官方说明文档地址:https://mmdetection.readthedocs.io/en/latest/INSTALL.html
Github 地址:https://github.com/open-mmlab/mmdetection
简述
mmdetection 是一款优秀的基于 PyTorch 的开源目标检测系统,由 香港中文大学多媒体实验室开发,遵循 Apache-2.0 开源协议。
主要特点
- 模块化设计
将目标检测框架各个模块进行分解,可以进行自由组合成自定义的目标检测框架
- 支持多个主流目标检测框架
包括 Faster RCNN, Mask RCNN, RetinaNet, 等
- 高效
所有基本操作,如 bbox 和 mask 都可以在 GPU 上运行,训练速度比其他开源框架(如: Detectron, maskrcnn-benchmark 、SimpleDet.)相媲美或者更快
- 最先进
mmdetection 的创始团队在 2018 年的 COCO 目标检测竞赛上赢得冠军。
安装
要求
安装前,先看看环境是不是支持
- Linux系统(Windows 不是官方支持的系统)
- Python 3.5+
- PyTorch 1.1 或更高版本
- CUDA 9.0 或更高
- NCCL 2
- GCC 4.9 或更高 g**cc —version**
- mmcv
Python 虚拟环境安装(待确定是否有效)
# 使用清华源conda config --add channels https://mirrors.tuna.tsinghua.edu.cn/anaconda/pkgs/free/conda config --add channels https://mirrors.tuna.tsinghua.edu.cn/anaconda/pkgs/main/conda config --set show_channel_urls yes# 创建 python 虚拟环境conda create -n open-mmlab python=3.7 -yconda activate open-mmlab# 安装所需包conda install pytorch torchvision cudatoolkit=10.0
参考:
安装 NCCL
NCCL(NVIDIA Collective Communications Library) 主要用于多 GPU 和多节点的集体通信,可以对 Nvidia GPU 进行性能优化。
https://developer.nvidia.com/nccl 下载相应版本的安装包(CUDA 版本、系统版本Ubuntu)『注:下载前必须先进行注册』
sudo dpkg -i nccl-repo-ubuntu1604-2.5.6-ga-cuda10.0_1-1_amd64.deb # 这个文件就是从nvidia 下载下来的sudo apt updatesudo apt install libnccl2=2.5.6-1+cuda10.0 libnccl-dev=2.5.6-1+cuda10.0

参考
安装 Cython
conda install cython
安装 mmcv
mmcv 是 mmdetection 依赖的重要计算机视觉库
首先运行下面的命令
git clone https://github.com/open-mmlab/mmcv.gitcd mmcvpip install . # 注意有一个点(.) 安装的时候会有点久
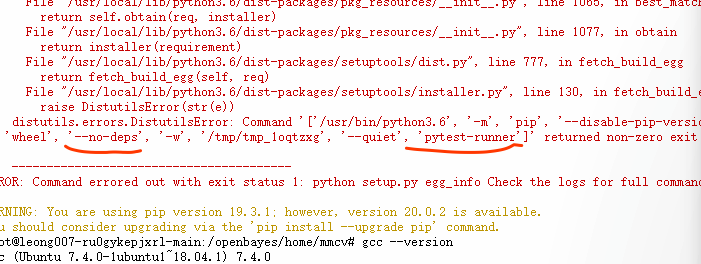
如是出现以下错误,可以运行以下命令后再运行上面的命令pip install pytest-runner pytest
pip install pytest-runner pytest
安装 mmdetection
git clone https://github.com/open-mmlab/mmdetection.gitcd mmdetectionpip install -v -e . # 注意有一个点(.) or "python setup.py develop" # 编译的时间会有点长
安装 pycocotools
pip install pycocotools
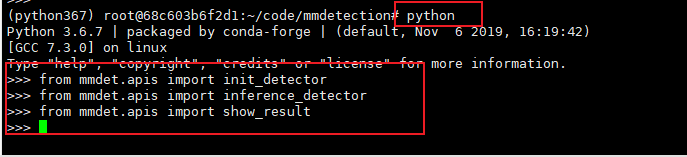
验证环境是否安装成功
Python 环境下运行一下代码,若没有错误,则代表环境安装成功
from mmdet.apis import init_detectorfrom mmdet.apis import inference_detectorfrom mmdet.apis import show_result
Dockerfile 安装
测试代码
测试前,先准备一张测试图片 test.jpg 并且新建一个 checkpoints 文件夹,在 https://github.com/open-mmlab/mmdetection/blob/master/docs/MODEL_ZOO.md 中下载预训练模型到 checkpoints 文件夹中
测试的模型下载地址是:
https://s3.ap-northeast-2.amazonaws.com/open-mmlab/mmdetection/models/faster_rcnn_r50_fpn_1x_20181010-3d1b3351.pth (这个是亚马逊云,下载会比较慢)
#coding=utf-8from mmdet.apis import init_detectorfrom mmdet.apis import inference_detectorfrom mmdet.apis import show_result# 模型配置文件config_file = './configs/faster_rcnn_r50_fpn_1x.py'# 预训练模型文件checkpoint_file = './checkpoints/faster_rcnn_r50_fpn_1x_20181010-3d1b3351.pth'# 通过模型配置文件与预训练文件构建模型model = init_detector(config_file, checkpoint_file, device='cuda:0')# # # 测试单张图片并进行展示img = 'test.jpg'result = inference_detector(model, img)print(result)# 运行测试图片,并保存为 result.jpgshow_result(img, result, model.CLASSES, show=False, out_file="result.jpg")
测试数据集
# single-gpu testingpython tools/test.py ${CONFIG_FILE} ${CHECKPOINT_FILE} [--out ${RESULT_FILE}] [--eval ${EVAL_METRICS}] [--show]# multi-gpu testing./tools/dist_test.sh ${CONFIG_FILE} ${CHECKPOINT_FILE} ${GPU_NUM} [--out ${RESULT_FILE}] [--eval ${EVAL_METRICS}]
CONFIG_FILE : CHECKPOINT_FILE :RESULT_FILE : EVAL_METRICS :--show : 会将结果绘制在一个新窗口上,仅限在单GPU时使用,也要确保环境支持GUI,否则会报错
COCO VOC 数据测试
COCO 数据集训练与测试
VOC 数据集训练与测试
- 数据集准备
在 mmdetection 文件夹下创建一个 data 文件夹,数据集的目录结构如下
mmdetection├── mmdet├── tools├── configs├── data│ ├── coco│ │ ├── annotations│ │ ├── train2017│ │ ├── val2017│ │ ├── test2017│ ├── VOCdevkit│ │ ├── VOC2007│ │ ├── VOC2012
cd mmdetectionmkdir datacd datamkdir VOCdevkitcd VOCdevkitln -s /you_dataset_path/ ./ # 创建软连接
- 训练
学习率设置
- 单 gpu,且 img_per_gpu = 2 lr = 0.00125。
- 8 gpus、imgs_per_gpu = 2:lr = 0.02;
- 4 gpus、imgs_per_gpu = 2:lr = 0.01
- 2 gpus、imgs_per_gpu = 2 或 4 gpus、imgs_per_gpu = 1:lr = 0.005;
- 16 GPUs 4 img/gpu.: lr=0.08
epoch 设置
epoch 的选择,默认 total_epoch = 12,learning_policy 中,step = [8,11]。total_peoch 可以自行修改,若 total_epoch = 50,则 learning_policy 中,step 也相应修改,例如 step = [38,48]。
configs/pascal_voc/aster_rcnn_r50_fpn_1x_voc0712.py
# model settingsmodel = dict(type='FasterRCNN',pretrained='torchvision://resnet50',backbone=dict(type='ResNet',depth=50,num_stages=4,out_indices=(0, 1, 2, 3),frozen_stages=1,style='pytorch'),neck=dict(type='FPN',in_channels=[256, 512, 1024, 2048],out_channels=256,num_outs=5),rpn_head=dict(type='RPNHead',in_channels=256,feat_channels=256,anchor_scales=[8],anchor_ratios=[0.5, 1.0, 2.0],anchor_strides=[4, 8, 16, 32, 64],target_means=[.0, .0, .0, .0],target_stds=[1.0, 1.0, 1.0, 1.0],loss_cls=dict(type='CrossEntropyLoss', use_sigmoid=True, loss_weight=1.0),loss_bbox=dict(type='SmoothL1Loss', beta=1.0 / 9.0, loss_weight=1.0)),bbox_roi_extractor=dict(type='SingleRoIExtractor',roi_layer=dict(type='RoIAlign', out_size=7, sample_num=2),out_channels=256,featmap_strides=[4, 8, 16, 32]),bbox_head=dict(type='SharedFCBBoxHead',num_fcs=2,in_channels=256,fc_out_channels=1024,roi_feat_size=7,num_classes=21,target_means=[0., 0., 0., 0.],target_stds=[0.1, 0.1, 0.2, 0.2],reg_class_agnostic=False,loss_cls=dict(type='CrossEntropyLoss', use_sigmoid=False, loss_weight=1.0),loss_bbox=dict(type='SmoothL1Loss', beta=1.0, loss_weight=1.0)))# model training and testing settingstrain_cfg = dict(rpn=dict(assigner=dict(type='MaxIoUAssigner',pos_iou_thr=0.7,neg_iou_thr=0.3,min_pos_iou=0.3,ignore_iof_thr=-1),sampler=dict(type='RandomSampler',num=256,pos_fraction=0.5,neg_pos_ub=-1,add_gt_as_proposals=False),allowed_border=0,pos_weight=-1,debug=False),rpn_proposal=dict(nms_across_levels=False,nms_pre=2000,nms_post=2000,max_num=2000,nms_thr=0.7,min_bbox_size=0),rcnn=dict(assigner=dict(type='MaxIoUAssigner',pos_iou_thr=0.5,neg_iou_thr=0.5,min_pos_iou=0.5,ignore_iof_thr=-1),sampler=dict(type='RandomSampler',num=512,pos_fraction=0.25,neg_pos_ub=-1,add_gt_as_proposals=True),pos_weight=-1,debug=False))test_cfg = dict(rpn=dict(nms_across_levels=False,nms_pre=1000,nms_post=1000,max_num=1000,nms_thr=0.7,min_bbox_size=0),rcnn=dict(score_thr=0.05, nms=dict(type='nms', iou_thr=0.5), max_per_img=100)# soft-nms is also supported for rcnn testing# e.g., nms=dict(type='soft_nms', iou_thr=0.5, min_score=0.05))# dataset settingsdataset_type = 'VOCDataset'data_root = 'data/VOCdevkit/'img_norm_cfg = dict(mean=[123.675, 116.28, 103.53], std=[58.395, 57.12, 57.375], to_rgb=True)train_pipeline = [dict(type='LoadImageFromFile'),dict(type='LoadAnnotations', with_bbox=True),dict(type='Resize', img_scale=(1000, 600), keep_ratio=True),dict(type='RandomFlip', flip_ratio=0.5),dict(type='Normalize', **img_norm_cfg),dict(type='Pad', size_divisor=32),dict(type='DefaultFormatBundle'),dict(type='Collect', keys=['img', 'gt_bboxes', 'gt_labels']),]test_pipeline = [dict(type='LoadImageFromFile'),dict(type='MultiScaleFlipAug',img_scale=(1000, 600),flip=False,transforms=[dict(type='Resize', keep_ratio=True),dict(type='RandomFlip'),dict(type='Normalize', **img_norm_cfg),dict(type='Pad', size_divisor=32),dict(type='ImageToTensor', keys=['img']),dict(type='Collect', keys=['img']),])]data = dict(imgs_per_gpu=2, # 根据 GPU 的数量修改workers_per_gpu=2,train=dict(type='RepeatDataset',times=3,dataset=dict(type=dataset_type,ann_file=[data_root + 'VOC2007/ImageSets/Main/trainval.txt',data_root + 'VOC2012/ImageSets/Main/trainval.txt'],img_prefix=[data_root + 'VOC2007/',data_root + 'VOC2012/'],pipeline=train_pipeline)),val=dict(type=dataset_type,ann_file=data_root + 'VOC2007/ImageSets/Main/test.txt',img_prefix=data_root + 'VOC2007/',pipeline=test_pipeline),test=dict(type=dataset_type,ann_file=data_root + 'VOC2007/ImageSets/Main/test.txt',img_prefix=data_root + 'VOC2007/',pipeline=test_pipeline))evaluation = dict(interval=1, metric='mAP')# optimizeroptimizer = dict(type='SGD', lr=0.01, momentum=0.9, weight_decay=0.0001)optimizer_config = dict(grad_clip=dict(max_norm=35, norm_type=2))# learning policylr_config = dict(policy='step', step=[3]) # actual epoch = 3 * 3 = 9checkpoint_config = dict(interval=1)# yapf:disablelog_config = dict(interval=50,hooks=[dict(type='TextLoggerHook'),# dict(type='TensorboardLoggerHook')])# yapf:enable# runtime settingstotal_epochs = 4 # actual epoch = 4 * 3 = 12dist_params = dict(backend='nccl')log_level = 'INFO'work_dir = './work_dirs/faster_rcnn_r50_fpn_1x_voc0712'load_from = Noneresume_from = Noneworkflow = [('train', 1)]
python tools/train.py configs/pascal_voc/faster_rcnn_r50_fpn_1x_voc0712.py
- VOC 数据集 mAP、recall 计算
# 生成 pkl 文件python tools/test.py ./configs/pascal_voc/faster_rcnn_r50_fpn_1x_voc0712.py ./work_dirs/faster_rcnn_r50_fpn_1x_voc0712/epoch_1.pth --out results.pk# 计算 mAPpython ./tools/voc_eval.py results.pkl ./configs/pascal_voc/faster_rcnn_r50_fpn_1x_voc0712.py

tool/test.py
import argparseimport osimport os.path as ospimport pickleimport shutilimport tempfileimport mmcvimport torchimport torch.distributed as distfrom mmcv.parallel import MMDataParallel, MMDistributedDataParallelfrom mmcv.runner import get_dist_info, init_dist, load_checkpointfrom mmdet.core import wrap_fp16_modelfrom mmdet.datasets import build_dataloader, build_datasetfrom mmdet.models import build_detectordef single_gpu_test(model, data_loader, show=False):model.eval()results = []dataset = data_loader.datasetprog_bar = mmcv.ProgressBar(len(dataset))for i, data in enumerate(data_loader):with torch.no_grad():result = model(return_loss=False, rescale=not show, **data)results.append(result)if show:model.module.show_result(data, result)batch_size = data['img'][0].size(0)for _ in range(batch_size):prog_bar.update()return resultsdef multi_gpu_test(model, data_loader, tmpdir=None, gpu_collect=False):"""Test model with multiple gpus.This method tests model with multiple gpus and collects the resultsunder two different modes: gpu and cpu modes. By setting 'gpu_collect=True'it encodes results to gpu tensors and use gpu communication for resultscollection. On cpu mode it saves the results on different gpus to 'tmpdir'and collects them by the rank 0 worker.Args:model (nn.Module): Model to be tested.data_loader (nn.Dataloader): Pytorch data loader.tmpdir (str): Path of directory to save the temporary results fromdifferent gpus under cpu mode.gpu_collect (bool): Option to use either gpu or cpu to collect results.Returns:list: The prediction results."""model.eval()results = []dataset = data_loader.datasetrank, world_size = get_dist_info()if rank == 0:prog_bar = mmcv.ProgressBar(len(dataset))for i, data in enumerate(data_loader):with torch.no_grad():result = model(return_loss=False, rescale=True, **data)results.append(result)if rank == 0:batch_size = data['img'][0].size(0)for _ in range(batch_size * world_size):prog_bar.update()# collect results from all ranksif gpu_collect:results = collect_results_gpu(results, len(dataset))else:results = collect_results_cpu(results, len(dataset), tmpdir)return resultsdef collect_results_cpu(result_part, size, tmpdir=None):rank, world_size = get_dist_info()# create a tmp dir if it is not specifiedif tmpdir is None:MAX_LEN = 512# 32 is whitespacedir_tensor = torch.full((MAX_LEN, ),32,dtype=torch.uint8,device='cuda')if rank == 0:tmpdir = tempfile.mkdtemp()tmpdir = torch.tensor(bytearray(tmpdir.encode()), dtype=torch.uint8, device='cuda')dir_tensor[:len(tmpdir)] = tmpdirdist.broadcast(dir_tensor, 0)tmpdir = dir_tensor.cpu().numpy().tobytes().decode().rstrip()else:mmcv.mkdir_or_exist(tmpdir)# dump the part result to the dirmmcv.dump(result_part, osp.join(tmpdir, 'part_{}.pkl'.format(rank)))dist.barrier()# collect all partsif rank != 0:return Noneelse:# load results of all parts from tmp dirpart_list = []for i in range(world_size):part_file = osp.join(tmpdir, 'part_{}.pkl'.format(i))part_list.append(mmcv.load(part_file))# sort the resultsordered_results = []for res in zip(*part_list):ordered_results.extend(list(res))# the dataloader may pad some samplesordered_results = ordered_results[:size]# remove tmp dirshutil.rmtree(tmpdir)return ordered_resultsdef collect_results_gpu(result_part, size):rank, world_size = get_dist_info()# dump result part to tensor with picklepart_tensor = torch.tensor(bytearray(pickle.dumps(result_part)), dtype=torch.uint8, device='cuda')# gather all result part tensor shapeshape_tensor = torch.tensor(part_tensor.shape, device='cuda')shape_list = [shape_tensor.clone() for _ in range(world_size)]dist.all_gather(shape_list, shape_tensor)# padding result part tensor to max lengthshape_max = torch.tensor(shape_list).max()part_send = torch.zeros(shape_max, dtype=torch.uint8, device='cuda')part_send[:shape_tensor[0]] = part_tensorpart_recv_list = [part_tensor.new_zeros(shape_max) for _ in range(world_size)]# gather all result partdist.all_gather(part_recv_list, part_send)if rank == 0:part_list = []for recv, shape in zip(part_recv_list, shape_list):part_list.append(pickle.loads(recv[:shape[0]].cpu().numpy().tobytes()))# sort the resultsordered_results = []for res in zip(*part_list):ordered_results.extend(list(res))# the dataloader may pad some samplesordered_results = ordered_results[:size]return ordered_resultsclass MultipleKVAction(argparse.Action):"""argparse action to split an argument into KEY=VALUE formon the first = and append to a dictionary."""def _is_int(self, val):try:_ = int(val)return Trueexcept Exception:return Falsedef _is_float(self, val):try:_ = float(val)return Trueexcept Exception:return Falsedef _is_bool(self, val):return val.lower() in ['true', 'false']def __call__(self, parser, namespace, values, option_string=None):options = {}for val in values:parts = val.split('=')key = parts[0].strip()if len(parts) > 2:val = '='.join(parts[1:])else:val = parts[1].strip()# try parsing val to bool/int/float firstif self._is_bool(val):import jsonval = json.loads(val.lower())elif self._is_int(val):val = int(val)elif self._is_float(val):val = float(val)options[key] = valsetattr(namespace, self.dest, options)def parse_args():parser = argparse.ArgumentParser(description='MMDet test (and eval) a model')parser.add_argument('config', help='test config file path')parser.add_argument('checkpoint', help='checkpoint file')parser.add_argument('--out', help='output result file in pickle format')parser.add_argument('--format_only',action='store_true',help='Format the output results without perform evaluation. It is''useful when you want to format the result to a specific format and ''submit it to the test server')parser.add_argument('--eval',type=str,nargs='+',help='evaluation metrics, which depends on the dataset, e.g., "bbox",'' "segm", "proposal" for COCO, and "mAP", "recall" for PASCAL VOC')parser.add_argument('--show', action='store_true', help='show results')parser.add_argument('--gpu_collect',action='store_true',help='whether to use gpu to collect results.')parser.add_argument('--tmpdir',help='tmp directory used for collecting results from multiple ''workers, available when gpu_collect is not specified')parser.add_argument('--options', nargs='+', action=MultipleKVAction, help='custom options')parser.add_argument('--launcher',choices=['none', 'pytorch', 'slurm', 'mpi'],default='none',help='job launcher')parser.add_argument('--local_rank', type=int, default=0)args = parser.parse_args()if 'LOCAL_RANK' not in os.environ:os.environ['LOCAL_RANK'] = str(args.local_rank)return argsdef main():args = parse_args()assert args.out or args.eval or args.format_only or args.show, \('Please specify at least one operation (save/eval/format/show the ''results) with the argument "--out", "--eval", "--format_only" ''or "--show"')if args.eval and args.format_only:raise ValueError('--eval and --format_only cannot be both specified')if args.out is not None and not args.out.endswith(('.pkl', '.pickle')):raise ValueError('The output file must be a pkl file.')cfg = mmcv.Config.fromfile(args.config)# set cudnn_benchmarkif cfg.get('cudnn_benchmark', False):torch.backends.cudnn.benchmark = Truecfg.model.pretrained = Nonecfg.data.test.test_mode = True# init distributed env first, since logger depends on the dist info.if args.launcher == 'none':distributed = Falseelse:distributed = Trueinit_dist(args.launcher, **cfg.dist_params)# build the dataloader# TODO: support multiple images per gpu (only minor changes are needed)dataset = build_dataset(cfg.data.test)data_loader = build_dataloader(dataset,imgs_per_gpu=1,workers_per_gpu=cfg.data.workers_per_gpu,dist=distributed,shuffle=False)# build the model and load checkpointmodel = build_detector(cfg.model, train_cfg=None, test_cfg=cfg.test_cfg)fp16_cfg = cfg.get('fp16', None)if fp16_cfg is not None:wrap_fp16_model(model)checkpoint = load_checkpoint(model, args.checkpoint, map_location='cpu')# old versions did not save class info in checkpoints, this walkaround is# for backward compatibilityif 'CLASSES' in checkpoint['meta']:model.CLASSES = checkpoint['meta']['CLASSES']else:model.CLASSES = dataset.CLASSESif not distributed:model = MMDataParallel(model, device_ids=[0])outputs = single_gpu_test(model, data_loader, args.show)else:model = MMDistributedDataParallel(model.cuda(),device_ids=[torch.cuda.current_device()],broadcast_buffers=False)outputs = multi_gpu_test(model, data_loader, args.tmpdir,args.gpu_collect)rank, _ = get_dist_info()if rank == 0:if args.out:print('\nwriting results to {}'.format(args.out))mmcv.dump(outputs, args.out)kwargs = {} if args.options is None else args.optionsif args.format_only:dataset.format_results(outputs, **kwargs)if args.eval:dataset.evaluate(outputs, args.eval, **kwargs)if __name__ == '__main__':main()
代码分析
COCO数据分析
- annotations.json 分析
以下分析 COCO 数据格式的数据,如果自己的数据,可能需要根据自己数据的需要拆分数据集。需要注意的是 annotations.json 文件的 annotations 字段必须要有以下几个字段,如果没有 segmentation 字段,需要添加 segmentation 字段,并赋值空列表。
{'segmentation': [[312.29,562.89,402.25,511.49,400.96,425.38,398.39,...]],'area': 54652.9556,'iscrowd': 0,'image_id': 480023,'bbox': [116.95, 305.86, 285.3, 266.03],'category_id': 58,'id': 86}
# 读取 annotations 文件import jsonwith open('annotations.json') as f:a=json.load(f)a.keys() # dict_keys(['info', 'images', 'license', 'categories', 'annotations'])# 创建类别标签字典category_dic = dict([(i['id'],i['name']) for i in a['categories']])category_dic""" COCO 的 80 个类别{1: 'person',2: 'bicycle',3: 'car',4: 'motorcycle',5: 'airplane',6: 'bus',7: 'train',8: 'truck',9: 'boat',10: 'traffic light',11: 'fire hydrant',13: 'stop sign', ..."""# 统计每个类别数据量counts_label=dict([(i['name'],0) for i in a['categories']])for i in a['annotations']:counts_label[category_dic[i['category_id']]]+=1counts_label"""{'person': 185316,'bicycle': 4955,'car': 30785,'motorcycle': 6021,'airplane': 3833,'bus': 4327,'train': 3159,'truck': 7050,'boat': 7590,'traffic light': 9159 ..."""a_copy = a.copy()a_copy["annotations"] = (list(filter(lambda x:x["category_id"]!=0, a["annotations"])))len(a_copy["annotations"])
训练主代码:tool/train.py
from __future__ import divisionimport osimport sysimport torchimport argparse_FILE_PATH = os.path.dirname(os.path.abspath(__file__))sys.path.insert(0, os.path.join(_FILE_PATH, '../'))from mmdet import __version__from mmcv import Configfrom mmdet.apis import (get_root_logger, init_dist, set_random_seed, train_detector) # 所有部件的注册在此完成.from mmdet.datasets import build_datasetfrom mmdet.models import build_detector# 该函数用来获得命令行的各个参数def parse_args():# 创建一个解析对象parser = argparse.ArgumentParser(description='Train a detector')# add_argument向该对象中添加你要关注的命令行参数和选项, # help可以写帮助信息parser.add_argument('--config', help='train config file path',default='../configs/guided_anchoring/ga_rpn_r50_caffe_fpn_1x.py')# parser.add_argument('config', help='train config file path')parser.add_argument('--work_dir', help='the dir to save logs and models')parser.add_argument('--resume_from', help='the checkpoint file to resume from')# action表示值赋予键的方式,这里用到的是bool类型# 如果使用是分布式训练,且设置了 --validate,会在训练中建立 checkpoint 的时候对该 checkpoint 进行评估。#(未采用分布式训练时,--validate 无效,# 因为 train_detector 中调用的 mmdet.apis._non_dist_train 函数未对 validate 参数做任何处理)parser.add_argument('--validate', action='store_true', help='whether to evaluate the checkpoint during training')# 指使用的 GPU 数量,默认值为 1 颗parser.add_argument('--gpus', type=int, default=1, help='number of gpus to use''(only applicable to non-distributed training)')# type指定参数类型parser.add_argument('--seed', type=int, default=None, help='random seed')# 分布式训练的任务启动器(job launcher),默认值为 none 表示不进行分布式训练;parser.add_argument('--launcher', choices=['none', 'pytorch', 'slurm', 'mpi'], default='none', help='job launcher')# 这个参数是torch.distributed.launch传递过来的,我们设置位置参数来接受,local_rank代表当前程序进程使用的GPU标号parser.add_argument('--local_rank', type=int, default=0)parser.add_argument('--autoscale-lr', action='store_true', help='automatically scale lr with the number of gpus')# 解析命令行, 这样后续的参数获取, 就可以通过args.xxx来获取, 比如:args.local_rank, args.work_dirargs = parser.parse_args()# 分布式相关参数if 'LOCAL_RANK' not in os.environ:os.environ['LOCAL_RANK'] = str(args.local_rank)return argsdef main():# 获取命令行参数,实际上就是获取config配置文件args = parse_args()# 1. 从配置文件(python, yaml, json)解析配置信息, 并做适当更新, 包括预加载模型文件, 分布式相关等# 读取配置文件cfg = Config.fromfile(args.config)# set cudnn_benchmark# 在图片输入尺度固定时开启,可以加速,一般都是关的,只有在固定尺度的网络如SSD512中才开启.# 一般来讲, 应该遵循以下准则:# 1.如果网络的输入数据维度或类型上变化不大,设置torch.backends.cudnn.benchmark = true;# 2.可以增加运行效率;# 3.如果网络的输入数据在每次iteration都变化的话, 会导致cnDNN每次都会去寻找一遍最优配置,这样反而会降低运行效率。if cfg.get('cudnn_benchmark', False):torch.backends.cudnn.benchmark = True# update configs according to CLI argsif args.work_dir is not None:# 创建工作目录存放训练文件,如果不键入,会自动从py配置文件中生成对应的目录,key为work_dircfg.work_dir = args.work_dirif args.resume_from is not None:# 断点继续训练的权值文件,为None就没有这一步的设置cfg.resume_from = args.resume_fromcfg.gpus = args.gpusif args.autoscale_lr:# apply the linear scaling rule (https://arxiv.org/abs/1706.02677)cfg.optimizer['lr'] = cfg.optimizer['lr'] * cfg.gpus / 8# init distributed env first, since logger depends on the dist info.if args.launcher == 'none':distributed = Falseelse:distributed = Trueinit_dist(args.launcher, **cfg.dist_params)# init logger before other stepslogger = get_root_logger(cfg.log_level)# log_level在配置文件里有这个key,value=“INFO”训练一次batch就可以看到输出这个str, info表示输出等级logger.info('Distributed training: {}'.format(distributed))# set random seeds, 关于设置随机种子的原因,是为了能更好的benchmark实验。if args.seed is not None:logger.info('Set random seed to {}'.format(args.seed))set_random_seed(args.seed)# 2. 根据配置信息构建模型.build_detector函数调用build函数, build函数调用build_from_cfg(), 按type关键字从注册表中获取# 相应的模型对象, 并根据配置参数实例化对象(配置文件的模型参数只占了各模型构造参数的一小部分, 模型结构并非可以随意更改)# 这里将检测模型的组件: backbone, neck, detecthead, loss等一并构建好.model = build_detector(cfg.model, train_cfg=cfg.train_cfg, test_cfg=cfg.test_cfg)# 3. 数据集生成, 其中build_dataset()在mmdet/datasets/builder.py里实现, 这里同样是build_dataset()函数调用# build_from_cfg()函数实现.datasets = [build_dataset(cfg.data.train)]if len(cfg.workflow) == 2:datasets.append(build_dataset(cfg.data.val))if cfg.checkpoint_config is not None:# save mmdet version, config file content and class names in checkpoints as meta data# 将mmdet版本, 配置文件和检查点中的类别等保存, meta的含义表示源信息, 也即metarial的意思cfg.checkpoint_config.meta = dict(mmdet_version=__version__,config=cfg.text,CLASSES=datasets[0].CLASSES)# add an attribute for visualization convenience: 添加属性以方便可视化# model的CLASSES属性本来没有的, 但是 python 不用提前申明, 而是在赋值的时候自动定义变量。model.CLASSES = datasets[0].CLASSES # 这里为什么这么写, 是因为, 不知道配置的是什么数据集, 因此, 进行动态赋值。# 如果要训练自己的数据,需要修改文件,见『训练自己的数据部分』# 4. 检测器训练, 将build_detector()函数创建好的build模型model, build_dataset创建好的datasets, cfg文件等传递train_detector(model, datasets, cfg, distributed=distributed, validate=args.validate, logger=logger)if __name__ == '__main__':main()
配置文件
- configs/faster_rcnn_r50_fpn_1x.py
# https://zhuanlan.zhihu.com/p/102072353# model settingsmodel = dict(type='FasterRCNN', # model 模型pretrained='torchvision://resnet50', # 预训练模型:imagenet-resnet50backbone=dict(type='ResNet', # backbone类型depth=50, # 网络层数num_stages=4, # resnet的stage数量out_indices=(0, 1, 2, 3), # 输出的stage的序号frozen_stages=1, # 冻结的stage数量,即该stage不更新参数,-1表示所有的stage都更新参数style='pytorch'), # 网络风格:如果设置pytorch,则stride为2的层是conv3x3的卷积层;如果设置caffe,则stride为2的层是第一个conv1x1的卷积层neck=dict(type='FPN',in_channels=[256, 512, 1024, 2048],out_channels=256,num_outs=5),rpn_head=dict(type='RPNHead',in_channels=256,feat_channels=256,anchor_scales=[8],anchor_ratios=[0.5, 1.0, 2.0],anchor_strides=[4, 8, 16, 32, 64],target_means=[.0, .0, .0, .0],target_stds=[1.0, 1.0, 1.0, 1.0],loss_cls=dict(type='CrossEntropyLoss', use_sigmoid=True, loss_weight=1.0),loss_bbox=dict(type='SmoothL1Loss', beta=1.0 / 9.0, loss_weight=1.0)),bbox_roi_extractor=dict(type='SingleRoIExtractor',roi_layer=dict(type='RoIAlign', out_size=7, sample_num=2),out_channels=256,featmap_strides=[4, 8, 16, 32]),bbox_head=dict(type='SharedFCBBoxHead',num_fcs=2,in_channels=256, # 输入通道数fc_out_channels=1024, # 输出通道数roi_feat_size=7,num_classes=11, # 分类器的类别数量+1,+1是因为多了一个背景的类别target_means=[0., 0., 0., 0.],target_stds=[0.1, 0.1, 0.2, 0.2],reg_class_agnostic=False,loss_cls=dict(type='CrossEntropyLoss', use_sigmoid=False, loss_weight=1.0),loss_bbox=dict(type='SmoothL1Loss', beta=1.0, loss_weight=1.0)))# model training and testing settingstrain_cfg = dict(rpn=dict(assigner=dict(type='MaxIoUAssigner',pos_iou_thr=0.7,neg_iou_thr=0.3,min_pos_iou=0.3,ignore_iof_thr=-1),sampler=dict(type='RandomSampler',num=256,pos_fraction=0.5,neg_pos_ub=-1,add_gt_as_proposals=False),allowed_border=0,pos_weight=-1,debug=False),rpn_proposal=dict(nms_across_levels=False,nms_pre=2000,nms_post=2000,max_num=2000,nms_thr=0.7,min_bbox_size=0),rcnn=dict(assigner=dict(type='MaxIoUAssigner',pos_iou_thr=0.5,neg_iou_thr=0.5,min_pos_iou=0.5,ignore_iof_thr=-1),sampler=dict(type='RandomSampler',num=512,pos_fraction=0.25,neg_pos_ub=-1,add_gt_as_proposals=True),pos_weight=-1,debug=False))test_cfg = dict(rpn=dict(nms_across_levels=False,nms_pre=1000,nms_post=1000,max_num=1000,nms_thr=0.7,min_bbox_size=0),rcnn=dict(score_thr=0.05, nms=dict(type='nms', iou_thr=0.5), max_per_img=100)# soft-nms is also supported for rcnn testing# e.g., nms=dict(type='soft_nms', iou_thr=0.5, min_score=0.05))# dataset settingsdataset_type = 'CocoDataset'data_root = "./data/"img_norm_cfg = dict(mean=[123.675, 116.28, 103.53], std=[58.395, 57.12, 57.375], to_rgb=True)train_pipeline = [dict(type='LoadImageFromFile'),dict(type='LoadAnnotations', with_bbox=True),dict(type='Resize', img_scale=(492,658), keep_ratio=True),dict(type='RandomFlip', flip_ratio=0.5),dict(type='Normalize', **img_norm_cfg),dict(type='Pad', size_divisor=32),dict(type='DefaultFormatBundle'),dict(type='Collect', keys=['img', 'gt_bboxes', 'gt_labels']),]test_pipeline = [dict(type='LoadImageFromFile'),dict(type='MultiScaleFlipAug',img_scale=(492,658), # 输入图像尺寸,最大边,最小边flip=False,transforms=[dict(type='Resize', keep_ratio=True),dict(type='RandomFlip'),dict(type='Normalize', **img_norm_cfg),dict(type='Pad', size_divisor=32),dict(type='ImageToTensor', keys=['img']),dict(type='Collect', keys=['img']),])]data = dict(imgs_per_gpu=8,workers_per_gpu=2,train=dict(type=dataset_type,ann_file=data_root + 'annotations/train_annotations.json',img_prefix=data_root + 'images/',pipeline=train_pipeline),val=dict(type=dataset_type,ann_file=data_root + 'annotations/val_annotations.json',img_prefix=data_root + 'images/',pipeline=test_pipeline),test=dict(type=dataset_type,ann_file=data_root + 'annotations/val_annotations.json',img_prefix=data_root + 'images/',pipeline=test_pipeline))# optimizeroptimizer = dict(type='SGD', lr=0.02, momentum=0.9, weight_decay=0.0001)optimizer_config = dict(grad_clip=dict(max_norm=35, norm_type=2))# learning policylr_config = dict(policy='step', # 优化策略warmup='linear', # 初始的学习率增加的策略,linear为线性增加warmup_iters=500, # 在初始的500次迭代中学习率逐渐增加warmup_ratio=1.0 / 3, # 起始的学习率step=[8, 11]) # 在第8和11个epoch时降低学习率checkpoint_config = dict(interval=1) # 每1个epoch存储一次模型# yapf:disablelog_config = dict(interval=50, # 每50个batch输出一次信息hooks=[dict(type='TextLoggerHook'), # 控制台输出信息的风格# dict(type='TensorboardLoggerHook')])# yapf:enable# runtime settingstotal_epochs = 12 # 最大epoch数dist_params = dict(backend='nccl') # 分布式参数log_level = 'INFO' # 输出信息的完整度级别work_dir = './work_dirs/faster_rcnn_r50_fpn_1x' # log文件和模型文件存储路径load_from = None # 加载模型的路径,None表示从预训练模型加载resume_from = None # 恢复训练模型的路径workflow = [('train', 1)] # 当前工作区名称
训练自己的数据
- 修改 mmdet/datasets/coco.py
class CocoDataset(CustomDataset):CLASSES = ('person', 'bicycle', 'car',...) # 修改成自己的类别def load_annotations(self, ann_file):self.coco = COCO(ann_file)self.cat_ids = self.coco.getCatIds()....
- 修改 mmdet/core/evaluation/class_names.py
def coco_classes():return ['person', 'bicycle', ...] # 修改成自己的类别
- 修改配置文件(包括 num_classes=类别数+1 )
优秀资源

若有收获,就点个赞吧
0 人点赞
