http://nodejs.cn/api/modules.html#modules_dirname module
module
module 模块,函数封装器
在 Node.js 模块系统中,每个文件都被视为一个独立的模块。
exports 可以导出对象。
module.exports 可以导出class,对象,array,string,number,…等等
// 赋值给 `exports` 不会修改模块,必须使用 `module.exports`。module.exports = class Square {constructor(width) {this.width = width;}area() {return this.width ** 2;}};
在执行模块代码之前,Node.js 会使用一个如下的函数封装器将其封装:
(function(exports, require, module, __filename, __dirname) {// 模块的代码实际上在这里});
通过这样做,Node.js 实现了以下几点:
- 它保持了顶层的变量(用
var、const或let定义)作用在模块范围内,而不是全局对象。 - 它有助于提供一些看似全局的但实际上是模块特定的变量,例如: - 实现者可以用于从模块中导出值的
module和exports对象。 - 包含模块绝对文件名和目录路径的快捷变量__filename和__dirname。
模块系统在 require('module') 模块中实现。
访问主模块
require.main
当 Node.js 直接运行一个文件时, require.main 会被设为它的 module。 这意味着可以通过 require.main === module 来判断一个文件是否被直接运行:
对于 foo.js 文件,如果通过 node foo.js 运行则为 true,但如果通过 require('./foo') 运行则为 false。
因为 module 提供了一个 filename 属性(通常等同于 __filename),所以可以通过检查 require.main.filename 来获取当前应用程序的入口点。
// entry.jsconsole.log(require.main);>node entry.jsModule {id: '.',exports: {},parent: null,filename: '/absolute/path/to/entry.js',loaded: false,children: [],paths:[ '/absolute/path/to/node_modules','/absolute/path/node_modules','/absolute/node_modules','/node_modules' ] }
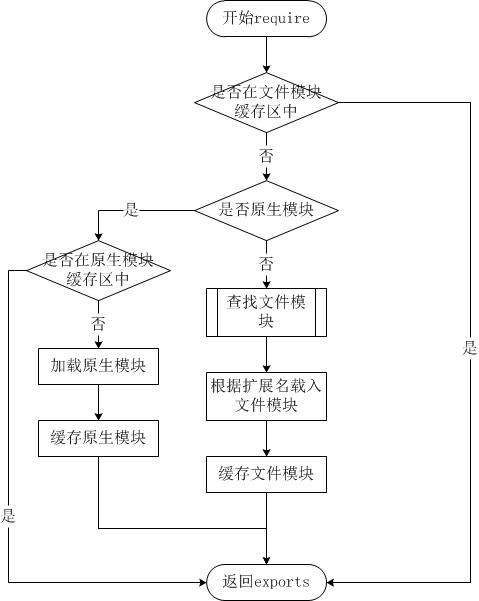
nodejs加载模块的伪代码
require.resolve(‘./entry’);
require.resolve.paths(‘./entry’);
var str = require.resolve('./entry'); // 此方法返回加载模块的路径 return 'path';console.log(str); // /xxx/xxx/entry.js// require.resolve('./entry', { paths: [''] });/*{ paths: [''] }解析模块的起点路径。此参数存在时,将使用这些路径而非默认解析路径。注意此数组中的每一个路径都被用作模块解析算法的起点,意味着 node_modules 层级将从这里开始查询。*/// ======================================================// 还可以使用require.resolve.paths(request)查询var str = require.resolve.paths('./entry');console.log(str); // [ '/Users/lijunyang' ]/*request <string> 被查询解析路径的模块的路径。返回: <Array> | <null>返回一个数组,其中包含解析 request 过程中被查询的路径。如果 request 字符串指向核心模块(例如 http 或 fs),则返回 null。*/
想要获得调用 require() 时加载的确切的文件名,使用 require.resolve() 函数。
综上所述,以下用伪代码描述的高级算法,解释 require.resolve() 做了些什么:
require(X) from module at path Y1. If X is a core module,a. return the core moduleb. STOP2. If X begins with '/'a. set Y to be the filesystem root3. If X begins with './' or '/' or '../'a. LOAD_AS_FILE(Y + X)b. LOAD_AS_DIRECTORY(Y + X)4. LOAD_NODE_MODULES(X, dirname(Y))5. THROW "not found"LOAD_AS_FILE(X)1. If X is a file, load X as JavaScript text. STOP2. If X.js is a file, load X.js as JavaScript text. STOP3. If X.json is a file, parse X.json to a JavaScript Object. STOP4. If X.node is a file, load X.node as binary addon. STOPLOAD_INDEX(X)1. If X/index.js is a file, load X/index.js as JavaScript text. STOP2. If X/index.json is a file, parse X/index.json to a JavaScript object. STOP3. If X/index.node is a file, load X/index.node as binary addon. STOPLOAD_AS_DIRECTORY(X)1. If X/package.json is a file,a. Parse X/package.json, and look for "main" field.b. let M = X + (json main field)c. LOAD_AS_FILE(M)d. LOAD_INDEX(M)2. LOAD_INDEX(X)LOAD_NODE_MODULES(X, START)1. let DIRS=NODE_MODULES_PATHS(START)2. for each DIR in DIRS:a. LOAD_AS_FILE(DIR/X)b. LOAD_AS_DIRECTORY(DIR/X)NODE_MODULES_PATHS(START)1. let PARTS = path split(START)2. let I = count of PARTS - 13. let DIRS = []4. while I >= 0,a. if PARTS[I] = "node_modules" CONTINUEb. DIR = path join(PARTS[0 .. I] + "node_modules")c. DIRS = DIRS + DIRd. let I = I - 15. return DIRS
缓存
require.cache
被引入的模块将被缓存在这个对象中。从此对象中删除键值对将会导致下一次 require 重新加载被删除的模块。注意不能删除 native addons(原生插件),因为它们的重载将会导致错误。
缓存说明
模块在第一次加载后会被缓存。 这也意味着(类似其他缓存机制)如果每次调用 require('foo') 都解析到同一文件,则返回相同的对象。
多次调用 require(foo) 不会导致模块的代码被执行多次。 这是一个重要的特性。 借助它, 可以返回“部分完成”的对象,从而允许加载依赖的依赖, 即使它们会导致循环依赖。
如果想要多次执行一个模块,可以导出一个函数,然后调用该函数。
模块缓存的注意事项
模块是基于其解析的文件名进行缓存的。 由于调用模块的位置的不同,模块可能被解析成不同的文件名(比如从 node_modules 目录加载),这样就不能保证 require('foo') 总能返回完全相同的对象。
此外,在不区分大小写的文件系统或操作系统中,被解析成不同的文件名可以指向同一文件,但缓存仍然会将它们视为不同的模块,并多次重新加载。 例如, require('./foo') 和 require('./FOO') 返回两个不同的对象,而不会管 ./foo 和 ./FOO 是否是相同的文件。
循环
当循环调用 require() 时,一个模块可能在未完成执行时被返回。
例如以下情况:a.js:
console.log('a 开始');exports.done = false;const b = require('./b.js');console.log('在 a 中,b.done = %j', b.done);exports.done = true;console.log('a 结束');
b.js:
console.log('b 开始');exports.done = false;const a = require('./a.js');console.log('在 b 中,a.done = %j', a.done);exports.done = true;console.log('b 结束');
main.js:
console.log('main 开始');const a = require('./a.js');const b = require('./b.js');console.log('在 main 中,a.done=%j,b.done=%j', a.done, b.done);
当 main.js 加载 a.js 时, a.js 又加载 b.js。 此时, b.js 会尝试去加载 a.js。 为了防止无限的循环,会返回一个 a.js 的 exports 对象的 未完成的副本 给 b.js 模块。 然后 b.js 完成加载,并将 exports 对象提供给 a.js 模块。
当 main.js 加载这两个模块时,它们都已经完成加载。 因此,该程序的输出会是:
$ node main.jsmain 开始a 开始b 开始在 b 中,a.done = falseb 结束在 a 中,b.done = truea 结束在 main 中,a.done=true,b.done=true
核心模块
Node.js 有些模块会被编译成二进制。 这些模块别的地方有更详细的描述。
核心模块定义在 Node.js 源代码的 lib/ 目录下。require() 总是会优先加载核心模块。 例如, require('http') 始终返回内置的 HTTP 模块,即使有同名文件。
文件模块
如果按确切的文件名没有找到模块,则 Node.js 会尝试带上 .js、 .json 或 .node 拓展名再加载。.js 文件会被解析为 JavaScript 文本文件, .json 文件会被解析为 JSON 文本文件。 .node 文件会被解析为通过 dlopen 加载的编译后的插件模块。
以 '/' 为前缀的模块是文件的绝对路径。 例如, require('/home/marco/foo.js') 会加载 /home/marco/foo.js 文件。
以 './' 为前缀的模块是相对于调用 require() 的文件的。 也就是说, circle.js 必须和 foo.js 在同一目录下以便于 require('./circle') 找到它。
当没有以 '/'、 './' 或 '../' 开头来表示文件时,这个模块必须是一个核心模块或加载自 node_modules 目录。
如果给定的路径不存在,则 require() 会抛出一个 code 属性为 'MODULE_NOT_FOUND' 的 Error。
目录作为模块,(创建一个模块)
可以把程序和库放到一个单独的目录,然后提供一个单一的入口来指向它。 把目录递给 require() 作为一个参数,有三种方式。
第一种方式是在根目录下创建一个 package.json 文件,并指定一个 main 模块。 例子, package.json 文件类似:
{ "name" : "some-library","main" : "./lib/some-library.js" }
如果这是在 ./some-library 目录中,则 require('./some-library') 会试图加载 ./some-library/lib/some-library.js。
这就是 Node.js 处理 package.json 文件的方式。
注意:如果 package.json 中 "main" 入口指定的文件不存在,则无法解析,Node.js 会将模块视为不存在,并抛出默认错误:
Error: Cannot find module 'some-library'
如果目录里没有 package.json 文件,则 Node.js 就会试图加载目录下的 index.js 或 index.node 文件。 例如,如果上面的例子中没有 package.json 文件,则 require('./some-library') 会试图加载:
./some-library/index.js-
从 node_modules 目录加载
如果传递给
require()的模块标识符不是一个核心模块,也没有以'/'、'../'或'./'开头,则 Node.js 会从当前模块的父目录开始,尝试从它的/node_modules目录里加载模块。 Node.js 不会附加node_modules到一个已经以node_modules结尾的路径上。
如果还是没有找到,则移动到再上一层父目录,直到文件系统的根目录。
例子,如果在'/home/ry/projects/foo.js'文件里调用了require('bar.js'),则 Node.js 会按以下顺序查找: /home/ry/projects/node_modules/bar.js/home/ry/node_modules/bar.js/home/node_modules/bar.js/node_modules/bar.js
这使得程序本地化它们的依赖,避免它们产生冲突。
通过在模块名后包含一个路径后缀,可以请求特定的文件或分布式的子模块。 例如, require('example-module/path/to/file') 会把 path/to/file 解析成相对于 example-module 的位置。 后缀路径同样遵循模块的解析语法。
从全局目录加载
如果 NODE_PATH 环境变量被设为一个以冒号分割的绝对路径列表,则当在其他地方找不到模块时 Node.js 会搜索这些路径。
注意:在 Windows 系统中, NODE_PATH 是以分号间隔的。
在当前的模块解析算法运行之前, NODE_PATH 最初是创建来支持从不同路径加载模块的。
虽然 NODE_PATH 仍然被支持,但现在不太需要,因为 Node.js 生态系统已制定了一套存放依赖模块的约定。 有时当人们没意识到 NODE_PATH 必须被设置时,依赖 NODE_PATH 的部署会出现意料之外的行为。 有时一个模块的依赖会改变,导致在搜索 NODE_PATH 时加载了不同的版本(甚至不同的模块)。
此外,Node.js 还会搜索以下位置:
- 1:
$HOME/.node_modules - 2:
$HOME/.node_libraries - 3:
$PREFIX/lib/node
其中 $HOME 是用户的主目录, $PREFIX 是 Node.js 里配置的 node_prefix。
这些主要是历史原因。
注意:强烈建议将所有的依赖放在本地的 node_modules 目录。 这样将会更快地加载,且更可靠。
module 对象
module.children 被该模块引用的模块对象。
module.exports 导出模块
exports 是一个快捷方式,exports 变量是在模块的文件级作用域内可用的,且在模块执行之前赋值给 module.exports。
module.filename 模块的完全解析后的文件名。
module.id 模块的标识符。 通常是完全解析后的文件名。
module.loaded 模块是否已经加载完成,或正在加载中。
module.parent 最先引用该模块的模块。
module.paths 模块的搜索路径。
module.require(id)
module.require 方法提供了一种类似 require() 从原始模块被调用的加载模块的方式。
注意,为了做到这个,需要获得一个 module 对象的引用。 因为 require() 会返回 module.exports,且 module 只在一个特定的模块代码中有效,所以为了使用它,必须明确地导出。
require(‘module’) model对象
const builtin = require(‘module’).builtinModules;
node.js提供的所有模块的名称列表。可用于验证模块是否由第三方维护。
请注意,此上下文中的模块与模块包装器提供的对象不同。要访问它,需要模块模块:
module.createRequireFromPath(filename)
作用未知???下次查一下
const builtin = require('module').builtinModules; // return <string[]>const { createRequireFromPath } = require('module');const requireUtil = createRequireFromPath('../src/utils');// require `../src/utils/some-tool`requireUtil('./some-tool');

若有收获,就点个赞吧
0 人点赞
