Paper https://arxiv.org/abs/1807.06521
https://github.com/Jongchan/attention-module
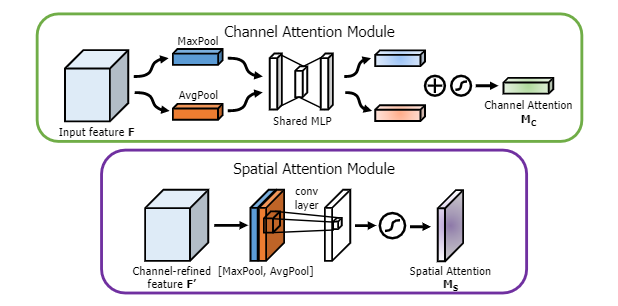
代码
import torchimport mathimport torch.nn as nnimport torch.nn.functional as Fclass BasicConv(nn.Module):def __init__(self, in_planes, out_planes, kernel_size, stride=1, padding=0, dilation=1, groups=1, relu=True, bn=True, bias=False):super(BasicConv, self).__init__()self.out_channels = out_planesself.conv = nn.Conv2d(in_planes, out_planes, kernel_size=kernel_size, stride=stride, padding=padding, dilation=dilation, groups=groups, bias=bias)self.bn = nn.BatchNorm2d(out_planes,eps=1e-5, momentum=0.01, affine=True) if bn else Noneself.relu = nn.ReLU() if relu else Nonedef forward(self, x):x = self.conv(x)if self.bn is not None:x = self.bn(x)if self.relu is not None:x = self.relu(x)return xclass Flatten(nn.Module):def forward(self, x):return x.view(x.size(0), -1)class ChannelGate(nn.Module):def __init__(self, gate_channels, reduction_ratio=16, pool_types=['avg', 'max']):super(ChannelGate, self).__init__()self.gate_channels = gate_channelsself.mlp = nn.Sequential(Flatten(),nn.Linear(gate_channels, gate_channels // reduction_ratio),nn.ReLU(),nn.Linear(gate_channels // reduction_ratio, gate_channels))self.pool_types = pool_typesdef forward(self, x):channel_att_sum = Nonefor pool_type in self.pool_types:if pool_type=='avg': # 平均池化avg_pool = F.avg_pool2d( x, (x.size(2), x.size(3)), stride=(x.size(2), x.size(3)))channel_att_raw = self.mlp( avg_pool )elif pool_type=='max': # 全局池化max_pool = F.max_pool2d( x, (x.size(2), x.size(3)), stride=(x.size(2), x.size(3)))channel_att_raw = self.mlp( max_pool )elif pool_type=='lp':lp_pool = F.lp_pool2d( x, 2, (x.size(2), x.size(3)), stride=(x.size(2), x.size(3)))channel_att_raw = self.mlp( lp_pool )elif pool_type=='lse':# LSE pool onlylse_pool = logsumexp_2d(x)channel_att_raw = self.mlp( lse_pool )if channel_att_sum is None: # 首次计算channel_att_sum = channel_att_rawelse:channel_att_sum = channel_att_sum + channel_att_raw # 累加不同方式的池化scale = torch.sigmoid( channel_att_sum ).unsqueeze(2).unsqueeze(3).expand_as(x)return x * scaledef logsumexp_2d(tensor):"""tensor: (B, C, H, W)"""tensor_flatten = tensor.view(tensor.size(0), tensor.size(1), -1) # (B, C, H×W)s, _ = torch.max(tensor_flatten, dim=2, keepdim=True) # (B, C, 1×1) 每个通道中的最大值outputs = s + (tensor_flatten - s).exp().sum(dim=2, keepdim=True).log()return outputsclass ChannelPool(nn.Module):def forward(self, x):# 找出 (H*W 平面每个点的在通道上最大值以及平均值)return torch.cat( (torch.max(x,1)[0].unsqueeze(1), torch.mean(x,1).unsqueeze(1)), dim=1 )class SpatialGate(nn.Module):def __init__(self, kernel_size):super(SpatialGate, self).__init__()self.kernel_size = kernel_sizeself.compress = ChannelPool()self.spatial = BasicConv(2, 1, self.kernel_size, stride=1, padding=(kernel_size-1) // 2, relu=False)def forward(self, x):x_compress = self.compress(x)x_out = self.spatial(x_compress)scale = torch.sigmoid(x_out) # broadcastingreturn x * scaleclass CBAM(nn.Module):def __init__(self, gate_channels, reduction_ratio=16, kernel_size=7, pool_types=['avg', 'max'], no_spatial=False):super(CBAM, self).__init__()self.ChannelGate = ChannelGate(gate_channels, reduction_ratio, pool_types)self.no_spatial=no_spatialif not no_spatial:self.SpatialGate = SpatialGate(kernel_size)def forward(self, x):x_out = self.ChannelGate(x)if not self.no_spatial:x_out = self.SpatialGate(x_out)return x_out

若有收获,就点个赞吧
0 人点赞
