卷积神经网络之-GoogLeNet / Inception-v1

简介
论文地址:https://arxiv.org/abs/1409.4842
Inception 是一个代号,是 Google 提出的一种深度卷积网络架构(PS:有一部电影的英文名就是它,中文名叫做盗梦空间)。

Inception 的第一个版本也叫 GoogLeNet,在 2014 年 ILSVRC(ImageNet 大规模视觉识别竞赛)的图像分类竞赛提出的,它对比 ZFNet(2013 年的获奖者)和 AlexNet (2012 年获胜者)有了显着改进,并且与 VGGNet(2014 年亚军)相比错误率相对较低。是 2014 年的 ILSVRC 冠军。
GoogLeNet 一词包含 LeNet ,这是在向第一代卷积神经网络为代表的 LeNet 致敬。
1×1 卷积
1×1 卷积最初是在 NiN 网络中首次提出的,使用它的目的是为了增加网络非线性表达的能力。
GoogLeNet 也使用了 1×1 卷积,但是使用它的目的是为了设计瓶颈结构,通过降维来减少计算量,不仅可以增加网络的深度和宽度,也有一定的防止过拟合的作用。
以下对比使用 1×1 卷积前后计算量的对比,看看 1×1 卷积是如何有效减少参数的。
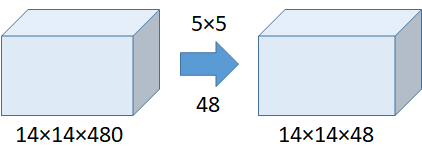
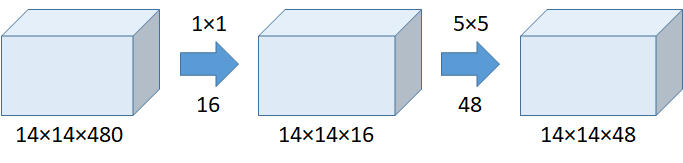

从上表可以看出,使用 1×1 卷积,参数量只有未使用 1×1 卷积的 5.3/112.9=4.7%,大幅度减少了参数量。
Inception 模块
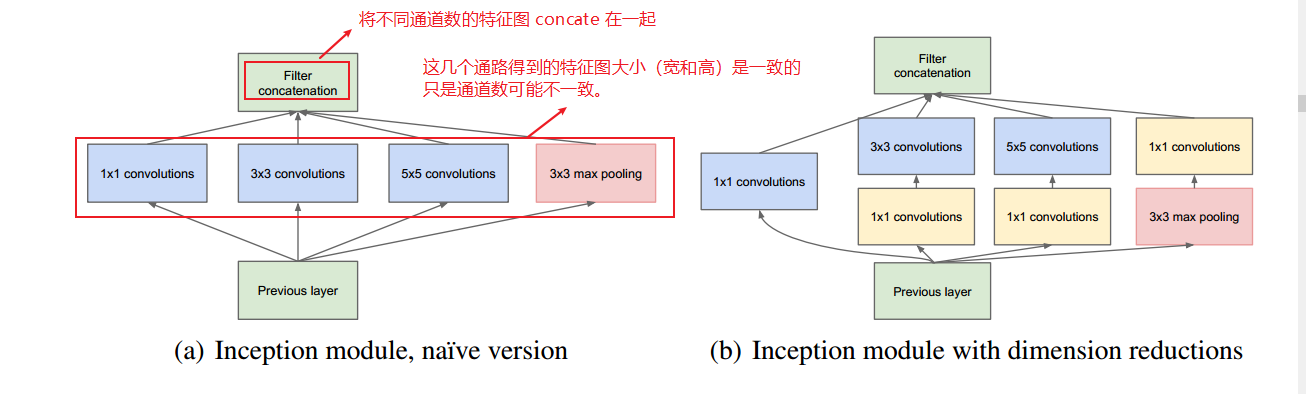
上图中,图(a) 是不带 1×1 卷积的版本,不具备降维的作用,图(b) 是带 1×1 卷积的版本,具有降维的作用,可以降低参数量。
Inception 模块有四条通路,包括三条卷积通路和一条池化通路,具有不同的卷积核大小,不同卷积核大小可以提取不同尺度的特征。最后将不同通路提取的特征 concate 起来,不同通路得到的特征图大小是一致的。
总体架构
GoogLenet 网络的结构如下,总共有 22 层,主干网络都是全部使用卷积神经网络,仅仅在最终的分类上使用全连接层。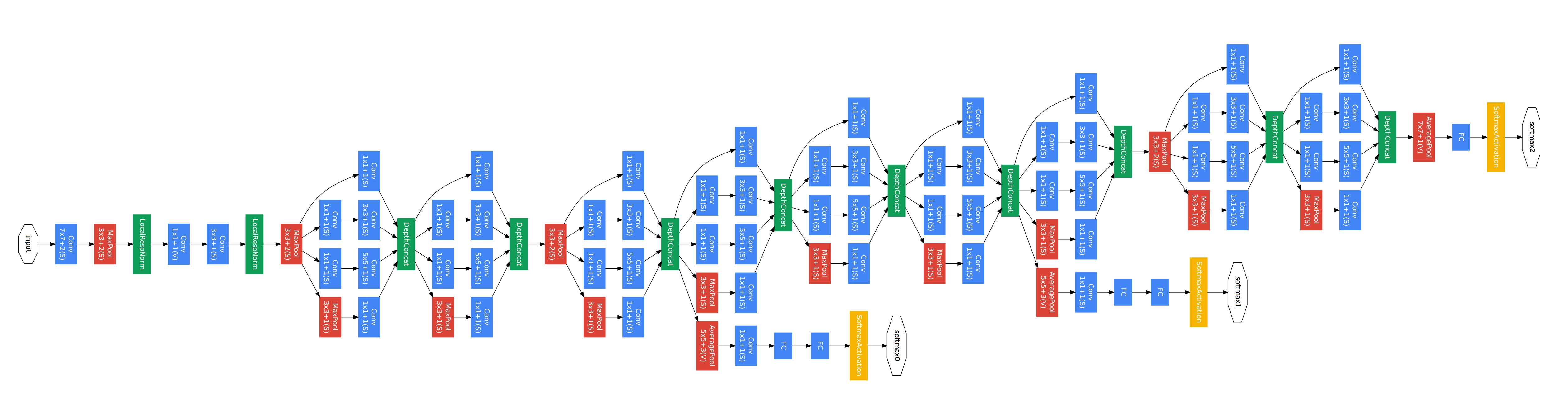
可以在 GoogLeNet 看到多个 softmax 分支,网络越深,越影响梯度的回传,作者希望通过不同深度的分支增加梯度的回传,用于解决梯度消失问题,并提供一定的正则化,所以在训练阶段使用多个分支结构来进行训练,它们产生的损失加到总损失中,并设置占比权重为 0.3,但是这些分支结构在推理阶段不使用。它们的详细参数可以看下图的注释
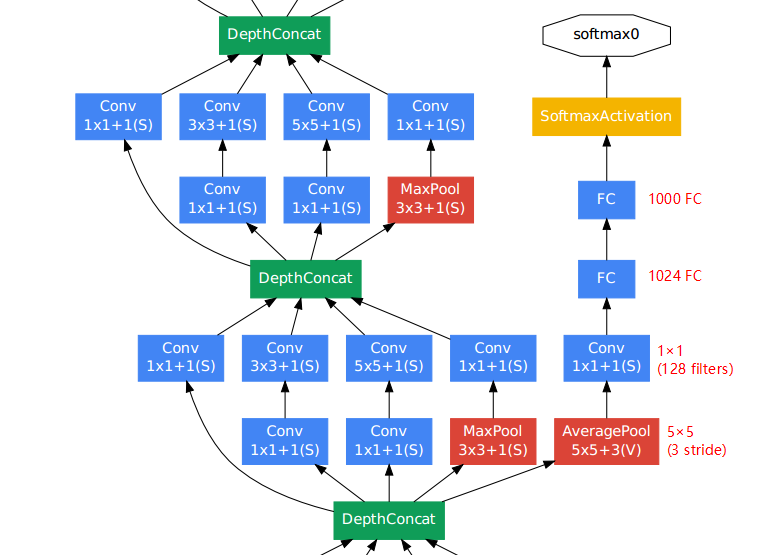
各层网络的具体参数见下表
代码实现
Inception 模块
class Inception(nn.Module):def __init__(self,in_ch,out_ch1,mid_ch13,out_ch13,mid_ch15,out_ch15,out_ch_pool_conv,auxiliary=False):# auxiliary 用来标记是否要有一条 softmax 分支super(Inception,self).__init__()self.conv1 = nn.Sequential(nn.Conv2d(in_ch,out_ch1,kernel_size=1,stride=1),nn.ReLU())self.conv13 = nn.Sequential(nn.Conv2d(in_ch,mid_ch13,kernel_size=1,stride=1),nn.ReLU(),nn.Conv2d(mid_ch13,out_ch13,kernel_size=3,stride=1,padding=1),nn.ReLU())self.conv15 = nn.Sequential(nn.Conv2d(in_ch,mid_ch15,kernel_size=1,stride=1),nn.ReLU(),nn.Conv2d(mid_ch15,out_ch15,kernel_size=5,stride=1,padding=2),nn.ReLU())self.pool_conv1 = nn.Sequential(nn.MaxPool2d(3,stride=1,padding=1),nn.Conv2d(in_ch,out_ch_pool_conv,kernel_size=1,stride=1),nn.ReLU())self.auxiliary = auxiliaryif auxiliary:self.auxiliary_layer = nn.Sequential(nn.AvgPool2d(5,3),nn.Conv2d(in_ch,128,1),nn.ReLU())def forward(self,inputs,train=False):conv1_out = self.conv1(inputs)conv13_out = self.conv13(inputs)conv15_out = self.conv15(inputs)pool_conv_out = self.pool_conv1(inputs)outputs = torch.cat([conv1_out,conv13_out,conv15_out,pool_conv_out],1) # depth-wise concatif self.auxiliary:if train:outputs2 = self.auxiliary_layer(inputs)else:outputs2 = Nonereturn outputs, outputs2else:return outputs
实验结果
GoogLeNet 使用了多种方法来进行测试,从而提升精度,如模型集成,最多同时使用 7 个模型进行融合;多尺度测试,使用256、288、320、352等尺度对测试集进行测试;crop 裁剪操作,最多达到 144 个不同方式比例的裁剪。
在集成7个模型,使用 144 种不同比例裁剪方式下,在 ILSVRC 竞赛中 Top-5 降到 6.67,GoogLeNet 的表现优于之前的其他深度学习网络,并在 ILSVRC 2014 上获奖。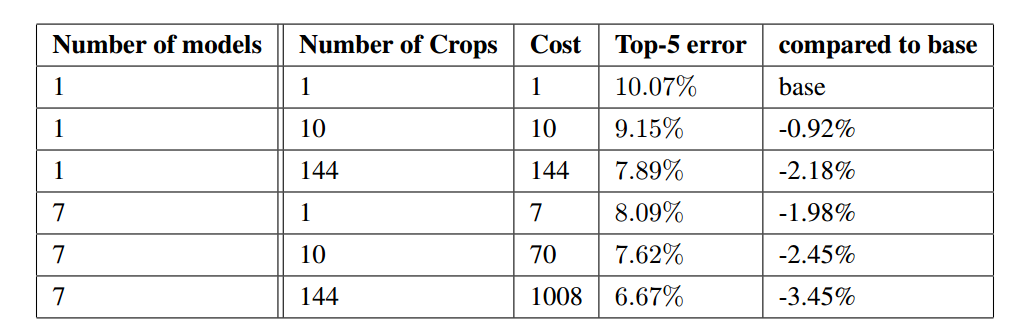
参考:
- https://medium.com/coinmonks/paper-review-of-googlenet-inception-v1-winner-of-ilsvlc-2014-image-classification-c2b3565a64e7
- https://github.com/pytorch/vision/blob/master/torchvision/models/googlenet.py
卷积神经网络之-BN-Inception / Inception-v2

简介
论文地址:https://arxiv.org/abs/1502.03167
Inception 的第二个版本也称作 BN-Inception,该文章的主要工作是引入了深度学习的一项重要的技术 Batch Normalization (BN) 批处理规范化 。
**
BN 技术的使用,使得数据在从一层网络进入到另外一层网络之前进行规范化,可以获得更高的准确率和训练速度
题外话:BN-Inception 在 ILSVRC 竞赛数据集上分类错误率是 4.8%,但是该结果并没有提交给 ILSVRC 官方。
为什么需要 BN 技术?
BN 技术可以减少参数的尺度和初始化的影响,进而可以使用更高的学习率,也可以减少 Dropout 技术的使用
BN 有效性
网络的输入输出表达式一般表示为: ,其中 F 是 sigmoid 函数,如下图所示,蓝色虚线是 sigmoid 函数,橙色曲线是 sigmoid 函数的导数。从中可以看出,sigmoid 函数在两端容易使导数为 0,而且随着网络深度的加深,这种影响程度更严重,会导致训练速度变慢。
,其中 F 是 sigmoid 函数,如下图所示,蓝色虚线是 sigmoid 函数,橙色曲线是 sigmoid 函数的导数。从中可以看出,sigmoid 函数在两端容易使导数为 0,而且随着网络深度的加深,这种影响程度更严重,会导致训练速度变慢。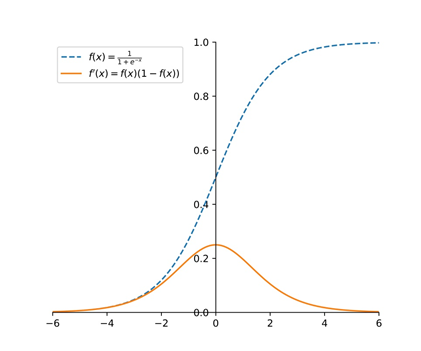
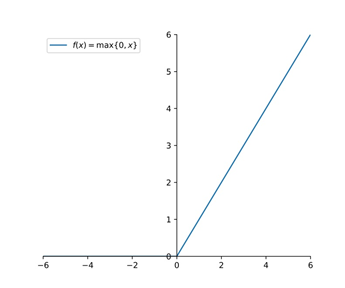
如果将激活函数换成 ReLU(x)=max(x,0) 激活(见下图),可以解决 sigmoid 存在的问题,但是使用 Relu 也需要细心的设置学习率和进行参数初始化。
随着训练的不断进行,数据的分布保持不变对训练是有利的,使用BN前后对训练的影响可以对照下图
BN 原理

Batch Normalization 中的 batch 就是批量数据,即每一次优化时的样本数目,通常 BN 网络层用在卷积层后,用于重新调整数据分布。假设神经网络某层一个 batch 的输入为 X=[x1,x2,…,xn],其中 xi 代表一个样本,n 为 batch size。步骤如下:
- 首先求解一个 batch 数据的均值

- 求解一个 batch 的方差

- 然后对每一个数据进行规范化
 ,
, 是为了防止分母为 0
是为了防止分母为 0 - 并使用其他可学习的参数 γ 和 β 进行缩放和平移,这样可以变换回原始的分布,实现恒等变换
最终得到的输出表达式是 Y=F(BN(W ⋅ X+b))
**在测试阶段,我们利用 BN 训练好模型后,我们保留了每组 mini-batch 训练数据在网络中每一层的 与
与  。此时我们使用整个样本的统计量来对 Test 数据进行归一化。
。此时我们使用整个样本的统计量来对 Test 数据进行归一化。
实验结果
MNIST 数据集
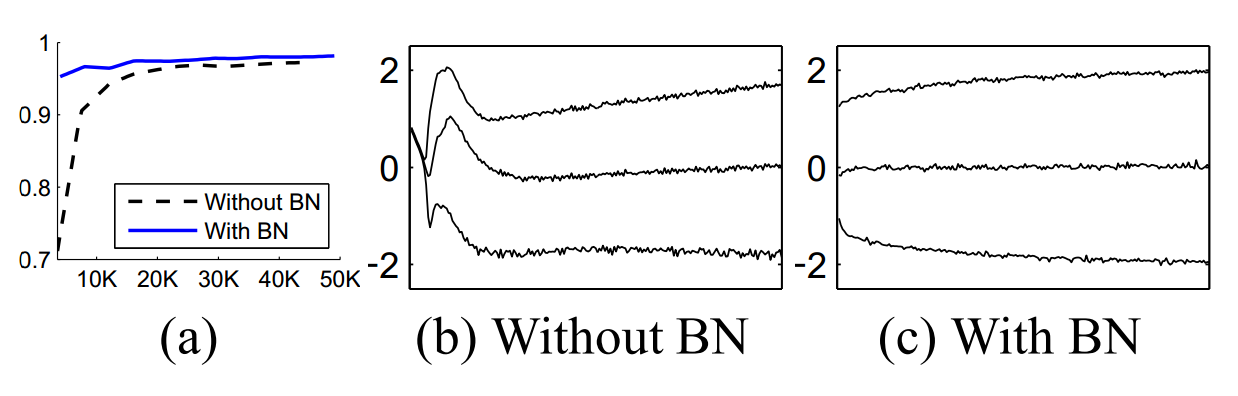
在 MNIST 数据上使用一个简单的网络比较使用BN技术和未使用BN技术训练精度的差异,如上图(a);上图 (b, c) 代表未使用 BN 技术和使用 BN 技术输入数据的分布,可以看出,使用 BN 技术,输入数据的分布更加稳定。
ILSVRC 数据集
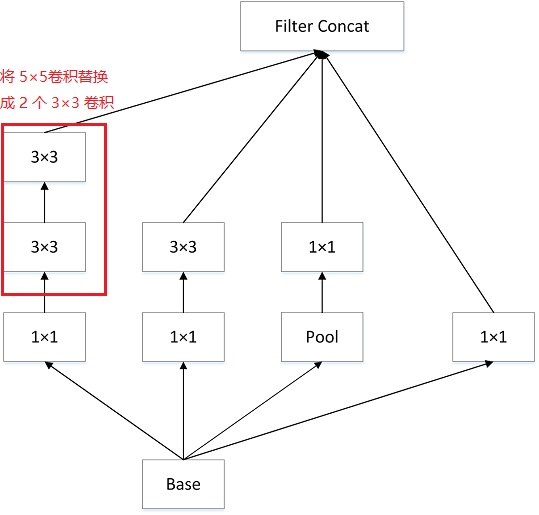
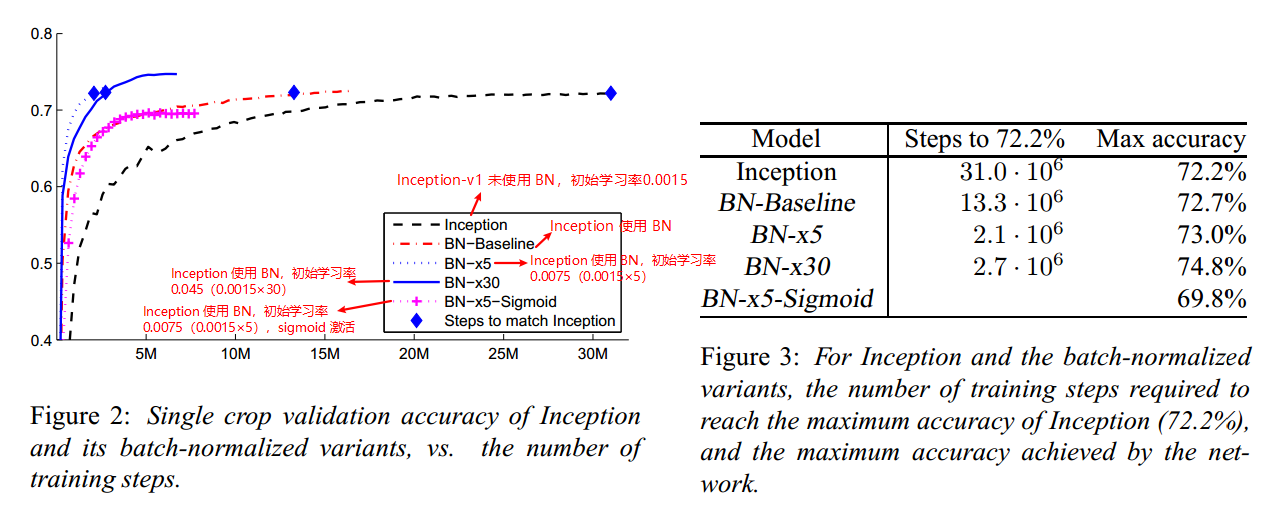
将 BN 运用到 GoogLeNet 网络上,同时将 Inception 模块中的 5×5 卷积替换成 2 个 3×3 卷积,将 5x5 卷积分解为两个 3x3 卷积运算,以提高计算速度。虽然这看似违反直觉,但 5x5 卷积比 3x3 卷积多 2.78 倍的参数量。因此,堆叠两个 3x3 卷积实际上可以提高性能。
在数据集 ILSVRC 上,使用 BN 技术并设计使用不同参数的 Inception 的网络,对比其精度,结果如下:使用 BN 技术,可以显著提高训练速度;对比 BN-×5 和 BN-×30,可以观察到,使用大的学习率可以提高训练速度。
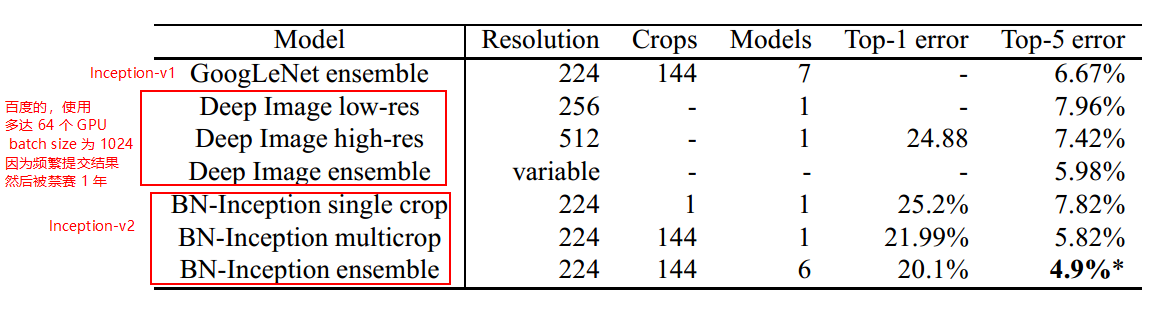
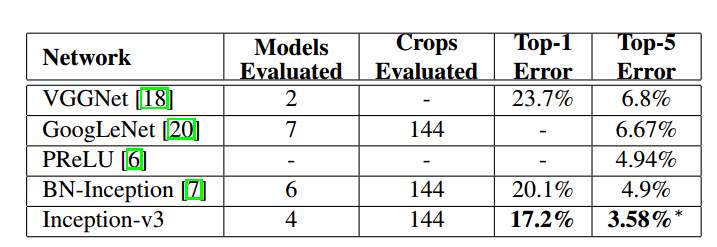
与其他网络性能对比
参考:
- https://medium.com/@sh.tsang/review-batch-normalization-inception-v2-bn-inception-the-2nd-to-surpass-human-level-18e2d0f56651
- https://mp.weixin.qq.com/s/Tuwg070YiXp5Rq4vULCy1w
- https://zhuanlan.zhihu.com/p/34879333
卷积神经网络之-Inception-v3
简介
论文地址:https://arxiv.org/abs/1512.00567
Inception-v3 架构的主要思想是 factorized convolutions(分解卷积) 和 aggressive regularization(激进的正则化)
注:一般认为 Inception-v2 (BN 技术的使用)和 Inception-v3(分解卷积技术) 网络是一样的,只是配置上不同,那么就暂且本文所述的是 Inception-v3 吧。
设计原则
作者在文章中提出了 4 个设计网络的原则,虽然不能证明这些原则是有用的,但是也能为网络的设计提供一定的指导作用。笔者对这些原则理解也并不透彻,并且没有做过相关实验,所以以下的表述可能表述有不周到,请读者指正:
- 网络从输入到输出的过程中,应该避免维度过度压缩,输入到输出特征的维度应该缓缓变化,例如像金字塔那般。
- 获得更加明晰的特征,得到的网络训练起来更快。
- 空间聚合可以通过低维度嵌套得到,而不损失表示能力。
- 网络的宽度和深度要均衡。
分解卷积
分解卷积的主要目的是为了减少参数量,分解卷积的方法有:大卷积分解成小卷积;分解为非对称卷积;
大卷积分解成小卷积
使用 2 个 3×3 卷积代替一个 5×5 卷积,可以减少 28% 的参数量,另外分解后多使用了一个激活函数(卷积层后面跟着激活函数,以前只有一个5×5 卷积,也就只有一个激活函数,现在有 2 个 3×3 卷积,也就有了 2 个激活函数),增加了非线性表达的能力,(VGGNet 也使用了相似的技术)分解示意图如下所示: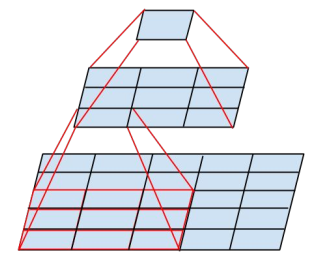
网络具体结构如下,简称为 Module A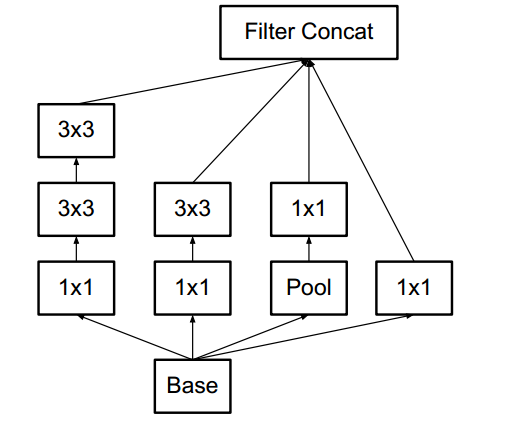
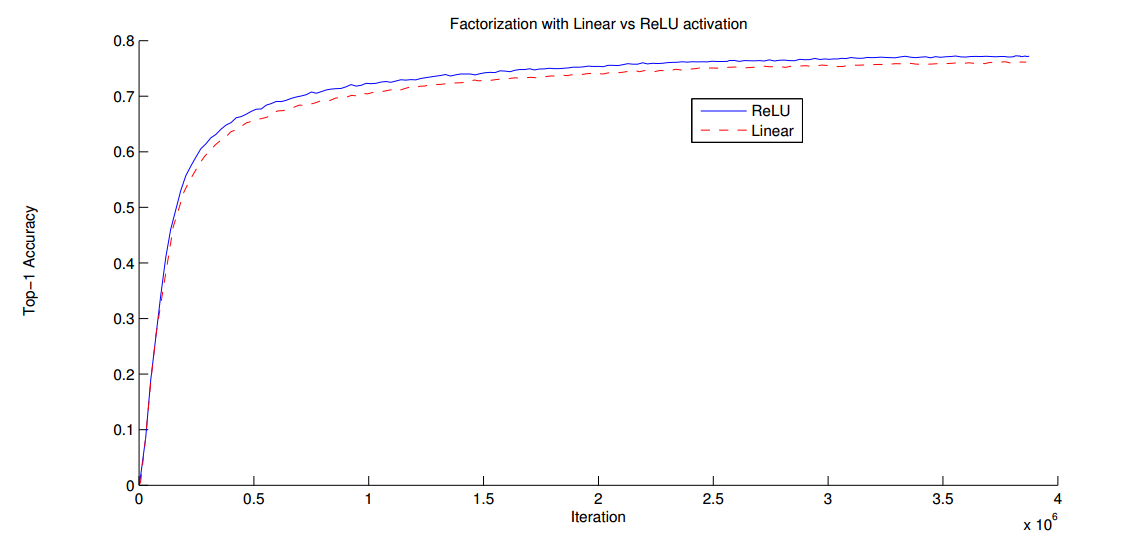
那么经过分解,是否会对性能造成影响呢,作者做了实验,得到结果如下图,其中蓝色曲线是对分解的卷积使用 2 个 ReLU 激活(得到验证集 77.2% 的精度),红色曲线是对分解的卷积使用 Linear+ReLU 激活(得到验证集 76.2% 的精度),实验结果表明,经过分解不会降低模型的 representation(表征)能力。
分解为非对称卷积
用 1 个 1×3 卷积和 1 个 3×1 卷积替换 3×3 卷积,这样可以减少 33% 的参数量
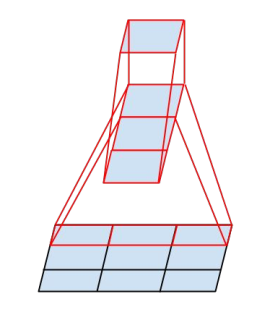
具体结构如下:简称为 Module B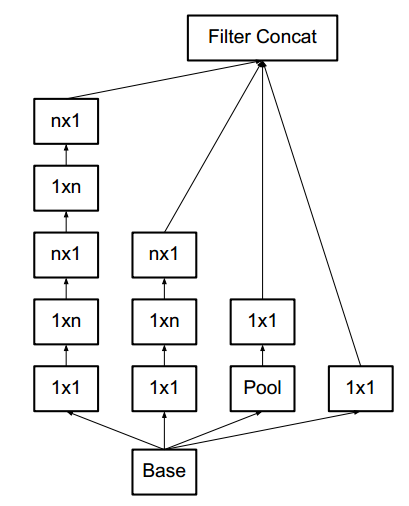
其他的非对称分解卷积如下,简称为 Module C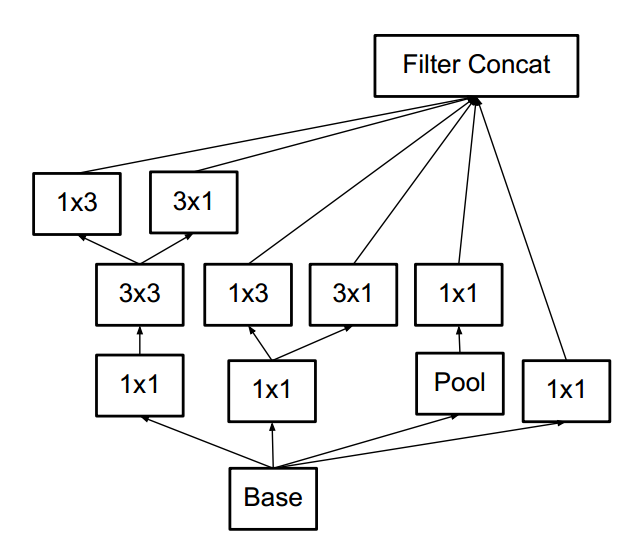
辅助分类器(Auxiliary Classifier)
在 Inception v1 中,使用了 2 个辅助分类器,用来帮助梯度回传,以加深网络的深度,在 Inception v3 中,也使用了辅助分类器,但其作用是用作正则化器,这是因为,如果辅助分类器经过批归一化,或有一个dropout层,那么网络的主分类器效果会更好一些。这也间接的说明,批归一化可以作为正则化器使用。
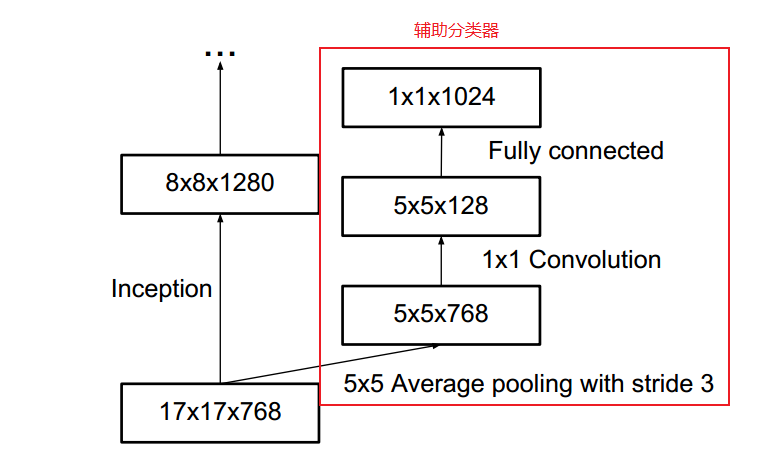
有效的特征网格大小缩减(Grid Size Reduction)
传统上,卷积网络使用一些池化操作来减小特征图的网格大小。为避免表示瓶颈,在进行最大池化或平均池化之前,增大网络滤波器激活的维数。作者设计了一个结构,可以有效减少计算量和参数
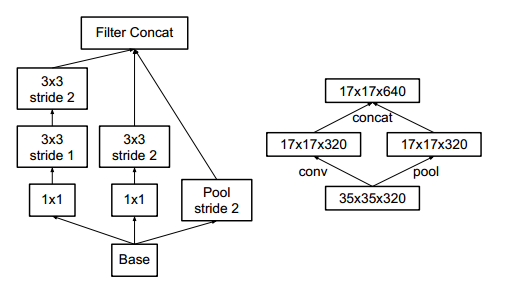
其中左边的图是详细的结构,右边的图是结构简图
Inception-v3 架构
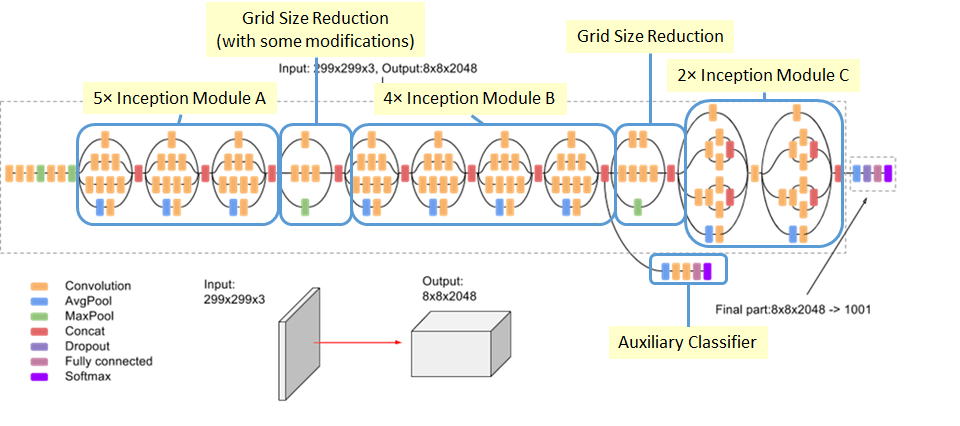
该网络有 42 层,计算量比 GoogLeNet 高 2.5 倍,但是比 VGGNet 更高效,具体网络参数如下:
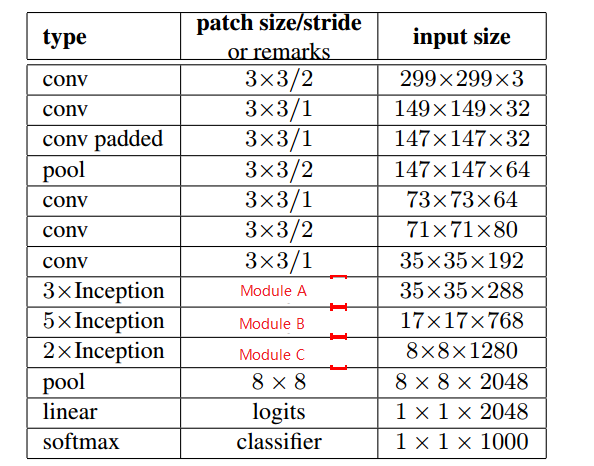
注:图中的 Module A、B、C 模型结构在前文已经说明
通过标签平滑来进行模型正则化
为了保证模型能够有较好的泛化能力,作者提出通过对标签进行平滑,原因是如果模型学会了对每个训练样本的真值标签都赋予充分最高概率,那么泛化能力就不能保证了。主要的工作是让真实标签的 logit 不要那么大。
实验结果
Inception 系列模型性能对比
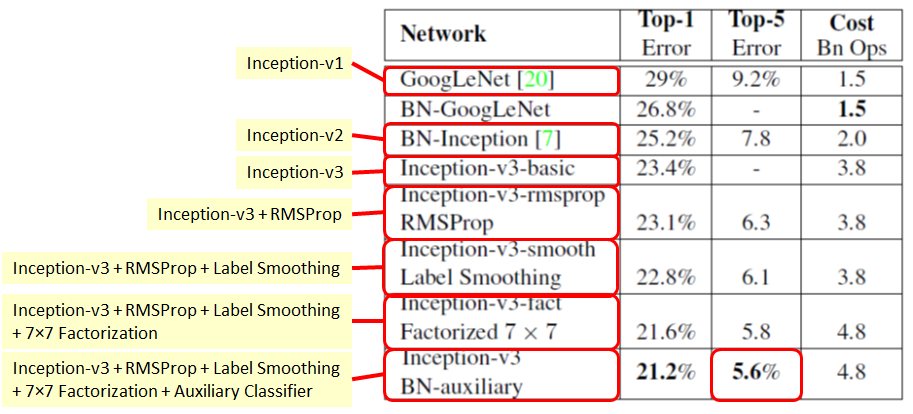
不同网络性能对比
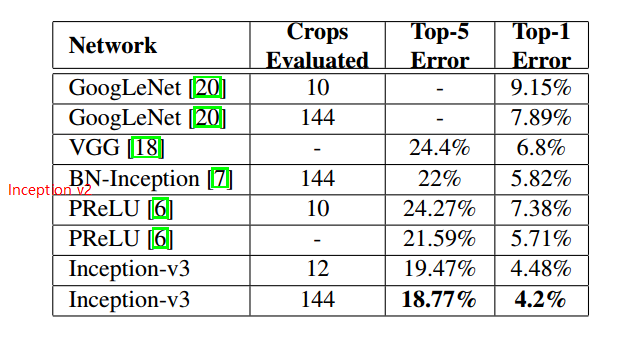
模型集成结果
可以看出,Inception-v3 在性能上有好的表现。在 ILSVRC 2015 竞赛上获得亚军,当年的冠军是 ResNet 。
参考:
- https://medium.com/@sh.tsang/review-inception-v3-1st-runner-up-image-classification-in-ilsvrc-2015-17915421f77c
- https://github.com/pytorch/vision/blob/master/torchvision/models/inception.py
- https://cloud.google.com/tpu/docs/inception-v3-advanced
- https://github.com/Mycenae/PaperWeekly/blob/master/Inception-V3.md
- https://blog.ddlee.cn/posts/5e3f4a2c/
- https://mp.weixin.qq.com/s/mXhVMHBsxrQQf_MV4_7iaw
- https://blog.csdn.net/u014061630/article/details/80383285
- https://blog.csdn.net/weixin_43624538/article/details/84963116
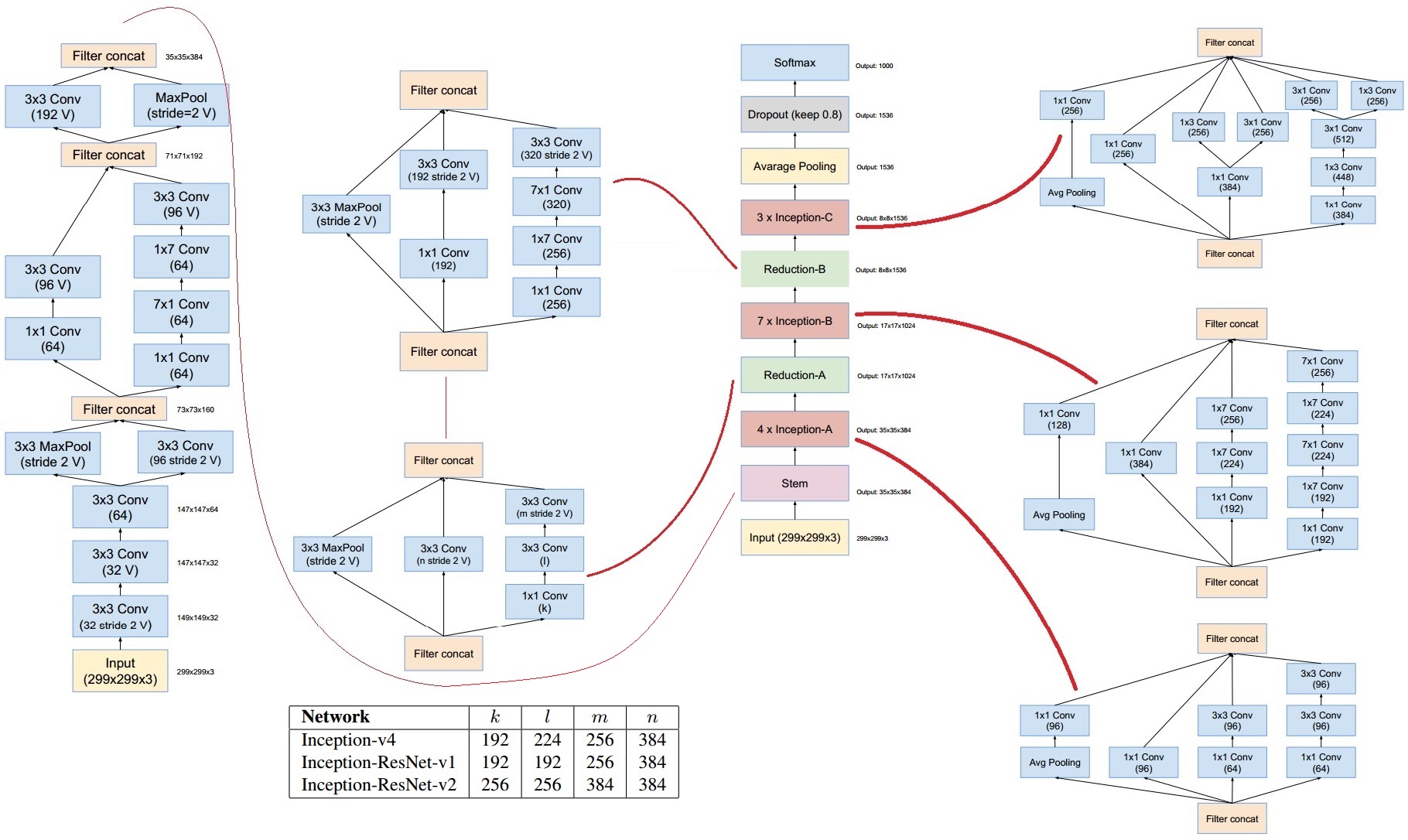
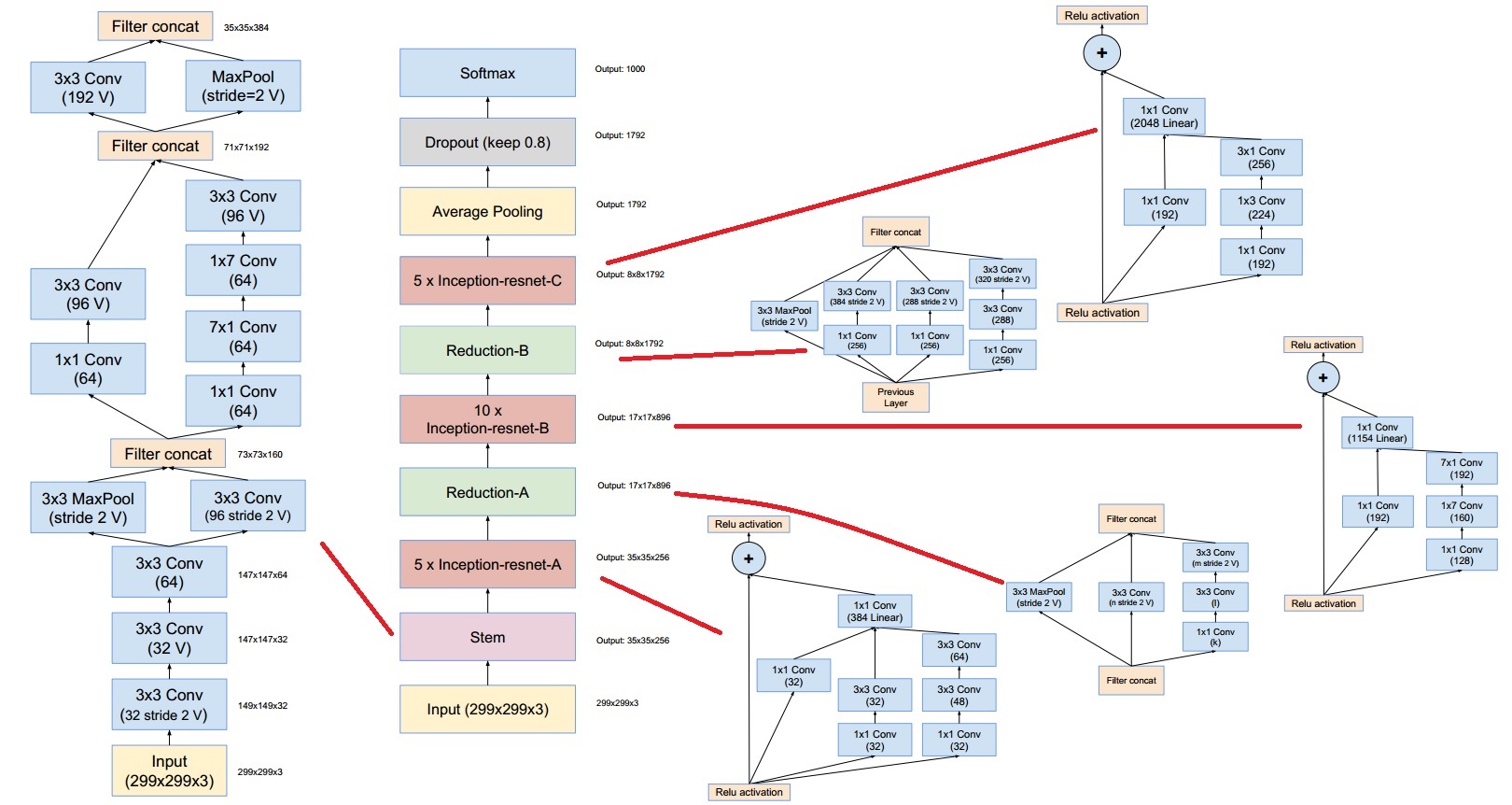
卷积神经网络之-Inception-v4
论文地址:https://arxiv.org/abs/1602.07261
INCEPTION 块
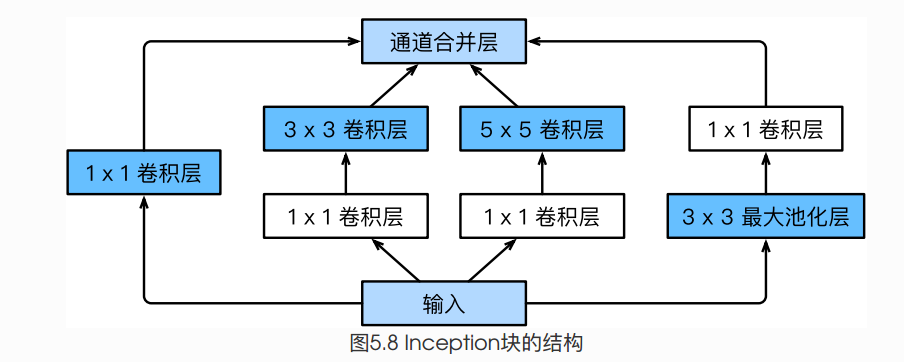
Inception块⾥有4条并⾏的线路。前3条线路使⽤窗⼝⼤⼩分别是 1×1 、3×3 和 5×5 的卷积层来抽取不同空间尺⼨下的信息,其中中间 2 个线路会对输⼊先做 1×1 卷积来减少输⼊通道数,以降低模型复杂度。第四条线路则使⽤3×3 最⼤池化层,后接1×1 卷积层来改变通道数。 4条线路都使⽤了合适的填充来使输⼊与输出的⾼和宽⼀致。最后我们将每条线路的输出在通道维上连结,并输⼊接下来的层中去。
(注意,每个卷积层和池化层后面都接一个 relu 激活,只是图中为展现出来,并且,经过每一个 Inception 结构,输出的特征图尺寸大小不变,即经过 33 卷积或者 33 最大池化需要 padding=1,经过 5*5 卷积需要 padding=2)
class Inception(nn.Module):# c1 - c4为每条线路里的层的输出通道数def __init__(self, in_c, c1, c2, c3, c4):super(Inception, self).__init__()# 线路1,单1 x 1卷积层self.p1_1 = nn.Conv2d(in_c, c1, kernel_size=1)# 线路2,1 x 1卷积层后接3 x 3卷积层self.p2_1 = nn.Conv2d(in_c, c2[0], kernel_size=1)self.p2_2 = nn.Conv2d(c2[0], c2[1], kernel_size=3, padding=1)# 线路3,1 x 1卷积层后接5 x 5卷积层self.p3_1 = nn.Conv2d(in_c, c3[0], kernel_size=1)self.p3_2 = nn.Conv2d(c3[0], c3[1], kernel_size=5, padding=2)# 线路4,3 x 3最大池化层后接1 x 1卷积层self.p4_1 = nn.MaxPool2d(kernel_size=3, stride=1, padding=1)self.p4_2 = nn.Conv2d(in_c, c4, kernel_size=1)def forward(self, x):p1 = F.relu(self.p1_1(x))p2 = F.relu(self.p2_2(F.relu(self.p2_1(x))))p3 = F.relu(self.p3_2(F.relu(self.p3_1(x))))p4 = F.relu(self.p4_2(self.p4_1(x)))return torch.cat((p1, p2, p3, p4), dim=1) # 在通道维上连结输出
- Inception块相当于⼀个有4条线路的⼦⽹络。它通过不同窗⼝形状的卷积层和最⼤池化层来并⾏抽取信息,并使⽤ 1*1 卷积层减少通道数从⽽降低模型复杂度。
- GoogLeNet将多个设计精细的 Inception 块和其他层串联起来。其中Inception块的通道数分配之⽐是在ImageNet数据集上通过⼤量的实验得来的。
- GoogLeNet和它的后继者们⼀度是ImageNet上最⾼效的模型之⼀:在类似的测试精度下,它们的计算复杂度往往更低。
Inception的四个版本:
- Inceptionv1 在同一层中采用不同的卷积核,并对卷积结果进行合并
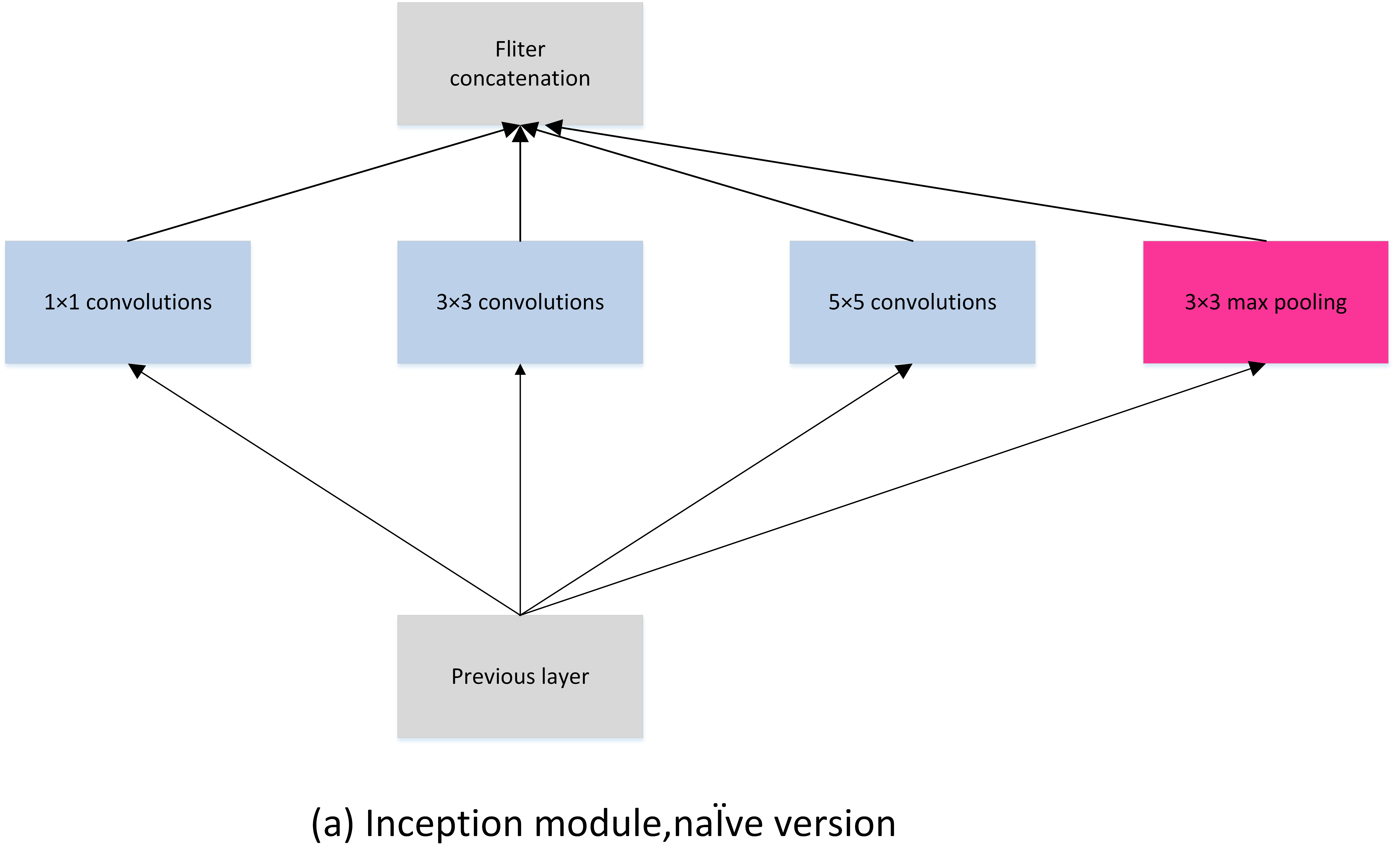
通过加入 1×1 卷积来降低通道数
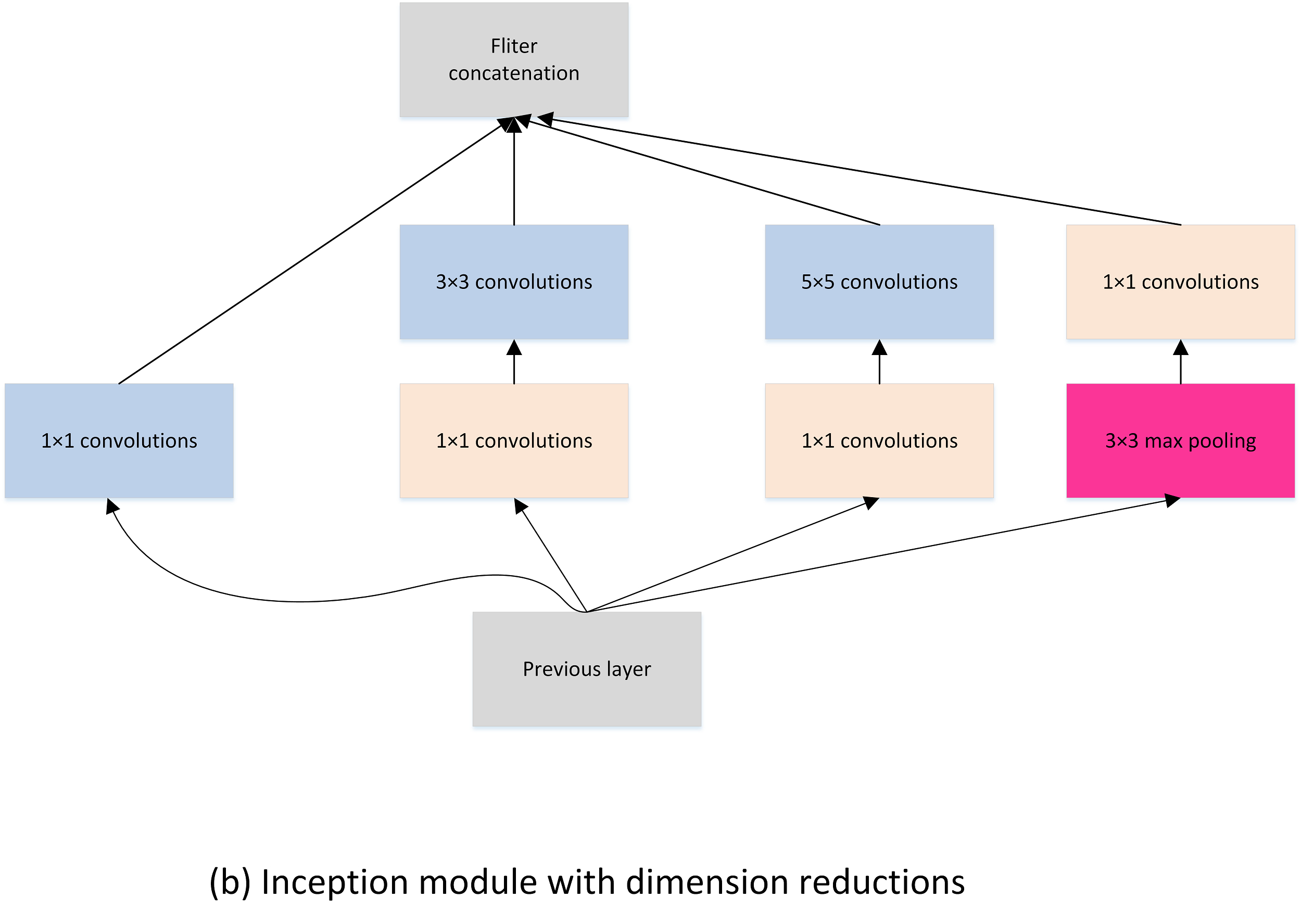
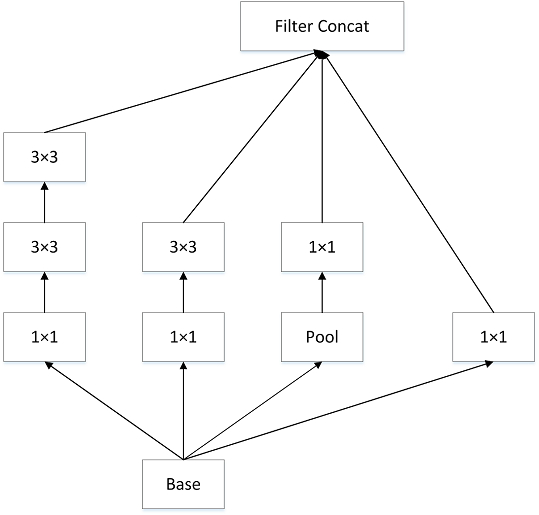
- Inceptionv2 组合不同卷积核的堆叠形式,并对卷积结果进行合并
将 5x5 卷积分解为两个 3x3 卷积运算,以提高计算速度。虽然这看似违反直觉,但 5x5 卷积比 3x3 卷积贵 2.78 倍。因此,堆叠两个 3x3 卷积实际上可以提高性能。
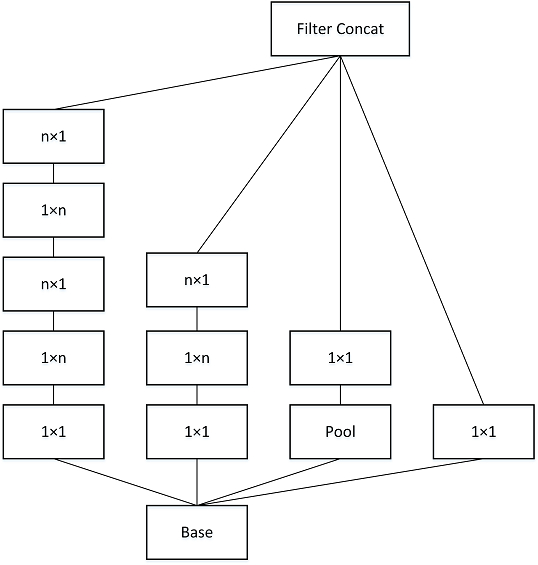
此外,它们将滤波器大小 nxn 的卷积分解为 1xn 和 nx1 卷积的组合。例如,3x3 卷积相当于首先执行 1x3 卷积,然后在其输出上执行 3x1 卷积。他们发现这种方法比单个 3x3 卷积便宜 33%
**
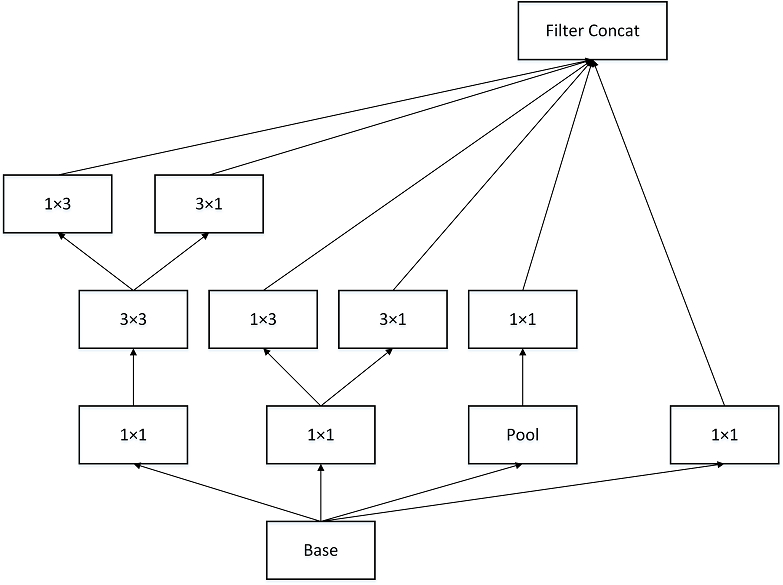
- Inceptionv3则在v2基础上进行深度组合的尝试
- Inceptionv4结构相比于前面的版本更加复杂,子网络中嵌套着子网络。
GoogLenet
- 采用不同大小的卷积核意味着不同大小的感受野,最后拼接意味着不同尺度特征的融合;
- 之所以卷积核大小采用1、3和5,主要是为了方便对齐。设定卷积步长stride=1之后,只要分别设定pad=0、1、2,那么卷积之后便可以得到相同维度的特征,然后这些特征就可以直接拼接在一起了;
- 网络越到后面,特征越抽象,而且每个特征所涉及的感受野也更大了,因此随着层数的增加,3x3和5x5卷积的比例也要增加。但是,使用5x5的卷积核仍然会带来巨大的计算量。 为此,文章借鉴NIN2,采用1x1卷积核来进行降维。
参考:

若有收获,就点个赞吧
0 人点赞
