https://www.runoob.com/python/python-reg-expressions.html
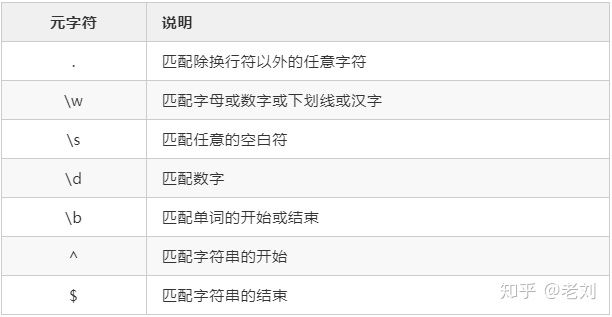
元字符
简单的例子
匹配有 abc 开头的字符串 \babc 或者 ^abc
匹配 9 位数字的 QQ 号码
^\d\d\d\d\d\d\d\d\d$
匹配 1 开头 11 位数字的手机号码:
^1\d\d\d\d\d\d\d\d\d\d$
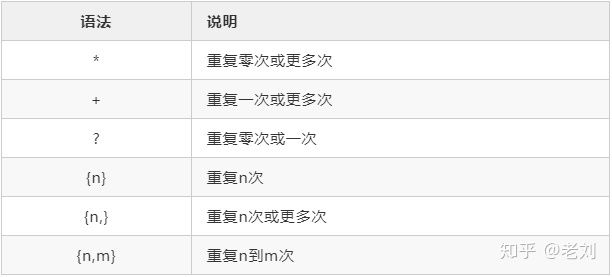
重复限定符
对重复部分用合适的限定符替代
匹配 9 位数字的 QQ 号码
^\d{9}$
匹配 1 开头 11 位数字的手机号码:
^1\d{10}$
匹配以 a 开头的,0 个或多个 b 结尾的字符串
^ab*$
分组
正则表达式中用小括号 () 来做分组,也就是括号中的内容作为一个整体。
- 匹配字符串中包含 0 到多个 ab 开头:
^(ab)*
转义
如果要匹配的字符串中本身就包含小括号,那是不是冲突?应该怎么办?
针对这种情况,正则提供了转义的方式,也就是要把这些元字符、限定符或者关键字转义成普通的字符,做法很简答,就是在要转义的字符前面加个斜杠,也就是 \ 即可。
- 匹配
(ab)的内容((ab))*
条件或
我们都知道:国内号码都来自三大网,它们都有属于自己的号段,比如联通有 130/131/132/155/156/185/186/145/176 等号段,假如让我们匹配一个联通的号码,那按照我们目前所学到的正则,应该无从下手的,因为这里包含了一些并列的条件,也就是 “或”,那么在正则中是如何表示 “或” 的呢?
正则用符号 | 来表示或,也叫做分支条件,当满足正则里的分支条件的任何一种条件时,都会当成是匹配成功。
- 处理条件或的问题
^(130|131|132|155|156|185|186|145|176)\d{8}$
区间
正则提供一个元字符中括号 [] 来表示区间条件。
- 限定 0 到 9 可以写成 [0-9]
- 限定 A-Z 写成 [A-Z]
- 限定某些数字 [165]
- 手机号匹配的问题的解法
^(13[0-2]|15[56]|18[56]|145|176)\d{8}$
正则进阶知识点
pattern = "(?<=xxx).{1, 10000}(?=xxx)"
零宽断言
- 断言:俗话的断言就是 “我断定什么什么”,而正则中的断言,就是说正则可以指明在指定的内容的前面或后面会出现满足指定规则的内容,
意思正则也可以像人类那样断定什么什么,比如 “ss1aa2bb3”, 正则可以用断言找出 aa2 前面有 bb3,也可以找出 aa2 后面有 ss1. - 零宽:就是没有宽度,在正则中,断言只是匹配位置,不占字符,也就是说,匹配结果里是不会返回断言本身。
- 正向先行断言(正前瞻)
- 语法:(?=pattern)
- 作用:匹配 pattern 表达式的前面内容,不返回本身。
找到 的花朵 前面的 祖国 
- 正向后行断言(正后顾):
- 语法:(?<=pattern)
- 作用:匹配 pattern 表达式的后面的内容,不返回本身。
找到 我爱 后面的 祖国 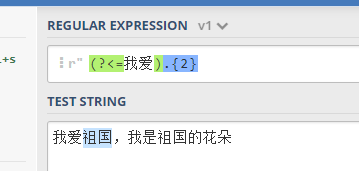
- 负向先行断言(负前瞻)
- 语法:(?!pattern)
- 作用:匹配非 pattern 表达式的前面内容,不返回本身。
找到非 的花朵 前面的 祖国 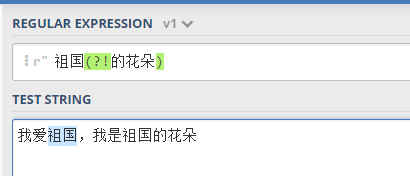
- 负向后行断言(负后顾)
- 语法:(?<!pattern)
- 作用:匹配非 pattern 表达式的后面内容,不返回本身。
匹配非 我爱 后面的 祖国 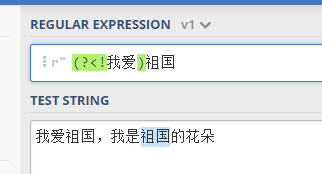
捕获和非捕获
捕获组:匹配子表达式的内容,把匹配结果保存到内存中中数字编号或显示命名的组里,以深度优先进行编号,之后可以通过序号或名称来使用这些匹配结果。
- 数字编号捕获组:
语法:(exp)
解释:从表达式左侧开始,每出现一个左括号和它对应的右括号之间的内容为一个分组,在分组中,第 0 组为整个表达式,第一组开始为分组。
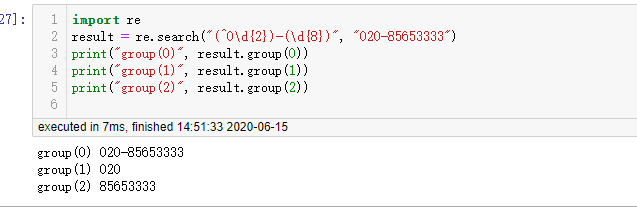
比如固定电话的:020-85653333
他的正则表达式为:(0\d {2})-(\d {8})
按照左括号的顺序,这个表达式有如下分组:

- 命名编号捕获组:
语法:(?
解释:分组的命名由表达式中的 name 指定
貌似 Python 不支持
反向引用
捕获会返回一个捕获组,这个分组是保存在内存中,不仅可以在正则表达式外部通过程序进行引用,也可以在正则表达式内部进行引用,这种引用方式就是反向引用。
比如要查找一串字母 “aabbbbgbddesddfiid” 里成对的字母
我们的思路是:
- 1)匹配到一个字母
- 2)匹配第下一个字母,检查是否和上一个字母是否一样
- 3)如果一样,则匹配成功,否则失败
这里的思路 2 中匹配下一个字母时,需要用到上一个字母,那怎么记住上一个字母呢???
这下子捕获就有用处啦,我们可以利用捕获把上一个匹配成功的内容用来作为本次匹配的条件
好了,有思路就要实践
首先匹配一个字母:\w
我们需要做成分组才能捕获,因此写成这样:(\w)
那这个表达式就有一个捕获组:(\w)
然后我们要用这个捕获组作为条件,那就可以:(\w)\1
这样就大功告成了
可能有人不明白了,\1 是什么意思呢?
还记得捕获组有两种命名方式吗,一种是是根据捕获分组顺序命名,一种是自定义命名来作为捕获组的命名
在默认情况下都是以数字来命名,而且数字命名的顺序是从 1 开始的
贪婪和非贪婪
- 贪婪匹配
当正则表达式中包含能接受重复的限定符时,通常的行为是(在使整个表达式能得到匹配的前提下)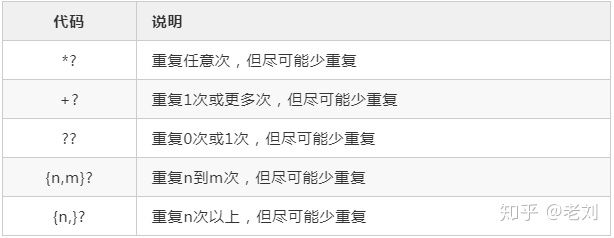
特性:一次性读入整个字符串进行匹配,每当不匹配就舍弃最右边一个字符,继续匹配,依次匹配和舍弃(这种匹配 - 舍弃的方式也叫做回溯),直到匹配成功或者把整个字符串舍弃完为止,因此它是一种最大化的数据返回,能多不会少。
- 懒惰匹配
当正则表达式中包含能接受重复的限定符时,通常的行为是(在使整个表达式能得到匹配的前提下)匹配尽可能少的字符,这匹配方式叫做懒惰匹配。
特性:从左到右,从字符串的最左边开始匹配,每次试图不读入字符匹配,匹配成功,则完成匹配,否则读入一个字符再匹配,依此循环(读入字符、匹配)直到匹配成功或者把字符串的字符匹配完为止。
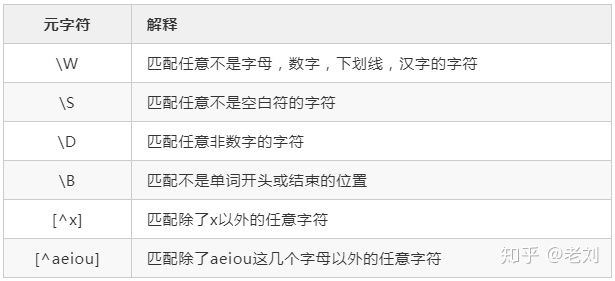
反义
不想匹配某些字符,正则也提供了一些常用的反义元字符:
修饰符
| 修饰符 | 描述 |
|---|---|
| re.I | 使匹配对大小写不敏感 |
| re.L | 做本地化识别(locale-aware)匹配 |
| re.M | 多行匹配,影响 ^ 和 $ |
| re.S | 使。匹配包括换行在内的所有字符 |
| re.U | 根据 Unicode 字符集解析字符。这个标志影响 \w, \W, \b, \B. |
| re.X | 该标志通过给予你更灵活的格式以便你将正则表达式写得更易于理解。 |
Python正则表达式
re.match
尝试从字符串的起始位置匹配一个模式,如果不是起始位置匹配成功的话,就返回 none。
re.search
扫描整个字符串并返回第一个成功的匹配。
re.compile 函数
compile 函数用于编译正则表达式,生成一个正则表达式( Pattern )对象,供 match () 和 search () 这两个函数使用。
re.findall
在字符串中找到正则表达式所匹配的所有子串,并返回一个列表,如果没有找到匹配的,则返回空列表。
re.finditer
和 findall 类似,在字符串中找到正则表达式所匹配的所有子串,并把它们作为一个迭代器返回。
re.split
split 方法按照能够匹配的子串将字符串分割后返回列表,

若有收获,就点个赞吧
0 人点赞
