idx_name` (`name`)) ENGINE=InnoDB;
插入如下sql
insert into student (`name`, `age`) value('a', 10);insert into student (`name`, `age`) value('c', 12);insert into student (`name`, `age`) value('b', 9);insert into student (`name`, `age`) value('d', 15);insert into student (`name`, `age`) value('h', 17);insert into student (`name`, `age`) value('l', 13);insert into student (`name`, `age`) value('k', 12);insert into student (`name`, `age`) value('x', 9);
数据如下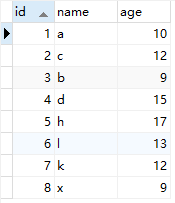
这些数据最终会持久化到文件中,那么这些数据在文件中是如何组织的?难道是一行一行追加到文件中的?其实并不是,「数据其实是存到页中的,一页的大小为16k,一个表由很多页组成,这些页组成了B+树」,最终的组织形式如下所示。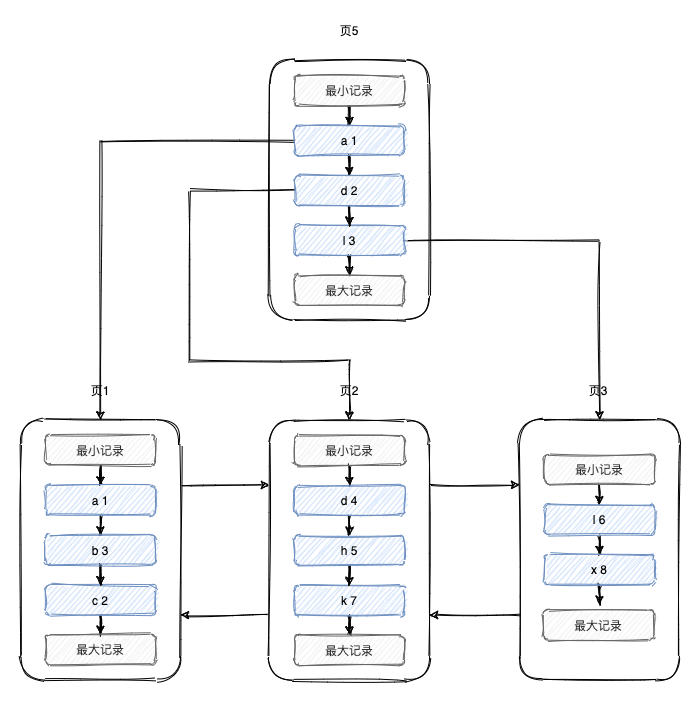
那么SQL语句是如何执行的呢?MySQL的逻辑架构图如下所示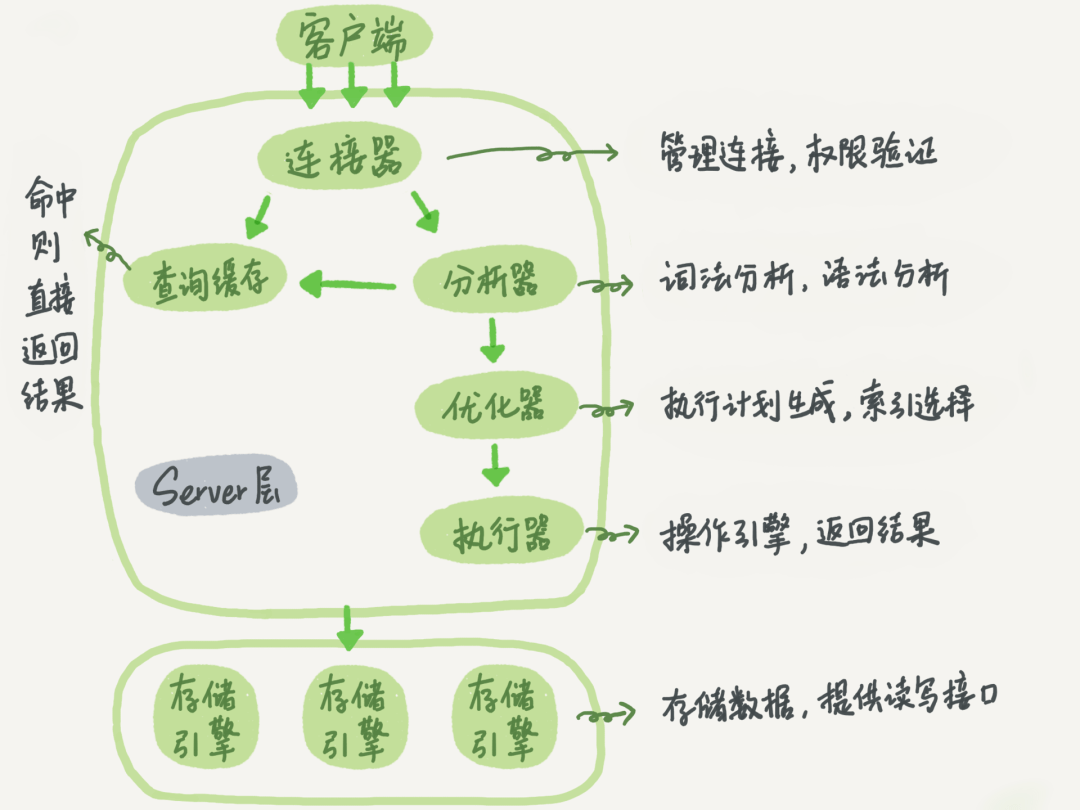
详细结构如为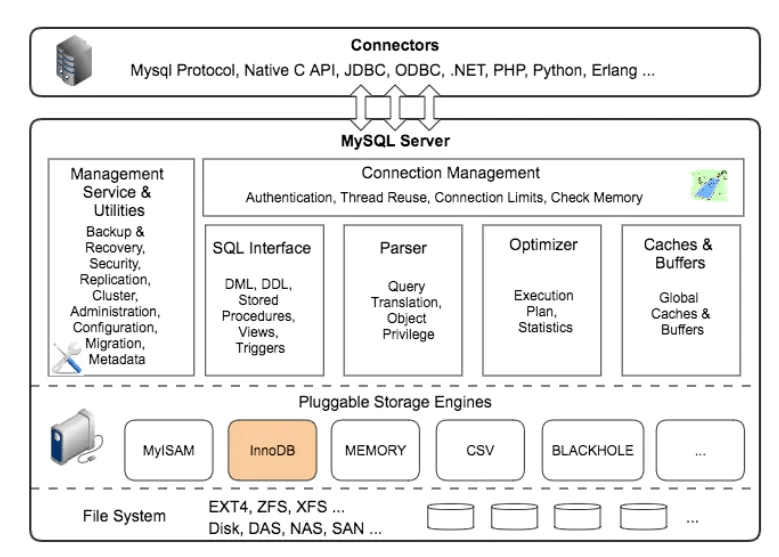
「当我们想更新某条数据的时候,难道是从磁盘中加载出来这条数据,更新后再持久化到磁盘中吗?」
如果这样搞的话,那一条sql的执行过程可太慢了,因为对一个大磁盘文件的读写操作是要耗费几百万毫秒的
真实的执行过程是,当我们想更新或者读取某条数据的时候,会把对应的页加载到内存中的Buffer Pool缓冲池中(默认为128m,当然为了提高系统的并发度,可以把这个值设大一点)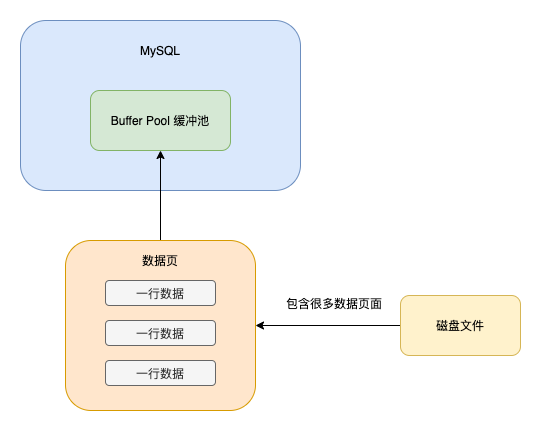
之所以加载页到Buffer Pool中,是考虑到当使用这个页的数据时,这个页的其他数据使用到的概率页很大,随机IO的耗时很长,所以多加载一点数据到Buffer Pool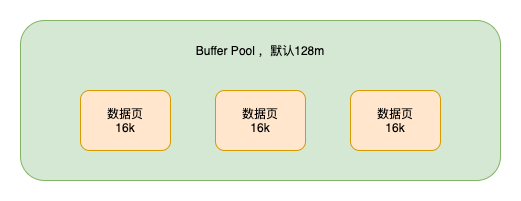
当更新数据的时候,如果对应的页在Buffer Pool中,则直接更新Buffer Pool中的页即可,对应的页不在Buffer Pool中时,才会从磁盘加载对应的页到Buffer Pool,然后再更新,「此时Buffer Pool中的页和磁盘中的页数据是不一致的,被称为脏页」。这些脏页是要被刷回到磁盘中的
「这些脏页是多会刷回到磁盘中的?」有如下几个时机
- Buffer Pool不够用了,要给新加载的页腾位置了,所以会利用改进的后的LRU算法,将一些脏页刷回磁盘
- 后台线程会在MySQL不繁忙的时候,将脏页刷到磁盘中
- redolog写满时(redolog的作用后面会提到)
- 数据库关闭时会将所有脏页刷回到磁盘
这样搞,效率是不是高很多了?
当需要更新的数据所在的页已经在Buffer Pool中时,只需要操作内存即可,效率不是一般的高
「看到这里可能会有一个疑问?如果对应的脏页还没有被刷到磁盘中,数据库就宕机了,那更改不就丢失了?」
要解决这个问题,就不得不提到rodolog了。
undolog:如何让更新的数据可以回滚?
以上面的student表为例,当我们想把id=1的name从a变为abc时,会把原来的值id=1,name=a写入到undo log中。当这条更新语句在事务中执行,当事务回滚时,就可以通过undolog将数据恢复为原来的模样。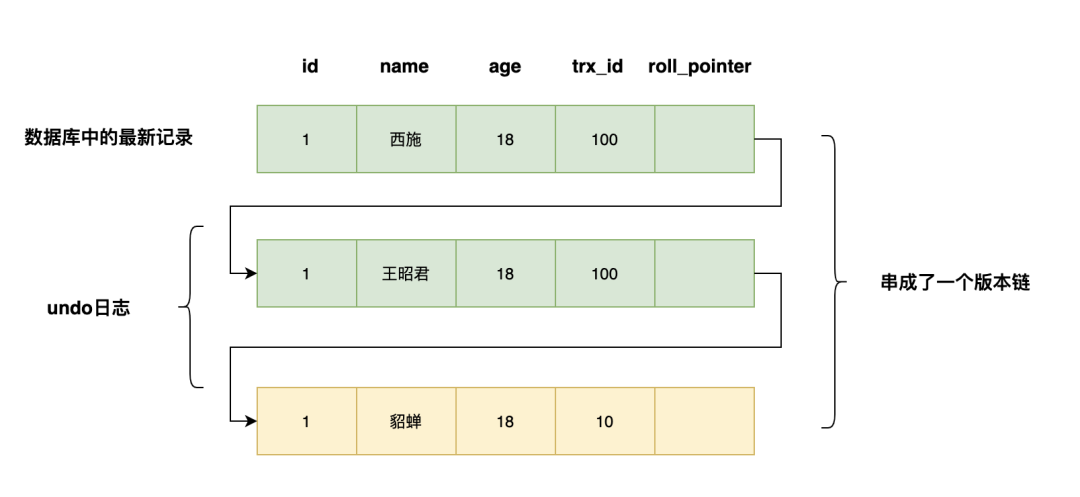
此外,undo log在mvcc的实现中也扮演了重要的作用。
rodolog:系统宕机了,如何避免数据丢失?
接着上面的问题,如果对应的脏页还没有被刷到磁盘中,数据库就宕机了,那更改不就丢失了?
为了解决这个问题,需要把内存所做的修改写入到 redo log buffer中,这是内存里的一个缓冲区,用来存在redo日志。
rodo log记录了对数据所做的修改,如“将id=1这条数据的name从a变为abc”,物理日志哈,后面会再提一下。「redo log是顺序写所以比随机写效率高」
「InnoDB的redo log是固定大小的」,比如可以配置为一组 4 个文件,每个文件的大小是 1GB,那么总大小为4GB。从头开始写,写到末尾就又回到开头循环写,如下面这个图所示。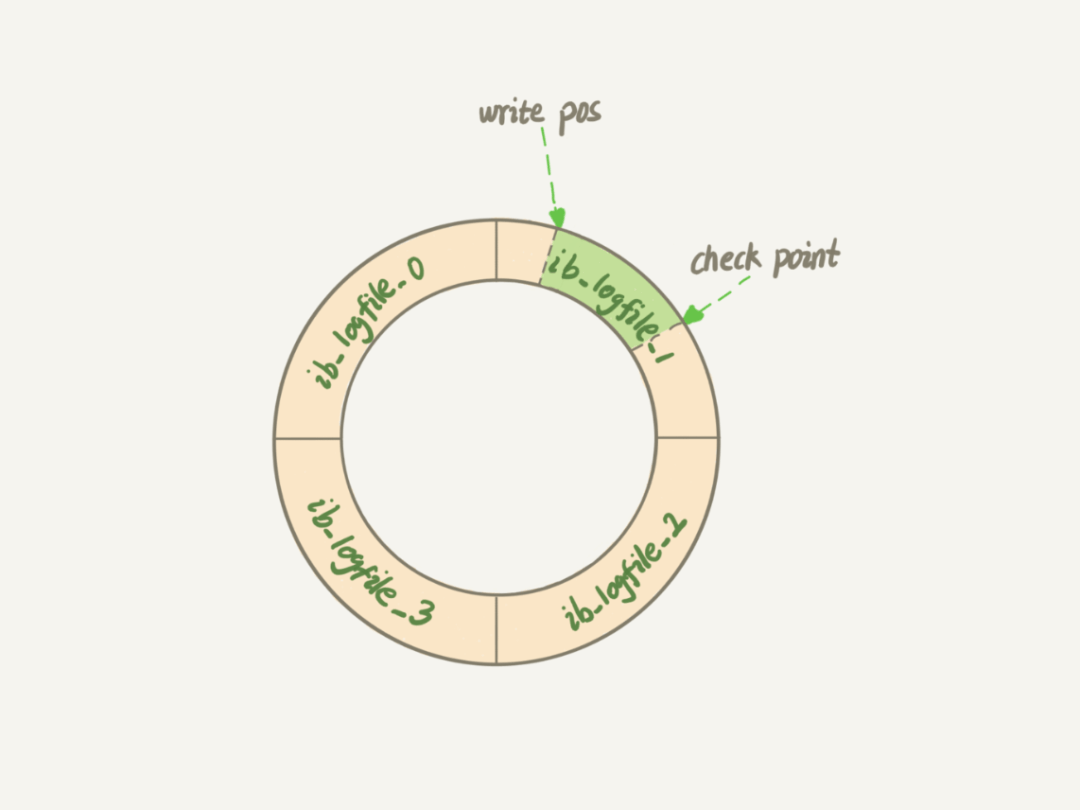
write pos是当前要写的位置,checkpoint是要擦除的位置,擦除前要把对应的脏页刷回到磁盘中。write pos和checkpoint中间的位置是可以写的位置。
当系统能支持的并发比较低时,可以看看对应的redo log是不是设置的太小了。太小的话会导致频繁的刷脏页,影响并发,可以通过工具监控redo log的大小redolog的大小=innodb_log_file_size*innodb_log_files_in_group(默认为2)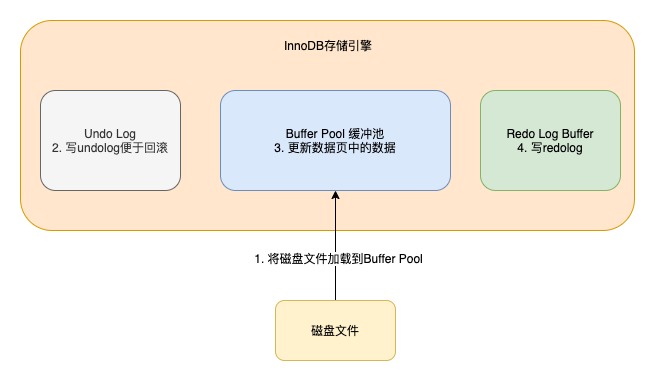
「接下来看看redolog是如何避免数据丢失的」
事务未提交,MySQL宕机,这种情况Buffer Pool中的数据丢失,并且redo log buffer中的日志也会丢失,不会影响数据
提交事务成功,redo log buffer中的数据没有刷到磁盘,此时会导致事务提交的数据丢失。
「鉴于这种情况,可以通过设置innodb_flush_log_at_trx_commit来决定redo log的刷盘策略」
查看innodb_flush_log_at_trx_commit的配置
SHOW GLOBAL VARIABLES LIKE 'innodb_flush_log_at_trx_commit';
innodb_flush_log_at_trx_commit值 |
作用 |
|---|---|
| 0 | 提交事务时,不会将redo log buffer中的数据写入os buffer,而是每秒写入os buffer并刷到磁盘 |
| 1 | 提交事务时,必须把redo log从内存刷入到磁盘文件中 |
| 2 | 提交事务时,将rodo log写入os buffer中,默认每隔1s将os buffer中的数据刷入磁盘 |
应为0和2都可能会造成事务更新丢失,所以一般系统中innodb_flush_log_at_trx_commit的值都为1。
binlog:主从库之间如何同步数据?
当我们把mysql主库的数据同步到从库,或者其他数据源时,如es,bi库时,只需要订阅主库的binlog即可。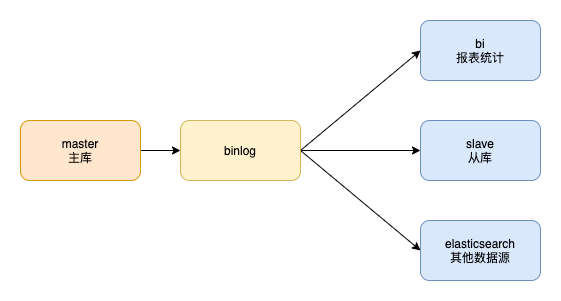
为什么要弄2种日志呢?其实这都是由历史原因决定的
MySQL刚开始用binlog实现归档的功能,但是binlog没有crash-safe的能力,所以后来InnoDB引擎加了redo log来实现crash-safe。假如MySQL中只有一个InnoDB引擎,说不定就能用redo log来实现归档了,此时就可以将redo log和 binlog合并到一块了
这两种日志的区别如下:
- redo log是InnoDB存储引擎特有,binglog是MySQL的server层实现的,所有引擎都可以使用
- redo log是物理日志,记录的是数据页上的修改。binlog是逻辑日志,记录的是语句的原始逻辑,如给id=2的这一行的c字段加1
- redo log是固定空间,循环写。binlog是追加写,当binlog文件写到一定大小后会切换到下一个,并不会覆盖以前的日志
「可以通过设置sync_binlog来决定binlog的刷盘策略」
sync_binlog值 |
作用 |
|---|---|
| 0 | 不立即刷盘,将binlog写入os buffer,由操作系统决定何时刷盘 ,有可能会丢失多个事务的数据 |
| 1 | 将binlog写入os buffer,每n个事务提交后,将os buffer的数据刷盘 |
两阶段提交
接着来看一下将id=2的行c字段加1的执行流程。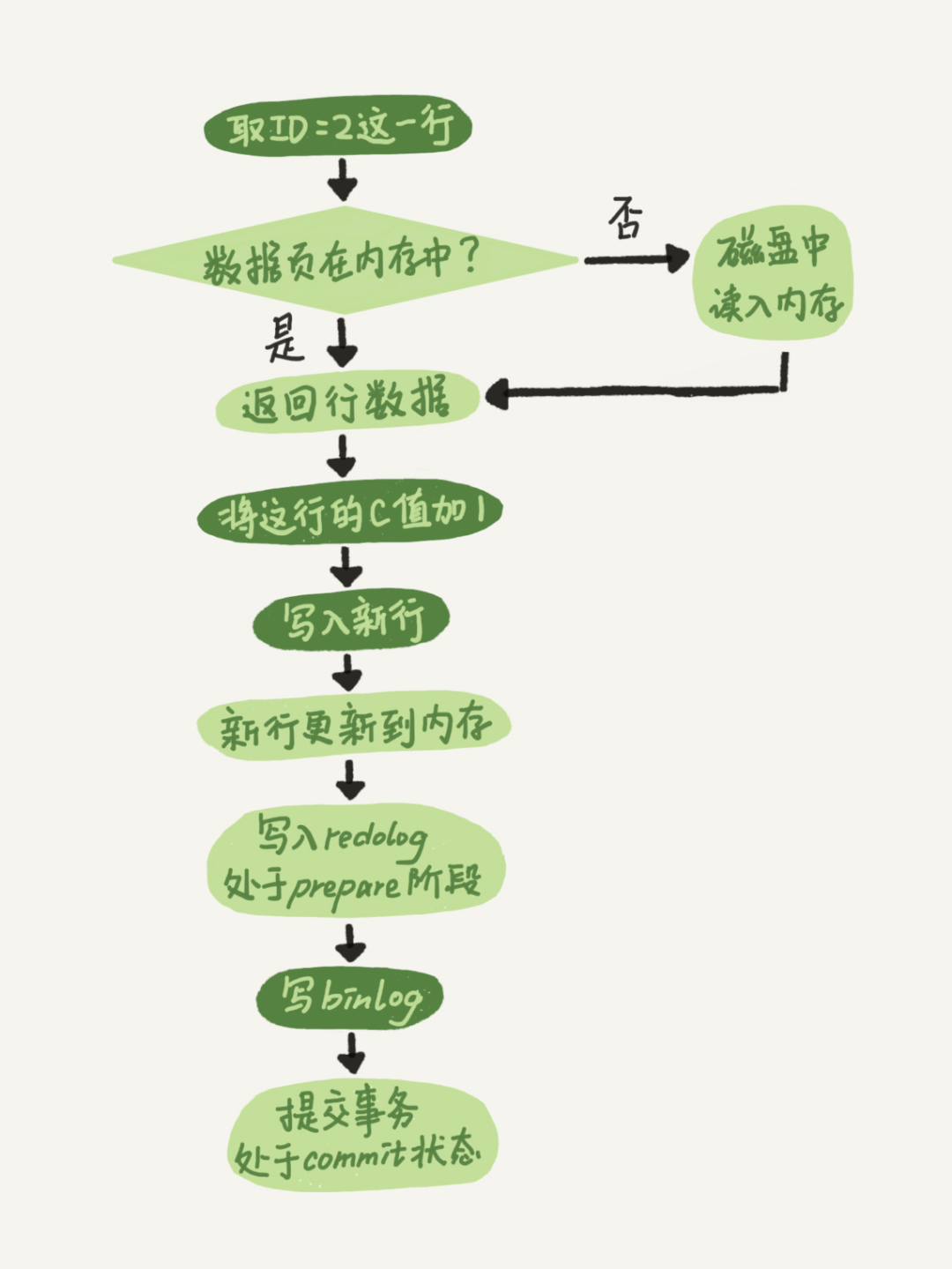
前面的这个阶段大家应该都能看懂,重点说一下最后三个阶段
- 引擎将新数据更新到内存中,将操作记录到redo log中,此时redo log处于prepare状态,然后告知执行器执行完成了,可以提交事务
- 执行器生成操作的binlog,并把binlog写入磁盘
- 引擎将写入的redo log改为提交状态,更新完成
「为什么要把relog的写入拆成2个步骤?即prepare和commit,两阶段提交」
因为不管先写redolog还是binlog,奔溃发生后,最终其实都有可能会造成原库和用日志恢复出来的库不一致
「而两阶段提交可以避免这个问题」
redolog和binlog具有关联行,在恢复数据时,redolog用于恢复主机故障时的未更新的物理数据,binlog用于备份操作。每个阶段的log操作都是记录在磁盘的,在恢复数据时,redolog 状态为commit则说明binlog也成功,直接恢复数据;如果redolog是prepare,则需要查询对应的binlog事务是否成功,决定是回滚还是执行。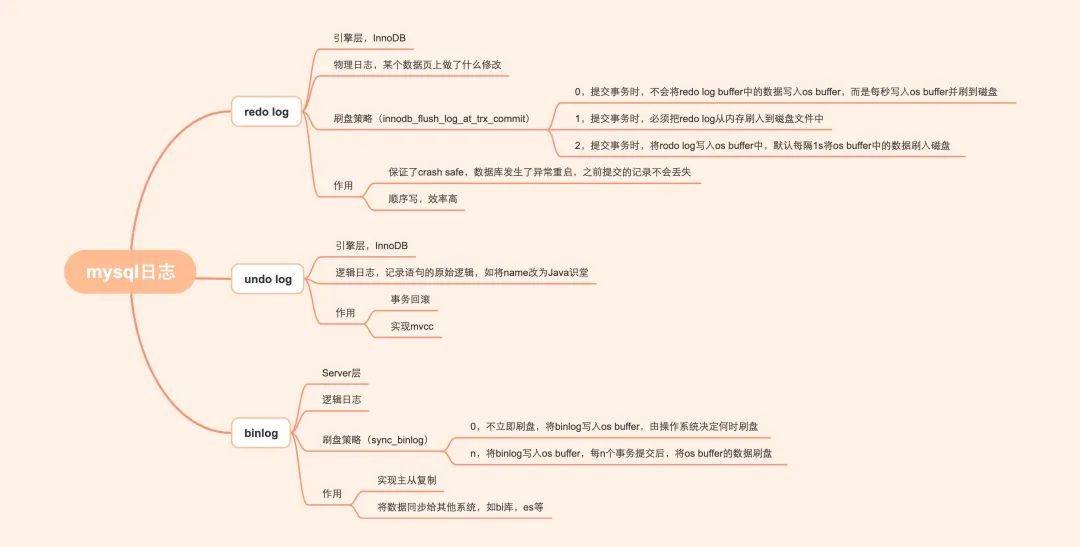
踩过的一些坑
「1. 数据库支持的并发度不高」
在一些并发要求高的系统中,可以调高Buffer Pool和redo log,这样可以避免频繁的刷脏页,提高并发
「2. 事务提交很慢」
事务提交很慢。监控到Buffer Pool和redo log的设置都很合理,并没有太小,所以问题出在哪了?
「dba排查到原因,把复制方式从半同步复制改为异步复制解决了这个问题」
「异步复制」:MySQL默认的复制即是异步的,主库在执行完客户端提交的事务后会立即将结果返给给客户端,并不关心从库是否已经接收并处理,这样就会有一个问题,主如果crash掉了,此时主上已经提交的事务可能并没有传到从库上,如果此时,强行将从提升为主,可能导致新主上的数据不完整
「半同步复制」:是介于全同步复制与全异步复制之间的一种,主库只需要等待至少一个从库节点收到并且 Flush Binlog 到 Relay Log 文件即可,主库不需要等待所有从库给主库反馈。同时,这里只是一个收到的反馈,而不是已经完全完成并且提交的反馈,如此,节省了很多时间
「全同步复制」:指当主库执行完一个事务,所有的从库都执行了该事务才返回给客户端。因为需要等待所有从库执行完该事务才能返回,所以全同步复制的性能必然会收到严重的影响
「3. 在一个方法中,先插入了一条数据,然后过一会再查一遍,结果插入成功,却没有查出来」
这个比较容易排查,如果系统中采用了数据库的读写分离时,写插入的是主库,读的却是从库,binlog同步比较慢时,就会出现这种情况,此时只需要让这个方法强制走主库即可

若有收获,就点个赞吧
0 人点赞
