A Simple Baseline for Multi-Object Tracking
Introduction
Related Work
介绍了在 MOT 领域的两种方案:two-step 和one-shot ,讨论他们的优缺点并进行比较
Two-Step MOT Methods
将目标检测和 Re-ID 做为两个任务来做。第一步是通过CNN定位出一些 bbox,然后对检测框提取 Re-ID 特征,然后连接这些检测框形成轨迹。标准的一个流程是:框连接——通过 Re-ID 特征和 bbox 的 IoU 计算损失矩阵,然后根据卡尔曼滤波和匈牙利算法完成连接任务。也有一些算法使用了更复杂的关联策略,如组模型和RNNs。
Two-Step 的优点是可以为每个子任务(目标检测和Re-ID)找到最优的模型,不用考虑两者的关联。此外,还可以根据检测到的边框信息来预测Re-ID的特征,这样有助于处理多尺度变化。但是,Two-Step 的速度慢,这是因为两个任务之间没有共用特征,导致大量的计算,很难达到视频速率的推理。
One-Shot MOT Methods
One-Shot 的主要核心理念就是将目标检测和Re-ID 两个任务用同样的网络完成,为的是通过共享更多计算量从而减少推理的时间,代表的作品有 Track-RCNN、JDE。与目标检测中的 One-Stage 同理,目标跟踪 One-Shot 方法对比 Two-Step 方法跟踪精度会更低。作者认为这是因为 One -Shot 学习到的 Re-ID 特征不是最优的,所以导致了大量的 IDSW( ID switches)。作者深入研究后发现 “在对象检测和身份嵌入中使用锚点是导致结果降级的主要原因。特别是,对应于对象不同部分的多个附近的锚点,可能会造成估计相同的身份,从而导致网络训练的歧义。”
所以作者建议使用 anchor-free 的方法来进行目标检测和 identity embedding ,提升目标跟踪的精度。**
The Technical Approach
这里将会介绍 FairMOT 网络的骨干结构、目标检测分支和Re-ID feature embedding 分支
Backbone Network
研究者们使用 ResNet-34 作为骨干结构,以便平衡检测精度和速度。为了适应不同尺度的对象,作者在 Backbone 的基础上使用了 DLA (Deep Layer Aggregation,https://arxiv.org/abs/1707.06484)变体,结构图如下: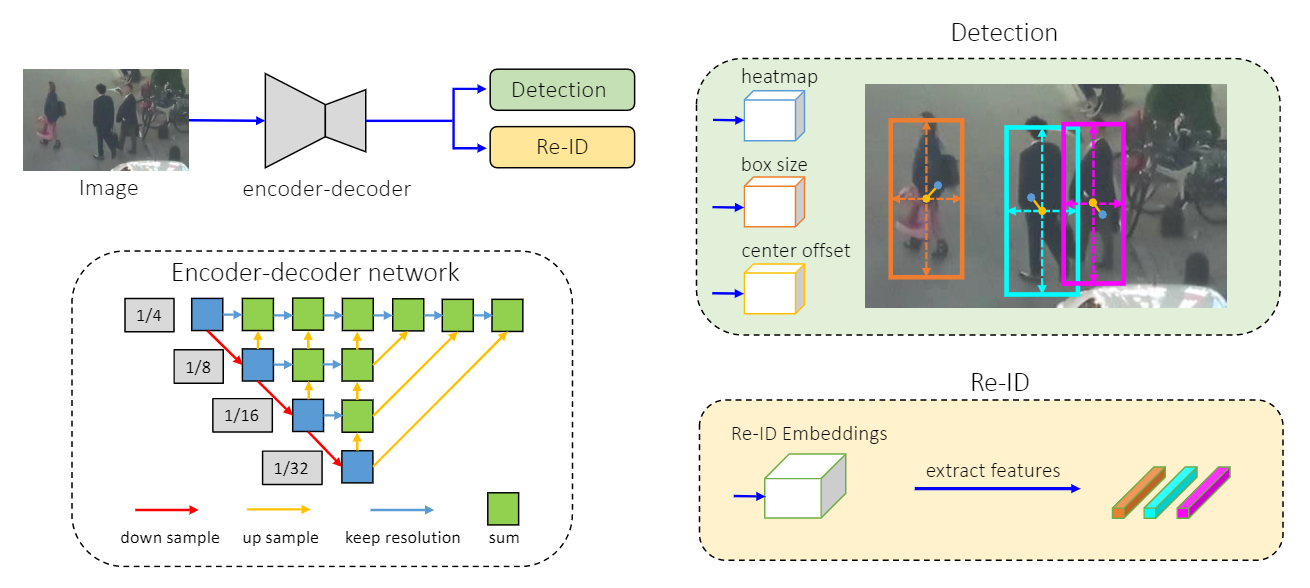
与原始的 DLA 不同的是,在低层和高层特征之间有更多的跳变连接『与特征金字塔网络(Feature Pyramid Network, FPN) 相似』此外,在上采样模块中所有的卷积层都被可变形的卷积层所替代,以便根据目标尺度和姿态动态调整接收域。这样的模型称作:DLA-34,输入用  表示,则输出大小为
表示,则输出大小为  ,这里
,这里 
Experiments
Conclusion
分析了之前的方法如:Towards real-time multi-object tracking. 不能取得 two-step methods. 性能的原因,主要是因为锚的存在,提出一种 anchor-free 的方法anchor-fre

若有收获,就点个赞吧
0 人点赞
