论文地址:https://arxiv.org/abs/1608.08710
CNN的剪枝主要分为两种,一种是基于幅值的剪枝,一种是基于通道的剪枝。基于幅值的剪枝主要思想是将小于一定阈值的权重抛弃,阈值用剪枝率来确定。而基于通道的剪枝主要思想是将不重要的整个权重通道剪掉,从而将模型变小。这篇论文就属于第二类。
https://zhuanlan.zhihu.com/p/63779916
https://mp.weixin.qq.com/s/hbx62XkEPF61VPiORGpxGw
剪通道为何有效
裁剪通道能够有效减少计算量
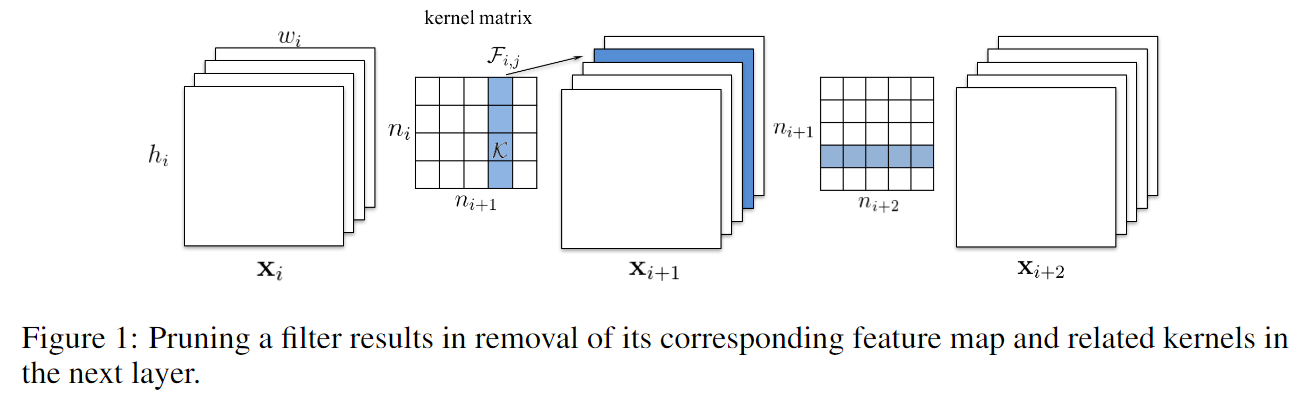
 是第 i 个卷积层的输入通道数,
是第 i 个卷积层的输入通道数,  是输入特征图
是输入特征图  的宽和高。卷积层将输入维度为
的宽和高。卷积层将输入维度为  的特征图转化为维度为
的特征图转化为维度为  的输出特征图,可以直接当作下一个卷积层的输入。这里卷积核的维度为
的输出特征图,可以直接当作下一个卷积层的输入。这里卷积核的维度为  ,卷积层的 MAdd 次数为
,卷积层的 MAdd 次数为  。当如 Figure 1 所示的那样,将一个卷积核剪掉,对应的一个 feature map 就没了,减少了
。当如 Figure 1 所示的那样,将一个卷积核剪掉,对应的一个 feature map 就没了,减少了  次运算,同时由此输出通道数的减少导致下一层的卷积通道维度的缩减,又减少了
次运算,同时由此输出通道数的减少导致下一层的卷积通道维度的缩减,又减少了  。原因在于:当前一个卷积层的卷积核被剪掉以后,该层保留的卷积核参数不仅是在卷积核个数这个维度上缩减了,还和上一个卷积层剪掉的卷积核个数有关,因此其间接导致了该层卷积核在通道维度的缩减。在卷积层 i 上裁剪掉 m 个滤波器,对于卷积层第 i 层和地 i+1 层会减少
。原因在于:当前一个卷积层的卷积核被剪掉以后,该层保留的卷积核参数不仅是在卷积核个数这个维度上缩减了,还和上一个卷积层剪掉的卷积核个数有关,因此其间接导致了该层卷积核在通道维度的缩减。在卷积层 i 上裁剪掉 m 个滤波器,对于卷积层第 i 层和地 i+1 层会减少  的计算量
的计算量
哪些通道需要剪
裁剪掉那些每层中重要性不大的卷积核,那么何为不重要呢,有一个指标是—— -norm,下面对这个指标进行细说
-norm,下面对这个指标进行细说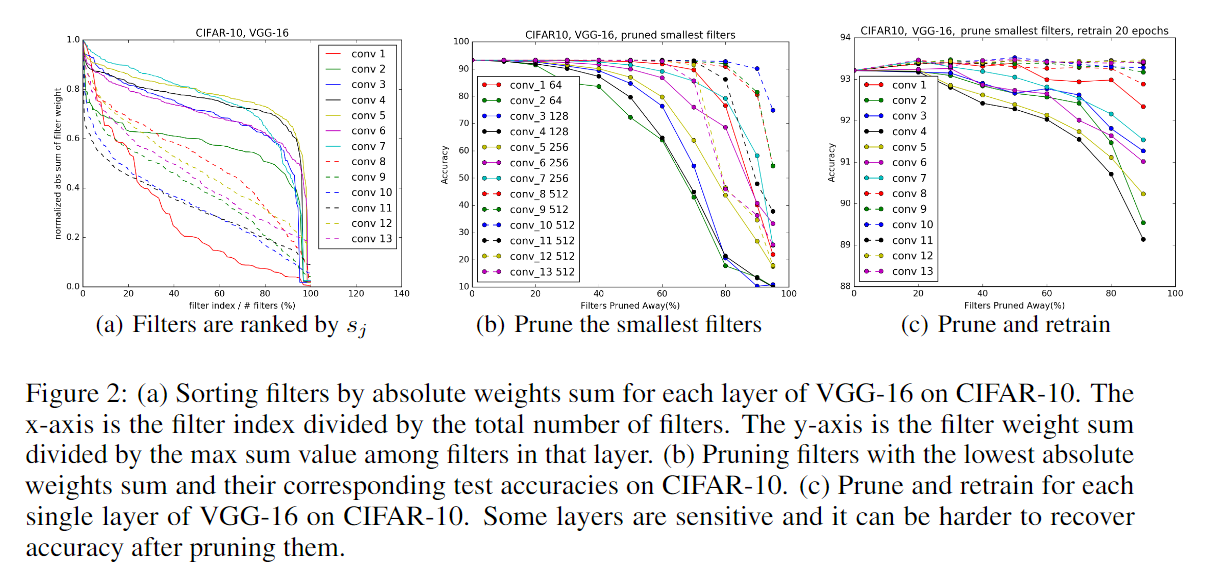
 表示第 i 层的一个卷积核,我们通过
表示第 i 层的一个卷积核,我们通过  (一个卷积核内所有权值绝对值的和 ——L1 正则项) 来表征每个层中该卷积核的重要性。Figure 2 (a) 展示了在 CIFAR-10 数据集上训练好的 VGG-16 网络中每一个卷积层中每个卷积核权重绝对值之和的分布,可以看到每层的分布是不同的,我们发现剪掉值最小的卷积核比随机(或剪最大)的效果要好,相比于基于其他的标准来衡量卷积核的重要性(比如基于激活值的 feature map 剪枝),l1-norm 确实是一个很好的选择卷积核的方法。
(一个卷积核内所有权值绝对值的和 ——L1 正则项) 来表征每个层中该卷积核的重要性。Figure 2 (a) 展示了在 CIFAR-10 数据集上训练好的 VGG-16 网络中每一个卷积层中每个卷积核权重绝对值之和的分布,可以看到每层的分布是不同的,我们发现剪掉值最小的卷积核比随机(或剪最大)的效果要好,相比于基于其他的标准来衡量卷积核的重要性(比如基于激活值的 feature map 剪枝),l1-norm 确实是一个很好的选择卷积核的方法。
从第 i 个卷积层剪掉 m 个卷积核的过程如下:
1. 对每个卷积核  ,计算它的权重绝对值之和
,计算它的权重绝对值之和  ;
;
2. 根据  排序;
排序;
3. 将 m 个权重绝对值之和最小的卷积核以及对应的 feature maps 剪掉。下一个卷积层中与剪掉的 feature maps 相关的核也要移除;
4. 一个对于第 i 层和第 i+1 层的新的权重矩阵被创建,并且剩下的权重参数被复制到新模型中;
确定每一层的剪枝对模型准确度的影响
为了弄清楚每层的敏感度,我们对每一层独立剪枝并在验证集上对剪枝后的网络进行评估。下图(也就是原始论文中Fig2 (b))展示了结果,可以明显看出斜率比较平缓的层对剪枝的敏感度更高,我们根据经验来决定对每一层的卷积核进行剪枝,对于深度网络(如 VGG-16 或 ResNets),我们观察到同一 stage(相同尺寸的特征图)对应的层对剪枝的敏感度相似,为了避免引入 layer-wise meta-parameters,我们对于同一 stage 的所有层使用相同的剪枝比例。对于那些敏感度高的层,剪枝时比例很小,甚至完全不进行剪枝。
高效的剪枝策略
确定每一层的卷积核的敏感性,然后逐层进行裁剪并重新训练,对于不是很深的网络可以适用,原因如下:
- 对于很深的网络,逐层剪枝再重新训练耗时严重;
- 整体剪枝的方法提供给网络稳健性的一个全局视野,从而产生一个更小的网络;
- 对于复杂的网络,一个整体的方法很有必要,比如对于 ResNet,对恒等映射特征图或者每个残差模块的第二个层剪枝会导致额外层的修剪;
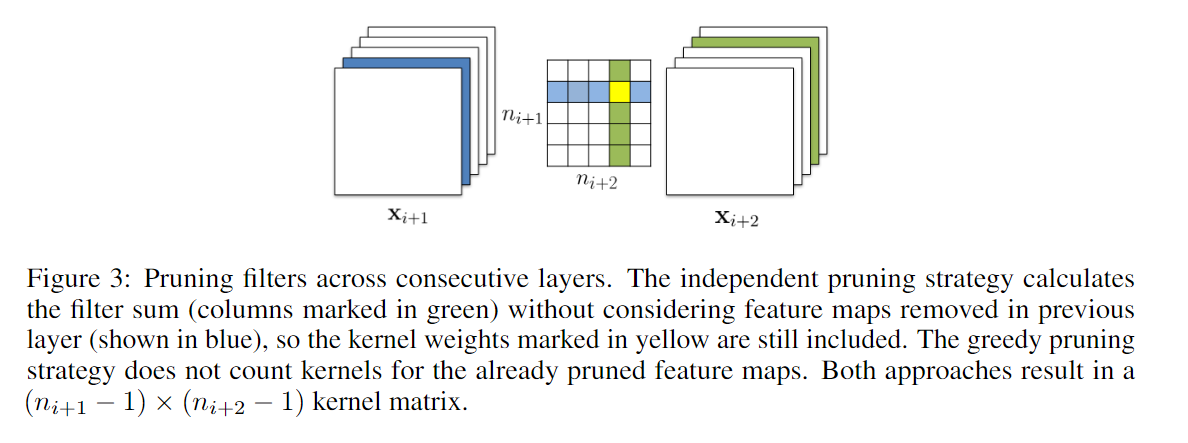
为了对多层同时剪枝,我们考虑了两个策略:
- 每一层独立剪枝,即在计算(求权重绝对值之和)时不考虑上一层的修剪情况,所以计算时下图中的黄点仍然参与计算;
- 贪心策略,计算时不计算已经修剪过的,即黄点不参与计算;
对于含有残差块的裁剪
对于简单的 CNN 网络,如 VGGNet 和 AlexNet,我们可以简单的对任意卷积层剪枝。然而,对于如 ResNet 这样的复杂网络,这是不可行的。ResNet 的结构对剪枝提出了限制条件,残差块中的第一个卷积层可以随意修剪,因为它不会改变残差块输出特征图的数目,然而第二个卷积层和特征映射的剪枝很困难。因此,为了残差模块的第二个卷积层进行剪枝,相关的 projected featured maps 必须也要剪掉,由于恒等特征映射要比添加的 residual maps 重要,对第二个层的剪枝应该由 shortcut 层的剪枝结果决定。为了决定那些恒等特征映射图被剪掉,我们对 shortcut 卷积层(1x1 卷积核)上采用相同的选择标准,即 residual block 中第二层修剪的 Filter index 与 shortcut layer 所选择的 Filter index 相同。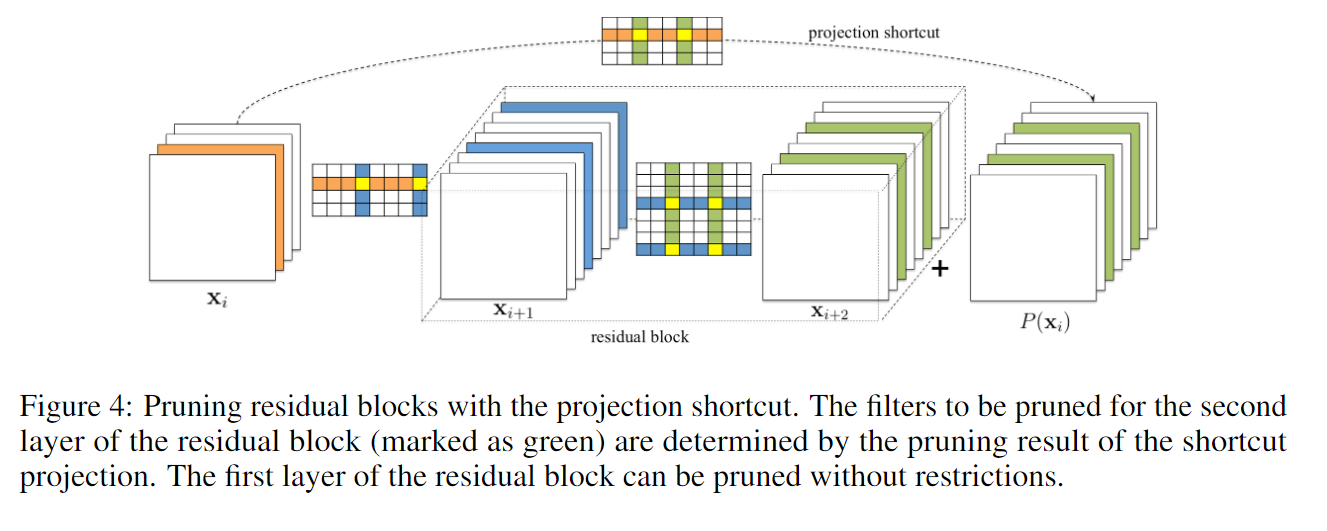 **
**
重新获得高精度
在剪枝过后,通过预训练可以补偿剪枝造成的精度损失,有两种策略:
- 一次剪枝和重新训练:一次性对多层的卷积核剪枝,然后重新训练直到原来的准确率恢复;
- 交替剪枝和训练:逐层或逐卷积核剪枝,然后再训练,重复多次。
对于具有修剪弹性的层,第一种方法可以用于删除网络的重要部分,并且可以通过短时间重新训练来恢复精度(小于原始训练时间)。但是,当敏感层的一些 Filter 被剪掉或大部分网络被剪掉时,可能无法恢复原始精度。这时第二种方法可能会产生更好的结果,但迭代过程需要更多的 epochs,特别是对于非常深的网络。
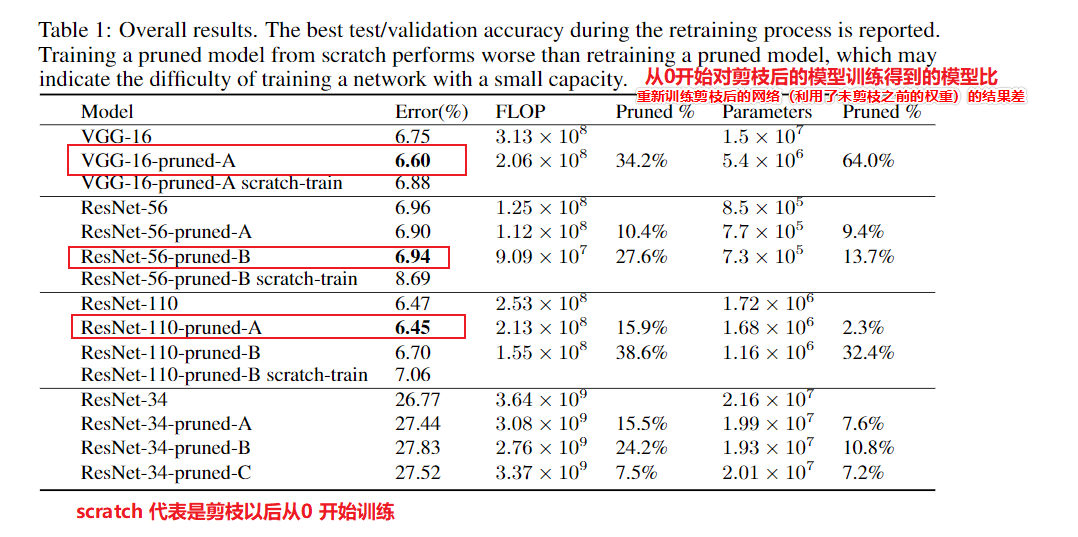
实验结果
Github 项目

若有收获,就点个赞吧
0 人点赞
