Focal Loss for Dense Object Detectionor Dense Object Detection
https://arxiv.org/pdf/1708.02002.pdf
https://zhuanlan.zhihu.com/p/60612064
https://mp.weixin.qq.com/s/2VZ_RC0iDvL-UcToEi93og
背景
One-Stage 算法的精度相对于 Two_Stage 偏低,然后作者把这种问题的原因归结于正负类别不平衡**(简单难分类别不平衡)。**
论文通过重新设计标准的交叉熵损失来解决这种难易样本不平衡的问题,即文章的核心 Focal Loss。结合了 Focal Loss 的 One-Stage 的目标检测器被称为 RetinaNet
基本概念
hard/esay postive/negtive example
- easy example: 易分样本,通俗的讲就是,比较容易分辨的样本,一般是对应概率比较大的样本,比如较好的前景(easy positive example),和较好的背景 (easy negative example)。
- hard example: 难分样本,通俗的讲就是,比较困难分辨的样本,一般是对应概率比较小的样本,比如背景与前景的边缘,包括(hard positive example,hard negative example)
- positive/negative example:IoU 大于阈值的就认为是 positive example 反之。
详细见下图
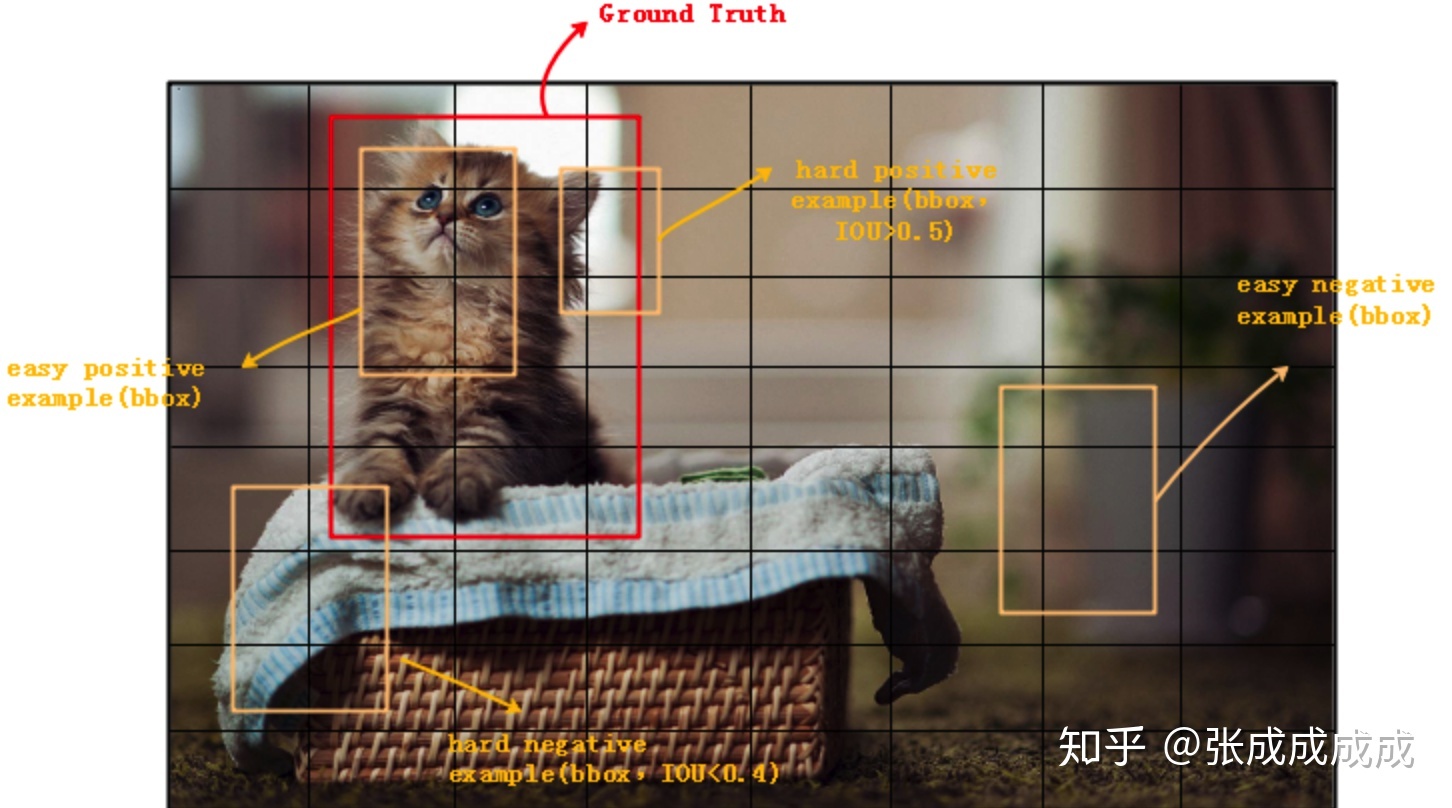
为什么 One-Stage 检测算法精度偏低?
一张图中,negative example 太多了
- 问题1、针对所有的 negtive example,数量过多造成它的 loss 太大,以至于主导了损失函数,不利于收敛(正负样本不平衡)。
- 问题2、针对单个 negtive example 来说,大多数的 negative example 不在前景和背景的过渡区域上(如上图最右边的框框),分类很明确 (这种易分类的 negative 称为 easy negative),训练时对应的背景类 score 会很大,换句话说就是单个 example 的 loss 很小,反向计算时梯度小。梯度小造成 easy negative example 对参数的收敛作用很有限,我们更需要 loss 大的对参数收敛影响也更大的 example,即 hard positive/negative example。(难易样本不平衡)
Faster-RCNN 为什么精度更高?
Faster-RCNN 在 FPN 阶段会根据前景分数提出最可能是前景的 example,这就会滤除大量背景概率高的 easy negtive 样本,这便解决了上面提出的问题2。同时,在生成样本给 ROIPooling 层的时候,会据 IOU 的大小来调整 positive 和 negative example 的比例,比如设置成 1:3,这样防止了 negative 过多的情况 (同时防止了 easy negative 和 hard negative),就解决了前面的问题1。因此,相对于 One-Stage 检测器,Faster-RCNN 的精度更高。
Focal Loss
一般的二分类交叉熵公式如下

结合交叉熵的 Focal Loss 损失如下: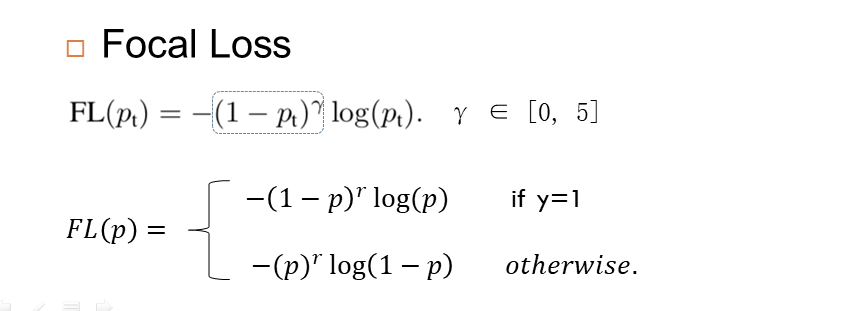
举个例子说明如何针对 easy example 在 Loss 上的平衡,当 r=2, p=0.9(大概率认为这个框是前景或者背景)计算损失时:
最终的 Focal Loss 如下:
 的加入是为了解决正负样本不平衡的问题,
的加入是为了解决正负样本不平衡的问题, 是为了解决难易样本不平衡的问题
是为了解决难易样本不平衡的问题
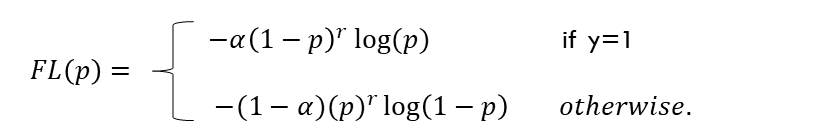
RetinaNet
Focal Loss 与 ResNet-101-FPN backbone 结合就构成了 RetinaNet(one-stage 检测器),RetinaNet 在 COCO test-dev 上达到 39.1mAP,速度为 5FPS。

若有收获,就点个赞吧
0 人点赞
