参考: 认识与学习 BASH
1 shell
1.1 定义
我们必须要透过『 Shell 』将我们输入的命令与 Kernel 沟通,好让 Kernel 可以控制硬件来正确无误的工作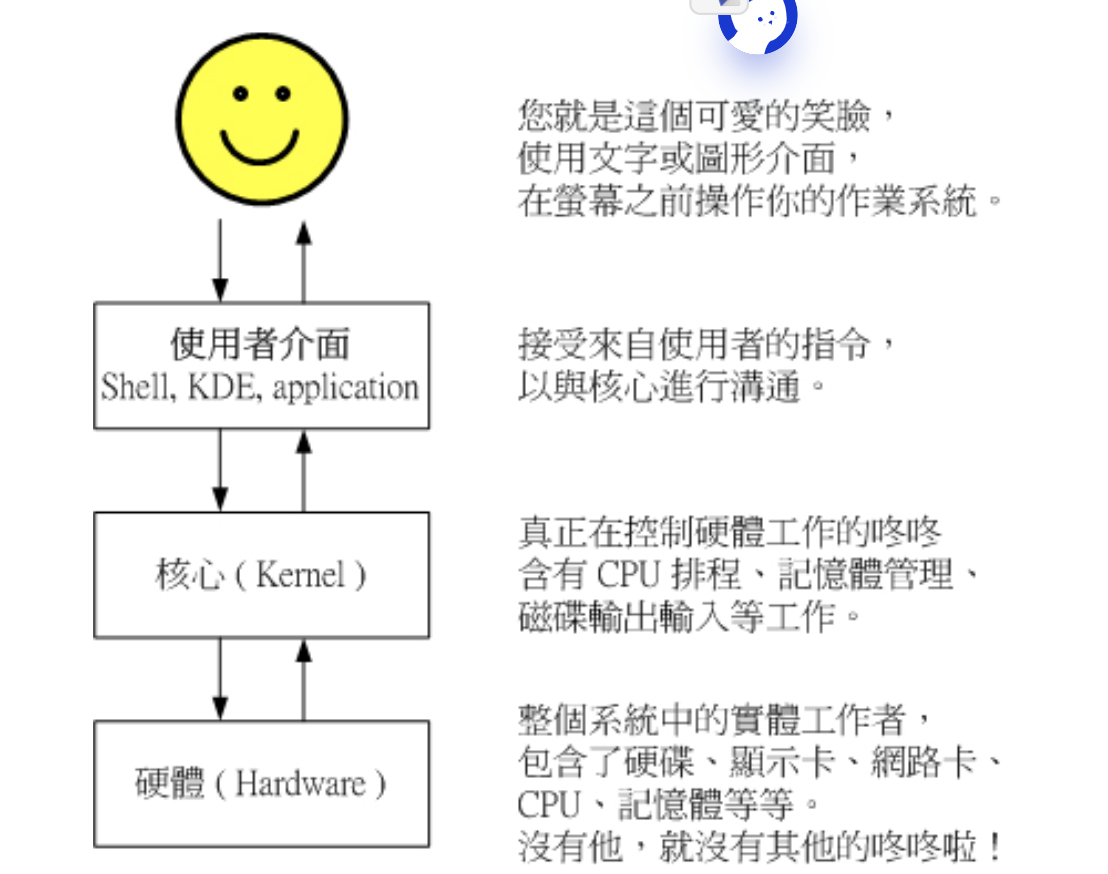
1.2 不同的shell
我们的 Linux (以 CentOS 5.x 为例) 有多少我们可以使用的 shells 呢? 你可以检查一下 /etc/shells 这个文件,至少就有底下这几个可以用的 shells:
mac系统
2 变量
2.1 默认环境变量
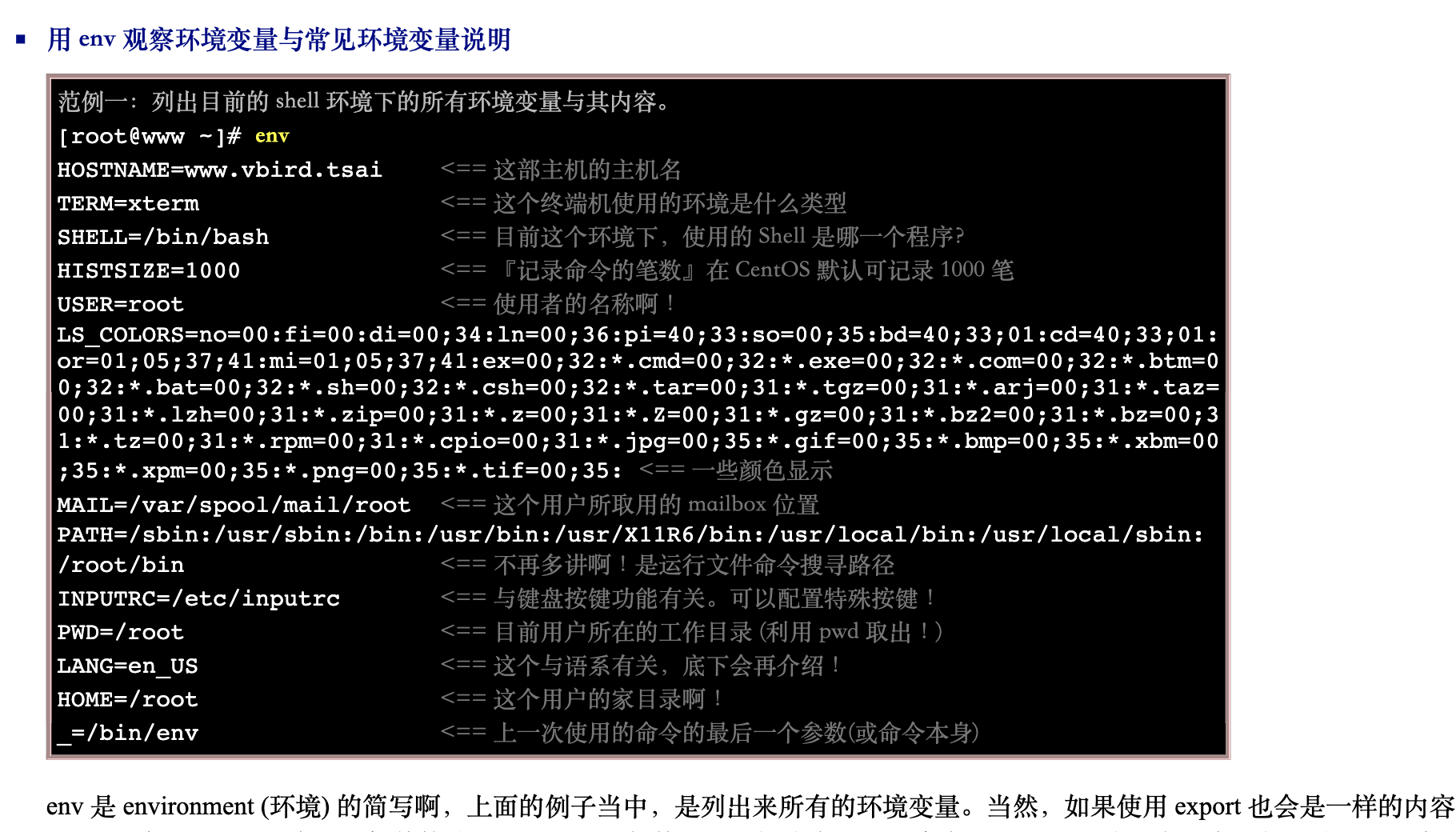
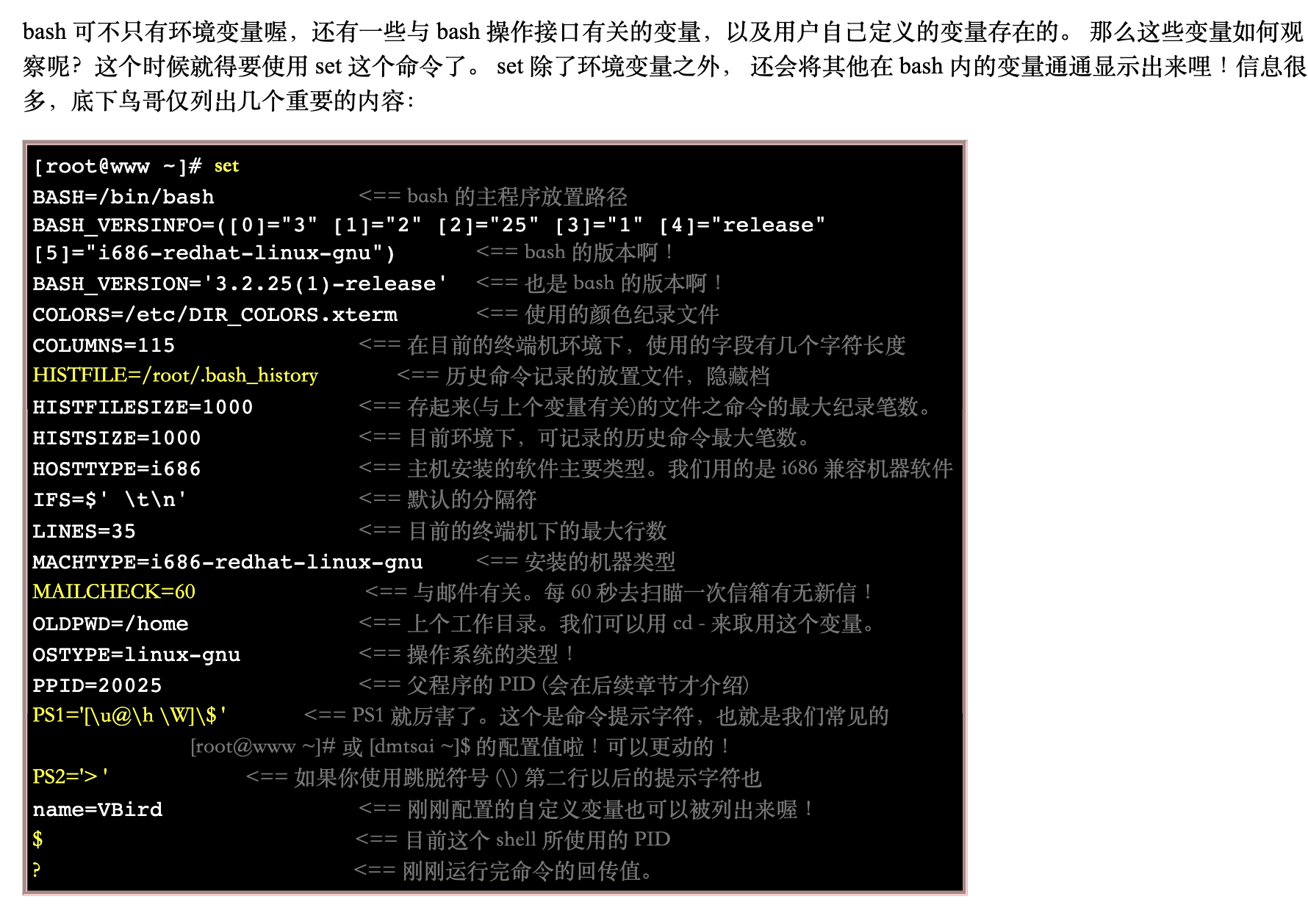
2.2 观察所有变量 (含环境变量与自定义变量)
3 数据流重导向 (Redirection)
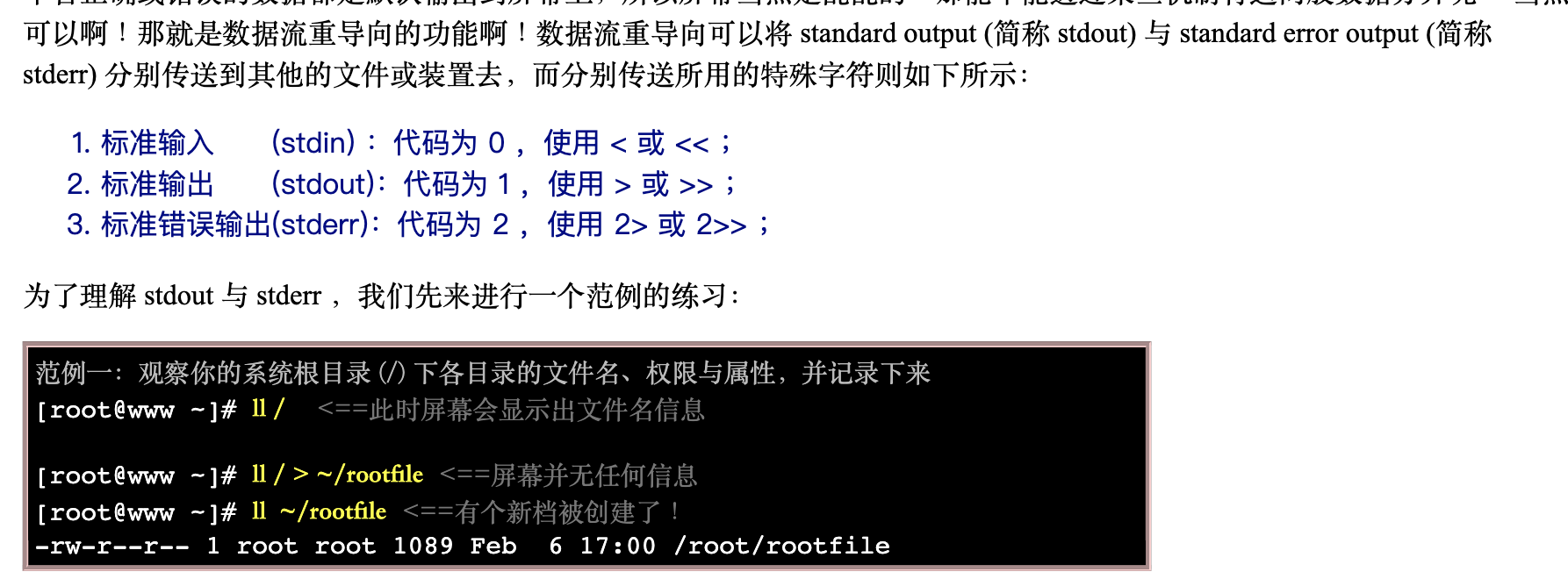
数据流重导向就是将某个命令运行后应该要出现在屏幕上的数据, 给他传输到其他的地方,例如文件或者是装置 (例如打印机之类的)!这玩意儿在 Linux 的文本模式底下可重要的! 尤其是如果我们想要将某些数据储存下来时,就更有用了!
3.1 standard output 与 standard error output
标准输出指的是『命令运行所回传的正确的信息』,而标准错误输出可理解为『 命令运行失败后,所回传的错误信息』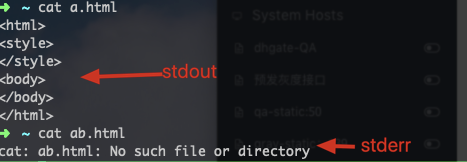
不管正确或错误的数据都是默认输出到屏幕上
3.2 数据流重导向

4 管线命令 (pipe)
bash 命令运行的时候有输出的数据会出现! 那么如果这群数据必需要经过几道手续之后才能得到我们所想要的格式.这就牵涉到管线命令的问题了 (pipe) ,管线命令使用的是『 | 』这个界定符号
- 管线命令仅会处理 standard output,对于 standard error output 会予以忽略
- 管线命令必须要能够接受来自前一个命令的数据成为 standard input 继续处理才行。
例如 less, more, head, tail 等都是可以接受 standard input 的管线命令啦。至于例如 ls, cp, mv 等就不是管线命令了!因为 ls, cp, mv 并不会接受来自 stdin 的数据
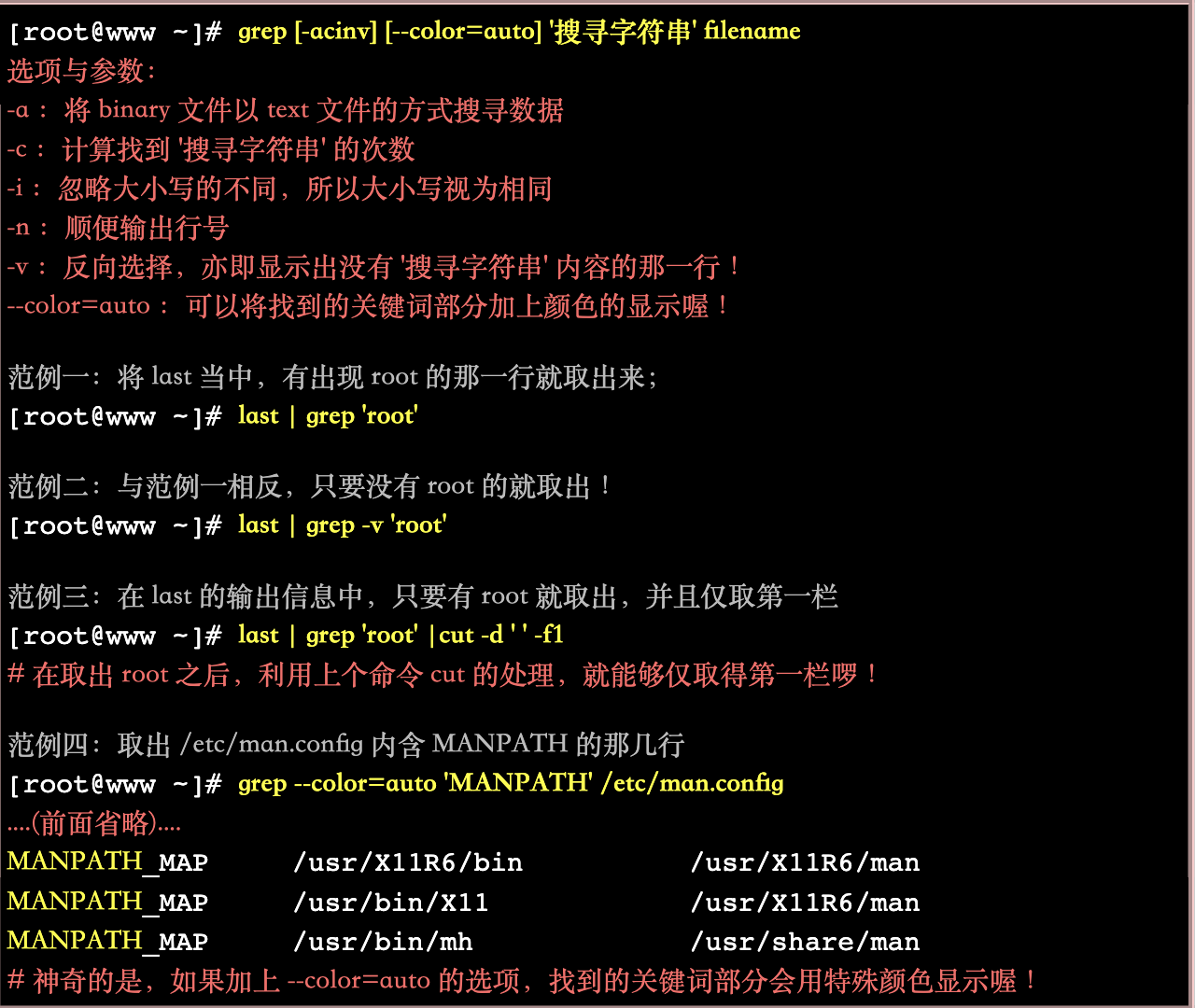
4.1 撷取命令: cut, grep
就是将一段数据经过分析后,取出我们所想要的。或者是经由分析关键词,取得我们所想要的那一行! 不过,要注意的是,一般来说,撷取信息通常是针对『一行一行』来分析的
4.1.1 grep
4.1.2 排序命令: sort, wc, uniq

若有收获,就点个赞吧
0 人点赞
