论文地址:https://arxiv.org/abs/1708.06519
论文《Learning Efficient Convolutional Networks through Network Slimming》
剪枝思路
(1) 在优化的目标函数中添加惩罚项,可以使得在训练的过程中直接对模型进行剪枝,而不是后剪枝

上式第二项就是加上去的惩罚项。这里的 x, y表示输入的训练数据以及目标, W 是需要训练的权重, 就是普通的损失函数,这里
就是普通的损失函数,这里  是关于
是关于 的稀疏度惩罚,
的稀疏度惩罚,  是平衡普通损失函数和稀疏度惩罚的因子。在论文中
是平衡普通损失函数和稀疏度惩罚的因子。在论文中  使用的是 L1 正则化,因为 L1 正则化广泛应用于实现稀疏性。
使用的是 L1 正则化,因为 L1 正则化广泛应用于实现稀疏性。
(2) 使用 BN 层中的缩放因子


µB 和 σB 分别是均值和方差,γ 和 β 是可训练的仿射变换的系数,剪枝的另外一个思路是直接使用 BN 层是缩放因子来进行模型的压缩,这样带来的好处是不会给网络带来任何额外的开销。
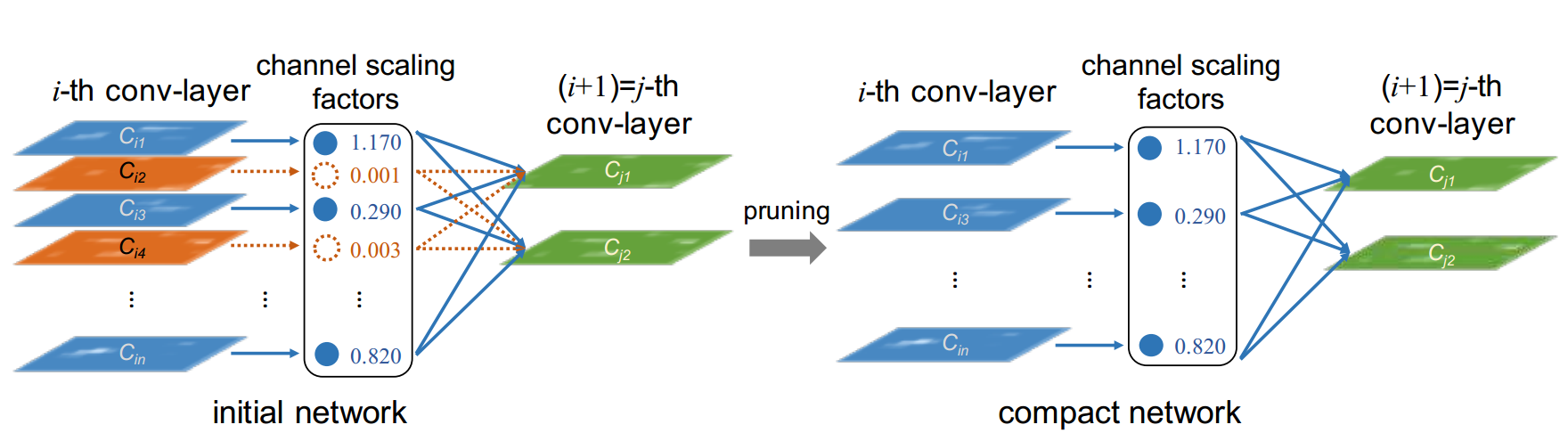
对于初始网络(initial network)通过从BN层中的参数复用,计算卷积层每个通道的缩放因子,确定每个通道的重要程度,对于缩放因子较小(不重要的通道,如上图的橙色)的将会被裁剪掉。得到裁剪后的网络(紧凑的网络 compact network),然后对其进行微调,以达到与正常训练的全网络相当(甚至更高)的精度。
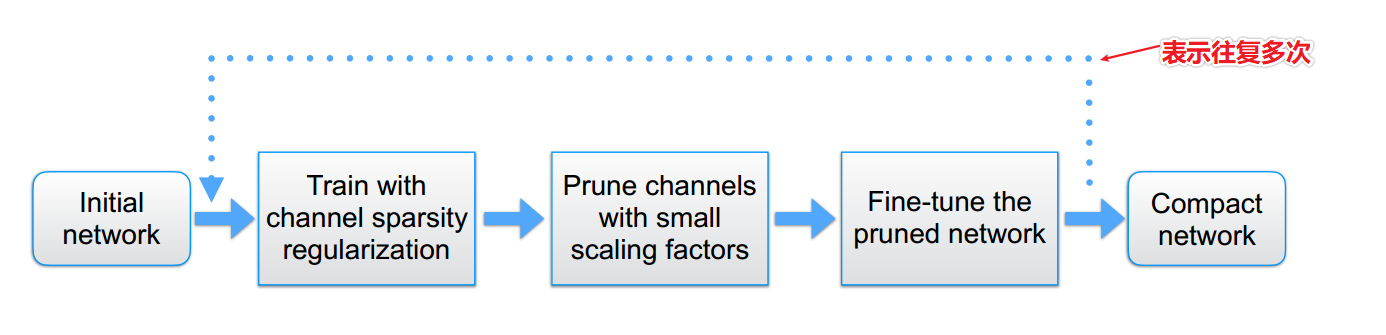
模型压缩的流程图:训练;剪枝;微调剪枝后的模型,循环执行
待关注的问题:普通的卷积和带跨层连接的卷积剪枝的处理方式
实验结果
基本概念:FLOPs:https://www.zhihu.com/question/65305385

结论
可以显著降低最先进的网络高达 20 倍的计算成本,并且没有精度损失。更重要的是, 该方法减少了模型大小、运行时的内存和计算操作,同时训练过程引入了最小的开销,并且得到的模型不需要特殊的库/硬件来进行有效的推理。
项目地址
原始版本:lua 版本 https://github.com/liuzhuang13/slimming
Pytorch 版本:https://github.com/Eric-mingjie/network-slimming

若有收获,就点个赞吧
0 人点赞
