将 VOC 格式转换成 COCO 格式
import os.path as ospimport xml.etree.ElementTree as ETimport mmcvdef voc_classes():return ['aeroplane', 'bicycle', 'bird', 'boat', 'bottle', 'bus', 'car', 'cat','chair', 'cow', 'diningtable', 'dog', 'horse', 'motorbike', 'person','pottedplant', 'sheep', 'sofa', 'train', 'tvmonitor']from glob import globfrom tqdm import tqdmfrom PIL import Imagelabel_ids = {name: i + 1 for i, name in enumerate(voc_classes())}def get_segmentation(points):return [points[0], points[1], points[2] + points[0], points[1],points[2] + points[0], points[3] + points[1], points[0], points[3] + points[1]]def parse_xml(xml_path, img_id, anno_id):tree = ET.parse(xml_path)root = tree.getroot()annotation = []for obj in root.findall('object'):name = obj.find('name').textif name == 'waterweeds':continuecategory_id = label_ids[name]bnd_box = obj.find('bndbox')xmin = int(bnd_box.find('xmin').text)ymin = int(bnd_box.find('ymin').text)xmax = int(bnd_box.find('xmax').text)ymax = int(bnd_box.find('ymax').text)w = xmax - xmin + 1h = ymax - ymin + 1area = w*hsegmentation = get_segmentation([xmin, ymin, w, h])annotation.append({"segmentation": segmentation,"area": area,"iscrowd": 0,"image_id": img_id,"bbox": [xmin, ymin, w, h],"category_id": category_id,"id": anno_id,"ignore": 0})anno_id += 1return annotation, anno_iddef cvt_annotations(img_path, xml_path, out_file):images = []annotations = []# xml_paths = glob(xml_path + '/*.xml')img_id = 1anno_id = 1for img_path in tqdm(glob(img_path + '/*.jpg')):w, h = Image.open(img_path).sizeimg_name = osp.basename(img_path)img = {"file_name": img_name, "height": int(h), "width": int(w), "id": img_id}images.append(img)xml_file_name = img_name.split('.')[0] + '.xml'xml_file_path = osp.join(xml_path, xml_file_name)annos, anno_id = parse_xml(xml_file_path, img_id, anno_id)annotations.extend(annos)img_id += 1categories = []for k,v in label_ids.items():categories.append({"name": k, "id": v})final_result = {"images": images, "annotations": annotations, "categories": categories}mmcv.dump(final_result, out_file)return annotationsdef main():xml_path = r'E:\VOC\VOC2007/Annotations' # xml 所在文件夹img_path = r'E:\VOC\VOC2007/JPEGImages' # 图片所在文件夹print('processing {} ...'.format("xml format annotations"))cvt_annotations(img_path, xml_path, r'E:/VOC/all.json') # 保存的结果print('Done!')if __name__ == '__main__':main()
数据分析
VOC2007 总共有 9963 张图片,30638 个标注框
官方的 VOC2007 将其进行划分:训练集(2501张图片)、验证集(2510张图片)、测试集(4952张图片)
每个类别的标注框数量如下所示,可以看到训练集和测试集上每个类别的标注框数量是相等的(保证训练集和验证集的分布是一致的)

整个数据集(9963 张图片)的类别分布如下,可以看出,person 这个类别是最多的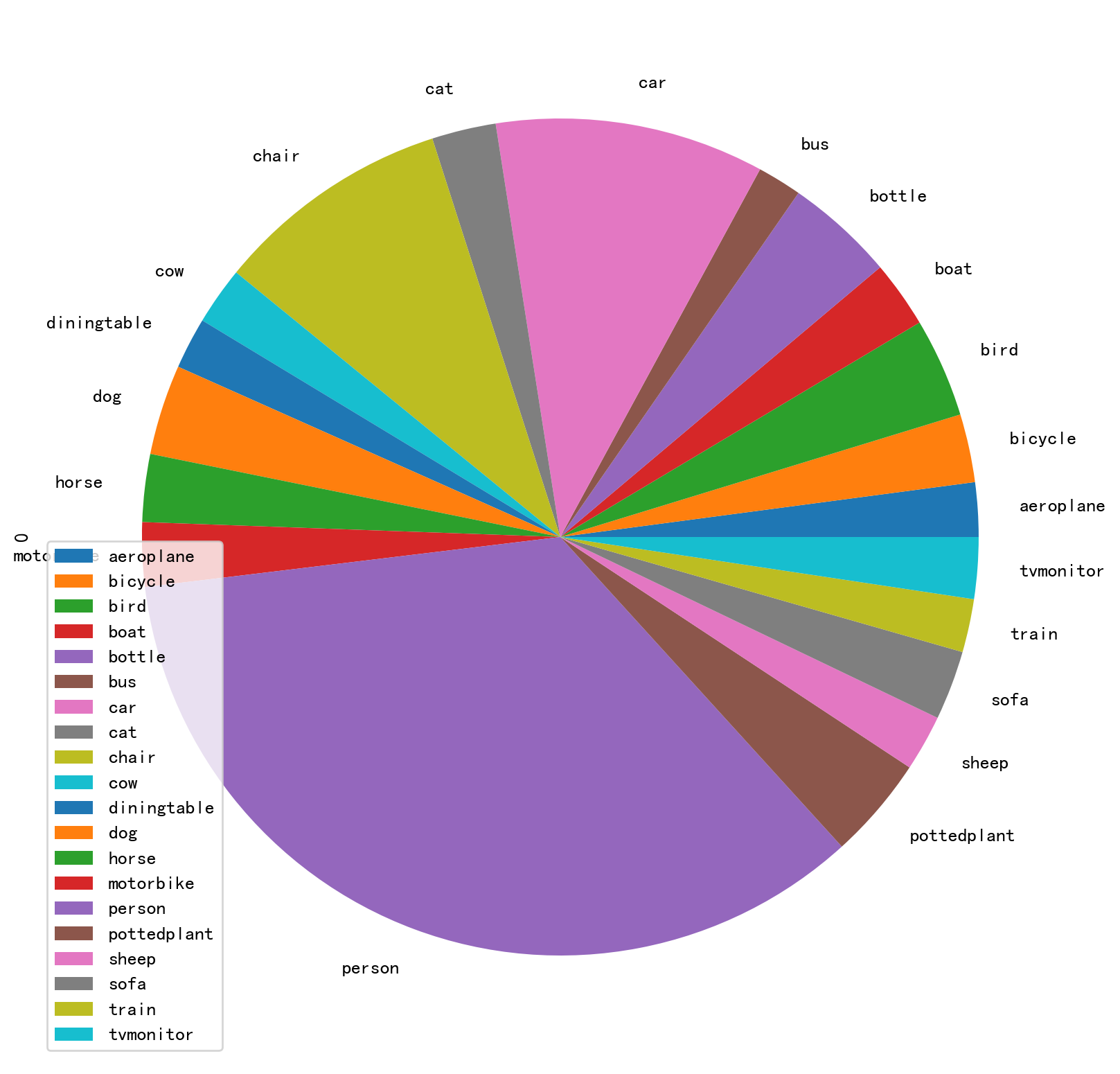

若有收获,就点个赞吧
0 人点赞
