简介: Feed流是一个目前非常常见的功能,在众多产品中都有展现,比如微博,朋友圈,消息广场,通知,IM等。通过Feed流可以把动态实时的传播给订阅者,是用户获取信息流的一种有效方式。在大数据时代,如何打造一个千万级规模的Feed流系统仍然是一个挑战。本文中会介绍如何设计一个千万量级的Feed流系统的架构。
在互联网领域,尤其现在的移动互联网时代,Feed流产品是非常常见的,比如我们每天都会用到的朋友圈,微博,就是一种非常典型的Feed流产品,还有图片分享网站Pinterest,花瓣网等又是另一种形式的Feed流产品。除此之外,很多App的都会有一个模块,要么叫动态,要么叫消息广场,这些也是Feed流产品,可以说,Feed流产品是遍布天下所有的App中。
概念
我们在讲如何设计Feed流系统之前,先来看一下Feed流中的一些概念:
- Feed:Feed流中的每一条状态或者消息都是Feed,比如朋友圈中的一个状态就是一个Feed,微博中的一条微博就是一个Feed。
- Feed流:持续更新并呈现给用户内容的信息流。每个人的朋友圈,微博关注页等等都是一个Feed流。
- Timeline:Timeline其实是一种Feed流的类型,微博,朋友圈都是Timeline类型的Feed流,但是由于Timeline类型出现最早,使用最广泛,最为人熟知,有时候也用Timeline来表示Feed流。
- 关注页Timeline:展示其他人Feed消息的页面,比如朋友圈,微博的首页等。
个人页Timeline:展示自己发送过的Feed消息的页面,比如微信中的相册,微博的个人页等。
特征
Feed流系统有一些非常典型的特点,比如:
多账号内容流:Feed流系统中肯定会存在成千上万的账号,账号之间可以关注,取关,加好友和拉黑等操作。只要满足这一条,那么就可以当做Feed流系统来设计。
- 非稳定的账号关系:由于存在关注,取关等操作,所以系统中的用户之间的关系就会一直在变化,是一种非稳定的状态。
- 读写比例100:1:读写严重不平衡,读多写少,一般读写比例在10:1,甚至100:1以上。
- 消息必达性要求高:比如发送了一条朋友圈后,结果部分朋友看到了,部分朋友没看到,如果偏偏女朋友没看到,那么可能会产生很严重的感情矛盾,后果很严重。
上面的就是Feed流产品的一些特点,下面我们来看一下Feed流系统的分类。
分类
Feed流的分类有很多种,但最常见的分类有两种:
- Timeline:按发布的时间顺序排序,先发布的先看到,后发布的排列在最顶端,类似于微信朋友圈,微博等。这也是一种最常见的形式。产品如果选择Timeline类型,那么就是认为
Feed流中的Feed不多,但是每个Feed都很重要,都需要用户看到。 - Rank:按某个非时间的因子排序,一般是按照用户的喜好度排序,用户最喜欢的排在最前面,次喜欢的排在后面。这种一般假定用户可能看到的Feed非常多,而用户花费在这里的时间有限,那么就为用户选择出用户最想看的Top N结果,场景的应用场景有图片分享、新闻推荐类、商品推荐等。
上面两种是最典型,也是最常见的分类方式,另外的话,也有其他的分类标准,在其他的分类标准中的话,会多出两种类型:
- Aggregate:聚合类型,比如好几个朋友都看了同一场电影,这个就可以聚合为一条Feed:A,B,C看了电影《你的名字》,这种聚合功能比较适合在客户端做。一般的Aggregate类型是Timeline类型 + 客户端聚合。
Notice:通知类型,这种其实已经是功能类型了,通知类型一般用于APP中的各种通知,私信等常见。这种也是Timeline类型,或者是Aggregate类型。
实现
上面介绍了Feed流系统的概念,特征以及分类,接下来开始进入关键部分:如何实现一个千万级Feed流系统。由于系统中的所有用户不可能全部在线,且不可能同时刷新和发布Feed,那么一个能支撑千万量级Feed流的系统,其实在产品上可以支撑上亿的用户。
如果要设计一个Feed流系统,最关键的两个核心,一个是存储,一个是推送。存储
我们先来看存储,Feed流系统中需要存储的内容分为两部分,一个是账号关系(比如关注列表),一种是Feed消息内容。不管是存储哪一种,都有几个问题需要考虑:
如何能支持100TB,甚至PB级数据量?
- 数据量大了后成本就很关键,成本如何能更便宜?
- 如何保证账号关系和Feed不丢失?
推送
推送系统需要的功能有两个,一个是发布Feed,一个是读取Feed流。对于提送系统,仍然有一些问题需要在选型之前考虑:
- 如何才能提供千万的TPS和QPS?
- 如何保证读写延迟在10ms,甚至2ms以下?
- 如何保证Feed的必达性?
再解答这些问题之前,我们先来大概了解下阿里云的表格存储TableStore。
TableStore
表格存储(TableStore)是阿里云自主研发的专业级分布式NoSQL数据库,是基于共享存储的高性能、低成本、易扩展、全托管的半结构化数据存储平台,
支撑互联网和物联网数据的高效计算与分析。
目前不管是阿里巴巴集团内部,还是外部公有云用户,都有成千上万的系统在使用。覆盖了重吞吐的离线应用,以及重稳定性,性能敏感的在线应用。目前使用的系统中,有些系统每秒写入行数超过3500万行,每秒流量超过5GB,单表总行数超过10万亿行,单表数据量超过10PB。
表格存储的具体的特性可以看下面这张图片。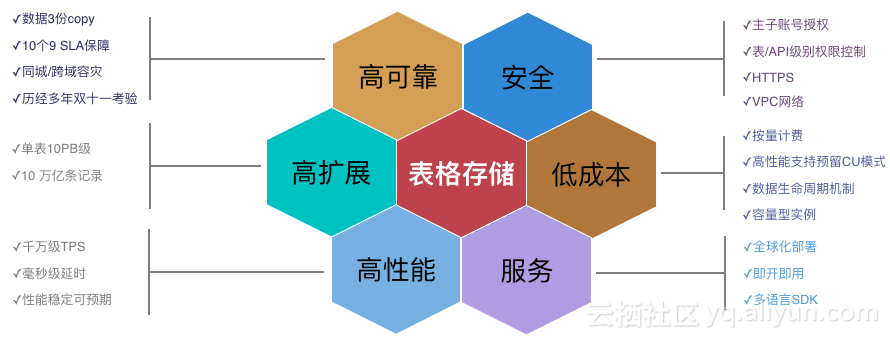
这里就不详细介绍表格存储(TableStore)的功能和特性了,有兴趣的话可以到官网页面和云栖博客了解,地址如下:
- 表格存储的官网地址:https://www.aliyun.com/product/ots/
- 表格存储云栖博客:https://yq.aliyun.com/teams/4/type_blog-cid_22
-
存储系统选择
我们接下来解决之前提出来的问题。
Feed流系统中需要存储的系统有两类,一类是账号关系(比如关注列表),一类是Feed消息。存储账号关系
我们先来看账号关系(比如关注列表)的存储,对于账号关系,它有一些特点:
是一系列的
变长链表,长度可达亿级别。- 这样就会导致
数据量比较大,但是关系极其简单。 - 还有一点是性能敏感,直接影响关注,取关的响应速度。
最适合存账号关系(关注列表)的系统应该是分布式NoSQL数据库,原因是数据量极大,关系简单不需要复杂的join,性能要求高。
对内设计实现简单,对外用户体验好。
除了上面这些特点外,还有一个特点:
有序性:有序性并不要求具有排序功能,只需要能按照主键排序就行,只要能按照主键排序,那么关注列表和粉丝列表的顺序就是固定的,可预期的。
使用开源HBase存储账号关系
能满足有序性的分布式NoSQL数据库中,开源HBase就是一个,所以很多企业会选择开源HBase来存储账号关系,或者是关注列表。
这样虽然满足了上述四个特征,可以把系统搭建起来,但是会有一些麻烦的问题:需要自己运维,调查问题,Fix bug,会带来较大的复杂度和成本开支。
-
使用表格存储(TableStore)存储账号关系
除此之外,阿里云的表格存储也属于有序性的分布式NoSQL数据库,之前有不少很有名的系统选择使用表格存储,在下面一些地方给系统带来了收益:
单表支持
10万亿行+,10PB+的数据量,再快的数据增长速度都不用担心。- 数据按
主键列排序,保证有序性和可预期性。 - 单key读写延迟在
毫秒级别,保证关注,取关的响应时间。 - 是
全托管的分布式NoSQL数据库服务,无需任何运维。 - 全部
采用C++实现,彻底无GC问题,也就不会由于GC而导致较大的毛刺。
使用表格存储(TableStore)来存储账号关系会是一个比较好的选择。
接下来看一下Feed消息的存储。
存储Feed消息
Feed消息有一个最大的特点:
- 数据量大,而且在Feed流系统里面很多时候都会选择写扩散(推模式)模式,这时候数据量会再膨胀几个数量级,所以这里的数据量很容易达到100TB,甚至PB级别。
除此之外,还有一些其他特点:
- 数据格式简单
- 数据不能丢失,可靠性要求高
- 自增主键功能,保证个人发的Feed的消息ID在个人发件箱中都是严格递增的,这样读取时只需要一个范围读取即可。由于个人发布的Feed并发度很低,这里用时间戳也能满足基本需求,但是当应用层队列堵塞,网络延迟变大或时间回退时,用时间戳还是无法保证严格递增。这里最好是有自增功能。
-
潜在的存储系统
根据上述这些特征,最佳的系统应该是
具有主键自增功能的分布式NoSQL数据库,但是在开源系统里面没有,所以常用的做法有两种: 关系型数据库 + 分库分表
关系型数据库 + 分布式NoSQL数据库:其中 关系型数据库提供主键自增功能。
使用关系型数据库存储Feed消息
目前业界有很多用户选择了关系系数据库+ 分库分表,包括了一些非常著名的Feed流产品,虽然这个架构可以运行起来,但是存在一些问题。
分库分表带来了
运维复杂性。- 分库分表带来了逻辑层和数据层的
极大耦合性。 - 关系型数据库,比如开源MySQL数据库的主键自增功能性能差。不管是用MyISAM,还是InnoDB引擎,要保证自增ID严格递增,必须使用表锁,这个粒度非常大,会严重限制并发度,影响性能。
有些用户觉得关系型数据库的可靠性高一些,但是关系型数据库的可靠性一般也就最多6个9,这个可靠性和分布式数据库完全不在一个层级,要低4到5个级别。
使用TableStore存储账号关系
基于上述原因,一些技术公司开始考虑使用表格存储(TableStore),表格存储是一个具有自增主键功能的分布式NoSQL数据库,这样就只需要使用一种系统,除此之外还有以下的考虑:
单表可达10PB,10万亿行。
10个9的SLA保障Feed内容不丢失。- 天然分布式数据库,
无需分库分表 - 两种实例类型:高性能实例采用全SSD存储媒介,提供极佳的读写性能。混合存储实例采用SSD+SATA存储媒介,提供极低的存储成本。
- 主键自增功能性能极佳,其他所有系统在做自增功能的时候都需要加锁,但是表格存储的主键自增功能在写入自增列行的时候,完全不需要锁,既不需要表锁,也不需要行锁。
从上面看,使用TableStore的话,不管是在功能,性能,扩展性还是成本方面都要更加适合一些。
看完推送系统选择后,我们再来看看推送方案的选择。
推送方案
我们先来回顾下之前说的Feed流系统最大的特点:
- 读写严重不平衡,读多写少,一般读写比例都在10;1,甚至100:1之上。
除此之外,还有一个方面会被推送方案影响:
发布, 刷新Feed时的延时本质上由
推送方案决定,其他的任何操作都只能是优化,质量量变,无法质变。推模式和拉模式对比
在推送方案里面的,有两种方案,分别是:
拉方案:也称为
读扩散。- 推方案:也成为
写扩散。
对于拉方案和推方案,他们在很多方面完全相反,在看对比之前有一点要强调下:
- 对Feed流产品的用户而言,刷新Feed流(读取)时候的延迟敏感度要远远大于发布(写入)的时候。 | | 拉模式(读扩散) | 推模式(写扩散) | | —- | :—- | :—- | | 发布 | 个人页Timeline(发件箱) | 粉丝的关注页(收件箱) | | 阅读 | 所有关注者的个人页Timeline | 自己的关注页Timeline | | 网络最大开销 | 用户刷新时 | 发布Feed时 | | 读写放大 | 放大读:读写比例到1万:1 | 放大写减少读:读写比例到50:50 | | 个性化 | 不支持 | 支持 | | 定向广告 | 不支持 | 支持 |
推模式的一个副作用
在上面的对比中可以明显看出来,推模式要远远比拉模式更好一些,但是也有一个副作用:
- 数据会极大膨胀。
针对这个缺点,可以从两个方面考虑:
- 目前的存储价格很低很低了,就以表格存储为例,容量型实例存储10TB的数据量,在现在(2017年10月)每年费用是1万六千元,以后价格会随着硬件技术升级,软件性能优化等继续降低。还有数据量越大价格越便宜。
想省点钱,那继续可以优化:
拉模式:
- 很多Feed流产品的第一版会采用这种方案,但很快就会抛弃。
- 另外,拉模式 + 图计算 就会是另一番天地,但是这个时候重心就是图计算了。
- 推模式:
- Feed流系统中最常用、有效的模式;
- 用户关系数比较均匀,或者有上限,比如朋友圈;
- 偏推荐类,同一个Feed对不同用户价值不同,需要为不同用户计算分数,比如pinterest。
- 推拉结合
- 大部分用户的账号关系都是几百个,但是有个别用户是1000万以上,比如微博。
推送系统
如果要实现一个千万量级的Feed流产品,那么推送系统需要具备一些特点:
- 具备千万TPS/QPS的能力。
- 读写链路延迟敏感,读写直接会影响用户发布,刷新Feed流时的延迟,尤其是极其敏感的刷新时的延迟。
- Feed消息的必达性要求很高。
- 主键自增功能,仍然是保证用户收件箱中的Feed ID是严格递增的,保证可以通过Scan(上次读取的最大ID —->MAX)读取到最新未读消息。
- 最好能为用户存储Timeline中所有的Feed。
从上述特点来看,需要的推送系统最好是一个性能极佳,又可靠的有自增功能的NoSQL系统,所以,业内一般如果选择开源系统的话,会在选择了关系型数据库作为存储系统的基础上,选择开源Redis,这样就能覆盖上述的几个特征,也能保证Feed流系统正常运行起来,但是也会带来一些其他问题:
- 纯内存系统,内存价格极高,整体成本就比较高了。
- 属于单机系统,为了支持千万TPS和保证消息必达性,需要使用cluster和replica模式,结果就是不仅带来了运维的复杂性,而且带来了成本的机器增加,成本再次上升。
- 成本上升了以后,就有架构师开始考虑是否可以节省一些成本,要节省成本只能是减少开源Redis里面存储的数据量,一般有两种做法,这两种做法都能减少存入Redis中的数据量:
- 只在开源Redis中存储Feed ID,不存储Feed内容。整体数据量会大量减少,但是在读取的时候需要先读Feed ID,然后在到存储系统里面去读取Feed内容,网络开销增长了一倍,而且是串行的,对用户的刷新延迟有较大影响。
- 只对普通用户或者活跃用户使用推模式,对大V和非活跃用户直接使用拉模式。
上述两个方案虽然可以节省成本,但是是以牺牲用户体验为代价的,最终需要在成本和用户体验之间权衡。
使用TableStore作为推送系统
除了使用开源系统外,还可以使用阿里云的表格存储(TableStore),有不少用户选择TableStore作为推送系统的原因无非下面几点:
- 天然分布式,单表可支持千万级TPS/QPS。
- LSM存储引擎极大
优化写,高性能实例极大优化读。 - 写入成功即保证落盘成功,数据可靠性提供10个9的SLA保障。
- 磁盘性数据库,费用比内存性的要低几个量级。
- 单表可存储十万亿行以上的数据,价格又低,轻松保存用户Feed流中的所有Feed数据。
上面说了使用开源Redis和阿里云TableStore的异同,如果使用开源可以用Redis,如果选择阿里云自研NoSQL数据库,可以使用TableStore。
架构图
下面我们来看一下使用TableStore的架构图,这里为了通用性,选用推拉结合的方式,推模式更加简单。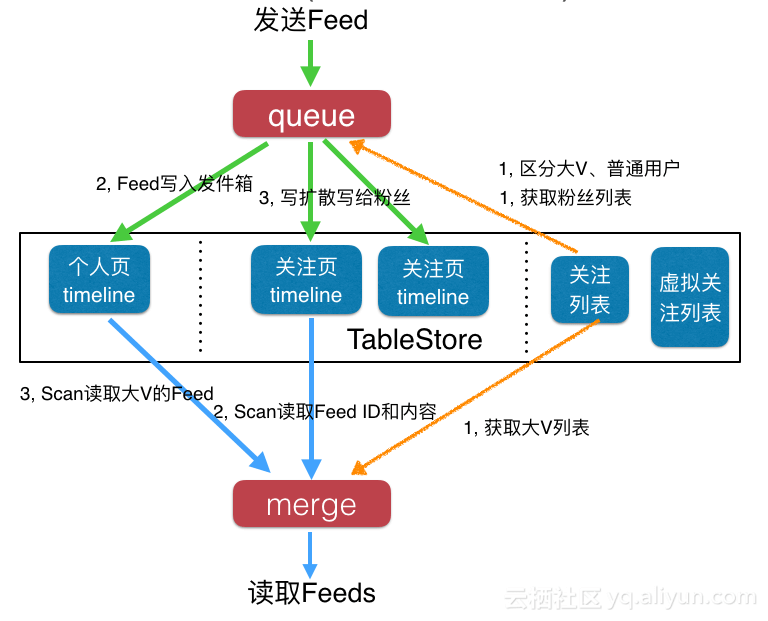
存储
我们先来看中间黑色框中的部分,这部分是使用TableStore的数据,从左往右分别是:
- 个人页Timeline:这个是每个用户的发件箱,也就是自己的个人页页面。
- 关注页Timeline:这个是每个用户的收件箱,也就是自己的关注页页面,内容都是自己关注人发布的消息。
- 关注列表:保存账号关系,比如朋友圈中的好友关系;微博中的关注列表等。
- 虚拟关注列表:这个主要用来个性化和广告。
发布Feed流程
当你发布一条Feed消息的时候,流程是这样的:
- Feed消息先进入一个队列服务。
- 先从关注列表中读取到自己的粉丝列表,以及判断自己是否是大V。
- 将自己的Feed消息写入个人页Timeline(发件箱)。如果是大V,写入流程到此就结束了。
- 如果是普通用户,还需要将自己的Feed消息写给自己的粉丝,如果有100个粉丝,那么就要写给100个用户,包括Feed内容和Feed ID。
- 第三步和第四步可以合并在一起,使用BatchWriteRow接口一次性将多行数据写入TableStore。
-
读取Feed流流程
当刷新自己的Feed流的时候,流程是这样的:
先去读取自己关注的大V列表
- 去读取自己的收件箱,只需要一个GetRange读取一个范围即可,范围起始位置是上次读取到的最新Feed的ID,结束位置可以使当前时间,也可以是MAX,建议是MAX值。由于之前使用了主键自增功能,所以这里可以使用GetRange读取。
- 如果有关注的大V,则再次并发读取每一个大V的发件箱,如果关注了10个大V,那么则需要10次访问。
- 合并2和3步的结果,然后按时间排序,返回给用户。
至此,使用推拉结合方式的发布,读取Feed流的流程都结束了。
更简单的推模式
如果只是用推模式了,则会更加简单:
- 发布Feed:
- 不用区分是否大V,所有用户的流程都一样,都是三步。
- 读取Feed流:
- 通过用户特征分析对用户分类,比如其中有一类是新生类:今年刚上大学的新生。(具体的用户特征分析可以依靠TableStore + MaxCompute,这里就不说了)。
- 创建一个广告账号:新生广告
- 让这些具有新生特征的用户虚拟关注新生广告账号。用户看不到这一层关注关系。
- 从七月份开始就可以通过新生广告账号发送广告了。
- 最终,每个用户可能会有多个特征,那么就可能虚拟关注多个广告账号。
上面是定向广告的一种比较简单的实现方式,其他方式就不再赘述了。
收益
上面我们详细说了使用TableStore作为存储和推送系统的架构,接下来我们看看新架构能给我们带来多大收益。
- 只使用1种系统,架构、实现简单。不再需要访问多个系统,架构,开发,测试,运维都能节省大力人力时间。
- TableStore 主键自增列功能性能极优。由于架构的不同,不仅不需要表锁,行锁也不需要,所以性能要远远好于关系型数据库。
- 可以保存所有的Feed。一是系统可以支持存储所有Feed,二是价格便宜,存的起。
- 无须将Feed ID和内容分开存储。价格便宜,也就不需要再分开存储ID和内容了。
- 全托管服务,无运维操作,更无需分库分表。
- 磁盘型(SSD、Hybrid)数据库,成本低。
- 可靠性10个9,数据更可靠,更不易丢失。
大V和普通用户的切分阈值更高,读取大V的次数更少,整体延时更低。
一个设计缺陷
如果使用大V/普通用户的切分方式,大V使用拉模式,普通用户使用推模式,那么这种架构就会存在一种很大的风险。
比如某个大V突然发了一个很有话题性的Feed,那么就有可能导致整个Feed产品中的所有用户都没法读取新内容了,原因是这样的:大V发送Feed消息。
- 大V,使用拉模式。
- 大V的活跃粉丝(用户群A)开始通过拉模式(架构图中读取的步骤3,简称读3)读取大V的新Feed。
- Feed内容太有话题性了,快速传播。
- 未登录的大V粉丝(用户群B)开始登陆产品,登陆进去后自动刷新,再次通过读3步骤读取大V的Feed内容。
- 非粉丝(用户群C)去大V的个人页Timeline里面去围观,再次需要读取大V个人的Timeline,同读3.
结果就是,平时正常流量只有用户群A,结果现在却是用户群A + 用户群B+ 用户群C,流量增加了好几倍,甚至几十倍,导致读3路径的服务模块被打到server busy或者机器资源被打满,导致读取大V的读3路径无法返回请求,如果Feed产品中的用户都有关注大V,那么基本上所有用户都会卡死在读取大V的读3路径上,然后就没法刷新了。
所以这里设计的时候就需要重点关心下面两点:
- 单个模块的不可用,不应该阻止整个关键的读Feed流路径,如果大V的无法读取,但是普通用户的要能返回,等服务恢复后,再补齐大V的内容即可。
- 当模块无法承受这么大流量的时候,模块不应该完全不可服务,而应该能继续提供最大的服务能力,超过的拒绝掉。
那么如何优化呢?
- 不使用大V/普通用户的优化方式,使用活跃用户/非活跃用户的优化方式。这样的话,就能把用户群A和部分用户群B分流到其他更分散的多个路径上去。而且,就算读3路径不可用,仍然对活跃用户无任何影响。
完全使用推模式就可以彻底解决这个问题,但是会带来存储量增大,大V微博发送总时间增大,从发给第一个粉丝到发给最后一个粉丝可能要几分钟时间(一亿粉丝,100万行每秒,需要100秒),还要为最大并发预留好资源,如果使用表格存储,因为是云服务,则不需要考虑预留最大额度资源的问题。
实践
接下来我们来实现一个消息广场的功能。很多App中都有动态或消息广场的功能,在消息广场中一般有两个Tab,一个是关注人,一个是广场,我们这里重点来看关注人。
要实现的功能如下:用户之间可以相互关注
- 用户可以发布新消息
- 用户可以查看自己发布的消息列表
- 用户可以查看自己关注的人的消息
采取前面的方案:
- 使用TableStore作为存储和推送系统
- 采用Timeline的显示方式,希望用户可以认真看每条Feed
-
角色
接着,我们看看角色和每个角色需要的功能:
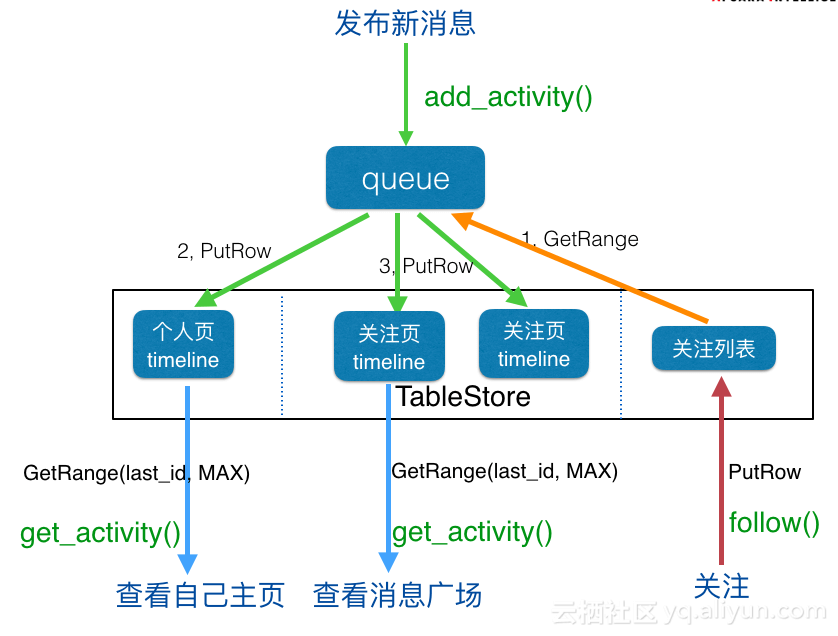
发送者
- 发送状态:add_activity()
- 接收者
- 关注:follow()
- 读取Feed流:get_activity()
Feed消息中至少需要包括下面内容:
消息:
发布新消息
- 接口:add_activity()
- 实现:
- get_range接口调用关注列表,返回粉丝列表。
- batch_write_row接口将feed内容和ID批量写入个人页表(发件箱)和所有粉丝的关注页表(收件箱),如果量太大,可以多次写入。或者调用异步batch_write_row接口,目前C++ SDK和JAVA SDK提供异步接口。
- 关注
- 接口:follow()
- 实现:
- put_row接口直接写入一行数据(关注人,粉丝)到关注列表和粉丝列表(粉丝,关注人)即可。
获取Feed流消息
- 接口:get_activity()
- 实现:
- 从客户端获取上次读取到的最新消息的ID:last_id
- 使用get_range接口读取最新的消息,起始位置是last_id,结束位置是MAX。
- 如果是读取个人页的内容,访问个人页表即可。如果是读取关注页的内容,访问关注页表即可。
计划
上面展示了如何使用表格存储TableStore的API来实现。这个虽然只用到几个接口,但是仍然需要学习表格存储的API和特性,还是有点费时间。
为了更加易用性,我们接下来会提供Feeds流完整解决方案,提供一个LIB,接口直接是add_activity(),follow()和get_activity()类似的接口,使用上会更加简单和快捷。扩展
前面讲述的都是Timeline类型的Feed流类型,但是还有一种Feed流类型比较常见,那就是新闻推荐,图片分享网站常用的Rank类型。
我们再来回顾下Rank类型擅长的领域:
潜在Feed内容非常多,用户无法全部看完,也不需要全部看完,那么需要为用户选出她最想看的内容,典型的就是图片分享网站,新闻推荐网站等。
我们先来看一种架构图: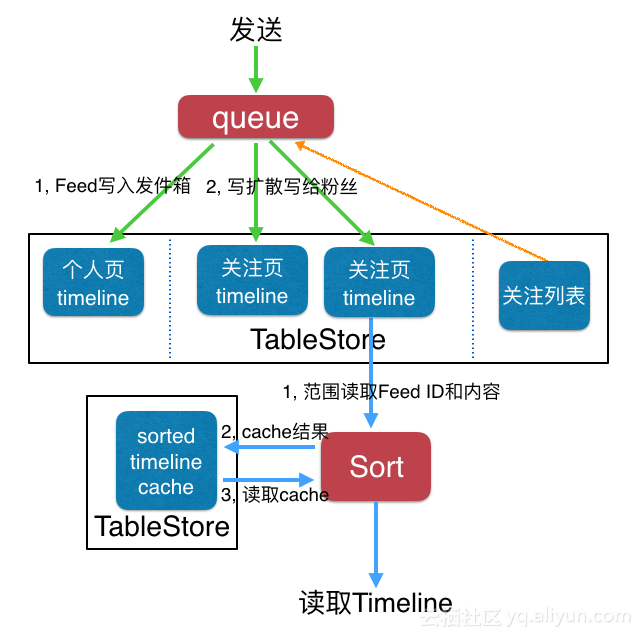
- 这种Rank方式比较轻量级,适用于推拉结合的场景。
- 写流程基本一样
- 读流程里面会先读取所有的Feed内容,这个和Timeline也一样,Timeline里面的话,这里会直接返回给用户,但是Rank类型需要在一个排序模块里面,按照某个属性值排序,然后将所有结果存入一个timeline cache中,并返回分数最高的N个结果,下次读取的时候再返回[N+1, 2N]的结果。
再来看另外一种: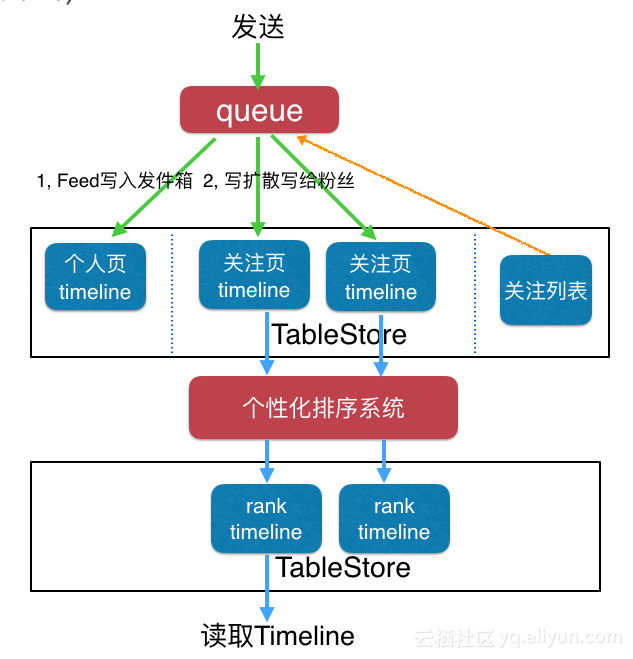
- 这种比较重量级,适用于纯推模式。
- 写流程也和Timeline一样。
- 每个用户有两个收件箱:
- 一个是关注页Timeline,保存原始的Feed内容,用户无法直接查看这个收件箱。
- 一个是rank timeline,保存为用户精选的Feed内容,用户直接查看这个收件箱。
- 写流程结束后还有一个数据处理的流程。个性化排序系统从原始Feed收件箱中获取到新的Feed 内容,按照用户的特征,Feed的特征计算出一个分数,每个Feed在不同用户的Timeline中可能分数不一样的,计算完成后再排序然后写入最终的rank timeline。
- 这种方式可以真正为每个用户做到“千人千面”。
最后
从上面的内容来看,表格存储(TableStore)在存储方面可以支持10PB级,推送方面可以支撑每秒千万的TPS/QPS,在Feed流系统中可以发挥很大的价值。

若有收获,就点个赞吧
0 人点赞
