引子
1960年,美国麻省理工学院研发了一个叫做Lisp的语言,这个语言今天已经很少使用,但是不是说这个语言已经死了(现在在人工智能领域仍然大量使用),一门技术如同一位伟人,伟人的逝世并不意味着伟人的离开,因为伟人的精神与世长存;
Lisp对于今天编程技术的发展有着不可替代的作用,如果没有Lisp,数据结构、元数据、并行处理甚至是人工智能都不会出现,今天所熟知的一切关于高级语言的特性以及常用的技术几乎都起源于Lisp,从另一种意义上来讲,Lisp并没有消失,反而化作计算机这个庞大世界的灵魂继续造福世人;
GC(垃圾回收机制)也是从Lisp语言开创的,因为Lisp是一门高度依赖动态内存内配的语言,学操作系统的时候就知道,内存分配有静态分配和动态分配两种,后者的效率更高所以普遍用的后者,Lisp中几乎所有的数据都是以“表”的形式出现的,而“表”所占用的空间都是在堆中动态分配的得到的,为了解决堆中灭每一个内存块的自动释放问题,Lisp的创始人研发了垃圾回收机制,如同其他影响深远的技术一样,GC技术也是从Lisp一脉相承过来的;
垃圾回收算法发展历程
GC当中最核心的部分莫过于垃圾回收算法(怎么回收)和垃圾收集器(用什么回收),通过了解今天所熟知的各种垃圾收集算法和垃圾收集器的发展历程来理清GC技术的框架,了解技术的发展史可以更好的了解一个技术的原理;
这一部分其实是把判断是否为垃圾的算法与垃圾回收算法放在了一起,因为判断垃圾是垃圾收集的先决条件;
下图是垃圾判断与垃圾回收算法的发展脉络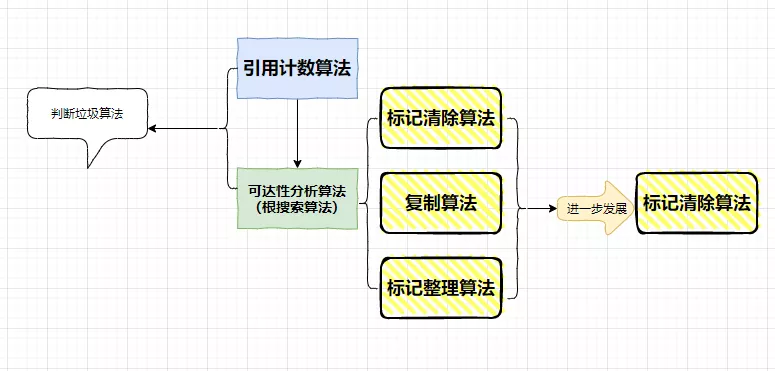
垃圾判断算法
引用计数算法
1960年之前的两年,大约在1958年的时候,Lisp的两位创始人,MarvinLee Minsky(明斯基)和John McCarthy(麦卡锡)首先构思引用计数算法,尽管后来他们自己就pass掉这个算法,但是正是这个死了的算法为以后的算法的出现提供了借鉴,此后的算法都是在引用计数的基础之上发展的;
引用计数法的官方解释是:给对象添加一个引用计数器,每当有一个地方引用它时,计数器的值就会加1,当引用时效时,计数器的值就会减1,任何时刻计数器都为0的对象不会再被使用;
一图胜千言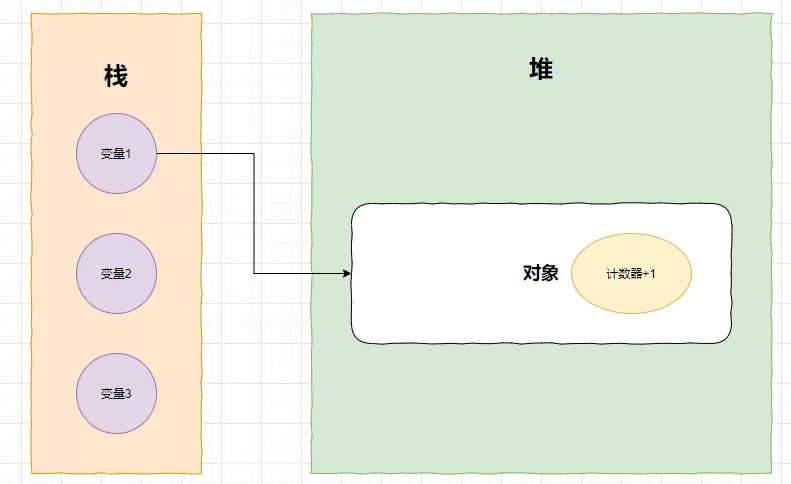
如果有一个变量指向了堆里的对象,计时器就会加1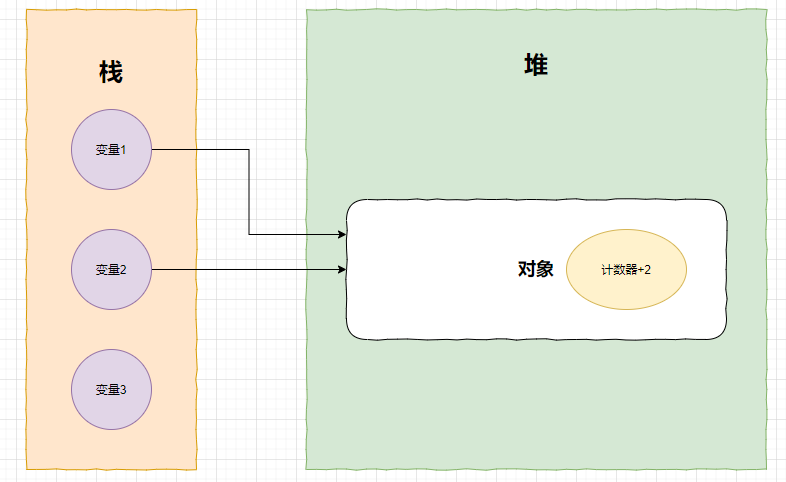
如果再有一个变量指向了堆里的对象,计数器就会加2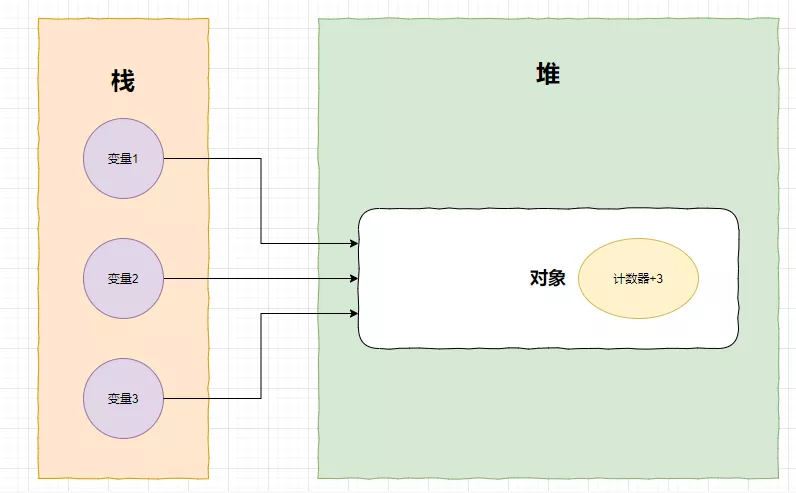
如果再来一个变量指向堆里的对象,计数器的直接就会加3
引用计数法非常简单,效率也高,为什么还会没等应用就淘汰了呢?致命缺陷在于:几乎无法解决对象之间相互循环引用的问题!
假如,栈里面有两个变量,堆里面有两个对象,这两个对象分别有一个示例成员变量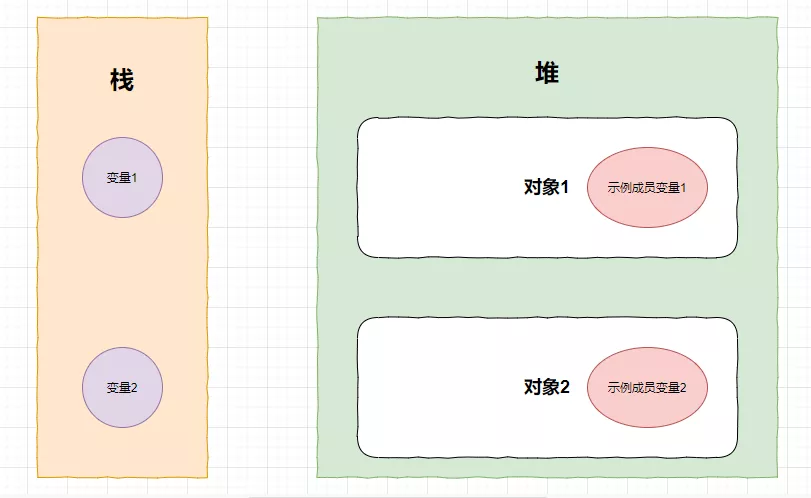
现在,对象1和对象2相互引用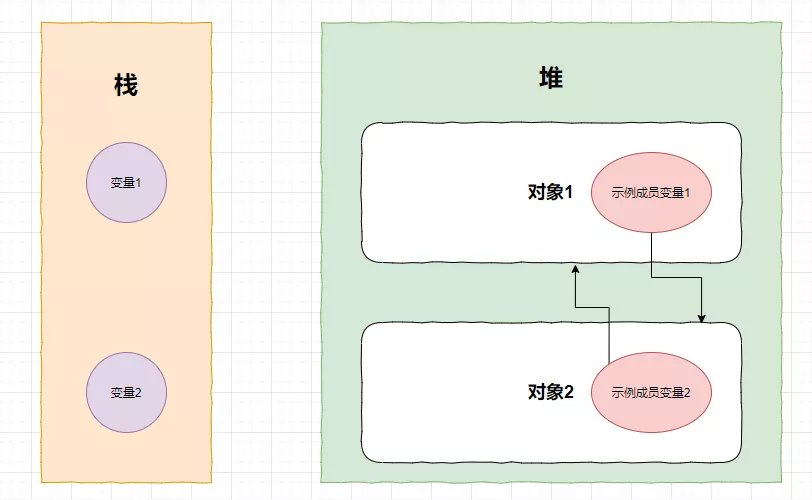
注意,这时候栈里面没有一个变量指向堆里面的任何一个对象!
语言都是相通的,还是用java来解释这一切,JVM中最常打交道的就是栈和堆了,一般栈里面放的是对象名,实际的对象都放在堆中;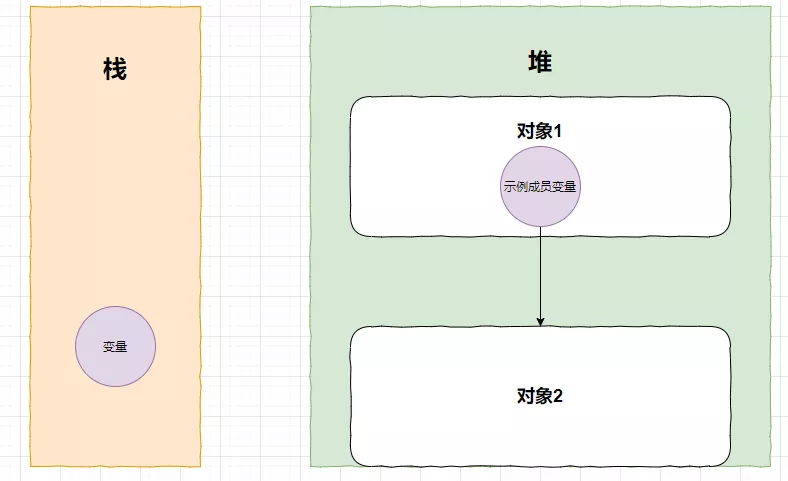
显然,栈中的变量不指向堆中的任何一个对象,所以那两个对象都是垃圾!
如果这时候做个修改,让变量指向对象1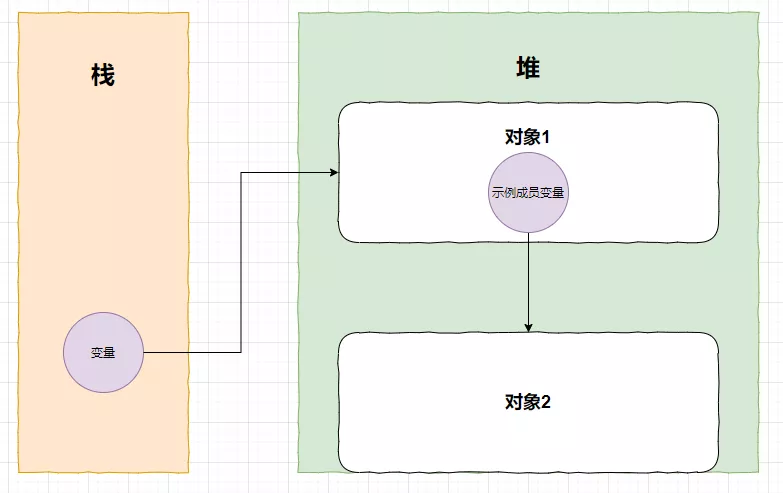
这时候,对象就不是垃圾对象了
回到之前的例子,把相应的图再复制过来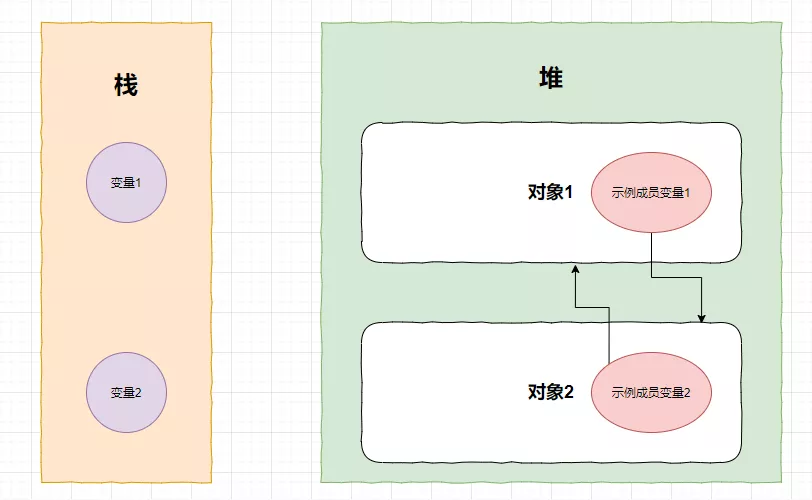
既然没有变量指向,那么这些对象就是垃圾,在引用计数法看来,对象1和对象2分别引用了一次,但是这些都应该进垃圾桶给回收掉,所以引用计数法的缺陷注定不能大展身手;
可达性分析算法
官方解释是:通过一系列的称为“GC roots”的对象作为起始点,从这些节点开始向下搜索,搜索过的路径称为“引用链”,当一个对象到一个GC Roots却没有任何引用链相连,也就是说从GC Roots到这个对象不可达,说明此对象不可用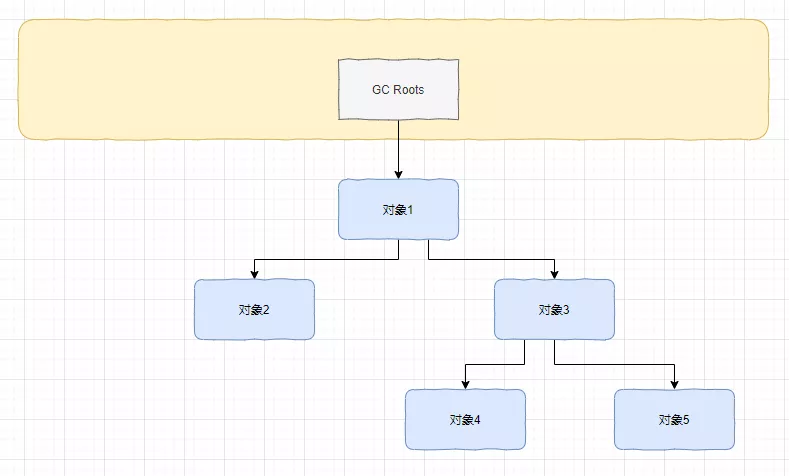
GCRoots往下搜索,能够搜索到的,无论是直接的还是间接的,全部视为可达,相反,GC Roots够不到的,则全部视为不可达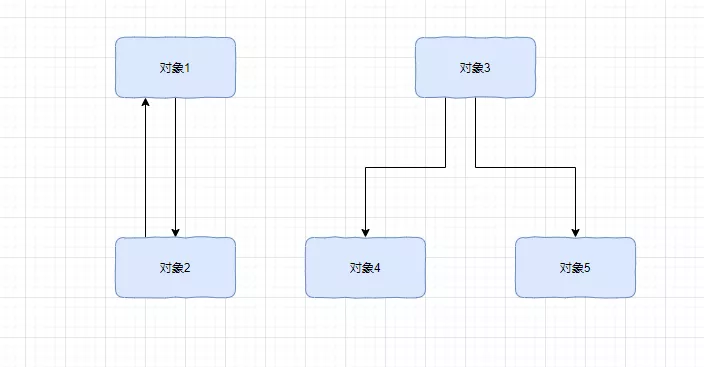
这些对象,自己玩自己的,全部都是垃圾对象
垃圾回收算法
在解决什么是垃圾和怎么找到垃圾的问题之后,准备工作算是做完了,就相当于,警察已经确定了小偷的所有的外貌特征以及行踪之后,就要部署抓捕行动了,这这个抓捕小偷的方式,就是java的垃圾回收算法;
软件的世界里处处都是算法,其实算法这个名字挺高大上,但其实就是软件问题的解决方案而已;
标记清除算法
这是第一种垃圾回收算法,也是Lisp所采用的算法,官方解释是:先标记再清除,标记就是标记出所有需要回收的对象,然后清除掉所有被标记的对象,下面用两个表格来直观的呈现一下
标记清除算法最大的贡献在于“分步”执行,在“标记”阶段记录每一个指针变量的走向,用类似思路设计的垃圾收集器叫做“跟踪收集器”这个算法最明显的缺点就是碎片太多太分散,清理完成之后不能把分散的碎片整合在一起,非常影响内存的利用率;
复制算法
很快,到了1963年,明斯基发表的论文A LISP Garbage Collector Algorithm Using Serial SecondaryStorage 中描述了后人称为复制算法的思路:把可用内存按照容量分成大小相等的两块,每一次只是用其中的一块,当这一块的内存使用完成之后,就将存活对象复制到另一块可用内存,然后把已使用的内存空间一次性全部清除,用另外一个表格来呈现下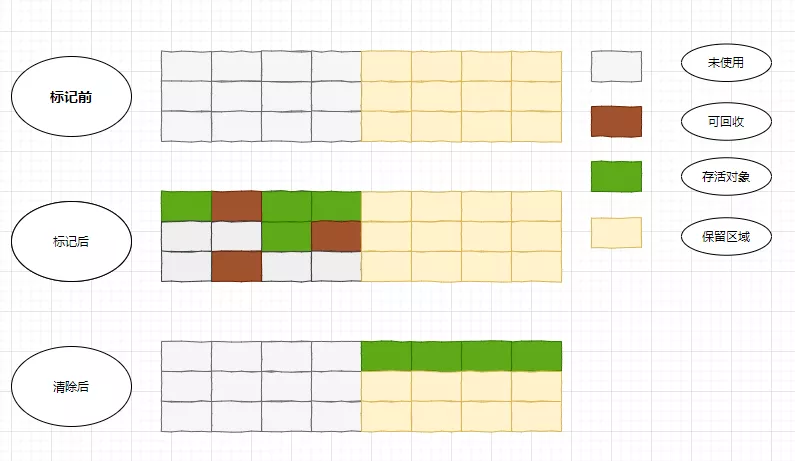
复制算法好很好的解决了碎片的问题,不过缺点就是有点浪费空间,不过在计算机硬件更新换代快的背景下这个缺点很大程度上可以很好的避免,复制算法应用的时间就比较长了,一直持续到上个世纪七十年代;
标记整理算法
随着人们对空间复杂度的要求的提高,也就是尽量用更少的内存,实现更有效率的垃圾回收,人们在上个世纪七十年达一直到八十年代提出过很多的算法,其中 G. L. Steele , C. J. Cheney 和 D. S. Wise 等研究者提出的标记整理算法日趋成熟并开始广泛应用;
标记整理算法是在复制算法上的升级,主要区别在于并不直接对可回收对象进行清理,而是让存活的对象都向一端移动,然后直接清理掉端边界以外的内存;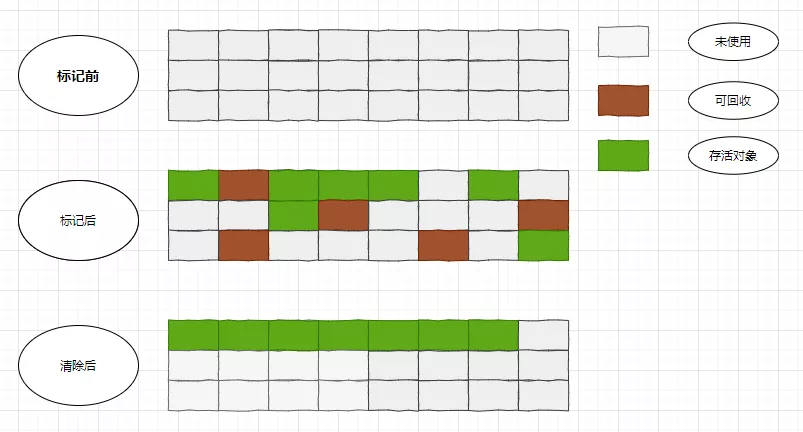
分代收集算法
经过二十多年的发展,垃圾回收技术日益成熟,并且不断有新的思路出现,虽然不部分都是在原有的基础上修修补补,比如增量收集算法,其实就是把标记清除和复制算法的结合;
1983年, H. Lieberman 和 C. Hewitt 在论文 A real-time garbage collector based onthe lifetimes of objects中提出了分代收集的算法,这也是今天几乎所有的虚拟机都采用的算法,分代(年轻代或新生代、老年代)作为垃圾分类的基本思想就是在这个时候奠定的;
分代收集的最大好处就在于,可以根据每个阶段的特点进行“私人订制”,比如新生代中每回都有大量的对象死去,存活率很低,那么就采用“复制算法”,而老年代因为对象的存活率高,就采用“标记清除算法”或者是“标记整理算法”;
可以说,分代收集算法不仅仅是对之前垃圾回收算法进行了一次大综合,更像是搭建了一个以“分代”为指导思想的全新的框架,把各个成熟的垃圾回收技术很好的运用到各个场景中,从而实现每种算法的最有利用,实现“1+1>2”的效果;
关于新生代和老年代
这是JVM的简略构成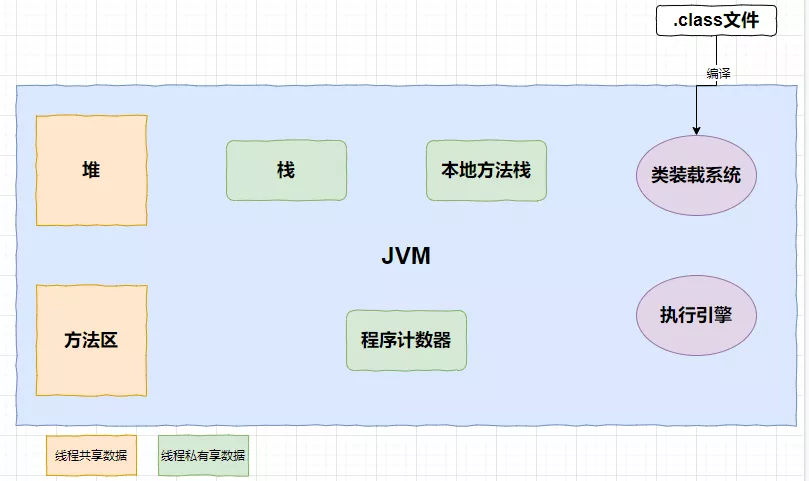
年轻代和老年代是指的堆内存里面的构成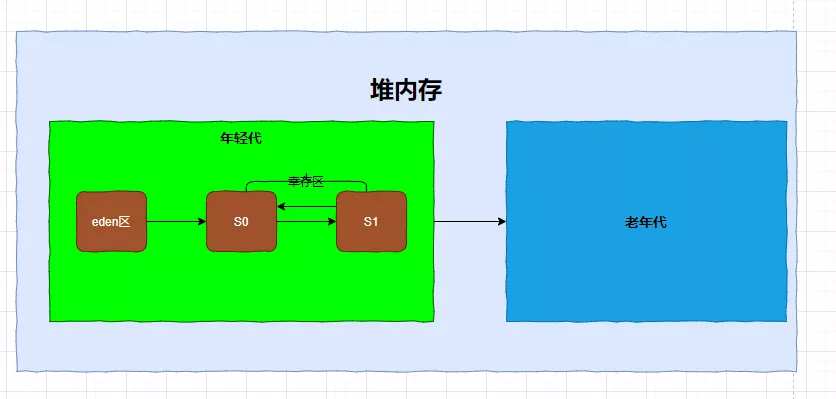
一般情况下,年轻代占堆内存的三分之一,老年代占堆内存的三分之二,年轻代中的eden区占年轻代的80%,剩下的占20%;
新建的对象都会先放到eden区,用可达性分析算法来判断是否为垃圾,如果是,就先移动到S0.在移动到S1,同时计数器分别加1,加到一定的是数值就会移动到老年代,具体干这个工作的是执行引擎,执行引擎通过GC垃圾收集线程来工作;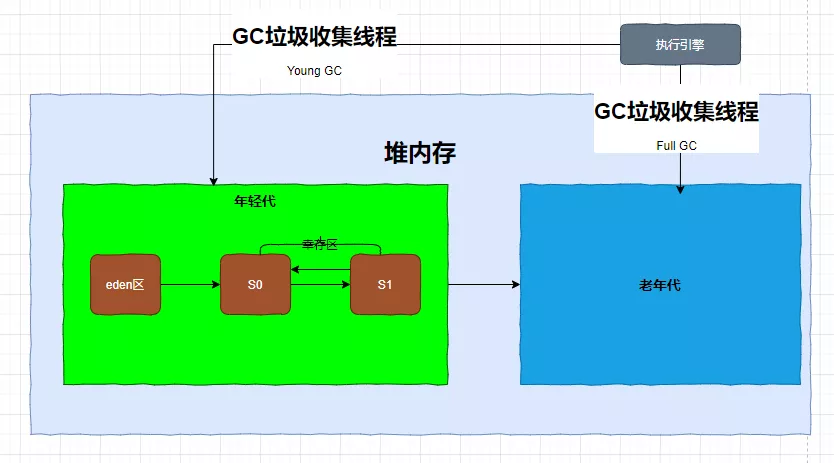
注意,Full GC既可以收集老年代也可以收集年轻代;
垃圾收集器发展历程
发布于1999年的Serial收集器是世界上第一个垃圾收集器,ParNew收集器是Serial收集器的并行版本,或者叫做多线程版本,三年后,2002年,发布Parallel收集器,最后一个出现是CMS收集器;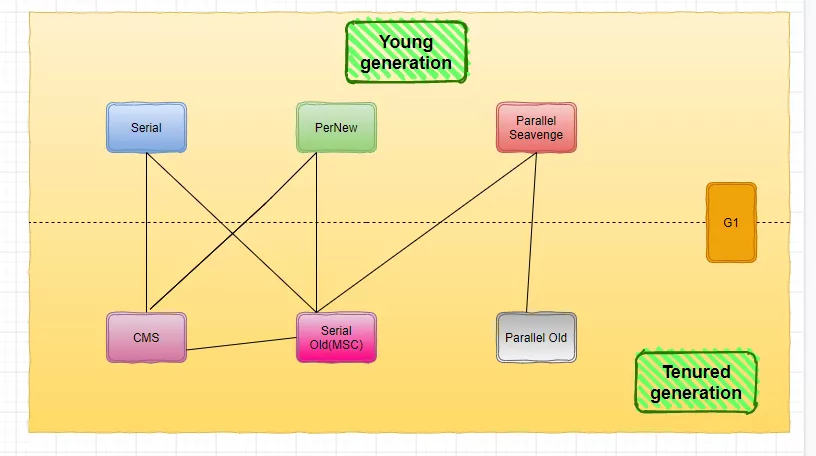
第一个:Serial收集器
这是个单线程的垃圾收集器,也就是说它只会用一个CPU或者是一个线程来完成垃圾收集的工作;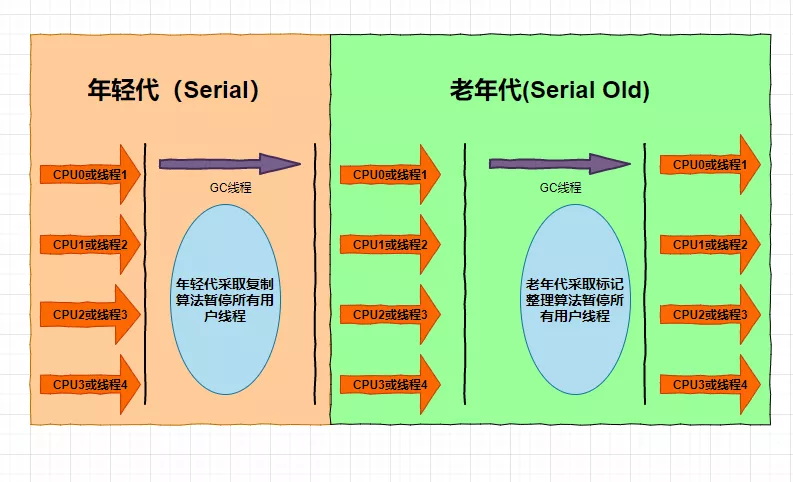
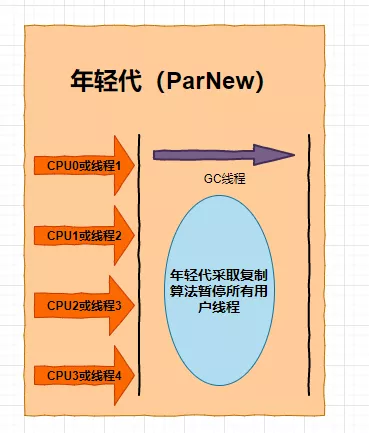
第二个:ParNew收集器
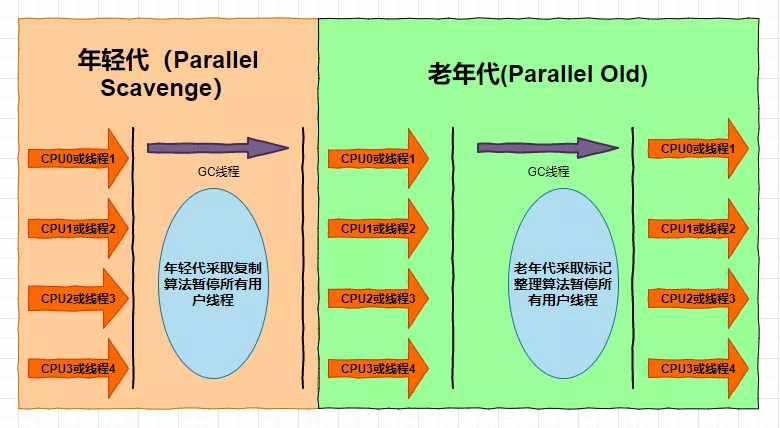
第三个:Parallel收集器
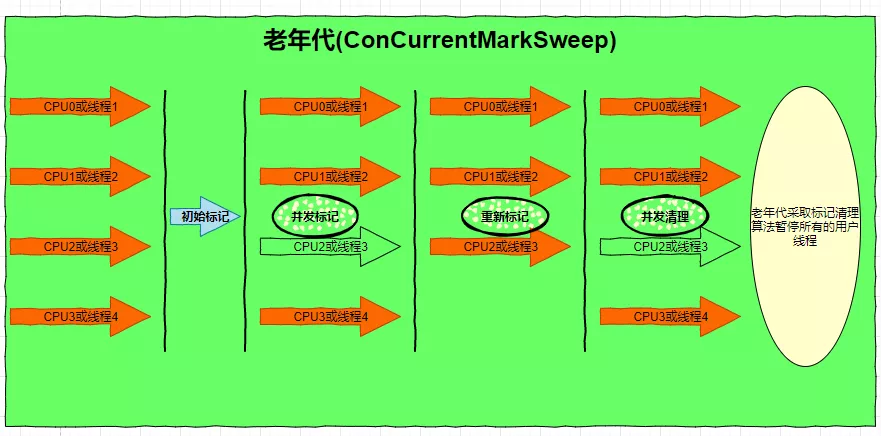
第四种:CMS收集器

总结
这就是GC当中比较关键的垃圾回收算法和垃圾收集器的主要发展历程,每一步都是一代又一代的计算机科学家智慧的结晶,正式他们的天才和努力,才让这个世界变得更好,Lisp的两位创始人同时人工智能的开创者,今天,大规模应用于人工智能领域不只有Python,还有不为大众所熟知的Lisp!

若有收获,就点个赞吧
0 人点赞
