环境说明
Linux(CentOS7.3)-Redis6.0.5源码编译版
相比于单机的 Redis 架构,主从复制架构具有如下优势:
- 保证数据安全性。从节点作为主节点备份,一旦主节点不可用,从节点可以顶上去,保证了数据尽量不被丢失
- 提高读能力。主从读写分离,横向扩展的系统的读负载
- Redis 高可用的基础
但是主从复制架构有一个非常致命的问题,那就是一旦主节点由于故障不可用时,需要手动将一个从节点晋升为主节点,需要将其他节点的主节点替换为新的主节点,同时还需要修改应用的主节点地址,如果应用方没使用配置中心则还需要重启服务,整个过程都需要人工干预,而且工程量也不小,这是一个无法接受的问题。在 Redis 2.8 提供比较完善的解决方案:Redis Sentinel。Redis Sentinel 是一个能够自动完成故障发现和故障转移并通知应用方,从而实现真正的高可用的分布式架构。下面是Redis官方文档对于哨兵功能的描述:
- 监控(Monitoring):哨兵会不断地检查主节点和从节点是否运作正常。
- 自动故障转移(Automatic failover):当主节点不能正常工作时,哨兵会开始自动故障转移操作,它会将失效主节点的其中一个从节点升级为新的主节点,并让其他从节点改为复制新的主节点。
- 配置提供者(Configuration provider):客户端在初始化时,通过连接哨兵来获得当前Redis服务的主节点地址。
- 通知(Notification):哨兵可以将故障转移的结果发送给客户端。
监控和自动故障转移使得 Sentinel 能够完成主节点故障发现和自动转移,配置提供者和通知则是实现通知客户端主节点变更的关键。架构分析
典型的哨兵架构图如上图所示,它主要包括两个部分:哨兵节点和数据节点。
- 哨兵节点:哨兵系统由若干个哨兵节点组成。其实哨兵节点就是一个特殊的 Redis 节点,只不过它是不存储数据的和仅支持部分命令
- 数据节点:由主节点和从节点组成的数据节点。
部署
这部分将部署一个简单的哨兵系统,包含 1 一个主节点,2 个从节点和 3 个哨兵节点,配置如下:
| 节点 | IP | 端口 |
|---|---|---|
| 主节点 | 127.0.0.1 | 6379 |
| 从节点 1 | 127.0.0.1 | 6380 |
| 从节点 2 | 127.0.0.1 | 6381 |
| 哨兵节点 1 | 127.0.0.1 | 26379 |
| 哨兵节点 2 | 127.0.0.1 | 26380 |
| 哨兵节点 3 | 127.0.0.1 | 26381 |
哨兵部署
典型的哨兵架构包括了哨兵节点和数据节点,所以这里分为两步部署。
部署 Redis 数据节点
部署 Redis 数据节点其实就是部署主从架构,按照上面的要求是一主两从的架构。
一主
6379 是主节点,配置如下:
--redis-6379.confport 6379daemonize yespidfile "/var/run/redis_6379.pid"logfile "/Users/chenssy/Documents/workSpace/environment/redis-5.0.3/6379/redis.log"dir "/Users/chenssy/Documents/workSpace/environment/redis-5.0.3/6379"
然后启动主节点即可。redis-server../6379/redis-6379.conf
两从
两个从节点的配置和主节点基本一致,如下:
--redis-6380.confport 6380daemonize yespidfile "/var/run/redis_6380.pid"logfile "/Users/chenssy/Documents/workSpace/environment/redis-5.0.3/6380/redis.log"dir "/Users/chenssy/Documents/workSpace/environment/redis-5.0.3/6380"slaveof 127.0.0.1 6379
启动 6380 和 6381 两个节点,这时他们与 6379 已经建立了主从关系,从 6379 视角看,它有两个从节点 6380、6381,如下: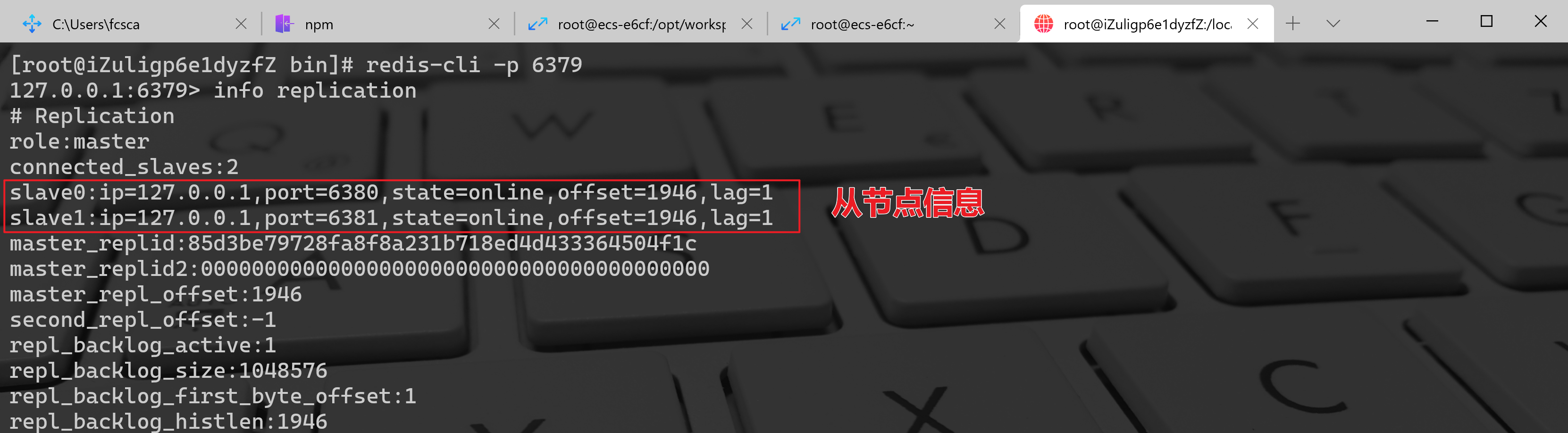
此时,拓扑结构图如下: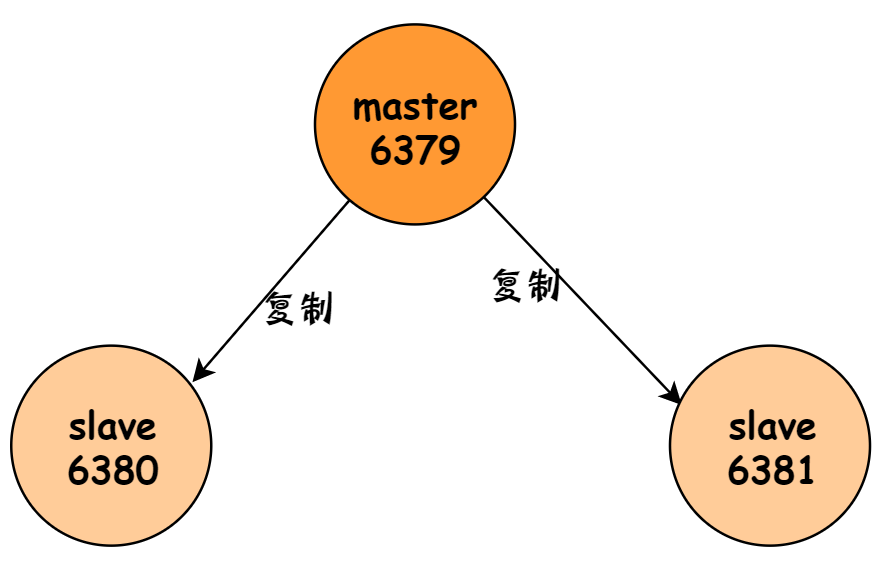
部署 Sentinel 节点
3 个 Sentinel 节点的部署方式完全一致,仅仅只是端口不同,下面只演示 26379 节点的部署。
配置
-- redis-26379.confport 26379daemonize yespidfile "/var/run/redis_26379.pid"logfile "/local/redis/sentinel/redis-sentinel3/log/redis-sentinel-26381.log"dir ./sentinel monitor fc-master 127.0.0.1 6379 2
相比数据节点的配置仅多了一个配置项,所以这里的配置部分尽量简化,更多配置会在后面介绍。sentinel monitor mymaster127.0.0.1:6379,表示的意义是该哨兵节点监控 127.0.0.1:6379 这个主节点,mymaster 是主节点的别名,最后的 2 的含义是至少需要2个哨兵节点同意,才能判定主节点故障并进行故障转移。
启动
哨兵节点的启动有两种方式:
$ ./redis-sentinel redis.conf$ ./redis-server redis.conf --sentinel
启动的效果完全一致。
按照上述配置和启动 26380 和 26381 哨兵节点。
验证
按照上述过程,整个哨兵架构已经搭建完毕了,可以通过 info 命令来进行验证。如下:
127.0.0.1:26381> info Sentinel# Sentinelsentinel_masters:1sentinel_tilt:0sentinel_running_scripts:0sentinel_scripts_queue_length:0sentinel_simulate_failure_flags:0master0:name=fc-master,status=ok,address=127.0.0.1:6379,slaves=2,sentinels=3

通过上图,可以看出 26379 哨兵节点已经监控了 mymaster 的主节点,地址为 127.0.0.1:6379,并且发现了两个从节点和其余 2 个哨兵节点。
此时,如果再看下哨兵节点的配置文件,会发现末尾多了几个配置,如下:
known-replica 和 known-sentinel 显示哨兵已经发现了从节点和其他哨兵;带有 epoch 的参数与配置纪元有关(配置纪元是一个从0开始的计数器,每进行一次领导者哨兵选举,都会+1;领导者哨兵选举是故障转移阶段的一个操作,在后文原理部分会介绍)
至此,整个哨兵架构已经搭建完毕了,整体拓扑结构图如下: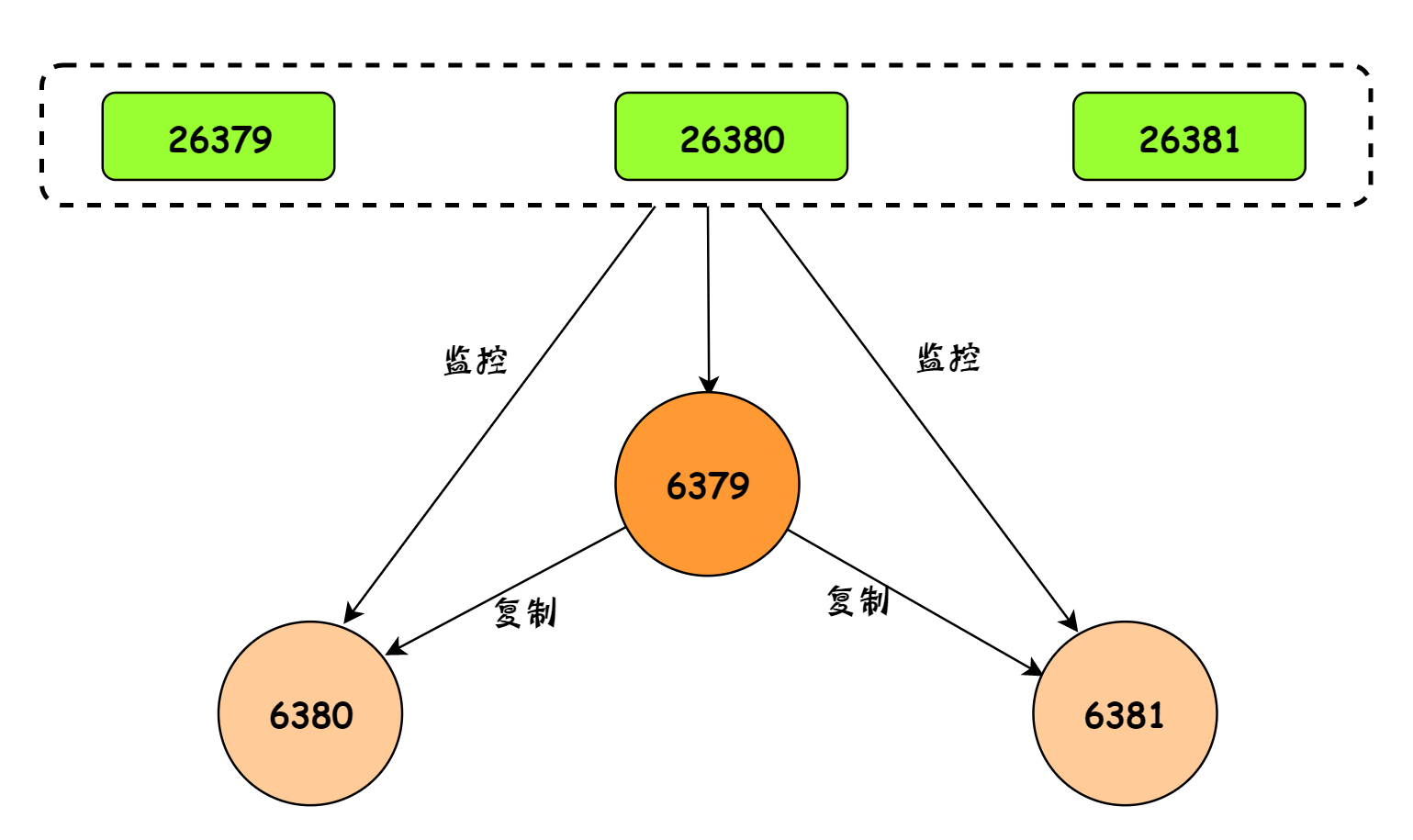
故障转移演示
在主从架构模式下,当主节点发生故障后,如何手动恢复的呢?
- 选定一个从节点对其执行
slaveofnoone命令,使其变成一个新的主节点 - 将其他从节点变成新主节点的从节点,执行命令
slaveof 新IP 新port - 更新客户端的 Redis 连接信息,重启应用
- 启动发送了故障的主节点,执行
slaveof新IP新port使其变成新主节点的从节点
上面的过程都需要人工干预,同时也会存在几个问题,比如是如何发送主节点故障了呢?判断主节点故障的机制是否完善?选择从节点的机制是否完善呢?等等一系列的问题,所以对于这种方案在生产环境下肯定是不可能接受的,那么如何解决呢?Redis Sentinel 就是解决这些问题的方案,下面就 Redis Sentinel 是如何实现故障转移的流程做一个简要的说明。
- 主节点出现故障导致不可用,这时从节点和客户端都与其失去联系
- Sentinel 节点通过定时监控发现主节点出现了故障,判断其不可用(可能是某个节点主观认为不可用),当大多数 Sentinel 对主节点的故障判断达成一致时,就会选举一个 Sentine-l 节点作为领导者来负责故障转移
- Sentinel-1 通过一定规则选择其中一个从节点作为新的主节点,然后整个过程就和上面手动恢复一致了,只不过它是又 sentinel-1 来自动完成的。
故障转移后,上图架构变成了下图所示: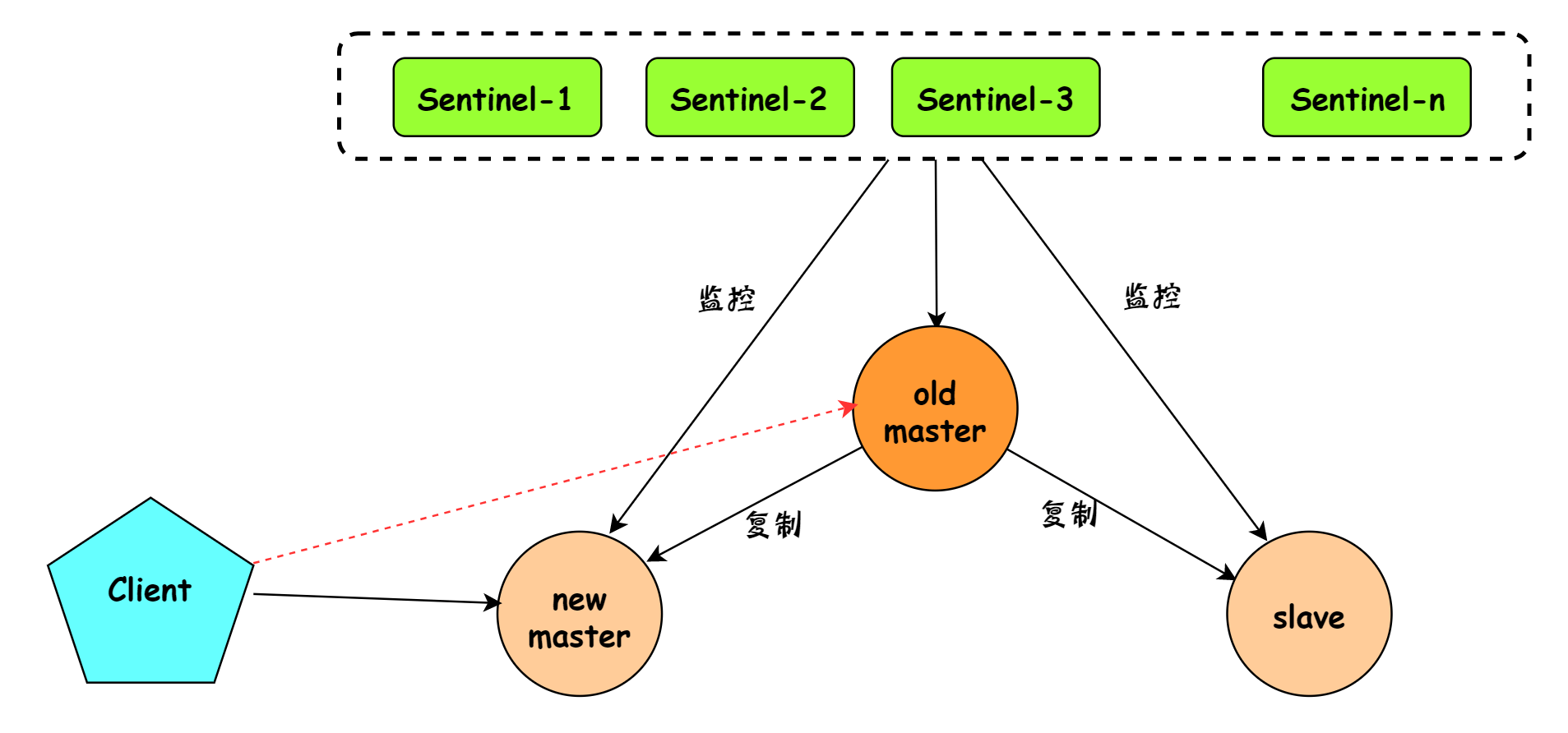
下面就主节点 6379 发生故障时,哨兵的监控和自动故障转移。
- (1) 首先利用 kill 命令将 6379 进程杀掉
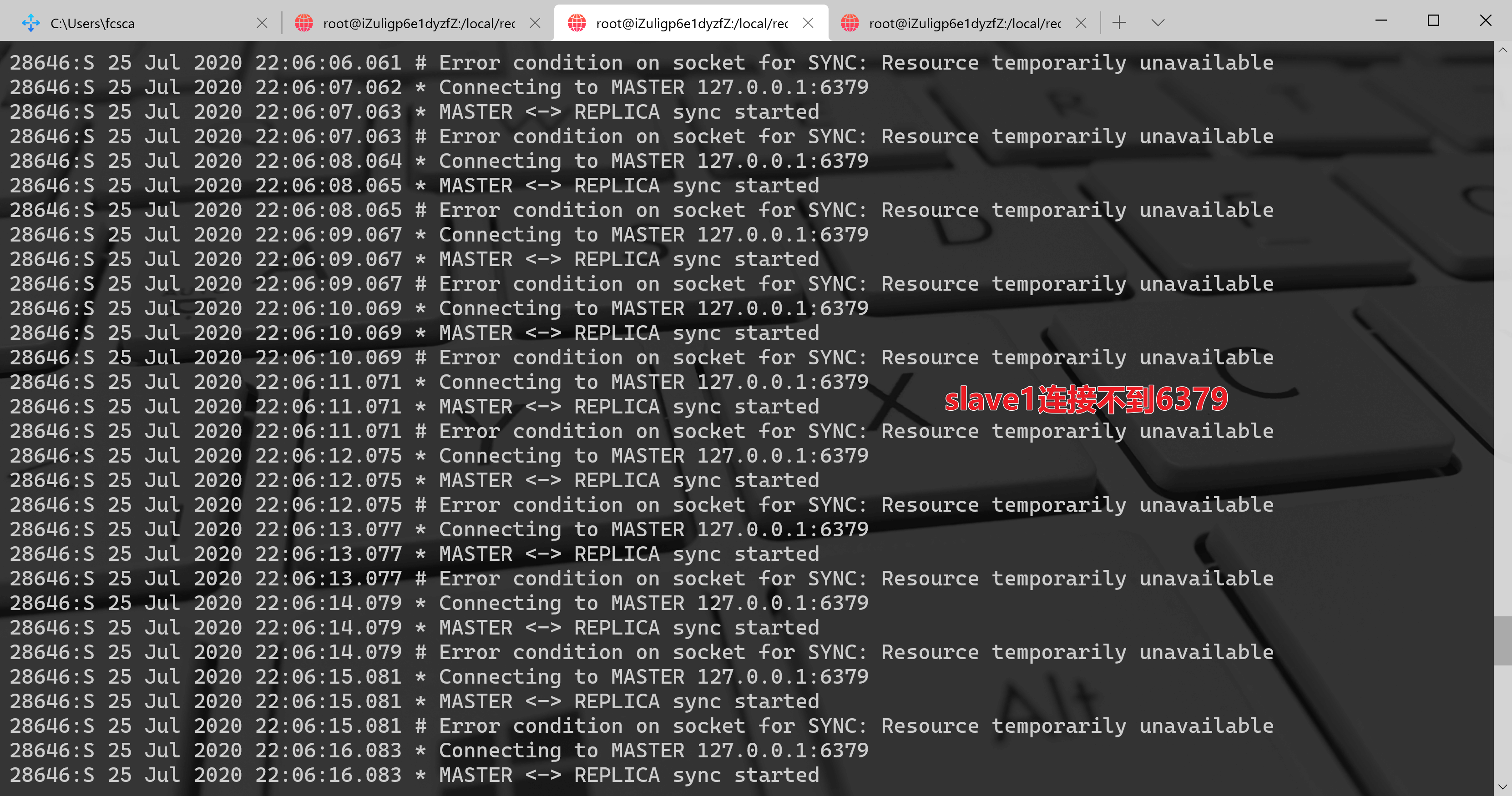
杀掉 6379 这个主节点后,6380、6381 两个从节点会连接不上 master 主节点,打印如下日志:[root@iZuligp6e1dyzfZ bin]# ps -aux | grep 6379root 18670 0.1 0.3 164832 7304 ? Ssl Jul24 2:15 /local/redis-6/bin/redis-server *:6379root 30850 0.2 0.3 164752 6824 ? Ssl 21:42 0:02 ./redis-server 127.0.0.1:26379 [sentinel]root 31062 0.0 0.0 112648 968 pts/0 R+ 22:05 0:00 grep --color=auto 6379[root@iZuligp6e1dyzfZ bin]# kill 18670[root@iZuligp6e1dyzfZ bin]# ps -aux | grep 6379root 30850 0.2 0.3 164752 6676 ? Ssl 21:42 0:02 ./redis-server 127.0.0.1:26379 [sentinel]root 31067 0.0 0.0 112648 972 pts/0 R+ 22:06 0:00 grep --color=auto 6379
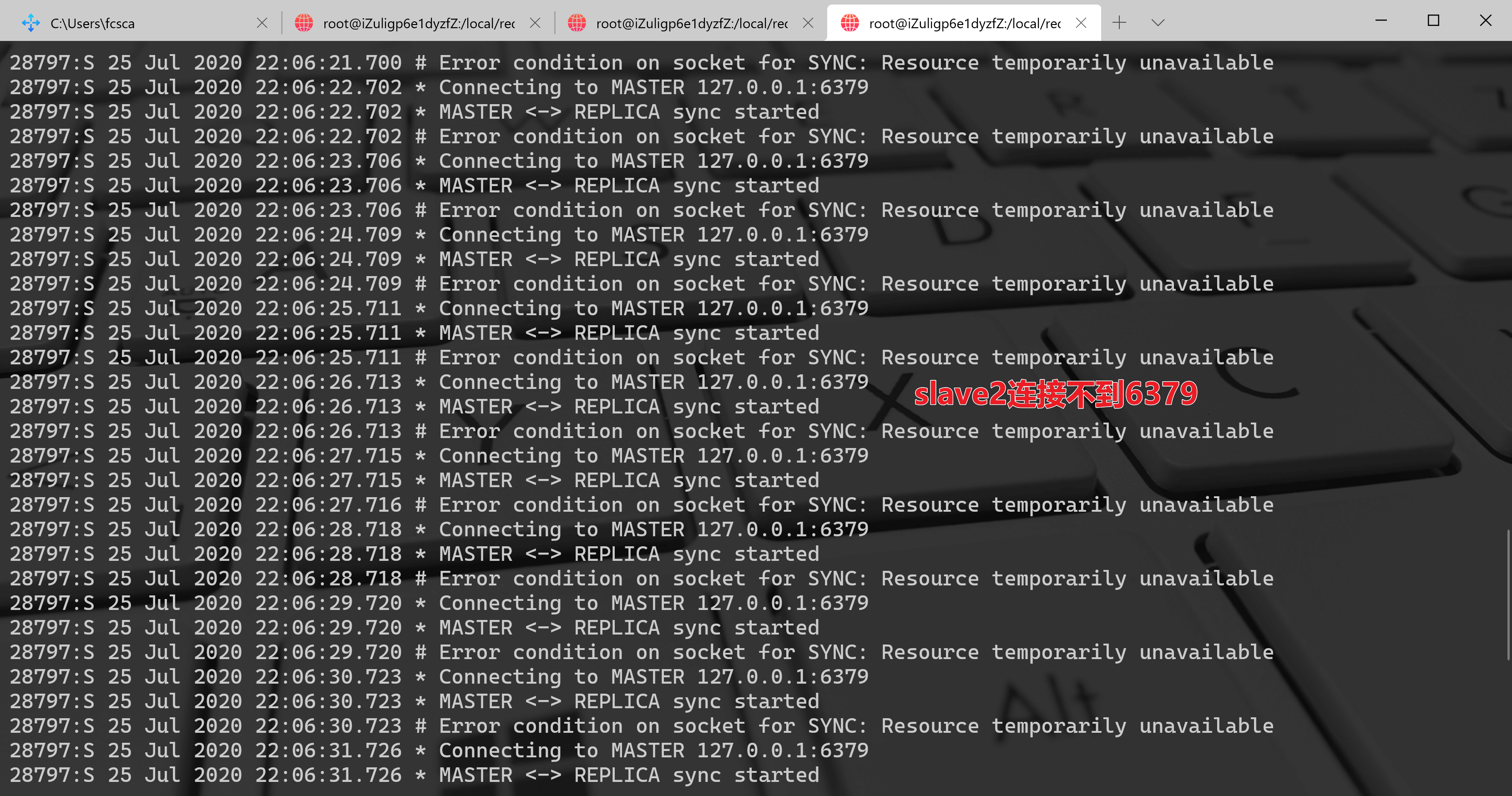
(2) 等待一段时间,因为哨兵发现主节点故障和转移故障是需要时间的。等待一段时间后,执行redis-cli -p 26379 info Sentinel,会发现 address 发生了变化,如下图:[root@iZuligp6e1dyzfZ bin]# redis-cli -p 26381 info Sentinel# Sentinelsentinel_masters:1sentinel_tilt:0sentinel_running_scripts:0sentinel_scripts_queue_length:0sentinel_simulate_failure_flags:0master0:name=fc-master,status=ok,address=127.0.0.1:6380,slaves=2,sentinels=3

address 变成了 127.0.0.1:6380 ,所以这里 6380 已经晋升为主节点了。节点 6380 的会出现如下日志:
节点 6381 的日志如下: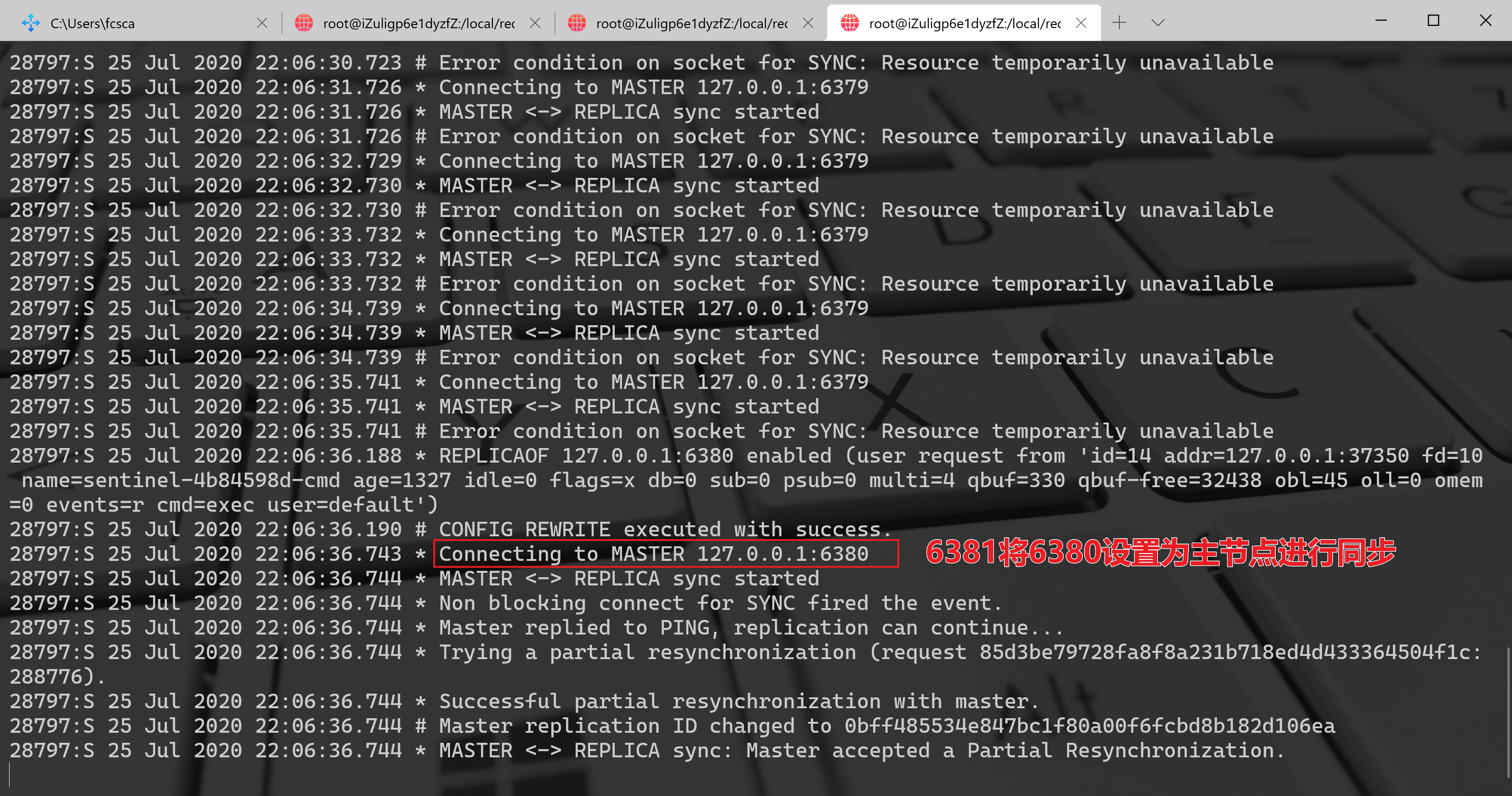
从这个日志可以看到如下几个信息:6381 变成了 6380 的从节点,向节点 6380 发送复制请求。
主节点 6380 的日志如下: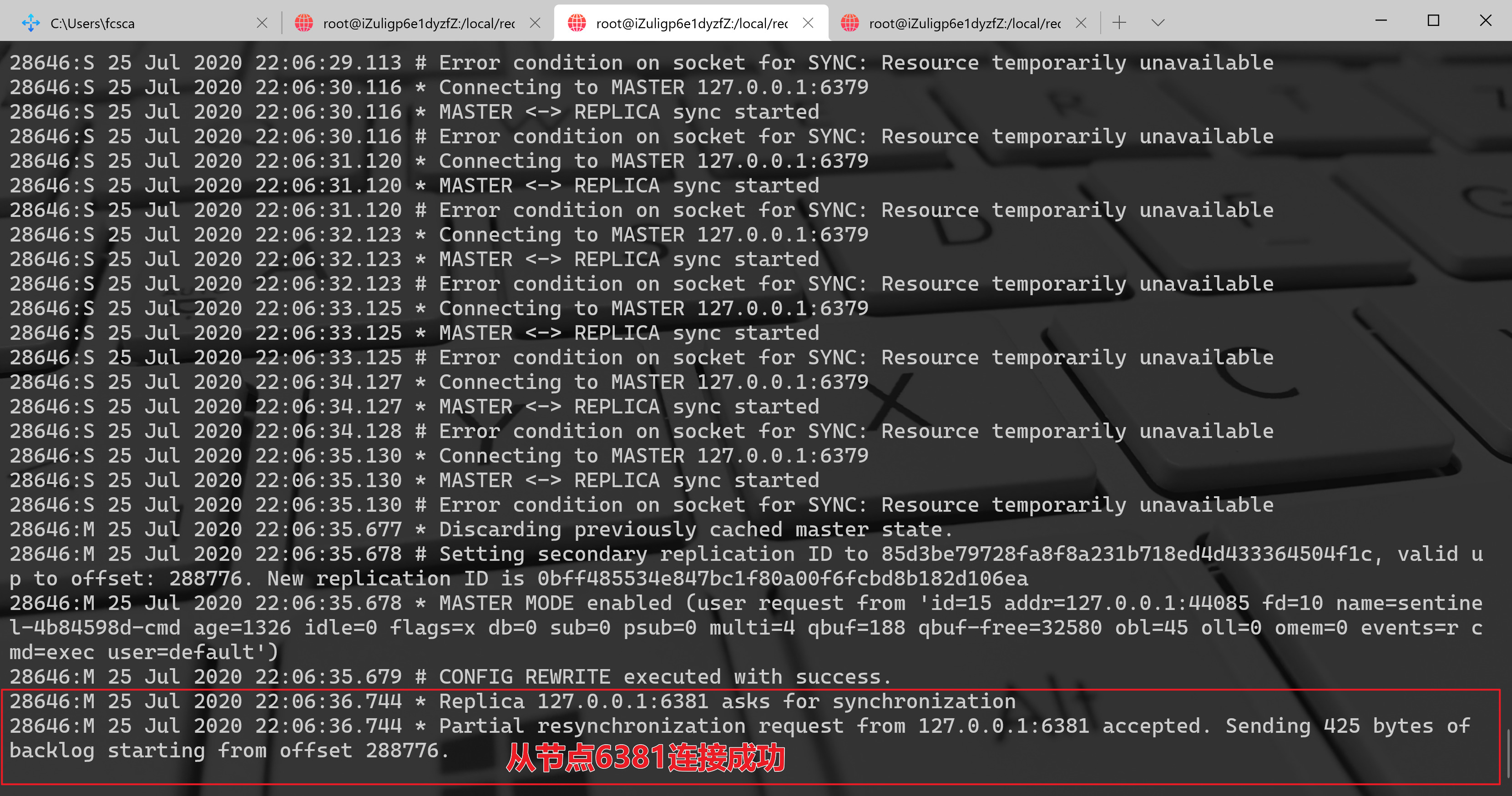
日志显示 6380 发送 6381 的数据量有 425 bytes。到这里了,如果对主从复制还记忆犹新的话,一定会有一个疑问:为什么 6380 与 6381 之间不是进行全量复制而是部分复制?,因为知道 6380 发送psync runid offset命令进行复制时,这里的 runid 照理来说应该是 6379 的 runid,与 6381 的 runid 不相等,所以应该是进行全量复制而不是部分复制?关于这点,那就是 Redis 4.0 以后的新特性PSYNC2,它解决了因实例重启和主实例故障切换带来的全量复制的问题。
通过上面的日志,就已经知道了数据节点是如何完成故障转移的,下面再分析哨兵节点的日志。
26379 的日志: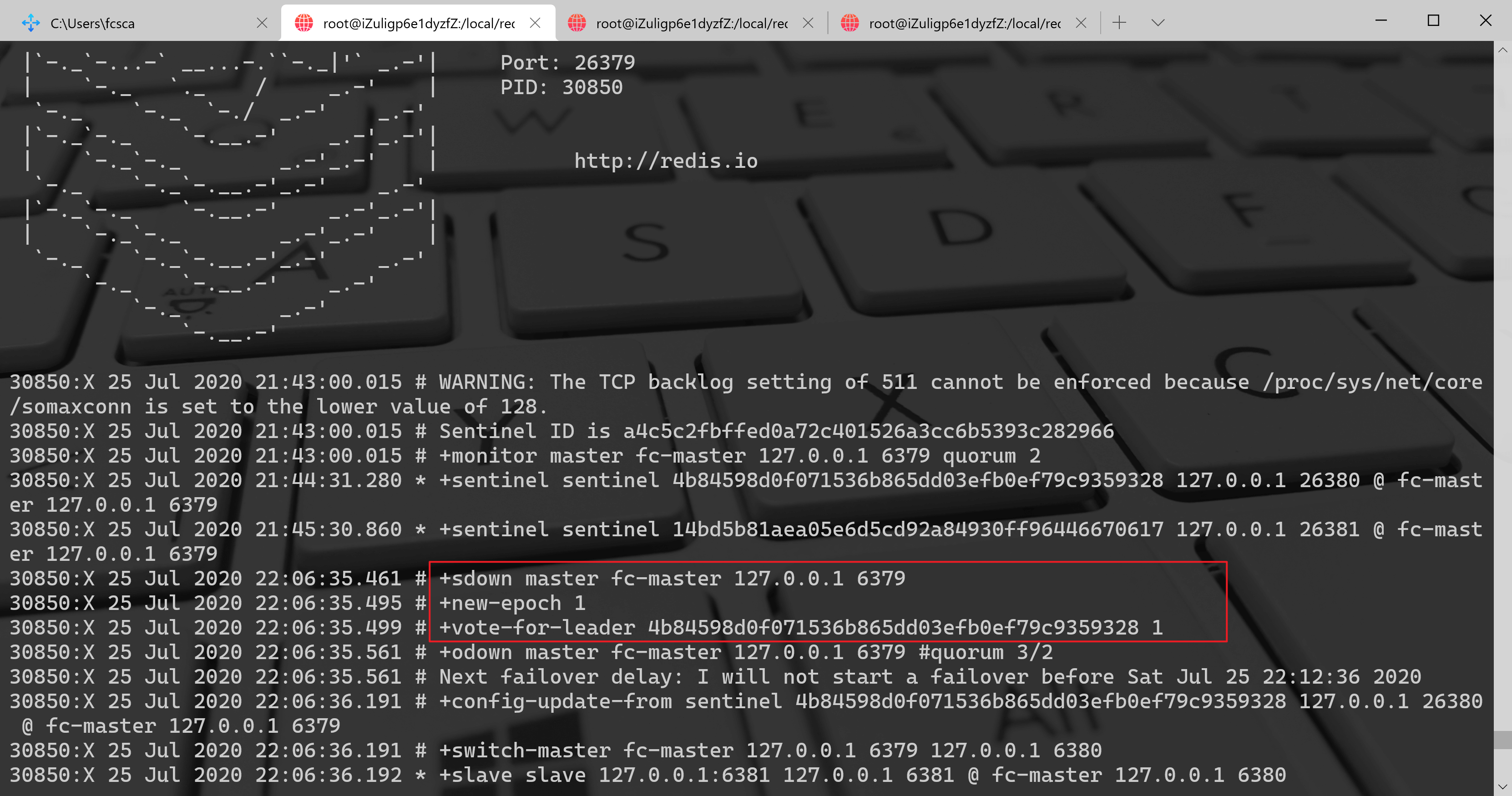
26380 的日志: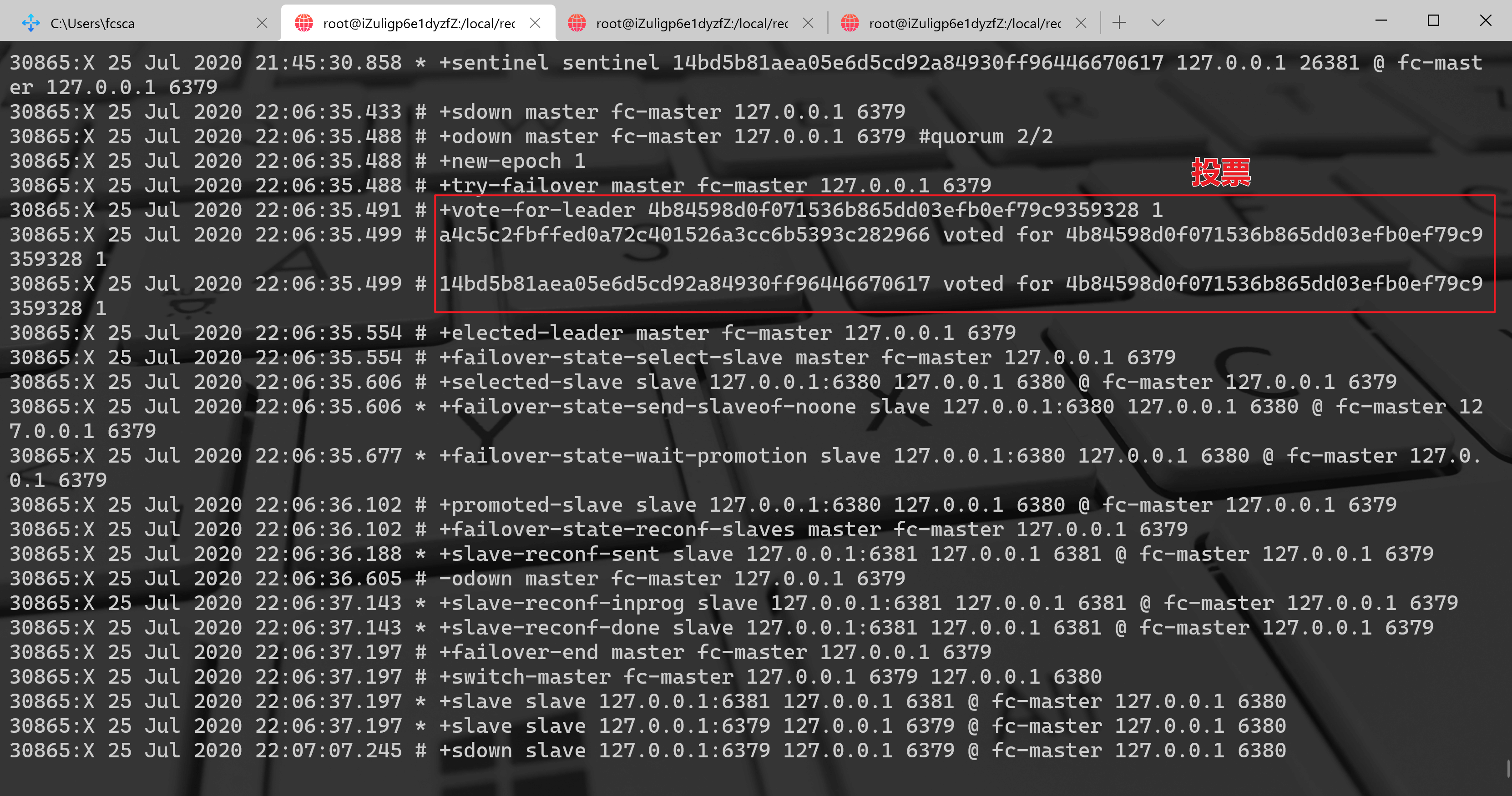
26381 的日志: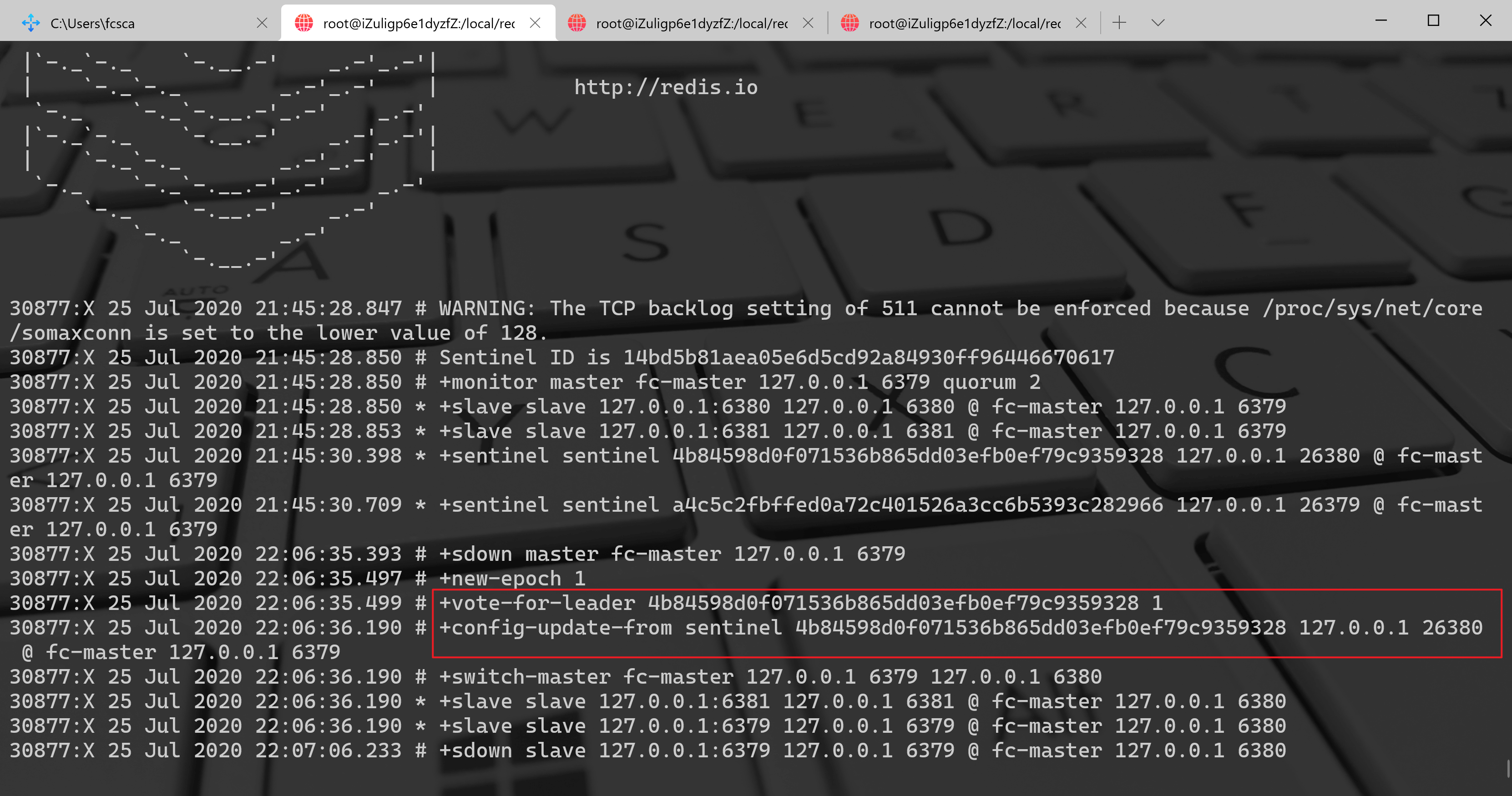
从这三个哨兵节点可以看出,三个哨兵节点都发现了主节点 6379 下线了,他们更新了自己的配置纪元(new-epoch),同时 26379、26381 投票给 26380,所以 26380 负责故障的转移工作,同时从 26380 的日志+odown master mymaster127.0.0.16379#quorum 2/2得知主节点 6379 已经达到了客观下线的条件了,其他两个陆续也会完成 6379 主节点的下线,如下:
按照日志的时间节点,可以得出 26380 最先完成客观下线,如下:--2637912951:X 05 Jun 2019 17:55:36.552 # +odown master mymaster 127.0.0.1 6379 #quorum 3/2--2638112969:X 05 Jun 2019 17:55:37.473 # +odown master mymaster 127.0.0.1 6379 #quorum 3/2
| 节点 | 下线时间 |
|---|---|
| 26379 | 17:55:36.552 # +odown master mymaster 127.0.0.1 6379 #quorum 3/2 |
| 26380 | 17:55:36.530 # +odown master mymaster 127.0.0.1 6379 #quorum 2/2 |
| 26381 | 17:55:37.473 # +odown master mymaster 127.0.0.1 6379 #quorum 3/2 |
继续看 26380 的日志:
12960:X 05 Jun 2019 17:55:36.530 # +try-failover master mymaster 127.0.0.1 637912960:X 05 Jun 2019 17:55:36.532 # +vote-for-leader 97fb37fc855e86a02eb446194cd4b1af6e2eef0c 112960:X 05 Jun 2019 17:55:36.536 # 0a16a0b3f348933c3dcc177239787ff47f735713 voted for 97fb37fc855e86a02eb446194cd4b1af6e2eef0c 112960:X 05 Jun 2019 17:55:36.536 # 742697f27e4d368be4ac2f204a3d1787cd3a96be voted for 97fb37fc855e86a02eb446194cd4b1af6e2eef0c 112960:X 05 Jun 2019 17:55:36.617 # +elected-leader master mymaster 127.0.0.1 6379
这段日志就已经表明了 26380 作为领导者来负责故障转移工作。
12960:X 05 Jun 2019 17:55:36.617 # +failover-state-select-slave master mymaster 127.0.0.1 6379
寻找合适的从节点作为新的主节点。
12960:X 05 Jun 2019 17:55:36.719 # +selected-slave slave 127.0.0.1:6381 127.0.0.1 6381 @ mymaster 127.0.0.1 6379
选择 6381 作为新的主节点。
12960:X 05 Jun 2019 17:55:36.719 * +failover-state-send-slaveof-noone slave 127.0.0.1:6381 127.0.0.1 6381 @ mymaster 127.0.0.1 6379
命令 6381 执行 slaveof no one 命令,使其变成主节点。
12960:X 05 Jun 2019 17:55:36.773 * +failover-state-wait-promotion slave 127.0.0.1:6381 127.0.0.1 6381 @ mymaster 127.0.0.1 637912960:X 05 Jun 2019 17:55:37.637 # +promoted-slave slave 127.0.0.1:6381 127.0.0.1 6381 @ mymaster 127.0.0.1 6379
等待和确认 6381 变成主节点。
12960:X 05 Jun 2019 17:55:37.638 # +failover-state-reconf-slaves master mymaster 127.0.0.1 6379
故障转移进入重新配置从节点阶段。
12960:X 05 Jun 2019 17:55:37.706 * +slave-reconf-sent slave 127.0.0.1:6380 127.0.0.1 6380 @ mymaster 127.0.0.1 6379
命令 6380 节点发送 slaveof 命令,复制新的主节点。
12960:X 05 Jun 2019 17:55:38.686 * +slave-reconf-inprog slave 127.0.0.1:6380 127.0.0.1 6380 @ mymaster 127.0.0.1 637912960:X 05 Jun 2019 17:55:38.686 * +slave-reconf-done slave 127.0.0.1:6380 127.0.0.1 6380 @ mymaster 127.0.0.1 6379
6380 节点完成对 6381 节点的复制。
12960:X 05 Jun 2019 17:55:38.762 # +failover-end master mymaster 127.0.0.1 6379
故障转移顺利完成。
12960:X 05 Jun 2019 17:55:38.762 # +switch-master mymaster 127.0.0.1 6379 127.0.0.1 6381
故障转移完成后,发布主节点的切换消息。
到这里整个故障转移工作已经完成了。
(3) 将 6379 启动,执行命令
redis-cli -p 6380 info replication,如下图:[root@iZuligp6e1dyzfZ bin]# redis-cli -p 6380127.0.0.1:6380> info replication# Replicationrole:masterconnected_slaves:2slave0:ip=127.0.0.1,port=6381,state=online,offset=589339,lag=1slave1:ip=127.0.0.1,port=6379,state=online,offset=589487,lag=0master_replid:0bff485534e847bc1f80a00f6fcbd8b182d106eamaster_replid2:85d3be79728fa8f8a231b718ed4d433364504f1cmaster_repl_offset:589487second_repl_offset:288776repl_backlog_active:1repl_backlog_size:1048576repl_backlog_first_byte_offset:1repl_backlog_histlen:589487
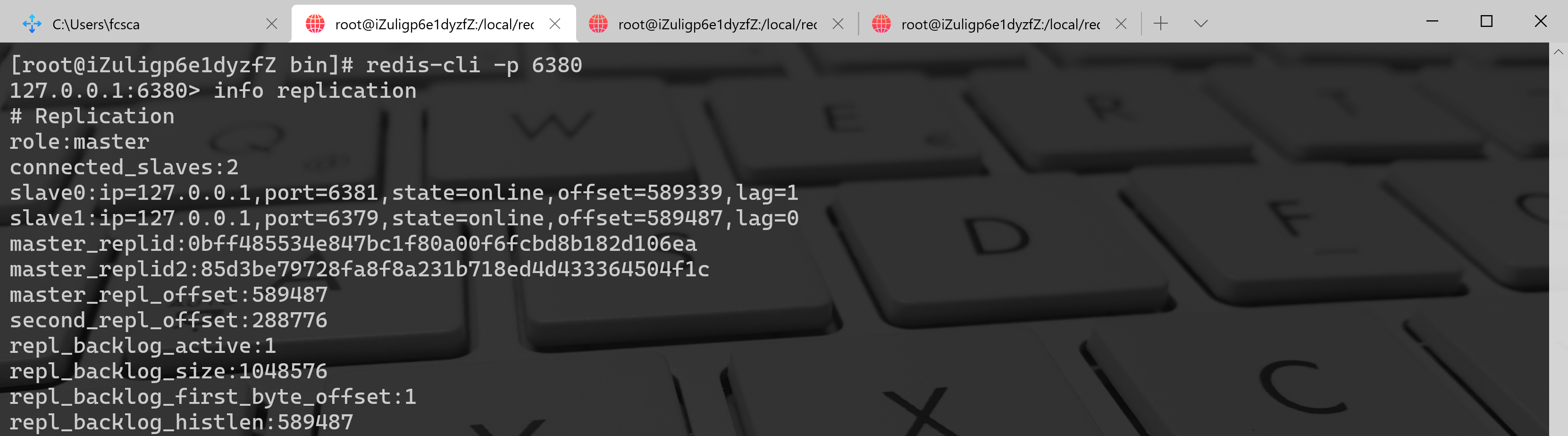
可以发现,6379 自动变成了 6380 的从节点(4)在故障转移阶段,哨兵和主从节点的配置文件都会被改写
哨兵节点的配置,监控主节点将会变成 6381,从节点有 6379、6381 两个节点,如下图: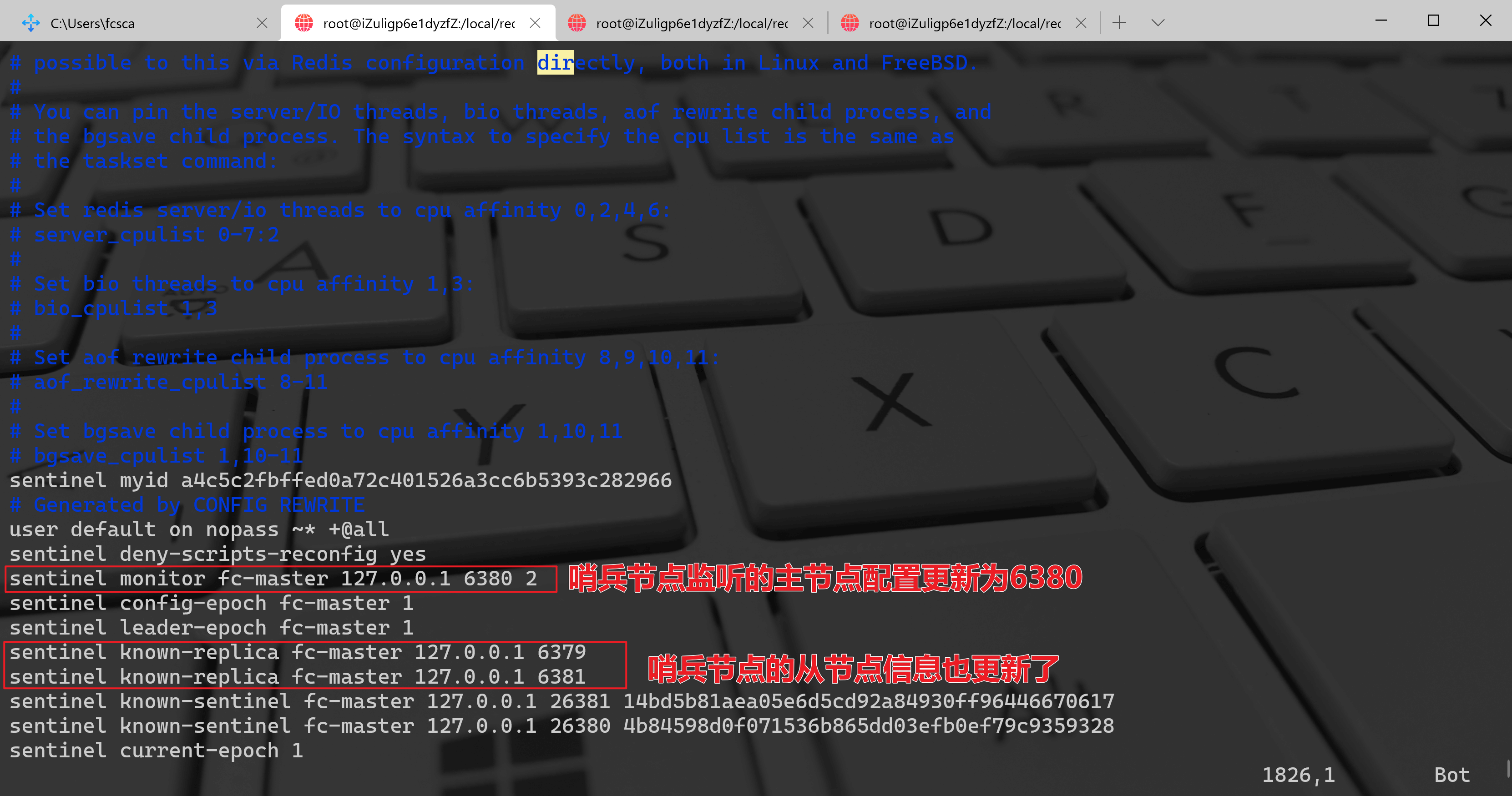
至于主从节点,会发现 6379、6380 的配置文件末尾多了一行 replicaof 127.0.0.1: 6380 :##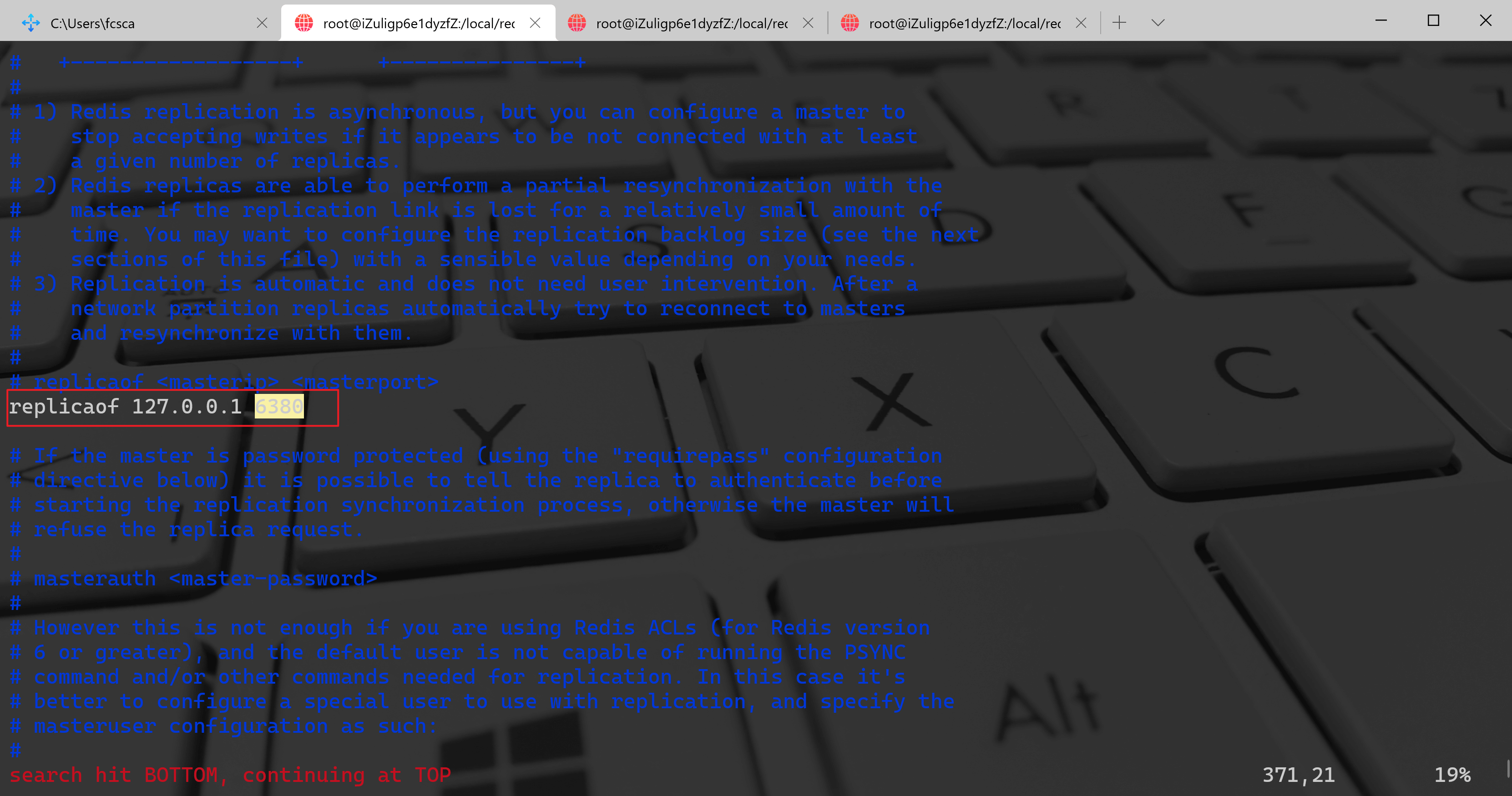

若有收获,就点个赞吧
0 人点赞
