FCN、DeconvNet和SegNet都表明为分类而训练的卷积网络可以用来进行语义分割。那么,在新的迁移网络中哪部分是真正有效的?哪部分在做稠密预测时会降低准确率?为稠密网络专门训练的模型是否能够进一步提升准确率呢?
分类网络通过下采样来获得不同尺度的上下文信息。然而,稠密预测不仅需要多尺度的上下文信息,还需要全分辨率的输出。最近有两种方法来解决多尺度和全分辨率输出的矛盾:第一,通过下采样获取全局信息后,使用多层上采样-卷积来恢复丢失的分辨率信息;第二,使用多尺度的输入图片作为多个输入,然后把不同输入的预测结合起来。
DilatedConvNet与前面所述的三种网络结构不同,前三种网络都是子分类网络的基础上加入了解码结构,使得原来求解分类问题的网络变为求解稠密问题的网络。而DilatedConvNet则使用了空洞卷积(Dilated Convolution),在不损失分辨率、不需要借助多尺度输入图片的基础上,融合了多尺度的上下文信息。这是卷积层的一个变种,不需要借助降采样/池化层。 空洞卷积示意图:
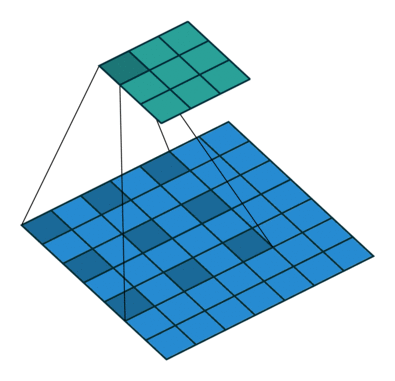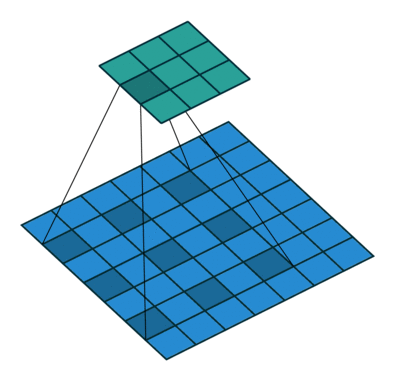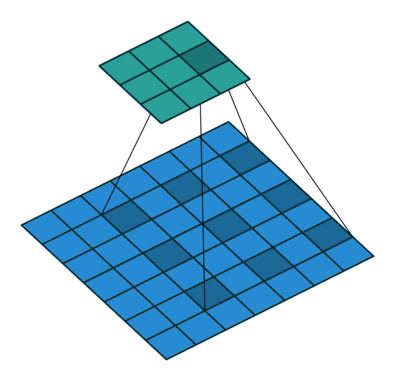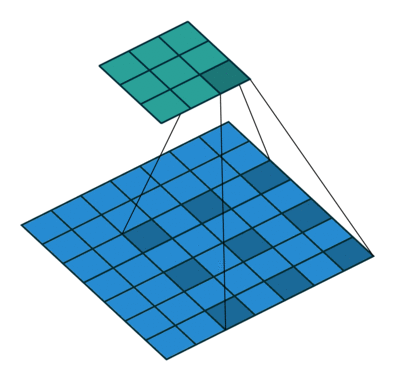
DilatedConvNet的实现也以VGGNet16为蓝本,但是去掉了所有的池化和步长(Stride),而是以空洞卷积层来扩大感受野。实验指出,去掉池化层和中间层的填充(Padding),会提升准确率。

若有收获,就点个赞吧
0 人点赞
