基本数据集介绍
MOT数据集
数据集用的最多的是 MOTChallenge,专注于行人追踪的。 https://motchallenge.net/
- 15 年的都是采集的老的数据集的视频做的修正。参考论文:MOTChallenge 2015: Towards a Benchmark for Multi-Target Tracking『https://arxiv.org/abs/1504.01942』
- 16 年的是全新的数据集,相比于 15 年的行人密度更高、难度更大。特别注意这个 DPM 检测器,效果非常的差,全是漏检和误检。参考论文:MOT16: A Benchmark for Multi-Object Tracking:『https://arxiv.org/abs/1603.00831』
- 17 年的视频和 16 年一模一样,只是提供了三个检测器,相对来说更公平。也是现在论文的主流数据集。
- 19 年的是针对特别拥挤情形的数据集,只有 CVPR19 比赛时才能提交。
KITTI 数据集
KITTI 数据集的是针对自动驾驶的数据集,有汽车也有行人,在 MOT 的论文里用的很少。http://www.cvlibs.net/datasets/kitti/index.php
MOT16
针对 MOT16 数据集介绍一下,它与 MOT15 数据的部分标注信息可能存在差别,需要注意~
MOT16 数据集是在 2016 年提出来的用于衡量多目标跟踪检测和跟踪方法标准的数据集,专门用于行人跟踪。
总共有 14 个视频,训练集和测试集各 7 个,这些视频每个都不一样,按照官网的说法,它们有些是固定摄像机进行拍摄的,有些是移动摄像机进行拍摄的,而且拍摄的角度各不一样(低、中、高度进行拍摄),拍摄的条件不一样,包括不同的天气,白天或者夜晚等,还具有非常高的人群密度,总之,这个数据集非常具有挑战性。
MOT16 数据集使用的检测器是 DPM,这个检测器在检测“人”这个类别上具有较好的性能。
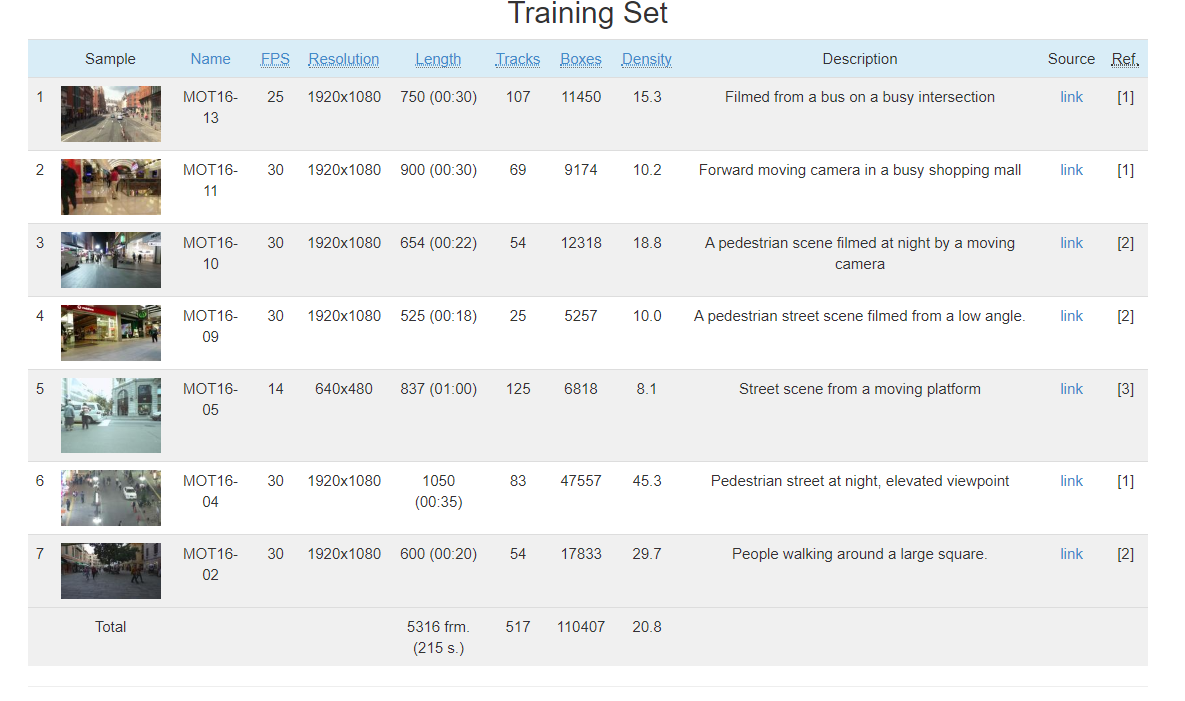
这些视频的主要信息如下:包括 FPS、分辨率、视频时长、轨迹数、目标书、密度、静止或者移动拍摄、低中高角度拍摄、拍摄的天气条件等。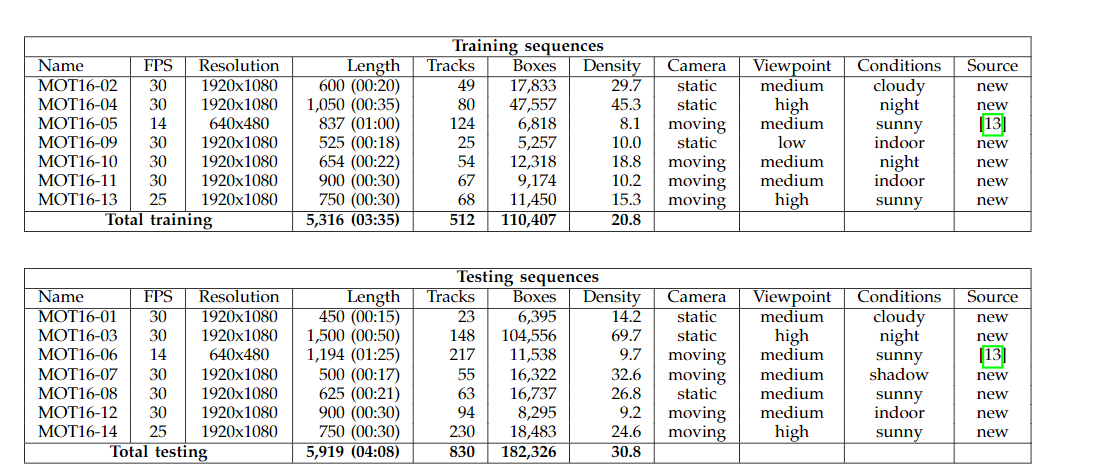
这些视频的检测框的信息如下: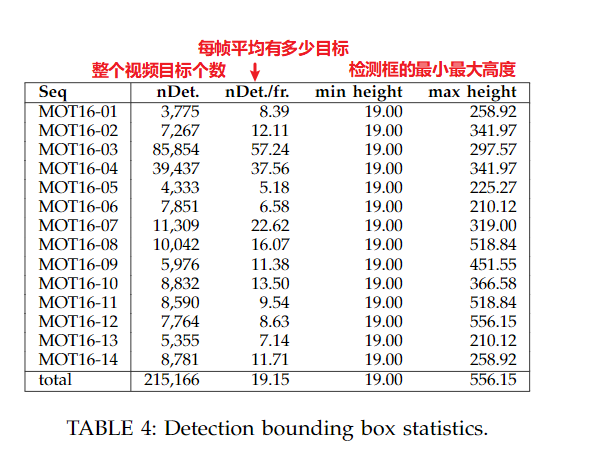
MOT16 数据的目录结构如下所示:包含训练集和测试集(各有7个视频)
每个子文件夹(如MOT16-01)代表一个视频转换后的数据集,包含几个文件或者文件夹,其目录结构与具体含义如下:
MOT16/├── test│ ├── MOT16-01│ │ ├── det│ │ │ └── det.txt│ │ ├── img1│ │ │ ├── 000001.jpg│ │ │ ├── xxxxxx.jpg│ │ │ └── 000450.jpg│ │ └── seqinfo.ini│ ├── MOT16-03│ ├── MOT16-06│ ├── MOT16-07│ ├── MOT16-08│ ├── MOT16-12│ └── MOT16-14│└── train├── MOT16-02│ ├── det│ │ └── det.txt│ ├── gt│ │ └── gt.txt│ ├── img1│ │ ├── 000001.jpg│ │ ├── xxxxxx.jpg│ │ └── 000600.jpg│ └── seqinfo.ini├── MOT16-04├── MOT16-05├── MOT16-09├── MOT16-10├── MOT16-11└── MOT16-13
- seqinfo.ini
文件内容如下,主要用于说明这个文件夹的一些信息,比如图片所在文件夹 img1,帧率,视频的长度,图片的长和宽,图片的后缀名。
[Sequence]name=MOT16-05imDir=img1frameRate=14seqLength=837imWidth=640imHeight=480imExt=.jpg
- det/det.txt
这个文件中存储了图片的检测框的信息 (这里用 MOT16-05 文件来说明,该文件下 img1 文件下有 837 张图片,代表视频的每一帧)
从左到右分别代表的意义是
- 第 1 个值:frame: 第几帧图片
- 第 2 个值:id: 这个检测框分配的 id,(由于暂时未定,所以均为 - 1)
- 第 3-6 个值:bbox (四位): 分别是左上角坐标(top, left)和宽(width)高(height)
- 第 7 个值:conf:这个 bbox 包含物体的置信度,可以看到并不是传统意义的 0-1,分数越高代表置信度越高
- 第8、9、10 个值:MOT3D (x,y,z): 是在 MOT3D 中使用到的内容,这里关心的是 MOT2D,所以都设置为 - 1
可以看出以上内容主要提供的和目标检测的信息没有区别,所以也在一定程度上可以用于检测器的训练。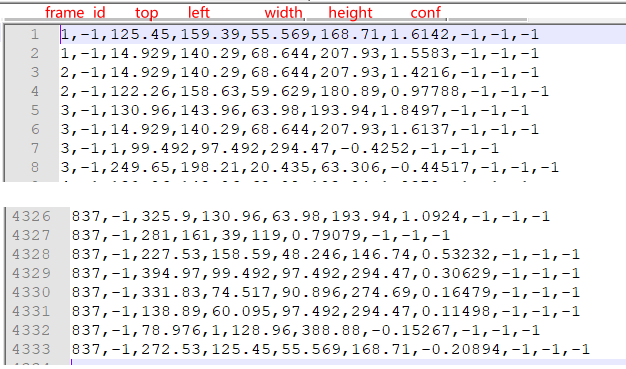
- img1 文件夹
这里面是将视频的每一帧抽取出来后的图片,图片格式是 jpg,按照视频流的顺序进行命名,如:xxxxxx.jpg
- gt/gt.txt 文件(train 训练集才有)
从左到右代表的含义是:
- 第 1 个值:frame: 第几帧图片
- 第 2 个值:ID: 也就是轨迹的 ID
- 第 3-6 个值:bbox: 分别是左上角坐标(top, left) 和宽(width)高(height)
- 第 7 个值:是否忽略:0 代表忽略(A value of 0 means that this particularinstance is ignored in the evaluation, while a value of1 is used to mark it as active.)
- 第 8 个值:classes: 目标的类别个数(这里是驾驶场景包括 12 个类别),7 代表的是静止的人。
第 8 个类代表错检,9-11 代表被遮挡的类别,12 代表反射,如下图中的第二列,可以看到店面的玻璃反射了路人的背景。
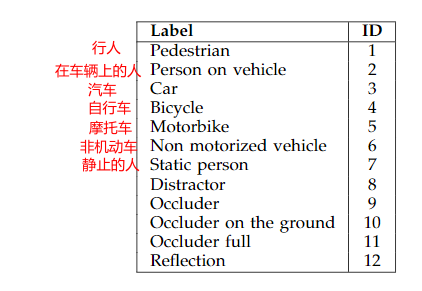

- 第 9 个值:代表目标运动时被其他目标包含、覆盖、边缘裁剪的情况。( The last number shows the visibility ratio of each bounding box. This can be due to occlusion by anotherstatic or moving object, or due to image border cropping.)
举个例子(该例子所在的视频是MOT16-05),在该视频中,有一位穿着类似于牛仔衣的老奶奶出现在视频的 1-381 帧,其中第 1 和第 376 帧视频截图如下,第 1 帧中这位老奶奶完全在视野中,所以,下面标注的第一行的最后一个值 1 代表没有被覆盖,在 376 帧的时候,老奶奶的身影部分已经超出视野了,所以下面标注第二行的最后一个值 0.56689 表示被遮挡 50% 左右。
1,1,17,150,77,191,1,1,1376,1,459,-27,258,594,1,1,0.56689

需要注意的是 gt/gt.txt 文件中的标注是按照轨迹顺序来标注的,什么意思呢,如果你打开 MOT16-05 的 gt.txt 文件你会发现从 1-381 行都是 轨迹 1 (上图绿框中的老奶奶)的标注,382-717行 是轨迹 2 的标注,以此类推…
PS:结合视频(https://motchallenge.net/vis/MOT16-05/gt/)与标注文件帮助理解
FairMOT项目数据加载
这里需要注意的是:MOT15 和 MOT16 的标志貌似有些差别,MOT15 在训练测试之前需要经过一步预处理,即在 FairMOT 项目中 src/gen_labels_15.py 文件。
FairMOT 项目加载数据的基本代码如下,最后通过 torch.utils.data.DataLoader 进行加载
class JointDataset(LoadImagesAndLabels): # for trainingdefault_resolution = [1088, 608]mean = Nonestd = Nonenum_classes = 1def __init__(self, opt, root, paths, img_size=(1088, 608), augment=False, transforms=None):self.opt = optdataset_names = paths.keys()self.img_files = OrderedDict()self.label_files = OrderedDict()self.tid_num = OrderedDict()self.tid_start_index = OrderedDict()self.num_classes = 1for ds, path in paths.items():with open(path, 'r') as file:self.img_files[ds] = file.readlines()self.img_files[ds] = [osp.join(root, x.strip()) for x in self.img_files[ds]]self.img_files[ds] = list(filter(lambda x: len(x) > 0, self.img_files[ds]))self.label_files[ds] = [x.replace('images', 'labels_with_ids').replace('.png', '.txt').replace('.jpg', '.txt')for x in self.img_files[ds]]for ds, label_paths in self.label_files.items():max_index = -1for lp in label_paths:lb = np.loadtxt(lp)if len(lb) < 1:continueif len(lb.shape) < 2:img_max = lb[1]else:img_max = np.max(lb[:, 1])if img_max > max_index:max_index = img_maxself.tid_num[ds] = max_index + 1last_index = 0for i, (k, v) in enumerate(self.tid_num.items()):self.tid_start_index[k] = last_indexlast_index += vself.nID = int(last_index + 1)self.nds = [len(x) for x in self.img_files.values()]self.cds = [sum(self.nds[:i]) for i in range(len(self.nds))]self.nF = sum(self.nds)self.width = img_size[0]self.height = img_size[1]self.max_objs = opt.Kself.augment = augmentself.transforms = transformsprint('=' * 80)print('dataset summary')print(self.tid_num)print('total # identities:', self.nID)print('start index')print(self.tid_start_index)print('=' * 80)def __getitem__(self, files_index):for i, c in enumerate(self.cds):if files_index >= c:ds = list(self.label_files.keys())[i]start_index = cimg_path = self.img_files[ds][files_index - start_index]label_path = self.label_files[ds][files_index - start_index]imgs, labels, img_path, (input_h, input_w) = self.get_data(img_path, label_path)for i, _ in enumerate(labels):if labels[i, 1] > -1:labels[i, 1] += self.tid_start_index[ds]output_h = imgs.shape[1] // self.opt.down_ratiooutput_w = imgs.shape[2] // self.opt.down_rationum_classes = self.num_classesnum_objs = labels.shape[0]hm = np.zeros((num_classes, output_h, output_w), dtype=np.float32)wh = np.zeros((self.max_objs, 2), dtype=np.float32)reg = np.zeros((self.max_objs, 2), dtype=np.float32)ind = np.zeros((self.max_objs, ), dtype=np.int64)reg_mask = np.zeros((self.max_objs, ), dtype=np.uint8)ids = np.zeros((self.max_objs, ), dtype=np.int64)draw_gaussian = draw_msra_gaussian if self.opt.mse_loss else draw_umich_gaussianfor k in range(num_objs):label = labels[k]bbox = label[2:]cls_id = int(label[0])bbox[[0, 2]] = bbox[[0, 2]] * output_wbbox[[1, 3]] = bbox[[1, 3]] * output_hbbox[0] = np.clip(bbox[0], 0, output_w - 1)bbox[1] = np.clip(bbox[1], 0, output_h - 1)h = bbox[3]w = bbox[2]if h > 0 and w > 0:radius = gaussian_radius((math.ceil(h), math.ceil(w)))radius = max(0, int(radius))radius = self.opt.hm_gauss if self.opt.mse_loss else radiusct = np.array([bbox[0], bbox[1]], dtype=np.float32)ct_int = ct.astype(np.int32)draw_gaussian(hm[cls_id], ct_int, radius)wh[k] = 1. * w, 1. * hind[k] = ct_int[1] * output_w + ct_int[0]reg[k] = ct - ct_intreg_mask[k] = 1ids[k] = label[1]ret = {'input': imgs, 'hm': hm, 'reg_mask': reg_mask, 'ind': ind, 'wh': wh, 'reg': reg, 'ids': ids}return ret
参考
https://zhuanlan.zhihu.com/p/97449724
https://zhuanlan.zhihu.com/p/109764650

若有收获,就点个赞吧
0 人点赞
