1、开源项目简介

比 MyBatis 效率快 100 倍的条件检索引擎,天生支持联表,使一行代码实现复杂列表检索成为可能!
2、开源协议
3、界面展示
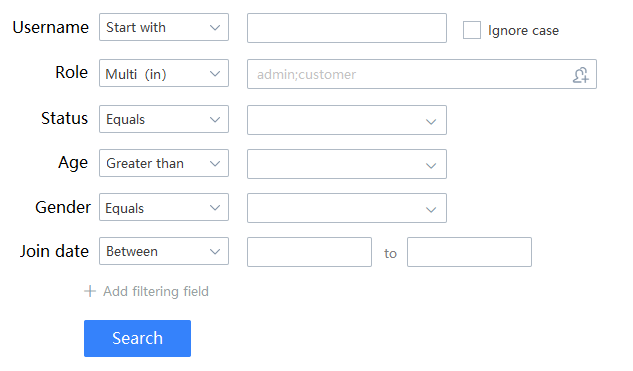
产品画了以上一张图,还附带了一些要求:
- 检索结果分页展示
- 可以按任意字段排序
- 按检索条件统计某些字段值
这时候,后台接口该怎么写???使用 Mybatis 或 Hibernate 写 100 行代码是不是还打不住?而使用 Bean Searcher,只需 一行代码 便可实现上述要求!!!
4、功能概述
特性
- 支持 实体多表映射
- 支持 动态字段运算符
- 支持 分组聚合 查询
- 支持 Select | Where | From 子查询
- 支持 实体类嵌入参数
- 支持 字段转换器
- 支持 Sql 拦截器
- 支持 数据库 Dialect 扩展
- 支持 多数据源 与 动态数据源
- 支持 注解缺省 与 自定义
- 支持 字段运算符 扩展
-
快速开发
使用 Bean Searcher 可以极大节省后端的复杂列表检索接口的开发时间
集成简单
可以和任意 Java Web 框架集成,如:SpringBoot、Grails、Jfinal 等
扩展性强
面向接口设计,用户可自定义扩展 Bean Searcher 中的任何组件
支持 注解缺省
约定优于配置,可省略注解,可复用原有域类,同时支持自定义注解
支持 多数据源
分库分表?在这里特别简单,告别分库分表带来的代码熵值增高问题
支持 Select 指定字段
同一个实体类,可指定只 Select 其中的某些字段,或排除某些字段
支持 参数过滤器
支持 字段转换器
支持添加多个字段转换器,可自定义数据库字段到实体类字段的转换规则
支持 SQL 拦截器
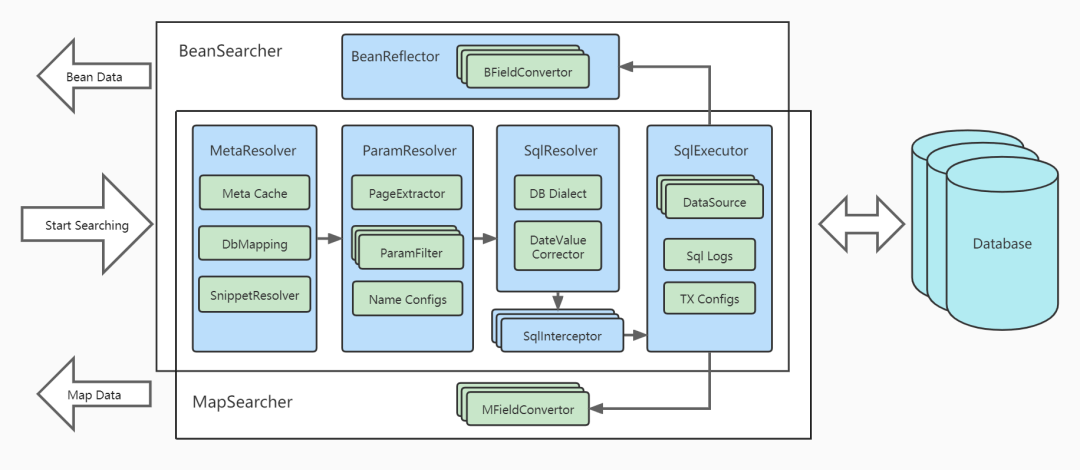
5、技术选型
框架目的:只一行代码实现:多表联查分页搜索任意字段组合过滤任意字段排序多字段统计
- 架构图:
这绝不是一个重复的轮子
虽然 增删改 是 hibernate 和 mybatis、data-jdbc 等等 ORM 的强项,但查询,特别是有 多条件、联表、分页、排序 的复杂的列表查询,却一直是它们的弱项。
传统的 ORM 很难用较少的代码实现一个复杂的列表检索,但 Bean Searcher 却在这方面下足了功夫,这些复杂的查询,几乎只用一行代码便可以解决。
- 例如,这样的一个典型的需求:
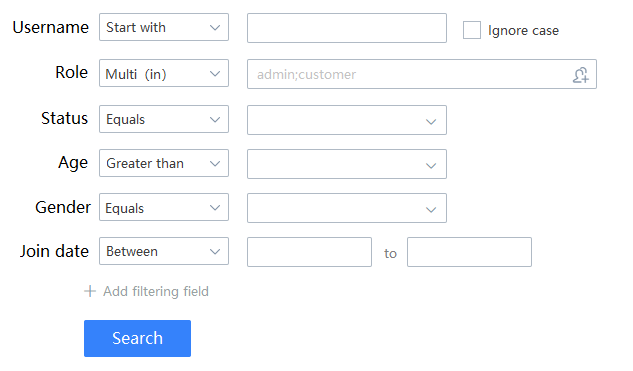
后端需要写一个检索接口,而如果用传统的 ORM 来写,代码之复杂是可以想象的。
而 Bean Searcher 却可以:
只一行代码实现以上功能
首先,有一个实体类:
@SearchBean(tables="user u, role r", joinCond="u.role_id = r.id", autoMapTo="u")public class User {private long id;private String username;private int status;private int age;private String gender;private Date joinDate;private int roleId;@DbField("r.name")private String roleName;// Getters and setters...}
然后就可以用一行代码实现这个用户检索接口:
@RestController@RequestMapping("/user")public class UserController {@Autowiredprivate BeanSearcher beanSearcher; // 注入 BeanSearcher 的检索器@GetMapping("/index")public SearchResult<User> index(HttpServletRequest request) {// 这里只写一行代码return beanSearcher.search(User.class, MapUtils.flat(request.getParameterMap()), new String[]{ "age" });}}
这一行代码实现了以下功能:
- 多表联查
- 分页搜索
- 组合过滤
- 任意字段排序
- 字段统计
例如,该接口支持如下请求:
- GET: /user/index
- 无参请求(默认分页):
- { “dataList”: [ { “id”: 1, “username”: “Jack”, “status”: 1, “level”: 1, “age”: 25, “gender”: “Male”, “joinDate”: “2021-10-01” }, … // 默认返回 15 条数据 ], “totalCount”: 100, “summaries”: [ 2500 // age 字段统计 ] }
- GET: /user/index? page=1 & size=10
- 指定分页参数
- GET: /user/index? status=1
- 返回 status = 1 的用户
- GET: /user/index? name=Jac & name-op=sw
- 返回 name 已 Jac 开头的用户
- GET: /user/index? name=Jack & name-ic=true
- 返回 name = Jack(忽略大小写)的用户
- GET: /user/index? sort=age & order=desc
- 按字段 age 降序查询
- GET: /user/index? onlySelect=username,age
- 只检索 username 与 age 两个字段:
- { “dataList”: [ { “username”: “Jack”, “age”: 25 }, … ], “totalCount”: 100, “summaries”: [ 2500 ] }
- GET: /user/index? selectExclude=joinDate
-
参数构建器
Map<String, Object> params = MapUtils.builder().selectExclude(User::getJoinDate) // 排除 joinDate 字段.field(User::getStatus, 1) // 过滤:status = 1.field(User::getName, "Jack").ic() // 过滤:name = 'Jack' (case ignored).field(User::getAge, 20, 30).op(Opetator.Between) // 过滤:age between 20 and 30.orderBy(User::getAge, "asc") // 排序:年龄,从小到大.page(0, 15) // 分页:第 0 页, 每页 15 条.build();List<User> users = beanSearcher.searchList(User.class, params);
快速开发
使用 Bean Searcher 可以极大地节省后端的复杂列表检索接口的开发时间!
普通的复杂列表查询只需一行代码
- 单表检索可复用原有 Domain,无需定义 SearchBean
集成简单
可以和任意 Java Web 框架集成,如:SpringBoot、Spring MVC、Grails、Jfinal 等等。Spring Boot 项目,添加依赖即集成完毕:
接着便可在 Controller 或 Service 里注入检索器: ```java /**implementation 'com.ejlchina:bean-searcher-boot-stater:3.6.0'
- 注入 Map 检索器,它检索出来的数据以 Map 对象呈现 */ @Autowired private MapSearcher mapSearcher;
/**
- 注入 Bean 检索器,它检索出来的数据以 泛型 对象呈现
*/
@Autowired
private BeanSearcher beanSearcher;
然后可以使用 SearcherBuilder 构建一个检索器: ```java DataSource dataSource = … // 拿到应用的数据源<a name="KOmbQ"></a>#### 其它框架,使用如下依赖:```groovyimplementation 'com.ejlchina:bean-searcher:3.6.0'
// DefaultSqlExecutor 也支持多数据源 SqlExecutor sqlExecutor = new DefaultSqlExecutor(dataSource);
// 构建 Map 检索器 MapSearcher mapSearcher = SearcherBuilder.mapSearcher() .sqlExecutor(sqlExecutor) .build();
// 构建 Bean 检索器 BeanSearcher beanSearcher = SearcherBuilder.beanSearcher() .sqlExecutor(sqlExecutor) .build(); ```
扩展性强
面向接口设计,用户可自定义扩展 Bean Searcher 中的任何组件!
比如可以:
- 自定义 FieldOp 来支持更多的字段运算符
- 自定义 FieldConvertor 来支持任意的 特殊字段类型
- 自定义 DbMapping 来实现自定义注解,或让 Bean Searcher 识别其它 ORM 的注解
- 自定义 ParamResolver 来支持其它形式的检索参数
- 自定义 Dialect 来支持更多的数据库
-
6、源码地址
- GitHub:https://github.com/ejlchina/bean-searcher

若有收获,就点个赞吧
0 人点赞
