什么是分库分表
分库,显而易见,就是一个数据库分成多个数据库,部署到不同机器。
分表,就是一个数据库表分成多个表。
那么为什么需要分库分表呢?
为什么需要分库分表?
首先要明确一个问题,单一的数据库是否能够满足公司目前的线上业务需求,比如用户表,可能有几千万,甚至上亿的数据,只是说可能,如果有这么多用户,那必然是大公司了,那么这个时候,如果不分表也不分库的话,那么数据了上来的时候,稍微一个不注意,MySQL单机磁盘容量会撑爆,但是如果拆成多个数据库,磁盘使用率大大降低。
这样就把磁盘使用率降低,这是通过硬件的形式解决问题,如果数据量是巨大的,这时候,SQL 如果没有命中索引,那么就会导致一个情况,查这个表的SQL语句直接把数据库给干崩了。
即使SQL命中了索引,如果表的数据量 超过一千万的话, 查询也是会明显变慢的。这是因为索引一般是B+树结构,数据千万级别的话,B+树的高度会增高,查询自然就变慢了,当然,这是题外话了。
那么接下来就得说说如何进行分库和分表的操作了。
分库分表方案
分库分表方案,不外乎就两种,一种是垂直切分,一种是水平切分。
但是总有做开发的小伙伴不知道这垂直切分和水平切分到底是什么样的,为什么垂直切分,为什么水平切分,什么时候应该选择垂直切分,什么时候应该选择水平切分。
有人是这么说的,垂直切分是根据业务来拆分数据库,同一类业务的数据表拆分到一个独立的数据库,另一类的数据表拆分到其他数据库。
有些人不理解这个,实际上垂直切分也是有划分的,上面描述的是垂直切分数据库,可能容易让很多人不太理解,但是如果是垂直切分表,那么肯定百分之90的人都能理解。
有一张Order表,表中有诸多记录,比如设计这么一张简单的表。
字段有如下。
| id | order_id | order_date | order_type | order_state |
|---|---|---|---|---|
| 1 | cd96cff0356e483caae6b2ff4e878fd6 | 2022-06-11 13:57:11 | 支付宝 | 1 |
| 2 | e2496f9e22ce4391806b18480440526a | 2022-06-12 14:22:33 | 微信 | 2 |
| 3 | 9e7ab5a1915c4570a9eaaaa3c01f79c1 | 2022-06-12 15:21:44 | 现金 | 2 |
以上是简化版Order表,如果想要垂直切分,那么应该怎么处理?
直接拆分成2个表,这时候就直接就一份为2 ,咔的一下拆分成两个表
Order1
| id | order_id | order_date |
|---|---|---|
| 1 | cd96cff0356e483caae6b2ff4e878fd6 | 2022-06-11 13:57:11 |
| 2 | e2496f9e22ce4391806b18480440526a | 2022-06-12 14:22:33 |
| 3 | 9e7ab5a1915c4570a9eaaaa3c01f79c1 | 2022-06-12 15:21:44 |
Order2
| id | order_type | order_state |
|---|---|---|
| 1 | 支付宝 | 1 |
| 2 | 微信 | 2 |
| 3 | 现金 | 2 |
这时候主键ID保持的时一致的,而这个操作,就是垂直拆分,分表的操作,
既然说了垂直拆分,那么必然就有水平拆分,
什么是水平拆分呢?
实际上水平拆分的话,那真的是只有一句话,
按照数据来拆分
水平拆分数据库:将一张表的数据 ( 按照数据行) 分到多个不同的数据库。每个库的表结构相同,每个 库都只有这张表的部分数据,当单表的数据量过大,如果继续使用水平分库,那么数据库的实例 就会不断增加,不利于系统的运维。这时候就要采用水平分表。
水平拆分分表:将一张表的数据 ( 按照数据行) ,分配到同一个数据库的多张表中,每个表都只有一部 分数据。
来看看Order表进行水平拆分的话,是什么样子的。
Order1
| id | order_id | order_date | order_type | order_state |
|---|---|---|---|---|
| 1 | cd96cff0356e483caae6b2ff4e878fd6 | 2022-06-11 13:57:11 | 支付宝 | 1 |
| 2 | e2496f9e22ce4391806b18480440526a | 2022-06-12 14:22:33 | 微信 | 2 |
Order2
| id | order_id | order_date | order_type | order_state |
|---|---|---|---|---|
| 3 | 9e7ab5a1915c4570a9eaaaa3c01f79c1 | 2022-06-12 15:21:44 | 现金 | 2 |
实际上就是水平的把表数据给分成了2份,这么看起来是不是就很好理解了。
分库分表带来的问题
事务问题
首先,分库分表最大的隐患就是,事务的一致性, 当需要更新的内容同时分布在不同的库时,不可避免的会产生跨库的事务问题。原来在一个数据库操 作,本地事务就可以进行控制,分库之后 一个请求可能要访问多个数据库,如何保证事务的一致性,目前还没有简单的解决方案。
无法连表的问题
还有一个就是,没有办法进行连表查询了,因为,, 原来在一个库中的一些表,被分散到多个库,并且这些数据库可能还不在一台服务器,无法关联查询。所以相对应的业务代码可能就比较多了。
分页问题
分库并行查询时,如果用到了分页 每个库返回的结果集本身是无序的,只有将多个库中的数据先查出来,然后再根据排序字段在内存中进行排序,如果查询结果过大也是十分消耗资源的。
分库分表的技术
目前比较流行的就两种,一种是MyCat,另外一种则是Sharding-jdbc,都是可以进行分库的,
MyCat是一个数据库中间件,Sharding-jdbc是以 jar 包提供服务的jdbc框架。
Mycat和Sharding-jdbc 实现原理也是不同,
Mycat的原理中最重要的一个动词是“拦截”,它拦截了用户发送过来的SQL语句,首先对SQL语句做了一些特定的分析:如分库分表分析、路由分析、读写分离分析、缓存分析等,然后将此SQL发往后端的真实数据库,并将返回的结果做适当的处理,最终再返回给用户。
而Sharding-JDBC的原理是接受到一条SQL语句时,会陆续执行SQL解析 => 查询优化 => SQL路由 => SQL改写 => SQL执行 => 结果归并 ,最终返回执行结果。
小结
垂直分表:将一张宽表(字段很多的表),按照字段的访问频次进行拆分,就是按照表单结构进行 拆。
垂直分库:根据不同的业务,将表进行分类,拆分到不同的数据库。这些库可以部署在不同的服 务器,分摊访问压力。
水平分库:将一张表的数据 ( 按照数据行) 分到多个不同的数据库。每个库的表结构相同
水平分表:将一张表的数据 ( 按照数据行) ,分配到同一个数据库的多张表中,每个表都只有一部 分数据。
接下来就实战使用SpringBoot和Mysql 来说实现分库分表,直接先从Sharding 开始,毕竟是jar包的方式,相对来说比较简单。
搭建Sharding环境完成分库分表
Sharding-JDBC分表
第一步
创建数据库及其对应的相同的两张表结构的表
先在MySQL上创建数据库,直接起名叫做order库

然后分别创建两个表,分别是order_1 和order2。
这两张表是订单表拆分后的表,通过Sharding-Jdbc向订单表插入数据,按照一定的分片规则,主键 为偶数的落入order_1表 ,为奇数的落入order_2表,再通过Sharding-Jdbc 进行查询。
DROP TABLE IF EXISTS order_1;CREATE TABLE order_1 (order_id BIGINT(20) PRIMARY KEY AUTO_INCREMENT ,user_id INT(11) ,product_name VARCHAR(128),COUNT INT(11));DROP TABLE IF EXISTS order_2;CREATE TABLE order_2 (order_id BIGINT(20) PRIMARY KEY AUTO_INCREMENT ,user_id INT(11) ,product_name VARCHAR(128),COUNT INT(11));
第二步
创建一个SpringBoot的项目,然后配置Sharding的依赖
依赖如下:
<dependency><groupId>mysql</groupId><artifactId>mysql-connector-java</artifactId></dependency><dependency><groupId>org.mybatis.spring.boot</groupId><artifactId>mybatis-spring-boot-starter</artifactId></dependency><dependency><groupId>com.alibaba</groupId><artifactId>druid-spring-boot-starter</artifactId></dependency><dependency><groupId>org.apache.shardingsphere</groupId><artifactId>sharding-jdbc-spring-boot-starter</artifactId></dependency><dependency><groupId>org.mybatis</groupId><artifactId>mybatis-typehandlers-jsr310</artifactId></dependency><dependency><groupId>junit</groupId><artifactId>junit</artifactId><scope>test</scope></dependency><dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-test</artifactId></dependency><!-- https://mvnrepository.com/artifact/javax.xml.bind/jaxb-api --><dependency><groupId>javax.xml.bind</groupId><artifactId>jaxb-api</artifactId><version>2.3.0-b170201.1204</version></dependency><!-- https://mvnrepository.com/artifact/javax.activation/activation --><dependency><groupId>javax.activation</groupId><artifactId>activation</artifactId><version>1.1</version></dependency><!-- https://mvnrepository.com/artifact/org.glassfish.jaxb/jaxb-runtime --><dependency><groupId>org.glassfish.jaxb</groupId><artifactId>jaxb-runtime</artifactId><version>2.3.0-b170127.1453</version></dependency>
第三步
第三步也是比较重要的一步,那就是配置分片规则,因为这里的分表是直接把数据进行水平拆分成到2个表中,所以属于水平切分数据表的操作,配置如下:
基础配置
spring:application:name: sharding-jdbc-simplehttp:encoding:enabled: truecharset: UTF-8force: truemain:allow-bean-definition-overriding: true
配置数据源
shardingsphere:datasource:names: db1db1:type: com.alibaba.druid.pool.DruidDataSourcedriver-class-name: com.mysql.jdbc.Driverurl: jdbc:mysql://127.0.0.1:3306/order?characterEncoding=UTF-8&useSSL=falseusername: rootpassword: 123456sharding:tables:order:actual-data-nodes: db1.pay_order_$->{1..2}key-generator:column: order_idtype: SNOWFLAKEtable-strategy:inline:sharding-column: order_idalgorithm-expression: pay_order_$->{order_id % 2 + 1}props:sql:show: trueserver:servlet:context-path: /sharding-jdbcmybatis:configuration:map-underscore-to-camel-case: true
上面的配置,就是完整的配置Sharding-JDBC配置了,其中还包括了 Mybatis 的一个配置,以及SQL日志打印。
接下来直接写一个Junit测试,然后在数据库中直接插入数据看一下,偶数订单在表1中,基数订单在表2中。
Junit测试 ```java @Mapper @Component public interface OrderDao { /**- 新增订单
- */ @Insert(“INSERT INTO order(user_id,product_name,COUNT) VALUES(#{user_id},#{product_name},#{count})”) int insertOrder(@Param(“user_id”) int user_id,@Param(“product_name”) String product_name,@Param(“count”) int count); }
//测试 public class OrderTest {
@AutowiredOrderDao orderDao;@Testpublic void testInsertOrder(){for (int i = 0; i < 10; i++) {orderDao.insertOrder(100+i,"大冰箱"+i,10);}}
}
当执行完毕的时候,去数据库里面去看一下这个数据是不是分开保存到两个不同表,在看之前先看看打印的sql日志。```javaSQLStatement: InsertStatement(super=DMLStatement(super=AbstractSQLStatement(type=DML, tables=Tables(tables=[Table(name=order, alias=Optional.absent())]), routeConditions=Conditions(orCondition=OrCondition(andConditions=[AndCondition(conditions=[])])), encryptConditions=Conditions(orCondition=OrCondition(andConditions=[])), sqlTokens=[TableToken(tableName=order, quoteCharacter=NONE, schemaNameLength=0), SQLToken(startIndex=17)], parametersIndex=3, logicSQL=INSERT INTO order(user_id,product_name,COUNT) VALUES(?,?,?)), deleteStatement=false, updateTableAlias={}, updateColumnValues={}, whereStartIndex=0, whereStopIndex=0, whereParameterStartIndex=0, whereParameterEndIndex=0), columnNames=[user_id, product_name, COUNT], values=[InsertValue(columnValues=[org.apache.shardingsphere.core.parse.old.parser.expression.SQLPlaceholderExpression@d611f1c, org.apache.shardingsphere.core.parse.old.parser.expression.SQLPlaceholderExpression@4f2d014a, org.apache.shardingsphere.core.parse.old.parser.expression.SQLPlaceholderExpression@51fc862e])])2022-06-13 13:47:59.923 INFO 7384 --- [ main] ShardingSphere-SQL : Actual SQL: db1 ::: INSERT INTO order_1 (user_id, product_name, COUNT, order_id) VALUES (?, ?, ?, ?) ::: [107, 大冰箱7, 10, 743103497175564288]2022-06-13 13:47:59.976 INFO 7384 --- [ main] ShardingSphere-SQL : Rule Type: sharding2022-06-13 13:47:59.976 INFO 7384 --- [ main] ShardingSphere-SQL : Logic SQL: INSERT INTO order(user_id,product_name,COUNT) VALUES(?,?,?)2022-06-13 13:47:59.976 INFO 7384 --- [ main] ShardingSphere-SQL : SQLStatement: InsertStatement(super=DMLStatement(super=AbstractSQLStatement(type=DML, tables=Tables(tables=[Table(name=order, alias=Optional.absent())]), routeConditions=Conditions(orCondition=OrCondition(andConditions=[AndCondition(conditions=[])])), encryptConditions=Conditions(orCondition=OrCondition(andConditions=[])), sqlTokens=[TableToken(tableName=order, quoteCharacter=NONE, schemaNameLength=0), SQLToken(startIndex=17)], parametersIndex=3, logicSQL=INSERT INTO order(user_id,product_name,COUNT) VALUES(?,?,?)), deleteStatement=false, updateTableAlias={}, updateColumnValues={}, whereStartIndex=0, whereStopIndex=0, whereParameterStartIndex=0, whereParameterEndIndex=0), columnNames=[user_id, product_name, COUNT], values=[InsertValue(columnValues=[org.apache.shardingsphere.core.parse.old.parser.expression.SQLPlaceholderExpression@d611f1c, org.apache.shardingsphere.core.parse.old.parser.expression.SQLPlaceholderExpression@4f2d014a, org.apache.shardingsphere.core.parse.old.parser.expression.SQLPlaceholderExpression@51fc862e])])2022-06-13 13:47:59.977 INFO 7384 --- [ main] ShardingSphere-SQL : Actual SQL: db1 ::: INSERT INTO order_2 (user_id, product_name, COUNT, order_id) VALUES (?, ?, ?, ?) ::: [108, 大冰箱8, 10, 743103497402056705]2022-06-13 13:48:00.036 INFO 7384 --- [ main] ShardingSphere-SQL : Rule Type: sharding2022-06-13 13:48:00.036 INFO 7384 --- [ main] ShardingSphere-SQL : Logic SQL: INSERT INTO order(user_id,product_name,COUNT) VALUES(?,?,?)2022-06-13 13:48:00.036 INFO 7384 --- [ main] ShardingSphere-SQL : SQLStatement: InsertStatement(super=DMLStatement(super=AbstractSQLStatement(type=DML, tables=Tables(tables=[Table(name=order, alias=Optional.absent())]), routeConditions=Conditions(orCondition=OrCondition(andConditions=[AndCondition(conditions=[])])), encryptConditions=Conditions(orCondition=OrCondition(andConditions=[])), sqlTokens=[TableToken(tableName=order, quoteCharacter=NONE, schemaNameLength=0), SQLToken(startIndex=17)], parametersIndex=3, logicSQL=INSERT INTO order(user_id,product_name,COUNT) VALUES(?,?,?)), deleteStatement=false, updateTableAlias={}, updateColumnValues={}, whereStartIndex=0, whereStopIndex=0, whereParameterStartIndex=0, whereParameterEndIndex=0), columnNames=[user_id, product_name, COUNT], values=[InsertValue(columnValues=[org.apache.shardingsphere.core.parse.old.parser.expression.SQLPlaceholderExpression@d611f1c, org.apache.shardingsphere.core.parse.old.parser.expression.SQLPlaceholderExpression@4f2d014a, org.apache.shardingsphere.core.parse.old.parser.expression.SQLPlaceholderExpression@51fc862e])])2022-06-13 13:48:00.036 INFO 7384 --- [ main] ShardingSphere-SQL : Actual SQL: db1 ::: INSERT INTO order_1 (user_id, product_name, COUNT, order_id) VALUES (?, ?, ?, ?) ::: [109, 大冰箱9, 10, 743103497649520640]
再看看数据库:
order2: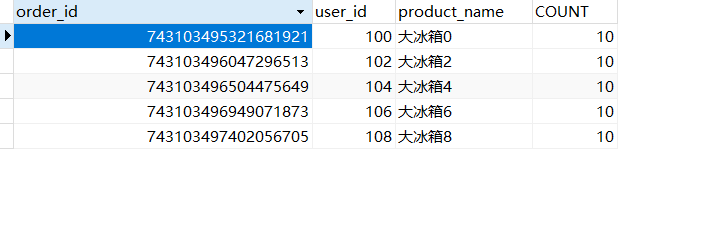
order1: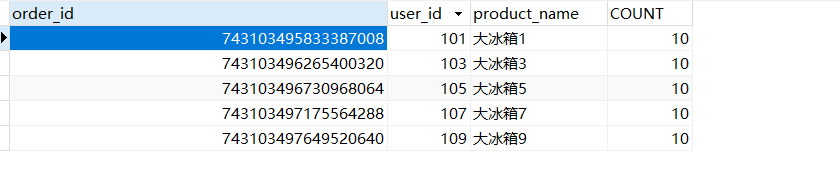
非常完美,直接成功,接下来就是直接执行查询,然后去查询对应表中的数据。
再来一个测试看一下:
@Testpublic void testFindOrderByIds(){List<Long> ids = new ArrayList<>();ids.add(743103495833387008L);ids.add(743103495321681921L);List<Map> list = orderDao.findOrderByIds(ids);System.out.println(list);}
同样的,给定1表和2表中的一个order_id 来进行 In 查询,看是否能正确返回想要的数据:
/*** 根据ID 查询订单* */@Select({"<script>"+"select * from order p where p.order_id in " +"<foreach collection='orderIds' item='id' open='(' separator = ',' close=')'>#{id}</foreach>"+"</script>"})List<Map> findOrderByIds(@Param("orderIds") List<Long> orderIds);
接下来就是看结果的时刻,
[{user_id=101, COUNT=10, order_id=743103495833387008, product_name=大冰箱1}, {user_id=100, COUNT=10, order_id=743103495321681921, product_name=大冰箱0}]
很成功,使用Sharding-JDBC 进行单库水平切分表的操作已经完成了。
水平分库分表
水平分库是把同一个表的数据按一定规则拆到不同的数据库中,每个库可以放在不同的服务器上,在上面装好数据库之后,就可以开始进行操作了。
第一步
创建数据库,分别在不同的两个数据库中创建相同表结构的两个表数据。
database1中,创建一个orderinfo的表
DROP TABLE IF EXISTS orderinfo;CREATE TABLE orderinfo (order_id BIGINT(20) PRIMARY KEY AUTO_INCREMENT ,user_id INT(11) ,product_name VARCHAR(128),COUNT INT(11));
database2中,创建同样的库,创建完成校验一下。
两个表的结构是一样的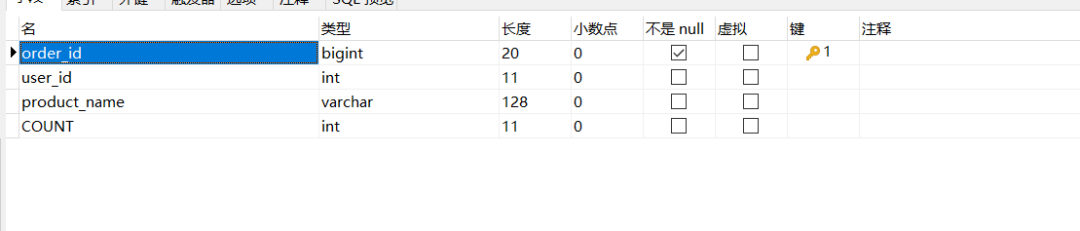
接下来使用上面创建SpringBoot项目。
第二步
更改配置:
spring:application:name: sharding-jdbc-simplehttp:encoding:enabled: truecharset: UTF-8force: truemain:allow-bean-definition-overriding: true#定义数据源shardingsphere:datasource:names: db1,db2db1:type: com.alibaba.druid.pool.DruidDataSourcedriver-class-name: com.mysql.jdbc.Driverurl: jdbc:mysql://localhost:3306/order?characterEncoding=UTF-8&useSSL=falseusername: rootpassword: 123456db2:type: com.alibaba.druid.pool.DruidDataSourcedriver-class-name: com.mysql.jdbc.Driverurl: jdbc:mysql://localhost:3306/ordersharding?characterEncoding=UTF-8&useSSL=falseusername: rootpassword: 123456## 分库策略,以user_id为分片键,分片策略为user_id % 2 + 1,user_id为偶数操作db1数据源,否则操作db2。sharding:tables:orderinfo:actual-data-nodes: db$->{1..2}.orderinfokey-generator:column: order_idtype: SNOWFLAKEdatabase-strategy:inline:sharding-column: user_idalgorithm-expression: db$->{user_id % 2 + 1}props:sql:show: trueserver:servlet:context-path: /sharding-jdbcmybatis:configuration:map-underscore-to-camel-case: true
配置文件,在这里是通过配置对数据库的分片策略,来指定数据库进行操作。
分库策略,以user_id为分片键,分片策略为user_id % 2 + 1,user_id为偶数操作db1数据 源,否则操作db2。
这样的分库策略,直接通过 user_id 的奇偶性,来判断到底是用哪个数据源,用哪个数据库和表数据的。
接下来直接写Junit测试来测试一下。
@AutowiredOrderDao orderDao;@Testpublic void TestInsertShardingDao(){for (int i = 0; i < 10; i++) {orderDao.insertOrder(i,"大电视",1);}}

如果是单独看日志的话,看样子是成功了,那么得实际来验证一下这个内容。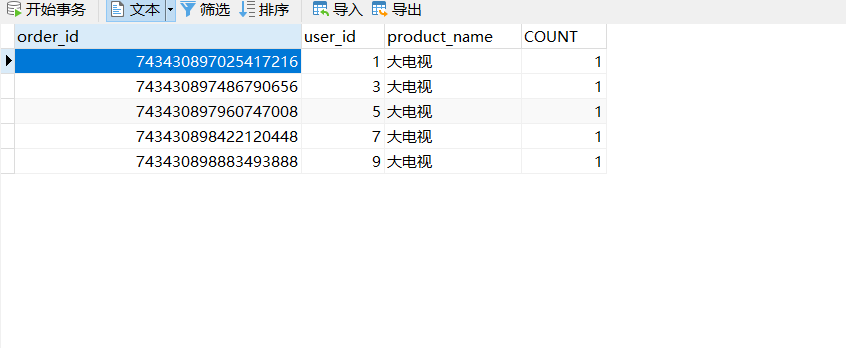
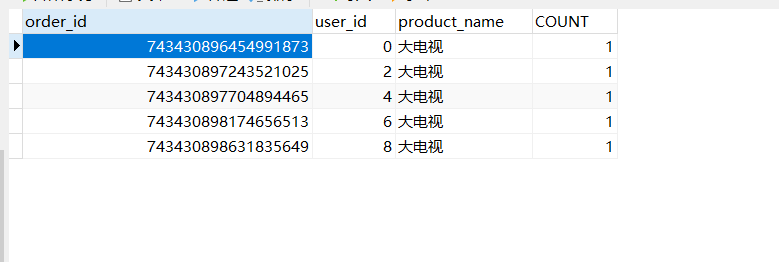
这么看下来,保存的数据是没问题的,从水平切分来看,把数据分别保存了database1 和database2 库中的 orderinfo 里面,也就是说数据算是水平切分到了不同的数据库对应的表中。
接下来是不是就得去执行查询了?
分库分表后的查询
直接查询:
@Testpublic void TestQueryShardingDao(){List<Long> ids = new ArrayList<>();ids.add(743430896454991873L);ids.add(743430897486790656L);List<Map> mapList = orderDao.findOrderByIds(ids); System.out.println(mapList);}/*** 根据ID 查询订单* */@Select({"<script>"+"select * from orderinfo p where p.order_id in " +"<foreach collection='orderIds' item='id' open='(' separator = ',' close=')'>#{id}</foreach>"+"</script>"})List<Map> findOrderByIds(@Param("orderIds") List<Long> orderIds);
直接看返回结果
[{user_id=0, COUNT=1, order_id=743430896454991873, product_name=大电视}, {user_id=3, COUNT=1, order_id=743430897486790656, product_name=大电视}]
这个样子看起来,水平分库分表拆分,是不是就完成了?
在这里,既然实战结束了,就得开始说说这个配置了。
在说配置之前,得先了解一下关于Sharding-JDBC的执行流程,不然也不知道这些配置都是干嘛用的。
当把SQL发送给 Sharding 之后,Sharding 会经过五个步骤,然后返回接口,这五个步骤分别是:
- SQL解析
- SQL路由
- SQL改写
- SQL执行
- 结果归并
SQL解析:编写SQL查询的是逻辑表,执行时 ShardingJDBC 要解析SQL,解析的目的是为了找到需要改写的位置。
SQL路由:SQL的路由是指 将对逻辑表的操作,映射到对应的数据节点的过程. ShardingJDBC会获取分片键判断是否正确,正确 就执行分片策略(算法) 来找到真实的表。
SQL改写:程序员面向的是逻辑表编写SQL,并不能直接在真实的数据库中执行,SQL改写用于将逻辑 SQL改为在真实的数据库中可以正确执行的SQL。
SQL执行:通过配置规则 order_$->{order_id % 2 + 1},可以知道当 order_id 为偶数时,应该向 order_1表中插入数据,为奇数时向 order_2表插入数据。
结果归并:将所有真正执行sql的结果进行汇总合并,然后返回。
都知道,要是用Sharding分库分表,那么自然就会有相对应的配置,而这些配置才是比较重要的地方,而其中比较经典的就是分片策略了。
分片策略
分片策略分为分表策略和分库策略,它们实现分片算法的方式基本相同,没有太大的区别,无非一个是针对库,一个是针对表。
而一般分片策略主要是分为如下的几种:
- standard:标准分片策略
- complex:复合分片策略
- inline:行表达式分片策略,使用Groovy的表达式.
- hint:Hint分片策略,对应
**HintShardingStrategy**。 - none:不分片策略,对应
**NoneShardingStrategy**。不分片的策略。
标准分片策略StandardShardingStrategy
使用场景:SQL 语句中有>,>=, <=,<,=,IN 和 BETWEEN AND 操作符,都可以应用此分片策略。
也就是说,SQL 语句中频繁的出现这些符号的时候,而且这个时候还想要进行分库分表的时候,就可以采用这个策略了。
但是这个时候要谨记一些内容,那就是标准分片策略(StandardShardingStrategy),它只支持对单个分片键(字段)为依据的分库分表,并提供了两种分片算法 PreciseShardingAlgorithm(精准分片)和 RangeShardingAlgorithm(范围分片)。
在使用标准分片策略时,精准分片算法是必须实现的算法,用于 SQL 含有 = 和 IN 的分片处理;范围分片算法是非必选的,用于处理含有 BETWEEN AND 的分片处理。
复合分片策略
使用场景:SQL 语句中有>,>=,<=,<,=,IN 和 BETWEEN AND 等操作符,不同的是复合分片策略支持对多个分片键操作。
这里要注意的就是多个分片键,也就是说,如果分片的话需要使用两个字段作为分片键,自定义复合分片策略。
行表达式分片策略
它的配置相当简洁,这种分片策略利用inline.algorithm-expression书写表达式。
这里就是使用的这个,来完成的分片,而且行表达式分片策略适用于做简单的分片算法,无需自定义分片算法,省去了繁琐的代码开发,是几种分片策略中最为简单的。
但是要注意,行表达式分片策略,它只支持单分片键。
Hint分片策略
Hint分片策略(HintShardingStrategy)和其他的分片策略都不一样了,这种分片策略无需配置分片键,分片键值也不再从 SQL中解析,而是由外部指定分片信息,让 SQL在指定的分库、分表中执行。
不分片策略
不分片策略这个没啥可说的,不分片的话,用Sharing-JDBC的话,可能就没啥意思了。毕竟玩的就是分片。
垂直分库分表
回顾垂直切分
什么是垂直切分,垂直分库是指按照业务将表进行分类,分布到不同的数据库上面,每个库可以放在不同的服务器上,它的核心理念是专库专用,也就是说,需要把不同之间的业务进行分库,比如,支付业务可以创建一个库,而订单业务可以再用另外的一个库保存数据,说起来是简单,实现起来也并没有想象的那么难办。看看如何实现。
垂直分表
垂直分表就是将一个表细分,且在同一个库里,正常操作即可。
这种相对来说就压根没必要用sharding-sphere,数据一部分在一个表,和数据存储在另外一个表,那就意味着,这就是两个表存了不同的数据,比如商品服务,把商品基本信息放在一张表,商品详情放在一张表,这就相当于是垂直分表了,但是看起来总是这么的奇怪,奇怪归奇怪,他还就是这样的。而垂直分库就不是这样的了。来看看如何实现。
垂直分库
第一步
还是需要去创建数据库
然后创建指定的表
DROP TABLE IF EXISTS users;CREATE TABLE users (id BIGINT(20) PRIMARY KEY,username VARCHAR(20) ,phone VARCHAR(11),STATUS VARCHAR(11) );
第二步
接下来就要和之前一样了,开始配置配置数据。
spring:application:name: sharding-jdbc-simplehttp:encoding:enabled: truecharset: UTF-8force: truemain:allow-bean-definition-overriding: true#定义数据源shardingsphere:datasource:names: db1,db2,db3db1:type: com.alibaba.druid.pool.DruidDataSourcedriver-class-name: com.mysql.jdbc.Driverurl: jdbc:mysql://localhost:3306/order?characterEncoding=UTF-8&useSSL=falseusername: rootpassword: 123456db2:type: com.alibaba.druid.pool.DruidDataSourcedriver-class-name: com.mysql.jdbc.Driverurl: jdbc:mysql://localhost:3306/ordersharding?characterEncoding=UTF-8&useSSL=falseusername: rootpassword: 123456#配置user的数据源db3:type: com.alibaba.druid.pool.DruidDataSourcedriver-class-name: com.mysql.jdbc.Driverurl: jdbc:mysql://localhost:3306/user?characterEncoding=UTF-8&useSSL=falseusername: rootpassword: 123456## 分库策略,以user_id为分片键,分片策略为user_id % 2 + 1,user_id为偶数操作db1数据源,否则操作db2。sharding:tables:#配置db3的数据节点users:actual-data-nodes: db$->{3}.userstable-strategy:inline:sharding- column: idalgorithm-expression: usersorderinfo:actual-data-nodes: db$->{1..2}.orderinfokey-generator:column: order_idtype: SNOWFLAKEdatabase-strategy:inline:sharding-column: user_idalgorithm-expression: db$->{user_id % 2 + 1}props:sql:show: trueserver:servlet:context-path: /sharding-jdbcmybatis:configuration:map-underscore-to-camel-case: true
接下来就是去写一组插入语句,然后把数据插入到数据库测试一下。
@RunWith(SpringRunner.class)@SpringBootTest(classes = RunBoot.class)public class UsersDaoTest {@AutowiredUsersDao usersDao;@Testpublic void testInsert(){for (int i = 0; i < 10; i++) {Long id = i+100L;usersDao.insertUser(id,"大佬"+i, "17458236963","1");}}}/*** 新增用户* */@Insert("insert into users(id,username,phone,status) values(#{id},#{username},#{phone},#{status})")int insertUser(@Param("id") Long id, @Param("username") String username, @Param("phone") String phone,@Param("status") String status);
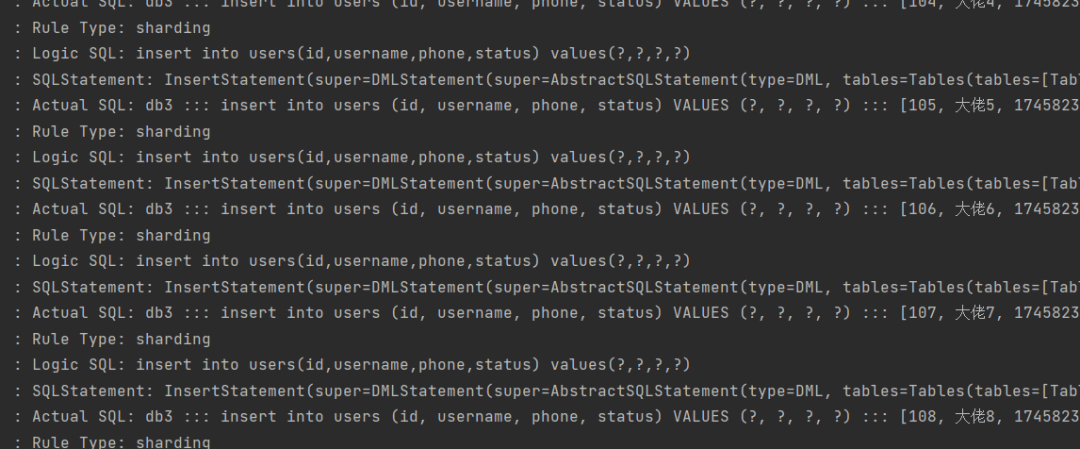
感觉没啥问题,再去数据库验证一下。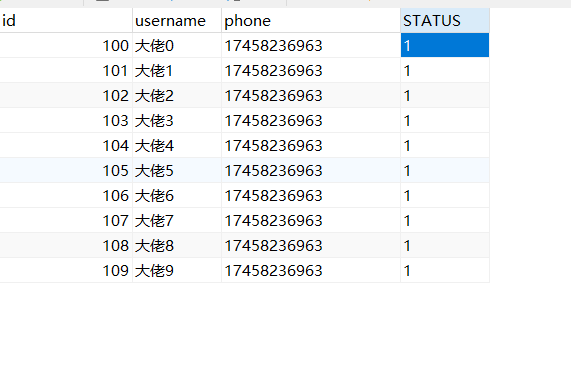
也确定了数据保存进去了,这就是垂直分库
那么什么时候垂直分库呢?答案是根据业务逻辑进行分割。比如可以把用户表和用户相关的表分配到用户数据库中,而把商品表和商品相关的数据分配到商品数据库中。

若有收获,就点个赞吧
0 人点赞
