构造函数
Array是 JavaScript 的内置对象,同时也是一个构造函数,可以用它生成新的数组。
var arr = new Array(2);// 等同于var arr = Array(2);
// 无参数时,返回一个空数组new Array() // []// 单个正整数参数,表示返回的新数组的长度new Array(1) // [ empty ]new Array(2) // [ empty x 2 ]// 非正整数的数值作为参数,会报错new Array(3.2) // RangeError: Invalid array lengthnew Array(-3) // RangeError: Invalid array length// 单个非数值(比如字符串、布尔值、对象等)作为参数,// 则该参数是返回的新数组的成员new Array('abc') // ['abc']new Array([1]) // [Array[1]]// 多参数时,所有参数都是返回的新数组的成员new Array(1, 2) // [1, 2]new Array('a', 'b', 'c') // ['a', 'b', 'c']
// badvar arr = new Array(1, 2);// goodvar arr = [1, 2];
静态方法
直接定义在构造函数上的方法和属性是静态的, 定义在构造函数的原型和实例上的方法和属性是非静态的(实例方法)
Array.isArray()
Array.isArray方法返回一个布尔值,表示参数是否为数组。它可以弥补typeof运算符的不足。
var arr = [1, 2, 3];typeof arr // "object"Array.isArray(arr) // true
上面代码中,typeof运算符只能显示数组的类型是Object,而Array.isArray方法可以识别数组。
Array 构造函数还有两个ES6新增的用于创建数组的静态方法:from() 和 of() 。
from() 用于将类数组结构转换为数组实例,而 of() 用于将一组参数转换为数组实例。
Array.form()
from() 用于将类数组结构转换为数组实例
Array.from() 的第一个参数是一个类数组对象,即任何可迭代的 结构,或者有一个 length 属性和可索引元素的结构。这种方式可用于很 多场合:


Array.from() 还接收第二个可选的映射函数参数。这个函数可以 直接增强新数组的值,而无须像调用Array.from().map() 那样先创建一个中间数组。还可以接收第三个可选参数,用于指定映射函数中 this 的值。但这个重写的 this 值在箭头函数中不适用。
Array.of()
Array.of() 可以把一组参数转换为数组。
这个方法用于替代在ES6 之前常用的Array.prototype.slice.call(arguments) ,一种异 常笨拙的将 arguments 对象转换为数组的写法:
console.log(Array.of(1, 2, 3, 4)); // [1, 2, 3, 4]console.log(Array.of(undefined)); // [undefined]
实例方法
- 数组的
valueOf方法返回数组本身 - 数组的
toString方法返回数组的字符串形式 - push() 向数组的末尾添加一个或更多元素,并返回新的长度
- pop() 删除并返回数组的最后一个元素
- unshift() 向数组的开头添加一个或更多元素,并返回新的长度
- shift() 删除并返回数组的第一个元素
- join()把数组的所有元素放入一个字符串。元素通过指定的分隔符进行分隔。
- concat() 连接两个或更多的数组
- slice(start,end) 从某个已有的数组返回选定的元素
- splice() 删除元素,并向数组添加新元素
- sort() 对数组的元素进行排序
- forEach()遍历数组中的每个元素 array.forEach(function(item, index, arr), thisValue)
valueOf()
valueOf方法是一个所有对象都拥有的方法,表示对该对象求值。
不同对象的valueOf方法不尽一致,数组的valueOf方法返回数组本身。
var arr = [1, 2, 3];arr.valueOf() // [1, 2, 3]
toString()
toString方法也是对象的通用方法,数组的toString方法返回数组的字符串形式。返回由数组中每个值的字符串形式拼接而成的一个以逗号分隔的字符串。相当于Array.join(',')
var arr = [1, 2, 3];arr.toString() // "1,2,3"var arr = [1, 2, 3, [4, 5, 6]];arr.toString() // "1,2,3,4,5,6"
栈方法
push()『 推入』
push方法用于在数组的末端添加一个或多个元素,并返回添加新元素后的数组长度。注意,该方法会改变原数组。
var arr = [];arr.push(1) // 1arr.push('a') // 2arr.push(true, {}) // 4arr // [1, 'a', true, {}]
pop()『 弹出』
pop方法用于删除数组的最后一个元素,并返回该元素。注意,该方法会改变原数组。如果数组已经为空,则pop()不改变数组,并返回undefined值
var arr = ['a', 'b', 'c'];arr.pop() // 'c'arr // ['a', 'b']
队列方法
shift() 『 移除』
shift()方法用于删除数组的第一个元素,并返回该元素。注意,该方法会改变原数组。
var a = ['a', 'b', 'c'];a.shift() // 'a'a // ['b', 'c']
上面代码中,使用shift()方法以后,原数组就变了。shift()方法可以遍历并清空一个数组。
var list = [1, 2, 3, 4];var item;while (item = list.shift()) {console.log(item);}list // []
上面代码通过list.shift()方法每次取出一个元素,从而遍历数组。它的前提是数组元素不能是0或任何布尔值等于false的元素,因此这样的遍历不是很可靠。push()和shift()结合使用,就构成了“先进先出”的队列结构(queue)。unshift()方法用于在数组的第一个位置添加元素,并返回添加新元素后的数组长度。注意,该方法会改变原数组。
var a = ['a', 'b', 'c'];a.unshift('x'); // 4a // ['x', 'a', 'b', 'c']
unshift()『添加』
unshift()方法可以接受多个参数,这些参数都会添加到目标数组头部。注意,该方法会改变原数组。
var arr = [ 'c', 'd' ];arr.unshift('a', 'b') // 4arr // [ 'a', 'b', 'c', 'd' ]
重排序方法
1.reverse()『 颠倒排列||反转』
reverse方法用于颠倒排列数组元素,返回改变后的数组。注意,该方法会改变原数组。
var a = ['a', 'b', 'c'];a.reverse() // ["c", "b", "a"]a // ["c", "b", "a"]
2.sort()『 字典顺序排序||自定义排序』
sort方法对数组成员进行排序,默认是按照字典顺序排序。排序后,原数组将被改变。
['d', 'c', 'b', 'a'].sort()// ['a', 'b', 'c', 'd'][4, 3, 2, 1].sort()// [1, 2, 3, 4][11, 101].sort()// [101, 11][10111, 1101, 111].sort()// [10111, 1101, 111]
上面代码的最后两个例子,需要特殊注意。sort()方法不是按照大小排序,而是按照字典顺序。也就是说,数值会被先转成字符串,再按照字典顺序进行比较,所以101排在11的前面。
如果想让sort方法按照自定义方式排序,可以传入一个函数作为参数。
[10111, 1101, 111].sort(function (a, b) {return a - b;})// [111, 1101, 10111]
上面代码中,sort的参数函数本身接受两个参数,表示进行比较的两个数组成员。如果该函数的返回值大于0,表示第一个成员排在第二个成员后面;
其他情况下,都是第一个元素排在第二个元素前面。
[{ name: "张三", age: 30 },{ name: "李四", age: 24 },{ name: "王五", age: 28 }].sort(function (o1, o2) {return o1.age - o2.age;})// [// { name: "李四", age: 24 },// { name: "王五", age: 28 },// { name: "张三", age: 30 }// ]
注意,自定义的排序函数应该返回数值,否则不同的浏览器可能有不同的实现,不能保证结果都一致。
// bad[1, 4, 2, 6, 0, 6, 2, 6].sort((a, b) => a > b)// good[1, 4, 2, 6, 0, 6, 2, 6].sort((a, b) => a - b)
上面代码中,前一种排序算法返回的是布尔值,这是不推荐使用的。后一种是数值,才是更好的写法。
操作方法
concat()『合并数组』
concat方法用于多个数组的合并。它将新数组的成员,添加到原数组成员的后部,然后返回一个新数组,原数组不变。
['hello'].concat(['world'])// ["hello", "world"]['hello'].concat(['world'], ['!'])// ["hello", "world", "!"][].concat({a: 1}, {b: 2})// [{ a: 1 }, { b: 2 }][2].concat({a: 1})// [2, {a: 1}]
除了数组作为参数,concat也接受其他类型的值作为参数,添加到目标数组尾部。
[1, 2, 3].concat(4, 5, 6)// [1, 2, 3, 4, 5, 6]
如果数组成员包括对象,concat方法返回当前数组的一个浅拷贝。所谓“浅拷贝”,指的是新数组拷贝的是对象的引用。
var obj = { a: 1 };var oldArray = [obj];var newArray = oldArray.concat();obj.a = 2;newArray[0].a // 2
上面代码中,原数组包含一个对象,concat方法生成的新数组包含这个对象的引用。所以,改变原对象以后,新数组跟着改变。
slice() 『提取 、切片』
slice方法用于提取目标数组的一部分,返回一个新数组,原数组不变。
arr.slice(start, end);
它的第一个参数为起始位置(从0开始),第二个参数为终止位置(但该位置的元素本身不包括在内)。如果省略第二个参数,则一直返回到原数组的最后一个成员。
var a = ['a', 'b', 'c'];a.slice(0) // ["a", "b", "c"]a.slice(1) // ["b", "c"]a.slice(1, 2) // ["b"]a.slice(2, 6) // ["c"]a.slice() // ["a", "b", "c"]
上面代码中,最后一个例子slice没有参数,实际上等于返回一个原数组的拷贝。
如果slice方法的参数是负数,则表示倒数计算的位置。
var a = ['a', 'b', 'c'];a.slice(-2) // ["b", "c"]a.slice(-2, -1) // ["b"]
上面代码中,-2表示倒数计算的第二个位置,-1表示倒数计算的第一个位置。
如果第一个参数大于等于数组长度,或者第二个参数小于第一个参数,则返回空数组。
var a = ['a', 'b', 'c'];a.slice(4) // []a.slice(2, 1) // []
**slice**方法的一个重要应用,是将类似数组的对象转为真正的数组。
Array.prototype.slice.call({ 0: 'a', 1: 'b', length: 2 })// ['a', 'b']Array.prototype.slice.call(document.querySelectorAll("div"));Array.prototype.slice.call(arguments);
上面代码的参数都不是数组,但是通过call方法,在它们上面调用slice方法,就可以把它们转为真正的数组。
splice() 任意位置删除、添加、替换原数组的一部分成员
splice方法用于删除原数组的一部分成员,并可以在删除的位置添加新的数组成员,返回值是被删除的元素。注意,该方法会改变原数组。
删除。需要给 splice() 传2个参数:要删除的第一个元素的位置和 要删除的元素数量。可以从数组中删除任意多个元素,比如 splice(0, 2) 会删除前两个元素。
插入。需要给 splice() 传3个参数:开始位置、0(要删除的元素 数量)和要插入的元素,可以在数组中指定的位置插入元素。第三个 参数之后还可以传第四个、第五个参数,乃至任意多个要插入的元 素。比如, splice(2, 0, “red” , “green”) 会从数组位置2开 始插入字符串 “red” 和 “green” 。
替换。 splice() 在删除元素的同时可以在指定位置插入新元素, 同样要传入3个参数:开始位置、要删除元素的数量和要插入的任意 多个元素。要插入的元素数量不一定跟删除的元素数量一致。比如, splice(2, 1, “red” , “green”) 会在位置2删除一个元素,然 后从该位置开始向数组中插入 “red” 和 “green” 。
arr.splice(start, count, addElement1, addElement2, ...);
splice的第一个参数是删除的起始位置(从0开始),第二个参数是被删除的元素个数。如果后面还有更多的参数,则表示这些就是要被插入数组的新元素。
var a = ['a', 'b', 'c', 'd', 'e', 'f'];a.splice(4, 2) // ["e", "f"]a // ["a", "b", "c", "d"]
上面代码从原数组4号位置,删除了两个数组成员。
var a = ['a', 'b', 'c', 'd', 'e', 'f'];a.splice(4, 2, 1, 2) // ["e", "f"]a // ["a", "b", "c", "d", 1, 2]
上面代码除了删除成员,还插入了两个新成员。
起始位置如果是负数,就表示从倒数位置开始删除。
var a = ['a', 'b', 'c', 'd', 'e', 'f'];a.splice(-4, 2) // ["c", "d"]
上面代码表示,从倒数第四个位置c开始删除两个成员。
如果只是单纯地插入元素,splice方法的第二个参数可以设为0。
var a = [1, 1, 1];a.splice(1, 0, 2) // []a // [1, 2, 1, 1]
如果只提供第一个参数,等同于将原数组在指定位置拆分成两个数组。
var a = [1, 2, 3, 4];a.splice(2) // [3, 4]a // [1, 2]
join()『数组转换成字符串』
join()方法以指定参数作为分隔符,将所有数组成员连接为一个字符串返回。如果不提供参数,默认用逗号分隔。
var a = [1, 2, 3, 4];a.join(' ') // '1 2 3 4'a.join(' | ') // "1 | 2 | 3 | 4"a.join() // "1,2,3,4"
如果数组成员是undefined或null或空位,会被转成空字符串。
[undefined, null].join('#')// '#'['a',, 'b'].join('-')// 'a--b'
通过call方法,这个方法也可以用于字符串或类似数组的对象。
Array.prototype.join.call('hello', '-')// "h-e-l-l-o"var obj = { 0: 'a', 1: 'b', length: 2 };Array.prototype.join.call(obj, '-')// 'a-b'
搜索和位置方法
1.严格模式
ECMAScript提供了3个严格相等的搜索方法: indexOf() 、 lastIndexOf() 和 includes() 。
其中,前两个方法在所有版本 中都可用,而第三个方法是ECMAScript 7新增的。
这些方法都接收两个参数:要查找的元素和一个可选的起始搜索位置。
indexOf() 和 lastIndexOf() 都返回要查找的元素在数组中的 位置,如果没找到则返回-1。 includes() 返回布尔值,表示是否 至少找到一个与指定元素匹配的项。
在比较第一个参数跟数组每一项 时,会使用全等( === )比较,也就是说两项必须严格相等。下面 来看一些例子:
let numbers = [1, 2, 3, 4, 5, 4, 3, 2, 1];alert(numbers.indexOf(4)); // 3alert(numbers.lastIndexOf(4)); // 5alert(numbers.includes(4)); // truealert(numbers.indexOf(4, 4)); // 5alert(numbers.lastIndexOf(4, 4)); // 3alert(numbers.includes(4, 7)); // falselet person = { name: "Nicholas" };let people = [{ name: "Nicholas" }];let morePeople = [person];alert(people.indexOf(person)); // -1alert(morePeople.indexOf(person)); // 0alert(people.includes(person)); // falsealert(morePeople.includes(person)); // true
indexOf() 第一次出现的位置
indexOf方法返回给定元素在数组中第一次出现的位置,如果没有出现则返回-1。
从数组开头开始查找
var a = ['a', 'b', 'c'];a.indexOf('b') // 1a.indexOf('y') // -1
indexOf方法还可以接受第二个参数,表示搜索的开始位置。
['a', 'b', 'c'].indexOf('a', 1) // -1
上面代码从1号位置开始搜索字符a,结果为-1,表示没有搜索到。
lastIndexOf() 最后出现的位置
lastIndexOf方法返回给定元素在数组中最后一次出现的位置,如果没有出现则返回-1。
从数组末尾开始查找,但是返回的位置还是从开头数起的位置
var a = [2, 5, 9, 2];a.lastIndexOf(2) // 3a.lastIndexOf(7) // -1
注意,这两个方法不能用来搜索NaN的位置,即它们无法确定数组成员是否包含NaN。
[NaN].indexOf(NaN) // -1[NaN].lastIndexOf(NaN) // -1
这是因为这两个方法内部,使用严格相等运算符(===)进行比较,而NaN是唯一一个不等于自身的值。
includes() 是否包含一个指定的值
ES7在ES6的基础上添加Array.prototype.includes()方法
includes() 方法用来判断一个数组是否包含一个指定的值,如果是返回 true,否则false
[1, 2, 3].indexOf(3) > -1 // true//等同于:[1, 2, 3].includes(3) // true
两者这都是通过===进行数据处理,但是对NaN数值的处理行为不同。includes对NaN的处理不会遵循严格模式去处理,所以返回true。indexOf会按照严格模式去处理,返回-1。
[1, 2, NaN].includes(NaN) // true[1, 2, NaN].indexOf(NaN) // -1
2.断言函数
ECMAScript也允许按照定义的断言函数搜索数组,每个索引都会调用 这个函数。断言函数的返回值决定了相应索引的元素是否被认为匹 配。
断言函数接收3个参数:元素、索引和数组本身。其中元素是数组中 当前搜索的元素,索引是当前元素的索引,而数组就是正在搜索的数 组。断言函数返回真值,表示是否匹配。
find() 和 findIndex() 方法使用了断言函数。这两个方法都从 数组的最小索引开始。
find() 返回第一个匹配的元素, findIndex() 返回第一个匹配元素的索引。
这两个方法也都接收第 二个可选的参数,用于指定断言函数内部 this 的值。
find() 返回第一个匹配的元素
const people = [{name: "Matt",age: 27},{name: "Nicholas",age: 29}];alert(people.find((element, index, array) => element.age < 28));// {name: "Matt", age: 27}alert(people.findIndex((element, index, array) => element.age < 28));// 0
findIndex() 返回第一个匹配元素的索引
at() 获取指定位置成员
Array.prototype.at()接收一个正整数或者负整数作为参数,表示获取指定位置的成员
参数正数就表示顺数第几个,负数表示倒数第几个,这可以很方便的获取某个数组末尾的元素
var arr = [1, 2, 3, 4, 5]// 以前获取最后一位console.log(arr[arr.length-1]) //5// 简化后console.log(arr.at(-1)) // 5
迭代方法
每个方法都接受两个参数:
- 在每一项上运行的函数
- 可选的,运行在该函数的作用域对象——影响
this的值 - 运行函数接受的参数:数组项的值
item、该项在数组中的位置index、数组对象本身arrayevery() 是否所有都符合条件
对数组中的每一项运行给定函数,如果该函数对每一项都返回 true,则返回 true
some() 是否有符合的条件的
对数组中的每一项运行给定函数,如果该函数对任一项返回 true,则返回 true
// key 存在时 value 不能为空,必须填写this.editBusinessData.attrLists.some((element, index) => {if (element.keySelected.key_name && !element.valueSelected.selected) {this.$message.warning(`第${index + 1}行属性value未填写`)//跳出循环 逐个提示return true}})
filter() 过滤掉不符合条件的
对数组中的每一项运行给定函数,返回运行函数时返回 true 的项组成的数组。该方法不会改变原始数组。
const options = res.rows.filter((item: any) => {return Number(item.keyCounts) > 0})
map() 运行结果组成的数组
对数组中的每一项运行给定函数,返回每次函数调用的结果组成的数组
// 修改 keylet json = res.data.data.data.map((item) => {return {备件编码: item.bom_id,备件名称: item.name,当前安全库存上限: item.stockupperlimit,当前安全库存下限: item.stockfloor,预测安全库存上限: item.forecast_limit,预测安全库存下限: item.forecast_floor,};});
forEach 遍历数组
语法
array.forEach(function(currentValue, index, arr), thisValue)
forEach()遍历数组中的每个元素;
第一个参数接收一个函数,必填;
第二个参数为传递给函数的值。
| 参数 | 描述 |
|---|---|
| function(currentValue, index, arr) | 必需。 数组中每个元素需要调用的函数。 |
函数参数描述:
currentValue
必需,当前元素。
index
可选,当前元素的索引值。
arr
可选,当前元素所属的数组对象。 |
| thisValue | 可选。传递给函数的值一般用 “this” 值。
如果这个参数为空, “undefined” 会传递给 “this” 值 |
有了for循环 为什么还要forEach?
js 中那么多循环,for for...in for...of forEach,有些循环感觉上是大同小异今天我们讨论下for循环和forEach的差异。我们从几个维度展开讨论:
for循环和forEach的本质区别。for循环和forEach的语法区别。for循环和forEach的性能区别。
本质区别
for循环是 js 提出时就有的循环方法。forEach是 ES5 提出的,挂载在可迭代对象原型上的方法,例如Array Set Map。forEach是一个迭代器,负责遍历可迭代对象。那么遍历,迭代,可迭代对象分别是什么呢。遍历:指的对数据结构的每一个成员进行有规律的且为一次访问的行为。迭代:迭代是递归的一种特殊形式,是迭代器提供的一种方法,默认情况下是按照一定顺序逐个访问数据结构成员。迭代也是一种遍历行为。可迭代对象:ES6 中引入了 iterable 类型,Array Set Map String arguments NodeList 都属于 iterable,他们特点就是都拥有 [Symbol.iterator] 方法,包含他的对象被认为是可迭代的 iterable。
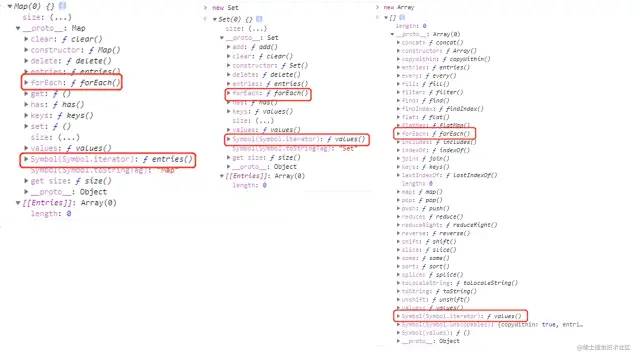
在了解这些后就知道 forEach 其实是一个迭代器,他与 for 循环本质上的区别是 forEach 是负责遍历(Array Set Map)可迭代对象的,而 for 循环是一种循环机制,只是能通过它遍历出数组。再来聊聊究竟什么是迭代器,还记得之前提到的 Generator 生成器,当它被调用时就会生成一个迭代器对象(Iterator Object),它有一个 .next()方法,每次调用返回一个对象{value:value,done:Boolean},value返回的是 yield 后的返回值,当 yield 结束,done 变为 true,通过不断调用并依次的迭代访问内部的值。迭代器是一种特殊对象。ES6 规范中它的标志是返回对象的 next() 方法,迭代行为判断在 done 之中。在不暴露内部表示的情况下,迭代器实现了遍历。
for循环和forEach的语法区别
了解了本质区别,在应用过程中,他们到底有什么语法区别呢?
forEach的参数。forEach的中断。forEach删除自身元素,index 不可被重置。for循环可以控制循环起点。
forEach 的中断
在 js 中有break return continue 对函数进行中断或跳出循环的操作,我们在 for循环中会用到一些中断行为,对于优化数组遍历查找是很好的,但由于forEach属于迭代器,只能按序依次遍历完成,所以不支持上述的中断行为。
let arr = [1, 2, 3, 4],i = 0,length = arr.length;for (; i < length; i++) {console.log(arr[i]); //1,2if (arr[i] === 2) {break;}}arr.forEach((self, index) => {console.log(self);if (self === 2) {break //报错}});arr.forEach((self, index) => {console.log(self);if (self === 2) {continue//报错}});
如果我一定要在 forEach 中跳出循环呢?其实是有办法的,借助try/catch:
try {var arr = [1, 2, 3, 4];arr.forEach(function (item, index) {//跳出条件if (item === 3) {throw new Error("LoopTerminates");} //do somethingconsole.log(item);});} catch (e) {if (e.message !== "LoopTerminates") throw e;}
若遇到 return 并不会报错,但是不会生效
let arr = [1, 2, 3, 4];function find(array, num) {array.forEach((self, index) => {if (self === num) {return index;}});}let index = find(arr, 2); // undefined复制代码
forEach 删除自身元素,index 不可被重置
在 forEach 中我们无法控制 index 的值,它只会无脑的自增直至大于数组的 length 跳出循环。所以也无法删除自身进行index重置,先看一个简单例子:
let arr = [1, 2, 3, 4];arr.forEach((item, index) => {console.log(item); // 1 2 3 4index++;});
index不会随着函数体内部对它的增减而发生变化。在实际开发中,遍历数组同时删除某项的操作十分常见,在使用forEach删除时要注意。
for 循环可以控制循环起点
如上文提到的 forEach 的循环起点只能为 0 不能进行人为干预,而for循环不同:
let arr = [1, 2, 3, 4],i = 1,length = arr.length;for (; i < length; i++) {console.log(arr[i]); // 2 3 4}
那之前的数组遍历并删除滋生的操作就可以写成
let arr = [1, 2, 1],i = 0,length = arr.length;for (; i < length; i++) {// 删除数组中所有的1if (arr[i] === 1) {arr.splice(i, 1); //重置i,否则i会跳一位i--;}}console.log(arr); // [2]//等价于var arr1 = arr.filter(index => index !== 1);console.log(arr1)
for循环和forEach的性能区别
在性能对比方面我们加入一个 map 迭代器,它与 filter 一样都是生成新数组。我们对比 for forEach map 的性能在浏览器环境中都是什么样的:性能比较:for > forEach > map 在 chrome 62 和 Node.js v9.1.0 环境下:for 循环比 forEach 快 1 倍,forEach 比 map 快 20% 左右。原因分析for:for 循环没有额外的函数调用栈和上下文,所以它的实现最为简单。forEach:对于 forEach 来说,它的函数签名中包含了参数和上下文,所以性能会低于 for 循环。map:map 最慢的原因是因为 map 会返回一个新的数组,数组的创建和赋值会导致分配内存空间,因此会带来较大的性能开销。如果将map嵌套在一个循环中,便会带来更多不必要的内存消耗。当大家使用迭代器遍历一个数组时,如果不需要返回一个新数组却使用 map 是违背设计初衷的。在我前端合作开发时见过很多人只是为了遍历数组而用 map 的:
let data = [];let data2 = [1, 2, 3];data2.map((item) => data.push(item));
迭代器方法
在ES6中, Array 的原型上暴露了3个用于检索数组内容的方法: keys() 、 values() 和 entries() 。 keys() 返回数组索引的迭 代器, values() 返回数组元素的迭代器,而 entries() 返回索引/值 对的迭代器:


keys()返回数组索引的迭 代器
values()返回数组元素的迭代器
entries()返回索引/值 对的迭代器
复制和填充方法
ES6新增了两个方法:批量复制方法 fill() ,以及填充数组方法 copyWithin() 。这两个方法的函数签名类似,都需要指定既有数组实 例上的一个范围,包含开始索引,不包含结束索引。使用这个方法创建的 数组不能缩放。
fill()
使用 fill() 方法可以向一个已有的数组中插入全部或部分相同的 值。注意,该方法会改变原数组。开始索引用于指定开始填充的位置,它是可选的。如果不提供结束索 引,则一直填充到数组末尾。负值索引从数组末尾开始计算。也可以将负 索引想象成数组长度加上它得到的一个正索引:


copyWithin()
copyWithin() 会按照指定范围浅复制数组中的 部分内容,然后将它们插入到指定索引开始的位置。注意,该方法会改变原数组。开始索引和结束索引 则与 fill() 使用同样的计算方法:
归并方法
ECMAScript5为数组提供了两个归并方法: reduce() 和 reduceRight() 。
这两个方法都会迭代数组的所有项,并在此基础上 构建一个最终返回值。
reduce() 方法从数组第一项开始遍历到最后一 项。而 reduceRight() 从最后一项开始遍历至第一项。
这两个方法都接收两个参数:对每一项都会运行的归并函数,以及可 选的以之为归并起点的初始值。
- 在每一项上调用的归并函数
- 可选的,作为归并基础的初始值
传给 reduce() 和 reduceRight() 的 函数接收4个参数:
- 前一个项的函数返回的值
prev - 当前项的值
cur - 项的索引
index - 数组对象
array
这个函数返回的任何值都会作为下一次调用同一个函数的第一个参数。如 果没有给这两个方法传入可选的第二个参数(作为归并起点值),则第一 次迭代将从数组的第二项开始,因此传给归并函数的第一个参数是数组的 第一项,第二个参数是数组的第二项。
reduce()
array.reduce 遍历并将当前次回调函数的返回值作为下一次回调函数执行的第一个参数。
从第一项开始遍历
var arr = [1, 2, 3, 4, 5];var sum = arr.reduce(function(prev, cur, index, array) {return prev + cur;});alert(sum); //15
第一次执行归并函数时, prev 是1, cur 是2。第二次执行时, prev 是3(1 + 2), cur 是3(数组第三项)。如此递进,直到把所有 项都遍历一次,最后返回归并结果。
reduceRight()
从最后一项开始遍历,与 reduce() 方法类似
let values = [1, 2, 3, 4, 5];let sum = values.reduceRight(function(prev, cur,index, array){return prev + cur;});alert(sum); // 15
在这里,第一次调用归并函数时 prev 是5,而 cur 是4。当然,最 终结果相同,因为归并操作都是简单的加法。
究竟是使用 reduce() 还是 reduceRight() ,只取决于遍历数组 元素的方向。除此之外,这两个方法没什么区别。
flat() 平展数组
ES2019引进平展数组新方法: Array.flat(),可以利用depth参数灵活控制数组层级的展平。
该**flat()**方法创建一个新数组,其中所有子数组元素都以递归方式连接到该数组中,直到达到指定的深度。
语法:
var newArray = arr.flat([depth]);
depth :可选的,指定嵌套数组结构应展平的深度级别。默认为1。
const arr1 = [1, 2, [3, 4]];arr1.flat();// [1, 2, 3, 4]const arr2 = [1, 2, [3, 4, [5, 6]]];arr2.flat();// [1, 2, 3, 4, [5, 6]]const arr3 = [1, 2, [3, 4, [5, 6]]];arr3.flat(2);// [1, 2, 3, 4, 5, 6]const arr4 = [1, 2, [3, 4, [5, 6, [7, 8, [9, 10]]]]];arr4.flat(Infinity);// [1, 2, 3, 4, 5, 6, 7, 8, 9, 10]
groupBy 对数组进行分类
假设我们有一个员工列表,其中每个员工都是一个具有 2 个属性的对象:name 和 age。
const people = [{ name: 'Alice', age: 21 },{ name: 'Max', age: 20 },{ name: 'Jane', age: 20 }];
现在,我们需要对其进行按 age 分类,最终实现输出结果如下:
const groupedPeople = {20: [{ name: 'Max', age: 20 },{ name: 'Jane', age: 20 }],21: [{ name: 'Alice', age: 21 }]}
通常的方法是使用 array.reduce(),reduce() 方法对数组中的每个元素按序执行一个由您提供的 reducer 函数,每一次运行 reducer 会将先前元素的计算结果作为参数传入,最后将其结果汇总为单个返回值。鉴于此,可以借其实现一个 groupBy 函数:
function groupBy(objectArray, property) {return objectArray.reduce(function (acc, obj) {let key = obj[property]if (!acc[key]) {acc[key] = []}acc[key].push(obj)return acc}, {})}const groupedPeople = groupBy(people, 'age')// groupedPeople is:// {// 20: [// { name: 'Max', age: 20 },// { name: 'Jane', age: 20 }// ],// 21: [// { name: 'Alice', age: 21 }// ]// }
为了简化我们的代码,数组又提供了一个新的方法来对数组按属性进行分类:Array.prototype.groupBy()。
const groupedPeople = people.groupBy(({ age }) => age)// groupedPeople is:// {// 20: [// { name: 'Max', age: 20 },// { name: 'Jane', age: 20 }// ],// 21: [// { name: 'Alice', age: 21 }// ]// }
同时也支持按条件自定义分类:
const groupedPeople = people.groupBy(({ age }) => age <= 20? 'a': 'b')// groupedPeople is:// {// 'a': [// { name: 'Max', age: 20 },// { name: 'Jane', age: 20 }// ],// 'b': [// { name: 'Alice', age: 21 }// ]// }

若有收获,就点个赞吧
0 人点赞
