JavaRedis
在一个分布式系统中,由于涉及到多个实例同时对同一个资源加锁的问题,像传统的synchronized、ReentrantLock等单进程情况加锁的api就不再适用,需要使用分布式锁来保证多服务实例之间加锁的安全性。常见的分布式锁的实现方式有zookeeper和redis等。而由于redis分布式锁相对于比较简单,在实际的项目中,redis分布式锁被用于很多实际的业务场景中。
redis分布式锁的实现中又以Redisson比较出名,所以本文来着重看一下Redisson是如何实现分布式锁的,以及Redisson提供了哪些其它的功能。
一、如何保证加锁的原子性
说到redis的分布式锁,可能第一时间就想到了setNx命令,这个命令保证一个key同时只能有一个线程设置成功,这样就能实现加锁的互斥性。但是Redisson并没有通过setNx命令来实现加锁,而是自己实现了一套完成的加锁的逻辑。
Redisson的加锁使用代码如下,接下来会有几节着重分析一下这段代码逻辑背后实现的原理。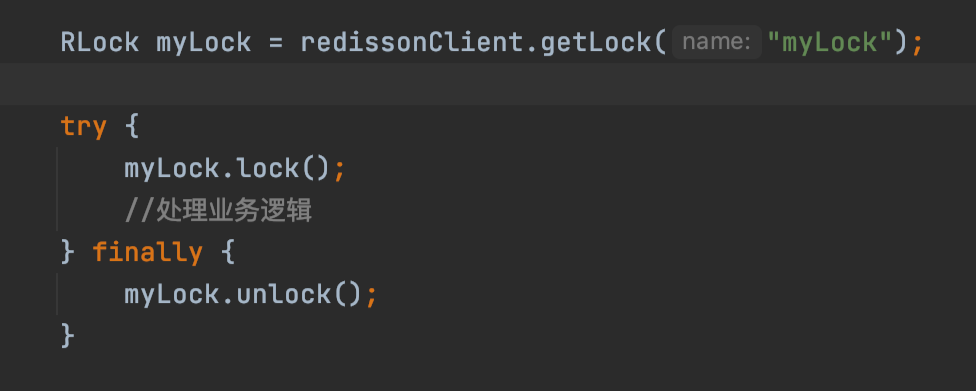
先通过RedissonClient,传入锁的名称,拿到一个RLock,然后通过RLock实现加锁和释放锁。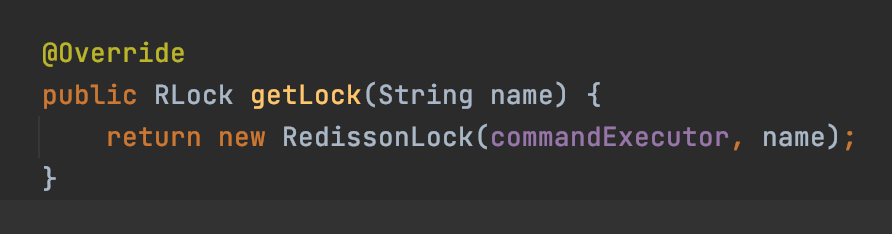
getLock获得的RLock接口的实现是RedissonLock,所以看一下RedissonLock对lock()方法的实现。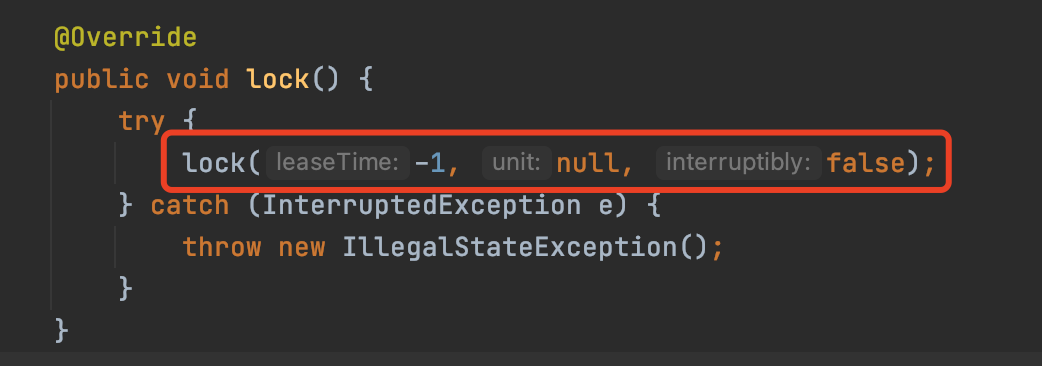
lock方法会调用重载的lock方法,传入的leaseTime为-1,调用到这个lock方法,之后会调用tryAcquire实现加锁的逻辑。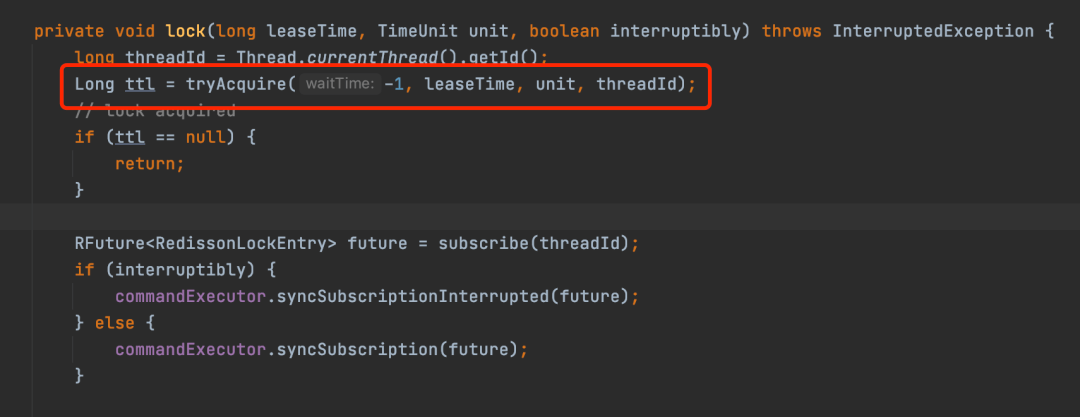
tryAcquire最后会调到tryAcquireAsync方法,传入了leaseTime和当前加锁线程的id。tryAcquire和tryAcquireAsync的区别就是tryAcquireAsync是异步执行,而tryAcquire是同步等待tryAcquireAsync的结果,也就是异步转同步的过程。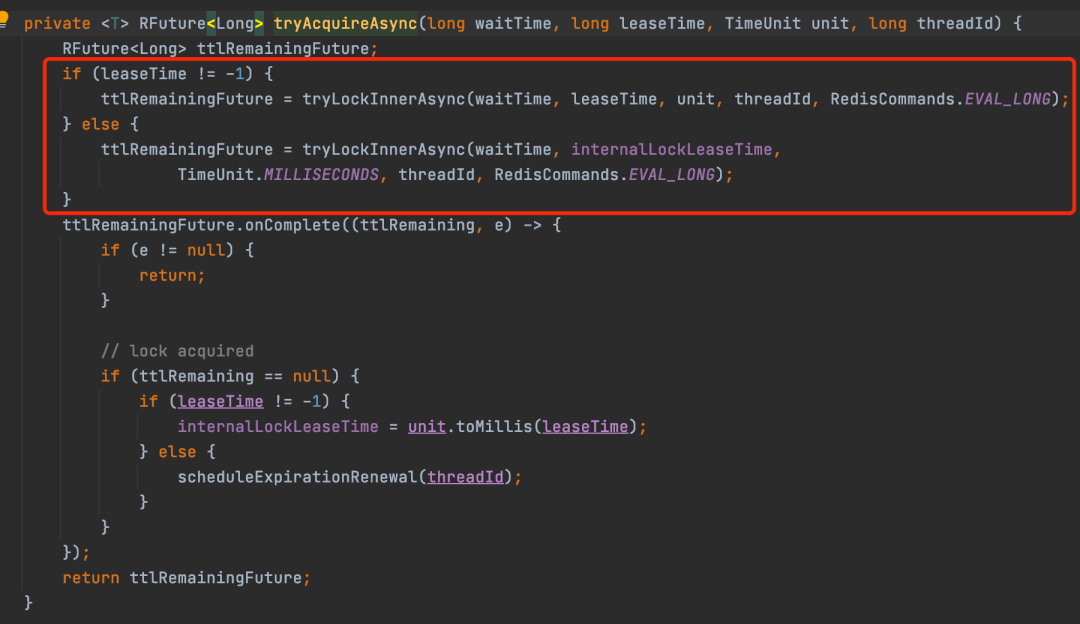
tryAcquireAsync方法会根据leaseTime是不是-1来判断使用哪个分支加锁,其实不论走哪个分支,最后都是调用tryLockInnerAsync方法来实现加锁,只不过是参数不同罢了。但是这里的leaseTime其实就是-1,所以会走下面的分支,尽管传入到tryAcquireAsync的leaseTime是-1,但是在调用tryLockInnerAsync方法传入的leaseTime参数是internalLockLeaseTime,默认是30s。tryLockInnerAsync方法。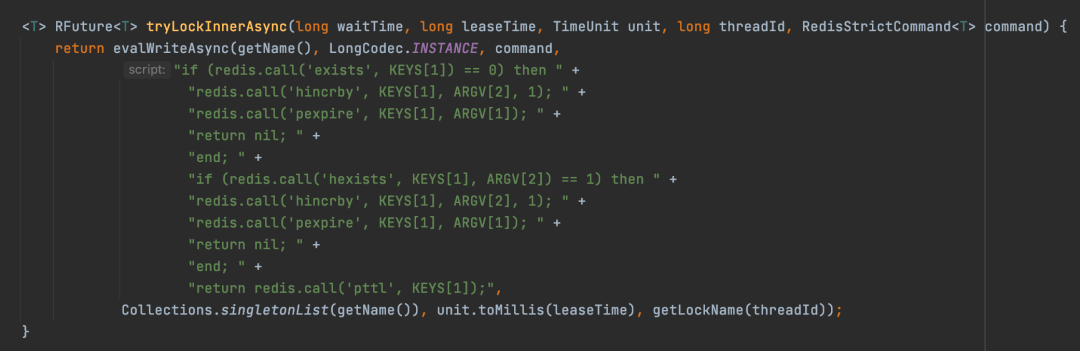
通过tryLockInnerAsync方法的实现可以看出,最终加锁是通过一段lua脚本来实现加锁的,redis在执行lua脚本的时候是可以保证加锁的原子性的,所以Redisson实现加锁的原子性是依赖lua脚本来实现的。其实对于RedissonLock这个实现来说,最终实现加锁的逻辑都是通过tryLockInnerAsync来实现的。
来一张图总结一下lock方法加锁的调用逻辑。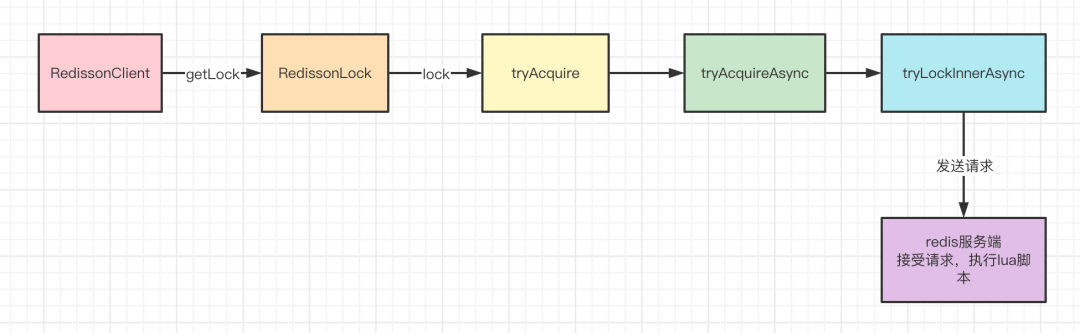
二、如何通过lua脚本实现加锁
通过上面分析可以看出,redis是通过执行lua脚本来实现加锁,保证加锁的原子性。那么接下来分析一下这段lua脚本干了什么。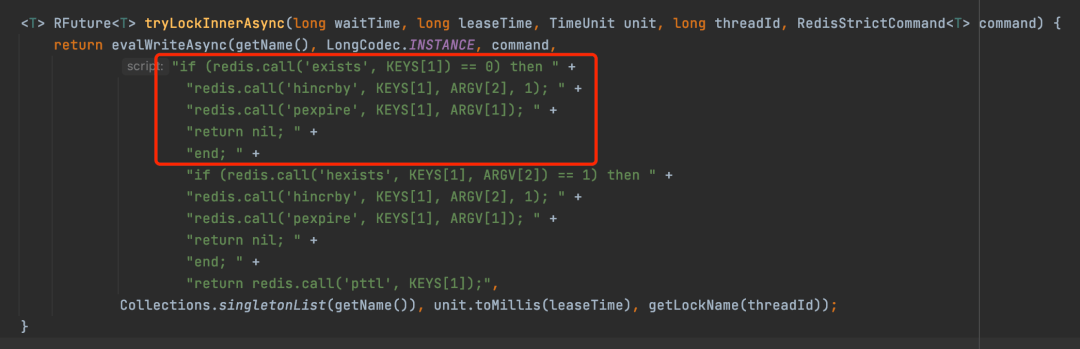
其中这段脚本中的lua脚本中的参数的意思:
- KEYS[1]:就是锁的名称,对于demo来说,就是myLock
- ARGV[1]:就是锁的过期时间,不指定的话默认是30s
- ARGV[2]:代表了加锁的唯一标识,由UUID和线程id组成。一个Redisson客户端一个UUID,UUID代表了一个唯一的客户端。所以由UUID和线程id组成了加锁的唯一标识,可以理解为某个客户端的某个线程加锁。
那么这些参数是怎么传过去的呢,其实是在这里。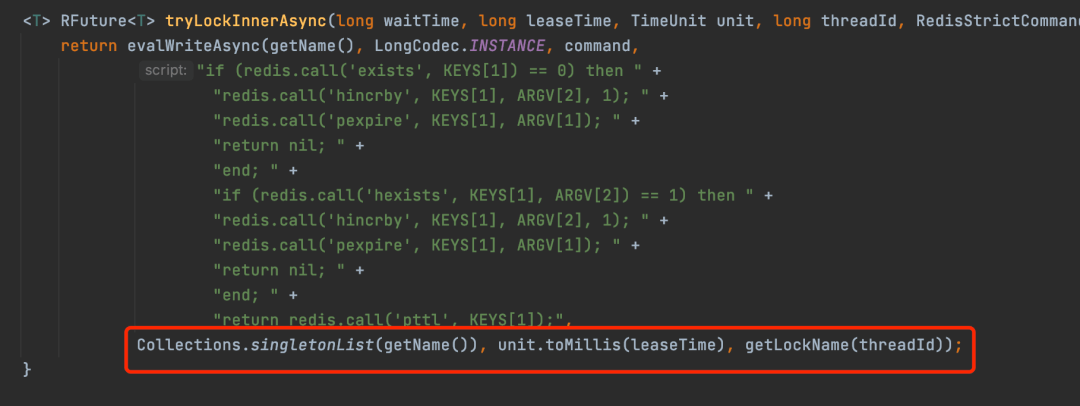
- getName:方法就是获取锁的名称
- leaseTime:就是传入的锁的过期时间,如果指定超时时间就是指定的时间,没指定默认是30s
getLockName:就是获取加锁的客户端线程的唯一标识。
分析一下这段lua的加锁的逻辑。
1)先调用redis的
exists命令判断加锁的key存不存在,如果不存在的话,那么就进入if。不存在的意思就是还没有某个客户端的某个线程来加锁,第一次加锁肯定没有人来加锁,于是第一次if条件成立。
2)然后调用redis的hincrby的命令,设置加锁的key和加锁的某个客户端的某个线程,加锁次数设置为1,加锁次数很关键,是实现可重入锁特性的一个关键数据。用hash数据结构保存。hincrby命令完成后就形成如下的数据结构。myLock:{"b983c153-7421-469a-addb-44fb92259a1b:1":1}
3)最后调用redis的
pexpire的命令,将加锁的key过期时间设置为30s。
从这里可以看出,第一次有某个客户端的某个线程来加锁的逻辑还是挺简单的,就是判断有没有人加过锁,没有的话就自己去加锁,设置加锁的key,再存一下加锁的线程和加锁次数,设置一下锁的过期时间为30s。
画一张图来看一下lua脚本加锁的逻辑干了什么。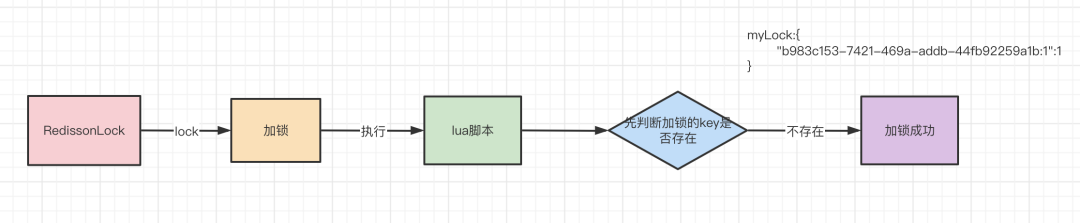
至于第二段if是干什么的,后面再说。三、为什么需要设置加锁key的过期时间
通过上面的加锁逻辑可以知道,虽然没有手动设置锁的过期时间,但是Redisson默认会设置一个30s的过期时间,为什么需要过期时间呢?
主要原因是为了防止死锁。当某个客户端获取到锁,还没来得及主动释放锁,那么此时假如客户端宕机了,又或者是释放锁失败了,那么如果没有设置过期时间,那么这个锁key会一直在,那么其它线程来加锁的时候会发现key已经被加锁了,那么其它线程一直会加锁失败,就会产生死锁的问题。四、如何自动延长加锁时间
通过上面的分析都知道,在加锁的时候,就算没有指定锁的过期时间,Redisson默认也会给锁设置30s的过期时间,主要是用来防止死锁。
虽然设置了默认过期时间能够防止死锁,但是这也有一个问题,如果在30s内,任务没有结束,但是锁已经被释放了,失效了,一旦有其它线程加锁成功,那么就完全有可能出现线程安全数据错乱的问题。
所以Redisson对于这种未指定超时时间的加锁,就实现了一个叫watchdog机制,也就是看门狗机制来自动延长加锁的时间。
在客户端通过tryLockInnerAsync方法加锁成功之后,如果没有指定锁过期的时间,那么客户端会起一个定时任务,来定时延长加锁时间,默认每10s执行一次。所以watchdog的本质其实就是一个定时任务。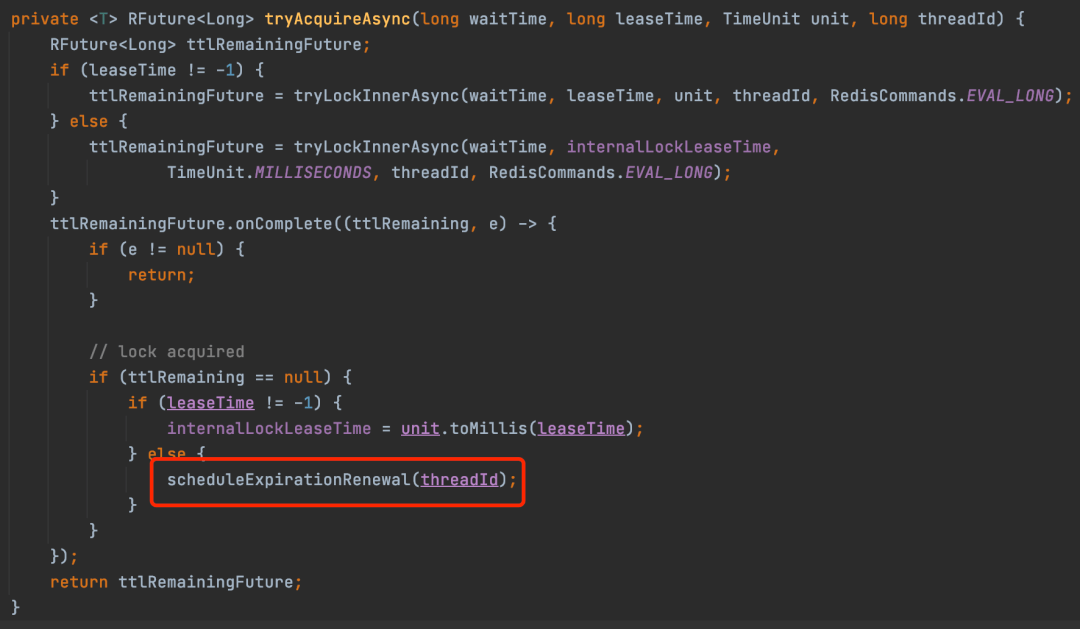
最后会定期执行如下的一段lua脚本来实现加锁时间的延长。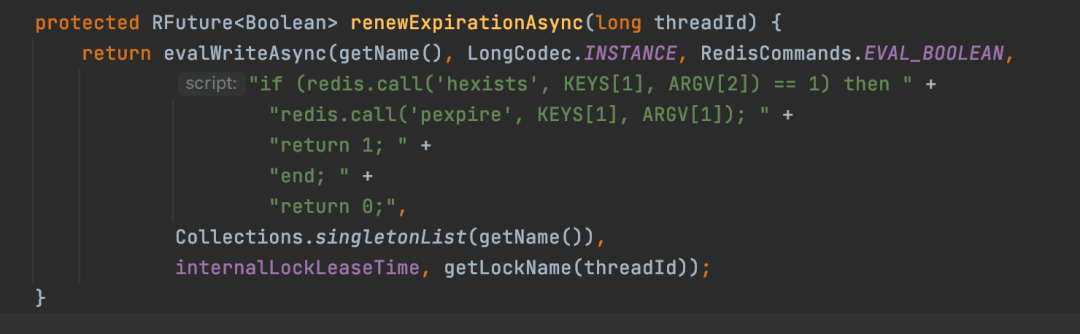
解释一下这段lua脚本中参数的意思,其实是跟加锁的参数的意思是一样KEYS[1]:就是锁的名称,对于demo来说,就是myLock
- ARGV[1]:就是锁的过期时间
- ARGV[2]:代表了加锁的唯一标识,b983c153-7421-469a-addb-44fb92259a1b:1。
这段lua脚本的意思就是判断来续约的线程跟加锁的线程是同一个,如果是同一个,那么将锁的过期时间延长到30s,然后返回1,代表续约成功,不是的话就返回0,代表续约失败,下一次定时任务也就不会执行了。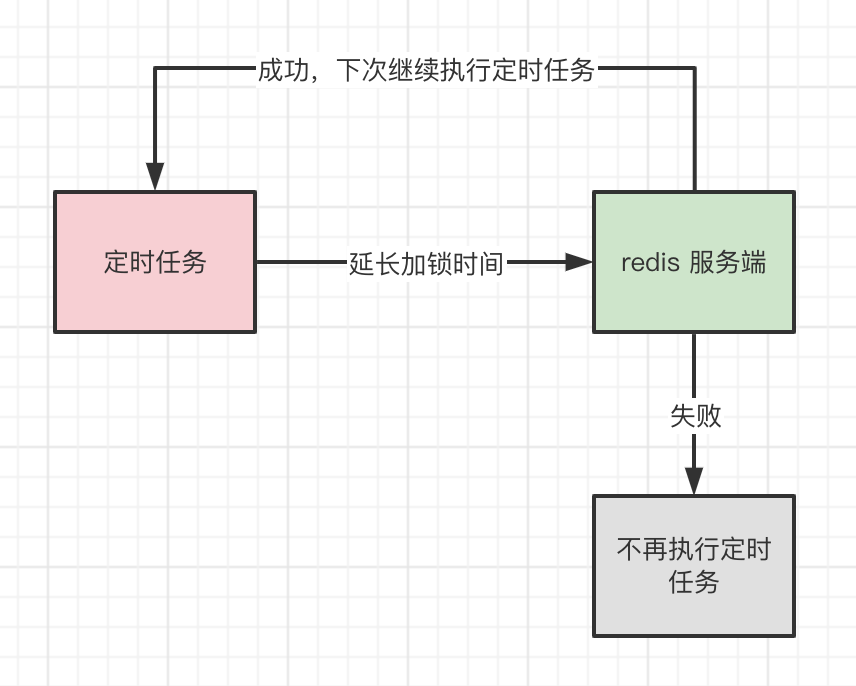
注意:因为有了看门狗机制,所以说如果没有设置过期时间(超时自动释放锁的逻辑后面会说)并且没有主动去释放锁,那么这个锁就永远不会被释放,因为定时任务会不断的去延长锁的过期时间,造成死锁的问题。但是如果发生宕机了,是不会造成死锁的,因为宕机了,服务都没了,那么看门狗的这个定时任务就没了,也自然不会去续约,等锁自动过期了也就自动释放锁了,跟上述说的为什么需要设置过期时间是一样的。
五、如何实现可重入加锁
可重入加锁的意思就是同一个客户端同一个线程也能多次对同一个锁进行加锁。
也就是同时可以执行多次 lock方法,流程都是一样的,最后也会调用到lua脚本,所以可重入加锁的逻辑最后也是通过加锁的lua脚本来实现的。
上面加锁逻辑的lua脚本的前段上面已经说过,下半部分也就是可重入加锁的逻辑。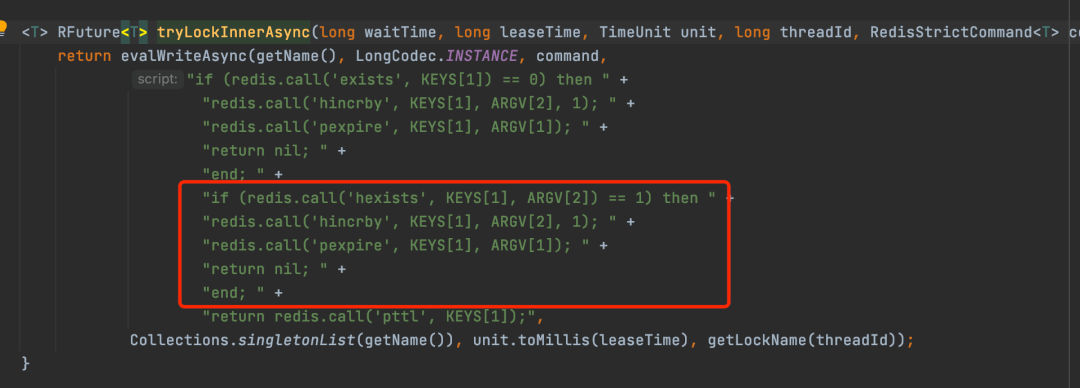
下面这段if的意思就是,判断当前已经加锁的key对应的加锁线程跟要来加锁的线程是不是同一个,如果是的话,就将这个线程对应的加锁次数加1,也就实现了可重入加锁,同时返回nil回去。
可重入加锁成功之后,加锁key和对应的值可能是这样。
myLock:{"b983c153-7421-469a-addb-44fb92259a1b:1":2}
所以加锁lua脚本的第二段if的逻辑其实是实现可重入加锁的逻辑。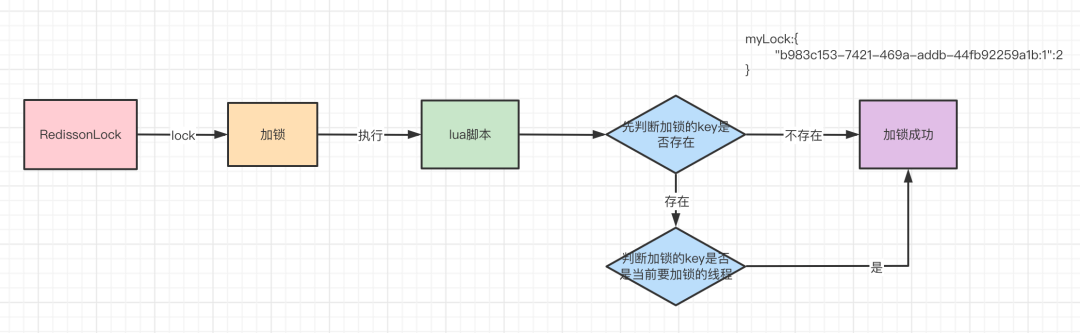
六、如何主动释放锁和避免其它线程释放了自己加的锁
当业务执行完成之后,肯定需要主动释放锁,那么为什么需要主动释放锁呢?
第一,假设任务执行完,没有手动释放锁,如果没有指定锁的超时时间,那么因为有看门狗机制,势必会导致这个锁无法释放,那么就可能造成死锁的问题。
第二,如果指定了锁超时时间(锁超时自动释放逻辑后面会说),虽然并不会造成死锁的问题,但是会造成资源浪费的问题。假设设置的过期时间是30s,但是任务2s就完成了,那么这个锁还会白白被占有28s的时间,这28s内其它线程都无法成功加锁。
所以任务完成之后,一定需要主动释放锁。
那么Redisson是如何主动释放锁和避免其它线程释放了自己加的锁?
主动释放锁是通过unlock方法来完成的,接下来就分析一下unlock方法的实现。unlock会调用unlockAsync,传入当然释放线程的id,代表了当前线程来释放锁,unlock其实也是将unlockAsync的异步操作转为同步操作。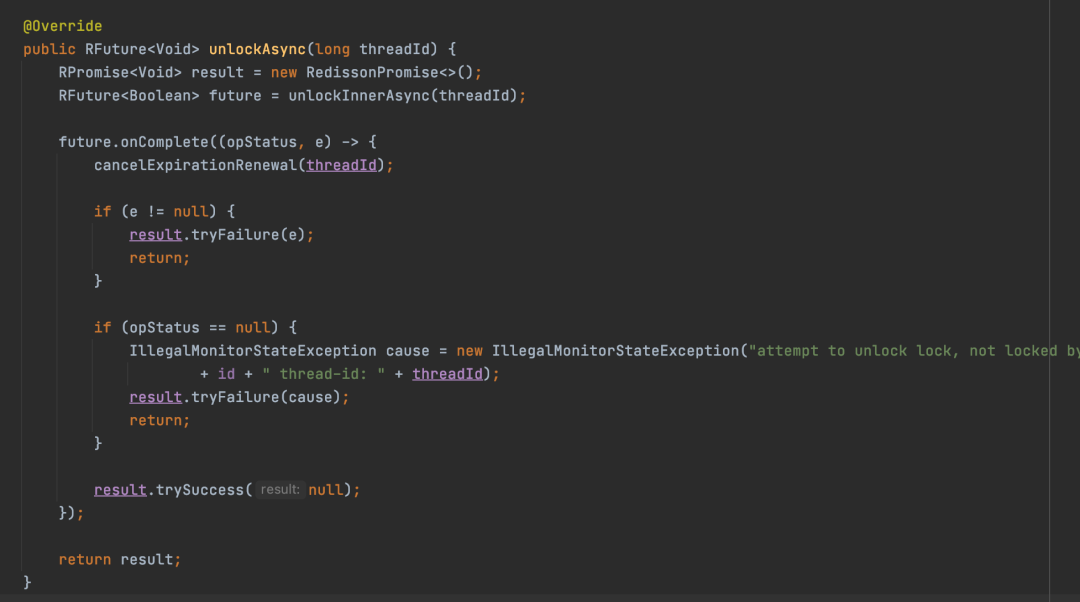
unlockAsync最后会调用RedissonLock的unlockInnerAsync来实现释放锁的逻辑。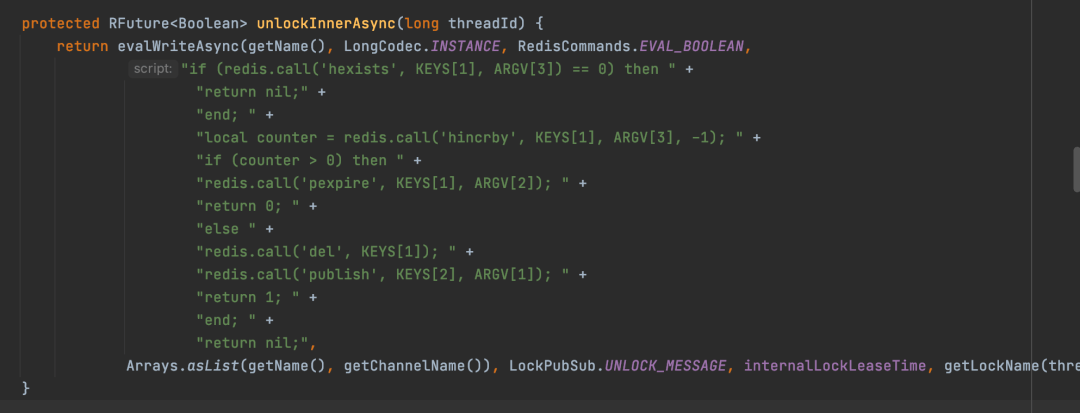
也是执行一段lua脚本。
1)先判断来释放锁的线程是不是加锁的线程,如果不是,那么直接返回nil,所以从这里可以看出,主要是通过一个if条件来防止线程释放了其它线程加的锁。
2)如果来释放锁的线程是加锁的线程,那么就将加锁次数减1,然后拿到剩余的加锁次数 counter 变量。
3)如果counter大于0,说明有重入加锁,锁还没有彻底的释放完,那么就设置一下锁的过期时间,然后返回0
4)如果counter没大于0,说明当前这个锁已经彻底释放完了,于是就把锁对应的key给删除,然后发布一个锁已经释放的消息,然后返回1。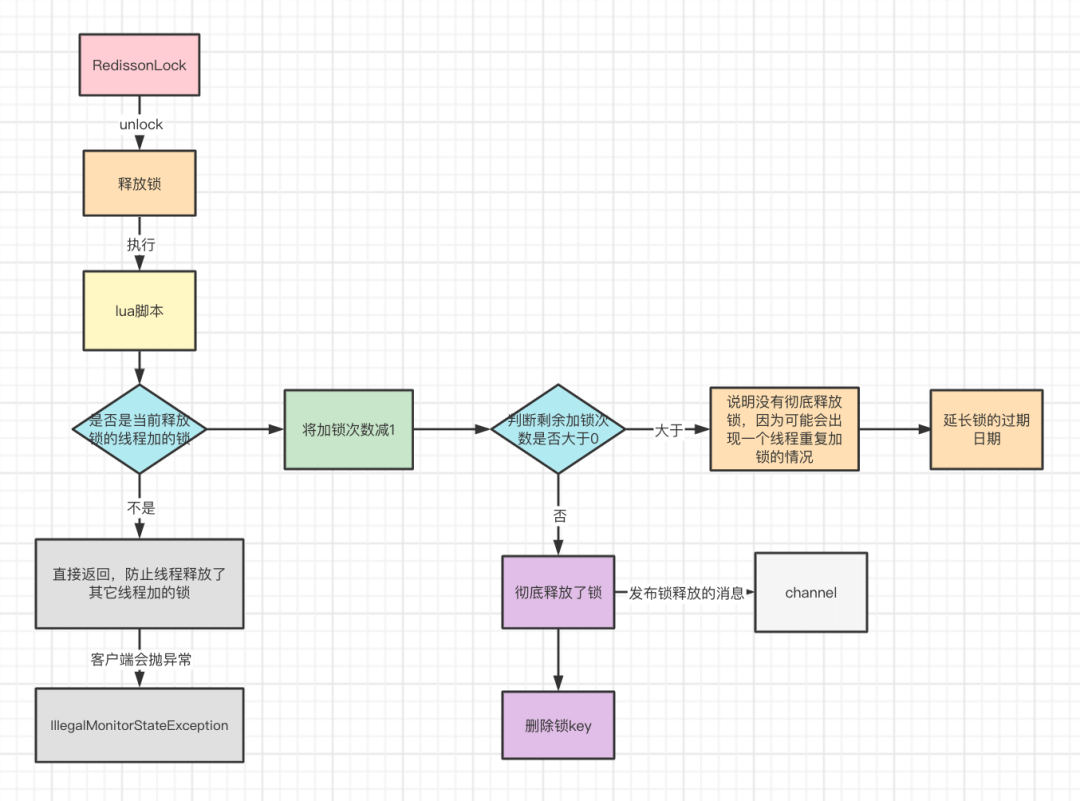
七、如何实现超时自动释放锁
前面说了不指定锁超时时间的话,那么会有看门狗线程不断的延长加锁时间,不会导致锁超时释放,自动过期。那么指定超时时间的话,是如何实现到了指定时间超时释放锁的呢?
能够设置超时自动释放锁的方法。
void lock(long leaseTime, TimeUnit unit)boolean tryLock(long waitTime, long leaseTime, TimeUnit unit)
通过传入leaseTime参数就可以指定锁超时的时间。
无论指不指定超时时间,最终其实都会调用tryAcquireAsync方法,只不过当不指定超时时间时,leaseTime传入的是-1,也就是代表不指定超时时间,但是Redisson默认还是会设置30s的过期时间;当指定超时时间,那么leaseTime就是自己指定的时间,最终也是通过同一个加锁的lua脚本逻辑。
指定和不指定超时时间的主要区别是,加锁成功之后的逻辑不一样,不指定超时时间时,会开启watchdog后台线程,不断的续约加锁时间,而指定超时时间,就不会去开启watchdog定时任务,这样就不会续约,加锁key到了过期时间就会自动删除,也就达到了释放锁的目的。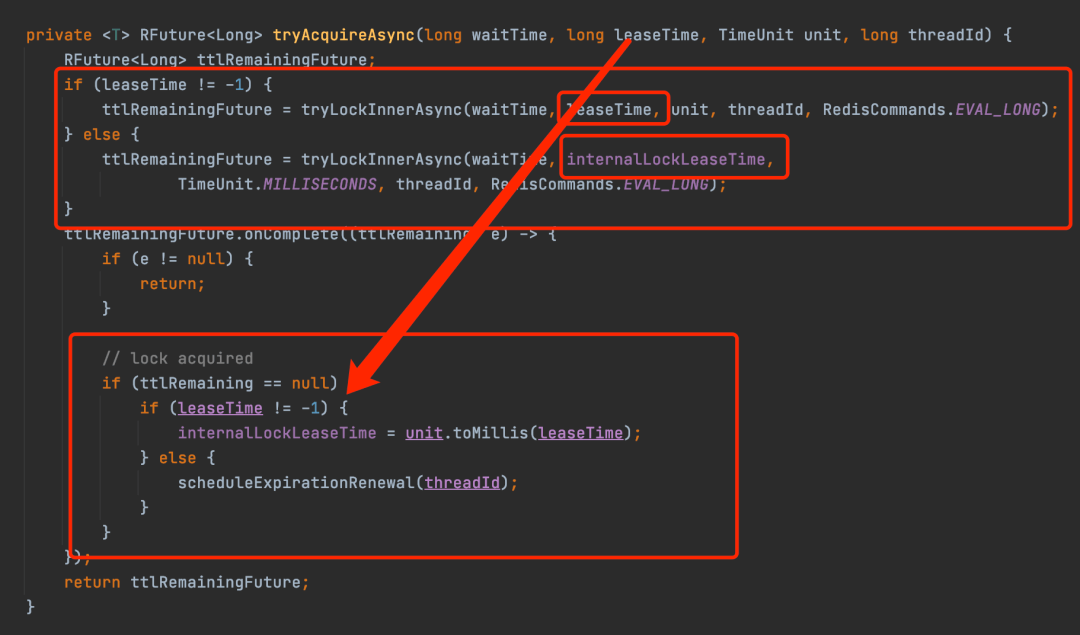
所以指定超时时间达到超时释放锁的功能主要还是通过redis自动过期来实现,因为指定了超时时间,加锁成功之后就不会开启watchdog机制来延长加锁的时间。
在实际项目中,指不指定锁的超时时间是根据具体的业务来的,如果能够比较准确的预估出代码执行的时间,那么可以指定锁超时释放时间来防止业务执行错误导致无法释放锁的问题,如果不能预估出代码执行的时间,那么可以不指定超时时间。
八、如何实现不同线程加锁的互斥
上面分析了第一次加锁逻辑和可重入加锁的逻辑,因为lua脚本加锁的逻辑同时只有一个线程能够执行(redis是单线程的原因),所以一旦有线程加锁成功,那么另一个线程来加锁,前面两个if条件都不成立,最后通过调用redis的pttl命令返回锁的剩余的过期时间回去。
这样,客户端就根据返回值来判断是否加锁成功,因为第一次加锁和可重入加锁的返回值都是nil,而加锁失败就返回了锁的剩余过期时间。
所以加锁的lua脚本通过条件判断就实现了加锁的互斥操作,保证其它线程无法加锁成功。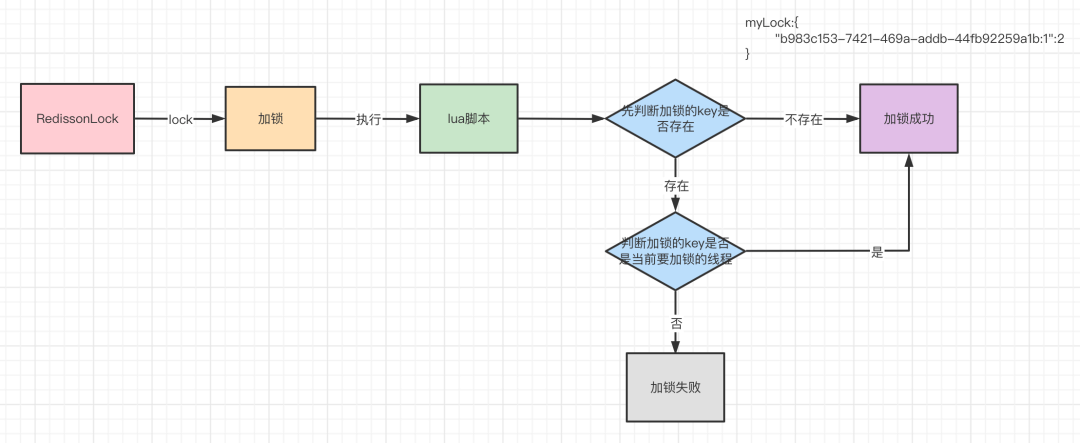
所以总的来说,加锁的lua脚本实现了第一次加锁、可重入加锁和加锁互斥的逻辑。
九、加锁失败之后如何实现阻塞等待加锁
从上面分析,加锁失败之后,会走如下的代码。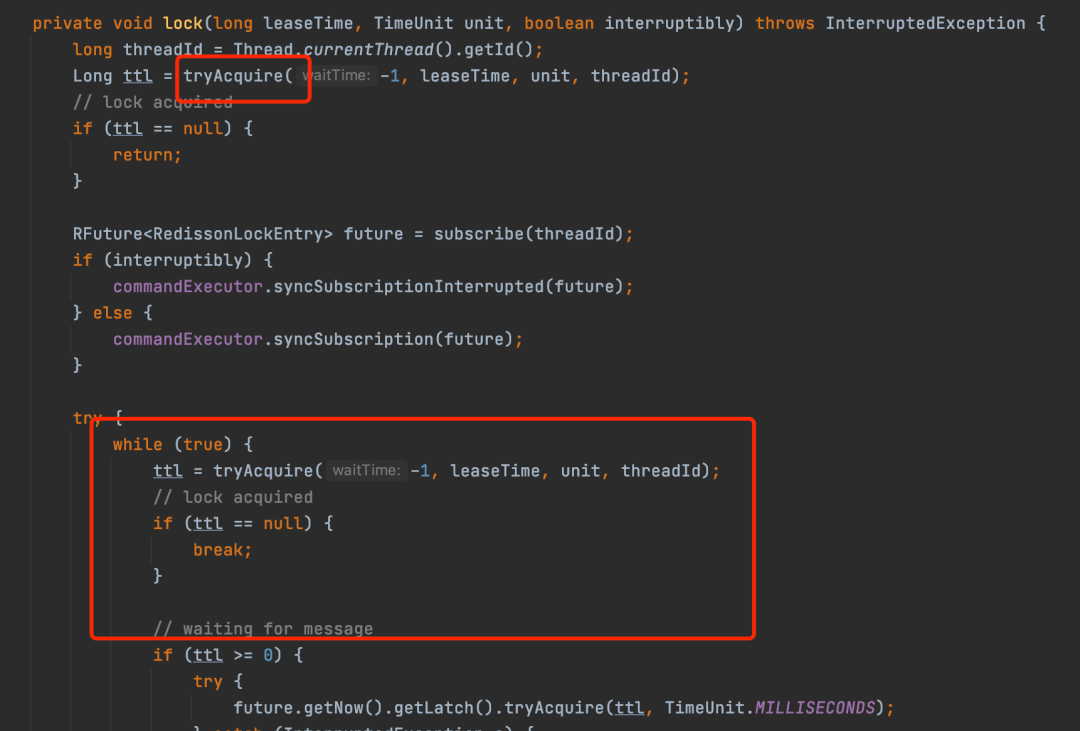
从这里可以看出,最终会执行死循环(自旋)地的方式来不停地通过tryAcquire方法来尝试加锁,直到加锁成功之后才会跳出死循环,如果一直没有成功加锁,那么就会一直旋转下去,所谓的阻塞,实际上就是自旋加锁的方式。
但是这种阻塞可能会产生问题,因为如果其它线程释放锁失败,那么这个阻塞加锁的线程会一直阻塞加锁,这肯定会出问题的。所以有没有能够可以指定阻塞的时间,如果超过一定时间还未加锁成功的话,那么就放弃加锁的方法。答案肯定是有的,接着往下看。
十、如何实现阻塞等待一定时间还未加锁成功就放弃加锁
超时放弃加锁的方法
boolean tryLock(long waitTime, long leaseTime, TimeUnit unit)boolean tryLock(long time, TimeUnit unit)
通过waitTime参数或者time参数来指定超时时间。这两个方法的主要区别就是上面的方法支持指定锁超时时间,下面的方法不支持锁超时自动释放。tryLock(long time, TimeUnit unit)这个方法最后也是调用tryLock(long waitTime, long leaseTime, TimeUnit unit)方法的实现。代码如下。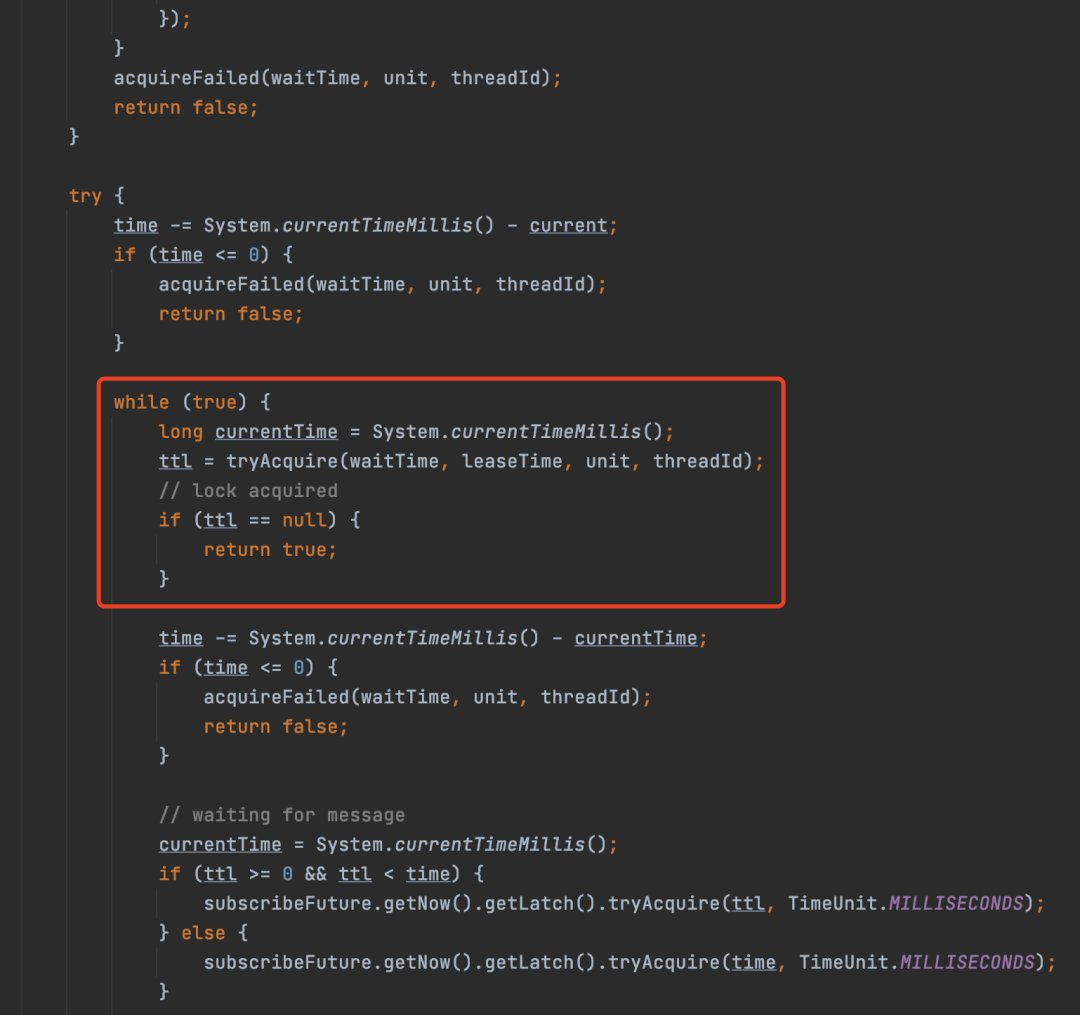
其实通过源码就可以看出是怎么实现一定时间之内还未获取到锁就放弃加锁的逻辑,其实相比于一直获取锁,主要是加了超时的判断,如果超时了,那么就退出循环,放弃加锁,
十一、如何实现公平锁
1)什么是公平锁
所谓的公平锁就是指线程成功加锁的顺序跟线程来加锁的顺序是一样,实现了先来先成功加锁的特性,所以叫公平锁。就跟排队一样,不插队才叫公平。
前面几节讲的RedissonLock的实现是非公平锁,但是里面的一些机制,比如看门狗都是一样的。
2)公平锁和非公平锁的比较
公平锁的优点是按序平均分配锁资源,不会出现线程饿死的情况,它的缺点是按序唤醒线程的开销大,执行性能不高。非公平锁的优点是执行效率高,谁先获取到锁,锁就属于谁,不会“按资排辈”以及顺序唤醒,但缺点是资源分配随机性强,可能会出现线程饿死的情况。
3)如何使用公平锁?
通过RedissonClient的getFairLock就可以获取到公平锁。Redisson对于公平锁的实现是RedissonFairLock类,通过RedissonFairLock来加锁,就能实现公平锁的特性,使用代码如下。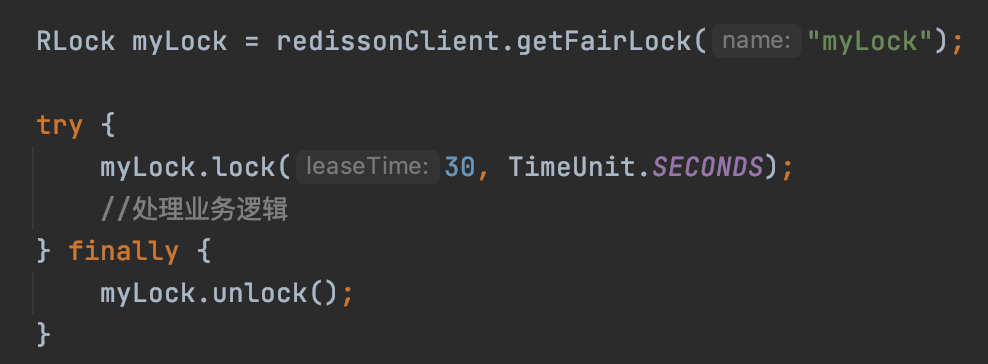
RedissonFairLock继承了RedissonLock,主要是重写了tryLockInnerAsync方法,也就是加锁逻辑的方法。
下面来分析一下RedissonFairLock的加锁逻辑。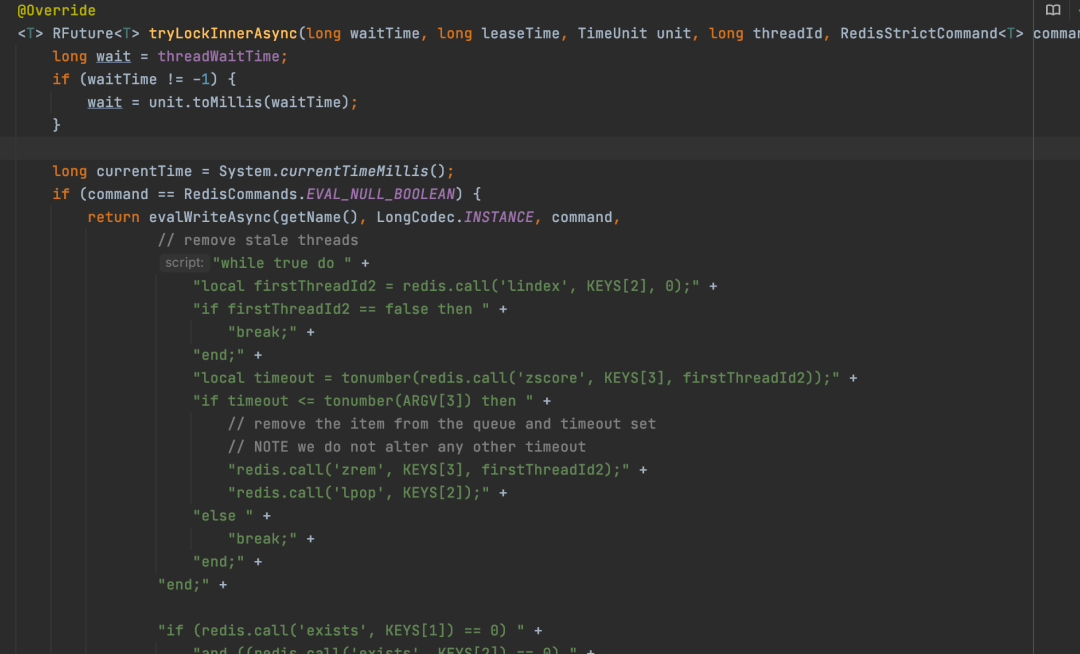
这段加锁的逻辑很长,简单说一下这段lua脚本干了啥。
当线程来加锁的时候,如果加锁失败了,那么会将线程扔到一个set集合中,这样就按照加锁的顺序给线程排队,set集合的头部的线程就代表了接下来能够加锁成功的线程。当有线程释放了锁之后,其它加锁失败的线程就会来继续加锁,加锁之前会先判断一下set集合的头部的线程跟当前要加锁的线程是不是同一个,如果是的话,那就加锁成功,如果不是的话,那么就加锁失败,这样就实现了加锁的顺序性。
当然这段lua脚本还做了一些其它细节的事,这里就不再赘述。
十二、如何实现读写锁
在实际的业务场景中,其实会有很多读多写少的场景,那么对于这种场景来说,使用独占锁来加锁,在高并发场景下会导致大量的线程加锁失败,阻塞,对系统的吞吐量有一定的影响,为了适配这种读多写少的场景,Redisson也实现了读写锁的功能。
读写锁的特点:
- 读与读是共享的,不互斥
- 读与写互斥
- 写与写互斥
Redisson使用读写锁的代码。
Redisson通过RedissonReadWriteLock类来实现读写锁的功能,通过这个类可以获取到读锁或者写锁,所以真正的加锁的逻辑是由读锁和写锁实现的。
那么Redisson是如何具体实现读写锁的呢?
前面说过,加锁成功之后会在redis中维护一个hash的数据结构,存储加锁线程和加锁次数。在读写锁的实现中,会往hash数据结构中多维护一个mode的字段,来表示当前加锁的模式。
所以能够实现读写锁,最主要是因为维护了一个加锁模式的字段mode,这样有线程来加锁的时候,就能根据当前加锁的模式结合读写的特性来判断要不要让当前来加锁的线程加锁成功。
- 如果没有加锁,那么不论是读锁还是写锁都能加成功,成功之后根据锁的类型维护mode字段。
- 如果模式是读锁,那么加锁线程是来加读锁的,就让它加锁成功。
- 如果模式是读锁,那么加锁线程是来加写锁的,就让它加锁失败。
- 如果模式是写锁,那么加锁线程是来加写锁的,就让它加锁失败(加锁线程自己除外)。
- 如果模式是写锁,那么加锁线程是来加读锁的,就让它加锁失败(加锁线程自己除外)。
十三、如何实现批量加锁(联锁)
批量加锁的意思就是同时加几个锁,只有这些锁都算加成功了,才是真正的加锁成功。
比如说,在一个下单的业务场景中,同时需要锁定订单、库存、商品,基于这种需要锁多种资源的场景中,Redisson提供了批量加锁的实现,对应的实现类是RedissonMultiLock。
Redisson提供了批量加锁使用代码如下。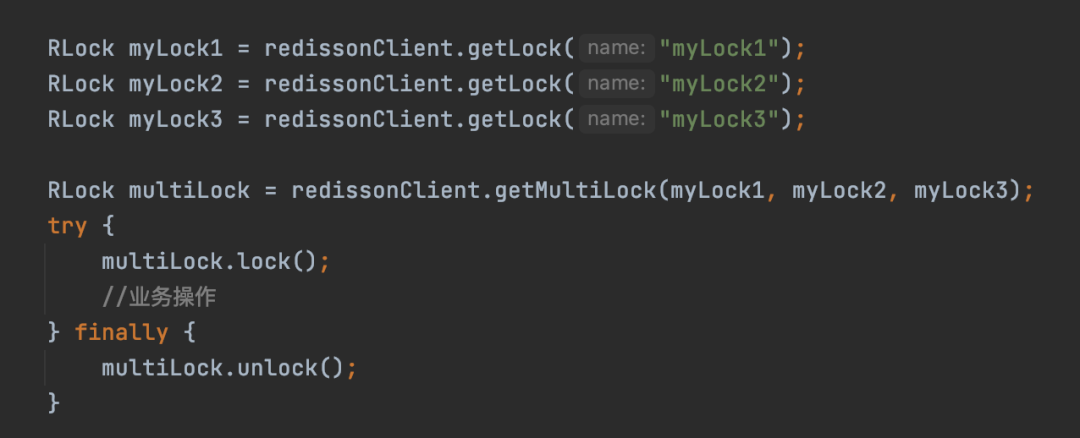
Redisson对于批量加锁的实现其实很简单,源码如下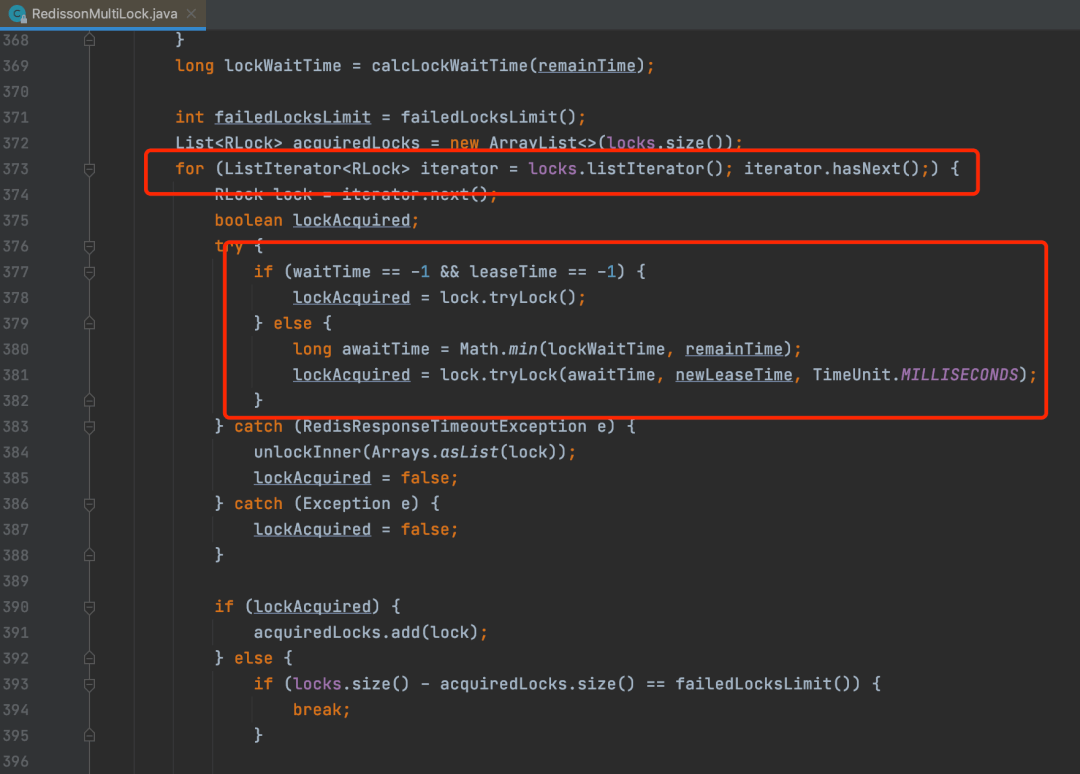
就是根据顺序去依次调用传入myLock1、myLock2、myLock3 加锁方法,然后如果都成功加锁了,那么multiLock就算加锁成功。十四、Redis分布式锁存在的问题
对于单Redis实例来说,如果Redis宕机了,那么整个系统就无法工作了。所以为了保证Redis的高可用性,一般会使用主从或者哨兵模式。但是如果使用了主从或者哨兵模式,此时Redis的分布式锁的功能可能就会出现问题。
举个例子来说,假如现在使用了哨兵模式,如图。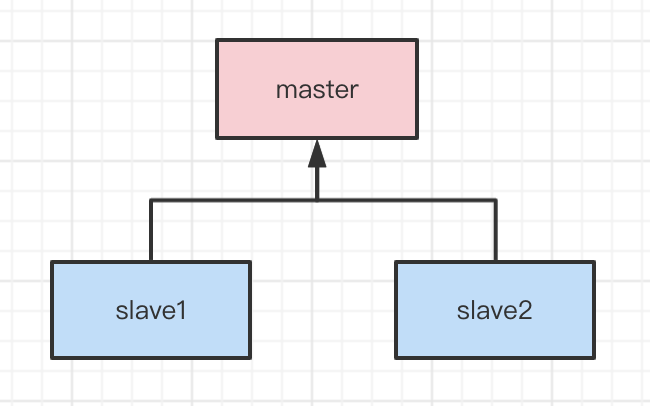
基于这种模式,Redis客户端会在master节点上加锁,然后异步复制给slave节点。
但是突然有一天,因为一些原因,master节点宕机了,那么哨兵节点感知到了master节点宕机了,那么就会从slave节点选择一个节点作为主节点,实现主从切换,如图: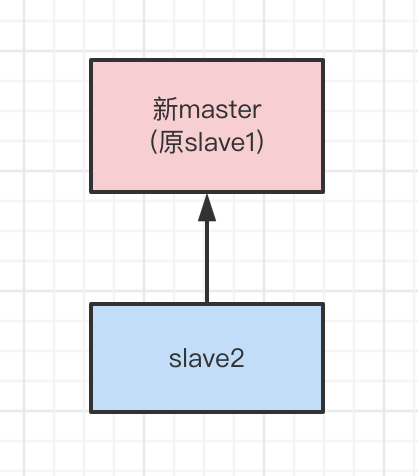
这种情况看似没什么问题,但是不幸的事发生了,那就是客户端对原先的主节点加锁,加成之后还没有来得及同步给从节点,主节点宕机了,从节点变成了主节点,此时从节点是没有加锁信息的,如果有其它的客户端来加锁,是能够加锁成功的,这不是很坑爹么。。
那么如何解决这种问题呢?Redis官方提供了一种叫RedLock的算法,Redisson刚好实现了这种算法,接着往下看。十五、如何实现RedLock算法
RedLock算法
在Redis的分布式环境中,假设有N个Redis master。这些节点完全互相独立,不存在主从复制或者其他集群协调机制。之前已经描述了在Redis单实例下怎么安全地获取和释放锁。确保将在每(N)个实例上使用此方法获取和释放锁。在这个样例中,假设有5个Redis master节点,这是一个比较合理的设置,所以需要在5台机器上面或者5台虚拟机上面运行这些实例,这样保证他们不会同时都宕掉。
为了取到锁,客户端应该执行以下操作:
- 获取当前Unix时间,以毫秒为单位。
- 依次尝试从N个实例,使用相同的key和随机值获取锁。在步骤2,当向Redis设置锁时,客户端应该设置一个网络连接和响应超时时间,这个超时时间应该小于锁的失效时间。例如锁自动失效时间为10秒,则超时时间应该在5-50毫秒之间。这样可以避免服务器端Redis已经挂掉的情况下,客户端还在死死地等待响应结果。如果服务器端没有在规定时间内响应,客户端应该尽快尝试另外一个Redis实例。
- 客户端使用当前时间减去开始获取锁时间(步骤1记录的时间)就得到获取锁使用的时间。当且仅当从大多数(这里是3个节点)的Redis节点都取到锁,并且使用的时间小于锁失效时间时,锁才算获取成功。
- 如果取到了锁,key的真正有效时间等于有效时间减去获取锁所使用的时间(步骤3计算的结果)。
- 如果因为某些原因,获取锁失败(没有在至少N/2+1个Redis实例取到锁或者取锁时间已经超过了有效时间),客户端应该在所有的Redis实例上进行解锁(即便某些Redis实例根本就没有加锁成功)。
Redisson对RedLock算法的实现
使用方法如下。 ```java RLock lock1 = redissonInstance1.getLock(“lock1”); RLock lock2 = redissonInstance2.getLock(“lock2”); RLock lock3 = redissonInstance3.getLock(“lock3”);
RedissonRedLock lock = new RedissonRedLock(lock1, lock2, lock3);
// 同时加锁:lock1 lock2 lock3
// 红锁在大部分节点上加锁成功就算成功。
lock.lock();
…
lock.unlock();
``
RedissonRedLock`加锁过程如下:
- 获取所有的redisson node节点信息,循环向所有的redisson node节点加锁,假设节点数为N,例子中N等于5。一个redisson node代表一个主从节点。
- 如果在N个节点当中,有N/2 + 1个节点加锁成功了,那么整个
RedissonRedLock加锁是成功的。 - 如果在N个节点当中,小于N/2 + 1个节点加锁成功,那么整个
RedissonRedLock加锁是失败的。 - 如果中途发现各个节点加锁的总耗时,大于等于设置的最大等待时间,则直接返回失败。
RedissonRedLock底层其实也就基于RedissonMultiLock实现的,RedissonMultiLock要求所有的加锁成功才算成功,RedissonRedLock要求只要有N/2 + 1个成功就算成功。

若有收获,就点个赞吧
0 人点赞
