SQL
给定如下模拟数据集,这也是SQL领域经典的学生成绩表问题。两张期望的数据表分别如下:
1)长表: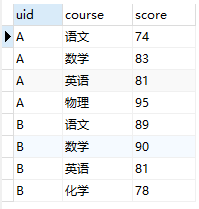
scoreLong
2)宽表: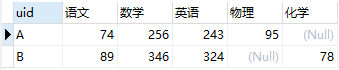
scoreWide
考察的问题就是通过SQL语句实现在这两种形态间转换,其中长表转为宽表即行转列,宽表转为长表即列转行。
1、行转列:sum+if
在行转列中,经典的解决方案是条件聚合,即sum+if组合。其基本的思路是这样的:
- 在长表的数据组织结构中,同一uid对应了多行,即每门课程一条记录,对应一组分数,而在宽表中需要将其变成同一uid下仅对应一行
- 在长表中,仅有一列记录了课程成绩,但在宽表中则每门课作为一列记录成绩
- 由多行变一行,那么直觉想到的就是要
groupby聚合;由一列变多列,那么就涉及到衍生提取; - 既然要用
groupby聚合,那么就涉及到将多门课的成绩汇总,但现在需要的不是所有成绩汇总,而仍然是各门课的独立成绩,所以需要用一个if函数加以筛选提取;当然,用case when也可以; - 在if筛选提取的基础上,针对不同课程设立不同的提取条件,并最终加一个聚合函数提取该列成绩即可。
按照这一思路,一句SQL实现行转列的写法如下:
SELECT uid, '语文' as course, `语文` as scoreFROM scoreWideWHERE `语文` IS NOT NULLUNIONSELECT uid, '数学' as course, `数学` as scoreFROM scoreWideWHERE `数学` IS NOT NULLUNIONSELECT uid, '英语' as course, `英语` as scoreFROM scoreWideWHERE `英语` IS NOT NULLUNIONSELECT uid, '物理' as course, `物理` as scoreFROM scoreWideWHERE `物理` IS NOT NULLUNIONSELECT uid, '化学' as course, `化学` as scoreFROM scoreWideWHERE `化学` IS NOT NULL
查询结果当然是预期的行转列后的结果: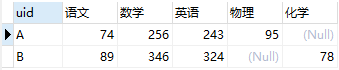
其中,if(course='语文', score, NULL)语句实现了当且仅当课程为语文时取值为课程成绩,否则取值为空,这相当于衍生了一个新的列字段,且对于每个uid而言,其所有成绩就只有特定课程的结果非空,其余均为空。这样,无论使用任何聚合函数,都可以得到该uid下指定课程的成绩结果。这里是用了sum函数,其实用min、max效果也是一样的,因为待聚合的数值中就只有那一个值非空。
2、列转行:union
列转行是上述过程的逆过程,所以其思路也比较直观:
- 行记录由一行变为多行,列字段由多列变为单列;
- 一行变多行需要复制,列字段由多列变单列相当于是堆积的过程,其实也可以看做是复制;
- 一行变多行,那么复制的最直观实现当然是使用
union,即分别针对每门课程提取一张衍生表,最后将所有课程的衍生表union到一起即可,其中需要注意字段的对齐
按照这一思路,给出SQL实现如下:
SELECT uid, '语文' as course, `语文` as scoreFROM scoreWideWHERE `语文` IS NOT NULLUNIONSELECT uid, '数学' as course, `数学` as scoreFROM scoreWideWHERE `数学` IS NOT NULLUNIONSELECT uid, '英语' as course, `英语` as scoreFROM scoreWideWHERE `英语` IS NOT NULLUNIONSELECT uid, '物理' as course, `物理` as scoreFROM scoreWideWHERE `物理` IS NOT NULLUNIONSELECT uid, '化学' as course, `化学` as scoreFROM scoreWideWHERE `化学` IS NOT NULL
查询结果当然是预期的长表。这里重点解释其中的三个细节:
- 在每个单门课的衍生表中,例如这句:
SELECT uid, '语文'as course,语文as score,用单引号包裹起来的课程名称是字符串常量,比如语文课的衍生表中的课程名都叫语文,然后将该列命名为course;第二个用反引号包裹起来的课程名实际上是从宽表中引用这一列的取值,然后将其命名为score。
这实际上对应的一个知识点是:在SQL中字符串的引用用单引号(其实双引号也可以),而列字段名称的引用则是用反引号
- 上述用到了
where条件过滤成绩为空值的记录,这实际是由于在原表中存在有空值的情况,如不加以过滤则在本例中最终查询记录有10条,其中两条记录的成绩字段为空 - 最后,本例中用
union关键字实现了多表的纵向拼接,实际上用union all更为合理,二者的区别是union会完成记录去重;而union all则简单的拼接,在确定不存在重复或无需去重的情况下其效率更高。

若有收获,就点个赞吧
0 人点赞
