索引的类型(常见的)
- 主键索引(primary key)主键索引,这个从刚开始接触开发的时候,就被各种灌输,表的主键就默认是索引,不允许出现空值。
- 普通索引(index/normal)MySQL中基本索引类型,没有什么限制,允许在定义索引的列中插入重复值和空值。
- 全文索引(fulltext)只能在文本类型CHAR,VARCHAR,TEXT类型字段上创建全文索引。MyISAM和InnoDB中都可以使用全文索引。
- 唯一索引(unique)索引列中的值必须是唯一的,但是允许为空值。
索引的类型肯定不限制于这几项,
既然知道分类了,接下来再来看看不同索引的创建方式
不同索引的创建方式
其实如果真的不会去写 SQL 去创建索引,最简单的,Navicat 图形化的界面操作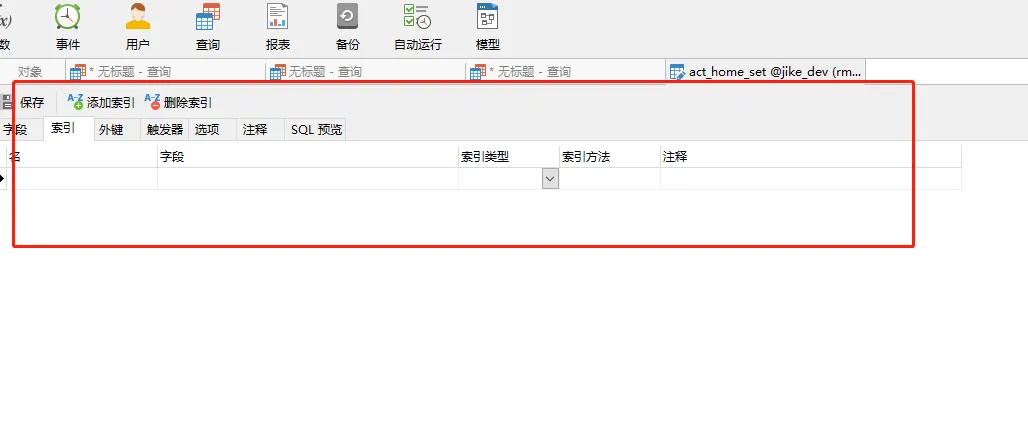
这样子操作是不是简单明了,选择想要创建索引的类型,然后指名想要创建索引的字段,最后再给他加上个注释,完美解决,但是还是要写语句来看一下的。
创建普通的索引
ALTER TABLE table_name ADD INDEX index_name (column)
比如有一张表叫做 user, 给 user 表中的一个叫做 phone 字段增加一个索引,应该怎么去写呢?
ALTER TABLE user ADD INDEX phoneIndex (phone)
这时候就创建好了一个索引了,索引的删除,相对来说也是非常的简单。其实说是创建索引,实际上就是给原有表中的某个字段上增加一个索引,这个大家一定得清楚,千万别和 Create 给搞混了。下面就直接简单的称之为创建。
ALTER TABLE testalter_tb1 DROP INDEX index_name
这样删除刚才建立的索引就是
ALTER TABLE user DROP INDEX phoneIndex
这时候就能看到删除成功了。
> OK> 时间: 0.012s
创建唯一索引(unique)并删除
ALTER TABLE user ADD unique phoneIndex (phone)ALTER TABLE user DROP INDEX phoneIndex;
千万不要想当然的认为创建的时候指定了索引的类型,然后删除的时候也执行一个
ALTER TABLE user DROP unique phoneIndex;
创建主键索引(primary key)并删除
ALTER TABLE user ADD PRIMARY KEY (phone):ALTER TABLE user DROP PRIMARY KEY
一般在建表的时候,都把这个主键索引都建好了,所以使用的场景并不是很多见。
创建全文索引(fulltext)并删除
创建方式都差不多就是这样
ALTER TABLE user ADD FULLTEXT phoneIndex (phone)ALTER TABLE user DROP INDEX phoneIndex;
既然了解了创建的方式了,该说为什么使用索引就会快,这就得涉及到索引的底层知识了,
索引的实现
在没有索引的情况下,查找数据只能按照从头到尾的顺序逐行查找,每查找一行数据,意味着要到到磁盘相应的位置去读取一条数据。
如果把查询一条数据分为到磁盘中查询和比对查询条件两步的话,到磁盘中查询的时间会远远大于比对查询条件的时间,这意味着在一次查询中,磁盘io占用了大部分的时间。更进一步地说,一次查询的效率取绝于磁盘io的次数,如果能够在一次查询中尽可能地降低磁盘io的次数,那么就能加快查询的速度。
所以就要开始引入索引,然后分析索引底层是如何实现查找迅速的。
实际上索引的底层实际上就是树,也就 B 树和 B+ 树,也可以称之为变种的 B+ 树。大家也都知道 Mysql中最常用的引擎像InnoDB和MyISAM,最终都选择了B+树作为索引
来说说这个B树和B+树。
B-树,也称为B树,是一种平衡的多叉树(可以对比一下平衡二叉查找树),它比较适用于对外查找
画一个二阶B树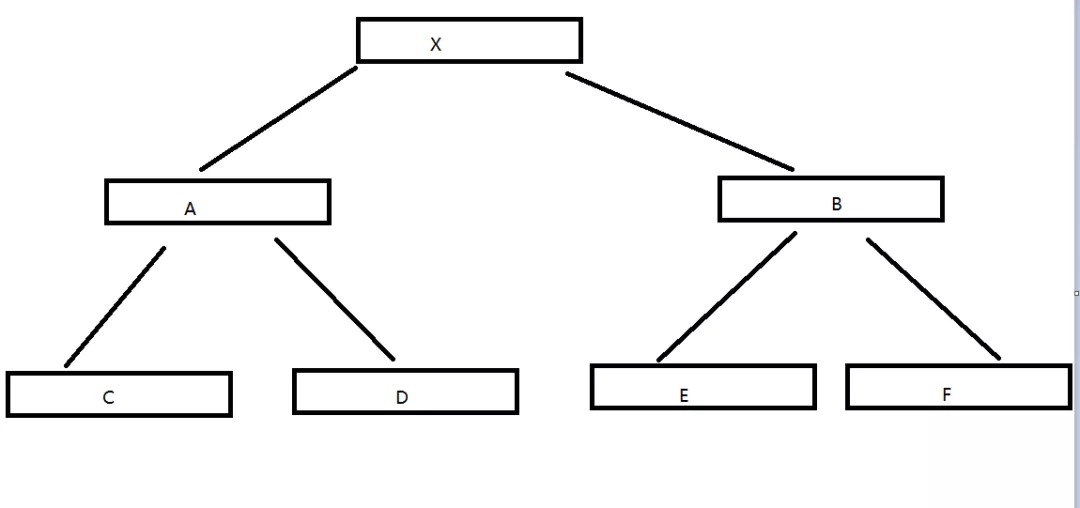
二阶B树
那么为什么称他为二阶 B 树呢?这个阶数实际上就是说一个 节点 最多有几个 子节点
上面的图,X元素,有2个子节点,A 元素,又有2个 子节点 C 和 D ,而 B 元素,又有 2 个子节点 E F ,也就是说一个节点最多有多少个子节点,就称它为几阶的树,通常这个值一般用 m 来表示。
注意我们所说的,也就是一个节点上 最多 的子节点数,如果有一个分支是有三个节点,而有一个是 两个节点 ,那就称它为 三阶 B 树。
一颗m阶的 B 树 要满足什么条件呢?
- 每个节点至多可以拥有m棵子树。
- 根节点,只有至少有2个节点(要么极端情况,就是一棵树就一个根节点,单细胞生物,即是根,也是叶,也是树)。
- 非根非叶的节点至少有的Ceil(m/2)个子树(Ceil表示向上取整,图中3阶B树,每个节点至少有2个子树,也就是至少有2个叉)。
- 非叶节点中的信息包括[n,A0,K1,A1,K2,A2,…,Kn,An],,其中n表示该节点中保存的关键字个数,K为关键字且Ki<Ki+1,A为指向子树根节点的指针。
- 从根到叶子的每一条路径都有相同的长度,也就是说,叶子节点在相同的层,并且这些节点不带信息,实际上这些节点就表示找不到指定的值,也就是指向这些节点的指针为空。
B树的查询过程和二叉排序树比较类似,从根节点依次比较每个节点,因为每个节点中的关键字和左右子树都是有序的,所以只要比较节点中的关键字,或者沿着指针就能很快地找到指定的关键字,如果查找失败,则会返回叶子节点,即空指针。
B树搜索的简单伪算法如下:
BTree_Search(node, key) {if(node == null) return null;foreach(node.key){if(node.key[i] == key) return node.data[i];if(node.key[i] > key) return BTree_Search(point[i]->node);}return BTree_Search(point[i+1]->node);}data = BTree_Search(root, my_key);
那么什么是 B+ 树呢?
B+ 树是一种树数据结构,是一个n叉树,每个节点通常有多个孩子,一颗B+树包含根节点、内部节点和叶子节点。根节点可能是一个叶子节点,也可能是一个包含两个或两个以上孩子节点的节点。
B+ 树通常用于数据库和操作系统的文件系统中。
NTFS, ReiserFS, NSS, XFS, JFS, ReFS 和BFS等文件系统都在使用B+树作为元数据索引。
B+ 树的特点是能够保持数据稳定有序,其插入与修改拥有较稳定的对数时间复杂度。
B+ 树元素自底向上插入。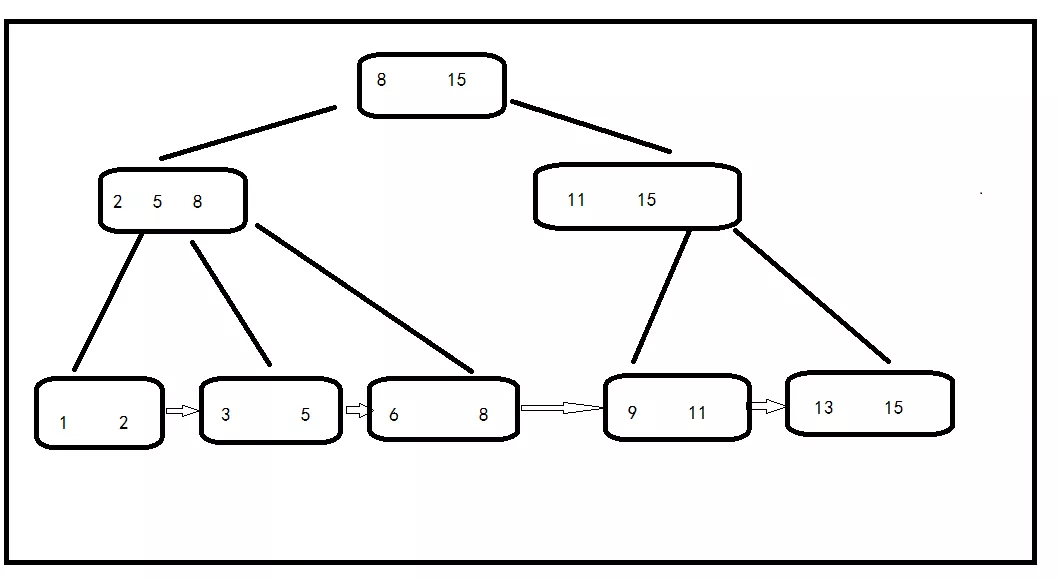
那 B+ 树又有哪些比较显著的特点呢?
- 每个父节点的元素都出现在了子节点中,分别是子节点最大或者最小的元素。
- 在上面的这一棵树中,根节点元素8是子节点258的最大的元素,根元素15也是。这时候要注意了,根节点最大的元素等同于整个B+树的最大的元素,以后无论是怎么插入或者是删除,始终都要保持最大的元素在根节点中。
- 叶子节点,因为父节点的元素都出现在了子节点当中,因此所有的叶子节点包含了全量的元素信息。
B+树与B树差异
有k个子节点的节点必然有k个元素
非叶子节点仅具有索引作用,跟记录有关的信息均存放在叶子节点中
树的所有叶子节点构成一个有序链表,可以按照元素排序的次序遍历全部记录
B树和B+树的区别在于,B+树的非叶子节点只包含导航信息,不包含实际的值,所有的叶子节点和相连的节点使用链表相连,便于区间查找和遍历。
说到这里,就会有读者开始想,说了半天,没有说到重点,为什么加了索引就快呢?
数据库读取数据,是从磁盘上通过 IO 来进行数据的操作,一次磁盘IO操作可以取出物理存储中相邻的一大片数据,如果查询的索引数据(就是B+树中从根节点一直到叶子节点整个过程中查询的节点数)都集中在该区域,那么只需要一次磁盘IO,否则就需要多次磁盘IO。
这么说是不是就相对的简单明了了。
再举出一个简单的例子:
比如想要查询 user 表中 name 为 xiaohong 的数据,在写 SQL 的时候
这时候没有索引的情况下,数据库直接就把整个表全部扫描一遍,然后去找select * from user where name = 'xiaohong'
name = 'xiaohong'的数据
而给他加上索引之后,会通过索引查找去查询名为 ‘xiaohong’ 的数据,因为该索引已经按照字母顺序排列,因此要查找名为 ‘xiaohong’ 的记录时会快很多。
明白了么?就像是一个词典,把 x 开头的数据都罗列出来,然后从 x 开头的数据中去寻找,和直接没有任何处理,直接一页一页的翻词典的速度,哪一个更快,相信大家也都明白了吧。

若有收获,就点个赞吧
0 人点赞
