BIO
BIO 网络模型实际上就是使用传统的 Java IO 编程,相关联的类和接口都在 java.io 下。
BIO 模型到底是个什么玩意?
BIO (blocking I/O) 同步阻塞,看这个翻译,blocking I/O,实际上就能看出来,就是阻塞,当客户端发起请求的时候,服务端就会开启一个线程,专门为这个客户端提供对应的读写操作,只要客户端发起了,这个服务端的线程就一直保持存在,就算客户端啥也不干,那也在那里开着,就是玩。
来整一个服务端和客户端来看看是什么样子的模型。
Server端:
public class TimeServer {public static void main(String[] args){ServerSocket server=null;try {server=new ServerSocket(18080);System.out.println("服务启动 端口:18080...");while (true){Socket client = server.accept();//每次接收到一个新的客户端连接,启动一个新的线程来处理new Thread(new TimeServerHandler(client)).start();}} catch (IOException e) {e.printStackTrace();}finally {try {server.close();} catch (IOException e) {e.printStackTrace();}}}}public class TimeServerHandler implements Runnable{private Socket clientProxxy;public TimeServerHandler(Socket clientProxxy) {this.clientProxxy = clientProxxy;}@Overridepublic void run() {BufferedReader reader = null;PrintWriter writer = null;try {reader = new BufferedReader(new InputStreamReader(clientProxxy.getInputStream()));writer =new PrintWriter(clientProxxy.getOutputStream()) ;while (true) {//因为一个client可以发送多次请求,这里的每一次循环,相当于接收处理一次请求String request = reader.readLine();if (!"GET CURRENT TIME".equals(request)) {writer.println("BAD_REQUEST");} else {writer.println(Calendar.getInstance().getTime().toLocaleString());}writer.flush();}} catch (Exception e) {throw new RuntimeException(e);} finally {try {writer.close();reader.close();clientProxxy.close();} catch (IOException e) {e.printStackTrace();}}}}
Client端:
public class TimeClient {public static void main(String[] args) {BufferedReader reader = null;PrintWriter writer = null;Socket client=null;try {client=new Socket("127.0.0.1",18080);writer = new PrintWriter(client.getOutputStream());reader = new BufferedReader(new InputStreamReader(client.getInputStream()));while (true){//每隔5秒发送一次请求writer.println("GET CURRENT TIME");writer.flush();String response = reader.readLine();System.out.println("Current Time:"+response);Thread.sleep(5000);}} catch (Exception e) {e.printStackTrace();} finally {try {writer.close();reader.close();client.close();} catch (IOException e) {e.printStackTrace();}}}}
执行结果如下:
服务端:
服务启动 端口:18080...
客户端:
Current Time:2021-6-16 11:37:34Current Time:2021-6-16 11:37:39Current Time:2021-6-16 11:37:44Current Time:2021-6-16 11:37:49Current Time:2021-6-16 11:37:54Current Time:2021-6-16 11:37:59Current Time:2021-6-16 11:38:04
我们使用的是 Client 发送请求指令”GET CURRENT TIME”给server端,每隔5秒钟发送一次,每次 Server 端都返回当前时间。
这就相当于是多个 Client 同时请求 Server ,每个 Client 创建一个线程来进行处理.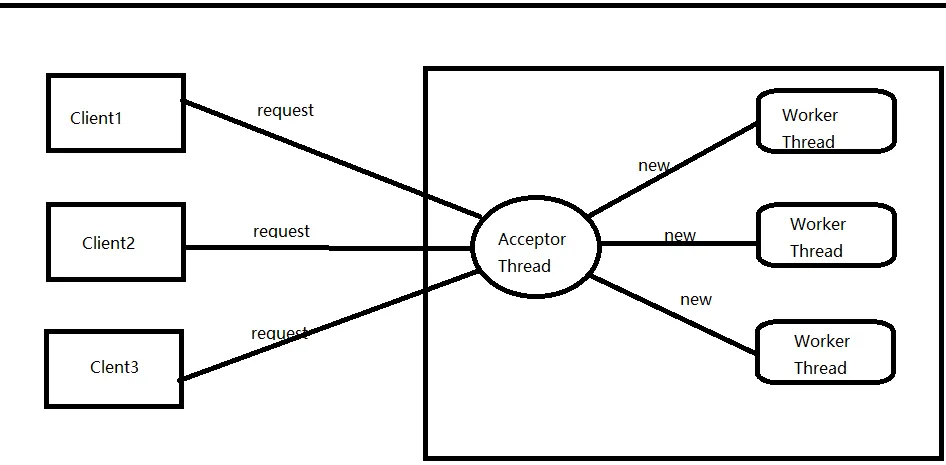
Accpetor thread 只负责与 Client 建立连接,worker thread用于处理每个thread真正要执行的操作。
在到了这里的时候,就发现了一些事情,感觉不对了有没有,
BIO 的局限性一
- 每一个 Client 建立连接后都需要创建独立的线程与 Server 进行数据的读写,业务处理。
这时候就会出现什么样子的问题,如果说有上千个客户端的时候,服务端就会创建上千个线程,有多少客户端,就创建多少个线程,这对于 Java 来说, 代价实在是太大。
如果说线程在到达一定数量的时候,在做线程的切换的时候,大家可以想象一下对资源的浪费是什么样子的,一个线程和一百个线程甚至超过一千个线程的时候,在线程进行上下文切换的时候,会出现什么样子的问题。
针对某个线程来说,这种 BIO 的模型,在这个线程读取数据的时候,如果没有数据了,那线程就开始了阻塞,为了能够做到响应数据,这个线程在一直阻塞,这时候有新的请求的时候,线程阻塞,好吧,那只能等,一直处于一个等待不能执行的状态。
BIO 的局限性二
实际上说是三个局限性,总得来说,他就是一个局限,浪费资源,开销大,这是非常致命的,一个小小的功能的话,占用的服务器大量的资源,只是硬件上这块的内容,都得增加多少的成本,现在万恶的资本家们,抱着能省就省的原则,又扯远了,还是回归到 BIO 上。
而且这种 BIO 的模型,在本质上说,实际上就相当于是一个 1:1 的关系,而这种 1:1 的关系如果在客户端非常多的时候,创建的线程数所浪费的资源是非常巨大的,所以就出现了另外一种模型,NIO 模型。而 NIO 模型实际上目前使用的那可真的是太普遍了,比如说 Netty ,都是选择使用这种模型,不再继续使用 BIO 的模型了。

若有收获,就点个赞吧
0 人点赞
