JDK7 的HashMap
先说 JDK7 中的 HashMap 的数据结构,然后再去看 JDK8 中的 HashMap的数据结构.
都知道 JDK7 中的 HashMap 的数据结构是一个数组加上链表的形式,也就是下面这副图,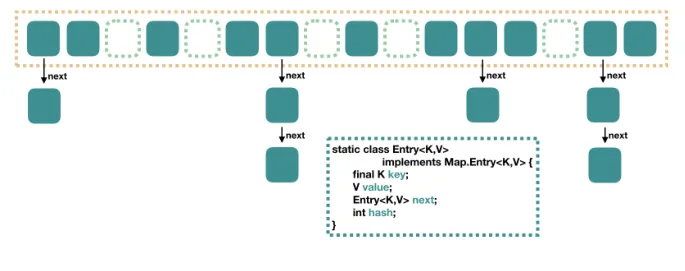
也就是说相当于从左到右,HashMap 就相当于一个数组,而数组中每个元素是一个单向链表,图中的横向的每一个绿色的方块都表示 Entry,Entry 包含四个属性:key, value, hash 值还有用于单向链表的 next。
static final int DEFAULT_INITIAL_CAPACITY = 16;static final float DEFAULT_LOAD_FACTOR = 0.75F;int threshold;final float loadFactor;static class Entry<K, V> implements java.util.Map.Entry<K, V> {final K key;V value;HashMap.Entry<K, V> next;int hash;Entry(int var1, K var2, V var3, HashMap.Entry<K, V> var4) {this.value = var3;this.next = var4;this.key = var2;this.hash = var1;}}
其实如果对比 JDK7 和JDK8 的源码的话,差距不小呢,改动也算是挺大的改动了,
CAPACITY: 当前数组容量,始终保持 2^n,可以扩容,扩容后数组大小为当前的 2 倍
loadFactor: 负载因子,默认为 0.75
threshold: 扩容的阈值,等于 capacity * loadFactor
这时候,HashMap 其实可以看成一种懒加载的方式,当没有数据 put 进来的时候,是不会创建数组的。
当进行put的时候,数据插入到 HashMap 中,
JDK8 的HashMap
Java8 对 HashMap 进行了一些修改,最大的不同就是利用了红黑树,所以其由 数组+链表+红黑 树组成。
就像下面的图: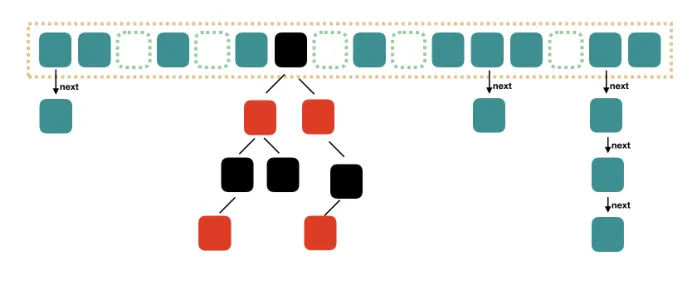
public HashMap(int initialCapacity, float loadFactor) {if (initialCapacity < 0)throw new IllegalArgumentException("Illegal initial capacity: " +initialCapacity);if (initialCapacity > MAXIMUM_CAPACITY)initialCapacity = MAXIMUM_CAPACITY;if (loadFactor <= 0 || Float.isNaN(loadFactor))throw new IllegalArgumentException("Illegal load factor: " +loadFactor);this.loadFactor = loadFactor;this.threshold = tableSizeFor(initialCapacity);}public HashMap(int initialCapacity) {this(initialCapacity, DEFAULT_LOAD_FACTOR);}public HashMap() {this.loadFactor = DEFAULT_LOAD_FACTOR; // all other fields defaulted}
上面是 JDK8 的构造函数
在无参构造函数时,JDK8 是初始化 loadFactor 让其等于默认值,那 JDK7 是什么样子的呢?
public HashMap(int initialCapacity, float loadFactor) {if (initialCapacity < 0)throw new IllegalArgumentException("Illegal initial capacity: " + initialCapacity);if (initialCapacity > MAXIMUM_CAPACITY)initialCapacity = MAXIMUM_CAPACITY;if (loadFactor <= 0 || Float.isNaN(loadFactor))throw new IllegalArgumentException("Illegal load factor: " + loadFactor);this.loadFactor = loadFactor;threshold = initialCapacity;init();}public HashMap(int initialCapacity) {this(initialCapacity, DEFAULT_LOAD_FACTOR);}public HashMap() {this(DEFAULT_INITIAL_CAPACITY, DEFAULT_LOAD_FACTOR);}
这么一看是不是感觉有点类似,但是是不是有那个地方有点不一样呢,对,就是无参构造的时候,JDK8在这里和JDK7出现了差异化的地方,JDK7 是调用了一个有参的构造函数,参数使用了默认值,
但是最终的结果实际上是一致的,都是使用的一个默认值。
这里最重要的就是数据结构了,一个使用的数组+链表,另外一个则是数组+链表+红黑树。
那就区别在红黑树了,就得好好的说说红黑树到底是个什么玩意!
红黑树
红黑树又称红-黑二叉树,它首先是一颗二叉树,它具有二叉树所有的特性。同时红黑树更是一颗自平衡的排序二叉树。
为什么平衡?就是因为它在进行插入和删除操作时通过特定操作保持二叉查找树的平衡,从而获得较高的查找性能。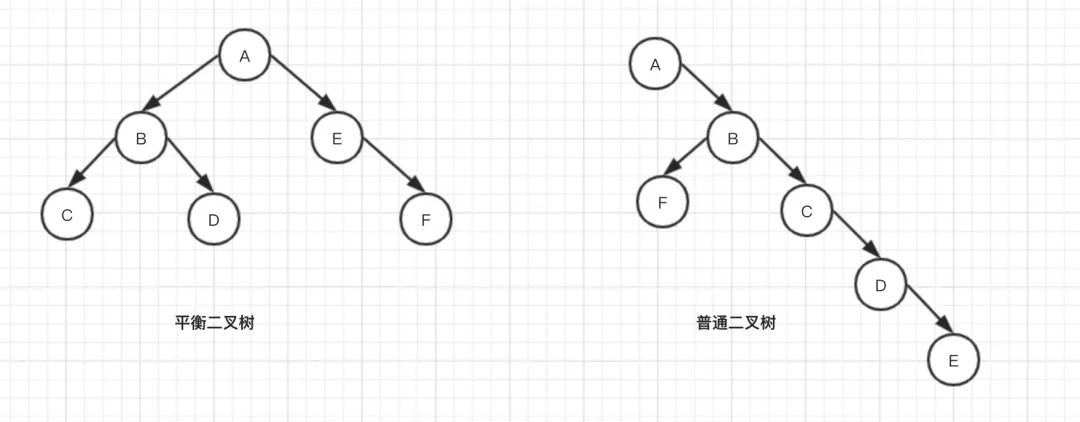
红黑树有下面几个特性
- 1、每个节点要么是红色,要么是黑色,但根节点永远是黑色的;
- 2、每个红色节点的两个子节点一定都是黑色;
- 3、红色节点不能连续(也即是,红色节点的孩子和父亲都不能是红色);
- 4、从任一节点到其子树中每个叶子节点的路径都包含相同数量的黑色节点;
- 5、所有的叶节点都是是黑色的(注意这里说叶子节点其实是上图中的 NIL 节点);
在树的结构发生改变时(插入或者删除操作),往往会破坏上述条件3或条件4,但是呢,他在经过调整过后,还能使得查找树重新满足红黑树的条件
而在 HashMap 中最直接的使用体现,就是在插入的方法上做出和 JDK7 不一样的体现,源码放上:
/*** 红黑树的插入操作*/final TreeNode<K,V> putTreeVal(HashMap<K,V> map, Node<K,V>[] tab,int h, K k, V v) {Class<?> kc = null;boolean searched = false;TreeNode<K,V> root = (parent != null) ? root() : this;for (TreeNode<K,V> p = root;;) {//dir:遍历的方向, ph:p节点的hash值int dir, ph; K pk;//红黑树是根据hash值来判断大小// -1:左孩子方向 1:右孩子方向if ((ph = p.hash) > h)dir = -1;else if (ph < h)dir = 1;//如果key存在的话就直接返回当前节点else if ((pk = p.key) == k || (k != null && k.equals(pk)))return p;//如果当前插入的类型和正在比较的节点的Key是Comparable的话,就直接通过此接口比较else if ((kc == null &&(kc = comparableClassFor(k)) == null) ||(dir = compareComparables(kc, k, pk)) == 0) {if (!searched) {TreeNode<K,V> q, ch;searched = true;//尝试在p的左子树或者右子树中找到了目标元素if (((ch = p.left) != null &&(q = ch.find(h, k, kc)) != null) ||((ch = p.right) != null &&(q = ch.find(h, k, kc)) != null))return q;}//获取遍历的方向dir = tieBreakOrder(k, pk);}//上面的所有if-else判断都是在判断下一次进行遍历的方向,即dirTreeNode<K,V> xp = p;//当下面的if判断进去之后就代表找到了目标操作元素,即xpif ((p = (dir <= 0) ? p.left : p.right) == null) {Node<K,V> xpn = xp.next;//插入新的元素TreeNode<K,V> x = map.newTreeNode(h, k, v, xpn);if (dir <= 0)xp.left = x;elsexp.right = x;//因为TreeNode今后可能退化成链表,在这里需要维护链表的next属性xp.next = x;//完成节点插入操作x.parent = x.prev = xp;if (xpn != null)((TreeNode<K,V>)xpn).prev = x;//插入操作完成之后就要进行一定的调整操作了moveRootToFront(tab, balanceInsertion(root, x));return null;}}}
那么问题来了,他肯定想知道的是为什么要引入红黑树的设计,之前 JDK7 的 HashMap 使用的不是很不错的么?
而答案也是需要理解的:(当冲突的链表长度超过8个的时候),为什么要这样设计呢?好处就是避免在最极端的情况下冲突链表变得很长很长,在查询的时候,效率会非常慢。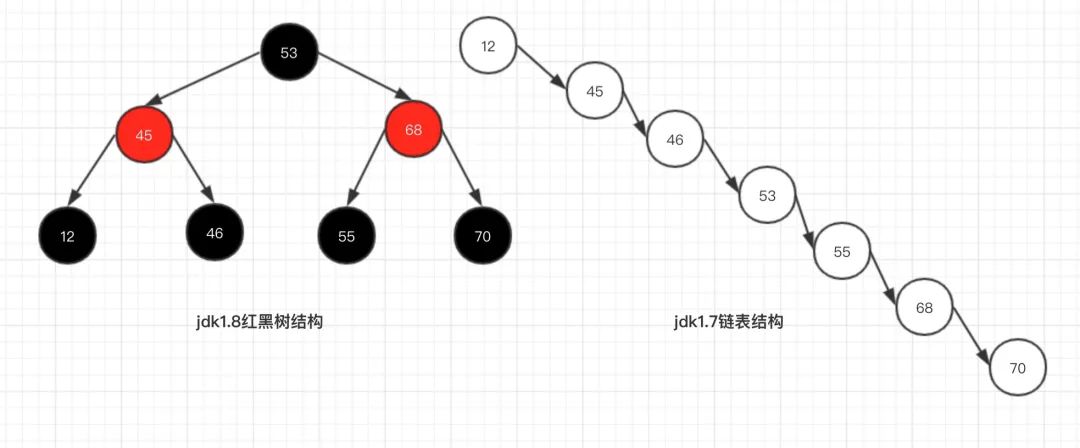
- 红黑树查询:其访问性能近似于折半查找,时间复杂度O(logn);
- 链表查询:这种情况下,需要遍历全部元素才行,时间复杂度O(n);

若有收获,就点个赞吧
0 人点赞
