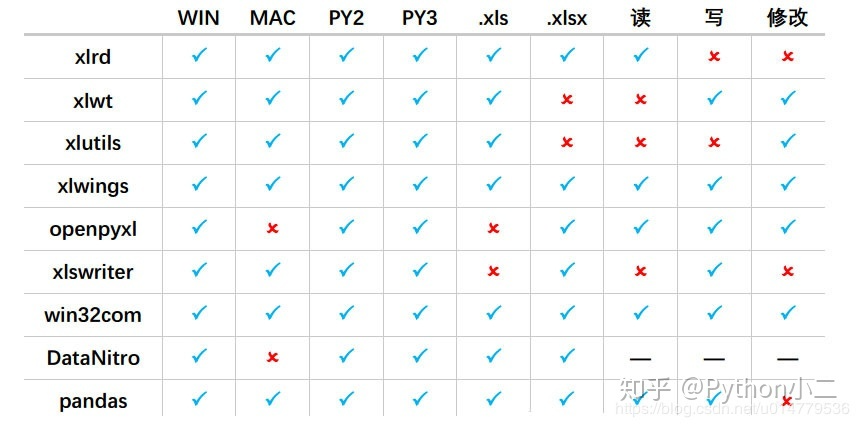
Pandas
读取与索引
索引
df[["k1", "k2"]] # 获取列名为 k1 和 k2 的列df[df["k1"].str.contains("v1")] # 获取列名为 k1 中含有 v1 的行
值修改
根据条件修改值
df.loc[df["k1"]=="v1", "k2"] = "v2" # 如果满足 条件是列名为k1 的值为 v1 ,则将列名为 k2 的值修改为 v2df.loc[((df["k1"]=="v1") & (df["k2"]=="v2")), "k3] = "v3" # 多重条件,修改值
数据透视表
pandas.pivot_table(*data*, *values=None*, *index=None*, *columns=None*, *aggfunc='mean'*, *fill_value=None*, *margins=False*, *dropna=True*, *margins_name='All'*, *observed=False*)
使用前将要数据透视表的数据提取出来,再进行数据透视表,好像只需要 index, columns 参数来判断行和列各自为什么即可
- data:dataframe格式数据
- values:需要汇总计算的列,可多选
- index:行分组键,一般是用于分组的列名或其他分组键,作为结果DataFrame的行索引
- columns:列分组键,一般是用于分组的列名或其他分组键,作为结果DataFrame的列索引
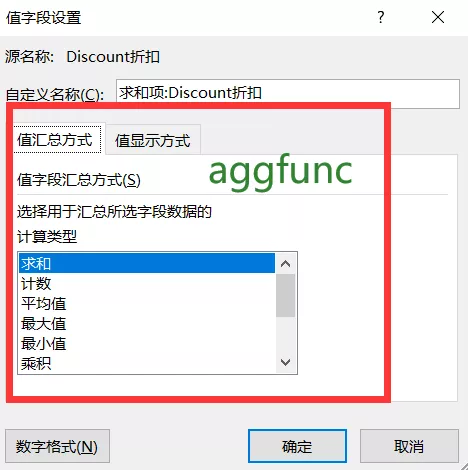
- aggfunc:聚合函数或函数列表,默认为平均值:
- 计数:len
- 求和:np.sum,
- 平均值:np.mean
- 最大值:max )
- fill_value:设定缺失替换值
- margins:是否添加行列的总计
- dropna:默认为True,如果列的所有值都是NaN,将不作为计算列,False时,被保留
- margins_name:汇总行列的名称,默认为All
- observed:是否显示观测值

修改格式
df["k1"] = df["k1"].map(lambda x: str(x), na_action="ignore") # 将 k1 列修改为文本格式,遇到空值是忽略
openpyxl
在openpyxl中,主要用到三个概念:Workbooks,Sheets,Cells。
- Workbook就是一个excel工作表;
- Sheet是工作表中的一张表页;
- Cell就是简单的一个格。
列名与数值的转换
from openpyxl.utils import get_column_letter, column_index_from_string# 根据列的数字返回字母print(get_column_letter(2)) # B# 根据字母返回列的数字print(column_index_from_string('D')) # 4
单元格格式
合并单元格
from openpyxl import load_workbookwb = load_workbook(r"xlsx 文件路径") # 加载 excel 表sheet = wb.get_sheet_by_name("Sheet1") # 获取 sheet 表sheet.merge_cells('A1:D1') # 合并一行中的几个单元格 #合并单元格 A1:D!wb.save((r"C:\Users\asus pc\Desktop\新建文本文档2.xlsx")) # 保存

若有收获,就点个赞吧
0 人点赞
