首先Diff为什么能优化性能
在渲染的过程中,
1.有可能会出现中间状态(不能直接到的最终状态),多次反复更新同一个元素(被操作元素)的情况
2.更新不需要被更新的元素
而Diff算法,就是为了减少这种无意义的消耗,而产生的一种算法。那Diff是不是没有缺点呢,也不是的,DIff通过虚拟元素节点来计算元素变更的情况,所以它会产生更多的内存消耗(因为要保存虚拟节点的状态),而且有可能因为计算会带来更多CPU的开销,所以掌握Diff的原理其实是很重要的一件事情。
在灵活使用Diff算法提高我们的渲染性能时需要注意哪些事情呢?
1.你的多次修改树的元素节点状态时,是否是当你确定修改完毕之后,在执行页面的重新计算与渲染
举一个例子,React中通过setState的方法更新虚拟DOM,并当“当前轮React事件”执行完毕后,开始重新计算虚拟DOM树,并按新的虚拟DOM更新页面。
class Mod extends React.Component {state = {varA: 1,varB: 2,varC: 3}dispatchClick = () => {this.setState({varA: 'A'});this.setState({varB: 'B'});this.setState({varA: 'C'});}render () {cosnt {varA, varB, varC} = this.state;return (<div onClick={this.dispatchClick}>{varA},{varB},{varC}</div>)}}
上面的代码执行了3次setState,要求更新虚拟DOM状态。
假设多次变更没有合并会发送什么情况呢?
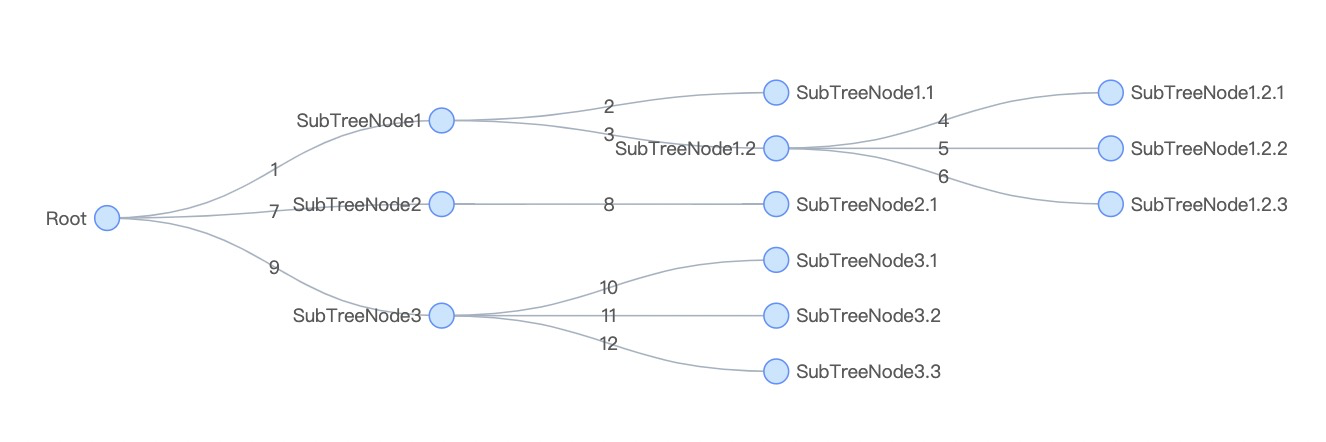
参考上面的图例,总共有12个子节点,每次更新时需要循环整个树,光循环次数就有36次了,有24次是其实是可以被合并的。
你可能会说,我当前这个组件没有子组件,它更新自身,应该是不需要循环整个树的,或者我有子组件,当我更新时,我应该循环的是某个子树,以减少循环次数的发送,理论上的确应该是这样的。
但是实际使用时,因为对象引用等情况,我是可以在某个节点中更新其他节点或其他子树让其发生变化的,也就是跨组件或者是跨树的更新的情况都有可能发生的,这是一个需要注意的问题。
2.当多个节点依赖或共享同一个状态时,此状态可能导致多个节点的无意义计算。
dva,redux是dispatch触发式数据流更新的状态管理库组件。
有的组件依赖某个状态可能是不涉及变更,有的组件依赖某个状态是涉及变更的,当这些组件混在一起时,有可能导致例外的开销。
React Diff
初始化阶段
1.首先必须要有一个原始树结构的数据源DATA,按此DATA生成对应的虚拟DOM树
2.循环此虚拟DOM树,将节点创建出来
3.将节点上下关系,串连起来,并渲染到页面中。
注意:React通过一组自定义事件,完成Proxy的功能,可以在事件执行前,与事件执行后,完成一系列的功能,所以它的setState是同步的,它通过Proxy在自定义事件触发时,标记状态,自定义事件结束后(此时状态在事件回调函数中合并),开始重新计算虚拟DOM,并完成更新。
更新
1.通过非React事件, 某个React实例调用setState更新
此时状态不合并
2.通过某个React实例的事件,发起setState更新
此时状态合并
3.通过某个React实例的事件,发起setState更新,但是在里面使用setTimeout,或某种导致异步发生的callback方法
此时状态不合并
4.直接通过React实例发起setState更新
此时状态不合并
具体的更新细节
虚拟DOM更新
假设有一个树R,树R中有a,b,c三个子树,以下三种情况
1.a子树发生更新,此时只循环a子树,跳过树R的根节点,与b,c子树
2.在a子树中某个节点,调用b子树的实例,驱动b子树的更新,跳过根节点,a,c子树 (跨组件的更新)
3.循环树R
层级遍历
在React中遍历树时,是按层序遍历的方式进行遍历的,用上面的那个图例来讲解
1.根节点
2.SubTreeNode1,SubTreeNode2,SubTreeNode3
3.SubTreeNode1.1,SubTreeNode1.2
按层级对比新老节点状态。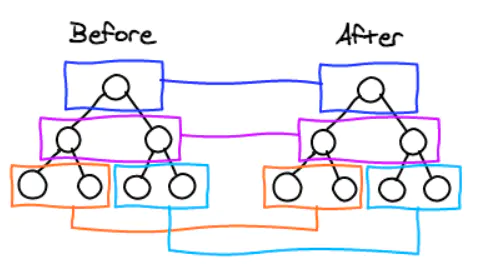
插入节点
删除节点
移动节点
Vue Diff

若有收获,就点个赞吧
0 人点赞
