深度学习炼丹,当然少不了 GPU 和 Linux 系统了,部分朋友没有 GPU 的话只能租用远程服务器来训练,这样就少不了 Xshell 这样一款利器了,以下,我们就来介绍 Xshell 这款工具在深度学习的时候一些常用的功能和 Linux 命令。 Xshell 工具
Xshell 工具
后台回复 Xshell 可以获取 Xshell 家庭版 / 校园版 以及 FTP 传输工具
工具
Xshell 使用
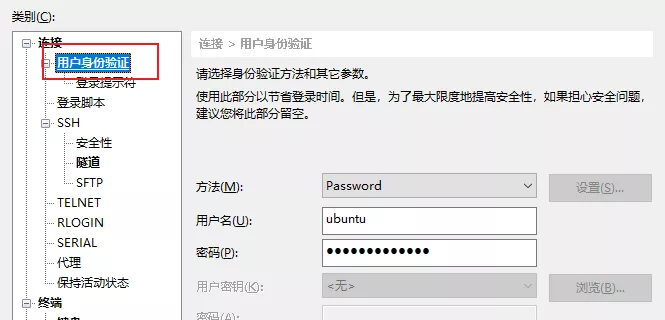
打开 Xshell 工具,点击左上角新建会话,在连接处输入远程服务器的 IP 和 端口号,然后点击用户身份验证,输入账号(一般账户名是 root)密码点击连接即可连接至远程服务器。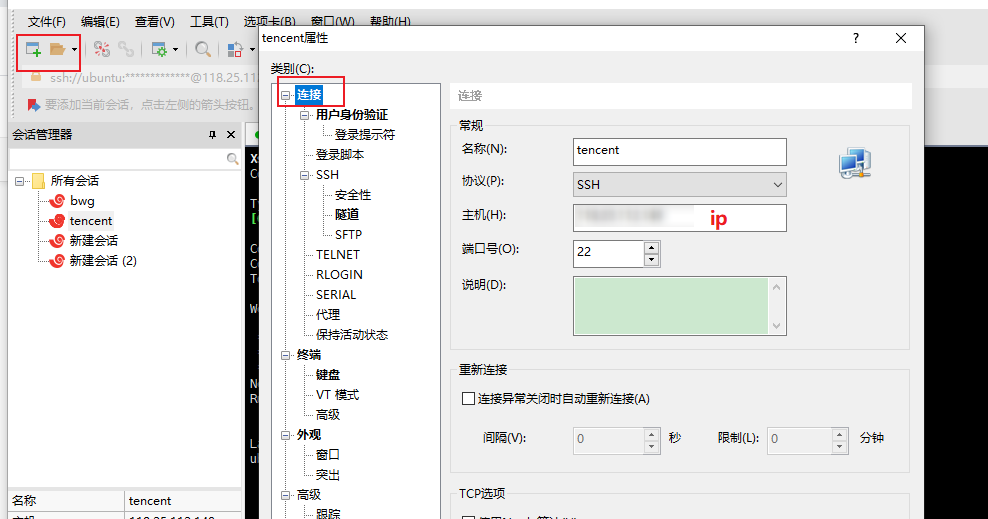
终端复用器 Tmux
远程进行深度学习的时候,为了确保本地的网络不会终止现有的训练,我们需要在服务器的创建一个会话,就是 XShell 软件关闭的时候,也能确保训练正常进行。
# Ubuntu 或 Debian 安装sudo apt-get install tmuxtmux new -s <session-name> # 新建会话 <session-name> 是会话名# Ctrl+D 可以退出会话,但是不会关闭会话,就是程序会在后台一直运行tmux ls # 查看当前所有会话tmux attach -t <session-name> # 接入会话 <session-name> 是会话名
传输工具
如果你有两台服务器,可能需要传输数据或者模型的话,可以使用 Linux 是传输功能,相关的命令如下:
apt install ssh # 安装必要包# 本地传输文件到远程服务器scp -P [remote-port] filename root@ip:/dir/ # 传输 filename 文件到远程服务器的 dir 文件夹下scp -P [remote-port] -r [文件夹] root@ip:/root/code # 传输 文件夹到远程服务器的 /root/code/ 文件夹下
远程访问 tensorboard
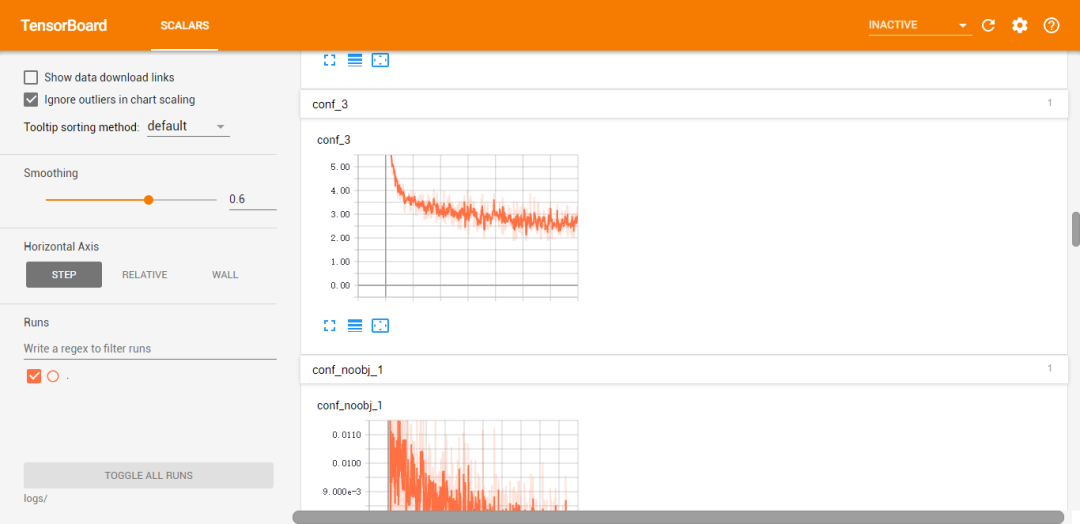
对于深度学习炼丹师来说,可视化的使用是必不可少的,那么如何将远程服务器可视化到本地,请看以下操作的截图
需要确保 tensorflow、tensorboard、tensorboardX 的版本一致,然后在 xshell 中进行设置,设置完成以后,运行 tensorboard --logdir='logs' --port=6006 其中 logs/ 是运行日志的文件夹,并指定端口,然后在本地浏览器打开 http://localhost:6006/ 即可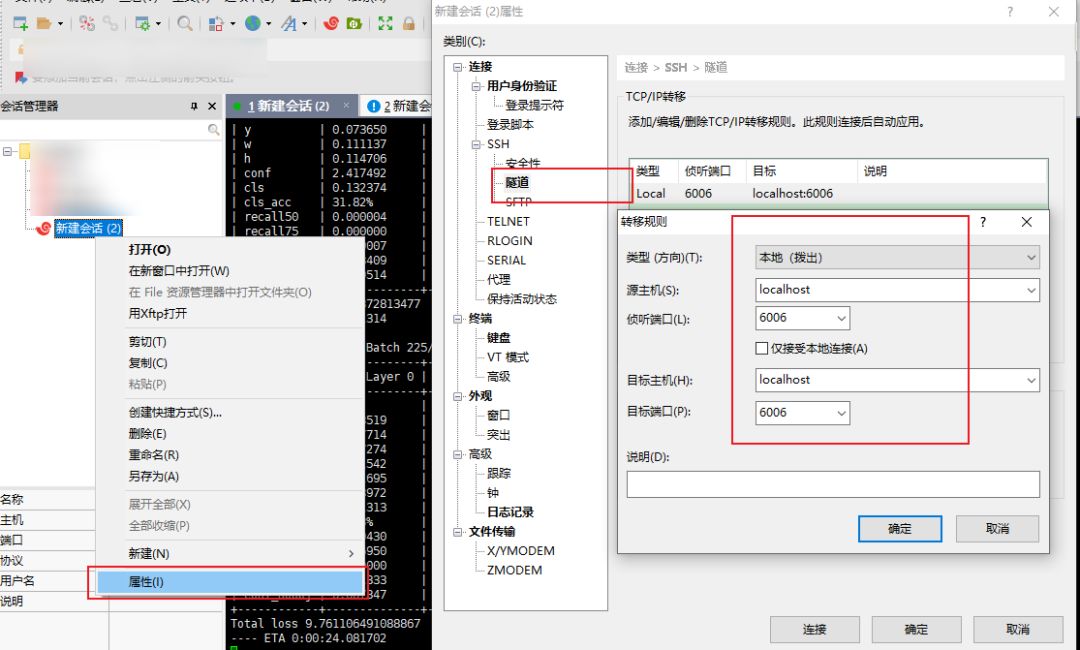
命令
GPU 使用情况
一些场景下,可能需要查看 GPU 的运行状况,来调节 batchsize 大小,可以使用以下命令进行查看
watch -n 10 nvidia-smi # 查看 GPU 使用情况,每 10s 刷新一次,可以设置小一点,如 0.1 可以实时刷新
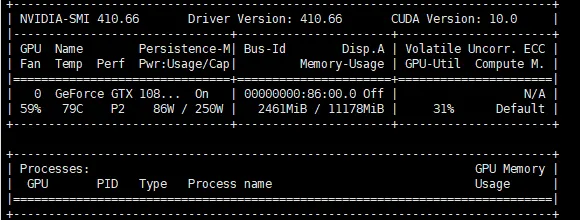
以下是对上图参数的说明:
- Fan:显示风扇转速,数值在 0 到 100% 之间,是计算机的期望转速,如果计算机不是通过风扇冷却或者风扇坏了,显示出来就是 N/A;
- Temp:显卡内部的温度,单位是摄氏度;
- Perf:表征性能状态,从 P0 到 P12,P0 表示最大性能,P12 表示状态最小性能;
- Pwr:能耗表示;
- Bus-Id:涉及 GPU 总线的相关信息;
- Disp.A:是 Display Active 的意思,表示 GPU 的显示是否初始化;
- Memory Usage:显存的使用率;
- Volatile GPU-Util:浮动的 GPU 利用率;
- Compute M:计算模式;
查看文件数目
深度学习当然少不了数据,那么有时需要对数据的情况进行简单的计数,可以使用一下命令ls 、grep 、wc 三者的组合可以实现多种文件数目的查看
ls -l | grep "^-" | wc -l # 统计当前目录下文件的个数(不包括目录(即统计有后缀名的文件数量))ls -lR| grep "^-" | wc -l # 统计当前目录下文件的个数(包括子目录)ls -lR | grep "^d" | wc -l # 查看某目录下文件夹 (目录) 的个数(包括子目录)
下面是 ls 、grep 、wc 参数的具体说明
ls
-a 显示所有文件及目录 (ls 内定将文件名或目录名称开头为 "." 的视为隐藏档,不会列出)-l 除文件名称外,亦将文件型态、权限、拥有者、文件大小等资讯详细列出-r 将文件以相反次序显示 (原定依英文字母次序)-t 将文件依建立时间之先后次序列出-A 同 -a ,但不列出 "." (目前目录) 及 ".." (父目录)-F 在列出的文件名称后加一符号;例如可执行档则加 "*", 目录则加 "/"-R 若目录下有文件,则以下之文件亦皆依序列出
grep:用于查找文件里符合条件的字符串。
-a 或 --text : 不要忽略二进制的数据。-A <显示行数> 或 --after-context=< 显示行数 > : 除了显示符合范本样式的那一列之外,并显示该行之后的内容。-b 或 --byte-offset : 在显示符合样式的那一行之前,标示出该行第一个字符的编号。-B <显示行数> 或 --before-context=< 显示行数 > : 除了显示符合样式的那一行之外,并显示该行之前的内容。-c 或 --count : 计算符合样式的列数。-C <显示行数> 或 --context=< 显示行数 > 或 -< 显示行数 > : 除了显示符合样式的那一行之外,并显示该行之前后的内容。-d <动作> 或 --directories=< 动作 > : 当指定要查找的是目录而非文件时,必须使用这项参数,否则 grep 指令将回报信息并停止动作。-e <范本样式> 或 --regexp=< 范本样式 > : 指定字符串做为查找文件内容的样式。-E 或 --extended-regexp : 将样式为延伸的正则表达式来使用。-f <规则文件> 或 --file=< 规则文件 > : 指定规则文件,其内容含有一个或多个规则样式,让 grep 查找符合规则条件的文件内容,格式为每行一个规则样式。-F 或 --fixed-regexp : 将样式视为固定字符串的列表。-G 或 --basic-regexp : 将样式视为普通的表示法来使用。-h 或 --no-filename : 在显示符合样式的那一行之前,不标示该行所属的文件名称。-H 或 --with-filename : 在显示符合样式的那一行之前,表示该行所属的文件名称。-i 或 --ignore-case : 忽略字符大小写的差别。-l 或 --file-with-matches : 列出文件内容符合指定的样式的文件名称。-L 或 --files-without-match : 列出文件内容不符合指定的样式的文件名称。-n 或 --line-number : 在显示符合样式的那一行之前,标示出该行的列数编号。-o 或 --only-matching : 只显示匹配 PATTERN 部分。-q 或 --quiet 或 --silent : 不显示任何信息。-r 或 --recursive : 此参数的效果和指定 "-d recurse" 参数相同。-s 或 --no-messages : 不显示错误信息。-v 或 --revert-match : 显示不包含匹配文本的所有行。-V 或 --version : 显示版本信息。-w 或 --word-regexp : 只显示全字符合的列。-x --line-regexp : 只显示全列符合的列。-y : 此参数的效果和指定 "-i" 参数相同。
wc
-c 或 --bytes 或 --chars 只显示 Bytes 数。-l 或 --lines 只显示行数。-w 或 --words 只显示字数。--help 在线帮助。--version 显示版本信息。
查看文件大小(bit、GB 等)
du -b [filename or path] # 计算文件夹或者文件的字节数du -h [filename or path] # 计算文件夹或者文件的大小(以MB、GB 形式展示、符合人的直觉)

如果有需要对不同单位的数据进行转换的话,可以使用:字节、GB 转换计算器,看文后参考链接
解压缩
一般上传数据是使用压缩包的方式,那么到远程服务器就无法使用可视化操作进行,这时候需要使用命令对压缩包进行解压了,针对不同压缩的格式,下面给出解压缩的命令:
.zip 文件
apt install zip# 解压unzip -o test.zip -d tmp/ # 解压 test.zip 文件到 tmp/ 下# 压缩将 /home/html/ 这个目录下所有文件和文件夹打包为当前目录下的 html.zip:zip -q -r html.zip /home/html
tar.gz 格式
tar -zxvf ×××.tar.gz
.7z 文件
sudo apt-get install p7zip-full# 压缩7za a 压缩包.7z 被压缩文件或目录# 解压#将压缩包解压到指定目录,注意:指定目录参数-o后面不要有空格7za x 压缩包.7z -o解压目录#将压缩包解压到当前目录7za x 压缩包.7z
测试网速
杠杠的网络不管对数据的传输,还是从互联网上下载模型,都是很关键的,所以有必要对远程服务器的网速进行测试一番。
curl -s https://raw.githubusercontent.com/sivel/speedtest-cli/master/speedtest.py | python
 网速测试
网速测试
ping
有时候模型无法下载?数据下载太慢?可能不是你的问题,而是墙的问题,这时候,你就需要对网络 ping 一下
apt install ping # 安装包,会出现以下信息"""Package ping is a virtual package provided by:iputils-ping 3:20161105-1 # 仅在 Linux 系统上使用inetutils-ping 2:1.9.4-2+b1 # 有更多的功能,可以在非 Linux 系统上使用You should explicitly select one to install."""ping bing.com
ping google.com
ping bing.com
参考:
- 菜鸟教程:https://www.runoob.com/linux/linux-command-manual.html
- https://www.ruanyifeng.com/blog/2019/10/tmux.html
- https://unix.stackovernet.com/cn/q/107009
- https://github.com/sivel/speedtest-cli
- 字节计算器:https://cn.calcuworld.com/% E5% AD%97% E8%8A%82% E8% AE% A1% E7% AE%97% E5%99% A8

若有收获,就点个赞吧
0 人点赞
