*监督学习最常见的四种算法
在机器学习中,无监督学习(Unsupervised learning)就是聚类,事先不知道样本的类别,通过某种办法,把相似的样本放在一起归位一类;而监督型学习(Supervised learning)就是有训练样本,带有属性标签,也可以理解成样本有输入有输出。
所有的回归算法和分类算法都属于监督学习。回归(Regression)和分类(Classification)的算法区别在于输出变量的类型,定量输出称为回归,或者说是连续变量预测;定性输出称为分类,或者说是离散变量预测。
以下是一些常用的监督型学习方法。
一. K-近邻算法(k-Nearest Neighbors,KNN)
K-近邻是一种分类算法,其思路是:如果一个样本在特征空间中的k个最相似(即特征空间中最邻近)的样本中的大多数属于某一个类别,则该样本也属于这个类别。K通常是不大于20的整数。KNN算法中,所选择的邻居都是已经正确分类的对象。该方法在定类决策上只依据最邻近的一个或者几个样本的类别来决定待分样本所属的类别。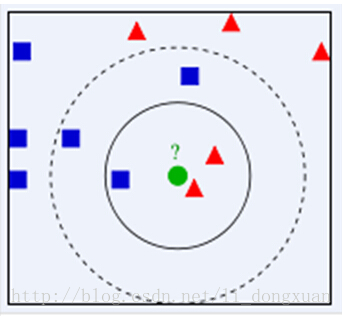
如上图,绿色圆要被决定赋予哪个类,是红色三角形还是蓝色四方形?如果K=3,由于红色三角形所占比例为2/3,绿色圆将被赋予红色三角形那个类,如果K=5,由于蓝色四方形比例为3/5,因此绿色圆被赋予蓝色四方形类。
算法的步骤为:
(1)计算测试数据与各个训练数据之间的距离;
(2)按照距离的递增关系进行排序;
(3)选取距离最小的K个点;
(4)确定前K个点所在类别的出现频率;
(5)返回前K个点中出现频率最高的类别作为测试数据的预测分类。
二. 决策树(Decision Trees)
决策树是一种常见的分类方法,其思想和“人类逐步分析比较然后作出结论”的过程十分相似。决策过程和下图类似。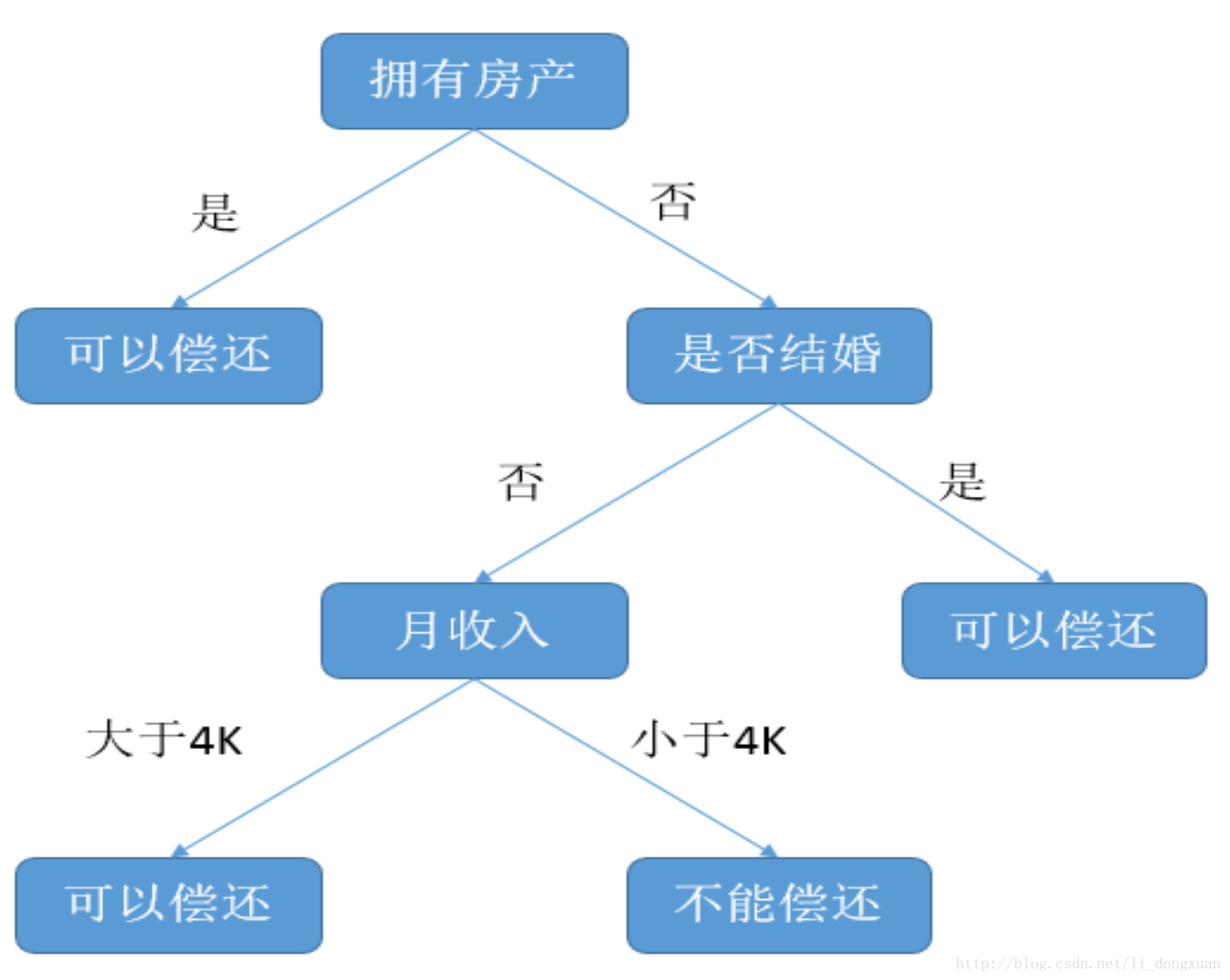
决策树是一个树结构(可以是二叉树或非二叉树)。其每个非叶节点表示一个特征属性上的测试,每个分支代表这个特征属性在某个值域上的输出,而每个叶节点存放一个类别。使用决策树进行决策的过程就是从根节点开始,测试待分类项中相应的特征属性,并按照其值选择输出分支,直到到达叶子节点,将叶子节点存放的类别作为决策结果。
不同于贝叶斯算法,决策树的构造过程不依赖领域知识,它使用属性选择度量来选择将元组最好地划分成不同的类的属性。所谓决策树的构造就是进行属性选择度量确定各个特征属性之间的拓扑结构。
那么如何划分数据呢?各个特征的优先级是怎么排的?常用的划分数据集方法有ID3和C4.5
(1) ID3算法
划分数据集的最大原则就是将数据变得更加有序。熵(entropy)是描述信息不确定性(杂乱程度)的一个值。设S是当前数据下的划分,那么S的信息熵的定义如下:
H(S)=−∑i=1np(xi)log2p(xi)
这里,n是类别的数目,p(xi)表示选择xi类别的概率(可用类别数量除以总数量估计)。
现在我们假设将S按属性A进行划分,则S的条件信息熵(A对S划分的期望信息)为:
H(S|A)=∑j=1mp(tj)H(tj)
这里,在属性A的条件下,数据被划分成m个类别(例如,属性A是体重,有轻、中、重三个选项,那么m=3),p(tj)表示类别tj(属性A中所有具有第j个特性的所有数据)的数量与S总数量的比值,H(tj)表示子类别tj的熵。
信息增益(Information gain)是指在划分数据集之前之后信息发生的变化,其定义如下:
IG(S,A)=H(S)−H(S|A)=H(S)−∑j=1mp(tj)H(tj)
在ID3算法里,每一次迭代过程中会计算所有剩余属性的信息增益,然后选择具有最大增益的属性对数据集进行划分,如此迭代,直至结束。这里有一个ID3算法的实例过程。
(2) C4.5算法
D3算法存在一个问题,就是偏向于多值属性,例如,如果存在唯一标识属性ID,则ID3会选择它作为分裂属性,这样虽然使得划分充分纯净,但这种划分对分类几乎毫无用处。ID3的后继算法C4.5使用增益率(gain ratio)的信息增益扩充,试图克服这个偏倚。严格上说C4.5是ID3的一个改进算法。
在按照ID3的中的方法得到了信息增益后,再定义分裂信息(Split Information):
SI(S,A)=−∑j=1m|tj||S|log2|tj||S|
然后定义增益率(Gain Ratio):
GR(S,A)=IG(S,A)SI(S,A)
C4.5选择增益率为分裂属性(连续属性要用增益率离散化)。C4.5算法有如下优点:产生的分类规则易于理解,准确率较高。其缺点是:在构造树的过程中,需要对数据集进行多次的顺序扫描和排序,因而导致算法的低效。此外,C4.5只适合于能够驻留于内存的数据集,当训练集大得无法在内存容纳时程序无法运行。
如果所有属性都作为分裂属性用光了,但有的子集还不是纯净集,即集合内的元素不属于同一类别。在这种情况下,由于没有更多信息可以使用了,一般对这些子集进行“多数表决”,即使用此子集中出现次数最多的类别作为此节点类别,然后将此节点作为叶子节点。
在实际构造决策树时,通常要进行剪枝,这时为了处理由于数据中的噪声和离群点导致的过分拟合问题。剪枝有两种:先剪枝——在构造过程中,当某个节点满足剪枝条件,则直接停止此分支的构造;后剪枝——先构造完成完整的决策树,再通过某些条件遍历树进行剪枝。悲观错误剪枝PEP算法是一种常见的事后剪枝策略。
三. 朴素贝叶斯(Naive Bayesian)
贝叶斯分类是一系列分类算法的总称,这类算法均以贝叶斯定理为基础,故统称为贝叶斯分类。朴素贝叶斯算法(Naive Bayesian) 是其中应用最为广泛的分类算法之一。朴素贝叶斯分类器基于一个简单的假定:给定目标值时属性之间相互条件独立。朴素贝叶斯的基本思想是对于给出的待分类项,求解在此项出现的条件下各个类别出现的概率,哪个最大,就认为此待分类项属于哪个类别。
首先给出条件概率的定义,P(A∥B)表示事件A在B发生下的条件概率,其公式为:
P(A|B)=P(AB)P(B)
贝叶斯定理用来描述两个条件概率之间的关系,贝叶斯定理公式为:
P(A|B)=P(B|A)P(A)P(B)
朴素贝叶斯分类算法的具体步骤如下:
(1)设x={a1,a2,…,am}为一个待分类项,a1,a2,…,am为x的m个特征属性;
(2)设有类别集合C={y1,y2,…,yn},即共有n个类别;
(3)依次计算x属于各项分类的条件概率,即计算P(y1∥x),P(y2∥x),… ,P(yn∥x):
P(y1|x)=P(x|y1)P(y1)P(x)=P(y1)P(x)∏i=1mP(ai|y1)
…
P(yn|x)=P(x|yn)P(yn)P(x)=P(yn)P(x)∏i=1mP(ai|yn)
注意,算法的下一步骤是对比这些结果的大小,由于各项分母都是P(x),所以分母不用计算。分子部分中P(yn)和P(ai∥yn)都是通过样本集统计而得,其中P(yn)的值为样本集中属于yn类的数量与样本总数量之比,P(ai∥yn)的值为yn类中满足属性ai的数量与yn类下样本总数量之比。
这样的计算方式符合特征属性是离散值的情况,如果特征属性是连续值时,通常假定其值服从高斯分布(也称正态分布),即g(x,η,σ)=12π√σe−(x−η)22σ2,那么P(ai∥yn)的值为:
P(ai|yn)=g(ai,ηyn,σyn)=12π−−√σyne−(x−ηyn)22σ2yn
其中,ηyn和σyn分别为训练样本yn类别中ai特征项划分的均值和标准差。
对于P(a∥y)=0的情况,当某个类别下某个特征项划分没有出现时,就是产生这种现象,这会令分类器质量大大降低。因此引入Laplace校准,对没类别下所有划分的计数加1,这样如果训练样本集数量充分大时,并不会对结果产生影响,也避免了乘积为0的情况。
(4)比较(3)中所有条件概率的大小,最大的即为预测分类结果,即:
P(yk|x)=max{P(y1|x),P(y2|x),…,P(yn|x)}
x∈yk
这里有一个朴素贝叶斯分类实例:检测SNS社区中不真实账号。
四. 逻辑回归(Logistic Regression)
我们知道,线性回归就是根据已知数据集求一线性函数,使其尽可能拟合数据,让损失函数最小,常用的线性回归最优法有最小二乘法和梯度下降法。而逻辑回归是一种非线性回归模型,相比于线性回归,它多了一个sigmoid函数(或称为Logistic函数)。逻辑回归是一种分类算法,主要用于二分类问题。逻辑回归的具体步骤如下:
(1)定义假设函数h(即hypothesis)
Sigmoid函数的图像是一个S型,预测函数就是将sigmoid函数g(x)里的自变量x替换成了边界函数θ(x),如下:
hθ(x)=g[θ(x)]=11+e−θ(x)
这里hθ(x)表示结果取1的概率,因此对于输入x分类结果为类别1和类别0的概率分别为:
P(y=1|x,θ)=hθ(x)
P(y=0|x,θ)=1−hθ(x)
(2)定义边界函数θ(x)
对于二维数据,如果是预设线性线性边界,那么边界函数为:
θ(x)=θ0+θ1x1+θ2x2
如果是预设非线性线性边界,那么边界函数为的形式就多了,例如:
θ(x)=θ0+θ1x1+θ2x2+θ3x21+θ4x22
假设我们现在要解决的是识别图片中的0或1(样本库只有0和1的图片),图片大小是20*20,那么这个时候有400个特征向量,那么边界函数为:
θ(x)=θ0+θ1x1+…+θ400x400
(3)构造损失函数(cost function,loss function)
损失函数的大小可以体现出边界函数的各项参数是否最优。对于线性回归,损失函数是欧式距离指标,但这样的Cost Function对于逻辑回归是不可行的,因为在逻辑回归中平方差损失函数是非凸,我们需要其他形式的Cost Function来保证逻辑回归的成本函数是凸函数。
我们选择对数似然损失函数:
Cost(hθ(x),y)={−loghθ(x), if y=1 −log(1−hθ(x)), if y=0
那么逻辑回归的Cost Function可以表示为:
J(θ)=1m∑i=1mCost(hθ(x(i)),y(i)) =−1m∑i=1m[y(i)loghθ(x(i))+(1−y(i))log(1−hθ(x(i)))]
这里m表示有m个样本,y是二值型数据,只能0或1,代表两种不同的类别。
(4)求最优θ
要想找到最合适的边界函数参数,只要使J(θ)最小即可。最优化的表达式为:
θ=argminθJ(θ)
与线性回归相似,可以采用梯度下降法寻优,也可以采用其他方法。

若有收获,就点个赞吧
0 人点赞
