基本形式
给定由 个属性描述的示例
个属性描述的示例 ,其中
,其中 是
是 在第
在第 个属性上的取值,线性模型试图学得一个通过属性的线性组合来进行预测的函数:
个属性上的取值,线性模型试图学得一个通过属性的线性组合来进行预测的函数:

一般用向量形式写成:

其中 ,
, 和
和 学得后,模型得以确定。
学得后,模型得以确定。
线性回归
一元线性回归
当输入的属性的数目只有一个时,进行的线性回归模型为一元线性回归。一元线性回归试图学得:
 ,使得
,使得
通过减少 与
与 的差别(即减少预测值与实际值的误差),就可以学得
的差别(即减少预测值与实际值的误差),就可以学得 和
和 即获得模型。通常使用均方差(Mean Square Error)来做,均方差的几何意义其实就是欧式距离:
即获得模型。通常使用均方差(Mean Square Error)来做,均方差的几何意义其实就是欧式距离:

在线性回归中,最小二乘法(基于均方误差最小化来进行模型求解的方法)就是试图找到一条直线,使所有样本到直线的欧式距离之和最小:



因为 是凸函数,导数为
是凸函数,导数为 时即为我们所寻找的
时即为我们所寻找的 和
和 (下列公式先求导再使导数为
(下列公式先求导再使导数为 求解):
求解):







多元线性回归
更一般的情况,即样本有多个特征:给定数据集 ,
, ,即
,即 为第
为第 个样本,
个样本, 为其对应类别,
为其对应类别, 为其第
为其第 个特征属性。多元线性回归试图学得:
个特征属性。多元线性回归试图学得:
 ,使得
,使得
类似的,可利用最小二乘法来对 和
和 进行估计。为方便讨论,我们把
进行估计。为方便讨论,我们把 和
和 表示为向量形式
表示为向量形式 ,相应的,把数据集
,相应的,把数据集 表示为一个
表示为一个 大小的矩阵
大小的矩阵 ,其中每行对应于一个示例,该行前
,其中每行对应于一个示例,该行前 个元素对应于示例的第
个元素对应于示例的第 个属性值,最后一个元素恒置为1,即:
个属性值,最后一个元素恒置为1,即:

再把标记也写成向量形式 ,则有
,则有

令 ,对
,对 求导得:
求导得:

推导过程:将 展开可得:
展开可得:

对 求导可得:
求导可得:

由向量的求导公式可得:


令上式为零可得 最优解的闭式解。
最优解的闭式解。
对数线性回归
当我们希望线性模型的预测值逼近真实标记 时,就得到了线性回归模型。可否令模型预测逼近
时,就得到了线性回归模型。可否令模型预测逼近 的衍生物呢?譬如说,假设我们认为示例所对应的输出标记是在指数尺度上变化,那就可以将输出标记的对数作为线性模型逼近的目标,即
的衍生物呢?譬如说,假设我们认为示例所对应的输出标记是在指数尺度上变化,那就可以将输出标记的对数作为线性模型逼近的目标,即

这就是“对数线性回归”,他实际上是在试图让 逼近
逼近 。在形式上仍然是线性回归,但实质上已是在求取输入空间到输出空间的非线性函数映射。如下图所示,这里的对数函数起到了将线性回归模型的预测值与真实标记联系起来的作用
。在形式上仍然是线性回归,但实质上已是在求取输入空间到输出空间的非线性函数映射。如下图所示,这里的对数函数起到了将线性回归模型的预测值与真实标记联系起来的作用
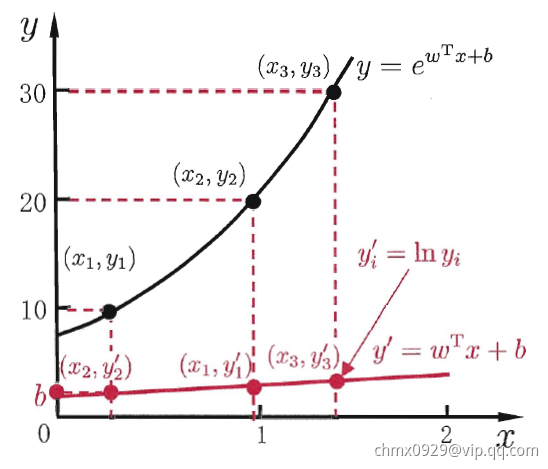
更一般地,考虑单调可微函数 ,令
,令

这样得到的模型称为“广义线性模型”,其中函数 称为“联系函数”。显然,对数线性回归是广义线性模型在
称为“联系函数”。显然,对数线性回归是广义线性模型在 时的特例。
时的特例。
LASSO、岭回归和弹性网络
岭回归&LASSO回归
即在原始的损失函数后添加正则项,来尽量的减小模型学习到的参数 的大小,使得模型的泛化能力更强
的大小,使得模型的泛化能力更强
岭回归(Ridge Regression):
Lasso Regression:
弹性网络(Elastic Net)
即在原始的损失函数后添加了 和
和 正则项,解决模型训练过程中的过拟合问题,同时结合了岭回归和LASSO回归的优势。
正则项,解决模型训练过程中的过拟合问题,同时结合了岭回归和LASSO回归的优势。 是新的超参数,表示添加的两个正则项的比例(分别为
是新的超参数,表示添加的两个正则项的比例(分别为 、
、 )
)

逻辑回归(对数几率回归)
二项逻辑回归
考虑分类任务,比如二分类任务,其输出标记 ,而线性回归模型产生的预测值
,而线性回归模型产生的预测值 是实值,于是,我们需将实值
是实值,于是,我们需将实值 转换为
转换为 值。最理想的是“单位阶跃函数”(unit-step function)
值。最理想的是“单位阶跃函数”(unit-step function)

即若预测值 大于零就判为正例,小于零就判为反例,预测值为临界值零则可任意判别。如下图所示
大于零就判为正例,小于零就判为反例,预测值为临界值零则可任意判别。如下图所示
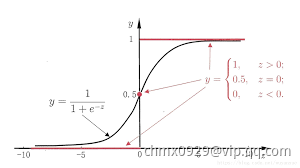
单位阶跃函数(上图红线)不连续,因此不能直接用作联系函数 。于是我们希望找到能在一定程度上近似单位阶跃函数的“替代函数”,并希望它单调可微。对数几率函数(logistic function)正是这样一个常用的替代函数:
。于是我们希望找到能在一定程度上近似单位阶跃函数的“替代函数”,并希望它单调可微。对数几率函数(logistic function)正是这样一个常用的替代函数:

对数几率函数是一种“Sigmoid函数”,它将 值转化为一个接近0或1的
值转化为一个接近0或1的 值,并且其输出值在
值,并且其输出值在 附近变化很陡,将对数几率函数作为联系函数
附近变化很陡,将对数几率函数作为联系函数 ,得到
,得到



即可变化为:

若将 视为样本
视为样本 作为正例的可能性,则
作为正例的可能性,则 是其反例的可能性,两者比值
是其反例的可能性,两者比值 称为“几率”,反映了
称为“几率”,反映了 作为正例的相对可能性。对几率取对数则得到“对数几率”:
作为正例的相对可能性。对几率取对数则得到“对数几率”:

由此可看出,实际上是在用线性回归模型的预测结果去逼近真实标记的对数几率,因此,其对应的模型称为“逻辑回归”或“对数几率回归”。特别注意的是,虽然名字是“回归”,但实际它却是一种分类学习方法。这种方法有很多优点,例如它是直接对分类可能性进行建模。无需事先假设数据分布,这样就避免了假设分布不准确所带来的问题;它不是仅预测出“类别”,而是可得到近似概率预测,这对许多需利用概率辅助决策的任务很有用。此外,对数几率是任意阶可导的凸函数,有很好的数学性质,现有的许多数值优化算法都可以直接用于求取最优解。
如何确定上式中的 和
和 。若将
。若将 视为类后验概率估计
视为类后验概率估计 ,则
,则







当然,我们也可通过极大似然法来估计 和
和 ,设
,设 ,
, 给定数据集
给定数据集 ,似然函数为:
,似然函数为:

对数似然函数为:



对 求极大值,得到
求极大值,得到 的估计值。这样,问题就变成了以对数似然函数为目标的最优化问题,逻辑回归学习中通常采用的方法是梯度下降法及牛顿法。假设
的估计值。这样,问题就变成了以对数似然函数为目标的最优化问题,逻辑回归学习中通常采用的方法是梯度下降法及牛顿法。假设 的极大似然估计值是
的极大似然估计值是 ,那么学到的逻辑回归模型为:
,那么学到的逻辑回归模型为:


多项逻辑回归
上面介绍的逻辑回归模型是二项分类模型,用于二分类。可以将其推广为多项逻辑回归模型,用于多分类任务。假设离散型随机变量 的取值集合是
的取值集合是 ,那么多项逻辑回归模型是:
,那么多项逻辑回归模型是:


二项逻辑回归的参数估计法也可以推广到多项逻辑回归。
线性判别分析
线性判别分析(Linear Discriminant Analysis,LDA)是一种监督学习的降维技术也可以做分类任务,也就是说它的数据集的每个样本是有类别输出的,这点和PCA不同。PCA是不考虑样本类别输出的无监督降维技术。LDA的思想可以用一句话概括,就是“投影后类内方差最小,类间方差最大”,如下图所示。我们要将数据在低维度上进行投影,我们投影后希望
- 每一种类别数据的投影点尽可能的接近
- 不同类别的数据的类别中心之间的距离尽可能的大
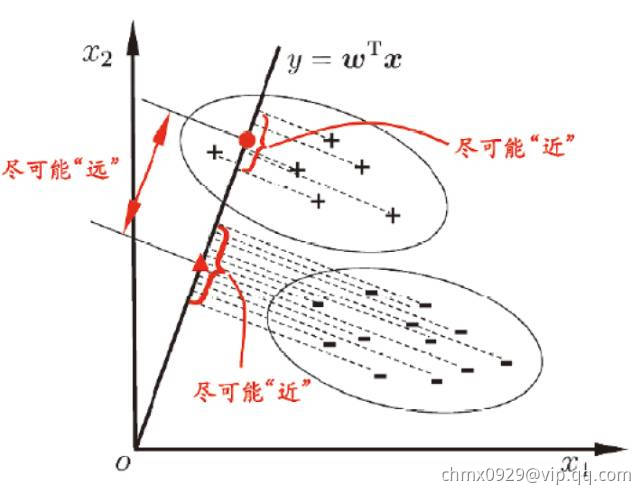
给定数据集 ,
,
第 类的集合
类的集合 ,第
,第 类的均值向量
类的均值向量 ,第
,第 类的协方差矩阵
类的协方差矩阵 ,
, 即一共就两类
即一共就两类
两类样本的中心在直线 上的投影,即直线与原均值向量的内积
上的投影,即直线与原均值向量的内积 和
和 。所有样本点都投影到直线上,则两类样本的协方差为
。所有样本点都投影到直线上,则两类样本的协方差为 和
和
- 投影后类内方差最小,即
 尽可能小
尽可能小 - 类间方差最大,即
 尽可能大
尽可能大
同时考虑优化二者,则可得到欲最大化的目标:

定义“类内散度矩阵”:
定义“类间散度矩阵”:
所以,我们可将最大化目标函数 写为:
写为:

这就是LDA欲最大化的目标,即 与
与 的“广义瑞利商”(Generalized Rayleigh Quotient)
的“广义瑞利商”(Generalized Rayleigh Quotient)
如何确定 呢?注意到上式的分子和分母都是关于
呢?注意到上式的分子和分母都是关于 的二次项,因此上式的解
的二次项,因此上式的解 的长度无关,只与其方向有关。不失一般性,令
的长度无关,只与其方向有关。不失一般性,令 ,上式等价于
,上式等价于

由拉格朗日乘子法,上式等价于

其中 是拉格朗日乘子。注意到
是拉格朗日乘子。注意到 的方向恒为
的方向恒为 ,不妨令
,不妨令 代入上式
代入上式

考虑到数值解的稳定性,在实践中通常是对 进行奇异值分解,即
进行奇异值分解,即 ,这里
,这里 是一个对角矩阵,其对角线上的元素是
是一个对角矩阵,其对角线上的元素是 的奇异值,然后再由
的奇异值,然后再由 得到
得到 。值得一提的是,LDA可从贝叶斯决策理论的角度来阐述,并可证明,当两类数据同先验,满足高斯分布且协方差相等时,LDA可达到最优分类。
。值得一提的是,LDA可从贝叶斯决策理论的角度来阐述,并可证明,当两类数据同先验,满足高斯分布且协方差相等时,LDA可达到最优分类。
多类别映射(分类)
若有很多类别,还是基于LDA基本思想,每个类间距离最大,类内距离最小。假定存在 个类,且第
个类,且第 类示例数为
类示例数为 ,我们先定义“全局散度矩阵”:
,我们先定义“全局散度矩阵”:

其中 是所有示例的均值向量,将类内散度矩阵
是所有示例的均值向量,将类内散度矩阵 重新定义为每个类别的散度矩阵之和,即
重新定义为每个类别的散度矩阵之和,即

整理上面两式可得

显然,多分类LDA可以有多种实现方法:使用 ,
, ,
, 三者中的任何两个即可,常见的一种实现是采用优化目标:
三者中的任何两个即可,常见的一种实现是采用优化目标:

其中 ,上式可通过广义特征值问题求解:
,上式可通过广义特征值问题求解: 。
。 的闭式解则是
的闭式解则是 的
的 个最大非零广义特征值所对应的特征向量组成的矩阵,
个最大非零广义特征值所对应的特征向量组成的矩阵, 。
。
将 视为一个投影矩阵,则多分类LDA将样本投影到
视为一个投影矩阵,则多分类LDA将样本投影到 维空间。
维空间。 通常远小于数据原有的属性数
通常远小于数据原有的属性数 于是,可通过这个投影来减少样本点的维数,且投影过程中采用了类别信息,因此LDA也常被视为一种经典的监督降维技术。
于是,可通过这个投影来减少样本点的维数,且投影过程中采用了类别信息,因此LDA也常被视为一种经典的监督降维技术。
Code实现
逻辑回归模型: ,其中
,其中
数据
from math import expimport numpy as npimport pandas as pdimport matplotlib.pyplot as plt%matplotlib inlinefrom sklearn.datasets import load_irisfrom sklearn.model_selection import train_test_split# datadef create_data():iris = load_iris()df = pd.DataFrame(iris.data, columns=iris.feature_names)df['label'] = iris.targetdf.columns = ['sepal length', 'sepal width', 'petal length', 'petal width', 'label']data = np.array(df.iloc[:100, [0,1,-1]])# print(data)return data[:,:2], data[:,-1]X, y = create_data()X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3)
手写实现
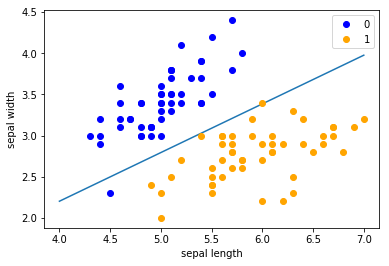
class LogisticReressionClassifier:def __init__(self, max_iter=200, learning_rate=0.01):self.max_iter = max_iterself.learning_rate = learning_ratedef sigmoid(self, x):return 1 / (1 + exp(-x))def data_matrix(self, X):data_mat = []for d in X:data_mat.append([1.0, *d])return data_matdef fit(self, X, y):# label = np.mat(y)data_mat = self.data_matrix(X) # m*nself.weights = np.zeros((len(data_mat[0]),1), dtype=np.float32)for iter_ in range(self.max_iter):for i in range(len(X)):result = self.sigmoid(np.dot(data_mat[i], self.weights))error = y[i] - resultself.weights += self.learning_rate * error * np.transpose([data_mat[i]])print('LogisticRegression Model(learning_rate={},max_iter={})'.format(self.learning_rate, self.max_iter))# def f(self, x):# return -(self.weights[0] + self.weights[1] * x) / self.weights[2]def score(self, X_test, y_test):right = 0X_test = self.data_matrix(X_test)for x, y in zip(X_test, y_test):result = np.dot(x, self.weights)if (result > 0 and y == 1) or (result < 0 and y == 0):right += 1return right / len(X_test)lr_clf = LogisticReressionClassifier()lr_clf.fit(X_train, y_train)lr_clf.score(X_test, y_test)x_ponits = np.arange(4, 8)y_ = -(lr_clf.weights[1]*x_ponits + lr_clf.weights[0])/lr_clf.weights[2]plt.plot(x_ponits, y_)#lr_clf.show_graph()plt.scatter(X[:50,0],X[:50,1], label='0')plt.scatter(X[50:,0],X[50:,1], label='1')plt.legend()
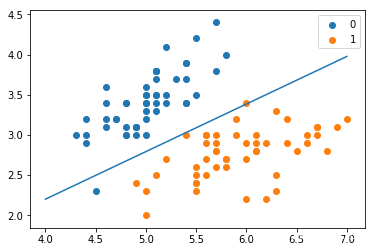
sklearn实现
https://scikit-learn.org/stable/modules/generated/sklearn.linear_model.LogisticRegression.html
solver参数决定了我们对逻辑回归损失函数的优化方法,有四种算法可以选择,分别是:
- liblinear:使用了开源的liblinear库实现,内部使用了坐标轴下降法来迭代优化损失函数。
- lbfgs:拟牛顿法的一种,利用损失函数二阶导数矩阵即海森矩阵来迭代优化损失函数。
- newton-cg:也是牛顿法家族的一种,利用损失函数二阶导数矩阵即海森矩阵来迭代优化损失函数。
- sag:即随机平均梯度下降,是梯度下降法的变种,和普通梯度下降法的区别是每次迭代仅仅用一部分的样本来计算梯度,适合于样本数据多的时候。
from sklearn.linear_model import LogisticRegressionclf = LogisticRegression(max_iter=200)clf.fit(X_train, y_train)clf.score(X_test, y_test)print(clf.coef_, clf.intercept_)x_ponits = np.arange(4, 8)y_ = -(clf.coef_[0][0]*x_ponits + clf.intercept_)/clf.coef_[0][1]plt.plot(x_ponits, y_)plt.plot(X[:50, 0], X[:50, 1], 'bo', color='blue', label='0')plt.plot(X[50:, 0], X[50:, 1], 'bo', color='orange', label='1')plt.xlabel('sepal length')plt.ylabel('sepal width')plt.legend()
Source

若有收获,就点个赞吧
0 人点赞
