Redis ziplist
Redis之所以那么快,还有一个很重要的一点,那就是Redis精心设计的数据结构,Redis另外一种底层数据结构: ziplist 。
在Redis中,有五种基本数据类型,除了 String,还有list,hash,zset,set,其中list,hash,zset都间接或者直接使用了ziplist,所以说理解ziplist也是相当重要的。
什么是压缩列表
ziplist 是为了节省内存而设计出来的一种数据结构。ziplist 是由一系列特殊编码组成的连续内存块的顺序型数据结构,一个 ziplist 可以包含任意多个 entry,而每一个 entry 又可以保存一个字节数组或者一个整数值。ziplist 作为一种列表,其和普通的双端列表,如 linkedlist 的最大区别就是 ziplist 并不存储前后节点的指针,而 linkedlist 一般每个节点都会维护一个指向前置节点和一个指向后置节点的指针。那么 ziplist 不维护前后节点的指针,它又是如何寻找前后节点的呢?ziplist 虽然不维护前后节点的指针,但是它却维护了上一个节点的长度和当前节点的长度,然后每次通过长度来计算出前后节点的位置。既然涉及到了计算,那么相对于直接存储指针的方式肯定有性能上的损耗,这就是一种典型的用时间来换取空间的做法。
因为每次读取前后节点都需要经过计算才能得到前后节点的位置,所以会消耗更多的时间,而在 Redis 中,一个指针是占了 8 个字节,但是大部分情况下,如果直接存储长度是达不到 8 个字节的,所以采用存储长度的设计方式在大部分场景下是可以节省内存空间的。
为什么要有ziplist
有两点原因:
- 普通的双向链表,会有两个指针,在存储数据很小的情况下,存储的实际数据的大小可能还没有指针占用的内存大,有点得不偿失。而且Redis是基于内存的,而且是常驻内存的,内存是弥足珍贵的,所以Redis的开发者们肯定要使出浑身解数优化占用内存,于是,ziplist出现了。
链表在内存中,一般是不连续的,遍历相对比较慢,而ziplist可以很好的解决这个问题。
来看看ziplist的存在
zadd programmings 1.0 go 2.0 python 3.0 java
创建了一个zset,里面有三个元素,然后看下它采用的数据结构:
debug object programmings"Value at:0x7f404ac30c60 refcount:1 encoding:ziplist serializedlength:36 lru:2689815 lru_seconds_idle:9"
HSET website google "www.g.cn"
创建了一个hash,只有一个元素,看下它采用的数据结构:
debug object website"Value at:0x7f404ac30ac0 refcount:1 encoding:ziplist serializedlength:30 lru:2690274 lru_seconds_idle:14"
可以很清楚的看到,zset和hash都采用了ziplist数据结构。
当满足一定的条件,zset和hash就不再使用ziplist数据结构了:debug object website"Value at:0x7f404ac30ac0 refcount:1 encoding:hashtable serializedlength:180 lru:2690810 lru_seconds_idle:2"
可以看到,hash的底层数据结构变成了hashtable。szet就不做实验了,感兴趣的小伙伴们可以自己实验下。至于这个转换条件是什么,放到后面再说。
尝试看下list的底层数据结构发现并不是ziplist:LPUSH languages pythondebug object languages"Value at:0x7f404c4763d0 refcount:1 encoding:quicklist serializedlength:21 lru:2691722 lru_seconds_idle:22 ql_nodes:1 ql_avg_node:1.00 ql_ziplist_max:-2 ql_compressed:0 ql_uncompressed_size:19"
可以看到,list采用的底层数据结构是quicklist,并不是ziplist。
在低版本的Redis中,list采用的底层数据结构是ziplist+linkedList,高版本的Redis中,quicklist替换了ziplist+linkedList,而quicklist也用到了ziplist,所以可以说list间接使用了ziplist数据结构。探究ziplist
ziplist源码:https://github.com/redis/redis/blob/unstable/src/ziplist.c
ziplist源码的注释写的非常清楚,如果英语比较好,可以直接看上面的注释。ziplist的存储结构
<zlbytes> <zltail> <zllen> <entry> <entry> ... <entry> <zlend>
其中
zlbytes,zltail,zllen为ziplist的head部分,entry为ziplist的entries部分,每一个entry代表一个数据,最后zlend表示ziplist的end部分,如下图所示: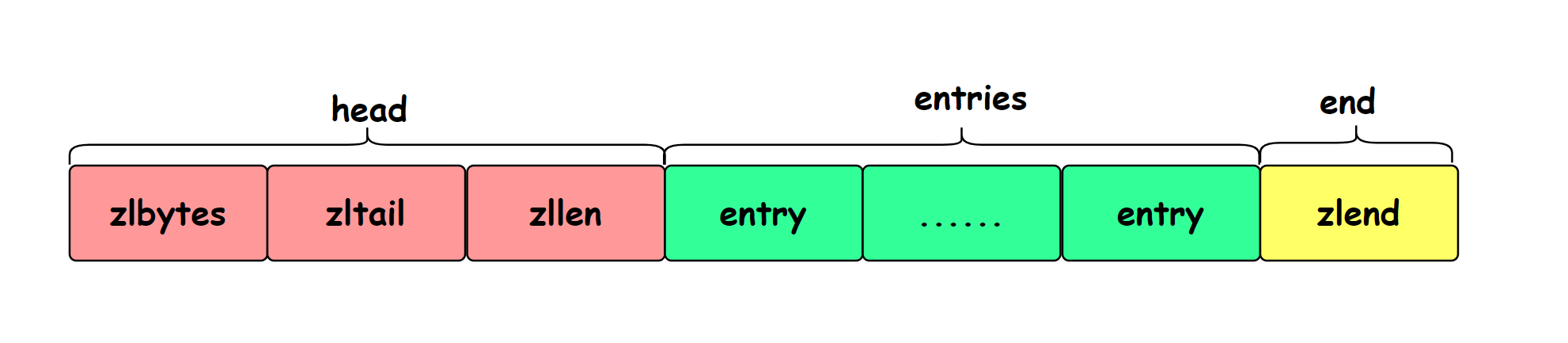
这是在注释中说明的ziplist布局,一个个来看,这些字段是什么:zlbytes:32bit无符号整数,表示ziplist占用的字节总数(包括本身占用的4个字节);
- zltail:32bit无符号整数,记录最后一个entry的偏移量,方便快速定位到最后一个entry;
- zllen:16bit无符号整数,记录entry的个数;
- entry:存储的若干个元素,可以为字节数组或者整数;
- zlend:ziplist最后一个字节,是一个结束的标记位,值固定为255。
具体见下表
| 属性 | 类型 | 长度 | 说明 |
|---|---|---|---|
| zlbytes | uint32_t | 4字节 | 记录压缩列表占用内存字节数(包括本身所占用的4个字节)。 |
| zltail | uint32_t | 4字节 | 记录压缩列表尾节点距离压缩列表的起始地址有多少个字节(通过这个值可以计算出尾节点的地址) |
| zllen | unint16_t | 2字节 | 记录压缩列表中包含的节点数量,当列表值超过可以存储的最大值( 65535 )时,此值固定存储65535(即2的16次方减1),因此此时需要遍历整个压缩列表才能计算出真实节点数。 |
| entry | 节点 | 压缩列表中的各个节点,长度由存储的实际数据决定。 | |
| zlend | unint8_t | 1字节 | 特殊字符0xFF(即十进制255 ),用来标记压缩列表的末端(其他正常的节点没有被标记为255的,因为255用来标识末尾,后面可以看到.正常节点都是标记为254 )。 |
Redis通过以下宏定义实现了对ziplist各个字段的存取:
// 假设char *zl 指向ziplist首地址// 指向zlbytes字段#define ZIPLIST_BYTES(zl) (*((uint32_t*)(zl)))// 指向zltail字段(zl+4)#define ZIPLIST_TAIL_OFFSET(zl) (*((uint32_t*)((zl)+sizeof(uint32_t))))// 指向zllen字段(zl+(4*2))#define ZIPLIST_LENGTH(zl) (*((uint16_t*)((zl)+sizeof(uint32_t)*2)))// 指向ziplist中尾元素的首地址#define ZIPLIST_ENTRY_TAIL(zl) ((zl)+intrev32ifbe(ZIPLIST_TAIL_OFFSET(zl)))// 指向zlend字段,指恒为255(0xFF)#define ZIPLIST_ENTRY_END(zl) ((zl)+intrev32ifbe(ZIPLIST_BYTES(zl))-1)
entry的构成
ziplist 的 head 和 end 存的都是长度和标记,而 entry 存储的是具体元素,这又是经过特殊的设计的一种存储格式,每个 entry 都以包含两段信息的元数据作为前缀,每一个 entry 的组成结构为:
<prevlen> <encoding> <entry-data>
再来看看这三个字段是什么:
- prevlen:前一个元素的字节长度,便于快速找到前一个元素的首地址,假如当前元素的首地址是x,那么(x-prevlen)就是前一个元素的首地址。
- encoding:当前元素的编码,这个字段实在是太复杂了,放到后面再说;
-
prevlen
prevlen属性存储了前一个entry的长度,通过此属性能够从后到前遍历列表。prevlen属性的长度可能是1字节也可能是5字节,prevlen字段是变长的: 前一个元素的长度小于254字节时,prevlen用1个字节表示;
<prevlen from 0 to 253> <encoding> <entry>
前一个元素的长度大于等于254字节时,prevlen用5个字节进行表示,此时,prevlen的第一个字节是固定的254(0xFE)(作为这种情况的一个标志),后面4个字节才表示前一个元素的长度。
0xFE <4 bytes unsigned little endian prevlen> <encoding> <entry>
:::danger 注意:
1个字节完全能存储255的大小,之所以只取到254是因为zlend就是固定的255,所以255这个数要用来判断是否是ziplist的结尾。 :::encoding
Redis为了节约空间,对encoding字段进行了相当复杂的设计,Redis通过encoding来判断存储数据的类型,下面就来看看Redis是如何根据encoding来判断存储数据的类型的:
encoding属性存储了当前entry所保存数据的类型以及长度。encoding长度为1字节,2字节或者5字节长。前面我们提到,每一个entry中可以保存字节数组和整数,而encoding属性的第1个字节就是用来确定当前entry存储的是整数还是字节数组。当存储整数时,第1个字节的前两位总是11,而存储字节数组时,则可能是00、01和10三种中的一种。
00xxxxxx最大长度位 63 的短字符串,后面的6个位存储字符串的位数;01xxxxxx xxxxxxxx中等长度的字符串,后面14个位来表示字符串的长度;10000000 aaaaaaaa bbbbbbbb cccccccc dddddddd特大字符串,需要使用额外 4 个字节来表示长度。第一个字节前缀是10,剩余 6 位没有使用,统一置为零;11000000表示 int16;11010000表示 int32;11100000表示 int64;11110000表示 int24;11111110表示 int8;11111111表示 ziplist 的结束,也就是 zlend 的值 0xFF;1111xxxx表示极小整数,xxxx 的范围只能是 (0001~1101), 也就是1~13。
如果是第10种情况,那么entry的构成就发生变化了:
<prevlen> <encoding>
因为数据已经存储在encoding字段中了。
可以看出Redis根据encoding字段的前两位来判断存储的数据是字符串(字节数组)还是整型,如果是字符串,还可以通过encoding字段的前两位来判断字符串的长度;如果是整形,则要通过后面的位来判断具体长度。
entry的结构体
在源码中可以看到entry的结构体,上面有一个注释非常重要:
/* We use this function to receive information about a ziplist entry.* Note that this is not how the data is actually encoded, is just what we* get filled by a function in order to operate more easily. */typedef struct zlentry {//存储prevrawlen所占用的字节数unsigned int prevrawlensize; /* Bytes used to encode the previous entry len*///存储上一个链表节点需要的字节数unsigned int prevrawlen; /* Previous entry len. *///存储len所占用的字节数unsigned int lensize; /* Bytes used to encode this entry type/len.For example strings have a 1, 2 or 5 bytesheader. Integers always use a single byte.*///存储链表当前节点的字节数unsigned int len; /* Bytes used to represent the actual entry.For strings this is just the string lengthwhile for integers it is 1, 2, 3, 4, 8 or0 (for 4 bit immediate) depending on thenumber range. *///当前链表节点的头部大小(prevrawlensize + lensize)即非数据域的大小unsigned int headersize; /* prevrawlensize + lensize. *///编码方式unsigned char encoding; /* Set to ZIP_STR_* or ZIP_INT_* depending onthe entry encoding. However for 4 bitsimmediate integers this can assume a rangeof values and must be range-checked. *///指向当前节点的起始位置(因为列表内的数据也是一个字符串对象)unsigned char *p; /* Pointer to the very start of the entry, thatis, this points to prev-entry-len field. */} zlentry;
重点看上面的注释。一句话解释:这个结构体虽然定义出来了,但是没有被使用,因为如果真的这么使用的话,那么entry占用的内存就太大了。
ziplist 数据示例
下面就是一个压缩列表的存储示例,这个压缩列表里面存储了 2 个节点,节点中存储的是整数 2 和 5:
[0f 00 00 00] [0c 00 00 00] [02 00] [00 f3] [02 f6] [ff]| | | | | |zlbytes zltail zllen "2" "5" end
- 第一组
4个字节为zlbytes部分,0f转成二进制就是1111也就是15,代表整个ziplist长度是15个字节。 - 第二组
4个字节zltail部分,0c转成二进制就是1100也就是12,这里记录的是压缩列表尾节点距离起始地址有多少个字节,也就是就是说[02 f6]这个尾节点距离起始位置有12个字节。 - 第三组
2个字节就是记录了当前ziplist中entry的数量,02转成二进制就是10,也就是说当前ziplist有2个节点。 - 第四组
2个字节[00 f3]就是第一个entry,00表示0,因为这是第1个节点,所以前一个节点长度为0,f3转成二进制就是11110011,刚好对应了表格中的编码1111xxxx,所以后面四位就是存储了一个0-12位的整数。0011转成十进制就是3,减去1得到2,所以第一个entry存储的数据就是2。 - 第五组
2个字节[02 f6]就是第二个entry,02即为2,表示前一个节点的长度为2,注意,因为这里算出来的结果是小于254,所以就代表了这里只用到了1个字节来存储上一个节点的长度(如果等于254,这说明接下来4个字节才存储的是长度),所以后面的f6就是当前节点的数据,转换成二进制为11110110,对应了表格中的编码1111xxxx,同样的后四位0110存储的是真实数据,计算之后得出是5。 - 最后一组1个字节[ff]转成二进制就是
11111111,代表这是整个ziplist的结尾。
假如这时候又添加了一个 Hello World 字符串到列表中,那么就会新增一个 entry,如下所示:
[02] [0b] [48 65 6c 6c 6f 20 57 6f 72 6c 64]
- 第一组的
1个字节02转成十进制就是2,表示前一个节点(即上面示例中的[02 f6])长度是2。 - 第 二组的
2个字节0b转成二进制为00001011,以00开头,符合编码00pppppp,而除掉最开始的两位00,计算之后得到十进制11,这就说明后面字节数组的长度是11。 - 第三组刚好是
11个字节,对应了上面的长度,所以这里就是真正存储了Hello World的字节数组。ziplist的存储形式
Redis并没有像上篇博客介绍的SDS一样,封装一个结构体来保存ziplist,而是通过定义一系列宏来对数据进行操作,也就是说ziplist是一堆字节数据,上面所说的ziplist的布局和ziplist中的entry的布局只是抽象出来的概念。为什么不能一直是ziplist
满足一定的条件后,zset、hash的底层存储结构不再是ziplist,既然ziplist那么强大,Redis的开发者也花了那么多精力在ziplist的设计上面,为什么zset、hash的底层存储结构不能一直是ziplist呢?
因为ziplist是紧凑存储,没有冗余空间,意味着新插入元素,就需要扩展内存,这就分为两种情况:
- 分配新的内存,将原数据拷贝到新内存;
- 扩展原有内存。
所以ziplist 不适合存储大型字符串,存储的元素也不宜过多。
ziplist存储界限
那么满足什么条件后,zset、hash的底层存储结构不再是ziplist呢?
在配置文件中可以进行设置:
hash-max-ziplist-entries 512 # hash 的元素个数超过 512 就必须用标准结构存储hash-max-ziplist-value 64 # hash 的任意元素的 key/value 的长度超过 64 就必须用标准结构存储zset-max-ziplist-entries 128 # zset 的元素个数超过 128 就必须用标准结构存储zset-max-ziplist-value 64 # zset 的任意元素的长度超过 64 就必须用标准结构存储
ziplist元素太多,怎么办
在介绍ziplist布局的时候,说到ziplist用两个位来记录ziplist的元素个数,如果元素个数实在太多,两个位不够怎么办呢?这种情况下,求ziplist元素的个数只能遍历了。
ziplist 连锁更新问题
上面提到 entry 中的 prevlen 属性可能是 1 个字节也可能是 5 个字节,那么来设想这么一种场景:假设一个 ziplist 中,连续多个 entry 的长度都是一个接近但是又不到 254 的值(介于 250~253 之间),那么这时候 ziplist 中每个节点都只用了 1 个字节来存储上一个节点的长度,假如这时候添加了一个新节点,如 entry1 ,其长度大于 254 个字节,此时 entry1 的下一个节点 entry2 的 prelen 属性就必须要由 1 个字节变为 5 个字节,也就是需要执行空间重分配,而此时 entry2 因为增加了 4 个字节,导致长度又大于 254 个字节了,那么它的下一个节点 entry3 的 prelen 属性也会被改变为 5 个字节。依此类推,这种产生连续多次空间重分配的现象就称之为连锁更新。同样的,不仅仅是新增节点,执行删除节点操作同样可能会发生连锁更新现象。
虽然 ziplist 可能会出现这种连锁更新的场景,但是一般如果只是发生在少数几个节点之间,那么并不会严重影响性能,而且这种场景发生的概率也比较低,所以实际使用时不用过于担心。

若有收获,就点个赞吧
0 人点赞
