本文实现了从项目调研、数据收集、数据预处理、深度卷积神经网络训练再到服务器部署,实现了一个人脸表情识别的小项目,非常适合新手进行实战学习,可以充分掌握一个项目的整体实现流程。
整个项目的代码以及数据集可以在文末获取!
0 项目成果
先展示一下我们本次项目的成功。我们测试的图片来自《将夜》电视剧中莫山山(图片来自互联网,侵删!)

选择图片文件上传,Upload 后就会返回预测结果,其中 smile 表示微笑,pout 表示嘟嘴,no-smile 表示中性表情。那么接下来就开始我们整个项目的讲解了
1 前言
作为一名深度学习的爱好者,提升自己的最好的方式就是参与一项项目,那么什么才能够称作项目呢?训练过 MNIST 数据集?做过 dogs VS. cats?想必这很难被称作一个项目,放在简历上,想必不能让 HR 看到闪光点。那么项目的定义是什么?个人在项目中的角色是什么?以及如何判断项目的成败?简单总结如下:
- 项目定义:给定时间费用的限制,达成特定的目的的工作
- 个人在项目中的角色:参与(某个环节)、主导(负责人)、独立承担
- 判断项目成败:开头的目标是什么,达成了就算成功,没达成就算失败。就算没有参加整个项目的流程,也需要关注子项目(自己做的部分)的成败
- 项目的是否高级:在规定时间、费用范围内产出更大的、投入更少的,都是“高级”项目;产出率低,耗时耗力多的就是“低级”项目
思维导图如下:
文字稿可以在此获取:https://mubu.com/doc/qoN0xUKmt0
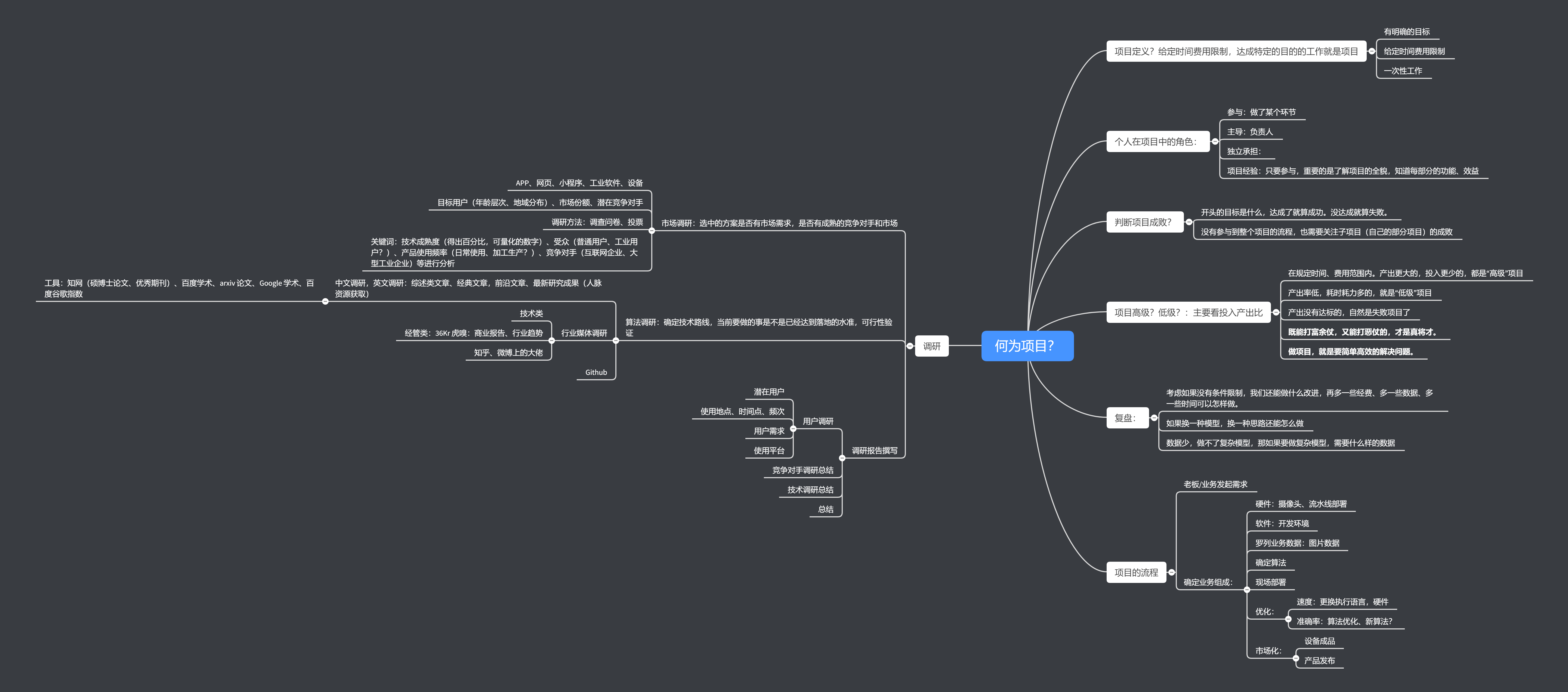
如果以后想从事相关工作,那么有一个实战项目加持,在简历上能够添光不少,并尽可能的去模拟企业开发产品的流程,让自己提前以实际开发者的心态来开发一款产品或者服务。于是我选择以人脸表情识别做为实战项目。
2. 为什么是人脸表情分类
深度学习入门时我们一般是以现成的数据集,官方的 Demo 作为开始,一步步调节参数,达到我们所需要的精度。但是在实际的企业开发流程中,往往涉及到流程之多,工程问题的细节也非常多。简单的流程可以归纳为如下:
- 老板/业务发起需求
- 确定业务组成
- 项目调研:市场调研、算法调研
- 确定算法及收集数据
- 确定框架、基准模型
- 服务端部署
人脸表情分类整个项目涉及到几个方面,如数据采集、数据预处理、人脸检测、人脸关键点检测、深度学习模型训练、模型在线部署等,不仅涉及到传统的机器学习,也与深度学习的相关知识紧密结合。故以人脸表情识别作为实战再合适不过了。
3. 项目调研
开始一个项目之前,肯定是做调研啦,调研包括市场调研和算法调研。
市场调研
市场调研需要了解市面上有没有相似的服务或者产品,如 APP、小程序、网页等;选中的方案是否有市场需求,是否有成熟的竞争对手和市场;看看我们所服务的内容的目标用户(年龄层次、地域分布)、市场份额以及潜在的竞争对手、是否已经达到落地水准。没有充分的调研,有可能你的产品做出来了,但是其实市场上已经有成熟的产品,那么前期投入的所有资源都白白浪费。所谓人无我有、人有我优、人优我廉、人廉我走 ,做到知根知底,不至于做出来时心里落差太大。
当然,对于我们这个小型的项目可能并不需要有上面的整个流程,但是大致也相似,我们需要了解市场上相似的产品,这里当然就是市面上有没有人脸表情识别的软件、小程序、API 等等。
在此之前,我们先简单介绍一下人脸表情识别的几个应用场景:
- 微表情在情绪识别任务上的可靠度很高,对表情情感识别任务有潜在的利用价值,如婚姻关系预测、交流谈判、教学评估等.除了用于情感分析,研究人员观察到了有意说谎时产生的微表情经过微表情识别训练,普通人识别说谎的能力得到提高;
- 金融领域:有报道显示,将微表情结合知识图谱的指南回答引擎,可以识别银行客户是否有欺诈风险;
- 智能家居:识别用户的行为,智能调节电器,更具智能化;
- 自动驾驶:监测分析驾驶过程中出现的分心、疲劳以及相关负面情绪波动,结合驾驶辅助系统提升驾驶安全;
- 教育领域:实时测量学习者对学习内容与学习过程中的情绪变化(如注意力集中、理解困惑、厌恶度等)。
接下来就是现有产品的测试啦!
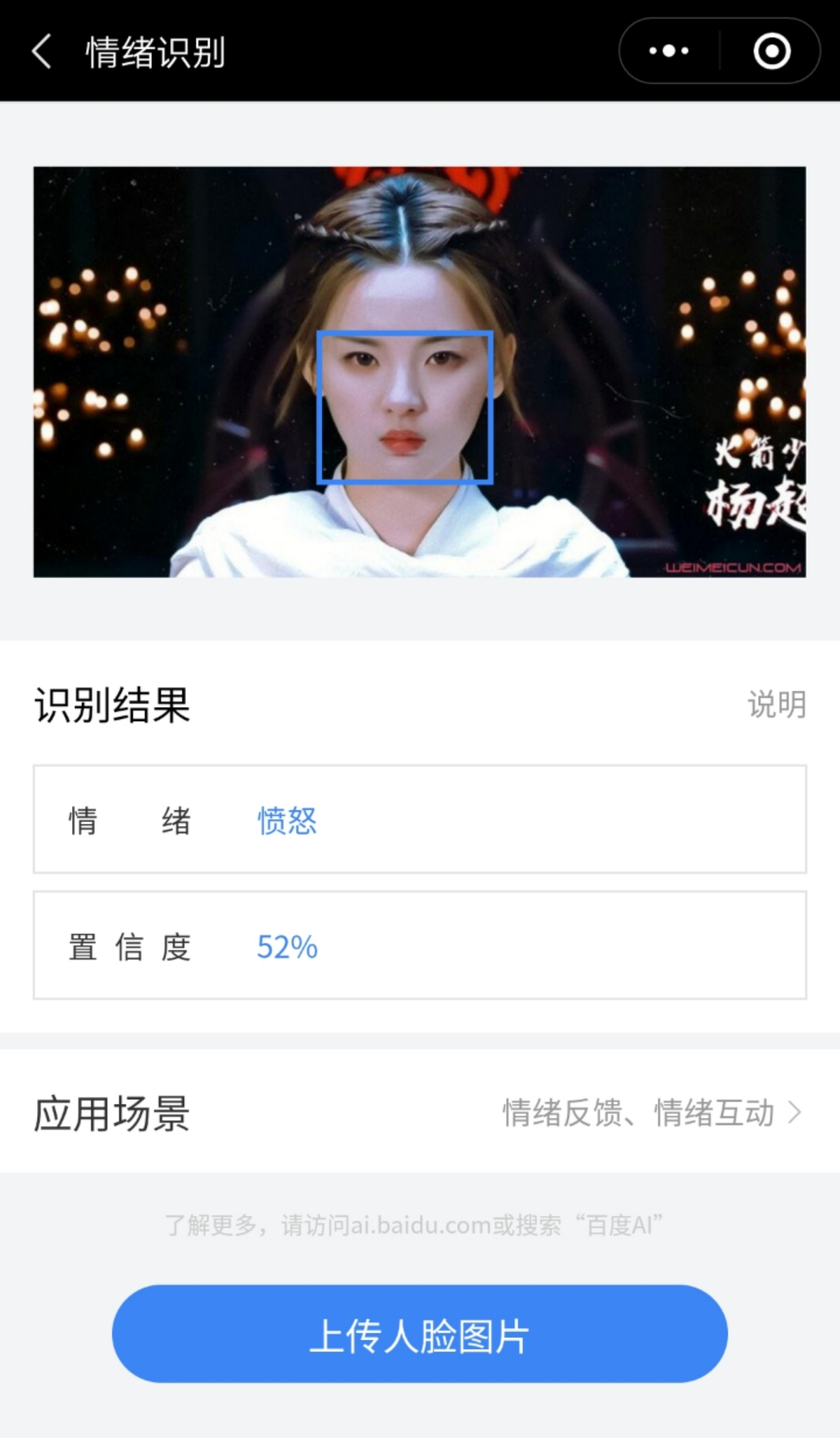
- 百度 AI 体验中心
在微信小程序搜索 百度 AI 体验中心,可以体验人脸与人体识别、语音技术等功能
- 旷视人工智能平台
在旷视人工智能平台 https://www.faceplusplus.com.cn/emotion-recognition/ 申请表情识别的 API 进行测试,目前 Face++ 能够识别愤怒、厌恶、恐惧、高兴、平静、伤心、惊讶等七类情绪。测试结果如下:在返回的结果中,微笑的程度是一个值为 [0,100] 的浮点数,小数点后 3 位有效数字。数值越大表示笑程度高。在程序处理中,我设定阈值为 60 ,即大于 60 就认为是微笑表情。具体参数可以参见官方文档:https://console.faceplusplus.com.cn/documents/4888373
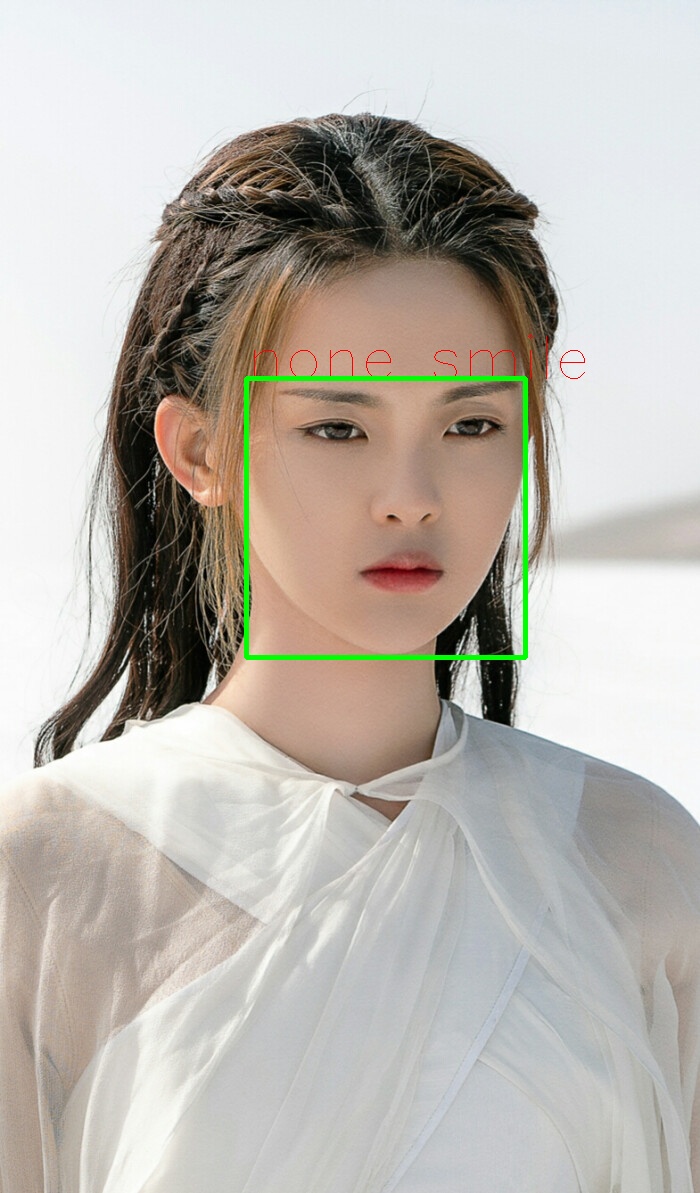
想尝试一下 Face++ 的同学可以在旷视平台(https://www.faceplusplus.com.cn/emotion-recognition/)上注册自己的 API,然后更换下面程序的 KEY 和 SECRET 值即可。
# -*- coding: utf-8 -*-import urllib.requestimport urllib.errorimport timeimport cv2import jsonhttp_url = 'https://api-cn.faceplusplus.com/facepp/v3/detect'key = "xxx" # "填上你的KEY"secret = "xxx" #"填上你的SECRET"filepath = r"./test_img/tiannv.jpg" # 测试图片路径boundary = '----------%s' % hex(int(time.time() * 1000))data = []data.append('--%s' % boundary)data.append('Content-Disposition: form-data; name="%s"\r\n' % 'api_key')data.append(key)data.append('--%s' % boundary)data.append('Content-Disposition: form-data; name="%s"\r\n' % 'api_secret')data.append(secret)data.append('--%s' % boundary)fr = open(filepath, 'rb')data.append('Content-Disposition: form-data; name="%s"; filename=" "' % 'image_file')data.append('Content-Type: %s\r\n' % 'application/octet-stream')data.append(fr.read())fr.close()data.append('--%s' % boundary)data.append('Content-Disposition: form-data; name="%s"\r\n' % 'return_landmark')data.append('1')data.append('--%s' % boundary)data.append('Content-Disposition: form-data; name="%s"\r\n' % 'return_attributes')data.append("gender,age,smiling,headpose,facequality,blur,eyestatus,emotion,ethnicity,beauty,mouthstatus,eyegaze,skinstatus")data.append('--%s--\r\n' % boundary)for i, d in enumerate(data):if isinstance(d, str):data[i] = d.encode('utf-8')http_body = b'\r\n'.join(data)# build http requestreq = urllib.request.Request(url=http_url, data=http_body)# headerreq.add_header('Content-Type', 'multipart/form-data; boundary=%s' % boundary)try:# post data to serverresp = urllib.request.urlopen(req, timeout=5)# get responseqrcont = resp.read()# if you want to load as json, you should decode first,# for example: json.loads(qrount.decode('utf-8'))#print(qrcont.decode('utf-8'))result = json.loads(qrcont.decode('utf-8'))print(result)smile_value = result['faces'][0]['attributes']['smile']['value'] # 微信值# 人脸位置face_rectangle = result['faces'][0]["face_rectangle"] # {'top': 318, 'left': 402, 'width': 296, 'height': 296}pt1 = (face_rectangle["left"], face_rectangle["top"])pt2 = (face_rectangle["left"]+face_rectangle["width"], face_rectangle["top"]+face_rectangle["height"])if float(smile_value) > 60:smile_flag = "smile"else:smile_flag = "none smile"img = cv2.imread(filepath)cv2.putText(img,smile_flag,pt1,fontFace=cv2.FONT_HERSHEY_SIMPLEX,fontScale=2,color=(0, 0, 255),thickness=1)cv2.rectangle(img, pt1, pt2, (0, 255, 0), 3)cv2.imwrite("tiannv.jpg", img)cv2.waitKey(0)cv2.destroyAllWindows()except urllib.error.HTTPError as e:print(e.read().decode('utf-8'))
- 其他:面向企业的产品
希亚思(上海)信息技术有限公司:http://www.cacshanghai.com/www/index.php?m=page&f=view&pageID=124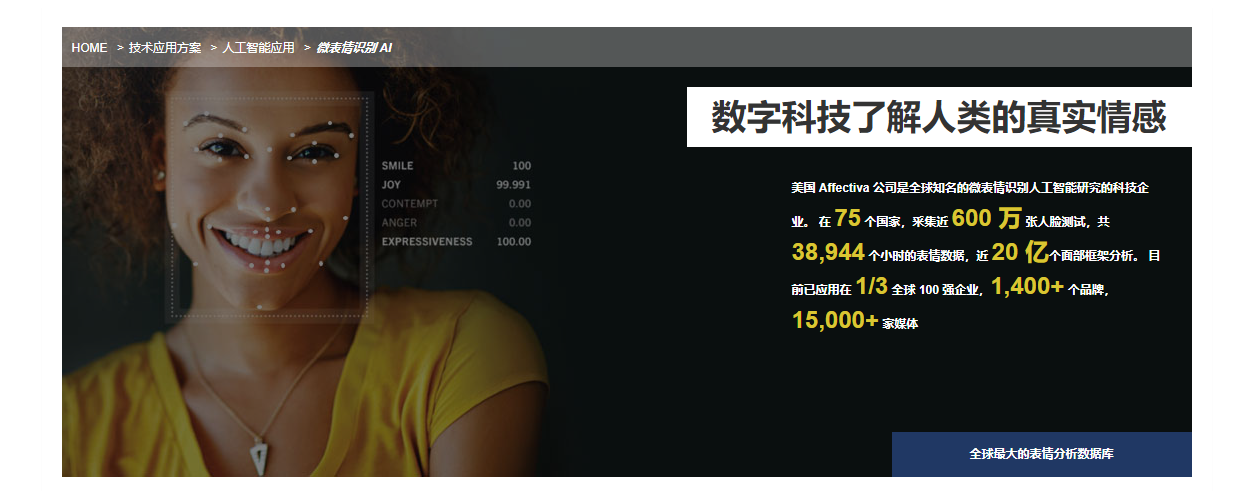
平安云https://yun.pingan.com/ssr/smart/WBQ
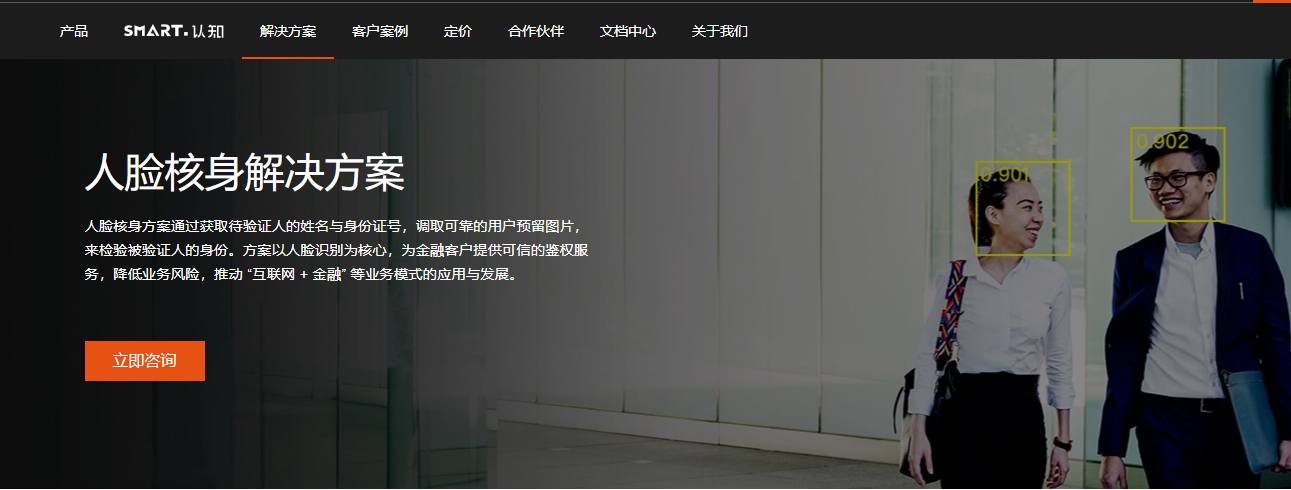
其中平安银行在 微表情国际权威评测OMG微表情竞赛 上获得第一名,可见平安银行在人脸表情识别上的技术突破,同时也看到表情识别在金融领域的使用也非常受欢迎。
算法调研
完成市场调研,接下来就是算法调研了,所谓的算法调研就是我们现在做的项目所使用的算法是什么,所能达到的精度如何
主要从几个方面入手:Paper 看看别人的文章,在知网或者 Google 学术上都能找到相关的文章,找找有没有相关的竞赛或者数据集,行业媒体报道也是一种手段,比如虎嗅、36Kr 都会发布相关的行业深度文章。
- 人脸微表情识别综述:http://html.rhhz.net/ZDHXBZWB/html/20170302.htm
- 基于SIFT算法的多表情人脸识别:http://html.rhhz.net/YJYXS/html/yj20161209.htm
- 何良华. 人脸表情识别中若干关键技术的研究[D]. 东南大学, 2005.
- 周书仁, 梁昔明, 朱灿,等. 基于ICA与HMM的表情识别[J]. 中国图象图形学报, 2008, 13(12):2321-2328.
- 周书仁. 人脸表情识别算法分析与研究[D]. 中南大学, 2009.
- 应自炉, 唐京海, 李景文,等. 支持向量鉴别分析及在人脸表情识别中的应用[J]. 电子学报, 2008, 36(4):725-730.
- Khorasani K. Facial expression recognition using constructive neural networks[C]// Signal Processing, Sensor Fusion, and Target Recognition X. Signal Processing, Sensor Fusion, and Target Recognition X, 2001:1588 - 1595.
- Kyperountas M, Tefas A, Pitas I. Salient feature and reliable classifier selection for facial expression classification[J]. Pattern Recognition, 2010, 43(3):972-986.
- Zheng W, Zhou X, Zou C, et al. Facial expression recognition using kernel canonical correlation analysis (KCCA).[J]. IEEE Transactions on Neural Networks, 2006, 17(1):233.
- 付晓峰. 基于二元模式的人脸识别与表情识别研究[D]. 浙江大学, 2008.
4. 数据收集
巧妇难为无米之炊,没有数据集的支撑,那么再厉害的深度学习模型也寸步难行,在开始训练模型之前我们要收集数据,基本的思路是先看看是否有开源数据集、若没有开源数据集,那么考虑互联网这个大宝库进行爬虫采集
本项目主要识别三种表情,分别是微笑、嘟嘴、中性表情,故我们所需要的数据也是围绕这三个表情展开的
首先,我们查找开源的数据集,可以从各大竞赛平台开始,比如 Kaggle 本身就是一个数据大宝库,我们发现在 Kaggle 上有个 CelebFaces Attributes (CelebA) Dataset 竞赛(地址:https://www.kaggle.com/jessicali9530/celeba-dataset),里面提供的数据包含 202599 张图片,每张图片共有 40 个属性,我们用到其中的 smiling 属性,每个类别选取 5-6k 图片,把图片拆分成微笑表情和中性表情两个文件夹

在采集到微笑和中性表情以后,接下来就是寻找有关嘟嘴的表情,笔者在网络上搜了一圈,找不到有关嘟嘴的表情的开源数据集,那么接下来考虑爬虫采集了。若你没有爬虫相关的知识,那么要在这一步就停滞不前了吗?不!Github 总有你要的资源~
本项目使用的以下两个开源的图片爬虫项目:关键词 “嘟嘴 pout”
下载下来为一个 exe 文件,运行并设置关键的参数,就可以从三大搜索引擎中爬取相关的图片

该项目只要下载下来,修改你要下载图片的关键词就能从百度上下载图片
通过以上方法,我从互联网上爬取了 1200+ 图片作为“嘟嘴”表情的训练集
5. 数据预处理
上一步中,我们从不同渠道获取到了训练集,那么在训练模型之前要对数据集进行清洗与整理,大致包括以下几个方面
- 数据规范化处理
- 数据整理分类
- 数据去噪
- 数据去重
- 数据存储与备份
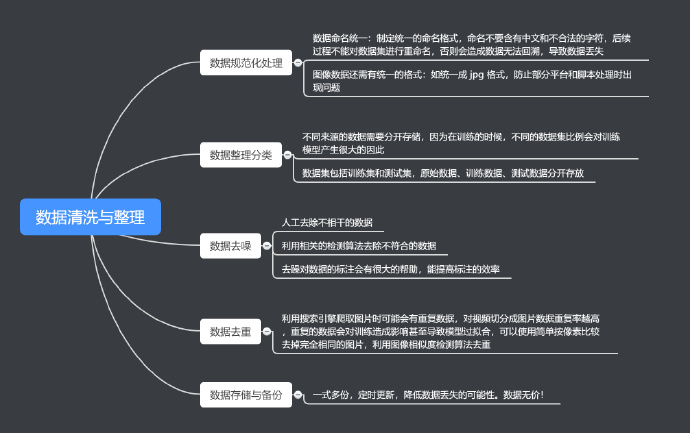
数据处理在整个项目中占比的时间也非常多、处理起来比较繁琐但是却是关键的一环,笔者在这个步骤花费了不少时间。
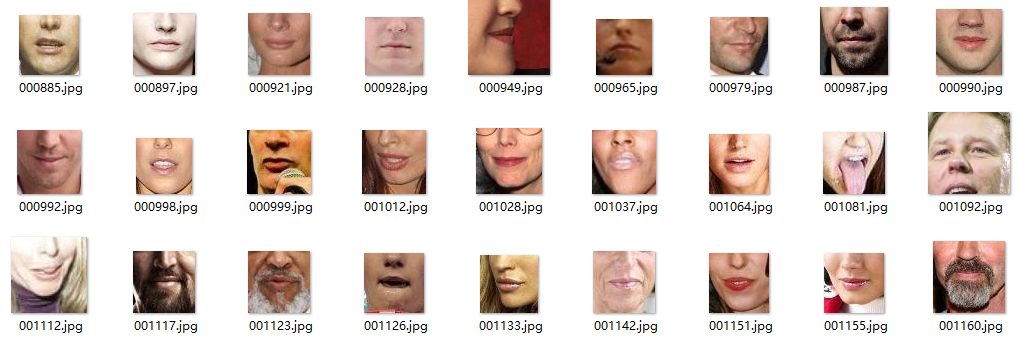
最终获取到的图像如下所示,那是不是意味着我们就可以马上开始搞模型,就开始训练了,事实上并非如此。如果有对微表情有了解的同学应该知道,人脸的表情是由面部结构决定的,如嘴巴、眉毛、眼睛、鼻子都会影响表情的表达,在本项目中,我们想实现的是嘴巴区域对表情的决定性,故我们可以将问题进行简化,我们只关注嘴巴的区域,这一区域影响了我们表情的表达。

对此,我们可以对采集下来的图像进行进一步的处理,把嘴巴区域给裁剪出来,作为我们模型的输入,一般裁剪下来的图片在 60-70 分辨率左右,对比把原图送进模型训练,这样子做大大降低了我们模型的训练时间。现在有很多人脸检测算法已经相当成熟,我们使用的是 OpenCV(图像处理的库)+dlib(人脸识别处理的库) 这两个库。在开始之前,我们需要安装他们,对于 OpenCV 安装比较简单,而对于 dlib 的安装,我们给出 Windows 和 Linux 下的安装方法,安装之前需要去 [https://pypi.org/simple/dlib/](https://pypi.org/simple/dlib/) 下载与设备向匹配的 whl 文件,通过 whl 的方法进行安装
安装 OpenCV
Windoes 和 Linux 下安装 OpenCV
pip install opencv-python
可能遇见的问题
若出现:libXrender.so.1: cannot open shared object file: No such file or directory 考虑安装下面的包
apt-get install libsm6apt-get install libxrender1apt-get install libxext-dev
安装 dlib
- Windows 下安装 dlib
pip install *.whl # * 是下载下来的 whl 文件的名字,安装过程比较缓慢,请耐心等待
- Linux 下安装 dlib
sudo apt-get install build-essential cmakesudo apt-get install libgtk-3-devsudo apt-get install libboost-all-devpip install dlib
经过关键点检测后,得到的效果如下所示,在本文中,我们使用的是 68 关键点检测,故只要提取出标号 48-67 的点周围的区域(嘴巴区域)即可

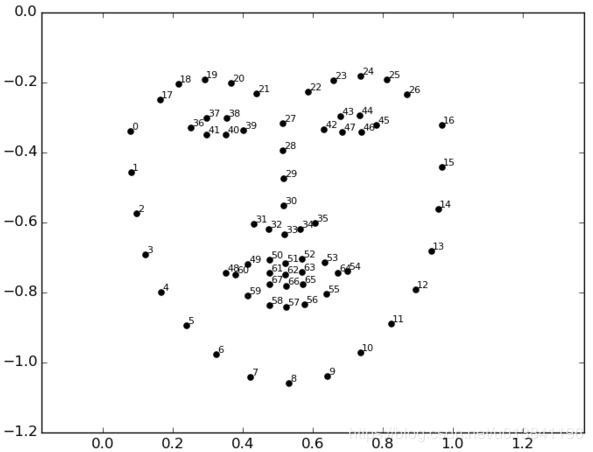
最终得到的结果如下所示:数据集大小是:微笑和中性表情各 1000 张,嘟嘴表情经过处理以后最终剩下 761 张
我们对数据集进行 9:1 的比例进行拆分,拆分成训练集和测试集
6. 选择框架基准模型
得到我们目标的数据集,那么下一步就是着手开始训练了,我们选择 PyTorch 这个深度学习框架,之后我们需要确定一个基准模型,由于我们的数据数量上并不是很多。若想要将深度学习应用于小型图像数据集,一种常用且非常高效的方法是使用预训练网络。预训练网络(pretrained network)是一个保存好的网络,之前已在大型数据集(通常是大规模图像分类任务)上训练好。如果这个原始数据集足够大且足够通用,那么预训练网络学到的特征的空间层次结构可以有效地作为视觉世界的通用模型,因此这些特征可用于各种不同的计算机视觉问题,即使这些新问题涉及的类别和原始任务完全不同。举个例子,你在 ImageNet 上训练了一个网络(其类别主要是动物和日常用品),然后将这个训练好的网络应用于某个不相干的任务,比如在图像中识别家具。这种学到的特征在不同问题之间的可移植性,是深度学习与许多早期浅层学习方法相比的重要优势,它使得深度学习对小数据问题非常有效。
一句话总结上面这一段就是,使用别人在大规模数据上训练的模型好参数,我们只修改最后的分类参数,然后应用到我们的数据集上,通常效果并不差,但是,由于我们的输入数据较小(只包含嘴巴区域,图像的像素在 50×50 左右,经典的神经网络的输入是 224×244 ),不能符合大部分基准模型的输入要求,故自行设计了一个简单的卷积神经网络,PyTorch 框架的代码如下:
class simpleconv3(nn.Module):def __init__(self):super(simpleconv3,self).__init__()self.conv1 = nn.Conv2d(3, 12, 3, 2)self.bn1 = nn.BatchNorm2d(12)self.conv2 = nn.Conv2d(12, 24, 3, 2)self.bn2 = nn.BatchNorm2d(24)self.conv3 = nn.Conv2d(24, 48, 3, 2)self.bn3 = nn.BatchNorm2d(48)self.fc1 = nn.Linear(48 * 5 * 5 , 1200)self.fc2 = nn.Linear(1200 , 128)self.fc3 = nn.Linear(128 , 3)def forward(self , x):x = F.relu(self.bn1(self.conv1(x)))#print "bn1 shape",x.shapex = F.relu(self.bn2(self.conv2(x)))x = F.relu(self.bn3(self.conv3(x)))x = x.view(-1 , 48 * 5 * 5)x = F.relu(self.fc1(x))x = F.relu(self.fc2(x))x = self.fc3(x)return x

7. 模型训练
由 ResNet18 作为基准模型,冻结所有的卷积层,只更改最后的分类器,以 Adam 优化器训练 500 个轮次得到如下结果,精度在 90% 左右,由于使用的是其他深度学习平台的算力,平台暂时无法下载训练结果的图片,所以截图了模型的训练精度及验证精度如下,总共 500 个轮次,可以看出在 260batch 左右网络就已经收敛了
- 模型训练精度曲线

- 模型验证精度曲线

8. 服务器部署
- 前端
模型训练完成以后,我们得到了一个以 .ckpt 为后缀的模型文件,我们将这个模型放到服务器,为了得到友好的交互,我们需要编写前端和后端处理的程序,前端我们使用的是 Flask 框架,根据官方的教程 [https://dormousehole.readthedocs.io/en/latest/](https://dormousehole.readthedocs.io/en/latest/) 结合 html 的模板,我们很快就能搭建出一个简单的 web 界面,包括一个上传文件按钮和图片显示页面以及文字描述等,整体效果如下:

#-*- coding:utf-8 -**from flask import Flask, requestfrom flask import render_templateimport timefrom expression_demo import expression_predict # 表情预测项目import osimport cv2system_path = "./"app = Flask(__name__) # 创建一个 Flask 实例,使用单一模块,应该使用 __name__@app.route('/')def hello(imgPath=None):return render_template('index.html', imgPath=system_path+"static/image/demo.jpg")@app.route('/upload', methods=['POST'])def upload(imgPath=None, result="None"):""":param imgPath: 上传的图片会保存在服务器里:param result: 预测的结果:return:"""file = request.files['file']fileName = file.filenamefilePath = system_path+"static"+os.sep+"image"+os.sep+fileName # 图片路径# print(filePath)if file:file.save(filePath)result = expression_predict(filePath)print(filePath)if result is None:result = "could not found your beauty face"return render_template('index.html', imgPath=filePath, result=result)else:return render_template('index.html', imgPath=system_path+"static"+os.sep+"image"+os.sep+"demo.jpg")if __name__ == '__main__':# 使你的服务器公开可用,WIN+R-> cmd -> ipconfig/all 可以看见主机名:在任意电脑输入 主机名:5000 即可看到效果app.run(host="0.0.0.0") #
- 后端处理
后端处理就是对用户上传的图片进行处理,包括我们前期所作的一些工作,如:读取用户上传的图片、进行人脸检测、人脸关键点检测、图片裁剪以及预测返回等操作,我们将预测功能封装成一个函数,然后在主函数中直接调用即可,以后的每一个项目都封装成单独的一个函数,直接做调用就能实现相关的功能
from expression_demo import expression_predict # 表情预测项目,将所有处理的函数写在一个 py 文件中,在主函数中进行导入
- 代码上传服务器
将部署的代码上传至服务器,并将主代码运行至后台,这样,服务器就能一直工作了,将代码运行至后台的代码如下,其中 main.py 就是你的主要函数啦!
至此,所有的步骤都已完成!
9. 总结与思考
在本项目中,我们从 0 开始实现了一个人脸表情识别的项目,从项目调研、数据收集、数据预处理、人脸检测、深度学习模型的训练再到前端编写、服务器部署等,基本上走过了一款小产品开发的所有流程。
在公司里面,可能一个项目有不同方向的员工参与,如前端工程师、后端工程师、算法工程师等,但是自己做项目的话,整个流程都需要你自己做,相当于全栈工程师的工作量,是对个人能力很好的锻炼,整个流程做下来,多多少少都会遇见不少的坑,但是只要耐心去解决,都是很好的成长机会,就像笔者对前端和服务端的知识并不熟悉,在其中遇到了非常多的坑。在往下思考,其实本项目还是有很多需要思考的地方。
这些都是实实在在的痛点所在,如下:
- 光照角度、侧脸等都会影响到人脸的检测,从而影响后续的预测结果
- 如何继续提高模型的精度
- 服务端遇到大的请求如何处理
- WEB 端的一些请求的逻辑处理等等
由于个人知识水平有限,欢迎提出意见~
本文部分测试图片来自互联网,侵删!
参考:
- 《深度学习之图像识别—核心技术与案例实战》作者:言有三
- https://github.com/tinypumpkin/face_process
- https://github.com/foamliu/Facial-Expression-Prediction
- http://www.cvmart.net/community/article/detail/211
- https://www.thoughtworks.com/insights/blog/emopy-machine-learning-toolkit-emotional-expression
- https://www.digitalocean.com/community/tutorials/how-to-serve-flask-applications-with-uswgi-and-nginx-on-ubuntu-18-04
- https://www.digitalocean.com/community/tutorials/how-to-install-nginx-on-ubuntu-18-04

若有收获,就点个赞吧
0 人点赞
