- URL 字符串与 URL 对象
- URLSearchParams 类
- new URLSearchParams([string | object | iterable])
- urlSearchParams.append(name:string, value:string)
- urlSearchParams.delete(name:string)
- urlSearchParams.entries()
- urlSearchParams.forEach(fn[, thisArg])
- urlSearchParams.get(name)
- urlSearchParams.getAll(name)
- urlSearchParams.has(name)
- urlSearchParams.keys()
- urlSearchParams.set(name, value)
- urlSearchParams.sort()
- urlSearchParams.toString()
- urlSearchParams.values()
- urlSearchParams Symbol.iterator
- 特殊字符转换
URL 字符串与 URL 对象
URL 字符串是结构化的字符串,包含多个含义不同的组成部分。 解析字符串后返回的 URL 对象,每个属性对应字符串的各个组成部分。url 模块提供了两套 API 来处理 URL:一个是旧版本遗留的 API,一个是实现了 WHATWG标准的新 API。
遗留的 API 还没有被废弃,保留是为了兼容已存在的应用程序。 新的应用程序应使用 WHATWG 的 API。
WHATWG 的 API 与遗留的 API 的区别如下。 在下图中,URL 'http://user:pass@sub.example.com:8080/p/a/t/h?query=string#hash' 上方的是遗留的 url.parse() 返回的对象的属性。 下方的则是 WHATWG 的 URL对象的属性。
WHATWG 的 origin 属性包括 protocol 和 host,但不包括 username 或 password。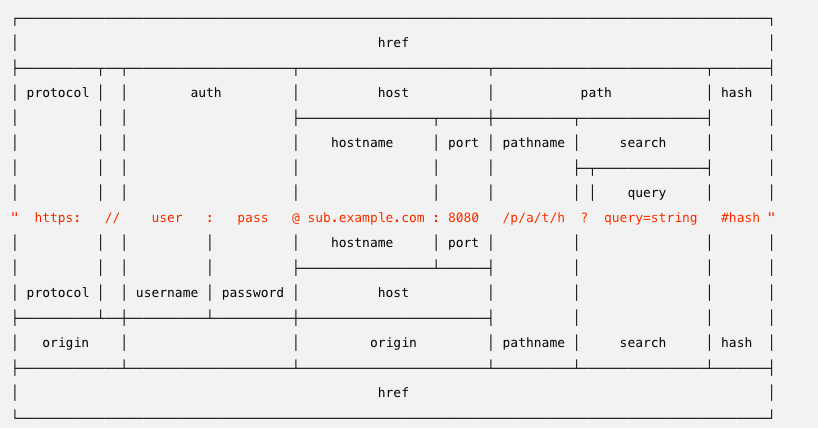 使用 WHATWG 的 API 解析 URL 字符串:
使用 WHATWG 的 API 解析 URL 字符串:
const myURL =new URL('https://user:pass@sub.host.com:8080/p/a/t/h?query=string#hash');URL {href:'https://user:pass@sub.host.com:8080/p/a/t/h?query=string#hash',origin: 'https://sub.host.com:8080',protocol: 'https:',username: 'user',password: 'pass',host: 'sub.host.com:8080',hostname: 'sub.host.com',port: '8080',pathname: '/p/a/t/h',search: '?query=string',searchParams: URLSearchParams { 'query' => 'string' },hash: '#hash' }
使用遗留的 API 解析 URL 字符串:
const url = require('url');const myURL =url.parse('https://user:pass@sub.host.com:8080/p/a/t/h?query=string#hash');Url {protocol: 'https:',// slashes 属性是一个 boolean,如果 protocol 中的冒号后面跟着两个,// ASCII 斜杠字符(/),则值为 true。slashes: true,auth: 'user:pass',host: 'sub.host.com:8080',port: '8080',hostname: 'sub.host.com',hash: '#hash',search: '?query=string',query: 'query=string',pathname: '/p/a/t/h',path: '/p/a/t/h?query=string',href:'https://user:pass@sub.host.com:8080/p/a/t/h?query=string#hash' }
WHATWG
url.toJSON()
返回string
在URL对象上调用toString()方法将返回序列化的URL。返回值与url.href和url.toJSON()的相同。
url.toString()
在URL对象上调用toJSON()方法将返回序列化的URL。返回值与url.href和url.toString()的相同。
const { URL } = require('url');const myURLs = [new URL('https://www.example.com'),new URL('https://test.example.org')];console.log(JSON.stringify(myURLs));// 输出 ["https://www.example.com/","https://test.example.org/"]
url.searchParams
url.domainToASCII(domain:string) : string
返回Punycode ASCII序列化的domain. 如果domain是无效域名,将返回空字符串。
它执行的是url.domainToUnicode()的逆运算。
url.domainToUnicode(domain:string) : string
返回Unicode序列化的domain. 如果domain是无效域名,将返回空字符串。
它执行的是url.domainToASCII()的逆运算。
url.fileURLToPath(url: string|URL) : string
此方法保证百分号编码字符解码结果的正确性,同时也确保绝对路径字符串在不同平台下的有效性。
new URL('file:///C:/path/').pathname; // 错误: /C:/path/fileURLToPath('file:///C:/path/'); // 正确: C:\path\ (Windows)new URL('file://nas/foo.txt').pathname; // 错误: /foo.txtfileURLToPath('file://nas/foo.txt'); // 正确: \\nas\foo.txt (Windows)new URL('file:///你好.txt').pathname; // 错误: /%E4%BD%A0%E5%A5%BD.txtfileURLToPath('file:///你好.txt'); // 正确: /你好.txt (POSIX)new URL('file:///hello world').pathname; // 错误: /hello%20worldfileURLToPath('file:///hello world'); // 正确: /hello world (POSIX)
url.format(URL[, options])
URL一个WHATWG URL对象 options

若有收获,就点个赞吧
0 人点赞
