Java ThreadLocal
FastThreadLocal 算是 ThreadLocal 的进阶版,是 Netty 针对 ThreadLocal 自己造的轮子。
了解 FastThreadLocal 之后呢,对平日的一些优化可能可以提供一些思路,或者面试就能装个x。
面试官:ThreadLocal 竟然有xxx这个缺点,那怎么优化啊?
把 FastThreadLocal 的实现说一遍不就稳妥了!
所以,来看看 Netty 是如何实现 FastThreadLocal 的:
- 数数 ThreadLocal 的缺点。
- 应该如何针对 ThreadLocal 缺点改进?
- FastThreadLocal 的原理。
FastThreadLocal VS ThreadLocal 的实操。
ThreadLocal 的缺点
应该都很清楚了 ThreadLocal 的一个缺点:hash 冲突用的是线性探测法,效率低。
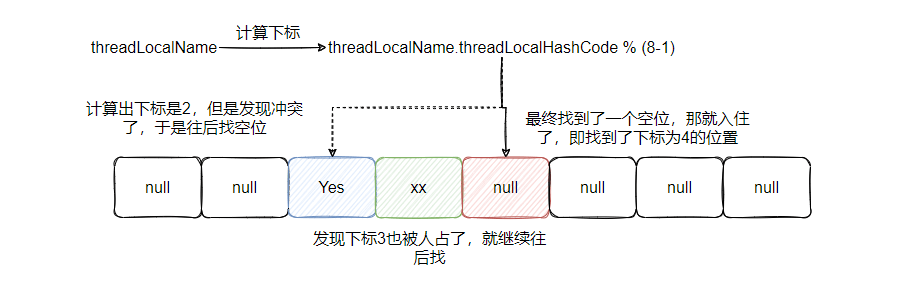
可以看到,图上显示的是经过两个遍历找到了空位,假设冲突多了,需要遍历的次数就多了。并且下次 get 的时候,hash 直接命中的位置发现不是要找的 Entry ,于是就接着遍历向后找,所以说这个效率低。
而像 HashMap 是通过链表法来解决冲突,并且为了防止链表过长遍历的开销变大,在一定条件之后又会转变成红黑树来查找,这样的解决方案在频繁冲突的条件下,肯定是优于线性探测法,所以这是一个优化方向。
不过 FastThreadLocal 不是这样优化的,下面再说。
还有一个缺点是 ThreadLocal 使用了 WeakReference 以保证资源可以被释放,但是这可能会产生一些 Etnry 的 key 为 null,即无用的 Entry 存在。
所以调用 ThreadLocal 的 get 或 set 方法时,会主动清理无用的 Entry,减轻内存泄漏的发生。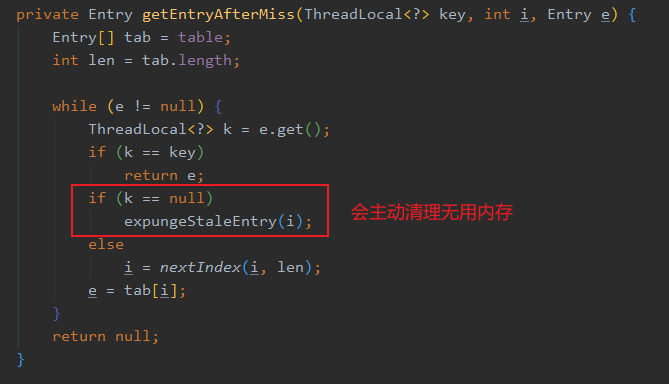
这其实等于把清理的开销弄到了 get 和 set 上,万一 get 的时候清理的无用 Entry 特别多,那这次 get 相对而言就比较慢了。
还有一个就是内存泄漏的问题了,当然这个问题只存在于用线程池使用的时候,并且上面也提到了 get 和 set 的时候也能清理一些无用的 Key,所以没有那么的夸张,只要记得用完后调用 ThreadLocal#remove 就不会有内存泄漏的问题了。
大致就这么几点。应该如何针对 ThreadLocal 缺点改进
所以怎么改呢?
前面提到 ThreadLocal hash 冲突的线性探测法不好,还有 Entry 的弱引用可能会发生内存泄漏,这些都和 ThreadLocalMap 有关,所以需要搞个新的 map 来替换 ThreadLocalMap。
而这个 ThreadLocalMap 又是 Thread 里面的一个成员变量,这么一看 Thread 也得动一动,但是又无法修改 Thread 的代码,所以配套的还得弄个新的 Thread。
所以不仅得弄个新的 ThreadLocal、ThreadLocalMap 还得弄个配套的 Thread 来用上新的 ThreadLocalMap 。
所以如果想改进 ThreadLocal ,就需要动这三个类。
对应到 Netty 的实现就是 FastThreadLocal、InternalThreadLocalMap、FastThreadLocalThread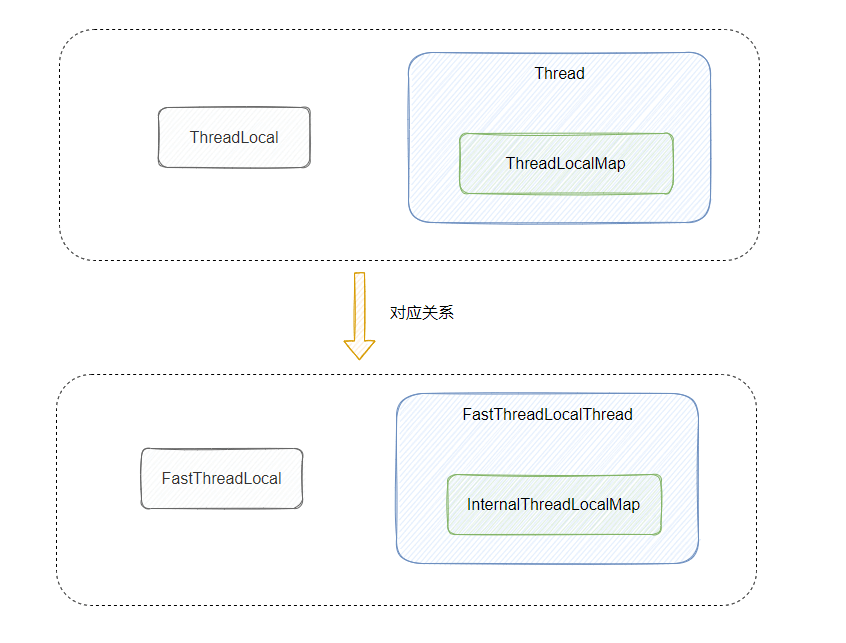
然后发散一下思维,既然 Hash 冲突的想线性探测效果不好,可能比较容易想到的就是上面提到的链表法,然后再基于链表法说个改成红黑树,这个确实是一方面,但是可以再想想。
比如,让 Hash 不冲突,所以设计一个不会冲突的 hash 算法?不存在的!
所以怎么样才不会产生冲突呢?
各自取号入座
什么意思?就是每往 InternalThreadLocalMap 中塞入一个新的 FastThreadLocal 对象,就给这个对象发个唯一的下标,然后让这个对象记住这个下标,到时候去 InternalThreadLocalMap 找 value 的时候,直接通过下标去取对应的 value 。
这样不就不会冲突了?
这就是 FastThreadLocal 给出的方案,具体下面分析。
还有个内存泄漏的问题,这个其实只要规范的使用即用完后 remove 就好了,其实也没太好的解决方案,不过 FastThreadLocal 曲线救国了一下,这个也且看下面的分析!FastThreadLocal 的原理
以下 Netty 基于 4.1 版本分析
先来看下 FastThreadLocal 的定义: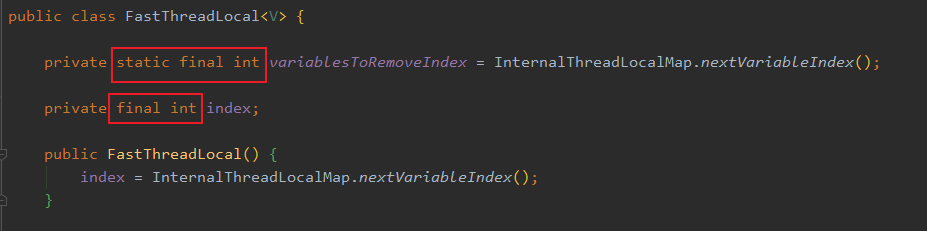
可以看到有个叫 variablesToRemoveIndex 的类成员,并且用 final 修饰的,所以等于每个 FastThreadLocal 都有个共同的不可变 int 值,值为多少等下分析。
然后看到这个 index 没,在 FastThreadLocal 构造的时候就被赋值了,且也被 final 修饰,所以也不可变,这个 index 就是上面说的给每个新 FastThreadLocal 都发个唯一的下标,这样每个 index 就都知道自己的位置了。
上面两个 index 都是通过InternalThreadLocalMap.nextVariableIndex()赋值的,盲猜一下,这个肯定是用原子类递增实现的。
来看一下实现: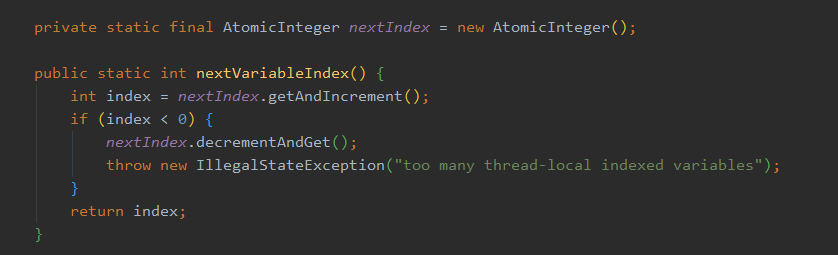
确实,在 InternalThreadLocalMap 也定义了一个静态原子类,每次调用 nextVariableIndex 就返回且递增,没有什么别的赋值操作,从这里也可以得知 variablesToRemoveIndex 的值为 0,因为它属于常量赋值,第一次调用时 nextIndex 的值为 0 。
看到这,不知道大家是否已经感觉到一丝不对劲了。好像有点浪费空间的意思,继续往下看。
InternalThreadLocalMap 对标的就是之前的 ThreadLocalMap 也就是 ThreadLocal 缺点集中的类,需要重点看下。
再来回顾一下 ThreadLocalMap 的定义。
它是个 Entry 数组,然后 Entry 里面弱引用了 ThreadLocal 作为 Key。
而 InternalThreadLocalMap 有点不太一样: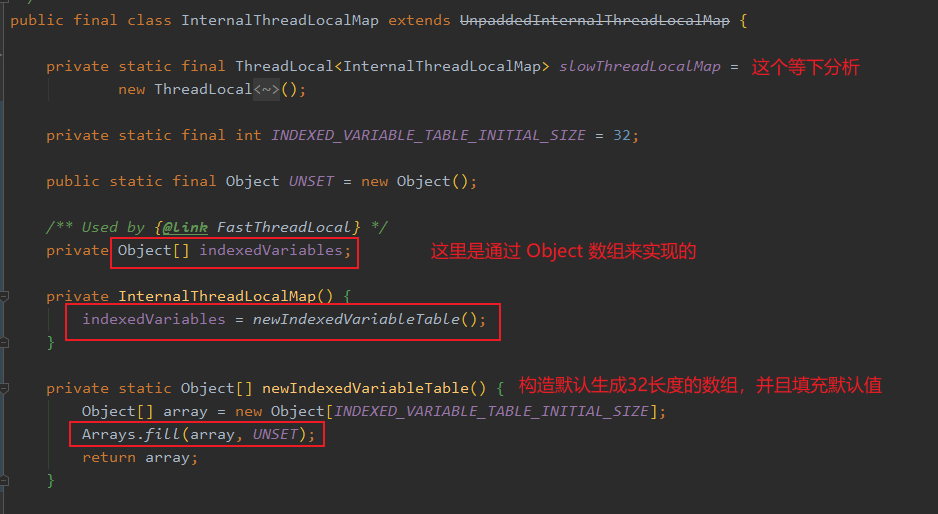
可以看到, InternalThreadLocalMap 好像放弃了 map 的形式,没用定义 key 和 value,而是一个 Object 数组?
那它是如何通过 Object 来存储 FastThreadLocal 和对应的 value 的呢?从 FastThreadLocal#set 开始分析:
因为已经熟悉 ThreadLocal 的套路,所以知道 InternalThreadLocalMap 肯定是 FastThreadLocalThread 里面的一个变量。
然后从对应的 FastThreadLocalThread 里面拿到了 map 之后,就要执行塞入操作即setKnownNotUnset。
先看一下塞入操作里面的setIndexedVariable方法: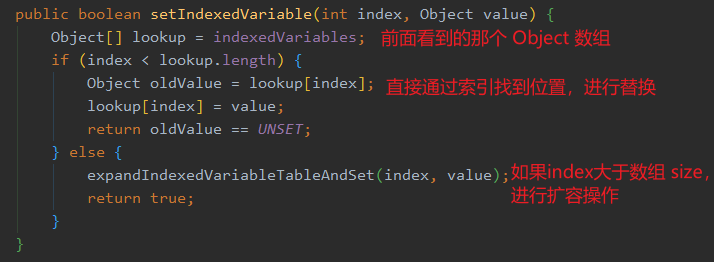
可以看到,根据传入构造 FastThreadLocal 生成的唯一 index 可以直接从 Object 数组里面找到下标并且进行替换,这样一来压根就不会产生冲突,逻辑很简单,完美。
那如果塞入的 value 不是 UNSET(默认值),则执行addToVariablesToRemove方法,这个方法又有什么用呢?
是不是看着有点奇怪?画个图来解释解释: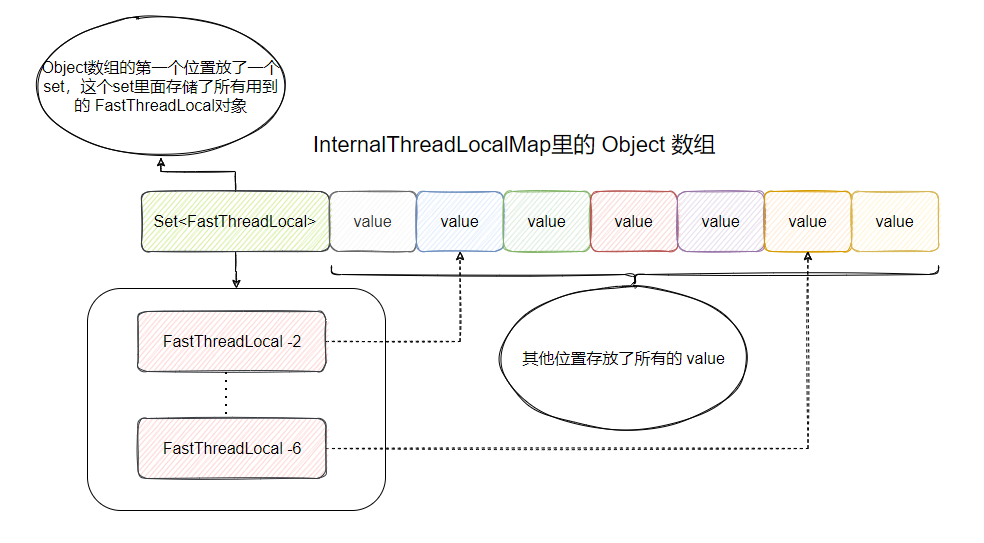
这就是 Object 数组的核心关系图了,第一个位置放了一个 set ,set 里面存储了所有使用的 FastThreadLocal 对象,然后数组后面的位置都放 value。
那为什么要放一个 set 保存所有使用的 FastThreadLocal 对象?
用于删除,假设现在要清空线程里面的所有 FastThreadLocal ,那必然得有一个地方来存放这些 FastThreadLocal 对象,这样才能找到这些家伙,然后干掉。
所以刚好就把数组的第一个位置腾出来放一个 set 来保存这些 FastThreadLocal 对象,如果要删除全部 FastThreadLocal 对象的时候,只需要遍历这个 set ,得到 FastThreadLocal 的 index 找到数组对应的 位置将 value 置空,然后把 FastThreadLocal 从 set 中移除即可。
刚好 FastThreadLocal 里面实现了这个方法,来看下: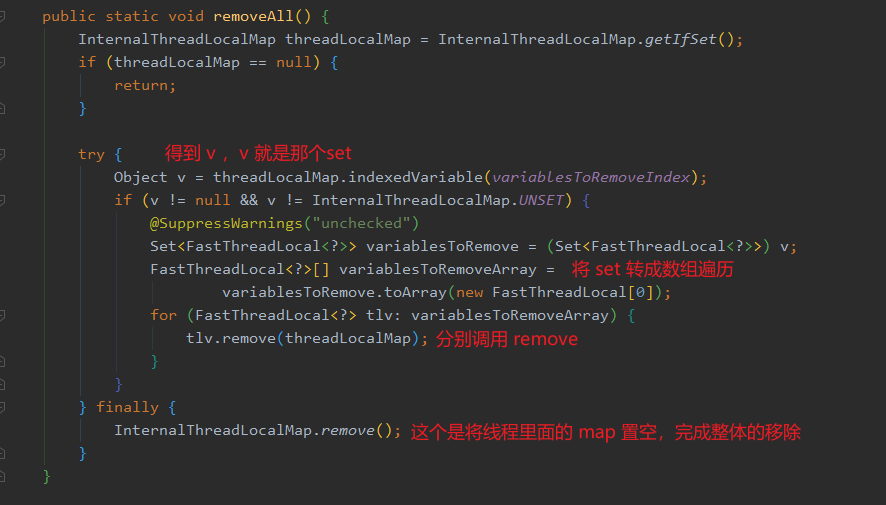
内容可能有点多了,做下小结,理一理上面说的:
首先 InternalThreadLocalMap 没有采用 ThreadLocalMap k-v形式的存储方式,而是用 Object 数组来存储 FastThreadLocal 对象和其 value,具体是在第一个位置存放了一个包含所使用的 FastThreadLocal 对象的 set,然后后面存储所有的 value。
之所以需要个 set 是为了存储所有使用的 FastThreadLocal 对象,这样就能找到这些对象,便于后面的删除工作。
之所以数组其他位置可以直接存储 value ,是因为每个 FastThreadLocal 构造的时候已经被分配了一个唯一的下标,这个下标对应的就是 value 所处的下标。
看到这里,不知道大家是否有感受到空间的浪费?
举个例子。
假设系统里面一个 new 了 100 个 FastThreadLocal ,那第 100 个 FastThreadLocal 的下标就是 100 ,这个应该没有疑义。
从上面的 set 方法可以得知,只有调用 set 的时候,才会从当前线程中拿出 InternalThreadLocalMap ,然后往这个 map 的数组里面塞入 value,这里再回顾一下 set 的方法。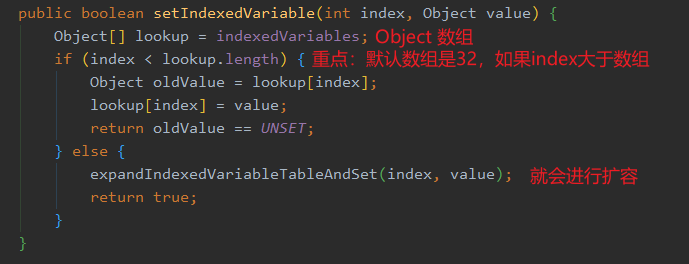
那这里是什么意思呢?
如果这个线程之前都没塞过 FastThreadLocal ,此时要塞入第一个 FastThreadLocal ,构造出来的数组长度是32,但是这个 FastThreadLocal 的下标已经涨到了 100 了,所以这个线程第一次塞值,也仅仅只有这么一个值,数组就需要扩容。
看到没,这就是所说的浪费,空间被浪费了。
Netty 相关实现者知道这样会浪费空间,所以数组的扩容是基于 index 而不是原先数组的大小,如果是基于原先数组的扩容,那么第一次扩容 2 倍,32 变成 64,还是塞不下下标 100 的数据,所以还得扩容一次,这就不美了。
所以可以看到扩容传进去的参数是 index 。
可以看到,直接基于 index 的向上 2 次幂取整。然后就是扩容的拷贝,这里是直接进行数组拷贝,不需要进行 rehash,而 ThreadLocalMap 的扩容需要进行rehash,也就是重新基于 key 的 hash 值进行位置的分配,所以这个也是 FastThreadLocal 优于ThreadLocal 的一个点。
对了,上面那个向上 2 次幂取整的操作这个和 HashMap 的实现是一致的。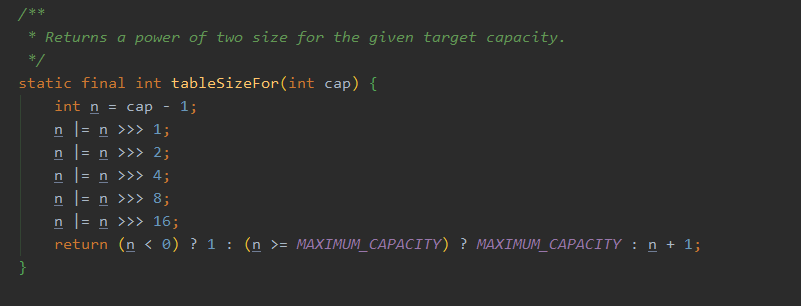
所以从上面的实现可以得知 Netty 就是特意这样设计的,用多余的空间去换取不会冲突的 set 和 get ,这样写入和获取的速度就更快了,这就是典型的空间换时间。
好了,想必此时已经弄懂了 FastThreadLocal 的核心原理了,再来看看 get 方法的实现,应该能脑补这个实现了。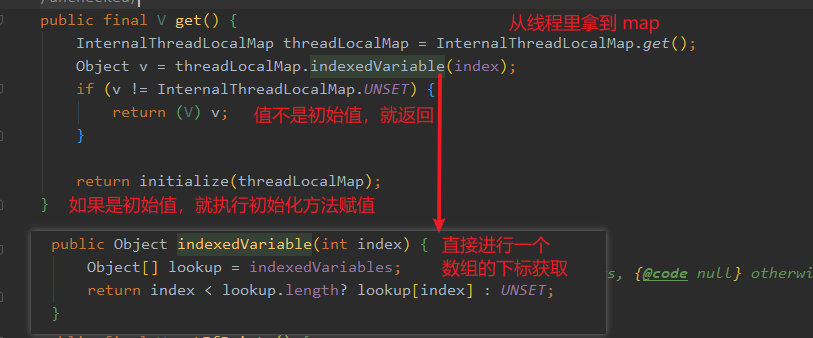
index 就是 FastThreadLocal 构造时候预先分配好的那个下标,然后直接进行一个数组下标查找,如果没找到就调用 init 方法进行初始化。
这里再继续探究一下InternalThreadLocalMap.get(),这里面做了一个兼容。不过要先介绍一下 FastThreadLocalThread ,就是这玩意替代了 Thread。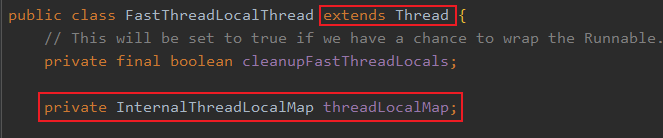
可以看到它继承了 Thread ,并且弄了一个成员变量就是前面说的 InternalThreadLocalMap。
然后再来看一下 get 方法,不过逻辑很简单。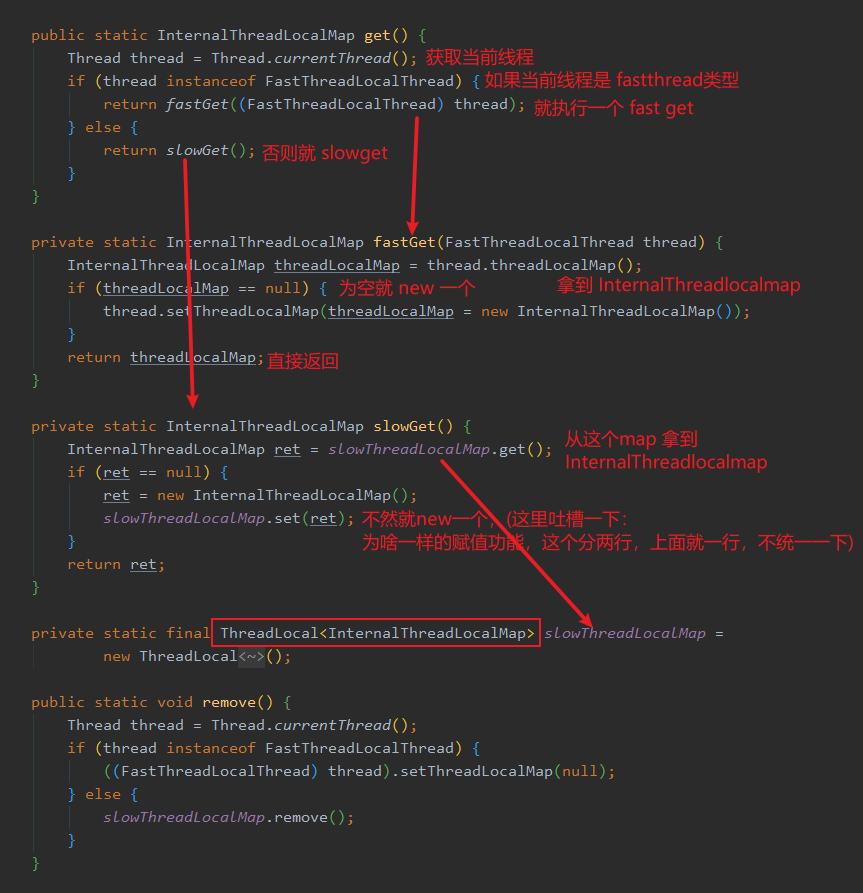
这里之所以分了 fastGet 和 slowGet 是为了做一个兼容,假设有个不熟悉的人,他用了 FastThreadLocal 但是没有配套使用 FastThreadLocalThread ,然后调用 FastThreadLocal#get 的时候去 Thread 里面找 InternalThreadLocalMap 那不就傻了吗,会报错的。
所以就再弄了个 slowThreadLocalMap ,它是个 ThreadLocal ,里面保存 InternalThreadLocalMap 来兼容一下这个情况。
从这里也能得知,FastThreadLocal 最好和 FastThreadLocalThread 配套使用,不然就隔了一层了。FastThreadLocal<String> threadLocal = new FastThreadLocal<String>();Thread t = new FastThreadLocalThread(new Runnable() { //记得要 new FastThreadLocalThreadpublic void run() {threadLocal.get();....}});
好了,get 和 set 这两个核心操作都分析完了,最后再来看一下 remove 操作吧。
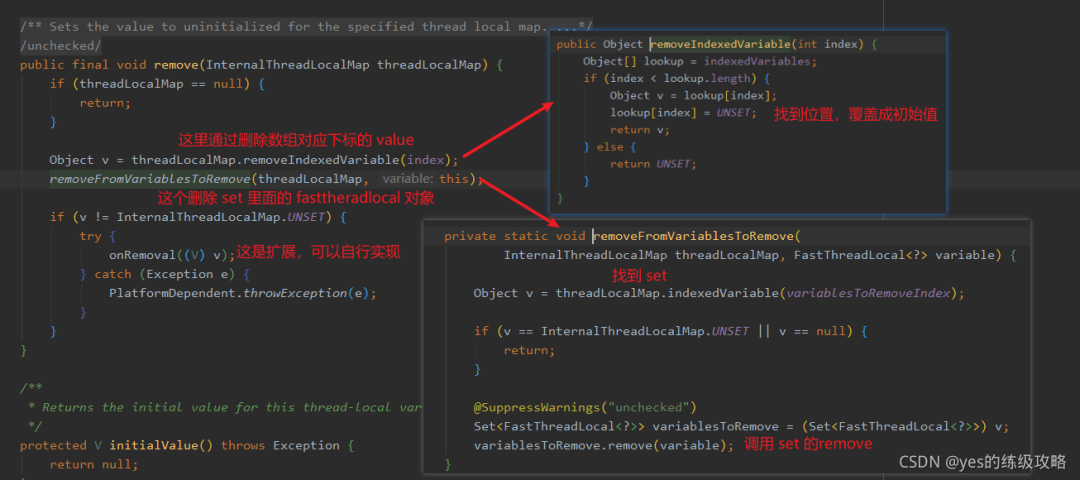
很简单对吧,把数组里的 value 给覆盖了,然后再到 set 里把对应的 FastThreadLocal 对象给删了。
不过看到这里,可能有人会发出疑惑,内存泄漏相关的点呢?
其实吧,可以看到 FastThreadLocal 就没用弱引用,所以它把无用 FastThreadLocal 的清理就寄托到规范使用上,即没用了就主动调用 remove 方法。
但是它曲线救国了一下,来看一下 FastThreadLocalRunnable 这个类: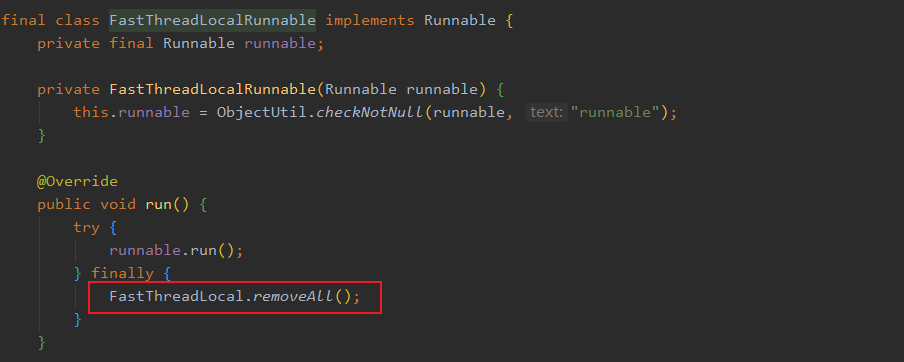
已经把重点画出来了,可以看到这个 Runnable 执行完毕之后,会主动调用FastThreadLocal.removeAll()来清理所有的 FastThreadLocal,这就是说的曲线救国。
当然,这个前提是不能用 Runnable 而是用 FastThreadLocalRunnable。不过这里 Netty 也是做了封装的。
Netty 实现了一个 DefaultThreadFactory 工厂类来创建线程。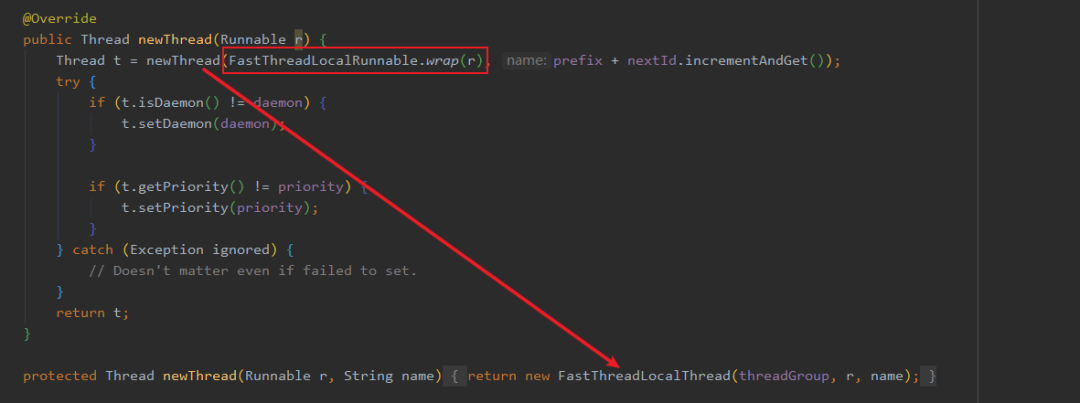
传入 Runnable 是吧,没事,把它包成 FastThreadLocalRunnable,并且 new 回去的线程是 FastThreadLocalThread 类型,这样就能在很大程度上避免使用的错误,也减少了使用的难度。
这也是工厂方法这个设计模式的好处之一啦。所以工程上如果怕对方没用对,就封装了再给别人使用,这样也屏蔽了一些细节。
所以说多看看开源框架的源码,有很多可以学习的地方!好了,FastThreadLocal 原理大致就说到这里。FastThreadLocal VS ThreadLocal
到此,已经充分了解了两者之间的不同,但是 Fast 到底有多 Fast 呢?
用实验说话,Netty 源码里面已经有 benchmark 了,直接跑就行了
里面有两个实验:
FastPath 对应的是使用 FastThreadLocalThread 线程对象。
SlowPath 对应的是使用 Thread 线程对象。
两个实验都是分别定义了 ThreadLocal 和 FastThreadLocal :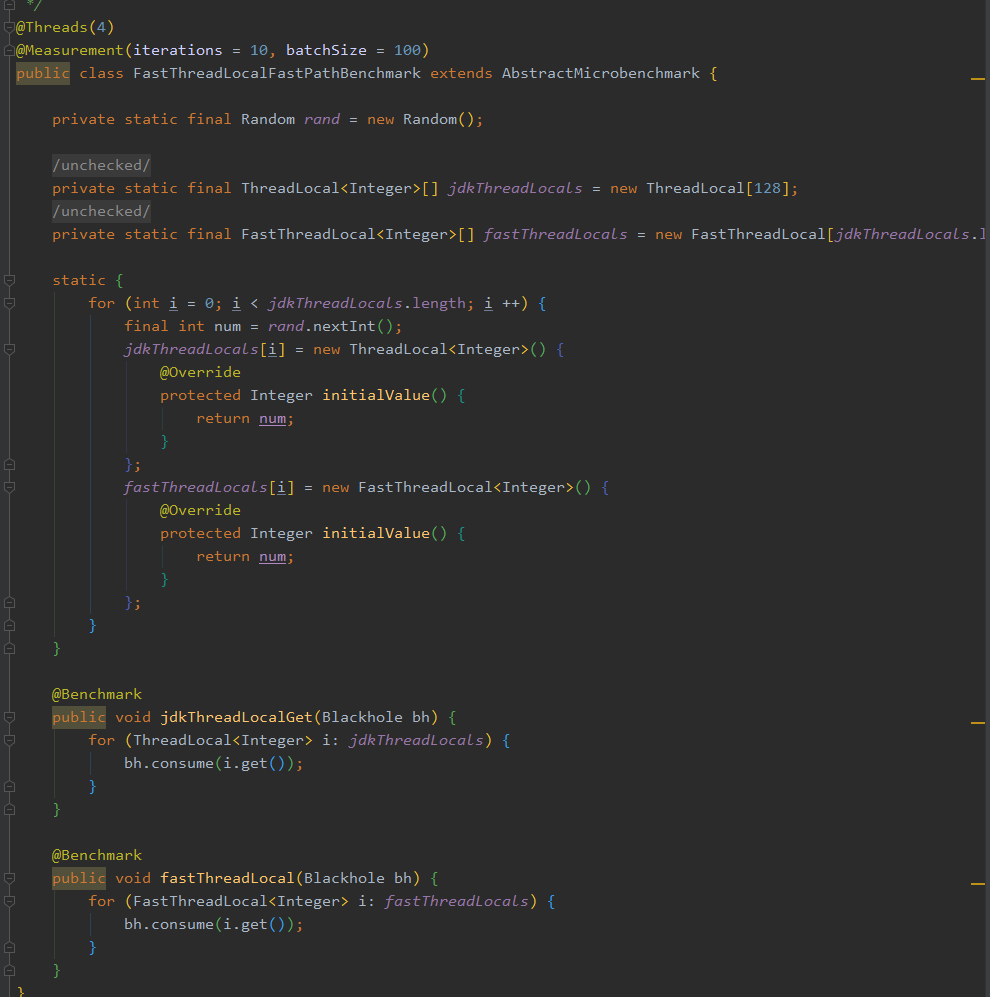
来看一下执行的结果:
FastPath:
SlowPath:
可以看到搭配 FastThreadLocalThread 来使用 FastThreadLocal 吞吐确实比使用 ThreadLocal 大,但是好像也没大太多?
不过,在网上有看别比人的 benchmark 对比,同样的代码,他的结果是大了三倍。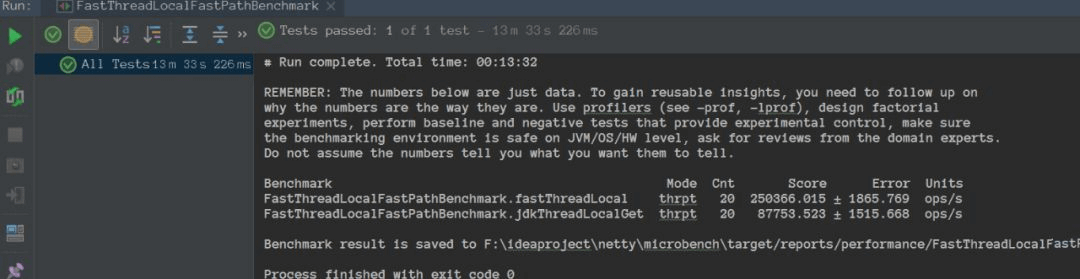
又跑了几遍,每次都比原生的 ThreadLocal 吞吐好,但是也没好那么多…有点奇怪。
至于 FastThreadLocal 搭配 Thread 则吞吐比 ThreadLocal 都少,说明 FastThreadLocal 的使用必须得搭配 FastThreadLocalThread ,不然就是反向优化了。
代码在 netty 的 microbench 这个项目里,有兴趣的可以自己 down 下来跑一跑看看。最后
再来总结一下:
FastThreadLocal 通过分配下标直接定位 value ,不会有 hash 冲突,效率较高。
- FastThreadLocal 采用空间换时间的方式来提高效率。
- FastThreadLocal 需要配套 FastThreadLocalThread 使用,不然还不如原生 ThreadLocal。
- FastThreadLocal 使用最好配套 FastThreadLocalRunnable,这样执行完任务后会主动调用 removeAll 来移除所有 FastThreadLocal ,防止内存泄漏。
- FastThreadLocal 的使用也是推荐用完之后,主动调用 remove。
这就是 Netty 实现的加强版 ThreadLocal,如果看过 Netty 源码,会发现内部是有挺多使用 ThreadLocal 的场景,所以这个优化还是有必要的。
并且 Netty work 线程池默认线程数是两倍 CPU 核心数,所以线程不会太多,那么空间的浪费其实也不会很多,所以这波空间换时间影响不大。
在 InternalThreadLocalMap 这个类里面发现了一些奇怪的 long 变量。
这是为了填充 Cache Line,避免伪共享问题的产生。

若有收获,就点个赞吧
0 人点赞
